基于拉曼光谱和机器学习的百合分类识别
2023-02-01王志新王慧荟张文波李月娥
王志新,王慧荟,张文波,王 忠,李月娥
兰州大学信息科学与工程学院,甘肃 兰州 730000
引 言
百合是百合科(Liliaceae)百合属(Lilium)植物, 其多年生草本球根生长的肥厚鳞片构成的地下变态茎称为百合鳞茎[1]。甘肃兰州、江苏宜兴、江西万载等地栽培百合鳞茎的历史悠久, 其产量、质量与产地有密切联系[2-3]。百合鳞茎有着高蛋白、低脂肪的特点,是十分理想的保健食品,同时百合鳞茎具有广泛的药理作用, 如抗肿瘤、抗抑郁、降血糖、提高免疫力等[4-5],产地不明或混淆使用会导致百合制品的质量不稳定,影响药理作用的发挥[6]。因此,实现精准产地和质量鉴别分析对促进百合鳞茎市场化发展具有重要意义。
传统检验依赖感官经验,通过外观、色泽、滋味及香气等感官指标实现产地和质量的鉴别分析,但当前市面上的百合品种众多,又存在种植条件和存储方式不同导致的外在差异,导致基于人工经验的感官评审模式无法实现快速、精确、无损的检测[7]。目前,除了传统的检验方式以外,还可用大型仪器结合化学计量学分析的方法,如高效毛细管电泳法(HPCE)[8]、高效液相色谱法(HPLC)[5]、液相色谱质谱联用法(LC-MS)、液相二级质谱法(LC-MS-MS)[9]、气相色谱法(GC)[10-11]等。袁志鹰[12]等采用傅里叶变换衰减全反射红外光谱(ATR-FTIR)技术采集百合的红外光谱,并使用层次聚类分析(HCA)区分几类百合粉末。上述方法样品前期处理过程复杂,操作繁琐且耗时长,会产生较高的现场仓储成本及检测成本,不能无损检测而且难以满足产地鉴别这一要求[13]。
