中文礼貌风格迁移的研究
2023-02-04朱洪坤左家莉何思兰曾雪强王明文
朱洪坤,左家莉,何思兰,曾雪强,王明文
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
0 引言
文本风格迁移(Text Style Transfer, TST)的目的是改变文本的风格,同时保留与风格无关的语义内容,TST有非常广泛的应用,如情感迁移(积极-消极)[1]、形式迁移(正式-非正式)[2]和礼貌迁移(礼貌-非礼貌)[3]等。
本文关注的是文本风格迁移中的礼貌迁移任务。在工作往来、学习交流等社交场合中,礼貌的表达至关重要。有学者将礼貌定义为一种文本属性,可以和文本内容脱离[4],例如,在“坐”这个动作前面加上一个“请”,内容并未改变,但是表达变得更为礼貌,更为符合社交礼仪。
文本风格迁移的关键是区分“风格”和“内容”,因此在定义“礼貌”风格之前首先要明确什么是“风格”。Jin等人认为目前主要有以下两类方法定义“风格”[5]。第一类是通过“语言定义”,直接将非功能语言特征归类为风格(如正式与非正式),风格可以通过使用特定的表达方式来体现,例如,隐喻,以及单词的选择、句法结构等。第二类是基于“数据驱动”[6],不同于语言定义,“数据驱动”在理论上限制了语句中构成文本风格的成分,例如,在正式文本中不能出现“isn’t”“don’t”等缩略词。给定两个语料库(如正面和负面的评论语料),风格差异体现在正面评论大多数使用积极情感词,消极评论大多使用消极情感词。本文采用的是数据驱动的风格定义。
此前的礼貌风格迁移的研究[3]认为,将礼貌风格迁移作为一种文本风格迁移是非常困难的,其原因是文本的风格属性难以被定义,且受文化、地域、场景甚至个体的影响[7]。Brown等人就认为,礼貌表达是丰富的、多层次的,一句话是否礼貌以及礼貌的程度取决于说话者的文化背景、使用的语言和社会地位[8]。以日常打招呼为例,中国人大多会问“吃了吗”“去哪呢”等等,这对于中国人而言是一种自然且亲切的交流方式。换到其他一些社会或文化中,这种寒暄会令对方感到突兀和尴尬,他们可能会认为这是一种对他们私生活的“盘问”。正因为语言的这些差异,Madaan等人根据语料的获取来源强调他们的工作主要关注的是北美英语。虽然中文与英文礼貌风格存在较大的差异,但主要体现在礼貌用语的不同,两者也存在着共同的挑战,即内容词与礼貌风格词的分离。对于中文的礼貌风格迁移,本文考虑从数据驱动的角度出发,而非语言的语义。这样做首先可以避免直接对“风格”进行定义,同时也可以减少不同的语言的直接影响,更关注模型。
直观上,我们可以通过使用“避免过于直接”或“表示尊重”的语言来表达礼貌。例如,尊敬的称呼(如“先生”或“女士”)能够体现某些“礼貌”的公式化词语(如“请”“谢谢”“抱歉”)。本文关注将非礼貌语句转换成礼貌语句,例如,非礼貌语句“在截止日期之前把文件发给我”,可以转换成礼貌语句“请在截止日期之前把文件发给我,谢谢”。这两句话所要传递的信息一样,但后者显然更为礼貌。因此,本文将非礼貌语句定义为不包含礼貌词语的中性语句。
