融合匹配长短时记忆网络和语法距离的方面级情感分析模型
2023-02-03张琳玉何如瑾
刘 辉,马 祥*,张琳玉,何如瑾
(1.重庆邮电大学 通信与信息工程学院,重庆 400065;2.重庆邮电大学 通信新技术应用研究中心,重庆 400065)
0 引言
情感分析按分析的粒度不同可以分为文档级、句子级和方面级[1],其中方面级情感分析(Aspect-Based Sentiment Analysis,ABSA)由于能分析出句子中特定方面的情感而受到广泛研究。在使用深度学习前,Jiang 等[2]首次提出40%的情感分析错误是由于没有考虑句子中的方面信息,并在Twitter 数据集上验证了方面词对于情感分析的重要作用,由此引发了对于ABSA 的广泛研究;Kiritchenko 等[3]利用支持向量机(Support Vector Machine,SVM)作为分类器在ABSA 中取得了不错的效果。但这些方法依赖人工标注特征,使ABSA 的发展受到了限制。近年来,深度学习方法被广泛用于方面级情感分析,并且大多依赖于长短时记忆(Long Short-Term Memory,LSTM)网络和注意力机制。LSTM 由于可以避免梯度消失或爆炸的问题被广泛用于特征提取[4-5],Tang等[6]使用LSTM 的隐藏表示预测情感;Ruder 等[7]使用双向长短时记忆网络(Bidirectional LSTM,Bi-LSTM)获得了更好的分类效果;Li 等[8]提出了特定目标的转换网络(Targetspecific transformation network,Tnet),将上下文特征和转换后的特征卷积以获取最终表示。但以上模型采用传统的LSTM,同等地看待上下文词,无法准确地匹配与方面词更相关的上下文词。因此,Wang 等[9]引入注意力机制,并将方面嵌入直接拼接到上下文嵌入中,取得了不错的效果,证明了注意力机制在ABSA 中的作用;Xu 等[10]结合局部上下文焦点,依赖集群构建注意力用于方面级情感分析;Basiri 等[11]基于注意力机制,构建了一种融合卷积神经网络(Convolution Neural Network,CNN)与循环神经网络(Recurrent Neural Network,RNN)的情感分析模型;Tang 等[12]提出深度记忆网络(deep Memory Network,MemNet),采用多层注意力分配上下文权重获得了更好的分类效果。但是以上模型采用的注意力机制忽略了方面词与上下文的交互,限制了分类性能。为了实现方面词与上下文的交互,获取更好的特征表示,Ma等[13]和Huang 等[14]分别提出了交互注意力网络(Interactive Attention Network,IAN)和双重注意力网络AOA(Attention-Over-Attention),使方面词与上下文词分别参与对方的建模,进一步提高了分类性能。然而,这些交互注意力机制没有逐词地计算方面词与上下文的一致性,可能错误地关联与方面词不相关的上下文词,限制了分类性能,此外,也缺少对语法特征的分析。图卷积网络(Graph Convolutional Network,GCN)由于能够捕获单词间的语法特征而被应用于ABSA,Zhou 等[15]提出一种基于语法和知识的图卷积网络;Zhu 等[16]提出一种利用局部和全局信息引导图卷积网络构建的模型;Zhang 等[17]提出了特定方面的图卷积网络(Aspect-Specific GCN,ASGCN),用GCN 提取方面词特征后再反馈给上下文表示,获得交互注意力权重作为情感分类的依据。然而,GCN 使用相对位置权重,缺乏语法距离的考虑,很可能错误地将方面词与语法上关联度不高的上下文进行匹配,导致情感分类错误。如“The food is great,the prices are very expensive.”中,方面词“prices”与“great”和“expensive”的相对距离分别为2 和3,则很可能将“great”作为情感线索得到对“prices”积极的情感。
针对上述方面词与不相关的上下文错误匹配的问题,本文提出了一种融合匹配长短时记忆网络(match-LSTM,mLSTM)和语法距离的方面级情感分析模型mLSTM-GCN,从语义上逐词计算方面词和上下文的一致程度,将得到的方面词注意力加权表示与上下文表示融合作为mLSTM 的输入,得到与方面词更关联的上下文表示;同时,从语法层面引入语法距离作为位置权重,使与方面词语法关联度更高的上下文可以获得更大的权重;最后,在计算上下文与方面词之间的交互信息时,增加语法距离权重作为输入,获得含有更多特征的注意力表示用于情感分类。在Twitter、REST14 以及LAP14 数据集上验证,mLSTM-GCN 在准确率和macro-F1 两个指标上明显优于对比模型。
1 mLSTM-GCN模型
mLSTM-GCN 模型如图1 所示,由Bi-LSTM 层、mLSTM层、语法距离权重层、图卷积层、方面掩盖层和信息交互层等组成,其中,mLSTM 用于获取更加准确的方面词与上下文匹配,得到与方面词关联度更高的上下文表示;语法距离权重层减少了方面词和语法关联度不大的上下文错误匹配的概率;信息交互层将语法距离权重的输出也作为输入,得到了有利于提升性能的最终表示。