拉曼光谱(Raman spectroscopy)是一种基于振动分子对光的非弹性散射的光学技术,基于拉曼光谱可以提供细胞、组织或生物液体的化学指纹图谱,做快速准确的无损检测,相比于其他光谱技术,拉曼光谱对水的敏感性较低,检测过程不易受到水的干扰,这为含水生物样本的检测提供了很大的方便性,现已在农牧业生产过程中获得广泛的应用[14-17]。
研究将拉曼光谱与机器学习算法相结合,建立了我国分布最为广泛的三种百合鳞茎(兰州百合、宜兴百合和龙牙百合)的产地分类模型,提出了一种基于拉曼光谱的成分含量定量估计的方法。采用了人工先验方法、主成分分析和t-分布随机邻域嵌入三种方法提取光谱数据特征,并分别应用到支持向量机、决策树和随机森林等算法。此外,拉曼光谱数据结合机器学习算法可以快速识别和鉴定百合鳞茎的产地,可为现代化生产的产地鉴别和百合鳞茎质量分析提供新方法。
1 实验部分
1.1 仪器
研究所用波长为532 nm激光(Verdi v-6)作为激发源的Alpha共聚焦拉曼显微镜系统(WITec,德国)和配备Pixis Spec 10-100× CCD相机(Princeton Instruments,Trenton,NJ)的ACTON 300i光谱仪采集拉曼光谱。激光束通过蔡司LD EC Epiplan-Neofluar 50×物镜(NA=0.55)聚焦到样品中(日本尼康)。
1.2 样本采集
样本选取甘肃省兰州市的兰州百合、江西省万载县的龙牙百合和江苏省宜兴市的宜兴百合,按照百合鳞茎采挖时间和保存情况进行分组,样本信息如表1所示。

表1 样本信息
