基于CARS-SAA的土壤铵态氮含量高光谱反演
2023-02-06汤能肖志云王生富
汤能肖志云王生富
(1.内蒙古工业大学电力学院,内蒙古 呼和浩特 010080;2.内蒙古自治区机电控制重点实验室,内蒙古 呼和浩特 010051;3.内蒙古自治区农村牧区社会事业发展中心,内蒙古 呼和浩特 010020)
铵态氮是植物生长发育必需的营养元素,在土壤微生物的作用下进行硝化作用转化成硝态氮素,进而增强氮素在土壤中的移动性,更好地被植物根系吸收,在植物的生长过程中起关键作用。故而铵态氮含量指标被广泛用于土壤养分供应能力的分析中[1-3]。随着科学技术的迅猛发展,高光谱技术为高效快速检测土壤属性提供了新的技术和方法[4]。针对高光谱成像技术的特征变量筛选问题,大量学者已进行了众多相关研究。李江波等[5]利用竞争性自适应重加权算法(CARS)、遗传算法(GA)和蒙特卡罗无信息变量消除算法(MC-UVE)对光谱特征变量进行筛选,并建立偏最小二乘(PLS)预测模型,结果表明,CARS-PLS预测模型的精度最高且筛选变量最少。Fan等[6]选择竞争性自适应重加权算法CARS选取特征变量后,再选取连续投影法(SPA)进一步筛选有效特征变量,在简化预测模型的同时更提升了模型预测精度。孙宇乐等[7]对土壤光谱用微波雷达四极化后采用相关分析法过滤筛选土壤属性特征变量取得较好的效果。朱淑鑫等[8]在研究土壤速效钾时,就光谱数据冗余、维度过高问题,将K均值法与连续投影算法耦合筛选光谱特征变量,有效提取了建模精度较好的特征变量。齐海军等[9]通过对平滑后的光谱数据进行标准正态变换来消除土壤颗粒、表面散射、光程变化对光谱曲线的影响,根据变量投影重要性筛选出后续较好的建模特征变量。李焱等[10]通过提取特征变量,以多元逐步线性回归和偏最小二乘回归建模,发现采取二阶微分变换后,以偏最小二乘回归建模R2达到了0.96最佳。刘九材等[11]利用高光谱技术进行苹果品种鉴定并分析不同的特征变量筛选算法,研究表明,模拟退火算法能够有效地筛选出特征变量。周伟等[12]提取粮虫特征时采取模拟退火算法能精准筛选最优特征,验证其特征筛选的可行性。
因此,为进一步探究土壤高光谱特征变量的优选方法,以建立优化的土壤铵态氮预测模型,本文分别采用CARS、SAA以及CARS-SAA进行特征变量筛选,并利用PLSR和RF相结合的模型,建立土壤铵态氮的预测模型。快速有效地对河套灌区土壤铵态氮含量进行预测,为实现土壤铵态氮的高光谱技术在线检测奠定理论基础。
1 材料与方法
1.1 研究区概况
五原县位于内蒙古自治区巴彦淖尔市,东临包头,西接临河,南隔黄河,北依阴山。地处河套灌区腹地沉积了较厚的肥美土质。气候偏向中温带大陆性气候,适合农作物及各种植被的生长。虽然部分土地盐碱化,但不影响耐碱作物如葵花、高粱等作物生长[13]。实验研究区位于五原县隆兴昌镇农业生产基地,如图1所示,主要以种植向日葵、玉米、高粱等农作物为主,是内蒙古地区农业高产高效的实验基地。

图1 研究区位图
1.2 土壤样本采集与测定
