基于YOLOv3-SE-RE 模型的羊姿态识别
2023-02-08李小迪王天一
李小迪,王天一
(贵州大学 大数据与信息工程学院,贵阳 550000)
0 引言
随着智能信息处理技术的快步发展,羊养殖业方式从传统的个体散养模式逐渐转变为规模化、智能化养殖。在传统养殖方式中多采用人工观测法[1]和无线射频[2]的方式,对羊只个体进行目标检测。人工观测法需要耗费大量的人力和时间,不仅检测效率低,且检测错误率高;无线射频的方式需要额外的设备与同步的识别方法,一定程度上提高了养殖场的运营成本,影响养殖场的经济效益。传统的姿态识别多使用回归出精确关节点坐标的方式或无线传感网络来对姿态进行判别,在运动灵活的个体识别上可扩展性较差,且识别成本较高。
近年来,基于深度学习的目标检测[3]和姿态识别的方法,已成为国内外研究热点,其典型算法为YOLO 系列算法。YOLO 系列算法利用了回归的思想,能够在原图片中的位置上,回归出目标检测的边框和目标的类别。为了实时对羊只状况进行了解,本文以羊只养殖场监控视频为研究对象,使用YOLOv3[4-6]网络。YOLOv3 主干网络采用残差结构,其目的是为了防止连续下采样导致的特征丢失。但是该方法仍然保持了传统的卷积操作,带来了巨大的flpos 计算量,虽保证了特征提取的多尺度性,但是却一定程度的增加了模型推理的时间。在监控视频的羊只检测与识别的视觉任务中,羊只整体呈现白色,RGB 3 通道值均接近255,其大部分本体并不包含足够的视觉信息。同时,目标本体一定程度上存在周围环境的遮挡,即使是人眼视觉都很难辨认。从深度学习层面可以认为这种监督信号比较稀疏,给检测和识别任务增加了难度。
在人脑对于羊只的感知中,当一张图片中存在羊只时,人眼看到后会下意识地将注意力转移到羊只上,而忽略周围环境。此外,人眼并不需要看全羊只整体,通过羊只犄角,腿部等局部特征便可辨认目标,还可以结合周围环境的全局线索去推理出羊只的具体位置。另一方面,对于骨干网络来说,占据整张图中绝大部分还是周围单调的环境信息,计算机对于不同通道之间的特征会等价处理。
