基于随机森林算法与供需关系的养老设施选址研究
2023-02-02王新建戴昭鑫
刘 新,王新建,吴 政,戴昭鑫,孙 哲
(1.山东科技大学 测绘与空间信息学院,山东 青岛 266590;2.山东科技大学 山东省基础地理信息与数字化技术重点实验室,山东 青岛 266590;3.中国测绘科学研究院,北京 100089)
人口老龄化是当今社会所面临的一个重要问题[1]。国际上对老龄化社会划分的标准为:60岁以上的人口占总人口的比重达到10%,65岁以上的人口占总人口的比重达到7%,这就意味着这个区域进入了老龄化。根据第七次全国人口普查数据显示,我国60岁及其以上的人口占总人口的比例已经达到了18.70%,与第六次人口普查结果13.26%相比,增加了5.44%,表明中国已经进入了老龄化社会,并且老龄化程度逐步加深[2]。在当前老龄化程度不断加深的社会背景下,社会养老服务设施和养老产品的供应不均衡问题逐渐显现,如城乡之间养老服务设施发展的不均衡问题,养老服务设施供给与需求之间发展的不均衡问题[3]。这就要求社会提供更多的养老服务资源以满足当前老龄化社会所带来的社会养老服务压力问题[4]。
选址是在研究区内为目标对象选择一个或多个最优位置的一个过程[5],是建设养老设施过程中最重要的一个环节,选址的合理性影响着城市基础设施的空间布局和服务对象的生活质量。科学选址是实现城市养老服务设施合理化布局的必要途径[6]。目前对养老设施选址的研究方法有GIS空间分析、层次分析法、蚁群算法、机器学习算法等。Murray等介绍了地理信息系统在选址方面的应用,借助该技术可以做出更好的决策[7]。吴聘奇等使用GIS的空间分析法、叠加分析对全龄化社区的建设进行适宜性评价[8]。李斌等在考虑养老服务设施供需关系的条件下,通过GIS空间分析工具对康复类社区综合养老设施进行布局选址[9]。许泉立等运用层次分析法确定养老设施选址指标的权重和选址评价模型,并借助GIS空间分析法对适宜选址区进行等级划分[10]。Yan等运用蚁群算法求解最优选址位置,并通过实例验证,证明了该选址模型方法的可行性[11]。汪晓春等使用兴趣点和第六次人口普查数据,运用决策树方法对武汉市养老设施的选址进行研究,通过老龄化程度对初步预测的结果进行筛选,最终提供一个选址结果的参考范围[12]。综上所述,目前的选址研究中,有学者将城乡统一进行选址研究,但未考虑城乡基础设施完善程度的不一致性,对选址结果会存在一定程度的影响。老龄化代表一个区域的老年人口占比,以单一指标老龄化对选址结果进行筛选,未能体现选址结果与人口之间的供需关系。
基于目前的研究现状,本文提出根据精细化人口数据、养老设施数据对格网单元进行养老服务压力、老龄化程度分析;结合POI(point of interest)数据与机器学习算法分别对滨城区主城区和主城区范围外的乡镇区域(下文简称乡镇)进行养老设施的选址研究,结合养老服务压力和老龄化程度双重约束条件对选址结果进行适宜性等级划分。
1 研究方法1.1 老龄化和养老服务压力1.1.1 老龄化
人口老龄化是指区域内的年轻人口数量减少、年长人口数量增加所导致的老年人口比例增加的一种现象。老龄化程度能够反映区域内的老年人口占总人口的比重,根据人口数据,计算格网单元的老龄化程度,算式如下:
(1)
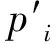
1.1.2 养老服务压力
根据山东省住房和城乡建设厅发布的《关于切实加强和改进城市规划建设管理工作的实施意见》,到2020年每千名老年人拥有的养老床位需达到40张以上,并以此作为区域养老需求的标准,结合养老设施的床位供给,分析区域的养老服务压力。
假设格网内的人口是均匀分布的,以老年人口占比为依据进行养老设施床位数的分配,结合供需关系计算各个格网的养老服务压力,算式为式(2)~(4)。
(2)
(3)
prei=Di-Bi.
(4)
1.2 量化方法与指标构建
1.2.1 量化方法
在养老设施的选址问题上,需要考虑目标区域及其附近区域基础设施的完善程度。根据养老设施与基础设施之间的相邻程度以及实际数量情况,对基础设施中的不同指标采用不同的量化方法,主要包括:近邻分析、核密度分析、缓冲区分析。
1)近邻分析。近邻分析可以计算输入要素与其他图层或要素类中的最近要素之间的距离和其他邻近性信息。
(5)
其中:Dm n表示第m个输入要素到第n个要素的距离。
2)核密度分析。核密度分析工具用于计算要素在其周围邻域中的密度。通过对输入要素进行核密度分析,计算每个输出栅格像元周围的点要素的密度,能够直观的识别研究对象的集聚和分散程度。
(6)
其中:p(x)为核密度估计值;N是范围内样本的数量;K表示和函数;h是核密度带宽;x-xk是x至xk的距离。
3)缓冲区分析。缓冲区分析就是对于给定的一个空间实体或集合,根据给定半径确定影响范围或服务范围的一种分析方法。
1.2.2 指标构建
根据基础设施的分类和目前的研究现状,从医疗服务、交通设施、金融服务、购物服务、人口因素、科教文化、风景园区等7个方面确定养老设施选址指标体系。考虑到主城区和乡镇区域基础设施的完善程度与分布情况的不同,选择的指标与量化方法存在一定程度的差异,具体如表1所示。

