机器人运动规划方法综述
2023-02-07唐永兴朱战霞张红文罗建军袁建平
唐永兴,朱战霞,*,张红文,罗建军,袁建平
1.西北工业大学 航天学院,西安 710072
2.航天飞行动力学技术国家级重点实验室,西安 710072
3.之江实验室,杭州 311121
机器人学是研究如何通过计算机控制装置感知并操纵客观世界的学科,现今已被应用于各个领域,如行星探索中的移动平台[1]、空间机械臂[2]、无人机[3]、自动驾驶汽车[4]等(图1)。设想这样的场景:一架无人机正在高楼耸立的城市中穿行,未知环境要求其应利用新接收到的信息不断修正它的运动;杂乱的障碍物要求其应避免与众多物体发生碰撞;传感器误差、阵风干扰、模型误差、控制约束等则要求真实运动与规划运动间的误差应尽量小。因此为了能在充满未知性和不确定性的真实世界中可靠地完成任务,机器人必须具有自主感知[5]、快速决策[6-7]、运动规划[8-10]与控制[11]的能力。其中运动规划作为上层决策与底层控制的连接模块,负责将决策序列转化为控制器可执行的参考路径(轨迹),在机器人研究中占有重要地位。

图1 典型的机器人系统Fig.1 Typical robotic systems
运动规划领域早期侧重于处理有障碍物的二维或三维世界中的开环运动规划问题[8-10],其结果可以是一条无碰路径,也可以是一条无碰轨迹。前者是几何意义上的连续(光滑)曲线,后者则是这一曲线的时间参数化表达。对机器人而言,路径规划(本文称其为传统运动规划)一般在构型空间(Configuration Space,C-space)[12]内进行,轨迹规划(本文称其为考虑微分约束的开环运动规划)则在状态空间(即构型空间或相空间)内进行。但无论构型空间亦或相空间,都是无限不可数的,故开环运动规划的一个中心主题是将连续空间离散化,进而借助人工智能领域的离散搜索思想[13],将求解运动规划问题视为在高维自由构型空间(Free Configuration Space,Cfree)或自由相空间中的搜索过程。除一般的可行性问题外,满足某类性能指标最优(如时间最优、路径长度最优等)的开环运动规划问题亦是学者们的关注焦点。一条最优路径往往可参数化为许多条轨迹,它们的速度时间历程各不相同,而最优轨迹仅是其中一条。不幸的是,计算最优路径(轨迹)的时间复杂度往往较高(甚至对某些问题来讲,计算可行路径就已十分困难),很难满足机器人实时规划的需求,这便促使研究人员不断开发新的算法[14-39]以实现两者间的平衡。另外,经典控制理论[11]的发展历史表明:反馈是应对不确定性的有效手段。但开环运动规划过程常常忽略了这一点,从而容易造成机器人沿规划路径(轨迹)运动时意外碰撞的发生(图2)。反馈运动规划则通过对不确定性进行建模,并将该模型融入规划过程,为机器人的实际运动提供了安全保障。虽然近年关于反馈运动规划的研究取得了一系列进展[40-48],但鲜有文章[49-50]对这一主题进行归纳总结。即使有所提炼[51],包括反馈运动规划在内的各类内容[49-51]也已稍显陈旧,而且将运动规划的研究范围局限于基于采样的运动规划(Sampling-based Motion Planning,SBMP)算法的做法[51]无疑限制了读者的视野。
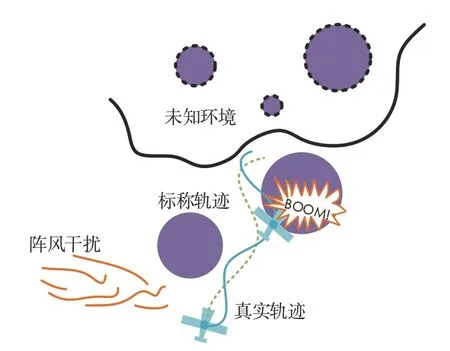
图2 运动规划与控制的解耦可能造成意外碰撞Fig.2 Decoupling of motion planning and control can cause accidental collisions
根据是否考虑微分约束和反馈,Lavalle 的经典专著[8]将运动规划问题分为表1 中的4 项子课题,本文则不区分最右侧2 项,并将其统称为反馈运动规划。进而在这种分类方式的基础上以单机器人为研究对象,依次总结了现有的传统运动规划、考虑微分约束的开环运动规划和反馈运动规划相关算法,形成了类似于“谱”的运动规划算法归类,便于读者对比分析各种方法间的区别与联系。其中针对解路径(轨迹)品质与求解效率间存在的矛盾,重点详述了如何利用已有信息来加速渐近最(近)优算法。另外则对不确定性建模方式、动态环境中的规划、学习算法与运动规划算法的融合等先进课题的最新成果进行了总结,以期为后续研究提供思路。

表1 运动规划问题分类[8]Table 1 Classification of motion planning problems[8]
1 传统运动规划
设G(V,E)为映射到Cfree的拓扑图(可参考图3~图6),其中V为图中节点的集合,每个节点相对应一个构型q。E为图中边的集合,每条边相对应两个构型间的无碰撞路径。对于所有edge∈E,定义

式中:edge([0 1])⊆Cfree表示路径edge 的像;S为可以通过G(V,E)到达的所有构型的集合。解决传统运动规划问题的思路正是用包含可数个节点的图结构G(V,E)捕捉Cfree的连通信息,并基于此离散结构搜索解路径。由于G(V,E)的构建过程显然受障碍物形状及其位置分布的影响,故一般可根据是否在C-space 中显式表示障碍物区域(Obstacle Region,Cobs),将处理传统运动规划问题的算法分为组合运动规划(Combinatorial Motion Planning,CMP)算法和基于采样的运动规划算法两类。
1.1 组合运动规划
基于显式表示的障碍物,CMP 首先构造满足下列条件[10]:
1)可达性(Accessibility):对于任一q∈Cfree,可以简单高效地计算一条以其为起点,以S中任一点s为终点的路径τ:[0 1]→Cfree,即τ(0)=q,(τ1)=s。
2)确保连通性(Connectivity-Preserving):对于起始构型qI、目标构型qG及它们在S中的连接点s1、s2,如果存在一条路径τ:[0 1]→Cfree,使得(τ0)=qI,(τ1)=qG,那么也将存在一条路径τ′:[0 1]→S,使得τ(′0)=s1,τ(′1)=s2的路图,其或由Cfree的胞腔剖分间接生成,如垂直胞腔剖分[52]、圆柱代数剖分[53]等;或通过其他方法直接构造,如可视图法[54]、广义维罗尼图法[55]、轮廓法[56]等。进而利用图搜索算法 如Dijkstra 算 法[57]、A*算法[58]、ARA*算法[59]、D*Lite 算法[60]、AD*算法[61]及Theta*算法[62-63]等寻找解路径。后四者都是A*的变体:ARA*通过放松对启发式的一致性要求并重复使用先前的搜索信息,可快速产生因子可控的次优路径,具有Anytime 特性,适用于计算时间受限的静态环境;D*Lite 是一种递增搜索算法,其先用A*算法从目标顶点反向计算相关节点的最优路径代价,待环境发生改变后,再以此有效信息为基础进一步调整相关节点的最优路径代价,适用于含动态障碍物的场景;AD*则是结合了ARA*和D*Lite 的优点,既具有Anytime特性,又有递增特性,真正实现了动态场景中的实时规划。另外由于A*算法找出的解路径角度往往被网格划分方式所限制,因而其并非真实地形中的最优路径,Theta*通过解除这一约束,可在相同时间复杂度下得到更高质量的解路径。
条件1)其实保证了Cfree内的任一起始、目标构型对(qI,qG)均可被连接到G中,条件2)则保证了在解路径存在的情况下,搜索总是可以成功。而这正是CMP 完备性的来源,即在有限时间内,算法要么找到一条解路径,要么正确地报告无解。虽然其几乎能解决任何运动规划问题,而且在一些简单情形(如二维世界中,Cobs为多边形,机器人仅进行平移运动)下可以高效地得到较好解,但对于大多数具有高维C-space 且障碍物数量巨大的问题,较长的运行时间和执行困难使此类方法失去了吸引力。
1.2 基于采样的运动规划
与CMP 不同,SBMP 通过碰撞检测模块来避免显式构建Cobs,并且利用可数的采样点集或采样序列及满足一定条件的连接方式近似捕捉无限不可数的Cfree的连通特性。尽管其永远不可能知晓Cfree的精确形状,但却节省了大量计算时间,是一种行之有效的折中方式,可用于高维空间中的运动规划。不过与此同时也牺牲了算法的完备性,并代之以更弱的概念:使用随机采样方法的运动规划算法是概率完备(Probabilistically Complete)的,使用确定性采样方法的运动规划算法是分辨率完备(Resolution Complete)的。为满足弱完备性要求:①Cfree中的采样序列必须稠密;②算法的搜索过程应具备“系统性”。更多关于SBMP 产生的历史原因和早期发展过程可参考Lindemann 和Lavalle 的综述文章[64]。
