基于超图神经网络以多角度概念特征融合的概念先决学习
2023-02-04杜洪霞
张 鹏,杜洪霞,代 劲
(重庆邮电大学 软件工程学院 智能信息技术与服务创新实验室,重庆 400065)
0 引言
中国大学MOOC(1)https://www.icourse163.org/、coursera(2)https://www.coursera.org/等国内外在线教育平台的蓬勃发展,为学习者积累了海量资源。为每位学习者在庞大的学习资源中规划精准合理、个性有效的学习路径,是自适应学习的重要研究内容之一,概念先决关系识别在其中扮演了关键角色。概念先决关系(Concept Prerequisite Learning)是概念之间的前后依赖关系,在确立后可被广泛应用于课程推荐[1-2]、学习路径规划、学习资源排序[3]、知识追踪[4-5]等下游任务。现有概念先决关系研究主要基于特征提取和基于二元图结构两类,其中基于特征提取的方法[6]依赖于手工制作特征,在文档结构规范的教科书[7]文档资源中表现良好,但缺乏泛化性,计算时间成本高。随着图神经网络的发展,更多工作针对概念,以及概念隶属的文档资源来建模二元图结构[8-9],但难以表征概念和文档资源对象间的复杂关系。在概念先决关系识别中,概念与文档资源具有多对多关系,概念在文档中的相关概念,以及概念与其相似概念呈现聚类现象等复杂关系,但二元图结构对以上的复杂关系表达能力有限。
本文提出超图概念先决关系学习HyperCPRL(Hypergraph Concept Prerequisite Relation Learning),首次利用超图编码高阶相关性的能力从三个角度构建不同语义的超图结构,以满足上文提出的概念、文档资源对象之间的关联关系,在不使用特征值计算的情况下利用超图卷积学习概念、文档资源潜在表征进行概念特征融合,通过实验验证,取得了较好的效果。
1 相关工作
1.1 概念先决关系学习
现有的概念先决关系学习可以分为三种类型: 基于特征计算,基于二元图神经网络和其他方法。Liang等人[10]以概念引用参考距离计算先决关系,随后Pan等人[6]扩展了7组特征值利用二分类模型预测。此外,概念在文档资源中首次出现的位置、前后关系[11],以及概念语义相关性度量[12]等特征被用于概念先决关系识别。基于特征计算的方法,广泛依赖于维基百科提供的特征信息,如链接、引用、分类、点击流等设计分类器特征[13-15]。维基百科作为外部资源在概念先决关系特征计算中发挥了一定作用,但存在计算时间成本高、无法涵盖所有概念、概念实体表达存在歧义等问题。总体而言,基于特征计算的方法依赖于手工特征提取或特征规则计算,但受限于文档资源结构,导致其泛化性能不佳。