图1 mLSTM-GCN模型框架Fig.1 Framework of mLSTM-GCN model
1.1 方面词与上下文的语义表示

1.2 mLSTM层
传统方法没有逐一地匹配方面词与上下文,方面词可能会将不相关的上下文作为判断情感的线索,导致错误的分类。受到Wang 等[18]的启发,将mLSTM 引入方面级情感分析,逐一计算方面词与上下文词的一致性,进一步加强方面词和重要的上下文词的匹配,可以有效地避免错误匹配的问题。本文在得到方面隐藏状态对上下文单词的注意力向量时,采用拼接操作将该注意力向量与上下文表示融合以增强方面特征,并将该矩阵作为mLSTM 的输入,得到与方面词更加关联的上下文表示。
逐词匹配的主要思想是引入方面隐藏状态的一系列注意力加权组合,每个组合用于上下文中对应的特定单词。使用和分别表示方面词和上下文词的隐藏状态,用ak表示方面隐藏状态对上下文中单词的注意力向量:

其中:αkj用于编码上下文词和方面词之间的注意权重,注意力权重越大,方面词与上下文之间的一致性越高。αkj由式(2)计算:

其中:ekj′用于获取上下文词与不同方面词之间的关联;ekj由式(3)得到。

其中:we和所有的参数矩阵W*均为可学习的权重矩阵是由mLSTM 产生的第k个位置的隐藏状态。mLSTM 模拟了方面词和上下文的匹配,通过mLSTM,重要的匹配会被保留,非必要的匹配则会被忽略。将上下文中第k个单词的关于方面词的注意力权重ak与上下文中第k个单词的隐藏状态融合起来,作为mLS TM 的输入mk。

得到mLSTM 的输入后,用式(5)~(9)构建mLSTM。

1.3 语法距离与图卷积网络
方面词和上下文语法关联度不高导致语法层面特征不足,分类效果不佳。引入语法距离代替传统的相对距离,语法距离是方面词和上下文在句法依赖树中的路径长度,可以获取更丰富的语法特征。句法依赖树由spaCy 库构建,如:句子“This French food tastes very well,but the restaurant has poor service.”中方面词“food”的句法依赖树如图2 所示,其中的数字为各单词到方面词“food”的语法距离。
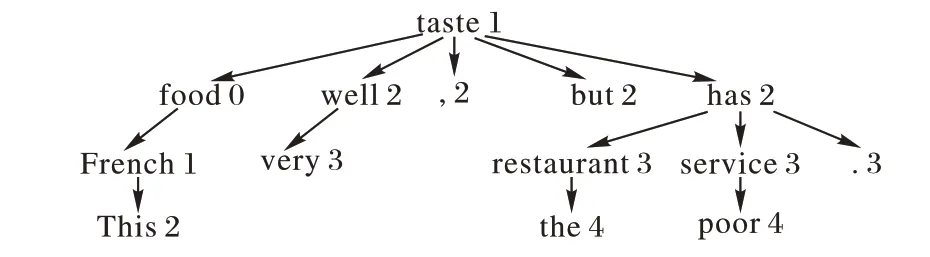
图2 “food”的句法依赖树Fig.2 Syntactic dependency tree of “food”
构建句法依赖树后,根据苏锦钿等[19]提出的语法距离算法得到语法距离向量DS,a=(d1,a,d2,a,…,dn,a),其中dk,a为上下文中第k个单词与方面词的语法距离。上下文词的权重值lk为:

其中:dmax为DS,a中语法距离的最大值。由式(10)可知,lk∈[0.5,1],保证了语法距离小的上下文具有更大的位置权重,可以减小与目标方面无关的其他方面的情感词的影响。
位置权重层的输出为Hpm=,其中=
图卷积网络充分利用句法依赖树,具备感知语法的能力,将词汇表示为节点,词汇之间的关系用边表示,可以将文本用图结构表示。单层的图卷积网络示例如图3 所示。
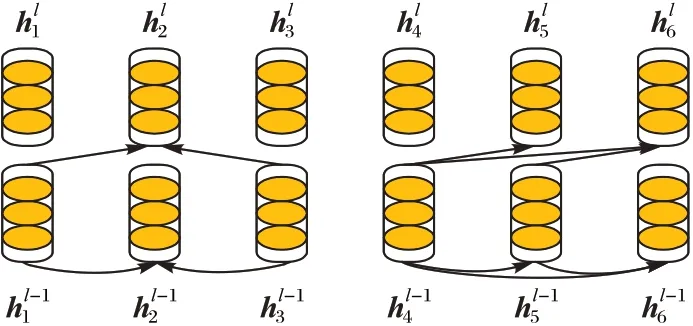
图3 图卷积网络示例Fig.3 Example of GCN
本文使用图卷积网络获取情感特征,将位置权重层的输出Hpm、上下文的隐藏表示Hm和句子依赖树的邻接矩阵Aij作为图卷积网络的输入。假设图卷积网络为L层,则图卷积网络的更新规则如式(11)所示。

其中:为第l层图卷积网络的第i个节点的隐藏表示;为第l-1 层的第j个节点的隐藏表示;Aij是n×n的邻接矩阵,由句法依赖树得到,Aij=1 表示节点i和节点j之间有连接,自环设定为1;Wl是权重矩阵bl为偏差项,Wl和bl都可训练表示与第i个节点相关联的边数。
最后得到L层图卷积网络的隐藏表示为HL=
1.4 方面掩盖层和情感分类层
方面掩盖层只让方面的隐藏表示通过,对于非方面的单词,不能通过。经过方面掩盖层的隐藏表示由式(12)表示。
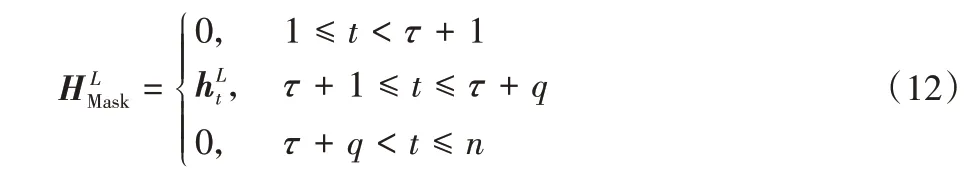
其中:代表方面词t的隐藏表示;τ+1 表示方面词的起始位置;τ+q表示方面词的结束位置。
在计算最终的注意力权重时,本文考虑了包含上下文语义、位置权重和带有语法信息的方面特征等多重因素,充分利用了文本信息。使用上下文表示Hm、位置权重层Hpm和方面特征表示得到最终的注意力权重向量ra。

情感分类层以最终的注意力权重ra作为输入,使用Softmax 函数获取情感的概率分布p。

其中:权重矩阵Wp和偏置项bp为可训练的。
2 实验与结果分析
2.1 数据集与参数选择
2.1.1 实验平台与数据集
本文实验在Pycharm 环境下进行,并基于Pytorch 深度学习平台,具体的实验环境信息如表1 所示。实验选取的3 个公开基准数据集数据集的详细信息如表2 所示。

表1 实验环境Tab.1 Experimental environment

表2 各数据集样本数量信息Tab.2 Information on the number of samples of each dataset
2.1.2 参数选择
词汇表以外的词语和权重矩阵,通过均匀分布U(-0.1,0.1)初始化,偏置初始化为0。由于Word2Vec 只考虑局部信息,GloVe 更容易并行处理文本,并且考虑了全局信息。此外,相较于基于变换器的双向编码器(Bidirectional Encoder Representations from Transformers,BERT),GloVe 能够更好地处理词汇表以外的单词,因此本文采用GloVe 得到初始的词嵌入,维度为300,隐藏状态的维度为300。训练过程使用适应性矩估计(Adaptive moment estimation,Adam)优化器更新参数,GCN 的层数设置为2,其他相关参数如表3 所示。

表3 实验参数设置Tab.3 Experimental parameter settings
2.2 评价指标
本文采用方面级情感分析中广泛使用的准确率(Accuracy,Acc)和宏平均(Macro-F1,FM)值作为模型的评价指标。准确率是正确预测的样本占样本总数的比例;FM将所有类别F1 的平均值作为整体样本的F1 值,指标的值越大表示分类效果越好。
准确率和F1 的计算如式(17)~(20)所示。