基于礼貌风格迁移任务,Madaan等人提出了T&G模型,它包含两个模块,分别是: Tagger模块,用于生成带有[TAG]标签的无属性风格句子;Generator模块,用于生成带有目标风格的句子,并在英文语料上开展了礼貌迁移的工作[3]。这个模型简洁、直观,其两步策略可以显式地生成中间结果,但它的生成不可控。如表1中“未对齐”语句所示,模型在生成的过程中加入了“感兴趣”这样的内容。本文基于T&G框架,研究了中文的礼貌风格迁移任务,我们引入了文本对齐模块和流畅度评估模块。为了使Generator的输入文本更贴近原始语料,我们采用文本对齐策略,将Tagger输出的句子与输入对齐,除[TAG]标签外其他内容保持不变。这一策略在一定程度上提高了内容保存率。如表1所示,经过对齐之后,“感兴趣”这样的多余内容会被去掉。最后将Generator输出的文本和真实值输入流畅度评估模块,得到风格迁移后的目标文本。

表1 文本对齐示例
我们主要的工作是关于中文的礼貌迁移的研究,为此我们构建了一个含有21万句的中文礼貌语料库(1)中文礼貌语料https://github.com/txdysdrbr/Chinese-politeness。
本文的组织结构如下: 引言描述礼貌风格迁移的任务;第1节概述文本风格迁移和礼貌风格迁移的研究现状;第2节简要介绍Transformer的架构;第3节给出基准的T&G模型;第4节介绍本文提出的中文礼貌风格迁移模型,该模型结合了文本对齐和流畅度评估;第5节详细说明实验设置、实验结果与分析;第6节对本文的工作进行总结。
1 相关工作
1.1 文本风格迁移
文本风格迁移是自然语言生成中的一项重要任务,近年来,随着文本生成任务的不断发展,基于非平行文本语料库的风格迁移已成为一项研究热点。
Prabhumoye等人[9]首先使用机器翻译学习源风格句子的潜在内容表示,这种做法有助于保留源句子的意义,同时也削弱了风格属性,然后使用反向翻译的潜在表示和风格分类器反馈来指导特定风格生成器的训练。Huang等人[10]提出了无监督文本风格迁移的非自回归生成模型,该模型对单词对齐进行建模,并利用不同风格文本之间的单词级转换以实现风格迁移的目的。Liu等人[2]使用GYAFC数据集展开“正式-非正式”迁移工作,通过已有平行语料训练得到基线模型,再通过基线模型生成伪对齐语料。考虑到伪对齐语料的质量,Liu等人[11]基于指标过滤器来获取质量较好的语料,然后再加入数据扰动,这样做的好处是可以增强模型的泛化能力,最后进行一致性训练。该工作基于半监督学习,给一些语料不足的任务提供了一个很好的方向。