土壤样本通过前往河套灌区野外实地调查取样,根据研究区域耕种面积,本次共采集土壤样本70份,采集土壤时采用网格布局法,每个采样点间距为5m,每份土壤采样深度为15cm,每个土壤样本采集重量为100g。将土壤装进保鲜密封袋内带回,经过筛去除草根、碎石等杂质,每个土壤样本分为2份分别不同处理。
1份利用土壤养分分析仪采用化学方法来测定土壤铵态氮含量的真实含量数据。将土壤用研钵研磨后再用筛子过筛放置于直径8cm、深2cm的四周涂黑的玻璃皿中,每个土壤玻璃皿样本中选取3个区域测量得出实测铵态氮含量。采用SPXY算法将70个土壤样本中的52个样本划为建模集,其余18个样本划分为验证集,划分结果如表1所示。
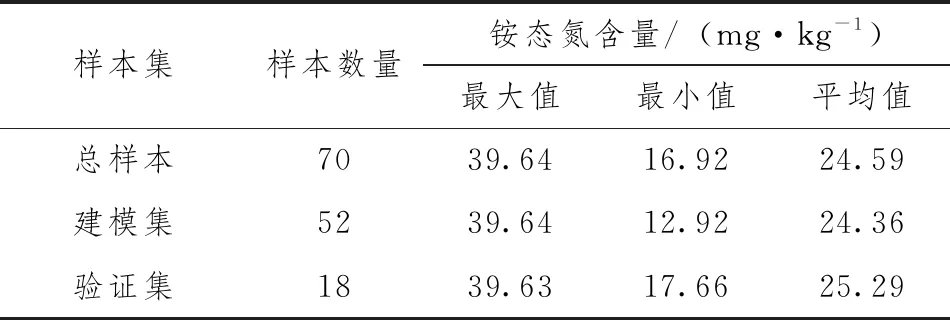
表1 土壤样本集铵态氮含量统计
另1份则采用实验室配备的一款产自芬兰的便携式高光谱相机Specim IQ进行河套灌区土壤样本的高光谱数据测定,该高光谱相机的测定波长范围为400~1000nm,光谱分辨率为3nm,在光谱维度上记录的光谱波段数量为204个。测定土壤前利用标准白板进行校准和调整,白板校正可以消除环境不匹配的问题。同时采集过程中为了减少外界环境对测定结果的影响,测定全程在密闭无外界干扰的环境下进行。将装有土壤的涂黑的玻璃皿放在中间实验台上,以50W卤素灯为测定光源,倾斜45°角,距离土样表层75cm进行照射,用高光谱相机进行拍摄。实验室高光谱拍摄系统如图2所示。

图2 室内拍摄系统
将拍摄到的土壤高光谱图像用ENVI 5.3软件标记出在之前测量铵态氮真实值的3个区域作为感兴趣区域(Region of interest,ROI),与用土壤养分分析仪测量的真实值一一对应。70个样本共计提取出210条光谱曲线。
1.3 土壤光谱预处理
为消除实验土壤样本间散射导致的基线偏移和减少平滑对有用信息的影响,同时也为了便于寻找和提取土壤铵态氮的高光谱敏感特征变量,本文对采集到的土壤样本的原始反射光谱曲线进行Savitzky-Golay平滑,多元散射校正(MSC),微分变换以及组合处理的土壤光谱数据预处理[14]。
1.4 特征变量筛选
1.4.1 CARS特征变量筛选
CARS是一种可以用来选取特征变量的算法,是由PLC模型回归系数、蒙特卡洛采样法相结合得出,CARS模拟“适者生存”的原则,进行自适应加权采样的同时剔除PLS模型中回归系数绝对值权重较小的点,保留权重较大的点建构起新的子集,在新的子集的基础上建立PLS模型,经进行一系列计算后,选定PLS模型交互验证均方根误差(RMSECV)最小的子集中的波长作为特征波长,详细过程如下[16]。
选用蒙特卡罗采样法,每次随机抽取样本的80%作为建模集,余下样本作为验证集,进行PLS模型的建构。对蒙特卡洛的采样次数(N),必须预先进行设定。在N次采样过程中,需依次记录PLS模型中回归系数的绝对值权重。
(1)
式中,m为单次采样中余下的变量数;|bi|为第i个变量的回归系数绝对值;|wi|为第i个变量的回归系数绝对值权重。
利用指数衰减函数强行去除回归系数绝对值权重较小的波长。在第i次基于蒙特卡洛采样建立PLS模型时,根据指数衰减函数得到保留的波长点的比例Ri:
Ri=ue-ki
(2)
式中,u和k是常数,可以按照以下2种情况计算。