其中:TN表示真负样本;FN表示假负样本;FP表示假正样本;TP表示真正样本;P表示精确率;R表示召回率。
2.3 损失函数
使用交叉熵函数以及L2正则化机制作为损失函数:

其中:C为情感类别的数目;y i为真实的情感极性;pi为预测的情感极性;λ为L2正则化的权重;θ为要训练的参数。同时,为了防止模型的过拟合,采用了Dropout 策略。
2.4 实验结果与分析
2.4.1 与其他模型的对比实验
为了评估m-LSTM-GCN 模型的性能,在三个数据集上与以下模型对比,实验结果如表4 所示,最优结果加粗表示,次优结果用下划线表示。
1)LSTM[6]:用LSTM 的隐藏表示预测情感。
2)MemNet[12]:多次循环计算注意力与方面词融合,最后用Softmax 预测情感。
3)AOA[14]:考虑方面词和上下文的相互影响,共同学习方面以及句子的表示。
4)IAN[13]:用注意力层交互建模方面词和上下文的语义表示,最后将二者融合作为最终表示。
5)Tnet[8]:将上下文特征和转换后的特征卷积以获取最终表示。
6)ASGCN[17]:构建多层GCN 获取方面词的语法特征,并结合注意力机制得到最终表示。
7)双向图卷积网络(Bidirectional GCN,BiGCN)[20]:分层次建立语法图和词汇图,区分各种类型的依赖关系和词对,通过BiGCN 利用这两个图,结合单词共现信息分类。
8)基于依赖树的图卷积网络(GCN based on Dependency tree,DepGCN)[21]:用自注意力的方法得到潜在图结构,再通过图卷积网络得到句法信息。
从表4 可以看出,在三个数据集上,m-LSTM-GCN 模型的准确率和FM在大部分情况下优于对比模型,说明同时考虑逐词匹配方面词和上下文、融合语法距离权重并改进最终的注意力机制能提高情感分类性能。与ASGCN 相比,本文模型使用了mLSTM 逐词地匹配方面词与上下文,大大降低了方面词将非目标方面情感线索作为判断该目标方面情感极性的概率,同时,使用语法距离可以更好地获得语法层面的特征,因此本文模型的准确率分别提高了1.32、2.50 和1.63个百分点,FM分别提升了2.52、2.19 和1.64 个百分点。在REST14 上表现次优的BiGCN 缺乏上下文与方面词之间的关联,而本文模型从语义上计算方面词与上下文的一致程度,又采用语法距离赋予和方面词语法关联更大的上下文更大的权重,因此结果更优。
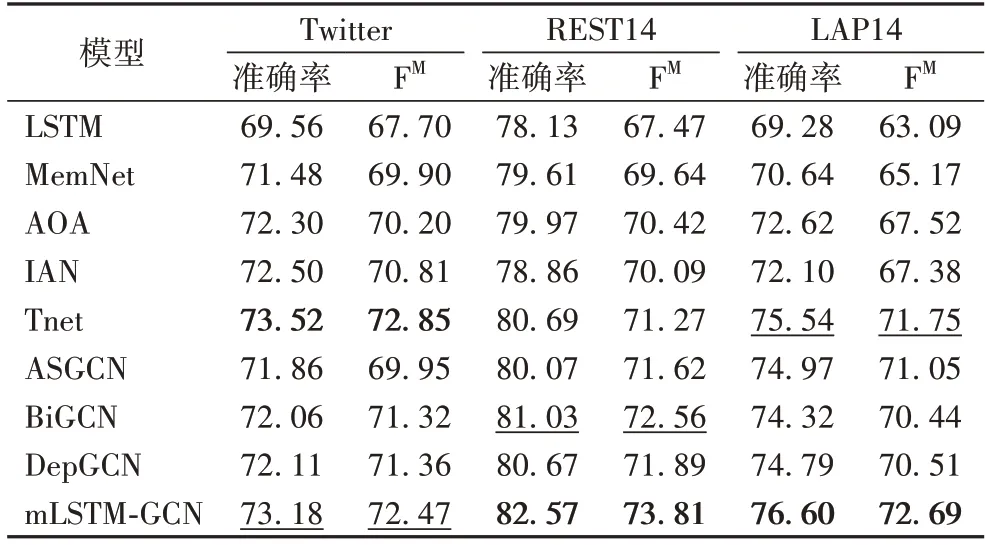
表4 不同模型的准确率和FM 单位:%Tab.4 Accuracy and FM score of different models unit:%
在Twitter 数据集上,与最优的Tnet 相比,本文模型的准确率和FM分别降低了0.34 和0.38 个百分点,这是由于Twitter 数据集上语料松散,相较于另外两个数据集容易出现一词多义现象,而本文采用的GloVe 预训练模型仅能获取其中一个的含义,一定程度上影响了模型性能;并且Twitter 数据集含有不符合语法的句子,因此本文模型按照语法结构分析,性能相较于最优的Tnet 略有降低。在LAP14 数据集上本文模型性能相较于Tnet 的提升程度低于REST14,因为前者数据集小于后者,说明数据集的大小也影响分类性能。在REST14 上本文模型性能有了明显提升,相较于Tnet,准确率和FM分别提升了1.88 和2.54 个百分点,因为REST14 的一个句子中多含有几个方面词,mLSTM 减少了将非目标方面的情感线索用来判断目标方面情感的概率,从而提升了性能。
2.4.2 各模块有效性实验
为了验证本文模型各子模块的有效性,进行消融实验。
1)mLSTM-GCN/mLSTM:移除mLSTM 子模块,将经过Bi-LSTM 的隐藏表示直接作为上下文的向量表示。
2)mLSTM-GCN-P:用单词间的相对距离权重pk代替语法距离权重lk,验证语法距离优于相对距离,其中的相对距离权重如式(22)所示。