Jin等人[3]将文本风格定义分为两种,一种是语言学风格定义,可以通过使用一定的修辞手法,如比喻,或者是词汇的选择、句法结构等来表达;另一种是数据驱动型的风格定义,数据驱动的风格定义可以包含更广泛的属性,包括文本的内容和主题。两种定义相比之下,基于数据驱动的风格定义可以很好地与深度学习方法结合,因此,本文的工作是基于数据驱动方式的。
1.2 礼貌风格迁移
当前,文本风格迁移工作主要是关于情绪、主题、性别和政治倾向等的风格迁移。一般而言,风格迁移方法大多把文本分成内容和风格属性两个部分,通过将内容与目标风格结合,生成带有目标风格的文本[12-14]。此外,删除、检索和生成也是较为有效的方法[15-16]。例如,Li等人[15]在源文本中删除风格属性词,再由目标风格语料库中检索内容相近的目标文本,基于RNN生成带有目标风格的句子。由于委婉、礼貌地表达在社交活动中作用不容忽视[6,8,11],礼貌风格迁移的研究也逐渐增多。礼貌风格迁移要求在保留句子内容不变,即不改变句子意思的前提下,将非礼貌性的句子转化成礼貌性的句子。
礼貌风格迁移任务首先由Madaan等人[3]提出,并在英文语料库上开展工作。此前有关礼貌文本生成的工作,Niu等人[17]侧重于礼貌情景对话的生成,而不是内容保留后的风格迁移。Madaan提出T&G模型,将礼貌迁移工作分为两个步骤: 第一步,通过Tagger将非礼貌句子生成带有[TAG]标签中间文本;第二步,将中间文本作为Generator的输入,生成带有礼貌属性的句子。
近年来,Transformer[18]以及各种变形过后的Transformer(X-Transformer)被广泛应用于各项试验中,使其已经成为自然语言处理任务中的首选[19]。Transformer的突出优势主要得益于注意力机制(Attention Mechanism),这一应用突破了循环神经网络(Recurrent Neural Network, RNN)模型不能并行计算的限制,大幅度提升了计算速度,降低了时间开销[20]。并且,相比卷积神经网络(Convolutional Neural Networks, CNN),Transformer计算两个位置之间的关联所需的操作次数不随距离增长,减少了大量的计算[21]。后续的研究表明,基于Transformer的预训练模型(Pre-Training Model, PTM)可以在各种任务中实现SOTA的性能,Transformer已经成为NLP中的首选架构,因此,本文引入Transformer来进行礼貌风格迁移实验。
1.3 非平行语料
基于数据驱动的文本风格迁移任务需要大量的平行语料,然而语料标注成本很高[22]。
此前已有工作将翻译之后的文本用于神经网络训练的验证[23]。反向翻译(Back Translation, BT)[9]的最初想法是训练一个目标句子到源句子的序列到序列(Sequence to Sequence, Seq2Seq)模型[24-25],并使用该模型从目标单语句子生成源语言句子,建立平行语句。Zhang等人将其推广为基本数据增强方法[26],将源语言句子翻译成另一种语言之后再翻译回源语言,通过学习风格分类器来确定经反向翻译生成的句子是否适合作为平行语料。以上工作给本文的工作提供了一定的理论基础。