百合鳞茎在采摘后通常冷藏贮存,为了模拟真实的过程,所有的样品存放于(3±0.5)℃的冷藏室中。百合鳞茎的所有内部鳞片样品都取自百合的中心鳞片上,选择较平整位置,用刀片切下厚度约为2 mm的组织,紧贴于载玻片上。
1.3 光谱采集
首先用单晶硅片作为待测物对光谱系统进行校准,然后选取激光功率为10 mW,单点测量积分时间为5 s,积分次数为3次。对每一个样品随机选取多点进行测量获取数据集,每次测量时调整位置使激光光斑进入样品内部的深度相同。对于单光谱测量的样品,调整到合适的视野后随机选取约10个点,计算这些光谱的平均谱,将其作为该样品的典型拉曼光谱。
1.4 光谱数据预处理
由于存在背景噪声、人工操作因素以及受到样品自身相关性质的影响,拉曼光谱上会表现出冗余的信息,荧光、噪声、宇宙射线等都会影响分析结果。因此,初次采集到的原始拉曼光谱需要进行预处理操作。
除宇宙射线(CRR)和波数校准使用WITec共聚焦拉曼光谱仪的同系列软件Project FIVE,随后采用四阶多项式拟合法基本上去除了荧光背景,机器学习过程中对所有的光谱进行归一化处理,使光谱的强度均落在[0,1]之间,其计算公式为
(1)
最后,去除光谱中非拉曼光谱的部分,即完成了拉曼光谱预处理,整体流程如图1所示。

图1 拉曼光谱预处理过程
2 结果与讨论
2.1 拉曼光谱采集及预处理
选取三大百合鳞茎产区的20份样本(表1)进行光谱采集,并进行了光谱数据预处理,典型拉曼光谱如图2所示。
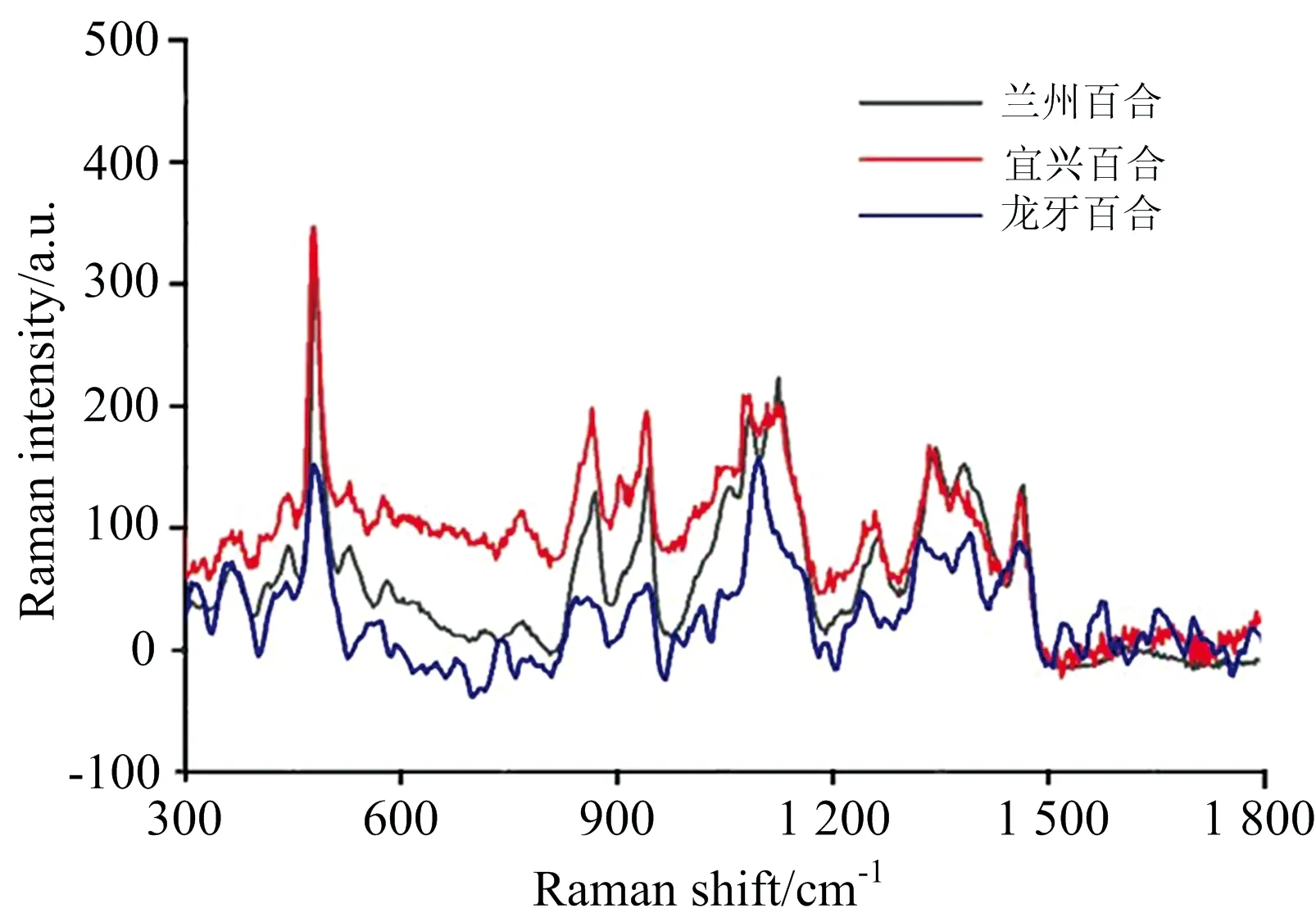
图2 三种百合鳞茎的典型拉曼光谱
2.2 光谱数据降维及特征提取
百合鳞茎的拉曼光谱中的波长范围较大,重点区域含有1 650个波长点,建模难度较高。这些特征峰之间存在一定的相关性,因此首先对数据进行特征提取来降维运算。