受此启发,为了实现骨干网络对于多尺度特征提取的性能,去除单调的环境对目标的干扰,同时减少模型的计算量,本文选择循环特征移位聚合器(Recurrent Feature-Shift Aggregator,RESA)[7]来替代YOLOv3 主干网络中的Resblock[8]部分,且增加了通道注意力[9]模块压缩激励 网 络(Squeeze-and -Excitation Networks,SENet),使网络在训练过程中将更多的权重转移到重要的通道信息上。此外,本文采用余弦退火学习率[10-11],在整个训练过程中控制模型的收敛性。通过在训练初期设置较大的学习率来避免陷入局部最优解,并在训练过程中逐渐降低学习率,使得模型能够稳定的学习,进而收敛到全局最优解。
1 网络结构
1.1 YOLOv3
如图1 所示,YOLOv3 由darknet53、特征金字塔(Feature Pyramid Network,FPN)及YOLO Head 3 部分构成。
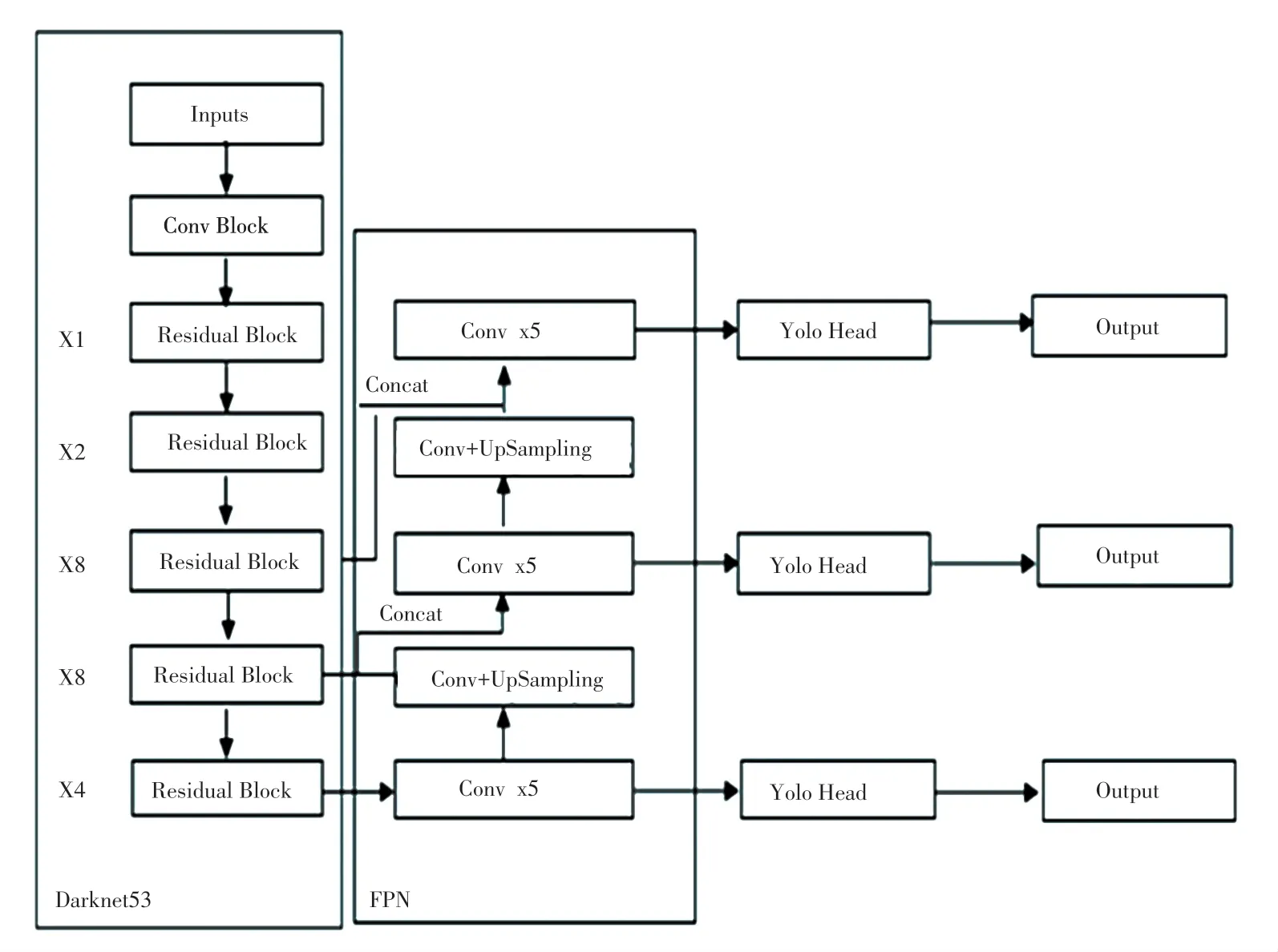
图1 YOLOv3 网络结构Fig.1 Yolov3 network structure
Darknet53 被称作YOLOv3 的主干特征提取网络,输入的图片首先会在Darknet53 中进行特征提取。该模块由一个普通卷积模块和5 个残差块组成,输入图片首先会被调整成416×416×3 的大小,卷积过程对图片进行下采样处理,每经过一个卷积模块图片的宽和高就会被压缩至原图片的1/2,通道数在卷积过程中不断扩张,以此获得一系列特征层,用来表示输入图片的特征。
FPN 被称作YOLOv3 的加强特征提取网络,在主干部分获得的3 个有效特征层,会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在获得3 个有效特征层后,利用其进行FPN 层的构建。