对于给定数个起始-目标构型对的多疑问(Multiple-Query)运动规划问题,如果环境结构不发生改变,则非常有必要花费时间对模型进行预计算以生成路图,从而提高后续搜索效率。概率路图法(Probabilistic Roadmap,PRM)[65]是其中的典型代表,它最初是为应对高自由度运动规划问题而发展的,算法流程如图3 所示。PRM 构建的路图可看作是对CMP 所导出路图的一种近似,因此也常被与CMP 共同归入基于图搜索的运动规划算法中[50]。Kavraki 等[66]通过对简化的PRM(Simplified PRM,s-PRM)进行分析,建立了算法失败概率Pfail与路径长度L、路径和障碍物间距R、采样点数量n之间的函数关系,其中Pfail随L的增加而线性增加,随n的增加而指数减小到0,从而证明了PRM 的概率完备性。但由于路径特性很难提前得知,故该完备性分析方法不易使用。另一分析方法[67]则借助ε-goodness[68]、β-lookout 和(ε,α,β)-expansive 的概 念,证明 算法失败概率为
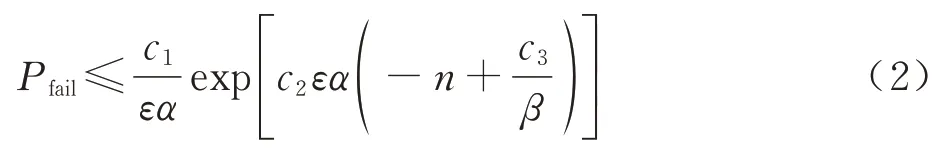

图3 PRM 算法流程Fig.3 Procedure of extending PRM
式中:c1、c2、c3为正常量。从式(2)不仅能得出Pfail与n的指数关系,而且可以发现如果暗含Cfree可视特性的ε、α、β越大,那么完成求解所需的采样点就越少,算法运行时间就越短。因为引起可视特性下降的狭窄通道不可能偶然出现[69],故实际中遇到的许多Cfree都具有良好的可视特性,即相应的ε、α、β较大。另外可视特性是用体积比率定义的,而不直接依赖于C-space 维数,这便解释了为什么当维数在一定范围内增加时,PRM 仍能较好地运行。
针对仅有一个起始-目标构型对的单疑问(Single-Query)运动规划问题,仅需覆盖与构型对相关的部分Cfree即可,预计算不能带来任何好处。大多数基于采样的单疑问规划算法都选择以逐步构建稠密搜索树的方式来探索C-space,而不用提前设定采样点数量。只要算法构建的路径集足够丰富,那么将找到一个解,该特点使其适合于在线执行。基于采样的单疑问运动规划算法可被统一至递增采样与搜索(Incremental Sampling and Searching)的框架下[8]:
步骤1 初始化,无向拓扑图G(V,E)的节点集V初始时一般包含起始构型qI和目标构型qG。
步骤2 节点选择方法(Node Selection Method,NSM),选择一 个节点qcur∈V进 行扩展。
步骤3 局部规划方法(Local Planning Method,LPM),选择新的构型点qnew∈Cfree,试图构造路径τ:[0 1]→Cfree,使得(τ0)=qcur且(τ1)=qnew。用碰撞 检测算 法确保τ⊆Cfree,否则返 回步骤2。
步骤4 在图中插入一条边,将τ作为连接qcur和qnew的边插入E中。若qnew不在V中,也将其插入。
步骤5 对解进行检验,确定G是否已经编码了一条解路径。
步骤6 返回步骤2。
步骤2 中的NSM 类似于图搜索算法中的优先队列(Priority Queue),而步骤3 中的LPM 之所以称为局部的,是因为其并不尝试解决整个规划问题,而是每次仅产生较短且简单的无碰路径段。对于非完整系统,LPM 也可称为Steering 方法。现有算法大多都是步骤2 和步骤3 有所不同,其中最著名的应是扩张空间树(Expansive-Spaces Tree,EST)[67]和快速扩展随机树(Rapidly Exploring Random Tree,RRT)[70-73]。前者将待扩展节点被选择的概率设置为关于树上节点分布密度的反比例函数,并在该节点周围一定范围内随机选择新的构型点进行扩展,从而保障了采样树的稠密生长。后者则通过定义一个无穷、稠密采样序列,并利用NEAREST 函数为每个采样点选择其在S中的最近点来迭代生长(参见图4[51])。正是因为每个节点被选择的概率与其对应Voronoi 区域的测度成正比,才保证了算法的快速扩展特性。两种方法的概率完备性也已在原文中得到证明。值得一提的是,PRM 算法的变体[74-75]也可用于单疑问运动规划问题:其先在忽略障碍物的情况下构建概率路图,待找到可行路径时仅对该路径进行碰撞检测。若某条边或节点发生碰撞,则将其移除并重新增强路图进行路径搜索和碰撞检测。Lazy PRM 的思想来源是碰撞检测耗费了算法90%以上的时间,且对单疑问运动规划问题来说大部分边的碰撞检测是无用的。
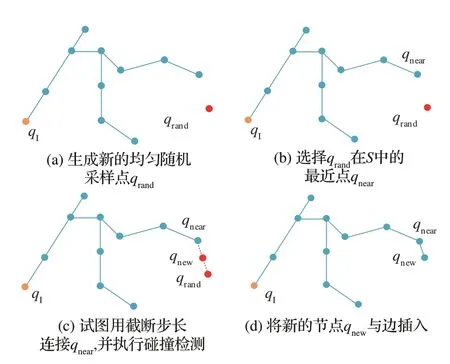
图4 RRT 算法流程[51]Fig.4 Procedure of extending RRT[51]
在大多数应用中,解路径的品质[76]亦十分重要,一般除可行性外还存在最优性要求,如最短长度路径、最短时间路径等。但可以证明,标准的PRM 算法和RRT 算法均不具备渐进最优性[77]。经典方法是利用启发式图搜索算法提供最优性保证,不过这种最优性受限于网格分辨率,且最坏情况下的运行时间随空间维数呈指数增长。Karaman 和Frazzoli[77]通过修 改邻近点选取方法和局部节点连接方式(在文章中分别对应Near Vertices 和Rewire),提出了概率完备的渐进最优算法—PRM*、快速扩展随机图(Rapidlyexploring Random Graph,RRG)和RRT*(算法流程参见图5[78]和 图6[78]),且后两种算法具有Anytime 特性。其虽不能完全克服经典方法的缺点,但的确在当时提供了一个保证算法渐进最优性的新视角。以RRT*为例,算法在Near vertices 步骤中用变化球半径的方式选择qnew的邻近采样点,其中半径为
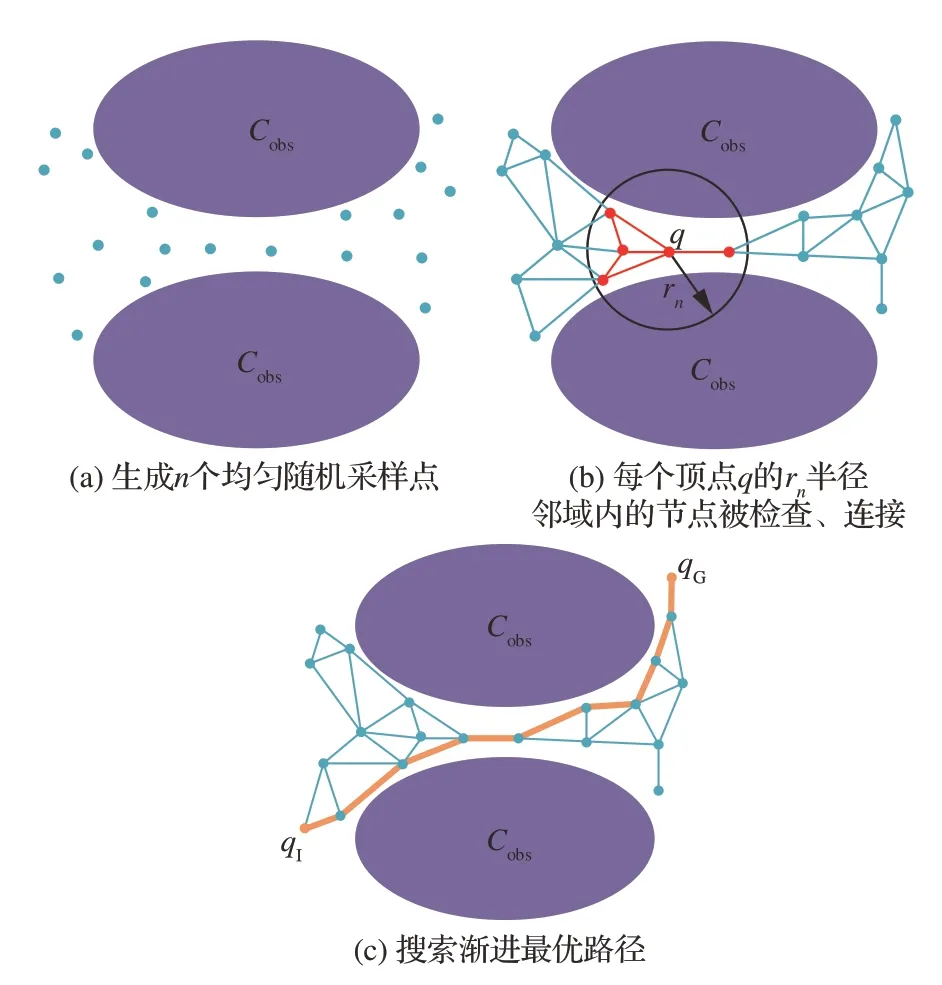
图5 PRM*算法流程[78]Fig.5 Procedure of extending PRM*[78]


图6 RRT*算法流程[78]Fig.6 Procedure of extending RRT*[78]
式(3)是采样离散度的函数,并随采样点数量n的增加而减小,d为构型空间维数,γ是与环境相关的参数。在Rewire 步骤中,首先将qnew连接至能为其提供更低代价的邻近节点上,其次若qnew能为剩余某些邻近节点提供更低的代价,则将该邻近节点的父节点设置为qnew。一些关于PRM*和RRT*理论分析的改进近来也已被提出[79-81]。
上面的论述详细探究了SBMP 的思想内涵,列举了几种经典的SBMP 算法以及它们的优缺点和适用场景。至于该算法框架中最近点函数[82]、距离度量[83-84]、局部规划器[84-85]、碰撞检测模块[86-87]的选择,在此不过多赘述。另外在经典SBMP 算法的基础上,目前也已产生了许多算法加速策略,本节余下部分将围绕这一主题展开。
1.2.1 利用确定性采样方式提升算法性能
SBMP 算法最初都使用了随机采样方式,那么一个问题是:如果以确定性方式进行采样,相关的理论保证和实际性能还会成立吗?答案是肯定的,确定性规划器可以简化证明过程,可以将一部分在线计算量变为离线计算(这对考虑微分约束的规划和高维空间中的规划尤其有意义)。另外对于栅格序列,亦可简化操作量(如定位相邻点)。以PRM 为例,实质上“概率性”对其是不重要的,反而会导致采样点的不规则分布,使连通性信息的捕捉变得更加复杂。Lavalle等[88]将局部规划器引入经典网格搜索,发展了子采样网格搜索(Subsampled Grid Search,SGS)算法,并将确定性的低差异度采样技术引入PRM,发展了拟随机路图算法(Quasi-Random Roadmap)[89]和栅格路图(Lattice Roadmap)算法,进行对比实验后发现:相较于分辨率完备的确定性采样方法(包括网格搜索),原始的PRM算法并没有体现出优势。故文章对“随机性是打破高维空间维数诅咒的必要分量”这一说法进行了驳斥,事实上为了维持固定的离散度,任何采样方案都需要与维数成指数关系的采样点数量[90]。但Lavalle 等的工作[88]仅限于讨论可行路径,就收敛到最优路径而言,独立同分布采样是否还有优势?Jason 等[91]针对PRM 算法进行了讨论(设g1、g2为从自然数集到实数集的映射,约定g1∈O(g2)表示存在某个自然数n0和正实数m,使得对于所有n≥n0,|g(n1)|≤m|g(n2)|;g1∈Ω(g2)表示存在某个自然数n0和正实数m,使得对于所有n≥n0,|g1(n)| ≥m|g2(n)|;g1∈ω(g2)表 示limn→∞g1(n)/g2(n)=∞):