表1 养老设施选址的指标选择与量化
1)医疗服务。在“病有所医”的视角下,要求生活区域附近要有足够的医疗服务设施来满足日常的健康需求问题。相关研究表明,老年人的患病率高于平均水平[13],近75%的老年人至少患有一种慢性病,老年人对医疗服务设施的依赖性更强。合理的养老设施的选址能够满足老年人在享受养老服务过程中得到足够的医疗服务。本研究根据医疗设施级别的不同,将医疗设施分为两类:一类为综合医院、专科医院、急救中心、卫生院;另一类为诊所、药房。根据近邻分析法确定目标要素点到医院的最近距离。主城区诊所、药房的数量分布较多,密度较大,消费者在主城区有多项选择的权力;乡镇诊所、药房数量较少,密度较小,主要以距离较近的医疗机构来满足需求。根据核密度分析确定主城区诊所、药房的聚集程度;根据近邻分析确定乡镇目标要素点到诊所、药房的最近距离。
2)交通设施。便利的交通服务能够提高生活满意度[14],交通的通达性和交通工具的便利性是选址的重要影响因素。相关调查研究表明,多数老年人选择公交车作为出行的主要交通工具[15]。文中选择公交车站为选址指标,参考公交车站基础设施服务半径,以300 m为服务半径进行缓冲区分析,确定公交车站的服务覆盖范围,统计目标要素点所受到的公交车站服务覆盖个数,以此来量化目标要素点的交通便捷程度。
3)人口因素。老年人是养老设施的使用主体,区域内老年人口的数量能够反映对养老设施的需求程度[16-17]。文中选择以60岁及其以上的老年人口进行核密度分析,确定研究区目标要素点老年人口的聚集程度。
4)金融服务。在“老有所助”的视角下,银行网点能够为老年人提供金融服务,保护老年人的现金权益。老年人主要以银行网点的柜台服务办理业务,文中选择近邻分析法来确定研究区目标要素点到银行网点的距离。
5)购物服务。购物服务设施能够满足老年人的日常生活所需,从衣食等方面确定选址指标;农贸市场能够满足老年人日常食品所需,衣帽皮具店能够满足老年人衣物需求。基于核密度分析,确定研究区内购物服务设施的分布聚集程度。
6)科教文化。部分老年人或许承担接送小孩上学的事务[18],适当的拉近养老服务设施和幼儿园、小学的距离,利于老年人和小孩之间的互动,消除老年人的孤独感[19]。文中选择近邻分析法,确定研究区目标要素点到幼儿园、小学的距离。
7)风景园区。在“老有所乐”的视角下,城市公园、广场能够为老年人提供舒适的休憩环境,提高老年人生活的幸福感。现有研究表明,养老服务设施的布局应尽量靠近公园、广场附近区域[20]。考虑公园、广场主要分布在主城区,以近邻分析法获取主城区目标要素点到公园、广场的距离;乡镇选址不再考虑该因素。
1.3 选址模型方法
随机森林(random forest)是通过集成学习的思想将多棵决策树集成的一种算法,具有决策速度快、解释性好、泛化能力强的特点[21]。基本步骤如图1所示:从含m个样本的数据集D={(x1,y1),(x2,y2),…,(xm,ym)}中随机且有放回的抽取m次,得到1个含m个样本的采样集,经过T次采样,获取T个包含m个样本的采样集,然后基于每个采样集训练出1个基学习器,采用简单投票法确定最后的分类结果。集成学习是使用一系列的基学习器进行学习,将多个基学习器的分类结果进行整合从而获得比单个基学习器学习效果更好的学习方法。