在首次采样并进行相应计算时,各波长都参与了建模分析,故而留下的波长点的比例为1。
在第N次采样完成并进行计算时,参与PLS建模的波长仅有2个,因而保留的波长点的比例为2/n,n对应的是原始波长点数。由此可知,u和k的计算公式:
(3)
(4)
每次采样时,都是采用自适应加权采样(ARS)在上一次采样时的变量数中选择相应数量的波长变量,进行PLS建模,计算交叉验证均方差。
完成N次采样后,得到N组候选的特征波长子集,以及对应的选择交叉验证均方差值,选择交叉验证均方差值最小值所对应的波长变量子集为特征波长。
1.4.2 SAA特征变量筛选
SAA在诸多领域都得了突出的应用,然而在近红外高光谱技术中运用还较罕见。此算法的优点在以一定概率接收差解用于跳出局部最优解,达到全局最优解,完成高光谱特征变量的筛选。这是一种模拟固体降温过程中内部变化规律进行优化的方法。模拟退火算法收敛速度取决于起始温度T0、终止温度Tf,马尔可夫链长度LK等,故而对控制算法进程的参数需做到合理选择,确保在有限时间内算法能够返回一个近似最优解是非常关键的[17]。
退火过程由冷却进度表控制。目的是使得系统能够尽量保持平衡,在有限时间内,确保算法能够逼近最优解。参数具体有第k个马尔科夫链的长度LK,控制温度参数初值T0和终值Tf,以及在k个温度控制的参数值Tk。若经LK次计算后,得到的解的概率分布与T=Tk时的分布高度接近,则反映出模拟退火算法达到准平衡。由此能够得出,在T有着足够大数值的情形下,该算法能够立刻实现准平衡,其中变量Tk衰减量越大,则相应花费越长的LK才可恢复准平衡,因而如果选取小的衰减量,能够有效避免过长。此外,在收敛性、执行效率方面,也是算法实际需要考量的[18]。综上,最后设置T0=100℃;Tk=0.95T,Tf=1℃,Lk=50为本次实验SAA特征变量筛选的参数。然而将土壤高光谱数据采用SAA特征变量筛选,虽然简化了建模的复杂度,但拍摄的土壤高光谱数据量巨大导致模拟退火算法产生的计算量大,在实际处理花费的时间较长。
1.4.3 CARS-SAA特征变量筛选
因CARS选择后仍有着较多数量的特征变量,且蒙特卡罗采样过程表现出一定的随机性,故而CARS筛选的特征变量并非具有固定性,可能未完全消除无关变量,建立的模型结果不稳定[16]。而SAA筛选特征变量虽然简化了建模复杂度,提高模型精度,但由于高光谱数据存在大量冗余信息数据量大,导致SAA在特征变量选取时就会相应地增加算法搜索时间从而使得计算量非常大,需要花费较长时间。
由此本文提出利用SAA对CARS提取的特征变量再次进行变量筛选处理,降低因为CARS产生的随机性问题,将筛选的特征变量更加优化使与铵态氮含量有关的信息变量被筛选的概率得到提升,不仅稳定预测模型精度,还解决了SAA单独使用过程中其计算量繁琐,运算时间缓慢的问题。
1.5 建模方法与评价
为避免使用单一的模型反演导致训练数据中的某些相关信息变量缺失以及避免单个模型预测效果不佳的风险,本研究采用了偏最小二乘回归与随机森林回归的结合模型(PLSR-RF、RF-PLSR),2种模型相结合可以扩大假设空间,使数据之间在模型中包含尽可能多的真实性,进而提高了模型对数据的逼近能力,达到更高的预测精度[19]。