YOLO Head 实际上就是YOLOv3 的分类器与回归器,其所做的工作就是进行分类预测与回归预测。因此,整个YOLOv3 网络所作的工作就是特征提取-特征加强-获得预测结果。
1.2 SENet
如图2 所示为SENet 的结构图,SENet 可以分为压 缩(squeeze),激 励 excitation)和 重 标 定(reweight)3 个部分。
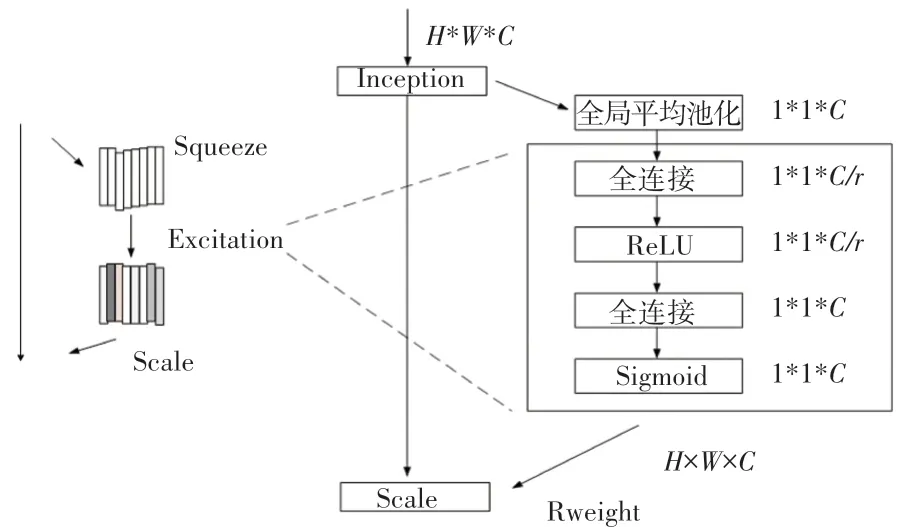
图2 SENet 结构图Fig.2 Structure of SENet
输入一张大小为H*W*C的特征图(H、W、C分别为该特征图的高、宽、通道数),经过squeeze 模块,将特征图顺着空间维度进行压缩,通过全局平均池化操作,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,最终输出1*1*C的特征图。输出的维度和输入的特征通道数相匹配,实现每个通道的所有特征求均值,旨在得到通道级的全局特征。
excitation 部分包括两个全连接层和两个激活函数。输入图片经过第一个全连接层时,通道数降为C/r(r为衰减因子,参照文献[12]中验证,r取值为16),然后使用ReLU激活函数激活;经过第二个全连接层时,恢复至C通道数,接着使用Sigmoid函数激活。基于通道间的相关性,每个通道生成一个权重,用来代表特征通道的重要程度。通过训练过程中学习权重,使得每一层通道获得非线性,即学习各个通道之间的主次关系。
最后,在reweight 部分,将excitation 输出的权重看做每个特征通道的重要性,通过乘法逐通道加权到之前的特征上,完成通道维度上对原始特征的重标定,从而实现不同通道特征重要性的区分。
1.3 RESA 算法