图1 随机森林建立过程
1.4 模型构建预测与筛选
对研究区进行格网化,分别以格网中心点、现有养老设施点为输入要素,统计输入要素的指标量化值,使用分类模型中常用的归一化方法MinMaxScaler对输入要素的指标量化值进行标准化处理。文献[12]中正负样本的分类方法,以现存的养老设施为正样本,以不存在养老设施的格网为负样本,分别统计主城区和乡镇区域的正、负样本,其中正样本为正训练样本,按等比例从负样本中随机抽样,将抽样结果作为负训练样本。对训练样本进行训练,分别得到主城区、乡镇的选址模型。以格网中心点为输入要素,统计主城区和乡镇的输入要素的指标量化值,并进行标准化,将其作为预测样本,并输入到各自的选址模型中进行空间预测,获得适宜选址区。根据自然断点法对有压力的格网进行分类,顾及格网人口老龄化程度和养老服务压力,对预测结果进行筛选与等级划分。
2 实验与分析
2.1 研究区概况与数据源
2.1.1 研究区概况
本研究以山东省滨州市滨城区为实验区进行养老设施选址研究。如图2所示,该地区位于37°12′~37°41′N、117°47′~118°10′E之间,总面积达697.49 km2,共辖12个街道、2个镇、1个乡。根据第七次人口普查数据,滨城区的常住人口为629 552人,60岁及其以上人口占18.61%,且乡镇范围的老龄化程度高于主城区。至2021年,滨城区已建成151家养老机构、拥有7 534张床位,收住老人2 195人、从业人员807人。

图2 研究区概况
2.1.2 数据源与预处理
研究中使用的POI数据来自网络爬取,它能体现一个城市中基础设施的数量和空间位置。养老设施数据来自滨州市民政局,其设施包括养老院、日间照料中心、幸福院;属性信息包括设施的床位数、收住老人、从业人员等信息。常住人口数据由公安部门提供,以2021年7月12日为截止日期统计滨城区60岁及其以上的人口(老年人口),将人口数据统计到400 m格网单元中(图3)。参考《国土空间规划城市体检评估规程》[22]中体检评估指标说明,以300 m为服务半径确定主城区养老设施的服务范围,以1 000 m为服务半径确定乡镇养老设施的服务范围。
2.2 实验结果
2.2.1 格网单元
1)格网老龄化程度。以400 m分辨率的格网对滨城区进行格网老龄化统计,通过格网老龄化的统计,可以获取局部区域内老龄化程度。
2)格网养老服务压力。在考虑供需关系的条件下,以400 m分辨率的格网为基础研究单元对滨城区进行格网养老服务压力统计,可以获取局部区域内养老服务的压力。