本文的礼貌风格迁移工作,使用处理之后的安然语料库[27]进行有监督训练,这一语料库由安然公司员工的大量电子邮件组成。电子邮件是交换请求的媒介,是礼貌迁移任务的理想语料库[3]。本文使用百度翻译API对安然语料库进行翻译,得到中文礼貌语料。
此外,本文的研究是基于数据驱动[6]的方式,对于翻译之后的中文文本,模型也能学习到隐藏在语句中的礼貌风格。在使用百度翻译API来构建语料时我们发现,翻译过程中会过滤掉一部分不礼貌的表达,这表明不礼貌的文本经过翻译之后,无法再作为语料。此外,对于中文的礼貌迁移任务,本文只作添加[TAG]操作,因此只用到礼貌风格的语料。
2 背景
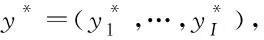
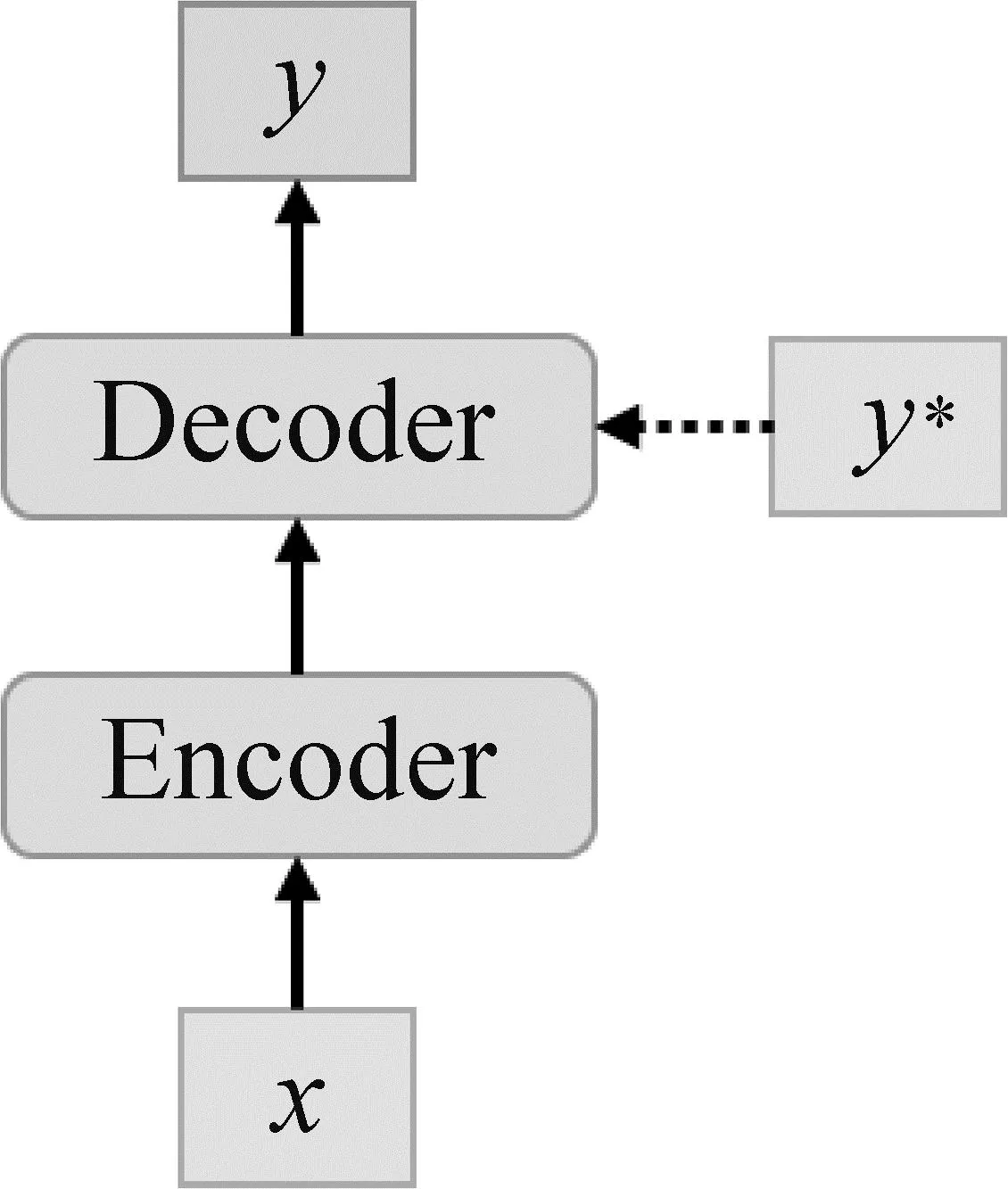
图1 框架图
2.1 编码器
编码器由N个相同的层组成,每一层有两个子层。第一个子层是多头注意力层(Multi-head attention),用于计算输入序列的自注意力(Self-attention);第二个子层是全连接前馈网络,称为FFN子层。在这两个子层之后都有一个残差连接操作和一个层归一化操作。输入序列矩阵经过变换之后得到一组Queries(Q)、Keys(K)和Values(V),多头注意力单元采用点积注意力来处理它们。
对于编码器的第n层,可以将多头子层形式化如式(1)所示。
Zn=AddNorm(MutiHead(Hn-1,Hn-1,Hn-1)
(1)
其中,Hn-1∈J×dmodel是第n-1层的完整输出矩阵。然后将第n层的FFN子层形式化如式(2)所示。
2.2 解码器
解码器也由N个相同的层组成,不同的是,每一层除了multi-head子层和FFN子层外,还插入了第三个子层,称为交叉注意力(Cross-Attention)子层。Cross-attention子层对编码器的输出执行多头注意操作。和编码器一样,解码器在每个子层之后还进行了残差连接和层归一化操作。此外,应用一个掩码矩阵来防止模型接触到后续位置的信息。
对于解码器的第n层,可以将multi-head子层形式化如式(3)所示。
其中,Sn-1∈I×dmodel是第n-1层的输出。Cross-attention子层可以形式化如式(4)所示。
FFN子层形式化如式(5)所示。
完成以上操作后,第n层的最终输出记为S=[s1;…;sI]T,其中si是yi的隐藏状态。通过对目标隐藏状态进行线性变换和SoftMax操作,我们可以得到式(6)。
2.1 两组患者的基本资料比较 两组患者的基本资料,包括性别、年龄、BMI、有无合并症、肿瘤距肛缘距离、肿瘤直径及TNM分期,组间差异无统计学意义(P>0.05)。见表1。