基于二元图神经网络的方法,Li等人[16-19]利用图自编码器(Graph Autoencoder, GAE)、变分图自编码器(Variational Graph Autoencoder, VGAE)重构概念邻接矩阵进行链路预测。Zhang等人[20]提出的MHAVGAE模型结合多头注意力机制与VGAE预测概念链接关系。Jia等人[8]提出的CPRL构建文档-概念异构图,利用关系图卷积网络(Relational Graph Convolutional Networks, RGCN)学习节点表征,并结合概念特征值联合训练。ConLearn[9]利用概念先决关系和两跳先决关系(3)DSA和ML数据集明确标注了正负概念先决关系,经检测,两跳关系存疑。构造有向概念先决关系图,使用门控图神经网络(Gated Graph Neural Network, GGNN)学习节点表征。基于二元图关系结构的模型难以表征问题核心对象,即概念、文档资源两者之间的复杂关系。
其他方法包括,PREREQ[21]利用Pairwise-Link LDA主题模型训练文档资源的先后顺序关系,从而得到文档资源中概念的潜在表征,Liu等人[22]提出的方法利用双曲空间表征概念嵌入以保留概念的层次关系。Manrique等[23]则依赖于知识图谱剪枝提取概念先决关系。
1.2 超图神经网络
二元图结构(Graph)可以有效表征成对关系结构[24-27],包括基于空域[28-29]和基于频域[30-32]的图神经网络。现实世界中的对象关系除了简单的二元关系,还存在更复杂的非成对关系。超图的超边是任意结点数量的集合,在数据建模上更加灵活,目前已经成功应用于多个领域[33-36]。超图神经网络以学习结点之间的高阶依赖关系,大致可分为以超图拉普拉斯矩阵为核心的谱分析超图方法和以神经网络为模型结构的神经网络超图方法。对超图结构的学习,关注于展开式,如星式展开和团式展开[37-38],以及非展开式学习[39-40]。
2 问题定义
本节先给出概念先决关系问题定义和超图定义,表1总结了本文常用符号。

表1 本文所使用的符号
问题定义: 给定文档资源集合D、概念集合C以及部分已知标注概念对P,利用超图构建D与C对象之间的高阶拓扑关系,学习函数f=C2→{0,1},预测概念对
超图定义: 超图(Hypergraph)是一种广义上的图结构,其边可以与任意数量的结点连接,称之为超边(Hyperedge)。超图g=(V,E,W)。W∈|E|×|E|是对角矩阵,表示超边权重。超图g的拓扑结构使用关联矩阵H∈|V|×|E|表示,如式(1)所示。

(1)
∀v∈V,其度表示为d(v)=∑e∈Ew(e)h(v,e),而∀e∈E,超边度表示为δ(e)=∑v∈Vh(v,e),结点和超边度矩阵为Dv∈|V|×|V|和De∈|E|×|E|。
3 HyperCPRL模型
3.1 模型基本思想