图3 格网单元的人口分布
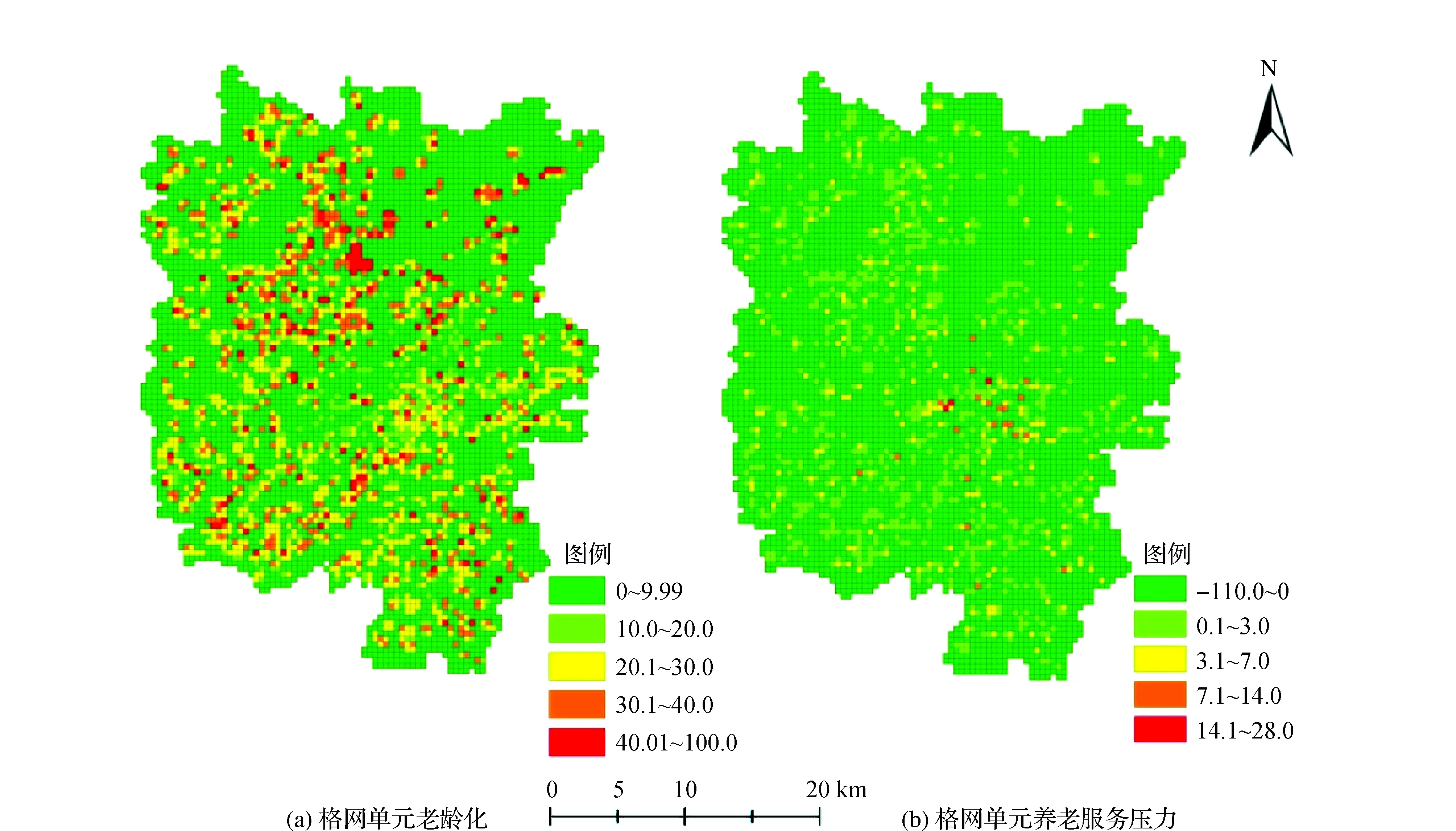
图4 格网单元
2.2.2 指标权重
通过随机森林算法对主城区、乡镇分别构建选址模型,其正确率分别为89.83%、90.72%,权重结果如表2所示;由权重值可以发现老年人口数量是影响主城区养老设施选址的主要因素,而乡镇养老设施的选址则是优先考虑与基础设施相近的区域,这说明在乡镇基础设施不完善的条件下,养老设施的选址优先选择基础设施较完善的区域。
2.2.3 预测与结果筛选
通过选址模型对主城区、乡镇分别进行选址预测,得到适宜选址区,如图5(a)所示,从图中可以发现,主城区内适宜建设养老设施的位置相对较多,乡镇适宜区相对较少;初步预测的适宜区范围较大,给选址决策带来了一定程度的困扰。因此,需要考虑格网老龄化程度和养老服务压力对初步预测的结果进行进一步筛选;顾及城乡养老设施发展的均衡性问题,分别对主城区、乡镇的选址结果进行筛选,以划分两级需求适宜区为目标,通过自然断点法分别对主城区、乡镇的养老服务压力进行分类,其中主城区以“7”为中断值,乡镇以“4”为中断值;结合老龄化程度对选址结果进行级别划分,划分标准如表3所示。

表2 主城区、乡镇选址指标的权重

表3 预测结果的等级划分

图5 滨城区养老设施选址结果
通过筛选条件,将选址结果划分为主城区一级需求适宜区、二级需求适宜区,乡镇一级需求适宜区、二级需求适宜区,如图5(b)所示。该划分的结果顾及了老龄化程度和养老服务压力,均衡了城乡养老设施的决策布局,根据实际规划可以优先选择一级需求适宜区作为最终的决策结果。
3 结束语
参考目前养老设施选址的研究现状,利用POI数据与随机森林算法研究了养老设施的选址问题,并提出了一种顾及老龄化程度和养老服务压力的选址结果筛选标准,最终得到不同等级的选址结果。该选址方法考虑了主城区和乡镇区域基础设施条件的差异性,并分别进行了选址预测,由选址指标权重可以发现,主城区和乡镇选址存在一定的差异性。以滨城区为例验证了选址方法和筛选方法的可行性,为未来城市养老服务设施选址提供参考。
研究中也存在一定的不足,文中所使用的养老设施服务范围是参考标准[22]所确定的,实际情况可能会与标准存在一定的差异,养老服务设施的影响范围还需进一步研究。
