基于LBP 等价模式和注意力机制的图像修复算法
2023-02-08王浩明
王浩明
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
图像修复是指运用技术手段对图像中缺失破损的区域进行重建的过程。这一技术被广泛应用于文物和老照片的修复、医学图像和卫星遥感图像的去噪、影视特效以及军事安全等多个领域。
目前图像修复算法中常采用两阶段网络结构:先在第一阶段网络中粗略地预测缺失的结构,再用预测的结构信息指导第二阶段网络进行更精细的修复,这是一个由粗到细的过程。Huang 等人[1]在第一阶段使用一个简单的膨胀卷积网络,在第二阶段整合上下文注意层来完成最终的修复;Liu 等人[2]提出的两阶段网络都是基于U-Net 结构,为了获得更好的空间一致性,在第二阶段还额外引入了连贯语义注意层;Ren 等人[3]设计了StructureFlow,在第一阶段保留边缘的平滑图像来训练结构重建器,在第二阶段使用带有外观流的纹理生成器生成图像细节;Nazeri 等人[4]还提出了一个由边缘生成器紧接一个图像修复网络组成的EdgeConnect 模型。
尽管两阶段网络模型已经取得一定成效,但是在面对内容复杂的图像时,得到的修复结果仍然容易产生伪影与模糊,使得最终修复结果的整体与局部的一致性都有所下降。造成这一结果的根本原因在于第一阶段得到的结构信息质量不高,不足以为第二阶段提供良好的指导,且在第二阶段中不能使用最适合的patches 来对缺失区域进行进一步填充,对两阶段网络的不同设计将产生不同的修复效果。
基于这一思路,本文在Wu 等人[5]的工作的启发下提出了一种新的两阶段网络,更好地解决面对复杂图像会出现伪影与模糊的问题。
1 算法整体概述
本文算法的整体流程如图1 所示。在生成器G1、G2中,每一层上面的数字表示输入256×256×3的图像时卷积层/反卷积层得到的每层特征图的尺寸,每一层下面的数字则表示卷积层/反卷积层每层的输入通道数。
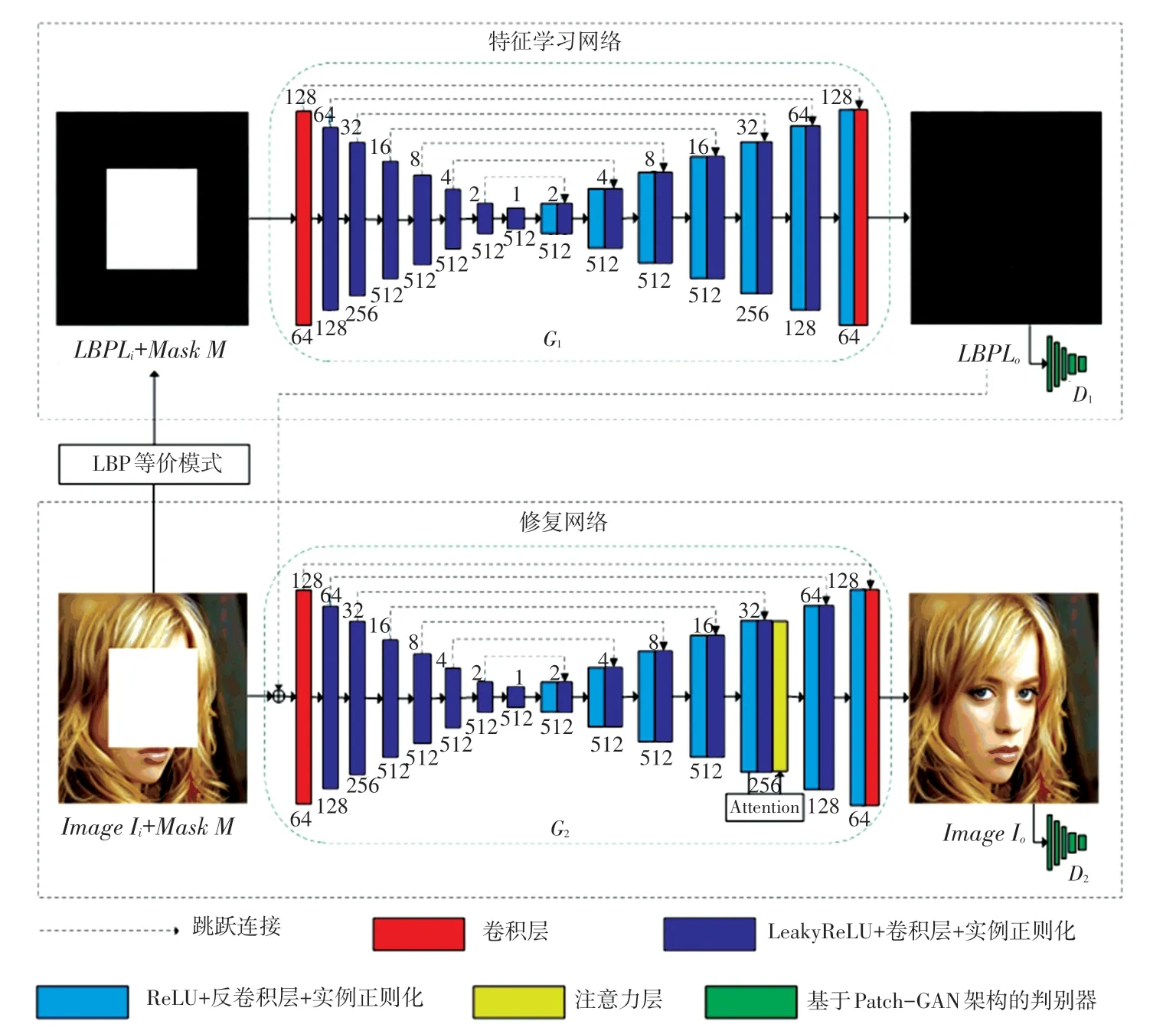
图1 算法整体流程图Fig.1 Overall flow chart of the algorithm
1.1 特征学习网络流程
第一阶段的特征学习网络用于预测出完整的LBP 结构信息,为第二阶段修复网络进一步的精细修复提供指导,是一种粗修复。
特征学习网络的输入由Ii的LBP 特征图Li以及合成Ii对应的MaskM组成。
其中,Ii是由完整图片与MaskM融合生成的破损图片,LBP 特征的提取是通过LBP 等价模式完成的;输入的Li和M经过生成器G1与判别器D1的不断博弈,最终由G1预测出完整的LBP 特征图Lo,作为第二阶段修复网络输入的一部分。
1.2 修复网络流程