RESA 算法是通过一个介于编码器(用于特征提取)和解码器(用于目标恢复)之间的RESA 模块,将骨干网络中提取到的空间信息(局部信息与全局信息)进行聚合,使得原始特征得到增强。该模块在特征传递之前会将特征图中的特征进行切片,若要将特征进行左右传递,则先将特征图在列方向分为很多个切片,随后不同特征加权叠加。同理,在行方向上进行特征切片以及加权,左右及上下方向的信息传递均能够增强羊只不同特征部位以及周围环境的关联性。通过信息传递,理论上能够有助于目标的推理。从网络结构来看,RESA 模块采用了大量切片特征加权,因此这种非常规卷积的特征传递方式,能够减少时间消耗,且经过不同步长的特征迭代,最终输出的特征图上,每个像素整合了全局的每一处特征信息,能够有效防止传播过程中信息的丢失。
RESA 模块如图3 所示,其中包含了4 种子模块。分别为左->右、上->下、右->左、下->上,每部分模块均为n次迭代。图3(a)为左->右模块1-n次迭代的结构图,其中包含了不同步长下的信息传递示意图。特征图被纵向分为许多切片,当步长为1 时,由左数第一个切片的特征经卷积操作后,叠加至第二个切片。同理,当步长为2 的时候会叠加至第三个切片,以此类推。图3(b)为从下->上的模块,处理过程同上。
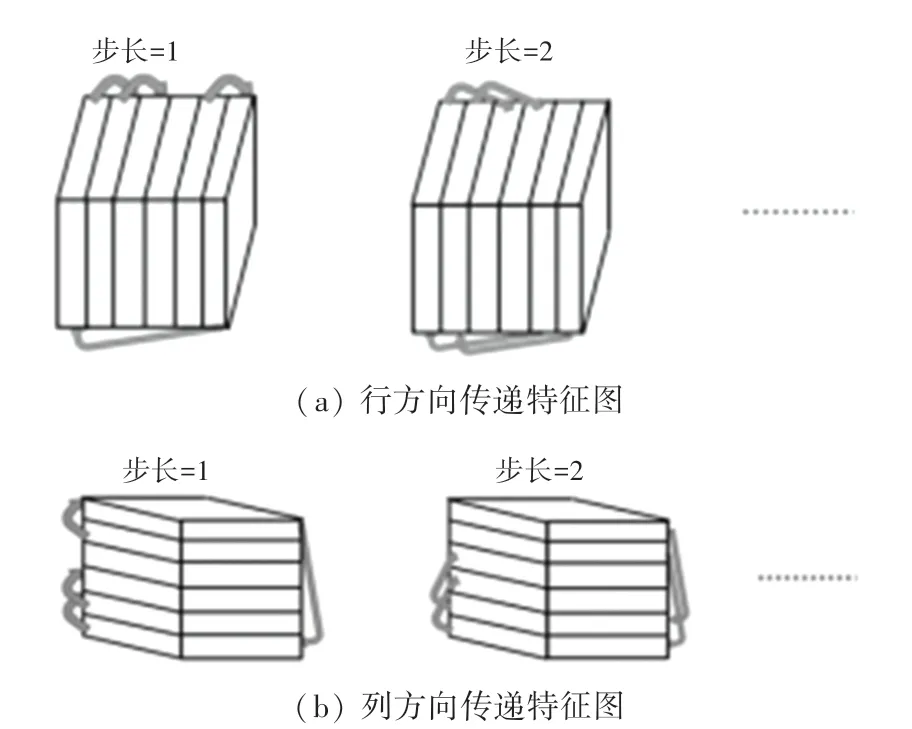
图3 RESA 模块结构图Fig.3 Structure diagram of RESA module
1.4 YOLOv3-SE-RE 模型
本文在YOLOv3 的主干网络上进行了模型的优化,当第一次完成特征层提取后,嵌入SENet 模块,如图4 所示。首先,输入图片的尺寸会被调整为416×416×3,经过一次1×1 卷积后,特征图的通道数得到扩展,尺寸变为416×416×32;随后,特征图进入SE 模块进行压缩,经过全局平均池化操作后,特征图的大小被压缩为1×1×32;经过全连接层,特征图的大小变为1×1×2,衰减因子r为16。使用ReLU激活函数进行激活,此时的通道数不变;再经过一层全连接层,恢复通道数为32;最后使用Sigmoid函数进行激活,此时每个通道都分配到了不同的权重;再通过乘法,逐通道加权到之前的特征上,权重值越大,说明网络对该通道的关注度越高;其次,去除YOLOv3 主干网络中的残差结构,将分配好权重的特征图输入到RESA 模块中,进行行方向和列方向的切片处理,使得空间通道特征得以丰富。