1)确定性渐进最优性,在d维空间中,使用l2离散度的上界为γn-1/d,连接半径rn∈ω(n-1/d)的确定性采样序列的PRM 算法是确定性渐进最优的。而使用独立同分布随机采样序列的PRM*算法是概率性渐进最优的,且需要更大的连接半径Ω((log(n)/n)1/d)。
2)收敛率,在没有障碍物的情况下,采用确定性采样序列的PRM 的次优因子上界为2D(nrn-2Dn),其中Dn是采样序列的l2离散度(存在障碍物时的结果更复杂一点)。而采用独立同分布采样的类似结果仅是概率成立,且更加繁琐和难以理解。
3)计算复杂度和空间复杂度,在低离散度栅格上运行PRM 的计算复杂度和空间复杂度为。由于可以用rn∈ω(n-1/d)来获得渐近最优性,故PRM 存在一个计算复杂度和空间复杂度为ω(n)的渐近最优版本。而使用独立同分布采样的复杂度结果为O(nlogn)量级。
可以看出确定性方法在需要更小的连接半径的同时,具有更好的计算复杂度和时间复杂度。本质原因在于确定性低离散度序列和独立同分布序列间离散度的差异,二者分别为O(n-1/d)和O((log(n)/n)1/d)[92]。另外,从使用低离散度栅格的PRM 中得到的结果在其他一些情况下也精确或近似地成立,如k-nearestneighbor 算法、批处理算法、非栅格的低离散度采样序列(如Halton 序列)、非均匀采样和含微分约束的规划[93]等。多类实验结果表明:对于给定数量的采样点,确定性低离散度采样不会差于独立同分布采样。因而结合Lavalle 的结论[88],Jason等[91]建议基于SBMP 算法都应使用非独立同分布的低离散度采样序列。
1.2.2 利用收集到的Cfree形状信息改善采样分布
事实上Cfree中的可视特性并非均匀分布,且描述整个Cfree可视特性的ε、α、β取决于其中最差的构型和lookouts。当含有狭窄通道时,以上3 个参数就会减小。而为了保证算法的失败概率不超过Pfail,由式(2)可知所需的均匀采样点数量随即大幅增加。如果规划器能根据已有的或运行过程中收集到的信息对Cfree的形状做出概率上的推测,则可以此推测来偏置采样点分布,使其能更好地捕捉C-space 的连通特性,从而减少所需的采样点数量,提高算法效率。但显式维持该概率模型的代价很高,因此早期研究仅是用启发式[94]来近似最优采样策略,其本质上是一种离线方法。包括基于工作空间的策略[95-98]、基于障碍物的策略[99-100]、基于可视性的策略[101]、Bridgetest 采样策略[102]等。但由于基于可视性的策略[101]采用的是拒绝采样方式,故实际使用中的效果不太理想[85]。
自适应采样则在线调整采样点的分布。Hsu 等[103]将以上离线偏置采样方法线性加权,并在每次采样后调整权重,称为混合PRM 采样策略。由于“边界点”一般有更大的Voronoi 偏置却不能被成功扩展,Yershova 等[104]针对含有复杂几何的运动规划问题,提出了将“边界点”采样域限制在以预设值为半径的球内的Dynamic-Domain RRT(DD-RRT)方法。Jaillet 等[105]则根据“边界点”成功扩展的概率来调整边界域半径,实验结果表明Adaptive Dynamic-Domain RRT(ADD-RRT)在大多数实验场景下都比原始RRT 的性能高出数个量级。对于多疑问运动规划问题,Burns 和Brock 建立了表示Cfree形状的混合高斯模型[106]和k-nearest-neighbor 模型[107],并用采样信息更新该模型。前者最大程度地减小模型方差,后者则用期望效用来引导采样。相应结果同样被扩展至单疑问运动规划问题[108],在提升计算效率的同时也增强了规划器的鲁棒性。
1.2.3 利用解路径代价和尚需代价的估值导引采样分布
随着采样点数量趋于无穷,虽然RRT*可以保证渐进收敛到最优解,但这种按照随机次序进行搜索的方式在无用状态上浪费了大量计算时间,降低了算法效率,使其难以应用到一些实际问题中,如无界空间(即室外环境中的规划)和高维空间(即机械臂的规划)。因而启发式被用来或缩小搜索区域,或安排搜索次序。heuristically-guided RRT(hRRT)算法[109]以 与启发代价成反比的概率选择采样点,使采样树朝着低代价区域生长,从而得到质量更好的次优路径。Anytime RRT[110]迭代地用前次的解来界定本次的搜索范围,用与hRRT 类似的思路选择待扩展节点,使解路径的代价随运行次数不断下降,但并未提供最优性保证,且前次采样点被不断丢弃,信息复用率不高。Transition-based RRT[111]将构型空间代价地图与规划问题作为输入,用随机优化方法决定是否保留新的采样点,以使RRT 朝着构型空间代价地图的谷地和鞍点进行扩展。Karaman 等[112]通过“图修剪”技术,周期性地移除那些当前代价与启发式代价之和大于已有最好路径代价的顶点,发展了RRT*的Anytime 版本。Hauser[113]则在“图修剪”技术的基础上结合Lazy 检测,提出了Lazy-PRM*算法和Lazy-RRG*算法。Akgun 和Stilman[114]、Islam等[115]均采用了路径偏置方法,即通过增加当前解路径节点邻域的采样频率来加速RRT*的收敛,但该方法基于不切实际的同伦假设且需持续全局采样以规避局部极小值。除此之外,前者还用到了双向搜索和采样点拒绝(Sample-Rejection)技术,虽然一次采样迭代消耗的时间极短,但随着关注区域与Cfree间体积比率的减小,找到一个可接受的采样点所需的迭代次数也会增加,此时的计算量便再不容忽视。RRT#[116]利用启发式在由RRG 递增建立的图上寻找并更新树,并通过LPA*[117]将变化传播到整个图中,从而有效维持了到每个顶点的最优连接。虽然用启发式缩小搜索区域的方法带来了一定的性能提升,但其仍采用了与RRT*类似的扩展次序,使得重要的、难以采样的状态由于目前不能连接到树而被简单丢弃,同时还可能浪费计算时间。Informed RRT*[14]首先运行原始的RRT*算法,待找到解后再直接在不断缩小的椭球形信息集内进行采样(参见图7[118])。相比于RRT#,Informed RRT*在椭球体积减少时,仍能有效提高收敛率和解路径质量[118]。

图7 Informed RRT*算法流程[118]Fig.7 Procedure of extending Informed RRT*[118]
至此所述方法虽然均在最优解的收敛速度上有所改进,但本质上其生长树的方式都是无序的。Jason 等[15]用一种Marching 方法,按Costto-Come 递增的次序(类似于Dijkstra 算法[57])搜索一批采样点。其中空间近似和搜索的分离使得搜索次序独立于采样次序,但却牺牲了Anytime 特性。在搜索完成之前,FMT*不会返回解路径。另外也与其它先验离散方法一样,如果解不存在,则搜索必须重新开始。Gammell 等[16-17]试图将有信息的图搜索算法和具有Anytime 特性的RRT*算法统一至同一框架下,从而发展了一种可以有效解决连续空间路径规划问题的有信息、有Anytime 特性、有渐进最优保证且避免大量计算无用状态的基于采样的运动规划算法—Batch Informed Trees(BIT*),该方法的主要贡献在于维持潜在解路径质量的优先级序列的同时利用分批采样技术,使空间近似和空间搜索得以交替进行。一些BIT*的改进算法也已被提出:Advanced BIT*(ABIT*)[119]使用类似于ARA*[59]的次优启发式因子快速找到初始解路径,再以Anytime 形式向最优解路径收敛。Adaptively Informed Trees(AIT*)[120]通过对称双向搜索来同时估计并使用一个精确的、针对特定问题的启发式,可较好地适用于局部路径评估较昂贵的情况。Regionally Accelerated BIT*(RABIT*)[121]利用局部优化器来解决不能通过直线连接的状态之间的连接问题,有助于在难以采样的同伦类中找到路径。
除上述算法之外,为平衡最优性与计算效率间的矛盾,一些文章[122-124]也通过放松关于最优性的要求,对渐近近优(Asymptotically Near-Optimal)算法进行了讨论。
1.2.4 重复使用之前有效的搜索信息并降低重规划的频率