第二阶段的修复网络用于完成最终精细的修复。修复网络的生成器G2是以第一阶段的最终输出Lo以及Ii与其对应的MaskM作为输入的,通过G2与修复网络的判别器D2的联合训练,输出最终的修复结果Io。
2 特征学习网络
特征学习网络主要由LBP 等价模式模块、生成器G1和判别器D1组成。
2.1 LBP 等价模式
在许多两阶段图像修复网络中,都需要使用在第一阶段网络中捕获的结构信息为第二阶段网络提供指导,因此捕获到的结构信息质量将直接影响后续图像修复的质量。目前许多两阶段图像修复网络中使用的结构信息,通常涉及许多参数,如预滤波强度和边缘响应阈值等,并且其最佳设置也因图像而异。
相比之下,LBP 特征涉及参数少,并且在纹理较细的区域,包含了更丰富的结构信息。此外,相比其他特征需要不断调整参数设置,来获取最佳效果,LBP 特征更加通用简单,因此本文选用LBP 特征作为第一阶段的结构信息。在此基础上,本文使用了LBP 的等价模式,通过设置半径R =1,采样点P =8,实现LBP 算子模式种类数量的进一步减少。实验证明,本文采用的LBP 等价模式对于最终的修复效果起到了很好的引导作用。
2.1.1 原始LBP
局部二值模式(Local Binary Pattern,LBP)是一种用于描述图像局部纹理特征的算子,具有涉及参数少,包含丰富结构信息的优点[6]。
原始LBP 的计算方式示意如图2 所示。以图像上任一像素点(如图2 中像素值为5 的黄色像素点)为中心,对其取一个3×3 的邻域,依次将邻域中的其余8 个点与中心像素点进行像素值的比较,比中心像素点像素值大的置1,反之置0;从左上角(如图2 中原像素值为3 的像素点)开始,顺时针依次将这些0 和1 连成一个八位二进制序列(图2 中为01100101);最后,将序列转换为十进制,便得到了这一像素点的LBP 值;依次计算图像上的每一个像素点的LBP 值,便可得到整张图像的LBP 特征图。
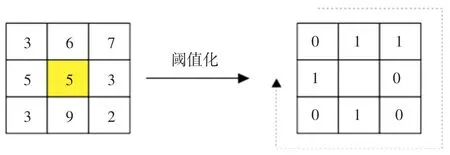
图2 原始LBP 计算方式示意图Fig.2 Schematic diagram of the original LBP calculation method
2.1.2 圆形LBP 算法
为了增强LBP 适应不同尺寸图片的能力,圆形LBP 算法被提出[7]。具体来说是通过使用半径为R,采样点总个数为P的圆形邻域代替正方形邻域,如图3 所示。从左到右依次为:半径为1,采样点数为8;半径为2,采样点数为8;半径为2,采样点数为16 的示意图。
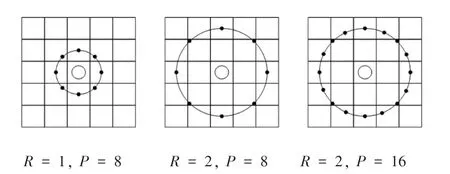
图3 圆形LBP 示意图Fig.3 Schematic diagram of Circular LBP