其中,x是模型输入序列,y是输出序列,W0∈dmodel×|Vt|和|Vt|是目标词汇表的大小。Transformer通过最小化交叉熵损失来训练,从而最大化ground truth序列的概率,交叉熵损失计算如式(7)所示。
3 T&G模型
T&G模型是一个显式的两阶段模型,包含Tagger和Generator两个模块,其结构如图2所示。其中,Tagger用于识别并移除句子中的源风格属性词,用[TAG]标签替代,当句子中没有风格属词时,Tagger则要在句子中某些位置加入[TAG],Generator则是学习如何将带[TAG]标签的句子生成目标风格句子。对于风格Fv,v∈{1,2},首先需要学习一组表达风格Fv特征的短语(Γv)。若句子xi中出现带有风格Γv的短语,则xi的风格是Fv。 例如,像“相当不错”和“非常值得”等短语在“消极-积极”迁移任务中属于“积极”风格。

图2 Tagger和Generator流程图示例
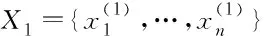

其中,k为一个风格分数,Γ2包含的是X2中分数大于或等于k的风格属性词,Γ1计算方法类似于此。
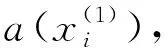
(11)


需要注意的是,这里需要学习一组带位置的标记[TAG]t,其中t∈{0,1,…,T},表示长度为T的句子中的位置。通过使用这些位置t训练Tagger和Generator,这样可以实现风格属性在不同位置上的分布不同。例如,一般情况下,在句子开头也即[TAG]0几乎总是生成“请……”这样的礼貌词。而对于句子中更靠后的位置,[TAG]T生成“谢谢”的概率更高。
4 中文礼貌风格迁移模型

本文基于T&G的框架,引入了文本对齐模块和流畅度评估模块。本文模型由四个模块组成,Tagger、Generator、文本对齐模块(Alignment)和流畅模块(Fluency),结构如图3所示。在训练阶段,Tagger和Generator分别训练,由Generator得到初步的输出文本,进一步和Ground truth经Fluency得到风格迁移后的目标文本,如图3所示。测试阶段,源文本经过Tagger模块后进行文本对齐。

图3 模型框架图
4.1 文本对齐策略
在文本风格迁移任务中,由数据驱动[6]定义下的风格,可以和内容分离。因此,本文认为Tagger和Generator理想的输出是内容不变,即只改变“风格”,文本的其他内容不发生变化。为了确保内容不变,受到Huang等人[10]的启发,我们采取了一种文本对齐策略。
在模型的训练阶段,Tagger的Ground truth与Generator的输入相同,因此,我们只在验证和测试时使用文本对齐策略。如图3所示,在Tagger的输出端使用文本对齐,Generator的输出端不使用。文本示例如图4所示。

图4 文本对齐示例