HyperCPRL模型由超图卷积模块、概念融合模块、孪生网络模块组成。模型使用基于推理数据集预训练,并采用对比学习实现的SimCSE[41]得到概念嵌入X∈|N|×|d|,以减少原始BERT生成词嵌入具有的各向异性带来的影响,d为概念词向量分布维度。超图卷积模块以集合D、C构造多角度超图结构,包括概念结构超图gstruct、概念语义距离超图gsemantic和文档-概念超图gdoc,建模文档资源、概念对象两两之间的高阶关系。概念融合模块融合多角度超图生成的概念潜在表征,使用自注意力机制在概念全域下进一步挖掘概念先决关系。孪生网络模块预测概念先决关系和文档资源先决关系,实现联合训练。HyperCPRL模型基本思想如图1所示。
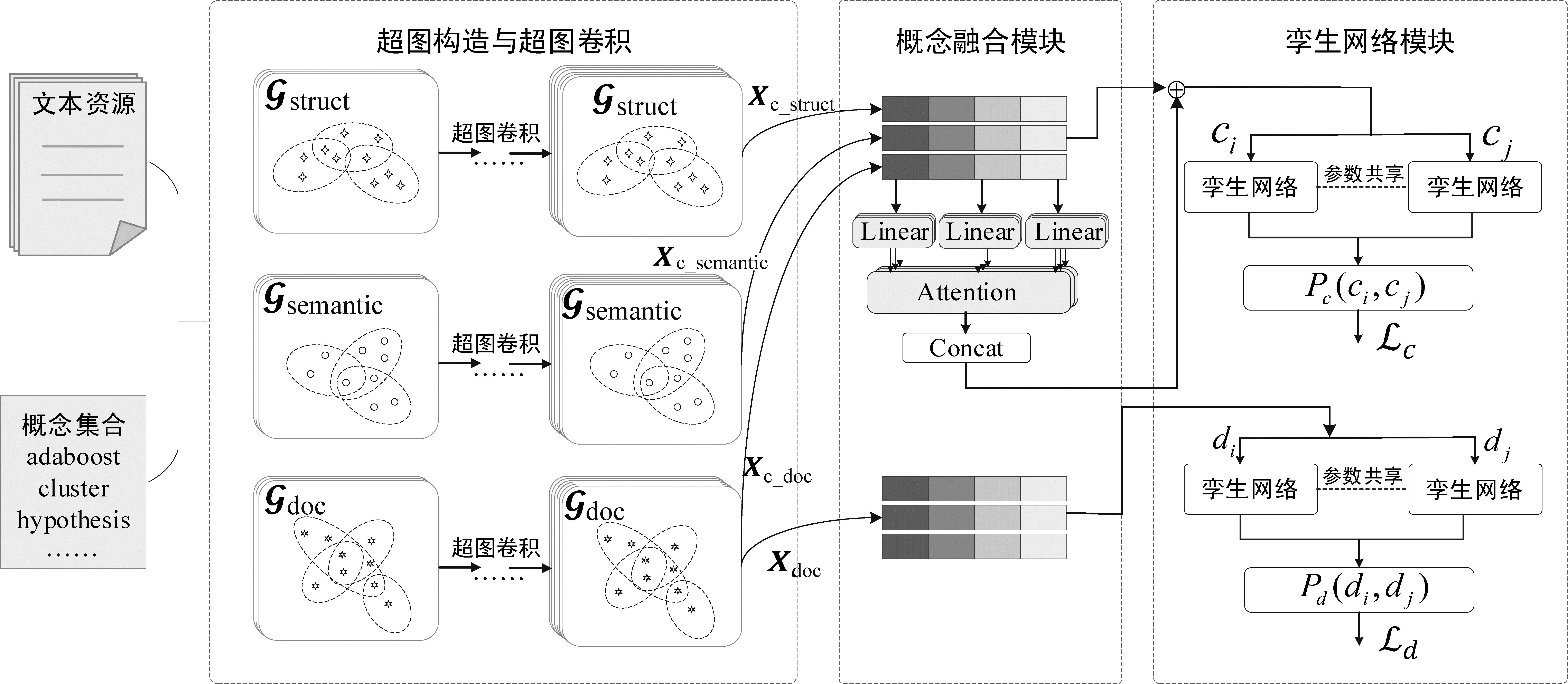
图1 HyperCPRL模型架构
3.2 超图构造与卷积模块
HyperCPRL不依赖于外部资源提供的基础信息,而充分利用给定的概念标注和包含概念的文档集合,分析概念和文档之间的多重关系,基于多语义角度建模,以挖掘不同语义角度中的共性和特性,实现信息互补,以改进单一角度下学习不充分的局限。并且,HyperCPRL利用超图结构进一步学习多语义角度下的高阶复杂关联关系。算法1展示了三个超图关联矩阵生成的伪代码。
3.2.1 概念结构超图(gstruct)
逐点互信息(PMI)被广泛应用于文本中两个词的关联度量[25,42],HyperCPRL基于PMI计算D中概念之间的结构关联度得到概念结构矩阵STM∈R|N|×|N|,STM[i][j]=PMI(i,j),如式(2)~式(4)所示。
(2)
(3)
(4)
其中,#W(i,j)是包含概念ci和cj的滑动窗口数量,#W(i)是包含ci的滑动窗口数量,#W是D中滑动窗口的总数。当概念ci对应的集合{(STM[i][l],l)|l=0,…,N-1,i≠l,STM[i][l]>0}不为空集时,以ci作为超边,集合作为其连接的结点。

算法1: 超图构造输入: D, C, X输出: Hstruct, Hsemantic,Hdoc1: Begin2: Hstruct←[], Hsemantic←[], Hdoc ←[] //1.构造结构超图Gstruct3: 由式(2)计算STM矩阵4: for ci∈C do5: Ti={(STM[i][l],l)|l=0,…,N-1,i≠l, STM[i][l]>0}且Ti≠⌀6: for p1∈Ti do7: HTstruct[i][p1[1]]=p1[0] 8: end for9: end for //2.构造语义距离超图Gsemantic10: 由ISOMAP[42]计算概念测地线距离 DX=dist(X) //词嵌入欧式距离 DX=sorted(DX) //每行从小到大排序 DFloydX=floyd(DX, η) //Floyd更新最短距离11: SEM=exp-DFloydXμ 12: for ci∈C do13: Ei={(SEM[i][l],l)|l=0,…,N-1,i≠l, SEM[i][l]>0.5}且Ei≠⌀14: for p2∈Ei do 15: HTsemantic[i][p2[1]]=p2[0] 16: end for17: end for //3.