首先归纳了百合鳞茎的光谱和物质对应特点,使用了人工提取法确定代表物质,通过对国内外学者在植物组织中的糖类、蛋白质类、脂类、氨基酸类等物质的研究文献进行分析比较,提取出样品拉曼光谱中各个特征峰的波数和强度等信息,归纳了百合鳞茎的拉曼光谱中出现的特征峰以及其对应的化学键和物质种类,详见表2。
经过筛选,本研究选取了光谱数据中的27个特征,拉曼位移分别为436,479,518,520,525,832,874,876,896,942,952,1 054,1 082,1 096,1 120,1 127,1 262,1 265,1 320,1 343,1 374,1 382,1 455,1 457,1 606,1 635和1 640 cm-1。
将获得的特征使用主成分分析(principal component analysis, PCA)和t-分布随机邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)进行特征提取。
主成分分析是一种常见的降维方法,对三类百合鳞茎样品的拉曼光谱数据进行特征提取。各主成分的贡献率及累积贡献率如图3所示, 第一主成分PC1和第二主成分PC2的贡献率分别为42.06%和20.56%,前6个主成分累积贡献率达到了81.33%。
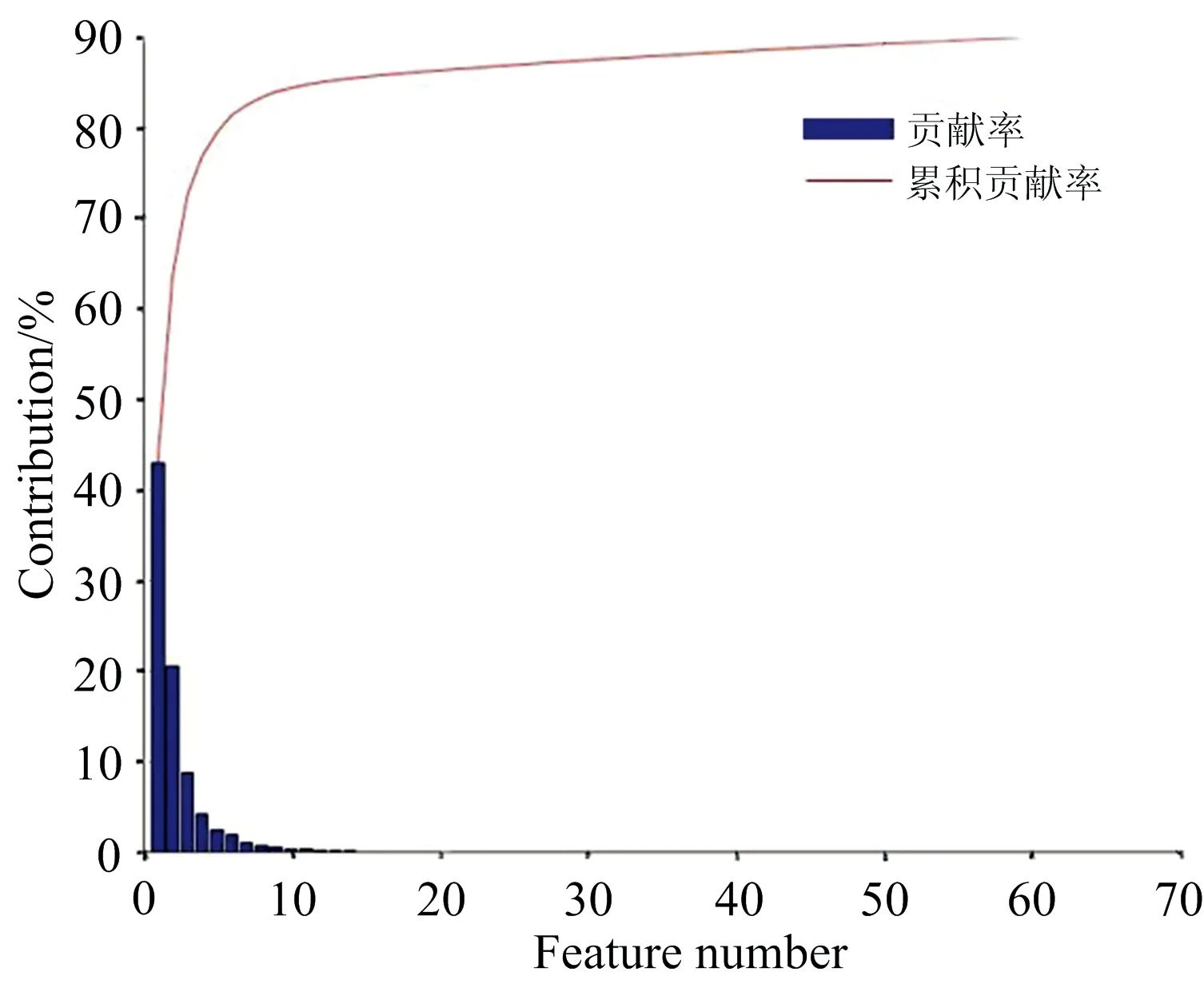
图3 三种百合拉曼光谱各个主成分的贡献率和累积贡献率
t-分布随机邻域嵌入是一种无监督降维方法,本研究执行t-SNE时选取参数值:嵌入空间维度为2,困惑度perplexity=30,数据初步降维的PCA维度为50。利用t-SNE算法对上述三种百合的拉曼光谱数据进行降维。