圆形LBP 算法首先需要计算出除了中心像素点以外其余各个采样点的坐标,根据坐标找到对应位置的像素值,依旧按照前面的原始LBP 计算方式计算出中心像素对应的LBP 值,第p个采样点的坐标(xp,yp)计算公式如式(1)所示。
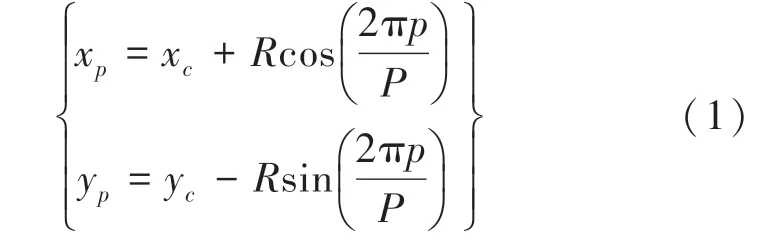
其中,(xc,yc)为中心像素点坐标;R表示半径;P表示采样点总个数。
2.1.3 LBP 等价模式
由圆形LBP 算法可以看出,P个采样点对应着2P种模式,这种指数对应关系,使得P即使变动不大,二值模式种类的数量也会发生巨大变化,这对于纹理的提取、识别和分类都是不利的。所以需要使用等价模式来减少LBP 算子的模式种类的数量,实现对圆形LBP 算法的进一步优化[7]。
当某个LBP 值所对应的二进制数从0 到1 或从1 到0 最多有两次跳变时,该LBP 值所对应的二进制就定义为一个等价模式类,其余的都被称为混合模式类。
LBP 等价模式使二值模式的种类数量大大减少,由原来的2P种减少为P(P -1)+1 种,而不会丢失任何信息。
2.2 生成器G1 概述
为了获得更精细的图像修复结果,本文的特征学习网络的生成器G1保留了Shift-Net 中生成器的U-Net 架构,其完整的网络结构见表1。Conv、DeConv、Cat、LReLU、IN 分别代表卷积层、反卷积层、连接层、α =0.2 的LeakyReLU 以及实例正则化(InstanceNorm)。每个括号里的4 个数字都分别代表滤波器数量(即通道数)、卷积核尺寸、步长以及padding 数目。如:Conv(128,4,2,1),括号里的4个数字分别表示滤波器数量为128,卷积核尺寸为4×4,步长为2,padding 为1。

表1 G1 完整结构Tab.1 The complete structure of G1
G1的编码器部分(层1-层8)除了第一层是卷积层外,每层都是由Leaky ReLU、卷积以及InstanceNorm层叠加而成,编码阶段各卷积层的输入通道数依次为64、128、256、512、512、512、512、512。
G1的解码器部分(层8-层15)都是由ReLU、反卷积层以及实例正则化叠加而成。解码阶段各反卷积层输入通道数依次为512、512、512、512、256、128、64、3。
2.3 判别器D1 概述
对于特征学习网络的判别器D1,本文采用PatchGAN 架构,见表2。D1与G1的编码器部分具有相似的设计模式,但只有5 个卷积层。除了第一层和第五层,每一层的卷积层后都紧接一个实例正则化,除了第一层,每一层都有一个α =0.2 的LeakyReLU 层。卷积层的卷积核尺寸都为4×4、步长都为2,padding 都为1,各卷积层的输入通道数依次为64、128、256、512、1。此外,最后一层使用了Sigmoid 作为激活函数。

表2 D1 完整结构Tab.2 The complete structure of D1