构造文档-概念超图Gdoc18: DCM=tfidf(D,C)19: for di∈D do20: Di={(DCM[i][l],l)|l=0,…,N-1,i≠l, DCM[i][l]>0}且Di≠⌀21: for p3∈Di do22: HTdoc[i][p3[1]]= p3[0] 23: end for24: end for25: return Hstruct, Hsemantic,Hdoc26: End
3.2.2 概念语义距离超图(gsemantic)
以往工作通过计算概念词嵌入余弦相似度[6]衡量概念之间的语义相似度,本文提出概念语义距离超图,利用等距特征映射(ISOMAP)[43]计算流形测地线距离衡量概念之间的语义相似度。由概念词嵌入X计算概念成对欧氏距离DX,选择概念的η个近邻点构成无向有权图,通过Floyd算法更新概念之间的测地距离得到DFloydX,式(5)将概念距离转换为概念语义相似度矩阵SEM∈N×N,η和μ为超参数。概念ci对应的集合{(SEM[i][l],l)|l=0,…,N-1,i≠l, SEM[i][l]>0.5}不为空时,以ci作为超边,集合作为其连接的结点。
3.2.3 文档-概念超图(gdoc)
gdoc是由概念隶属于文档的关系构建得到,以编码概念与文档资源之间的隶属关系。由D计算概念的术语频率逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF),得到文档-概念矩阵DCM∈M×N,以文档资源di作为超边,di包含的概念集合作为其连接的结点。
3.2.4 超图卷积
HyperCPRL利用超图神经网络(HGNN)[37]学习结点表征。Hstruct、Hsemantic和Hdoc与概念嵌入X分别送入gstruct、gsemantic、gdoc,按照式(6)进行超图卷积。
X(l)∈N×d(l)是第l层的结点表征,X(0)=X,σ是非线性激活函数,Φ∈d(l)×d(l+1)是可学习的转移矩阵,W是超边的权重矩阵,默认为单位矩阵。
3.3 概念融合模块
基于多语义角度超图卷积学习的概念潜在表征,在概念先决关系标签的监督学习下通过融合操作提取各语义角度特征实现特征互补,本文采用三种方式进行特征融合,以提取最有利于下游分类任务的概念特征,分别是取最大值、平均值、加和,融合操作F∈{Max,Avg,Sum},XF∈N×d′。
基于超图的表征学习具有结构下的局部性特征,本文进一步使用多头自注意力机制捕获概念全域下概念与概念之间的依赖关系,并与XF做残差连接。
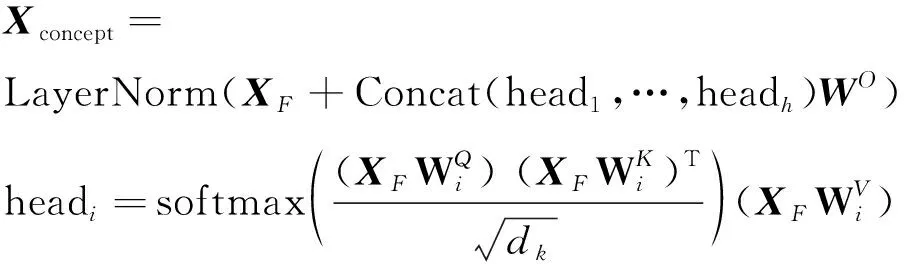
(8)
3.4 孪生网络模块