2.3 模型建立过程
采用了不同的算法对三种百合共1690个样本的拉曼光谱进行了特征提取,包括兰州百合数据500条、宜兴百合数据650条、龙牙百合数据540条。
使用“留出法”将采集到的数据集分为两个互斥的集合,其中一个作为训练集,另一个作为测试集,两者保持数据分布的一致性。本研究采用k折交叉验证法和“留一法”(leave-one-out, LOO)进行模型训练,将训练集S平均分成k份,轮流将其中的k-1份作为训练集,剩下的一份作为验证集,训练k次后的平均验证误差作为该模型的误差。
上述1 690条数据,其中1 260条数据作为训练集,剩下的430条作为测试集。以5折交叉验证为例,数据集的划分及训练过程如图4所示。
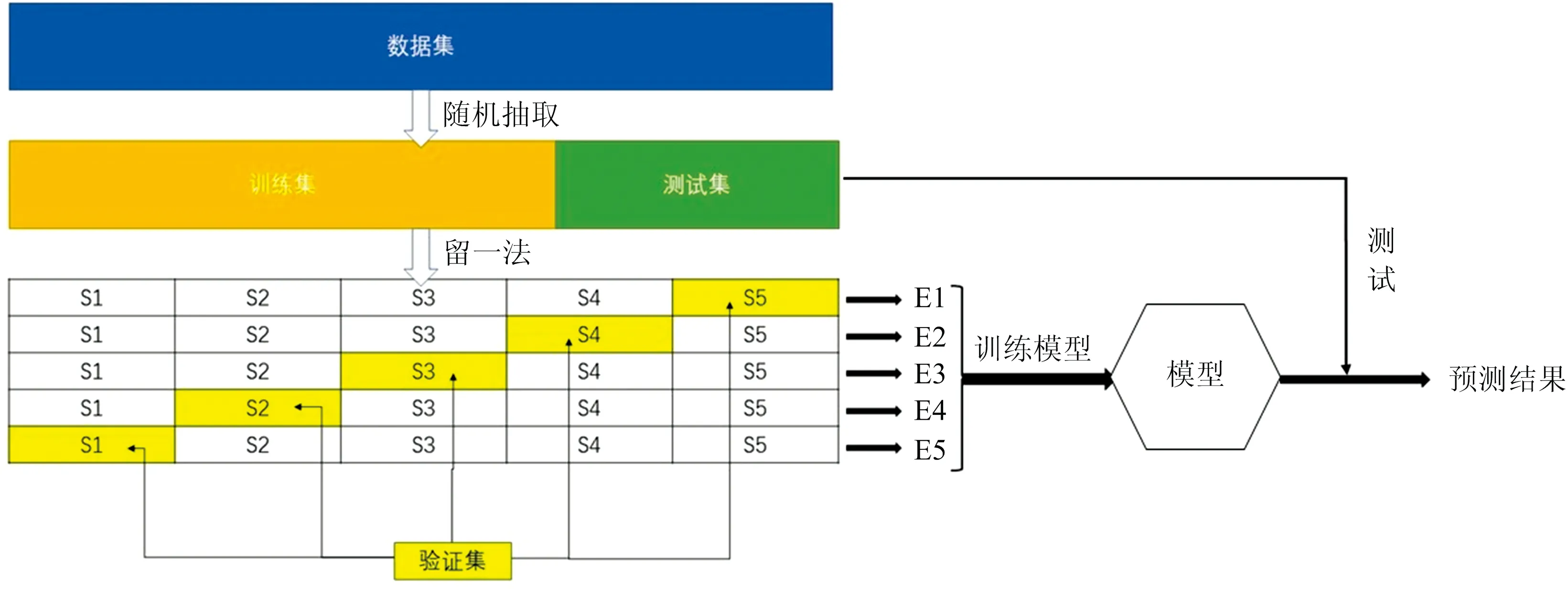
图4 数据集的划分和训练示意图
2.4 基于支持向量机的分类模型
支持向量机(SVM)是一种基于结构风险最小化准则的线性分类器,分别使用人工先验方法提取的特征、PCA提取的主成分和t-SNE提取的特征建立百合分类的SVM模型。
使用人工先验方法提取的27个特征,建立百合分类的SVM模型。将训练集的光谱数据作为自变量,使用参数为γ的径向基函数(RBF)作为核函数替换实例和实例之间的内积,定义为
K(xi,xj)=exp[-γ‖xi-xj‖]2
(2)
最优判别函数为
(3)
式中,sgn为阶跃函数,x为输入的特征向量;xi为输出的第i个支持向量。
