一种基于预训练模型的藏文分词方法
2023-02-04色差甲桑杰端珠才让加慈祯嘉措
色差甲,桑杰端珠,才让加,慈祯嘉措
(1. 省部共建藏语智能信息处理及应用国家重点实验室,青海 西宁 810008;2. 青海省藏文信息处理工程研究中心,青海 西宁 810008)
0 引言
自动分词是自然语言信息处理领域中基础研究课题之一,是在词法分词、句法分析、信息提取、机器翻译、自然语言理解及生成等下游任务中需要解决的首要问题。随着信息技术的不断发展,藏文分词研究已历经20余年(2002年陈玉忠等人提出的藏文自动分词方案[1]是较早的一篇研究工作),分词技术取得了长足的进步,也是目前藏文信息处理领域中比较成熟的研究任务之一。
藏文分词研究可分为三个阶段: 第一阶段使用规则方法,根据藏文含有丰富的格助词、接续词、正字知识及基础词典等先验知识的支撑下提出藏文分词方法,在藏文分词精度方面具有较高的实用价值[1-4];第二阶段使用统计和规则相结合的方法,主要利用条件随机场、最大熵模型及隐马尔可夫模型等统计模型来进行综合切分,并在此基础上,针对藏文紧缩格和未登录词等特殊问题利用规则进行进一步处理[5-8];第三阶段使用深度学习方法,也是目前主流的藏文分词方法,最常用的是BiLSTM和CRF相结合的方法,其中通过添加一个特殊标签有效解决了紧缩格的识别问题,而不需单独进行处理[9-10]。
通过对现有藏文分词方法进行对比并分析后发现,对未登录词无法有效识别与语料领域受限问题的处理技术有待进一步提高。因此,本文针对这个问题,首先收集、整理较大规模的藏文文本语料;然后借鉴近期很受欢迎的预训练语言模型,对藏文也预训练一个藏文语言模型;其次,利用人工标注的藏文分词语料在该模型上进行微调;最后,实验结果表明,与基线模型相比,本文方法能够缓解语料领域受限及未登录词问题,特别是对含有较多音译词、人名和地名词等的语料上F1值能够提高2.3到6个百分点。同时,本方法在第十八届全国少数民族语言文字信息处理学术研讨会暨第二届少数民族语言分词技术评测中荣获藏文分词的第一名。
1 基于预训练的藏文分词方法
自2018年BERT[11]模型问世至今,大量的研究工作表明,在大规模无标注文本语料上进行预训练的语言模型,不仅能够学习到词法、句法以及语义等通用语言表征,而且还能够缓解下游任务对数据规模不足和模型重新训练等问题。随着算力的发展、深层模型的出现以及训练技能的不断提高,预训练体系结构已然从浅层发展到了深层,已经成为目前比较主流的训练范式[12-13]。
本文把藏文分词模型的训练分为两个阶段: 第一阶段利用大规模藏文文本语料来预训练语言模型;第二阶段利用藏文分词语料来进一步训练该模型,使得该语言模型能够处理藏文分词任务。其步骤如图1所示。

图1 藏文分词模型的训练流程
1.1 基于UniLM的藏文预训练语言模型
UniLM[14]是微软提出的统一语言模型,该模型有效结合了语义理解和生成模型,而且结构简约,即直接复用了BERT的结构。该模型通过一个遮蔽机制(掩码矩阵)有效融合了单向、双向以及序列到序列等三种语言模型。该模型的架构如图2所示。

图2 UniLM的模型架构
从图2中可见,UniLM的输入方式与BERT一样,包括词向量、位置向量、片段向量,其骨架构由L层Transformer的编码器组成,其中对第1层的计算如式(1)、式(2)所示。
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(1)
Headi=Attentions(Qi,KiVi)
(2)