图4中,predicted为Tagger生成的句子,丢失了一部分源句子的信息,target是经过文本对齐之后的文本,信息保留较为完整。
4.2 流畅度评估
为保证经过礼貌迁移之后的文本的流畅度,本文引入了流畅度评估模块。我们认为,每个[TAG]生出目标内容时应充分考虑上下文,尤其是有多个[TAG]的情况下。这里我们借鉴了Feng等人[28]在机器翻译任务中使用的流畅度评估模块,不同于机器翻译任务中,仅在训练阶段使用流畅度模块,本文在训练、测试阶段都引入了流畅度模块。略有不同的地方在于,训练时使用Ground truth作为上下文,而测试时的上下文来自Generator的输出。
流畅度模块有两个解码器,两个解码器都由N个相同的层组成,其结构是使用Transformer的编码器,每层均有两个子层,分别是multi-head子层和FFN子层。如图5所示,左边的解码器输入为Generator的输出结果,右边的解码器的输入是Ground truth,我们希望用Ground truth指导模型学习上下文,测试时则是使用Generator生成的上下文来指导。
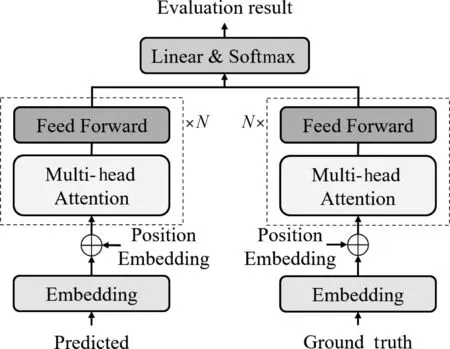
图5 流畅度评估模块结构图
评价模块通过交叉熵损失优化,损失函数如如式(14)所示。
5 实验与结果分析
5.1 数据准备
本文的实验数据,首先考虑使用电商平台顾客与客服之间的对话以及中文邮件,但是客服对话的礼貌表达方式较单一,且与日常表达方式相差较大;目前公开的中文邮件更适用于邮件分类任务,而不是本任务。因此,我们使用翻译工具将安然语料库[27]翻译为中文礼貌语料,我们也注意到虽然翻译可能会改变文本的风格,但经过后续的整理,仍然可以作为本任务的训练语料,因而进一步人工标注了500句的测试语料。
具体而言,我们对Madaan等人[3]构建的礼貌分数较高的句子进行翻译,得到了一个21万句的中文礼貌迁移训练语料。对于情感迁移任务和政治倾向迁移任务[9],分别使用的是Yelp餐厅评论数据集[1]和Voigt等人[29]发布的数据集,数据集的规模如表2所示,其中Politeness表示中英文礼貌语料库的大小。
5.2 基线任务
我们与三个经典模型进行比较,分别是DRG[15]、B_GST[16]和T&G[3]。对于DRG,我们只比较报告的最好的方法: 删除-检索-生成。所有参与比较的模型,遵循各自论文中描述的实验设置。
5.3 实验细节
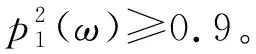
5.4 评价指标
本文使用了四个评价指标评估模型: 风格迁移精度(Acc)、内容保存率(BLEU)、困惑度(Perplexity,PPL)和BLEU与Acc的调和平均值(HM)。迁移精度指标指将生成的句子分类到目标风格中的百分比。内容保存率的度量标准是BLEU分数[33],本文是根据原始句子计算的。PPL可评估迁移后句子的语法正确性和流畅度,PPL值越小,语句越流畅。此外还加入了一个综合性指标HM,即BLEU和Acc的调和平均值[18]。