3 修复网络
修复网络主要由生成器G2和判别器D2组成。在生成器G2中,除了引入了新的注意层,G2与G1、D2与D1都分别采用了完全相同的结构。
为了使修复结果同时在全局和局部上具备更好的一致性,在修复网络的生成器中加入新的注意层。现有的使用注意力机制的算法都默认缺失区域与已知区域具有相同的结构特征,仅在已知区域中搜寻相似patches 来对缺失区域进行填充,可能会遗漏掉更高质量的patches。本文的注意层将搜索范围扩大到已知区域以及修复过程中生成的区域,以得到更高质量的相似patches。

其中,P代表从生成器G2第13 层的特征图中的生成区域中提取出的所有1×1 的patches 组成的集合,则代表从生成器G2第13 层的特征图中的已知区域中提取出的所有1×1 的patches 组成的集合。


(3)更新patches。为了更好的确保修复结果的全局一致性,本文采用非局部均值策略更新每个Pj∈P,更新的具体计算公式如式(4)、式(5)所示:

此外,将注意层安排在第13 层是出于对计算资源和性能的综合考量:进入解码器阶段,越深的层得到的特征图的尺寸越大,需要的计算资源需求也相应增加;但是当层数较小,提取的可用patches 数量不足,无法获得更相似的patches 来填充破损区域,最终的修复性能也会因此下降。因此,为了在计算资源和性能之间实现平衡,参照Shift-Net 的设置,本文最终选择在生成器的第13 层插入新的注意层,此时特征图的尺寸为32×32。
4 损失函数设计
4.1 特征学习网络损失函数设计
同主流的图像修复算法一样,特征学习网络整体的损失函数LLEARN是多个损失函数的加权和。LLEARN表示最终预测到的LBP 特征与Ground Truth的LBP 特征的差距,用于评估经过特征学习网络预测后得到的LBP 特征的质量,其具体计算方式为
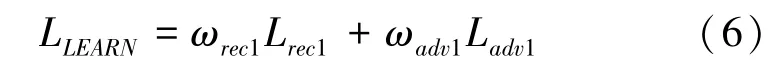
其中,Lrec1表示重建损失;Ladv1表示对抗损失;ωrec1,ωadv1分别代表Lrec1和Ladv1各自的权重。
重建损失Lrec1选用了L1损失,具体计算方式为
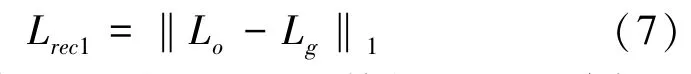
其中,Lo表示预测出的LBP 特征图,Lg则表示Ground Truth 的LBP 特征图。
对抗损失Ladv1的具体计算方式为
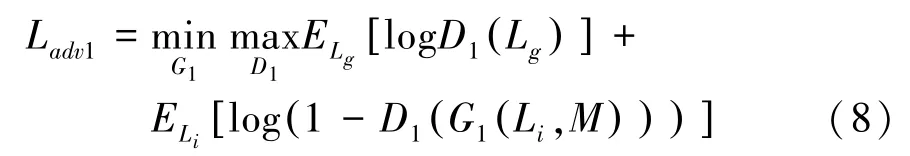
其中,M表示二值掩码,Li表示从输入的破损图片Ii中提取的LBP 特征。
4.2 修复网络损失函数设计
修复网络的整体损失函数LInp在特征学习网络的整体损失函数LLEARN的基础上额外引入了感知损失Lper和风格损失Lstyle,具体计算方式为