3)mLSTM-GCN/PA:在计算最终的交互信息时,不直接将语法距离权重作为输入,仅使用方面特征表示和上下文表示来计算交互信息。
4)mLSTM-GCN:本文模型。
分别在Twitter、REST14 和LAP14 数据集上进行实验,结果如图4 所示。可以看出,去除了本文的mLSTM 模块后,在三个数据集上的准确率和FM均最低;将语法距离换成相对位置距离,对Twitter 数据集的影响最小,这是由于与其他两个数据集相比,Twitter 中有更多不符合语法的句子;计算交互信息权重时不将语法距离权重作为输入,准确率和FM值也有一定的下降;本文模型在三个数据集上均取得了最好的性能,说明引入mLSTM 逐词对方面词和上下文匹配,降低错误匹配非目标的情感线索的概率以及用语法距离代替相对距离,可以取得更好的效果。
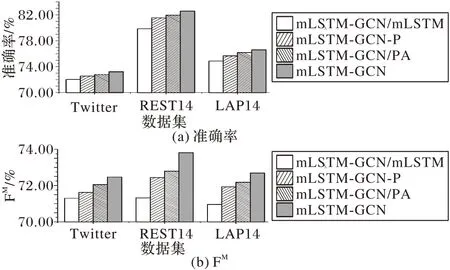
图4 消融实验结果Fig.4 Results of ablation experiment
2.4.3 GCN层数对性能的影响
为验证GCN 层数对模型性能的影响,在LAP14 数据集进行实验。取GCN 的层数从1 到12,结果如图5 所示。可以看出,GCN 层数为2 时,适当的GCN 层数可以学习到更深层次的特征,准确率和FM值均达到了最好性能,分别为76.60%和72.69%,因此本文GCN 层数设置为2;当GCN 层数为3 或者4 时,性能略有下降,这是因为随着层数的增加,GCN 中的变换操作变多,导致节点的特征方差过大,很容易出现梯度爆炸的问题,使得模型性能退化;当GCN 层数大于4 时,由于参数过多,难以训练,同时容易出现过拟合现象,因此性能呈迅速下降趋势。

图5 不同图卷积层数的准确率和FMFig.5 Accuracy and FM with different GCN layers
3 结语
针对现有研究容易出现的方面词与不相关上下文错误匹配的问题,本文设计了融合匹配长短时记忆网络和语法距离的方面级情感分析模型mLSTM-GCN,逐一地计算方面词与上下文的一致性,获取上下文关于方面词的注意力权重,并将该权值与上下文隐藏表示融合作为构建mLSTM 的输入,获取更精确的与方面词有关的上下文表示;同时使用语法距离从语法层面上使得方面词与上下文能够更准确地匹配。实验结果表明,mLSTM-GCN 模型在性能上有明显提升;但是在Twitter 数据集上处理不符合语法句子的效果仍有待提升。如何更好地分析不符合语法规则的句子以及考虑方面间的相互影响,将在今后的工作中完善。