表3展示了本文模型以及DRG、B_GST和T&G方法在中文礼貌数据集的效果。结果显示,本文模型在BLEU、PPL和HM上的得分都优于其他模型。文本对齐策略的应用使得本文模型在内容保存率上表现更好,流畅度评估模块提升了模型生成句子的流畅性。
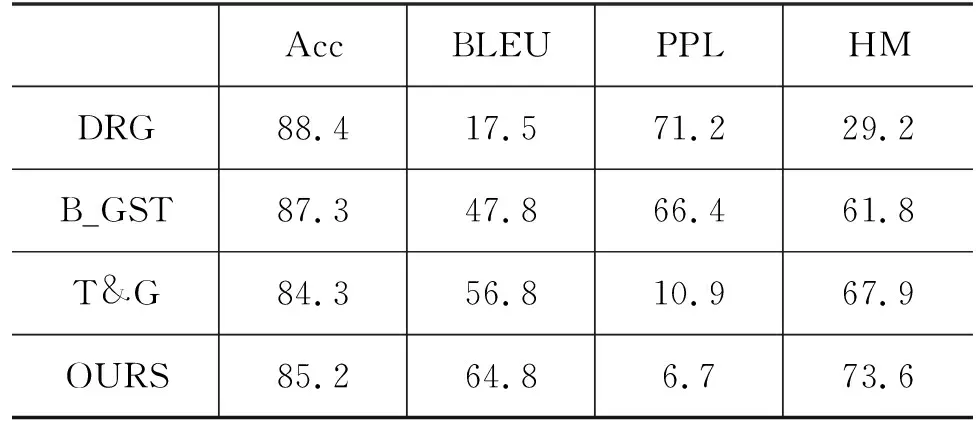
表3 中文礼貌风格迁移结果 (单位: %)
表4中给出了本文模型和其他模型在英文礼貌语料Politeness-en、Yelp和Political上的结果对比。实验结果表明,数据集的分布对模型的表现有一定的影响。在礼貌、情感和政治倾向语料上,通常情况下,DRG的分类精度较高,但在内容保留方面性能较弱,本文模型在BLEU、PPL和HM上的表现都更好,在Politeness-en上的分类精度表现也高于T&G。同时我们还观察到T&G以及本文模型在PPL指标上与另外DRG、B_GST对比相差明显,我们认为其原因是本文模型和T&G模型在训练时对于风格属性词的选择都是基于语料库中出现的频率,我们倾向于选择出现频率更高的词,因此模型生成语句在流畅度评估上表现得更好。
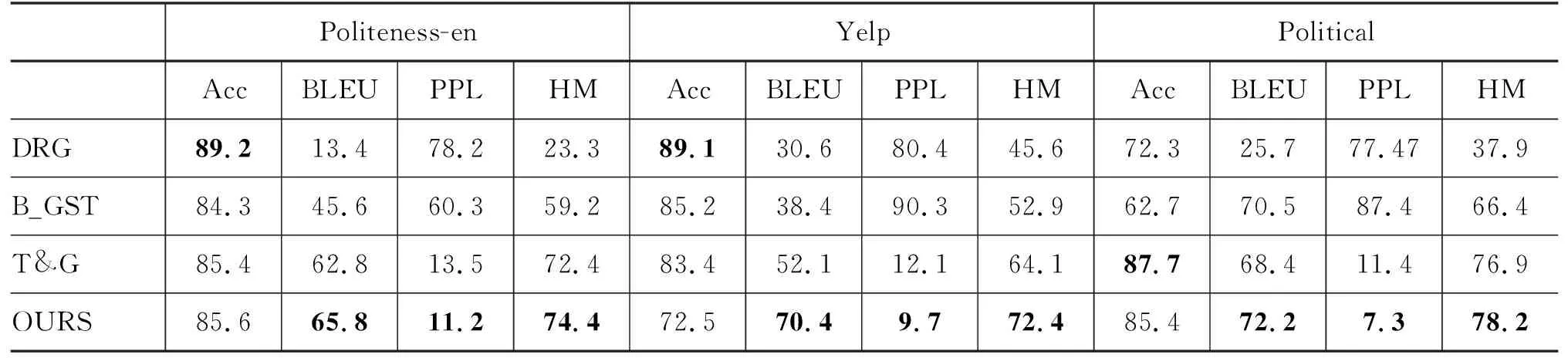
表4 Politeness-en、Yelp和Political数据集上的实验结果 (单位: %)
5.5 消融实验
本文中的礼貌风格理论上可以与内容分离[4],在礼貌风格迁移任务中改变内容词不符合我们的预期,因为其可能会彻底改变源句子的意义。我们认为对Tagger的输出进行文本对齐,可以在一定程度上提高内容的保存率。为了考察文本对齐模块和流畅度评估模块的效果,我们对这两个模型进行消融实验,实验结果见表5。
观察表5,根据加入对齐模块与否对比Ⅰ、Ⅱ或者Ⅲ、Ⅳ,引入文本对齐模块之后,模型生成语句的BLEU分数能得到有效提升。根据加入流畅度模块与否对比Ⅰ、Ⅲ或Ⅱ、Ⅳ的大小,结果表明流畅度评估模块能帮助模型生成更流畅的语句。
5.6 定性分析
表6中给出了Tagger生成带有[TAG]标签的中间句子,以及模型最后生成的目标句子。第一个句子加入“请”字,第二句通过加入“谢谢”,从而使句子变得礼貌。从表6来看,本文模型和T&G模型在礼貌风格迁移上的表现都不错,但本文方法在生成句子的内容保留和流畅度方面变现更佳。

表6 中文礼貌风格迁移的示例
6 结束语
本文研究中文礼貌迁移的任务,为此构建了一个中文的礼貌语料库。同时基于T&G模型,引入一个文本对齐模型和流畅度评估模块,在多个数据集上的实验结果表明,本文方法在内容保存和流畅度方面优于其他模型。
目前阻碍中文礼貌风格迁移任务的研究发展的主要因素是缺乏高质量的训练语料,我们采用的训练语料是翻译为中文的安然语料,这实在是无奈之举。未来我们要通过人工收集和整理,并结合数据增强方法,以生成更好的训练数据。