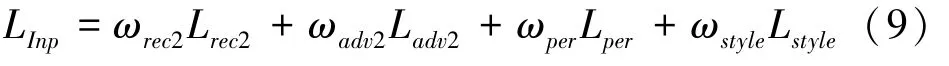
其中,ωper,ωstyle为感知损失Lper和风格损失Lstyle对应的权重,ωrec2,ωadv2为重建损失Lrec2和对抗损失Ladv2对应的权重。
感知损失Lper的计算方式为
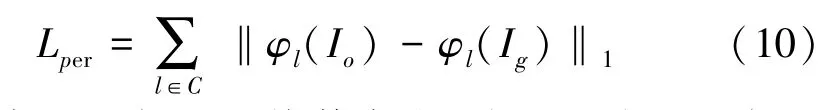
其中,Io表示最终修复得到的图片;Ig表示Ground Truth 图片;φl表示对应于ImageNet 预训练的VGG-16 网络的第l层的激活图,集合C包括了conv2_1、conv3_1、conv4_1 层的层索引。
本文的风格损失函数Lstyle具体计算方式为
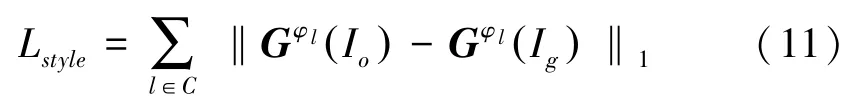
其中,Gφl是给定大小为Ci × Hi × Wi的特征图后,由与感知损失相同的激活图φl构造的Ci ×Ci的Gram 矩阵。
5 实 验
5.1 实验条件
5.1.1 数据集
本文实验共使用4 种数据集,即CelebA-HQ、Places 和Paris StreetView 以及NVIDIA 提供的不规则Mask 数据集。本文使用CelebA-HQ 数据集原有的训练集用于训练,原有的测试集对半分为本文的测试集与验证集,即训练集28 000 张,新的测试集和验证集各1 000 张;本文从Places 数据集中随机选择10 种场景,并将其原始验证集对半分成本文的新的验证集和测试集,即训练集是来自10 种场景的5 万张图片,验证集和测试集都分别是来自10 种场景的500 张图片;本文从Paris StreetView 数据集原始训练集中选择100 张图像作为验证集,使用剩下的14 800 张图像来构成训练集,测试集不变;训练时采用从不规则Mask 数据集中随机选取的策略。除了不规则Mask,本文还使用了中心Mask,中心Mask 的尺寸统一采用128×128(单位为像素)。此外,输入网络的图片都会预处理为256×256 的大小。
5.1.2 训练环境
本文的实验模型主要是基于Pytorch 1.6.0 和Tensorflow 1.8.0 框架搭建的,使用一台操作系统为Ubuntu 的服务器进行训练。服务器的显卡型号为RTX 3090,显存大小为24 G,处理器类型为i9-10900k、运行内存大小为64 GB,硬盘大小为2 T。编程语言使用python 3.6。
5.1.3 训练过程
首先在特征学习网络中训练生成器G1和判别器D1,将G1得到的结果连接到修复网络中,同时对G1、G2和D2进行训练。
5.1.4 部分参数设置
batchsize 设置为8,模型使用Adam 优化器对参数进行优化,其中β1=0,β2=0.9,生成器网络的学习率设为10-4,判别器的学习率为10-5来对网络微调,直至收敛为止,最多训练30 个epoch。