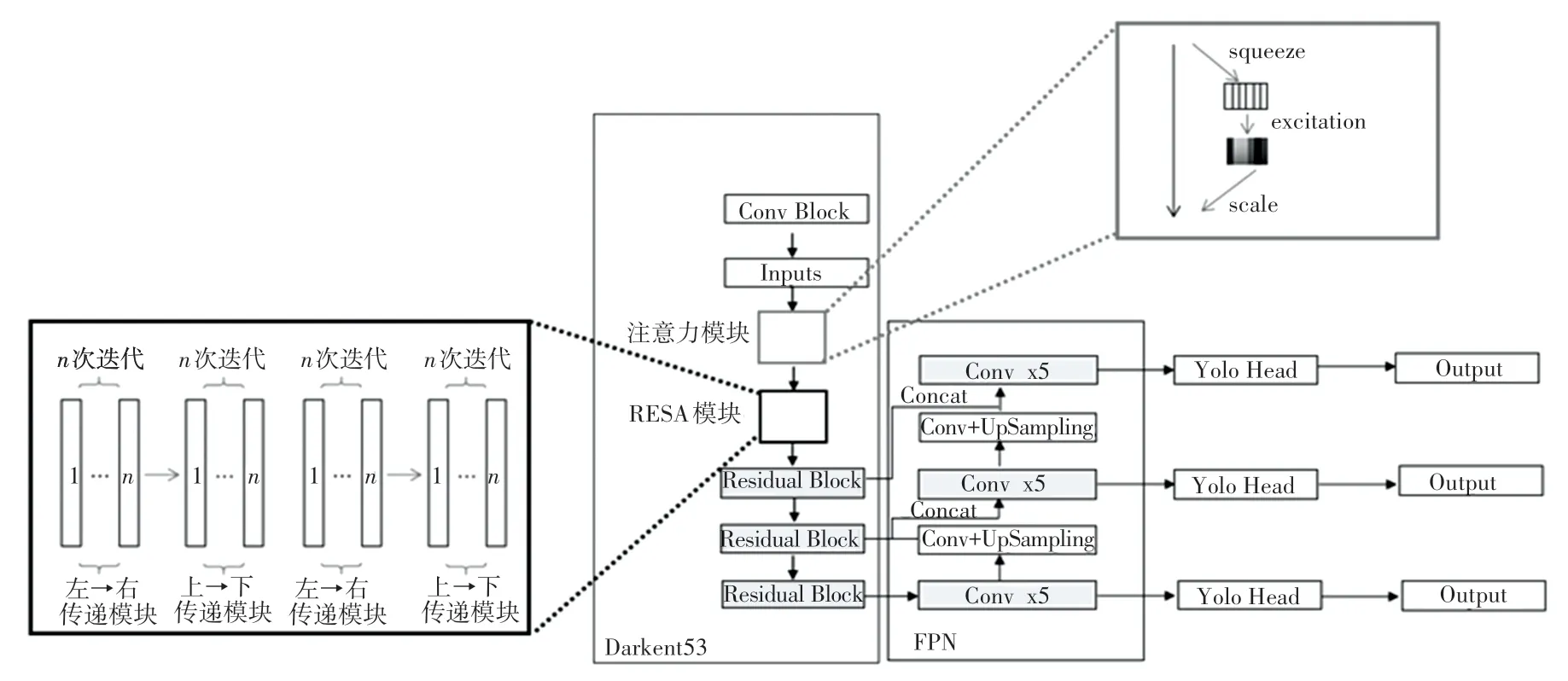
图4 YOLOv3-SE-RE 模型结构图Fig.4 Structure diagram of Yolov3-SE-RE model
2 余弦退火学习率
在训练网络时,学习率会随着训练而发生变化。在训练网络的后期,若学习率过高,则会造成损失的振荡,而学习率衰减过快,则会造成模型收敛变慢的情况。由于模型在训练初期对于图像是完全未知的,即模型对于像素信息的理解相当于均匀分布,因此训练初期模型非常容易陷入过拟合。基于此,本文采用余弦退火方式对学习率进行调整,余弦退火学习率整体符合余弦函数的变化方式。余弦函数中,随着x的变化,函数值先缓慢下降然后加速下降,以此为一个周期循环。当模型经过几个轮次的训练后,逐渐对于数据集有所了解,此时需要降低学习率,使得模型能够稳定的学习,从而向着全局最优解去收敛。这种下降模式与学习率结合,能轻松让模型跳出局部最优解。学习率定义如下:

这两个值限制了学习率的范围,使学习率能够在一定范围内衰减。Tcur表示当前执行了多少个轮次(epoch),由于Tcur在每个批次(batch)运行后将会更新,而此时的epoch 还没有执行完,因此Tcur可以为小数。Ti表示第i次运行时总的epoch 数。本文中,模型的初始学习率设置为0.01,随着epoch 的增加,学习率按照余弦规律减小,开始下降速度缓慢,当训练到第20 个epoch 时,学习率下降速度变快,最终大小为5×10-4。
3 实验
3.1 数据集
3.1.1 数据集构成