权重共享的孪生网络(Siamese Network)[44]可以有效学习两个对象的关联关系。融合后的概念表征Xconcept和Xdoc分别送入两个孪生网络,得到的成对概念表征(sci,scj)和文档表征(sdi,sdj)拼接后计算先决关系预测概率。
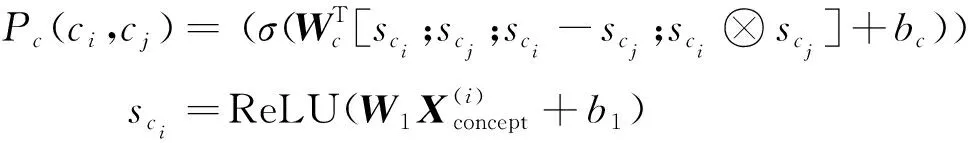
(9)
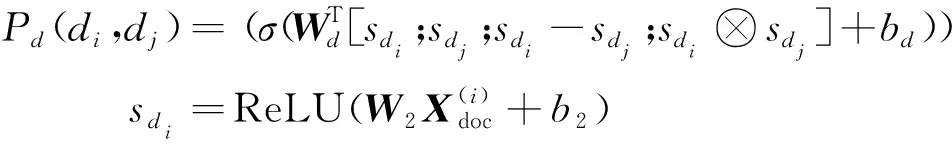
(10)
其中,σ是Sigmoid函数,-和⊗分别是各元素的减法和乘法运算符,[·;·]是向量拼接操作。
+(1-ycij)log(1-Pc(ci,cj))]
(11)
+(1-ydij)log(1-Pd(di,dj))]
(12)
3.5 计算复杂度分析
HyperCPRL超图构建过程中的时间复杂度主要由概念结构超图的PMI和概念语义距离超图的流形距离产生。D的滑动窗口总数#W计算概念集合C的概念频率的时间复杂度为O(#WN),其中#W>>M。ISOMAP流形距离计算基于Floyd算法更新最短距离,时间复杂度为O(N3)。
4 实验与分析
4.1 数据集与评测指标
实验选取DSA(4)http://keg.cs.tsinghua.edu.cn/jietang/software/acl17-prerequisite-relation.rar、ML(5)http://keg.cs.tsinghua.edu.cn/jietang/software/acl17-prerequisite-relation.rar、University Course(6)https://github.com/harrylclc/eaai17-cpr-recover(以下简称UST)、Lecture(7)https://github.com/Yale-LILY/LectureBank数据集进行分析。ML和DSA提供了概念的同义词概念,对UST和Lecture数据集提供的概念在课程描述中找出类似的同义词概念。删除未出现在D中的概念和未包含概念的文档。ML、DSA以每个章节中的视频先后顺序标注文档先决关系,章节中前一个视频文档是后续所有视频文档的先决文档,Lecture由文档的TFIDF特征计算余弦相似度,以相似度值大于0.8作为文档边权值。最终统计情况如表2所示。
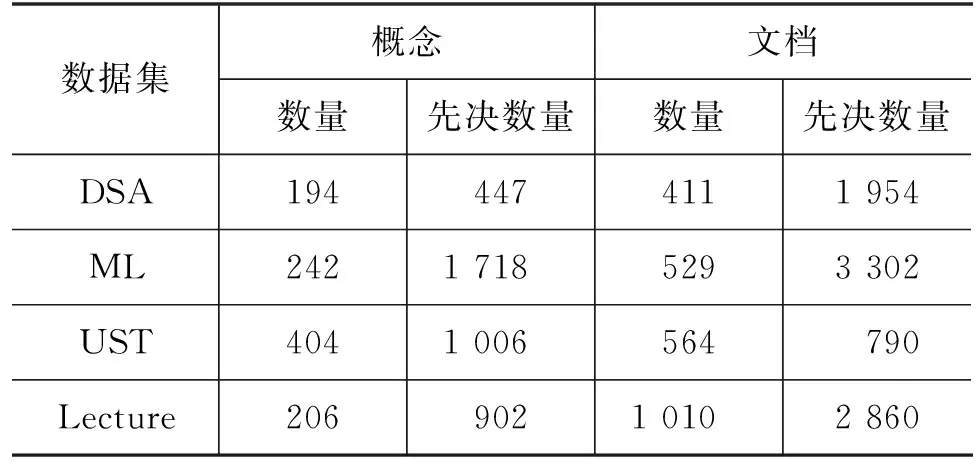
表2 数据集统计详情

4.2 基准方法与实验设置
HyperCPRL与基于特征提取的二分类方法[6],包括朴素贝叶斯(NB)、线性核支持向量机(SVM)、逻辑回归(LR)和随机森林(RF),与基于二元图神经网络的以下方法进行对比:
(1)GAE和VGAE[16]: 重构概念邻接矩阵进行链路预测。
(2)ConLearn[9]: 基于上下文语义,使用GGNN预测概念先决关系。手动实现该方法,使用Hugging face(8)https://huggingface.co/的Masked LM任务预训练数据集生成概念词嵌入。