在进行分类时,首先需要通过训练确定核函数参数γ和误差项惩罚因子C,使得模型训练正确率最高。ζ为松弛变量,ζ和γ都是为了解决线性不可分问题,在SVM模型中C和ζ为模型精度的决定因素。
经过多次实验表明,当C∈(22, 23),γ∈(2-2,1)时模型训练精度较高,在此范围内确定超参数,结果如表3所示。显然,当C=6、γ=0.9时,分类模型性能最好,此时训练分类正确率为91.2%,测试集的分类正确率为89.1%。
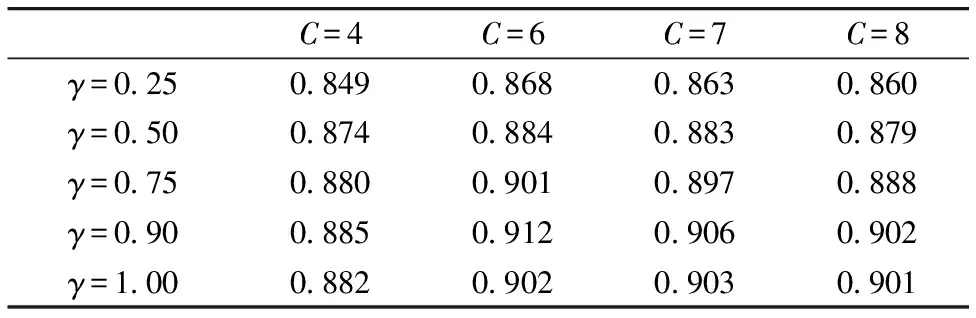
表3 不同超参数组合下的SVM模型训练精度
利用PCA提取的前60个主成分,建立百合分类的SVM模型。首先用同样的网格搜索方法确定超参数,经多次实验得最佳参数为C=7,γ=1.3,此时训练准确率为96.8%。随后选取不同的主成分个数进行五折交叉验证,结果如图5所示,选取PCA的前22个主成分作为输入时,测试数据的分类正确率最高,达到了91.2%。

图5 基于PCA特征提取的SVM模型分类正确率
利用t-SNE提取的特征,建立百合分类的SVM模型。仍然使用同样的网格搜索方法确定超参数,经多次实验得最佳参数为C=92.2,γ=512,此时模型训练准确率为95.7%,测试集的分类正确率为93.7%,与前两种特征提取方法相比,正确率有了明显的特高。
2.5 基于决策树的分类模型
为了进行对比,本研究采用决策树算法进行百合分类模型的训练。经过多次实验,基于人工先验的特征提取方法应用于决策树模型时最佳参数lAP=13,基于PCA的特征提取方法应用于决策树模型时最佳参数lPCA=13,基于t-SNE的特征提取方法应用于决策树模型时最佳参数lt-SNE=17,如图6所示。在最后进行剪枝优化后,基于人工先验的特征提取方法的决策树分类模型正确率为78.8%,基于PCA的特征提取方法的决策树模型正确率为91.7%,基于t-SNE的特征提取方法的决策树模型正确率为86.7%。