其中每个W都表示模型的权重;Headh表示多头注意力机制中的第h个头;M是自注意力机制的掩码矩阵,主要用于遮蔽一些未能关注的信息;dk表示隐藏层的维度。
本文借鉴UniLM模型,并通过遮蔽机制充分利用现有的藏文文本语料。换言之,将同一个句子通过不同数据方式或不同预测任务来多次利用。显然,本文中使用单向、双向以及序列到序列三种不同预测任务,不仅能提高文本语料的使用率,而且也能提高模型的性能及稳定性,同时能够防止出现过拟合现象。
1.2 基于UniLM的藏文预训练语言模型

在预训练藏文语言模型过程中,数据的预处理方式与UniLM模型的处理方式几乎一样。其中单向和双向语言模型的数据预处理方式与该模型保持一致,二者的主要区别在于序列到序列语言模型的数据预处理方式,借鉴了BART[15]模型中的数据预处理方法,并结合藏文丰富的虚词特征、动词时态等信息对句子进行加噪,包括删除和替换等操作[16],从而使每个输入序列的左半部分是加噪后的句子,而右半部分是该句子的原句。另外,模型除了要处理上述的任务之外,还要处理句子次序预测(SOP)任务,这与ALBERT[17]模型中的SOP任务一样,而未使用BERT模型中的NSP任务[11]。
在模型训练过程中,单向、双向和序列到序列等三者目标任务是交替训练的。与其他预训练语言模型相比,该模型有如下两个优点: 一是用同一个模型即可训练多种完全不同的目标任务;二是正因为同一个模型中有不同的多个目标任务,使得学习出来的模型更具泛化能力。
2 实验结果及分析
2.1 藏文分词的标签使用方法
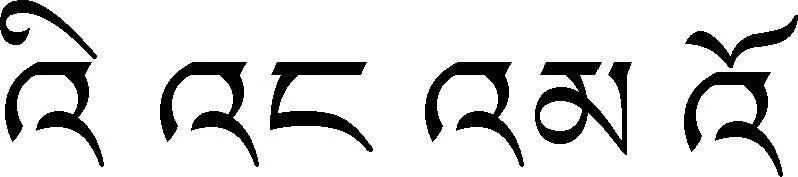