5.2 定性比较
为了直观地验证本文提出算法的有效性及优越性,将本文的算法与当下流行的几种算法在Places数据集上进行了定性比较,结果如图4、图5 所示。图4、图5 中的输入图片分别使用了中心Mask 以及不规则Mask,且图5 输入图片中的缺失比例自上而下不断扩大。

图4 使用中心Mask 的Places 数据集上的修复结果对比图Fig.4 Comparison of each algorithm on Places dataset with central mask
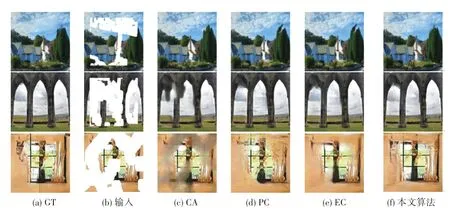
图5 使用不规则Mask 的Places 数据集上的修复结果对比图Fig.5 Comparison of each algorithm on Places dataset with irregular mask
由图4 可以看出,使用了中心Mask 的Places 图片,CA 出现了严重的语义不符:海面处出现了蓝色方框;EC 也出现了明显的掩膜边界:山后的天空出现了明显的正方形边界;本文算法的结果也在海面部分出现了模糊,只有PC 的结果细腻自然,具备更多的纹理细节。
由图5 可以看出,面对使用不规则Mask 的Places 图片:在缺失比例较小(0%~30%)时,所有算法均取得了较好的修复效果,与GT 图片相比,结果也很逼真。但是当缺失比例逐渐扩大(≥30%),除本文算法外的所有算法依次出现了模糊,其中CA的模糊最为严重,PC 和EC 均丢失了细节,本文算法所有图片依旧产生了自然真实的修复效果。
图4 从视觉上定性证明本文算法在使用了中心Mask 的Places 数据集上,性能未能达到最佳;图5则从视觉上定性证明了在使用了不规则Mask 的Places 数据集上,本文的算法产生了最好的修复效果。
5.3 定量比较
通过使用性能指标来对图像修复算法的性能进行客观的定量比较。本文采用图像修复中最常用的性能评价指标:峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似指数(Structural Similarity index,SSIM)。两种指标的值的大小都是与算法的修复性能呈正相关的,PSNR 的单位为dB,SSIM 的范围为0~1。
Contextual Attention(CA)、Partial Convolutions(PC)、Edge Connect(EC)以及本文算法在中心Mask 的CelebA-HQ 数据集和Paris StreetView 数据集上得到的性能评价指标如图6、图7 所示。