(3)MHAVGAE[20]: 基于多头注意力机制并融合文档特征的VGAE链路预测。
(4)gcnCPRL: HyperCPRL的同构图变体,以二元图替换超图,即实现Gstruct、Gsemantic和Gdoc,邻接矩阵Astruct(i,j)=PMI(i,j),Asemantic(i,j)=SEM[i][j],Adoc(i,j)=tfidf(i,j),使用GCN[32]编码图结构,文档资源嵌入采用Doc2Vec[45]生成。
(5)rgcnCPRL: HyperCPRL的异构图变体,以异构图替换超图,包含概念-概念边关系R(ci,cj)=PMI(i,j)以及R(ci,cj)=SEM[i][j],文档-概念边关系R(di,cj)=tfidf(i,j),文档-文档边关系R(di,dj)是文档TFIDF特征余弦相似度大于0.8的值,共4种边类型。使用RGCN[46](Relational Graph Convolutional Networks)编码图结构。
概念先决负样本是正样本的2.5倍, DSA和ML从已有负样本中随机采样,UST和Lecture由概念集合随机生成不相关的负样本。随机生成文档先决关系负样本,数量与正样本相等。二分类方法数据集划分为70%、30%的训练集和测试集,其他方法正、负样本分别划分60%,10%,30%再合并,训练过程中对概念先决正样本过采样,使其与负样本平衡。其中,ConLearn模型按照原论文要求生成负样本,即概念先决正样本的逆关系和随机抽取不相关概念对生成。所有实验基于Pytorch框架实现,使用Adam优化器,学习率lr为0.001,实验中其他超参数设置如表3所示。
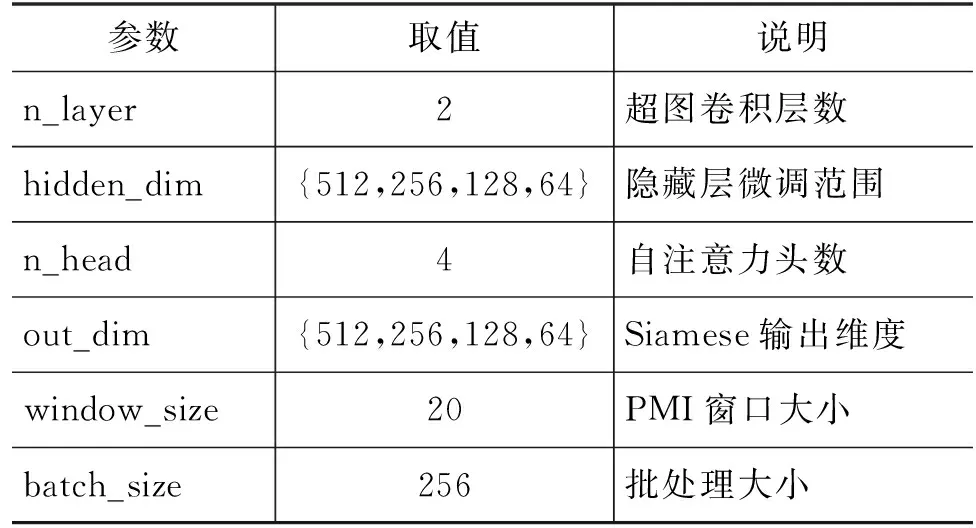
表3 超参数设置
4.3 特征融合及参数选择
本文首先探究HyperCPRL构建的不同语义下的超图结构选择概念特征融合操作和融合期间,以及概念语义距离超图构建中超参数η和μ的取值对实验性能的影响。
4.3.1 融合操作选择
图2展示了HyperCPRL选择最大值、平均值、加和三种特征融合操作的实验结果,可以看出,在同一参数设置下,所有数据集最大值融合操作均优于其他选择,将保留多种语义超图结构下最突出的概念潜在特征。
4.3.2 融合期间选择
HyperCPRL的融合操作可以选择在超图卷积期间或者卷积后执行,实验结果如表4所示,卷积后的特征融合操作更能准确抓取不同语义超图结构的最大特征。
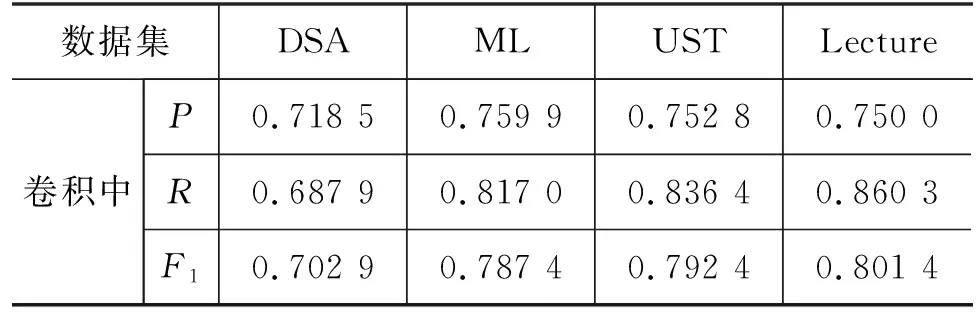
表4 不同融合期间的实验结果
4.3.3η和μ对实验的影响
HyperCPRL构建概念语义距离超图,超参数η和μ取值的F1值结果如图3所示。因此,实验对DSA、ML、UST和Lecture分别选择η/μ的值为{10/10,10/10,15/20,15/10}。