图3 藏文分词标签的使用示例
其中,标签“BEMS”跟常见的一致,分别表示开始、结束、中间、单独等含义,然而“N”表示该词的词尾音节中包含紧缩格(或),需要进一步切分,“C”表示该虚词(之一)不能切分,且需要进行还原处理。
2.2 实验参数设置
本文的基线模型有两个,分别为: 基于条件随机场的传统方法TIP-LAS[7],该方法已开源,可自行进行训练和测试(1)源码地址: https://github.com/liyc7711/tip-las;另一个是基于神经网络的方法BiLSTM-CRF[9-10],本文复现了该方法。然而,基于预训练的UniLM-CRF模型作为主方法。模型参数设置情况如表1所示。
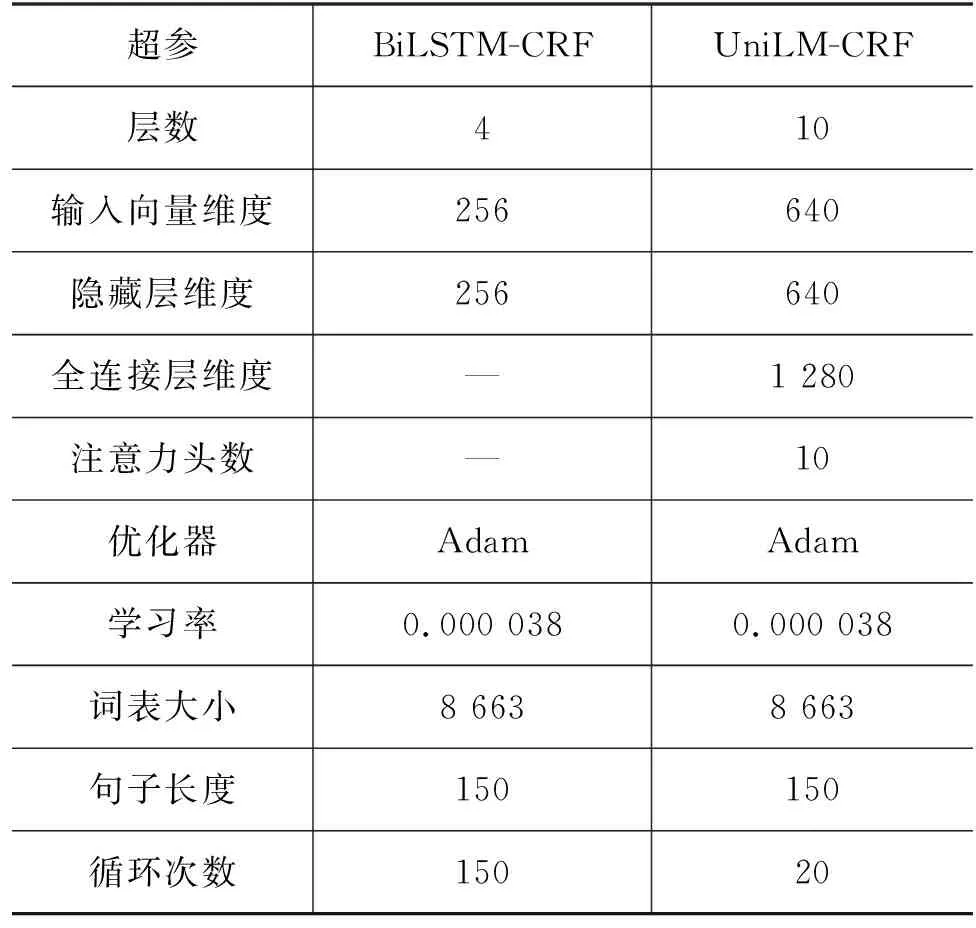
表1 参数设置情况
从表1中可知,两个模型中所使用的词表大小是一样的,摘自于《藏文规范音节频率词典》[18],是从大规模的藏文文本中统计和整理的,其中只含有具有实际意义的藏文音节,以及部分梵文。在此基础上添加了一些特殊符号,以用于表示句子的开始、结束、拼接等。UniLM-CRF的循环次数是指微调时的循环次数。通过对比可知,预训练模型在微调时有助于加快模型的收敛时间。然而语言模型预训练时,耗费了近十天的时间,但该模型非常便于迁移,能够提升更多下游任务的性能,甚至可以迁移到少样本或者零样本的任务中。
2.3 实验结果及分析
本文使用的第二届少数民族语言分词技术评测的藏文分词语料,是一种含有新闻、小说、教育及法律等综合性领域的语料,共有27 479个句子(含有778 817个词),其中只有训练集,未提供测试集。因此,在本实验中训练集和测试集以8∶2比例进行随机分配,并从训练集中删除共同出现的句子。为了避免出现过拟合的问题,本实验中采用交叉验证法,最后取三组交叉验证的平均值。用精确率P、召回率R以及F1值来进行评价和对比。各个模型的实验结果如表2所示。

表2 交叉验证的对比实验结果 (单位:%)