在模型精度上选用均方根误差(RMSE)、决定系数(R2)、相对分析误差(RPD)进行评价,RMSE越小,R2越接近1,模型越稳定[19]。如果RPD≥2,意味着模型的估测能力较好;如果1.4≤RPD<2.0,意味着模型能够粗略估测样本含量;如果RPD<1.4,意味着模型预测能力极差,无法估测样品含量[20]。
2 结果与分析
2.1 光谱预处理
由于高光谱拍摄相机本身以及采集系统所在外部环境的影响,采集到的高光谱信息会出现噪声、基线漂移等现象,光谱预处理可消除不利因素的影响。如图3所示,对采集到的原始光谱曲线,故而需使用SG平滑、多元散射校正(MSC)、平滑一阶微分变换(SG-FD)等多种方法进行预处理,并分别建立PLSR-RF、RF-PLSR模型,经后续建模效果对比后发现,在预处理效果上,SG-FD有着最佳表现,故而后续均基于SG-FD方法进行预处理。
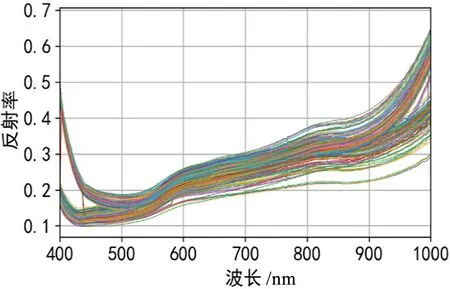
图3 土壤原始光谱曲线
SG-FD预处理后的光谱反射率曲线如图4所示,可知因铵态氮含量不同,光谱曲线的等级差异及基线漂移和背景干扰均得以有效消除,并放大光谱曲线的细节特征。

图4 SG-FD变换光谱曲线
2.2 CARS-SAA特征变量筛选
基于CARS进行特征变量的筛选,能够使得光谱变量间的高度共线性问题得到改善,从而使得预测模型具有更高的速度和精度[21]。如图5所示。

图5 CARS关键变量选择
能够发现优选变量的数量均随迭代次数的增加呈指数减少,其交叉验证均方差值整体呈现先减后升的趋势,运行次数增加,相应有着越少的变量数被选出,前9次采样有明显减少,此后趋平稳。在前9次采样中,整体上交叉验证均方差值呈逐步降低,反映出筛选过程中剔除的变量并不会影响到铵态氮去除量,而第9次采样迭代以后,交叉验证均方差值出现回升,反映出反射率光谱中有大量添加与铵态氮无关的噪声或信息,从而导致交叉验证均方差值上升。在第9次采样时,交叉验证均方差值最小,也就是选择的子集最优。CARS最终选择出40个特征变量,将筛选的特征变量显示在一条原始光谱曲线上的分布如图6所示。

图6 CARS特征变量分布图
提取后得到的40个特征变量作为SAA的输入,再进一步利用SAA对高光谱数据波长再次。本次实验所采用的SAA在退火过程中以一定的概率接受恶化解时,能够记住当前最优解,保证优化过程中最优解不会因为接受恶化解而退化。最终从高光谱数据的204个波数点中优选出519.25nm、622.26nm、678.71nm、714.55nm、810.86nm、886.84nm、889.90nm、892.95nm、917.42nm、935.81nm共10个特征变量,仅占全光谱波长变量的4.9%,和单纯用SAA提取特征变量过程相比,大大减少了计算量。特征变量如图7所示,集中在620~680nm、880nm~900nm附近。CARS-SAA特征变量筛选不仅消除无关的变量并减少变量之间的共线性,提高预测模型的精度及速度,同时将CARS筛选的特征变量利用SAA进一步优化使筛选有用信息变量的概率增大稳定了预测模型精度,也避免了SAA算法其计算量大的问题。