当机器人在含有静态障碍物或动态障碍物的未知环境中工作时,突然出现的障碍物一般只会对之前路径的一部分产生影响,而剩余部分对于接下来的搜索仍然有效。若能充分利用这一部分有效信息,无疑可以加速重规划过程(类似于D*Lite[60]算法和AD*[61]算法)。ERRT[125]用之前可行路径的Waypoint 进行偏置采样,但每次重新生成采样树的方式降低了算法效率。Dynamic RRT(DRRT)[126]则在ERRT 的基础上融合D*[127]算法的思想,从目标构型反向搜索可行路径,且仅丢弃发生碰撞的构型及其子节点,提高了采样树的重建速度(参见图8[126])。与DRRT 完全删除被障碍物影响的分枝不同,Multipartite RRT(MP-RRT)[128]依然保留这些不连通分量,并试图将其重新连接到采样树上。Van den Berg 等[129]结合PRM 与AD*算法:首先构建一个仅考虑静态环境的路图,通过简单预测动态障碍物轨迹,以Anytime 方式从目标反向搜索次优轨迹。若执行轨迹时环境发生改变,则更新路图及启发式,修复规划轨迹。Ferguson 和Stentz[130]也已将AD*的思想扩展至解决单疑问运动规划问题的RRT 算法中。
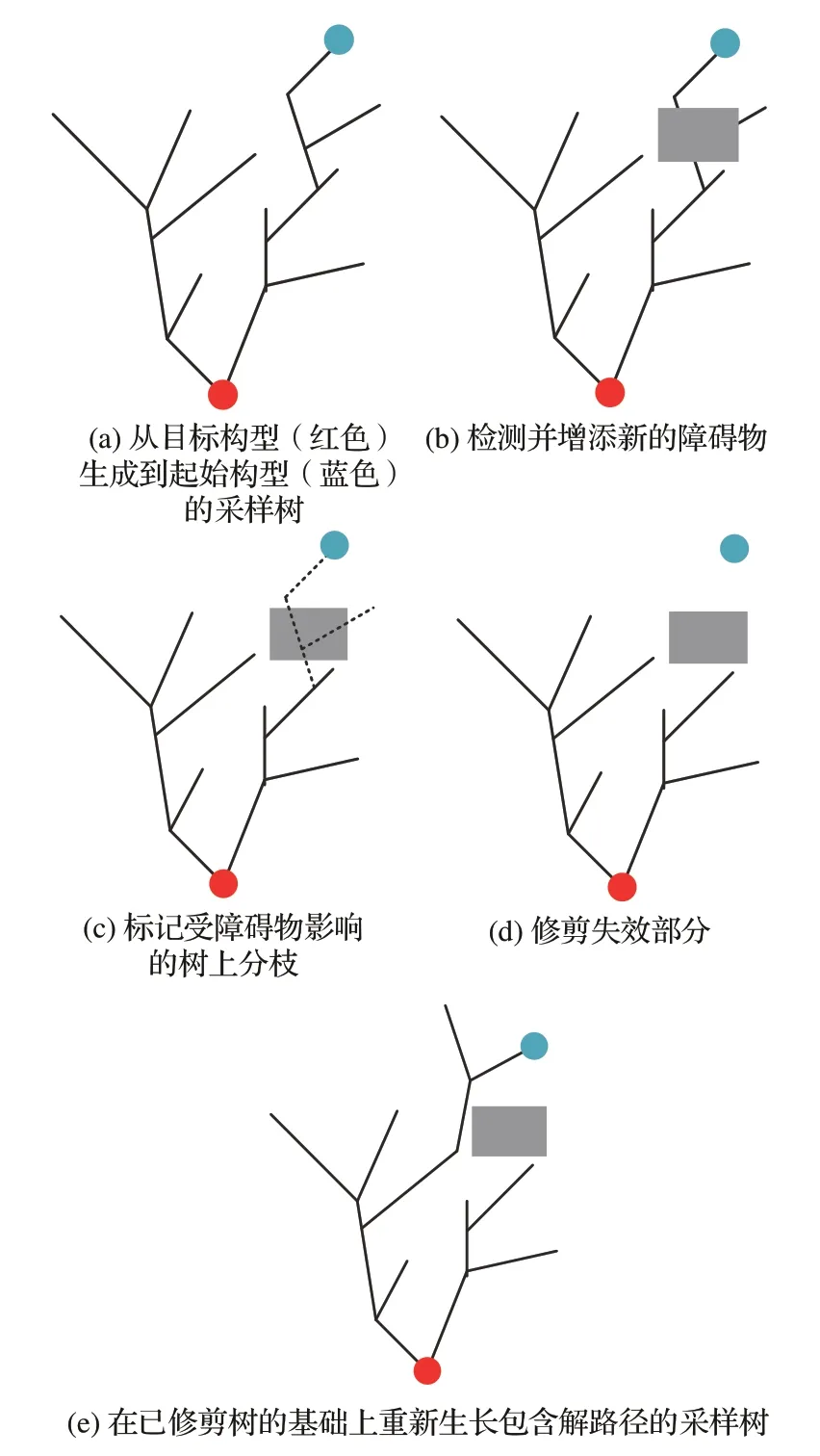
图8 DRRT 算法流程[126]Fig.8 Procedure of extending DRRT[126]
复用之前有效的搜索信息虽然可以加速算法,但前述的反应式避障(Reactive Avoidance)方案同时也可能造成机器人在某些情况下不断地进行重规划,从而增加完成任务所需的时间。相比之下,利用感知到的信息预测动态障碍物轨迹,并与已有运动规划算法进行融合显然是一种更好的避障手段。该规划框架可以提高解路径的品质(即延长路径可行性的持续时间),降低重规划的频率。其中的关键技术是运动物体未来行为或轨迹的预测,现有文献中的解决方案可以分为基于物理定律的方法(即感知-预测方案)、基于模式的方法(即感知-学习-预测方案)和基于规划的方法(即感知-推理-预测方案)3 类。前者根据牛顿运动定律显示地建立单个或多个动力学或运动学模型,并通过某种机制融合或选出一个模型进行前向仿真,以达到轨迹预测的目的;中者适用于含未知复杂动态的环境,其通过用不同的函数近似器(即神经网络、隐马尔可夫模型及高斯过程等)拟合数据来学习待预测目标的运动行为;后者则融合了理性智能体的概念,即假设智能体在长期运动过程中需最小化一个与其一系列行为相关的目标函数,并计算能使智能体达到这个目标的策略或路径猜想。其中目标函数可以预先指定,亦可通过学习得到(如利用逆强化学习技术等)。更多详细内容可参考Lefevre[131]和Rudenko[132]等的综述文章,此处不再赘述。
1.2.5 利用学习算法加速传统运动规划问题的求解过程
机器学习方法与传统运动规划算法的结合最近已成为研究人员的关注热点,此类方法的优势主要体现在两个方面:①相较传统运动规划算法,能更有效地找到近优路径;②可直接基于原始图像进行路径规划。一些文章已将深度学习技术如收缩自编码器(Contractive AutoEncoder,CAE)[133]、条件变 分自编码器(Conditional Variational AutoEncoder,CVAE)[134]、卷积神经网络(Convolutional Neural Network,CNN)、图神经网络(Graph Neural Networks,GNN)[135]及它们的变体成功应用于SBMP 中,且大多数结合方式都聚焦于①用神经网络编码C-Space,并改善SBMP 的采样点分布;②直接端到端地生成路径。Deep Sampling-based Motion Planner(DeepSMP)[136]由编码器和采样点生成器构成,前者用原始点云数据作为CAE 的输入以将障碍物空间编码为不变的、鲁棒的特征空间;后者用RRT*产生的近优路径训练基于Dropout[137]的统计前馈深度神经网络,使其能在给定起始构型、目标构型、障碍物空间编码信息的情况下,在包含解路径的构型空间区域内为SBMP迭代生成采样点。Neural RRT*[138]通过学习大量由A*算法生成的最优路径来训练CNN,该模型可为新的路径规划问题快速提供最优路径的预测概率分布,用于指导RRT*的采样过程。Ichter 等[139]认为解路径仅依赖于由C-space 结构决定的几个关键构型。因此其通过图论技术识别这些关键构型,并仅用局部环境特征作为CNN的输入来学习预测关键构型,从而提升了PRM算法的性能。其在另一文章[18]中用以往成功的规划结果和机器人经验训练CVAE,然后根据给定的初始构型、目标区域和障碍物信息,可以对CVAE 的隐空间(Latent Space)进行采样,并将其投影到状态空间中更有希望包含最优路径的区域。但这种预测最短路径采样点的做法其实把所有负担都压给了Learner,任何由近似或训练-测试不匹配造成的误差均可使算法失效。故LEGO[140]提取多条不同近优路径上的瓶颈点,并以其作为CVAE 的训练输入数据。针对CNN 和全连接网络(Fully-Connected Network,FCN)容易丢失环境结构信息而引起的泛化不良问题,Khan 等[141]利用GNN 的置换不变特性鲁棒地编码C-space 的拓扑结构,并计算采样分布的参数以生成采样点。实验结果表明:在学习关键采样点方面,GNN-CVAEs 的表现大大优于CNN,而GNN 则优于在高维空间中规划的FCN 模型。除了用原始点云数据和C-space 障碍物信息作为输入外,利用CNN 学习对象级语义信息产生的采样分布也可以改善未知环境中的导航结果[142]。与上述偏置采样点分布的方法不同,MPNet[19,143]则直接生成可行近优路径。其由编码网络(Enet)和规划网络(Pnet)组成,前者将机器人环境信息编码入隐空间,而后者则利用起始构型、目标构型和Enet 作为输入生成路径。
除深度学习外,强化学习(Reinforcement Learning,RL)[144]在运动规划领域也有一些成功应用的案例。Q-function sampling RRT(QSRRT)[145]根据学习到的状态-行为值函数(Qfunction),提出Softmax 节点选择方法,加速了RRT 的规划过程并避免陷入局部极小值。Chen等[146]建立了一个基于Tabular Q-learning 和值迭代网络(Value Iteration Networks,VIN)[147]的可学习神经扩展算子,以为基于树的运动规划算法学习有潜力的搜索方向。Bhardwaj 等[148]将Lazy搜索中边的选择问题建模为马尔可夫决策过程(Markov Decision Process,MDP),并引入模仿学 习(Imitation Learning)[149]进行求解。Zhang等[150]利用MDP 建立拒绝采样模型,并通过策略梯度方法优化采样分布以降低如碰撞检测次数和树的尺寸之类的规划代价,从而得以加速现有的最优运动规划器。
综上,尽管基于学习的技术在运动规划领域取得了一些进步,但此类方法在未经历环境中的性能表现还有待验证。
根据以上关于传统运动规划问题的讨论可知:相比CMP,SBMP 取得成功的原因在于其以牺牲完备性为代价,换取对复杂Cfree的连通性拥有较强的表示能力(即通过“采样”的方式构建包含解路径的离散结构),而非最初版本中所带有的“采样随机性”和“搜索盲目性”。相反该特性恰恰使算法抛弃了大量可用的有效信息,阻滞了性能的进一步提升。因此针对不同场景,如何在SBMP 算法的设计过程中妥善地融入1.2.1~1.2.5 节的5 类信息,从而提高解路径品质并避免在无价值节点上浪费大量计算时间,将是传统运动规划研究中要考虑的重要问题。
2 考虑微分约束的开环运动规划
大多数运动规划问题都会涉及来自机器人运动学或动力学的微分约束。一般的处理方式是先在规划过程中忽略这些约束,并通过传统运动规划算法生成几何可行路径,然后再在问题的改进过程中利用轨迹规划/轨迹优化技术处理它们。虽然这种解耦规划[151-152]在许多情况下可以节省大量计算时间,但同时也丢失了完备性和最优性保证。更好的选择是在规划过程中直接考虑微分约束,这样便可得到服从系统自然运动特性的轨迹,同时降低反馈控制器的跟踪误差。此类问题一般也被称为Kinodynamic Motion Planning(KMP)[153]。本质上,KMP 可被视为经典两点边值问题(Two-point Boundary Value Problem,TPBVP)的变体。后者通常是给定初始状态和目标状态的情况下,在状态空间中计算一条连接初末状态并满足微分约束的(最优)路径;而规划问题则牵扯到一类附加的复杂性:避免与状态空间中的障碍物发生碰撞,用控制理论的术语来讲即是为包含非凸状态约束和控制约束的非线性系统设计(最优)开环轨迹。但求解TPBVP的技术并不能很好地适用于考虑微分约束的运动规划,因为其本就不是为处理全局障碍物约束而设计的,或者说很难得到受非凸状态和控制约束的非线性系统的最优必要条件[154]。