表3 校对之后的对比实验结果 (单位: %)
从表3可知,训练集的质量对分词结果有一定的影响。随着训练集中分词质量的提升,对分词模型的性能也有所提升,F1分别提高了2和1.1个百分点。TIP-LAS无法有效解决未登录词的问题。
最后为了验证本方法在多领域中的有效性,分别收集了法律、新闻、语文和自传等领域差异较大的四种测试集,均有1 000个句子,并进行人工分词。在不同领域的对比结果如表4所示。
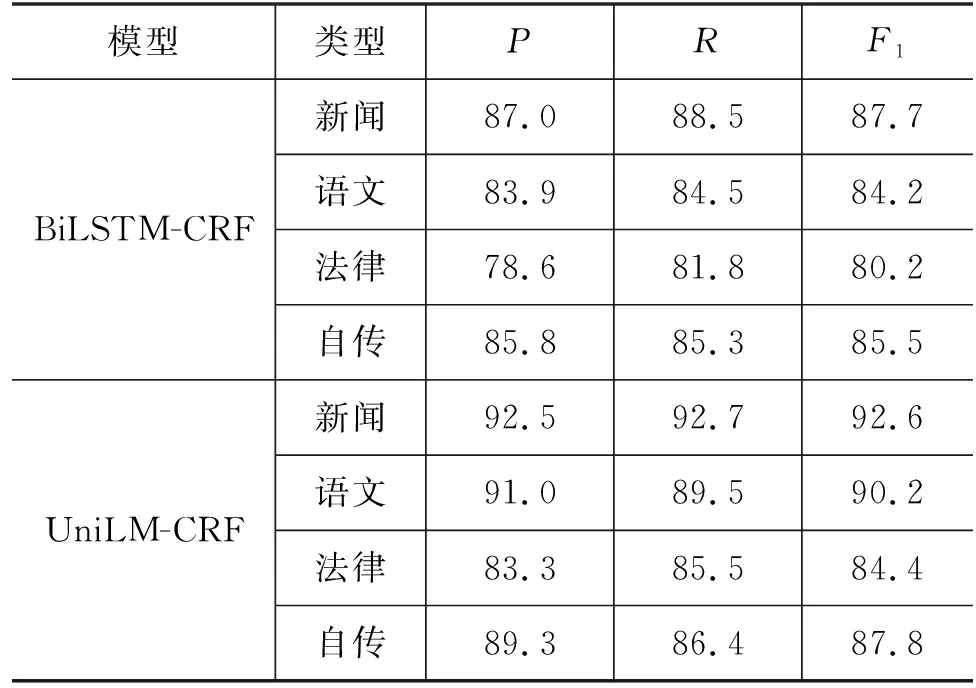
表4 不同领域的对比实验结果 (单位: %)
与基线模型BiLSTM-CRF相比,本文方法在领域差异较大的四个测试任务中均取得优异的成绩,F1提高了2.3到6个百分点。因此,预训练语言模型能够缓解藏文分词语料领域受限的问题。分词实例的对比结果如表5所示。
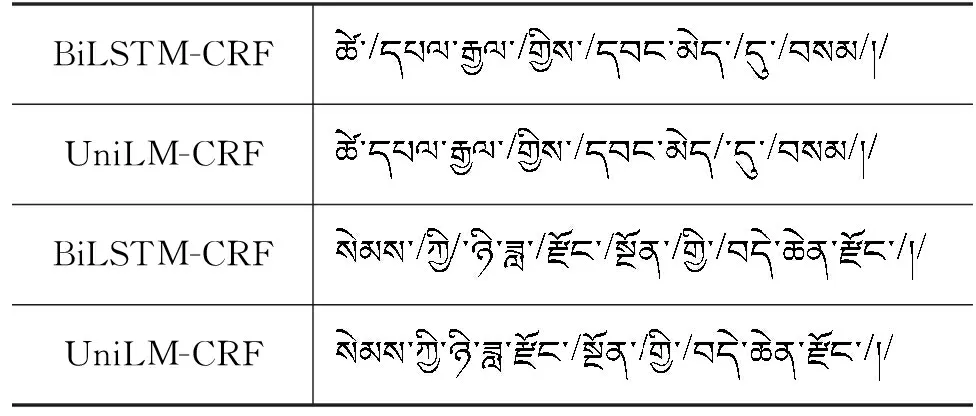
表5 藏文分词结果的实例对比
3 总结
本文围绕藏文分词训练集的规模少、未登录词、以及领域受限等问题进行设计,其关键任务是如何充分利用含有46.55亿字符的藏文文本语料。为了提高藏文分词模型的效果及泛化能力,借鉴了微软提出的统一语言模型UniLM[14]的框架。该模型将有效结合单向语言模型、双向语言模型、序列到序列语言模型,以及句子次序预测任务等,并在该文本语料上进行预训练。最后实验结果表明,与基线模型相比,我们的方法可以提升藏文分词的正确率,F1值在MLIP2021上提高了2.5个百分点,在新闻、语文、法律和自传等不同领域上分别提高了4.6、6、4.2和2.3个百分点,特别是对音译词、人名和地名等的切分正确率显著优于基线模型。