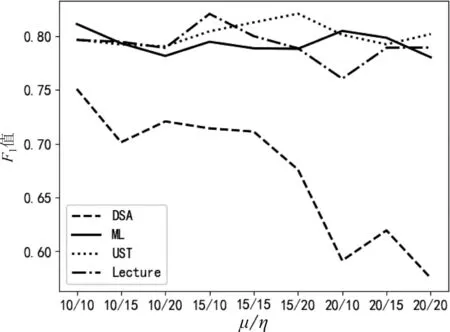
图3 不同超参数η和μ取值的F1值
4.4 基准实验对比及分析
所有基准实验均按照超参数范围微调提供最佳结果,比较结果见表5,从实验结果可知: ①HyperCPRL优于所有二分类方法,F1值分别提高6.78%、13.86%、8.25%以及21.58%。二分类方法中,RF的分类效果普遍优于其他分类器。②HyperCPRL与基于二元图神经网络方法比较,在DSA、ML和UST三个数据集上均表现优异,F1值相较于最好的方法分别提高0.76%、0.05%、1.97%。ConLearn在Lecture数据集上取得最佳结果,F1值优于HyperCPRL 5.23%。HyperCPRL在四个数据集上的ACC均优于其他方法,提升范围为0.56%~8.03%。③GAE和VGAE只考虑概念之间的先决关系重构邻接矩阵,性能弱于MHAVGAE。然而,基于重构图邻接矩阵均存在召回率R值高,而精确率P值低的现象。④HyperCPRL在所有数据集上的表现均优于其同构图变体gcnCPRL和异构图变体rgcnCPRL。ACC和F1值分别平均提高0.98%和1.78%,且异构图变体性能整体优于同构图变体,说明基于超图的多语义角度融合相较于二元图关系、异构图结构能提取更多有效特征。⑤ConLearn在ML上与HyperCPRL表现接近,在Lecture数据集上优于HyperCPRL。但是其丢弃了数据集原标注概念负样本,而两跳概念先决关系与原标注负样本存在冲突。

表5 模型对比实验结果(粗体: 最佳,下划线: 次之) (单位: %)
4.5 多角度特征融合对比实验及分析
ML和UST数据集在不同语义视角下的对比实验结果,以及相较于HyperCPRL结果的变化值如表6、表7所示。任意两个角度的概念特征融合时,结构关系+语义距离角度的特征融合在各指标下降最为明显,而结构关系+文档-概念隶属关系与语义距离+文档-概念隶属关系表现较为接近。而单一语义角度下,文档-概念隶属关系角度下降幅度较小。因此,文档-概念隶属关系角度为概念先决关系识别提供了更多有效信息,因为文档-概念隶属关系语义超图不仅提供了相关概念在同一文档中的关联关系,还提供了文档先后关系中隐含的概念先决关系。此外,概念在文档中的结构关系对概念先决关系识别相较于概念语义相似度更胜一筹。
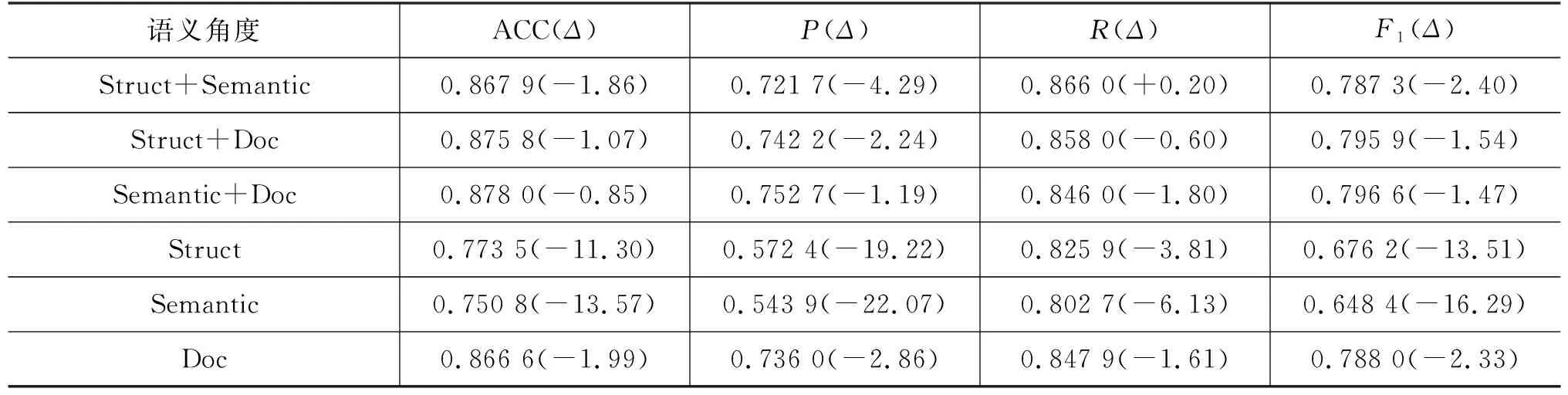
表6 ML数据集不同语义角度下的对比结果,(Δ)表示相较于HyperCPRL的变化值 (单位: %)
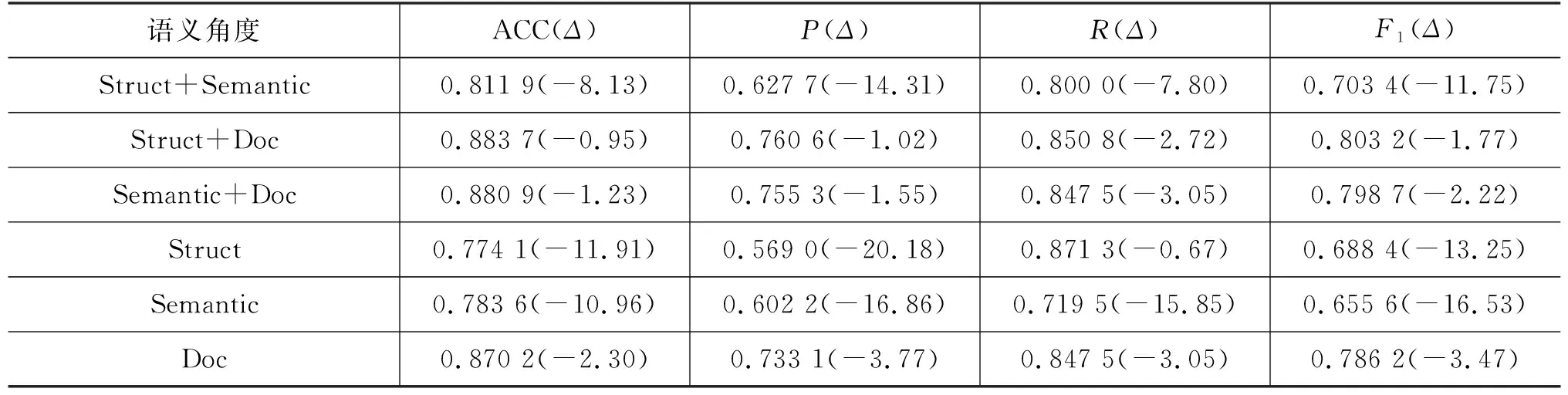
表7 UST数据集不同语义角度下的对比结果,(Δ)表示相较于HyperCPRL的变化值 (单位: %)
4.6 概念余弦相似度对比