文献中处理KMP 的方式一般有基于采样的方法和基于优化的方法两类。关于前者,由于微分约束破坏了CMP 所需的良好特性,故第1 节中仅有SBMP 可能实现较好移植。关于后者,其一般有3 种应用场景:一是在前述解耦规划中,用于平滑和缩短由其它规划算法(如SBMP)生成的路径;二是直接从较差初始猜想(可能是与障碍物相交的线段)开始计算局部最优的无碰轨迹;三是在已知自由空间的凸胞腔族中规划微分约束可行的(最优)轨迹。后两类场景将在2.2 节详述。而2.1 节将首先介绍如何利用SBMP 处理考虑微分约束的运动规划问题。
2.1 基于采样方法的KMP
要求一般的机器人系统在微分约束下精准到达状态空间中的某个采样点要么是不可行的(图9 中的橙色区域为机器人有限时间前向可达集,其在一定时间范围内无法到达可达集之外的采样点),要么则需解决复杂的TPBVP 问题(这亦是很少应用路图类算法的原因,即目前不存在有效的LPM 方法),故考虑微分约束的SBMP 通过离散动作空间和时间,并进行前向仿真来递增地生成采样树。离散的动作空间和时间其实暗含着初始状态的可达图,若状态的一阶微分函数满足Lipschitz 条件[8],则随着离散度(以概率1)趋于零,动作序列将任意接近相应动作轨迹,即可达图的节点将在可达集中(以概率1)变得稠密,这也是对基于采样方法的KMP 最重要的要求。加之“系统性”搜索,便保证了算法的分辨率(概率)完备概念。

图9 机器人有限时间前向可达集Fig.9 Finite time forward reachable set of the robot
RRT[71]与EST[155]最初便是为解决含微分约束的运动规划问题而设计,而非传统运动规划。其算法流程与上一节基本相同,稍微的区别在于—此处的算法一般在固定的离散动作集中选择能最小化积分后状态与采样点间距的离散动作,作为树上新加入的边所对应的控制输入(积分时间可以固定,也可以在某个区间[0,ΔTmax]内随机选择)。尽管RRT 为含微分约束的运动规划问题提供了较好解决方案,但它的缺点是性能对度量函数较为敏感,差的度量可能导致一些注定发生碰撞的状态和位于可达集边界的状态被重复选择,重复扩展,从而大大增加了运行时间,延缓了树的生长。如图10(a)[156]所示:橙色为初始状态可达集,而可达集边界状态(红色)有较大的Voronoi 区域,故容易被重复扩展;又如图10(b)[157]:红色状态有较大Voronoi 区域,但其扩展结果大概率会发生碰撞。理想距离函数应是满足某种最优性的代价泛函[158],但除非对于像无约束、有二次形式代价的线性系统存在解析解[159],一般来讲设计这样的伪度量与解决原始运动规划问题一样困难。虽然也有学者提出适应于弱非线性系统的近似度量[156,160],不过一个更重要的问题是如何令算法在较差的度量函数下依然有良好的性能?或者说如何令采样树在较差的度量函数下依然能(以概率1)快速稠密地覆盖初始状态的无碰可达集?另外,引入微分约束也对RRT*提供最优性的方式构成了挑战,发展新的考虑微分约束的渐近最优算法是又一亟需解决的问题。

图10 SBMP 算法的度量敏感性示意[156-157]Fig.10 Metric sensitivity of SBMP algorithm[156-157]
2.1.1 度量函数敏感性问题
针对RRT 对度量函数的敏感性问题,Resolution-Complete RRT(RC-RRT)[161-162]利用Constraint Violation Function(CVF)描述每个顶点发生碰撞的概率,并通过记录已成功应用的动作,在避免重复扩展的同时可以寻找到更有价值的顶点。RRT-blossom[163]选择待扩展节点的方式与RC-RRT 类似,不同的是RRTblossom 同时应用所有可能的行为,并移除碰撞轨迹和回退轨迹。Reachability-Guided RRT(RG-RRT)[164]的显著特点是为采样树上各顶点计算离散可达集,通过位于可达集Voronoi 区域内的采样点来引导搜索,从而在不需要特殊启发式的情况下缓解了对距离度量的敏感性。但由于RG-RRT 算法在狭窄通道环境中可能持续发生碰撞,而RC-RRT 则可能偏向选择那些有较小CVF 和较大Voronoi 区域面积的无价值顶点,因此促使 Environmentally Guided RRT(EGRRT)[157]算法将两种策略合并。Path-Directed Subdivision Tree(PDST)[165-166]用路径 段表示“采样点”,并将“采样点”按优先扩展顺序排列,同时用状态空间的非均匀细分来估计覆盖率,从而避免了度量敏感问题。GRIP(Greedy,Incremental,Path-directed)[167]通过用简单度量代替路径细分过程而进一步改进了PDST 算法,并以此偏置采样,加之DRRT[126]重复使用先前信息的优势,实现了未知环境中含微分约束的重规划。另一种与PDST 类似的方法是KPIECE(Kinodynamic Planning by Interior-Exterior Cell Exploration)[168-169],其用网格离散低维投影空间,并标记为外胞腔和内胞腔两类。因为前者较好捕捉了采样树的边界,故为实现更快的空间探索,文章以75%的概率选择外胞腔进行扩展。其次算法也将更偏爱于覆盖率较低、相邻胞腔较少、扩展次数较少等有利于采样树生长的胞腔。实验结果表明:KPIECE 的运行时间和内存消耗显著下降。最近一些机器学习方法也被用来离线学习度量函数和Steering 函数[170-173],它们通过最优控制算法提供数据集,以有监督的方式近似两状态间的尚需代价函数和对应的控制输入,从而为RRT 的在线执行提供有价值的信息。
2.1.2 最优性问题
正如前文所指出:为了获得渐近最优性,RRT*要求精确且最优地连接状态对,但其实这仅适用于完整系统[174]和存在较好Steering 方法的非完 整系统。Karaman 和Frazzoli[175]再次将RRT*算法扩展至含微分约束的运动规划问题中,并在存在局部最优Steering 方法的前提下,针对局部可控系统,提出了保证算法渐进最优性的充分条件。同样假设存在局部最优Steering 方法,满足动态环境中实时Kinodynamic 重规划的RRTX[176]算法也已被提出。类似于Kim 等[156]的工 作,LQR-RRT*[177]将基于 线性二次调节器(Linear Quadratic Regulators,LQR)的启发式应用于RRT*,即用LQR 代价函数作为度量函数来选择邻近顶点,用LQR 控制策略生成轨迹。但因为每次都是在新的采样点处进行系统线性化,所以代价函数各不相同,而且此类轨迹无法准确到达目标状态,也就无法确定结果的最优性。Kinodynamic RRT*[178]针对能控线性系统,利用fixed-final-state-free-final-time[159]控制器来精确且最优地连接状态对,从而满足了上述充分条件[175],使算法有了渐进最优性保证,类似工作还包 括Goretkin 等[179]关 于LQR-RRT*算法的改进。
与传统运动规划类似,如何利用已有信息改善采样分布以求加速算法,已经成为研究人员关心的一个问题。Xie 等[180]以欧式距离与最大速度的商做为BIT*的保守启发式,用序列二次规划(Sequential Quadratic Programming,SQP)[181]的变体求解局部BVP,提出了一种有较好性能提升的KMP 方法。同时FMT*的Kinodynamic 版本见 于Schmerling 等[182]的工作。不 考虑微分约束的系统的信息集形成了一个参数化的椭圆,直接在该椭圆中采样可有效降低算法运行时间[118]。但对含微分约束的系统来讲,显式表示信息集非常困难,而一般的拒绝采样方法在高维情况下又效率低下。故针对存在局部Steering方法的系统,Kunz 等[183]提出分层拒绝采样(Hierarchcal Reject Sampling,HRS)技术来缓解这一问题。Yi 等[184]则将其重新定义为在隐非凸函数的子水平集内的均匀采样问题,从而使蒙特卡罗采样方法得以应用:给定信息集中先前的一个采样 点,HNR-MCMC(Hit-and-Run Markov Chain Monte-Carlo)首先对某个随机方向进行采样,然后通过拒绝采样找到最大步长,使新采样点位于信息集内。Joshi 等[185]利用椭球工具箱[186]离线求解并保存线性系统的初始构型前向可达集和目标构型后向可达集,导出时间信息集(Time-Informed Set,TIS)。一旦找到初始解,后续搜索将被限定在TIS 中,从而加速KMP 的收敛。