为了获取高质量的羊只图片,需要对获取到的羊舍监控视频进行预处理操作,首先将获得的3 047个监控视频进行手动裁剪,裁剪出合适的角度后手动删除无效片段。由于羊只在监控视频中多出现站立和坐卧的姿势,于是将裁剪出的有效监控按照羊的姿势分为站立(stand)和坐卧(lie down)两个类别,共计309 个有效监控视频。然后对有效监控视频进行关键帧的提取,由于羊只在羊舍内的活动范围较小,在短时间内羊只的姿态不会发生明显的变化,因此每隔50 帧提取一张关键帧图片。此外,通过手动删除关键帧中羊只肢体不全、遮挡严重、无羊只等无效图像,最终得到808 张羊只站立图片和1 192张羊只坐卧图片,共计2 000 张图片。
3.1.2 数据集的标注
本文使用Labelimg 标注工具对羊只数据集图像进行标注,标注过程中为了不引入太多的背景,只对羊只主体进行标注,数据集按照训练集和测试集8 ∶2 的方式划分,模型优化前后均在相同的数据集下训练测试40 轮次。
3.2 实验环境
实验均在Ubuntu18.04.4LTS 操作系统上进行,python3.7,tensorflow2.0 深度学习框架,cpu 为i7-9700,显卡为RTX 2080Ti,使用Labelimg 对自建数据集进行标记,总共2 000 张图片,按照8 ∶2 的比例划分为训练集和测试集。
3.3 实验结果分析
本文将基于通道注意力机制的YOLOv3 模型称为YOLOv3-SE 模型、基于RESA 算法的YOLOv3 模型称为YOLOv3-RE 模型、基于通道注意力机制及RESA 算法的模型称为YOLOv3-SE-RE 模型。
3.3.1mAP及检测速度对比
将上述4 个模型在自建数据集上训练40 个epoch 后,对训练好的模型进行测试实验。测试集图片共400 张,在相同的测试集下分别测试了算法优化前后模型的推理速度,即前向传播一次,推理一张图片所用的时间及模型在测试集上的mAP值见表1。
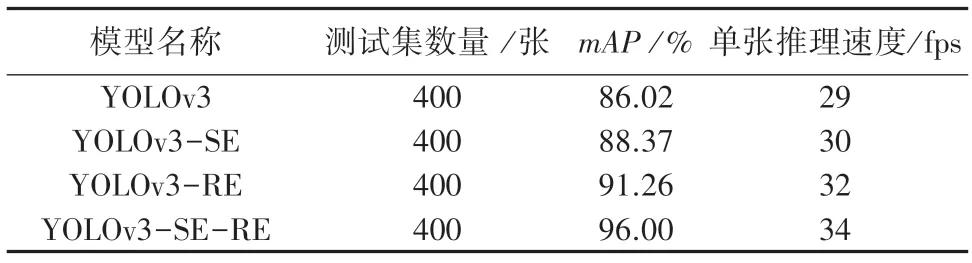
表1 YOLOv3 算法与改进后系列算法在测试集上的实验结果Tab.1 Experimental results of YOLOv3 algorithm and a series of improved algorithms on the test set