可以看出,在中心Mask 的CelebA-HQ 数据集上,本文算法的PSNR 和SSIM 值分别为28.19 dB 以及0.924;在中心Mask 的Paris StreetView 数据集上,本文算法的PSNR 和SSIM 值分别为26.35 dB 以及0.868;因此,无论在哪个数据集上,本文算法的PSNR 和SSIM 值都比当前流行的其他算法高,尤其是在CelebA-HQ 中,本文算法的PSNR 值比CA 高出4.95 dB,SSIM 值比CA 高出0.038,定量证明了本文算法与其他主流算法相比,在中心Mask 的CelebAHQ 和Paris StreetView 数据集上具有更好的修复性能,即从数值上反映了采用的LBP 等价模式和新的注意力层对于最终修复效果的有效性。
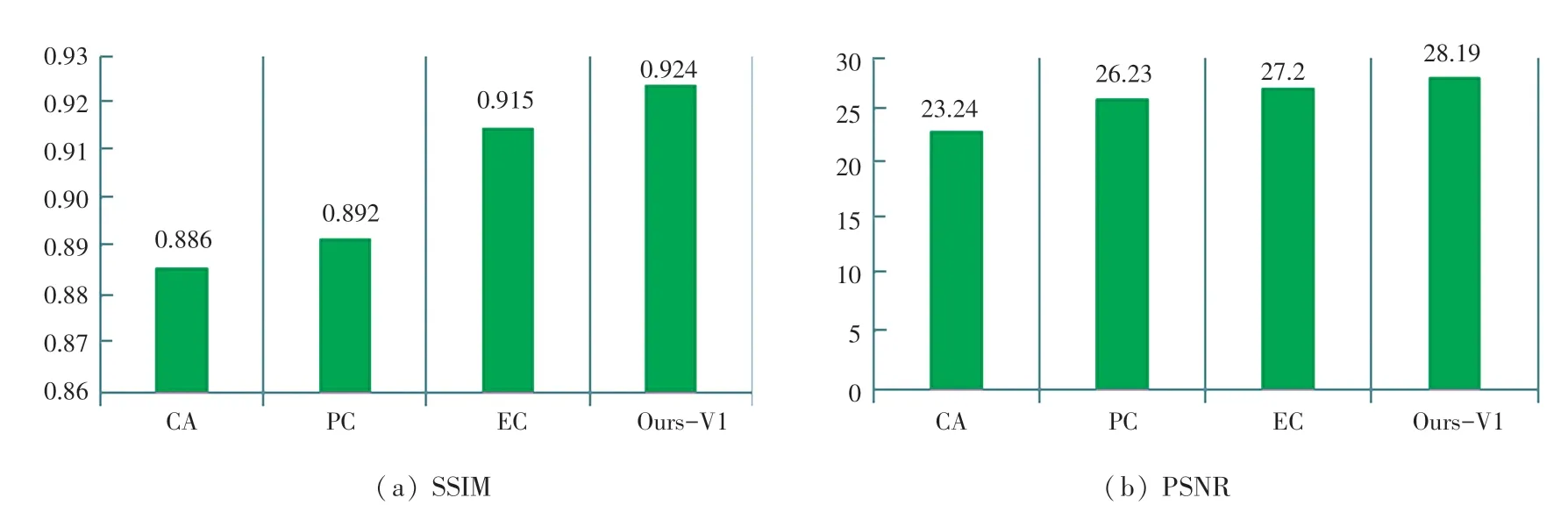
图6 各算法在中心Mask 的CelebA-HQ 数据集上的SSIM 与PSNR 值对比图Fig.6 Comparison of SSIM and PSNR values obtained by each algorithm on CeleBA-HQ dataset with central Mask
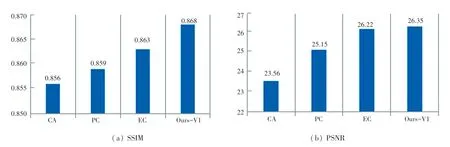
图7 各算法在中心Mask 的Paris StreetView 数据集上的SSIM 与PSNR 值对比图Fig.7 Comparison of SSIM and PSNR values obtained by each algorithm on Paris StreetView dataset with central Mask
5.4 消融实验
为了验证本文提出的LBP 等价模式和注意层对于图像修复任务的有效性与优越性,分别对这两部分依次进行消融实验。
5.4.1 LBP 等价模式
通过对LBP 等价模式进行消融实验,得到了图8 所示的结果。
由图8(c)、图8(g)对比可看出,未使用LBP 等价模式得到的修复结果出现了明显的扭曲与细节丢失,眉毛与眼睛的细节都未能很好地还原;而使用LBP 等价模式得到的修复结果则很好地还原了人脸的细节,产生了合理自然的结果,与Ground Truth 图像也更接近,两图之间的对比很好地从视觉上定性证明了LBP 等价模式的有效性。

图8 LBP 等价模式消融实验结果定性对比图Fig.8 Comparison of qualitative results of LBP uniform pattern ablation study
由图8(d)、图8(e)、图8(f)对比可看出:结构重建器预测的RTV 结构信息过于平滑,遗漏了大量的结构细节,边缘生成器预测的边缘结构信息包含不连续点,只有LBP 等价模式预测的结果包含了更完整的结构信息。