对含有更复杂微分约束的系统,RRT*类方法获得渐进最优性的方案很难继续应用。因此只通过模型前向仿真以收获最优性的思路便吸引了研究人员的注意力。AO-X[20-21]算法将最优KMP 问题表述为可行KMP 问题。首先利用任意可行的KMP 算法(文中为RRT 和EST)在State-Cost 空间中生成可行轨迹,再通过逐次缩小轨迹代价的上界以满足渐近最优性要求。且可以证明算法的期望运行时间为O(δ-2lnlnδ-1),其中δ是描述解轨迹次优性的参数。SST(Stable Sparse RRT)和SST*[22]通过蒙特卡洛前向传播(Monte-Carlo Forward Propagation)建立采样树,以修剪树上的局部次优分枝并维持稀疏结构,分别保证了算法的渐近几乎最优性和渐进最优性。另外,一些不要求Steering 方法的加速方案也已被提出:Dominance-Informed Region Tree(DIRT)[187]引 入 Dominance-Informed Region 来谋求Voronoi 偏置与路径质量间的平衡,并采用类似于RRT-blossom 的边扩展策略和图修剪技术以缩短找到高质量解轨迹所需的时间。同样在类似于RRT-blossom[161]的边扩展策略的基础上,Informed SST(iSST)[188]模仿A*引入启发式来起到有序选择待扩展顶点和修剪的作用,提高了有限时间内的求解成功率和相同时间内的路径质量。
除上述两类获得渐进最优性的方法外,状态栅格(State Lattice)方法[189-190]也可获得分辨率下的最优性。其由离线计算的运动基元库(Motion Primitives Library)在线导出,是对初始状态无碰可达集的近似。通过在状态栅格上的搜索过程,可求得符合要求的解轨迹。
2.1.3 考虑微分约束的基于学习的运动规划方法
与传统运动规划类似,基于学习的方法也被应用于考虑微分约束的运动规划问题,现有文献中的改进措施主要集中于:①端到端地生成轨迹;②学习在无碰可达集内生成稠密(最优)的采样点分布;③在不考虑障碍物的情况下,学习针对复杂系统的LPM;④学习有关NSM 的度量函数。Huh 等[191-192]提出的c2g-HOF(cost to go-High Order Function)神经网络架构以工作空间为输入,输出给定构型空间和目标构型的连续cost-to-go 函数,而据其梯度信息便可直接生成轨 迹。MPC-MPNet(Model Prective Motion Planning Network)[23]是MPNet[19,142]在KMP 领域的进一步扩展,算法框架包括神经网络生成器(Neural Generator)、神经网络鉴别器(Neural Discriminator)和并行模型预测控制器(Parallelizable Model Predictive Controller )。前者迭代生成批量采样点,中者选出有最小代价的采样点并通过后者进行最优连接(也可为所有批量采样点在树上找出最近点,并用MPC 并行计算局部最优轨迹,即文中的MPC-MPNet Tree 算法),实验结果表明MPC-MPNet 相较现有算法在计算时间、路径质量和成功率方面有较大提升。为研究任务约束、环境不确定性和系统模型不确定性场景中的长范围路图构建问题,Francis 等[24]和Faust 等[25]合并了PRM 的规划效率和RL 的鲁棒性,并提出由深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)[193]或连续动作拟合值迭代(Continuous Action Fitted Value Iteration,CAFVI)[194]训练的RL agent 决定路图连通性。结果表明无论相比RL agent 自身还是传统的基于采样的规划器,PRM-RL 的任务完成度都有所提高。RL-RRT[26]仍将RL agent 作为局部规划器,同时训练一个有监督的可达性估计器作为度量函数。该估计器以激光雷达等局部观测数据为输入,预测存在障碍物时RL agent 连接两状态所需的时间,以起到偏置采样分布的作用。L-SBMP(Latent Sampling-based Motion Planning)[27]方法由自编码网络、动力学网络和碰撞检测网络构成(分别模仿基于采样算法中的状态采样、局部Steering 和碰撞检测),前者隐式地编码了嵌入在状态空间的系统动力学低维流形,并提供了对隐空间直接采样的能力,加之动力学网络和碰撞检测网络,使L2RRT(Learned Latent Rapidly-exploring Random Trees)可以有效地、全局地探索学习到的流形。CoMPNet(Constrained Motion Planning Networks)[28]针对操作规划和有运动学约束的规划问题而提出,由环境感知和约束编码器组成,它的输出作为神经规划网络的输入,并与双向规划算法一起,在约束流形上生成起始构型和目标构型间的可行路径。
经过2.1 节的讨论,可以直观地觉察到引入微分约束后SBMP 算法所面临的新困难:首先算法的搜索范围发生了变化,即局部无碰可达集的概念代替了传统运动规划中可视区域的概念,用局部无碰可达集外的构型引导采样树的生长显然浪费了宝贵的计算时间。但在可达集中直接采样的思路目前却仍存在2 个难点:一是高维非线性系统可达集的实时计算,二是可达集形状的不规则;其次更一般的TPBVP 问题的求解很难逾越,即使代之以采样树的前向仿真方案,过长的运行时间也将使算法在实际应用中很难获得最优性,甚至变得不可行。综上,如何像传统运动规划那样,借助已有或学习到的信息限制搜索范围、安排搜索次序、设计度量函数,以加速考虑微分约束的运动规划算法,将是未来的发展方向。另外,前述SBMP 的加速策略或解品质提升策略已被总结在表2 中。

表2 SBMP 的加速策略或解品质提升策略总结Table 2 Summary of acceleration strategies or solution quality improvement strategies for SBMP
2.2 基于优化的运动规划算法
虽然考虑微分约束的基于采样的运动规划算法具有全局搜索特性且不需要初始猜想,但其在高维空间中的应用确需消耗较长计算时间,这使得一些研究人员诉诸于局部最优的基于优化的运动规划算法。与SBMP 将障碍物约束满足与否交予碰撞检测这一黑箱不同,基于优化的方法受益于最优控制直接法[195-196],即显式考虑障碍物约束。其将函数空间中的无穷维优化问题转化为有限维非线性参数优化问题[180],在一定意义上可被统一至模型预测控制(Model Predictive Control,MPC)[197-198]的框架下(参见图11,其根据当前测量到的系统状态x(t0)反复解一个开环最优控制问题,这里u为控制量,f为系统模型,d为扰动,X和U分别为可行的状态集合和控制集合,Xf为目标状态集合,J为优化指标。上标“*”表示最优值,“~”表示标称量,“·”表示导数)。文献中目前大致存在3 类基于优化的运动规划算法:

图11 标称MPC 的一般框架Fig.11 General framework for nominal MPC
1)无约束优化方法[29-31,199],其目标函数被由障碍物表示的人工势场所增强,或通过确定性协变方法[29-30],或通过概率梯度下降方法[31]减小目标函数值。虽不需要高质量的初始猜想,但并未从理论上提供收敛保证,而且在有杂乱障碍物的环境中的失败率较高,不适用于实时运动规划问题。
2)序列凸规划方法,对有约束的非凸优化问题来讲,通用类非线性规划算法[200-201]的收敛表现严重依赖于初始猜想,无法提供收敛保证并提前预知所需的计算时间,很难应用于实时任务。而凸优化问题可保证在多项式时间内可靠地得到全局最优解[202],为借助这一优势,必须将非凸的最优运动规划问题进行凸化。其中的代表性方法包括TrajOpt[32-33]、SCvx[34-35]、GuSTO[36],且后两者提供了理论证明,促进了其在实时任务中的应用。此类方法的详细介绍可参考Malyuta等[203]的文章,这里不再展开。除问题的凸化外,该类方法面临的另一困难则在于如何建立恰当的避障约束[204]。