图7 CARS-SAA特征变量分布图
2.3 模型建立与分析
以全光谱(full-spectra,FS)、CARS、SAA和CARS-SAA筛选的量作为模型的输入自变量,铵态氮含量作为因变量分别建立PLSR-RF、RF-PLSR回归模型并计算模型评价指标,模型预测结果如表2所示。从表2可以看出,不同的筛选变量方法以及不同的建模方法,其精度有一定的差异。从模型评价指标可知,将全光谱直接进行建模效果并不是很好,其验证集决定系数R2均未超过0.5,RMSE值均超过3.4mg·kg-1,RPD值范围在1.4~2.0,表示该模型可以对土壤铵态氮含量进行粗略估测。

表2 铵态氮含量回归模型
单独使用CARS和SAA筛选方法建立的模型与全光谱建立的模型相比精度和稳定性有了很大的提升,其中以SAA-PLSR-RF模型最佳,其验证集决定系数R2为0.856,RMSE值为1.924mg·kg-1,RPD值为2.632,已经具有较好预测土壤铵态氮含量的能力。将2种筛选变量方法结合后通过建模分析发现,CARS-SAA筛选变量后建立的PLSR-RF模型精度达到了最高,其验证集决定系数R2为0.902,RMSE值为1.583mg·kg-1,RPD值为3.198,具有最佳的预测土壤铵态氮含量的能力。
为了进一步观察土壤铵态氮的模型反演效果,选择采用CARS-SAA筛选方法建立的预测效果最好的模型为例,绘制模型的土壤铵态氮验证集的实测值与预测值的1∶1散点图。如图8、图9所示。从图8、图9可以看出,CARS-SAA-PLSR-RF更接近1∶1线,模型预测精度最高。综上所述,CARS-SAA是一种有效的高光谱数据特征变量筛选方法,利用该方法结合PLSR-RF可以准确预测土壤铵态氮含量,同时提高检测的实时性。
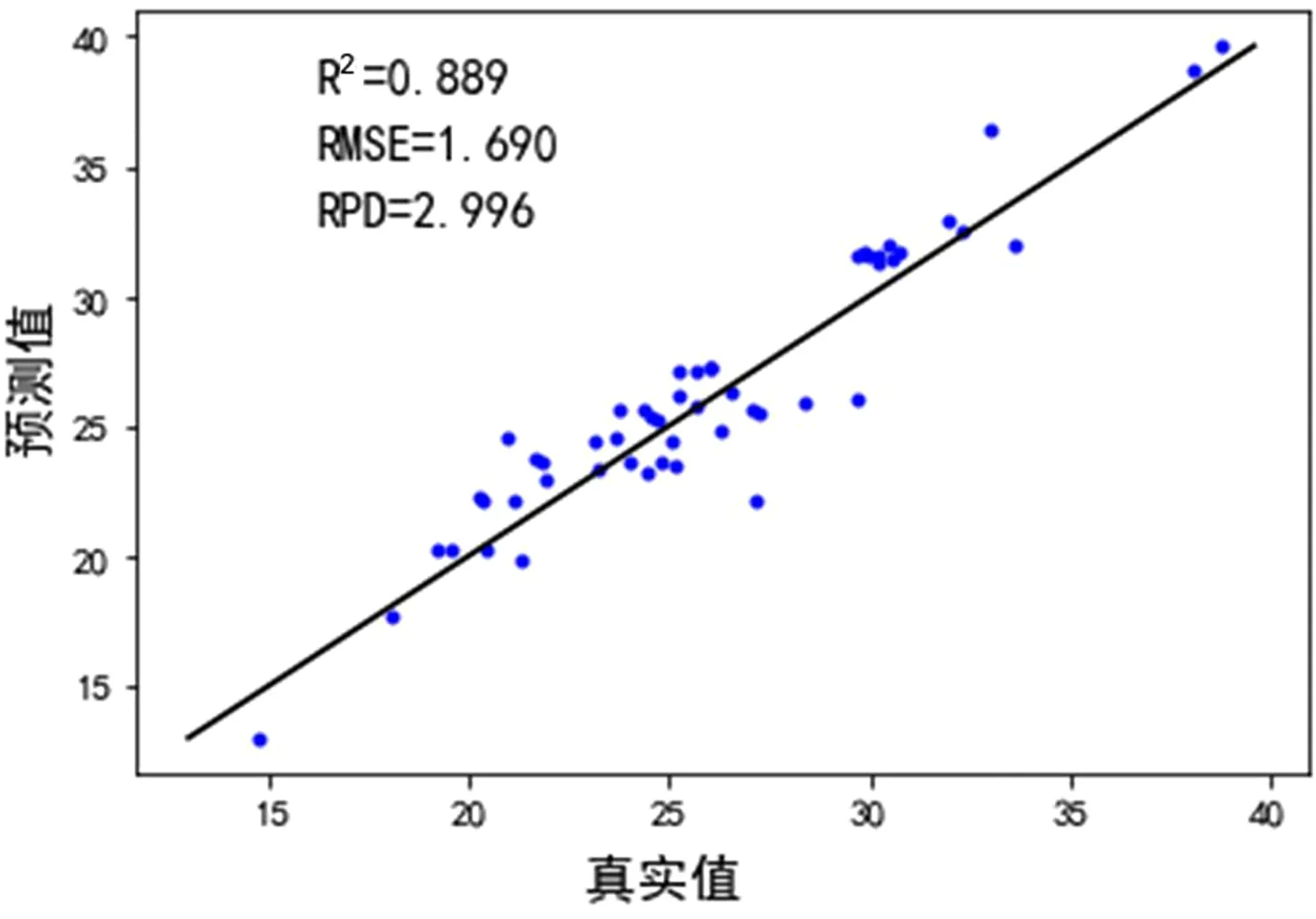
图8 CARS-SAA-RF-PLSR散点图

图9 CARS-SAA-PLSR-RF散点图
3 结论
以内蒙古自治区巴彦淖尔市五原县的河套灌区粮食生产基地为实验研究区,以70个土壤样本的铵态氮含量为研究对象,使用实测的高光谱土壤数据和土壤铵态氮含量,经预处理后采用CARS、SAA和CARS-SAA方法对土壤高光谱全波长进行特征变量的筛选,并分别构建PLSR-RF和RF-PLSR模型,研究表明,在预测精度上基于CARA-SAA建立的模型与单个筛选方法相比较有着更优表现,能够得出CARS可使得变量集更少存在共线性问题,并能够保留强信息变量,但是CARS筛选后,仍有干扰或无关信息变量存在的可能性,因而在预测精度上模型仍具有提高的空间。对CARS筛选后获取的变量,进行SAA筛选,在预测精度得以保证的前提下,缩减变量数,并有效避免变量筛选过程中的计算量大、复杂度较高且运算时间长的问题。结合PLSR-RF建立的模型,在预测效果上有着良好表现,故而能够认定CARS-SAA是一种有效的高光谱数据特征变量筛选方法,CARS-SAA-PLSR-RF模型可以快速有效地对河套灌区土壤铵态氮含量进行预测,为高光谱在线检测提供了理论依据,也为后续对土壤及其他成分含量的分析带来新的研究思路和方法。