将gsemantic中的概念语义相似度矩阵SEM替换为由概念嵌入的余弦相似度计算得到,以此对比以流形测地线距离作为语义相似度之间的差异。表8展示了与HyperCPRL各指标的比较结果。余弦相似度衡量概念语义相似度在所有数据集上的表现均弱于以流形测地距离计算的语义相似度。当数据具有高维特征时,测地距离更能衡量数据之间的差异。
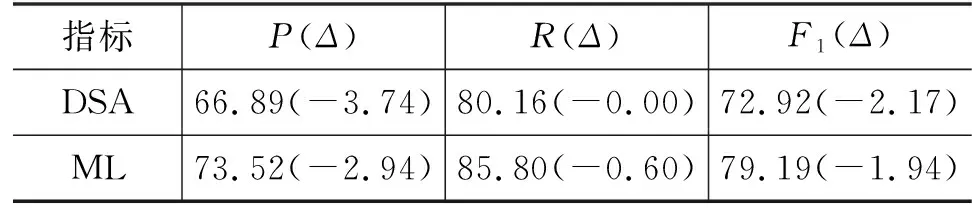
表8 余弦相似度性能表现,Δ表示变化比率 (单位: %)
4.7 案例分析
依据概念先决关系构建概念先决有向图,当概念结点的出度和入度均小于或等于平均度时,此类低度概念结点与其他概念结点交互信息较少。由表9统计结果可知,低度概念数量占概念总数50%左右,且UST概念先决有向图更加稀疏,由此加剧了概念先决关系识别的难度。HyperCPRL与基准实验结果比较的真阳性样本(TPP)实例如表10所示,实例中的概念均为低度概念。
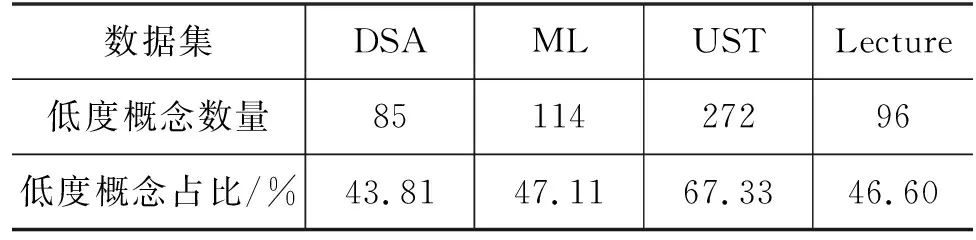
表9 数据集低度概念数量及其占比

表10 与基准实验比较的真阳性样本
为验证HyperCPRL对包含低度概念的样本先决关系识别能力更强,本文首先统计了gcnCPRL、rgcnCPRL、ConLearn、HyperCPRL四种方法对测试数据集执行结果中包含低度概念样本的错误识别数量相对于错误样本总数的比例,如图4所示。其中,ML、UST、Lecture数据集中,各个方法识别包含低度概念样本的错误占比均超过50%,DSA则接近50%。说明低度概念是导致概念先决关系识别错误的主要因素之一。
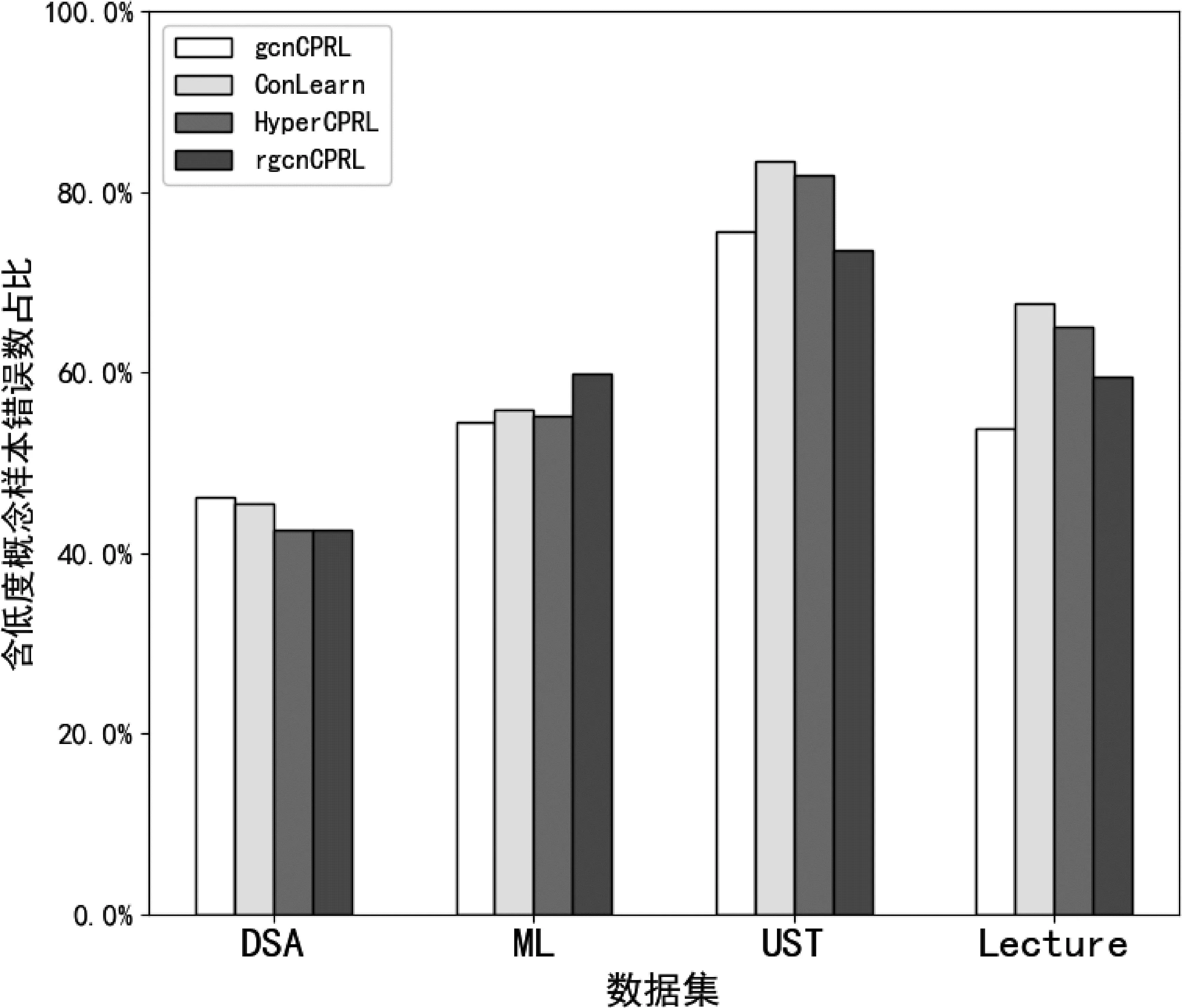
图4 数据集中含低度概念样本错误数占总错误数比例
图5进一步展示了上述四种方法中,包含低度概念样本的错误数/测试样本总数的结果,HyperCPRL在所有数据集中具有更低的错误率,而ConLearn模型训练方式对先决关系学习存在偏差导致较高的错误占比,由此可知,本文提出的方法,对概念先决关系有向图中,概念节点入度和出度均小于或等于平均度的低度概念,相关的先决关系识别更加准确,因为HyperCPRL能够利用多语义角度超图结构提取更加丰富的特征,由此提高了模型的准确度。
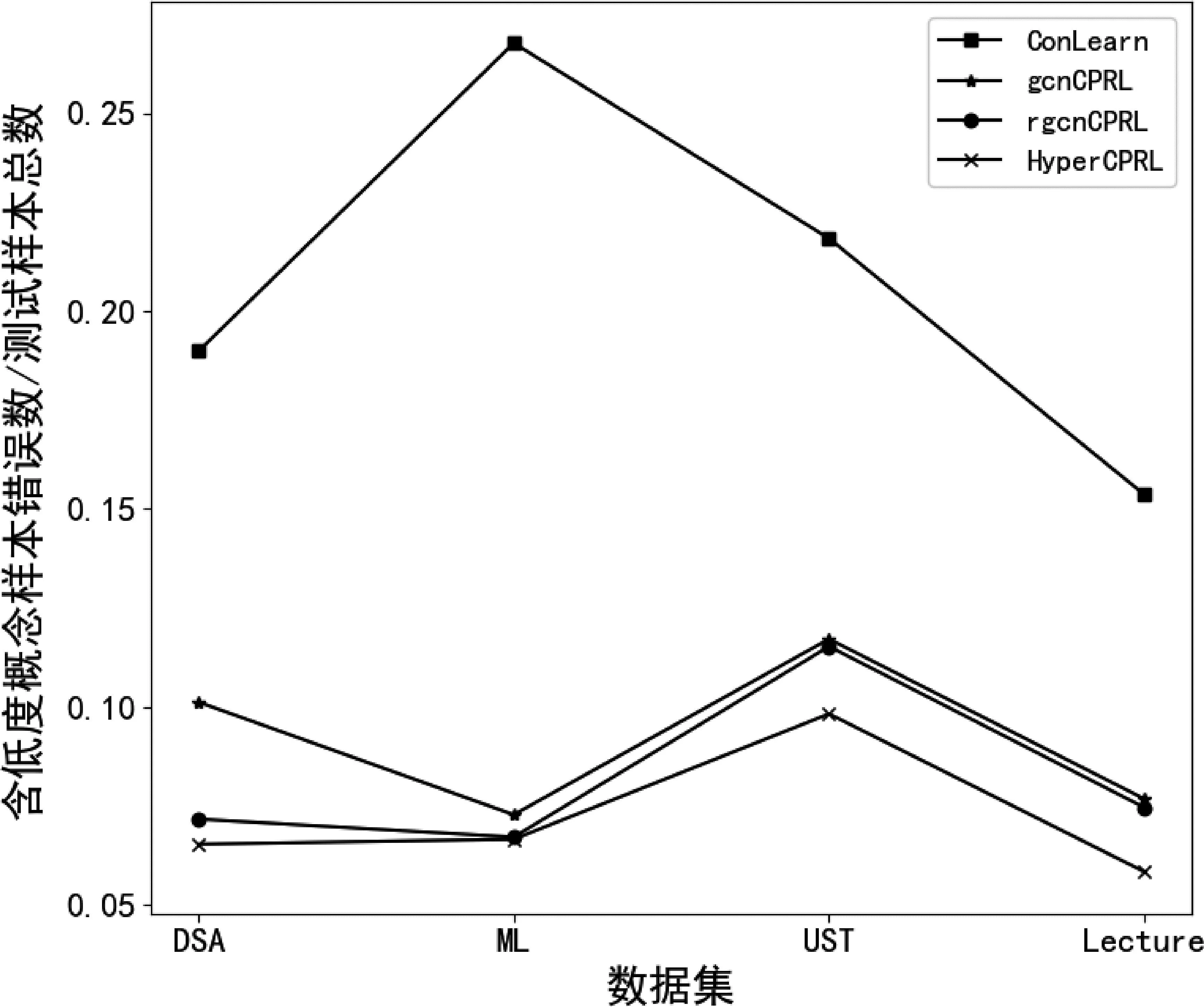
图5 数据集中含低度概念样本错误数占测试样本的比例
5 结论和展望
HyperCPRL利用超图建模概念、文档对象的复杂、高阶结构特征,从三个角度构造了三个不同表达能力的超图结构,与基准方法相比,取得了较好的效果。本文只应用了最基础的GCN、RGCN、HGNN学习图结构的结点表征,并且在构建超图时并未利用已标注的概念先决条件关系。本文首次将超图结构应用于概念、文档资源对象之间的关系建模,然而,如何挖掘对象关系,构建更强大的超图结构以学习对象的潜在表征,以及采用其他更有效的融合方法融合不同语义角度特征都需要进一步探索。