3)凸分解方法,为了避免由避障需求带来的非凸约束的影响,凸分解方法通常将已知自由空间分解为一系列重叠的凸胞腔,并保证数个插值曲线片段分别位于各凸胞腔内以满足机器人运动过程的安全性要求(参见图12,其中紫色为障碍物区域,绿色为已知自由空间分解后的凸胞腔,蓝色为规划的轨迹)。Deits 和Tedrake[205]用IRIS(Iterative Regional Inflation by Semidefinite Programming)计算安全凸区域,由混合整数优化完成多项式轨迹分配,最后利用一种基于平方和(Sums-of-Squares,SOS)规划[206]的技术确保了整个分段多项式轨迹不发生碰撞。相比于IRIS,Liu 等[37]根据由JPS(Jump Point Search)[207]算法求得的初始分段路径建立安全飞行走廊(Safe Flight Corridor,SFC),减少了凸分解的时间。同时SFC 为二次规划(Quadratic Program,QP)[180]过程提供了一组线性不等式约束,允许进行实时运动规划。Chen 等[38]逐步构建基于八叉树的环境表示,并通过在八叉树数据结构中的有效操作来在线生成由大型重叠三维网格组成的自由空间飞行走廊。Gao 等[39]则在环境点云地图的基础上,将SFC 的构建交付于SBMP。除此之外的另一个关键问题是区间分配(Interval Allocation)方式和时间分配(Time Allocation)方式,前者决定每个凸胞腔内的轨迹间隔,而后者则处理在每个间隔上所花费的时间。

图12 凸分解方法示意Fig.12 Illustration of convex decomposition method
虽然基于优化的运动规划算法采用了3 种不同的处理思路,但其本质上都是建立在有约束的非线性优化问题的基础上的,所以优化技术未来可预见的重大进展将是此类算法性能提升的主要渠道。表3[78]对本文所讨论的几种开环最优路径(轨迹)规划算法进行了总结,其中rn和kn分别代表在路图上选取邻域点时的半径和数量,n为采样点数量,d为Cfree的维数,μ为体积测度,ζd为d维单位球的体积,φ∈(0,1)为最优误差。对于RRT*:c*为最优路径代价,θ∈(0,1/4),ψ∈(0,1),而含微分约束的运动规划不需要几何邻域的定义。
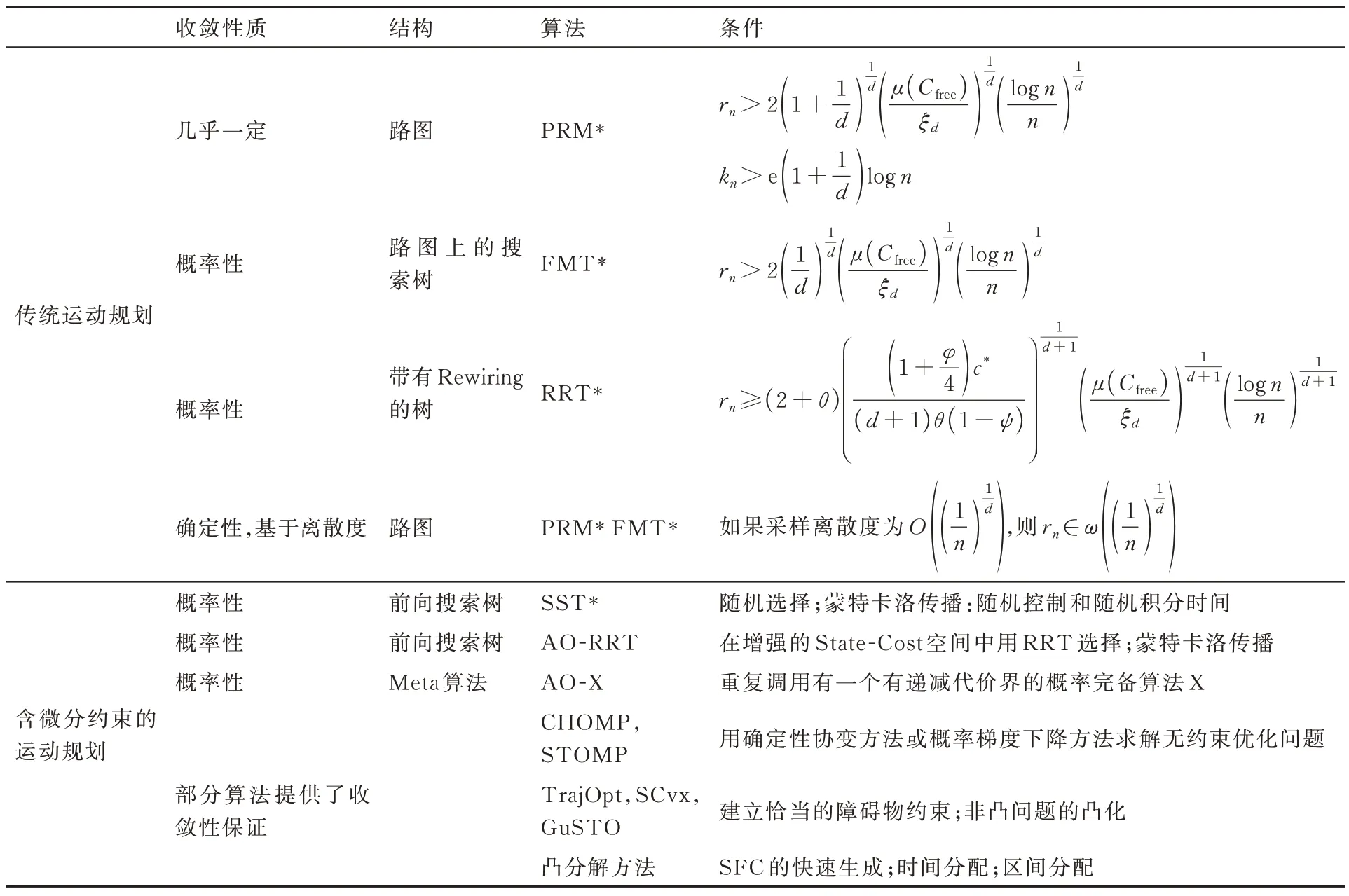
表3 考虑微分约束的最优算法总结[78]Table 3 Summary of optimal algorithms considering differential constraints[78]
3 反馈运动规划
真实物理世界中的大多数问题都需要反馈,这一需求来自于传感器测量的不确定性、环境的不确定性和未来状态的不确定性,因而规划结果应该以某种方式依赖于执行过程中收集到的信息。反馈运动规划有两种不确定性建模方法:显式方法和隐式方法。前者通过建立能显式考虑传感器误差和控制器误差的模型,并将其融入规划算法来解决不确定性下的运动规划问题。而后者则源于控制理论,即为系统设计反馈控制律或称为控制策略,而非开环控制律(一条动作轨迹或动作的时间序列),以使其即使处于不期望的状态,也知晓该采取何种动作。但在传统做法中,规划与控制往往是解耦的,由外部干扰、模型误差及控制约束等导致的跟踪误差可能造成意外碰撞(参见图2),因此有必要将两者放在一起来考虑。本节剩余部分将分别对显式建模和隐式建模两类方法进行综述。
3.1 显式建模不确定性
显式方法主要发生在信念空间(Belief Space)[208],可在部分可观测的马尔可夫过程(Partially Observable Markov Decision Process,POMDP)的框架下进行描述。但同时也面临着维数诅咒和历史诅咒,即计算复杂度关于规划问题的维数和时域长度指数增长。基于点(Point-based)的方法[209-212]一定程度上缓解了这个问题,其核心思想是用信念空间中的采样点集近似表示信念空间,用离线值迭代方式求得在线执行所依赖的动作策略,可在合理时间内解决具有数十万状态的中等复杂度的POMDP。相反,在线方法[40-41,213-214]将规划和执行规划结果交替进行:在每个时间步中,仅为当前信念搜索一个最优动作,进而执行该动作并更新信念。从而避免了预先为所有未来事件计算策略,具备更强的可扩展性。目前最快速的在线方法为POMCP(Partially Observable Monte-Carlo Planning)[40]和DESPOT(Determinized Sparse Partially Observable Tree)[41],两者均采用了蒙特卡洛采样技 术[215],可解决 状态数高达1056的大规 模POMDP 问题。POMCP 在信念树(Belief Tree)上进行蒙特卡罗树搜索(Monte-Carlo Tree Search,MCTS),并使用PO-UCT(Partially Observable-Upper Confidence Boun-ds for Trees)[215]来权衡探索(Exploration)与利用(Exploitation)。DESPOT 则通过一组采样场景得以在稀疏信念树中执行Anytime 启发式搜索,并且相较POMCP 提供了更好的理论保证。借助CPU 和GPU 的并行计算能力,HyP-DESPOT(Hybrid Parallel DESPOT)[216]进一步 发展了DESPOT,并通过实验验证了机器人在行人间进行导航的实时性能。Adaptive Belief Tree(ABT)[214]专门为适应环境变化而设计,使信念树的搜索过程不必从头开始。
早期POMDP 文献主要聚焦于离散状态空间、离散动作空间和离散观测空间。但对于机器人任务来讲,连续模型无疑是更合理的。一些工作已将基于点的离线规划方法扩展至连续状态空间[217-219]和连续观测空间[218,220]。至于在线规划,前述方法可容纳连续状态空间,且关于连续动作空间[221]和连续观测空间[42-43]的有效方法也已提出。其 中POMCPOW[42]和DESPOT-α[43]采用了一种受粒子滤波启发的加权方案,可较好应对具有连续观测空间的真实问题。除POMDP表述外,另外还包括结合传统运动规划和随机最优控制的方法[222-225],但这些工作均基于高斯噪声假设,存在一定的局限性。
3.2 隐式建模不确定性
隐式方法可用鲁棒模型预测控制(Robust Model Predictive Control,RMPC)[226]的框架进行统一描述。其直接考虑不确定性,通过优化选择最坏情形下的控制策略并同时生成轨迹。更正式地讲,优化器是构建了一个反馈,以使在所有可能的不确定性下约束都被满足,且代价函数被最小化。但由于RMPC 需要对任意函数进行优化,因此计算复杂度很高。而且由于维数诅咒,离散化也不可 行,如Scokaert 和Mayne[227]证明,即使只考虑不确定性集合的极值,线性鲁棒模型预测控制的计算复杂度关于预测时域仍是指数级的。对于非线性系统,这一情况则更加严重。
上述原因促使研究人员把精力集中在被称作Tube MPC[226]的解耦策略上,它将RMPC 分解为开环最优控制问题和辅助跟踪控制器的设计问题,即通过在线求解标称MPC,并且离线设计鲁棒跟踪控制器来使系统状态在不确定性作用下,一直保留在以期望轨迹为中心的一个鲁棒控制不变(Robust Control Invariant)Tube 内,从而将决策变量由控制策略π(x(t),t)转变为开环控制输入u(*t),具体参见图13(优化器反复求解开环最优轨迹;辅助控制器κ根据当前测量到的系统状态x、开环轨迹上对应的状态x*和控制输入u*,计算实际动作指令u)、图14(若初始状态x(t0)位于以开环轨迹为中心的Tube 内,则后续状态亦不会逃离Tube)。尽管从计算复杂度讲这种解耦设计是可行的,但同时也产生了较大的对偶间隙(Duality Gap)[228-229],Homothetic[230]、Parameteri-zed[231]、Elastic Tube MPC[232]虽致力于缓解该问题,但目前仅适用线性系统。

图13 Tube MPC 的一般框架Fig.13 General framework for nominal Tube MPC