由图8(g)、图8(h)、图8(i)对比可以看出,最终的修复结果也是经过LBP 特征引导的最为清晰准确,很好地证明了LBP 等价模式在提供结构信息方面相比其他结构特征提取器的优越性。
5.4.2 注意层
为了验证本文提出的注意层的有效性以及优越性,将不使用任何注意层、使用上下文注意层以及使用本文新的注意层得到的修复结果进行比较,比较的结果如图9 所示。
由图9(c)、图9(e)对比可直观看出,使用与不使用本文提出的注意层最终得到的修复结果之间差距明显:不使用本文提出的注意层得到的结果十分模糊,花朵的大部分细节也已经丢失;而使用本文提出的注意层得到的结果则很好地还原了花朵缺失部分的细节,得到的结果也更加细腻自然,从视觉上定性证明了本文提出的注意层的有效性。

图9 注意层消融实验定性结果比较图Fig.9 Comparison of qualitative results of attention layer ablation study
由图9(c)、图9(e)对比可直观看出,加入上下文注意层后,尽管修复效果获得了一定的提升,去除了部分模糊,还原了部分细节;将图9(d)与图9(e)进行对比可以看出,使用本文提出的注意层能更好地还原结构信息,得到的修复的结果也更为清晰,从视觉上定性证明了本文提出的注意层相比其他注意层的优越性。
除了上述的定性比较,本文还使用了不规则Mask 的Places 数据集做了注意层的定量比较,最终结果见表3。
由表3 的数据对比可看出,使用本文注意层的算法比不使用任何注意层的方法,PSNR 值高出了4.919 dB,SSIM 值高出了0.129,这一提升定量地验证了本文提出的注意层的有效性;使用本文注意层的算法比使用上下文注意层的方法,在PSNR 上高出4.439 dB,在SSIM 上高出0.067,定量地验证了本文提出的新的注意层的优越性。
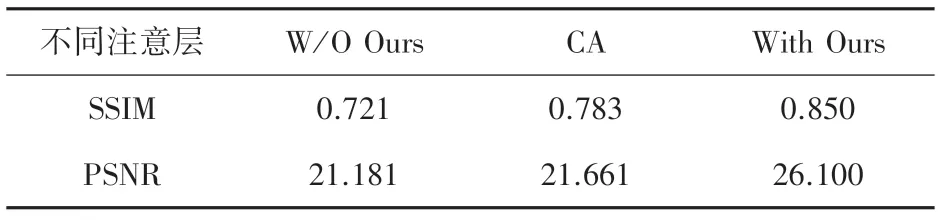
表3 注意层消融实验结果定量比较表Tab.3 Comparison of quantitative results of attention layer ablation study
6 结束语
为了更好地解决面对复杂图像时会出现伪影与模糊的问题,本文提出新的两阶段网络,在第一阶段的特征学习网络中使用的LBP 等价模式,获得了更高质量的结构信息,为第二阶段的修复提供了更好的指导。并且在第二阶段修复网络的生成器中插入的新的注意层同时在已知区域和生成区域中寻找更高质量的相似patches,使得最终的修复结果具备更好的全局和局部一致性。通过与其他算法进行主观的定性比较以及客观的定量比较,证明本文所提出的修复算法更好地解决了内容复杂的图像出现的伪影、模糊、不连贯的问题,能生成一致性更强、更加细腻真实的修复结果。但是,在面对具有大面积不规则缺失的图像时,本文算法出现了明显的性能下降,后续工作将针对这一不足开展。