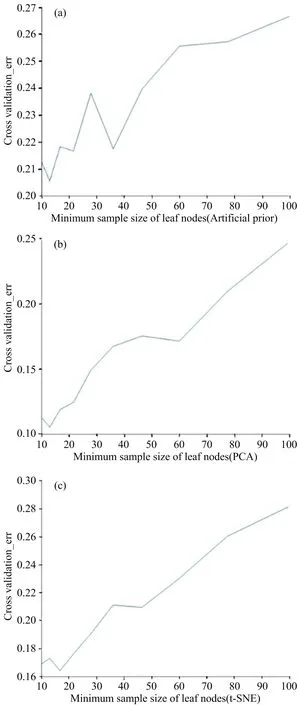
图6 叶子节点的最小样本数对决策树性能的影响
2.6 基于随机森林的分类模型
决策树算法进行分类时思想十分朴素,分类速度较快,但这也决定了它的泛化能力较弱。因此,本研究建立了基于RF算法的三种百合光谱数据分类模型。
利用人工先验方法提取的27个特征,结合RF进行模型训练。采用五折交叉验证结果表明,人工先验的特征结合RF分类模型在测试集上的最高正确率为90.2%;选取不同的PCA主成分个数,并结合RF进行分类模型训练,选择前8个主成分作为分类模型的输入时,在测试集数据上的平均正确率为95.8%,且选取更多主成分时,准确率的提升不再显著;利用t-SNE提取的特征,结合RF进行分类模型训练,采用五折交叉验证多次实验表明,模型的平均预测准确率为90.7%。本处展示效果最佳的基于PCA特征提取的RF模型,如图7所示。
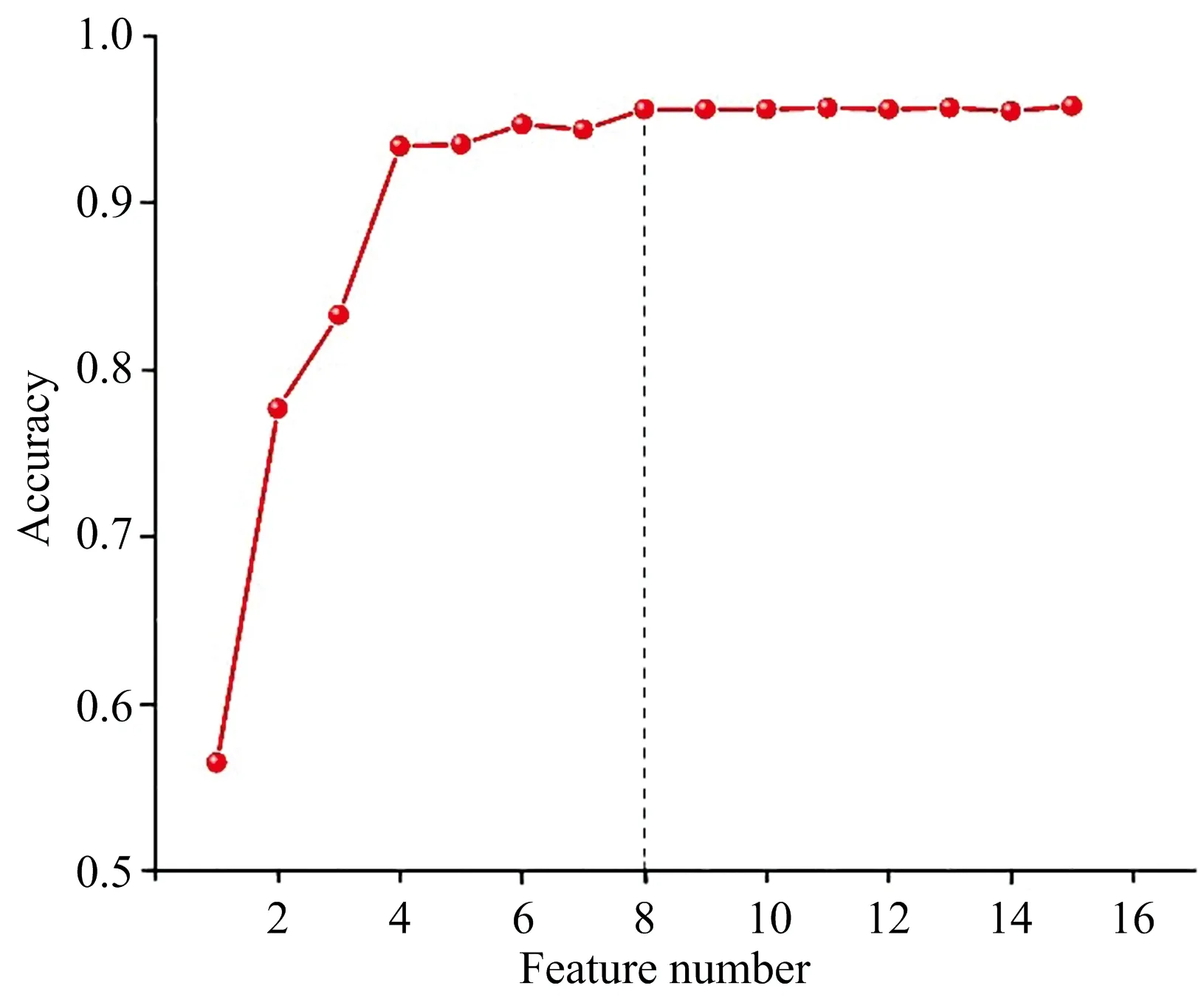
图7 基于PCA特征提取的RF模型分类正确率
2.7 模型准确性评估
在分类问题中,精度(accuracy)、查准率(precision)、召回率(recall)和F1分数是最常见的性能度量值,反映了使用该模型进行分类预测时的基本表现情况。
若将预测为1的样本称为阳性(positive),预测为0的样本称为阴性(negative),对比模型预测的类别和测试集样本的真实类别,所有测试集样本可以分为真阳性(true positive,TP)、假阳性(false positive,FP)、真阴性(true negative,TN)和假阴性(false negative,FN)。