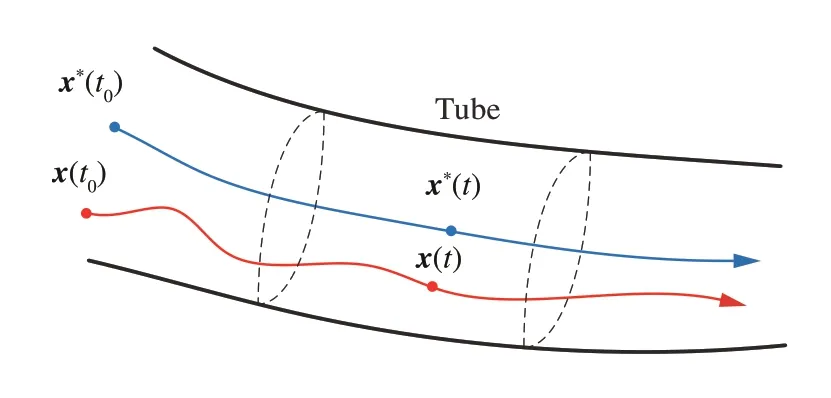
图14 Tube 示意Fig.14 Illustration of Tube
由于设计非线性控制器及计算相关不变集的复杂性,非线性Tube MPC 相较线性Tube MPC 面临着更大的挑战。不过即使如此,一些方案也已被发展来尝试解决这个问题,可达性分析便是其中之一。Althoff[233]将非线性视为有界干扰,利用线性化后的动力学方程估计非线性系统可达集,并成功在地面车辆[234]和飞行器[235]上进行了测试。但由于无法保证所有模型的线性部分都占据主导,故这种处理方式有很强的保守性。而HJ 可达性[236]分析借助水平集[237]这一有力工具,在状态空间的离散网格上求解哈密顿-雅可比-艾萨克(Hamilton-Jacobi-Isaacs,HJI)偏微分方程,可以应用于一般的非线性系统,且能够表示各种形状的集合、较容易地处理控制和扰动变量。Chen 和Herbert 等[44,238]利用上述手段分析跟踪系统和规划系统间的追逃博弈模型,离线计算并保存两系统间由干扰和控制约束造成的最大跟踪误差,同时将使用简化模型进行实时规划的路径或轨迹规划器融入其中,发展了一种名为FaSTrack 的快速安全规划算法(参见图15)。然而随着状态空间维数的增加,HJ 可达性的计算将逐渐变得不可行。Singh 等[239]通过用SOS[206]代替HJ 可达性分析,以期缓 解FaSTrack 在高维空间中的计算复杂性。其他的一些改进措施也已被提出,包括分解方法[240-241]、Warm-start 方法[242]、基于采样的方法[243]和基于学习的方法[244-246]。

图15 搭载FaSTrack 算法的无人机运动过程Fig.15 Motion of UAV with FaSTrack
李雅普诺夫函数[247]因不用求解方程便可验证系统稳定性而在非线性控制中具有重要地位,其水平集可被用来描述鲁棒不变Tube,然而为非线性系统计算这样的函数很有挑战性。近年得益于凸优化技术的发展,SOS[206]常被用来检查多项式形式的李雅普诺夫函数的正定性,以近似系统的吸引域。Tedrake 等[248]基于此想法并结合RRT 提出了LQR-Trees 算法,该算法通过建立一个局部稳定控制器树,可以驱使状态空间中某些有界区域内的任一初始状态达到目标,不过并不适于实时任务使用。与LQR-Trees 最大化后向可达集的内部近似不同,Majumdar 和Tedrake[45]利用SOS 技术为标称轨迹集离线计算最小尺寸的Funnels,然后通过序列组合达到在线避障的目的。但预先指定轨迹库的做法同时也使标称轨迹的灵活性受到限制,且每条轨迹的离线计算时间过于漫长(约为20~25 min)。控制李雅普诺夫函数(Control Lyapunov Function,CLF)可以保证渐近稳定性,控制障碍函数(Control Barrier Function,CBF)可以保证安全性,即将状态维持在一个前向不变集内。针对控制仿射系统,Ames 等[46-47]通过将软约束处理为前者,将硬约束处理为后者,并同时表示在二次规划的框架下,也发展出了一种可以保证安全性的在线轨迹跟踪技术,并被应用于多机器人系统[249]。收缩理论(Contraction Theory)[250-251]是研究非线性系统轨迹对间收敛性质的方法,因其在分析跟踪控制器的稳定特性时不需提前指定标称轨迹,故而特别适合于反馈运动规划问题。Singh 等[48]利用收缩理论得以将开环运动规划器作为黑箱,并通过SOS 优化离线计算最优控制收缩测度(Control Contraction Metrics,CCMs)(CLF 的推广概念),从而扩大了优化的可行区域,得到了尺寸固定、界面最小的不变Tube 及与之相关的反馈跟踪控制器。
至此本节已详细介绍了两类针对不确定性的反馈运动规划算法(参见表4),通过以上讨论可知:显式方法主要通过建立不确定性的概率模型,并进行离散搜索来达到规划目的,但其计算过程及计算结果显然受到搜索方式及模型精确程度的影响,目前一些更先进的采样搜索策略(如重要性采样方法)已被成功用于加速POMDP的求解[252],这也将是此类方法未来的发展方向之一。而隐式方法的焦点在于计算非线性系统的鲁棒控制不变Tube,不过上述研究均采用了有界干扰假设,从而使得Tube 的计算趋于保守。如果可以从收集到的数据中构造并不断更新动力学模型,那么将大大提升现有算法的性能。Hewing 等[253]的文章对这一问题进行了详细讨论,此处限于篇幅不再展开。

表4 反馈运动规划算法总结Table 4 Summary of feedback motion planning algorithms
4 结论
运动规划是机器人研究中的基础问题,过去四十年中出现了许多可同时保证求解效率和解路径(轨迹)质量的算法,包括组合运动规划、基于采样的运动规划、基于优化的运动规划和反馈运动规划算法。它们成功解决了一些复杂场景中的规划问题,显示了巨大优势。本文首先介绍了运动规划问题的内涵和几种经典的运动规划算法;随后按照传统运动规划、考虑微分约束的开环运动规划和反馈运动规划的顺序综述了大量相关文献,并重点讨论了渐近最(近)优算法的加速策略、不确定性下的反馈规划、动态环境中的运动规划、学习算法与运动规划算法的融合等具有挑战性的课题。通过以上评述可知,CMP 能严格保证算法的完备性,但在面临高维空间和障碍物数量巨大的场景时却无能为力,这进一步促使了SBMP 的出现。“采样”即意味着“离散”,故其优势正是在于以牺牲算法的完备性为代价,用可数点集或序列及它们间的连接关系来近似C-space 的连通特性。不过早期RRT 类算法将搜索过程完全交由固定搜索域内的随机采样点进行引导的做法无疑在无用状态上浪费了大量时间,当为了得到符合系统运动特性的轨迹而直接考虑微分约束时,这一问题则更加凸显。因此求解最优运动规划问题的另一思路是放弃全局搜索,将问题转换为有限维的非线性参数优化问题,从而借助优化领域丰富的工具进行求解,此类方法的关键研究点之一是为算法提供收敛保证。值得注意的是,上面的规划过程均未考虑现实中的不确定性,而由此产生的跟踪误差往往会造成意外碰撞的发生。反馈运动规划中的不确定性显式建模方法虽然提供了优美的分析框架,但建立这样的模型无疑是富有挑战性的。而隐式建模方法虽然可以保障机器人运动过程中的绝对安全性,但现有方法的计算复杂度和计算结果的保守性仍然较高。因此在综合考量各类算法优缺点(参见表5)的基础上,本文归纳了4 个未来值得研究的方向:
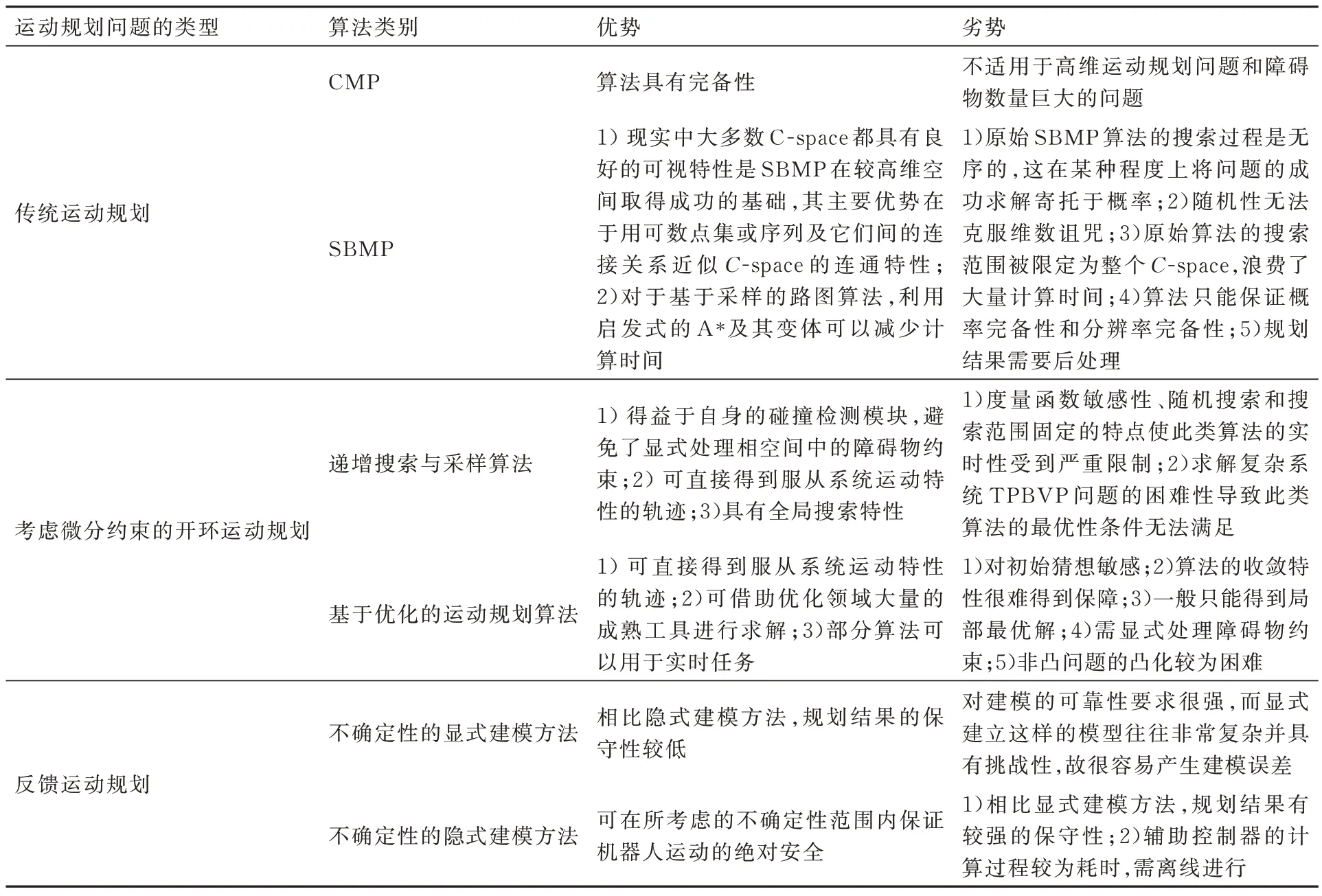
表5 各类运动规划算法的优劣势总结Table 5 Summary of advantages and disadvantages of various motion planning algorithms
1)运动规划算法的渐进最优性和实时性之间存在着矛盾。当考虑高维问题和微分约束时,这一矛盾被进一步激化。因此如何在算法设计过程中妥善地融入表2 中的各类已有信息来降低时间复杂度,并提高解的质量,仍是需要深入思考的一个问题。如为BIT*算法设计确定性采样序列和较好的启发函数,并与更先进的图搜索算法(ARA*、D*Lite、AD*等)进行融合;利用可达集及其对应的最优控制律信息引导算法的采样和局部连接等。
2)学习算法为运动规划问题提供了一个新的视角。如何在已有不精确模型的基础上,利用数据缓和开环运动规划算法中最优性与实时性的矛盾、降低反馈运动规划的保守性,将是后续研究的重点。如学习算法与无扰可达集计算过程的结合、学习算法与Tube 计算过程的结合[253]等。另外由于学习算法自身的特性,基于学习的运动规划算法对于环境的迁移性仍是待解决的问题。
3)借助计算机视觉领域的丰富成果,预测动态障碍物的行为或轨迹[130-131],并与已有运动规划算法框架进行融合也已成为最近的关注点之一。但除预测未来状态外,对预测效果的评估也至关重 要。如Fridovich-Keil 等[254]提出的Confidence-aware 方法可使机器人对当前预测模型的准确性进行推理,提高了动态环境中规划结果的鲁棒性。因此如何对轨迹预测模型或行为预测模型的不确定性进行建模也是未来值得研究的问题[255]。
4)运动规划问题的复杂度与状态空间的维数紧密相关,而后者随参与任务的机器人数量的增多而快速增加,将机器人简单地处理为独立个体的做法无疑为解决复杂问题设置了阻碍。虽然本文的关注范围限于单机器人运动规划问题,但更加耦合的多机器人协同或对抗亦将是未来主要的发展趋势。