由此可见,YOLOv3 模型的mAP为86.02%,YOLOv3-SE 模型的mAP达到了88.37%,相比YOLOv3 模型增加了2.35%;YOLOv3-RE 模型的mAP达到了91.26%,相比于YOLOv3 模型增加了5.24%。
实验表明,增加了注意力机制的YOLOv3 模型,以及增加了RESA 模块的YOLOv3 模型,目标检测均值平均精度略高于YOLOv3 模型。而结合了两个模块的YOLOv3-SE-RE 模型的目标检测的均值平均精度为96%,明显高于YOLOv3 模型,且单张图片推理速度也明显高于YOLOv3 模型。
3.3.2 精确度与召回率对比
模型优化前后,精确度与召回率的对比结果如图5 所示。
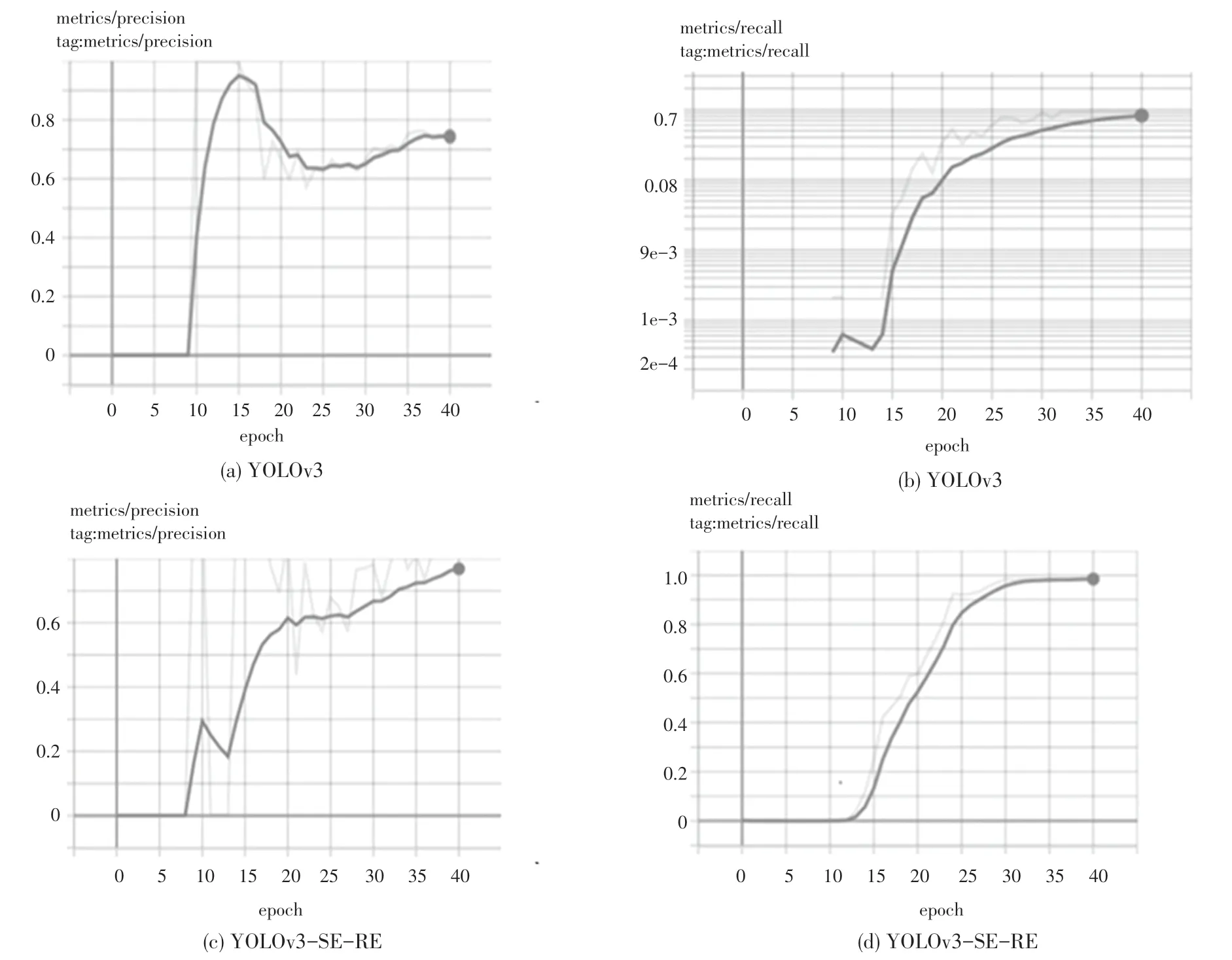
图5 精确度与召回率比较Fig.5 Comparison between accuracy and recall
由图5(a)、(b)所见,YOLOv3 模型的精确率与召回率稳定在0.75 与0.7,当模型在训练到第15 个epoch 时,精确度达到最高,然后开始下降。而YOLOv3-SE-RE 模型两项测试指标在模型训练至40 epoch分别提升至0.79 与0.97。由此可见,无论是精确率还是召回率,优化后的模型更加平稳,且收敛速度更快。
3.3.3 Loss 的对比
模型在训练过程中损失函数可视化结果如图6所示。由图6(a)可见,obj_loss 在第40 个epoch 时损失达到了2.5e-3。而从模型优化后的损失函数曲线(图6(b))可以看到,当模型训练到第40 个epoch 时,损失可降低至2e-3。由于余弦退火学习率的加入,使得整个训练过程中损失函数收敛的更快且更加平滑。
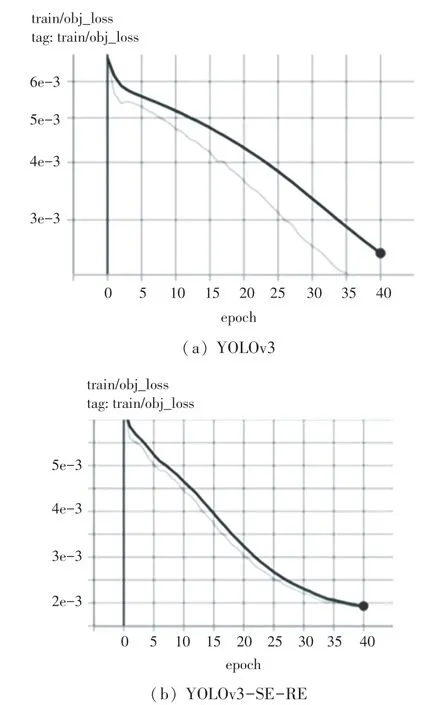