将正确率Acc、查准率P和召回率R定义为
(4)
(5)
(6)
由此可见,查准率是指所有被模型预测为阳性的样例中,有多少预测正确;查全率是指所有实际为阳性的样例中,有多少被预测出来,也就是敏感性(sensitivity)。这两个指标实际上是相对矛盾的,为了调和P和R,我们引入了F1分数,表示为
(7)
化简,得
(8)
在本研究中,每个模型都可以得到三个混淆矩阵,分别计算得到三组P和R,计算各自的均值,得
(9)
(10)
(11)
三种特征提取方法和三种机器学习算法相结合,建立了共9种百合拉曼光谱分类模型,在同一个测试集上的分类精度如表5和图8所示,当采用基于PCA提取的前8个主成分结合RF建立百合分类模型时,计算量较小且准确率最高,达到了95.8%。
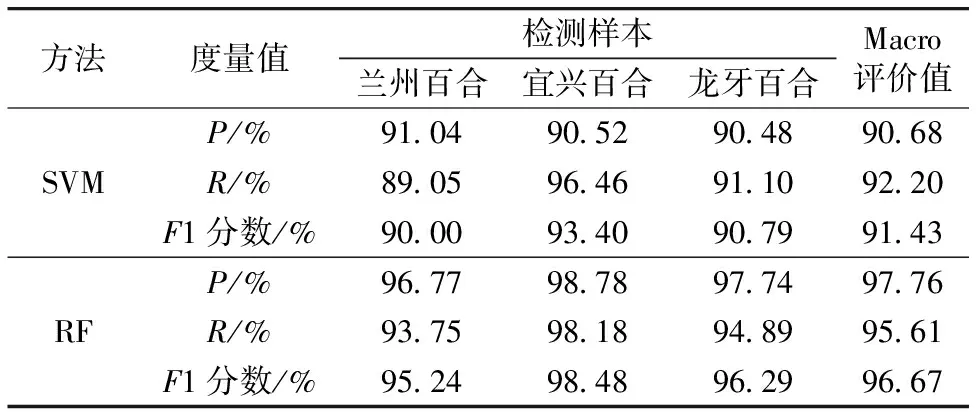
表4 不同模型方法组合下的模型评价结果
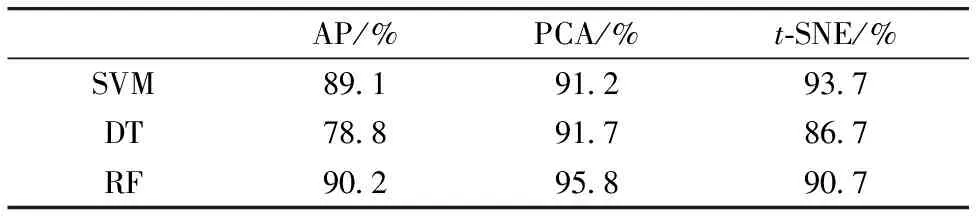
表5 所有模型的分类准确率
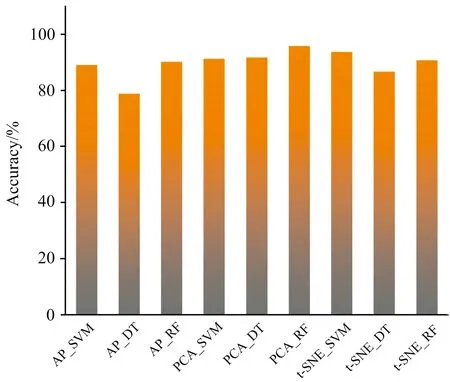
图8 所有模型的分类准确率对比图
3 结 论
基于三种百合在400~2 000 cm-1拉曼谱峰信息,将拉曼光谱与机器学习算法相结合,提出了现场快速识别和鉴定百合鳞茎产地的方法模型。实验结果表明该模型可以有效鉴定百合鳞茎质量,筛选不同产地样本的特征,为百合鳞茎的产地鉴别及溯源分析提供新思路。