图6 损失函数比较Fig.6 Loss function comparison
3.3.4 站立姿态检测效果对比
如图7 所示,在站立姿态下,与YOLOv3 算法相比,YOLOv3-SE 算法的预测框将右下角羊蹄完整框入其中,且预测框紧贴羊只个体;YOLOv3-RE 算法预测框将羊只的左右两只羊蹄完整框入其中,且预测框紧贴羊只个体;YOLOv3-SE-RE 算法预测框将羊只个体完整框入其中,且预测框紧贴羊只个体且没有将过多的背景框入其中。实验证明,通道注意力机制,可以使模型更加关注包含重要信息的通道,减少对背景的关注度。RESA 算法可以增加羊只不同部位之间的关联性,通道注意力机制与RESA 模块均可以提升模型的检测精度。
3.3.5 坐卧姿态检测效果对比
如图8 所示,在坐卧姿态中,与YOLOv3 算法相比,YOLOv3-SE 算法的预测框更完全的将羊只框入其中,且预测框紧贴羊只个体没有框入过多背景;YOLOv3-RE 算法预测框的准确率以及置信度均略高于YOLOv3 模型;YOLOv3-SE-RE 算法预测框,将两只紧贴的羊只个体完全框入其中,预测框紧贴羊只个体并没有将过多背景,且置信度也有所提高。实验证明,在坐卧姿态下,改进后的网络识别效果明显优于原模型。

图8 坐卧姿态检测效果Fig.8 Sitting and lying posture detection effect
4 结束语
本文通过对YOLOv3 算法的优化,实现了对视频监控中羊只姿态的高效识别。首先在主干网络darknet53 中增加通道注意力机制,增加不同通道的特征相关性,让网络重点关注权重值较大的通道信息,以提高网络的检测精度。其次通过增加RESA模块,对特征图进行行方向和列方向的切片和聚合,增加目标检测物体不同部位之间的关联性,同时提高了检测精度和速度。实验结果表明,YOLOv3-SE-RE 模型在检测精度和检测速度上都超过了原始YOLOv3 模型,对于不同姿态的识别,效果也有明显的优化,本应用在智能养殖方面有较好的应用前景。
