基于多尺度融合的自适应无人机目标跟踪算法
2023-01-31薛远亮金国栋谭力宁许剑锟
薛远亮,金国栋,谭力宁,许剑锟
火箭军工程大学 核工程学院,西安 710025
无人机(Unmanned Aerial Vehicle,UAV)因其操作简单、体积小和成本低等优势,在民用和军用领域都有着广泛的应用。特别是在智能化趋势的大背景下,目标跟踪成为了无人机应用的关键技术,也是其他后续任务(如:目标定位、目标精确打击等)的基础工作。视觉目标跟踪是计算机视觉领域中一个具有挑战性的问题,用于估计视频序列中每一帧跟踪目标的状态,而这跟踪目标的位置只在第一帧中给出。随着无人机执行任务的难度不断加大,研究准确高效且稳健的目标跟踪算法对于无人机的应用有着广泛的意义。
与地面平台相比,无人机视角下的目标主要有尺寸小、像素点少、尺度变化大、背景干扰严重、相似目标较多等特点,并且无人机飞行过程中容易出现相机抖动和飞行速度变化,造成目标出现模糊和形变等情况,都对无人机上的目标跟踪算法提出了更高的要求。目前主流目标跟踪算法分为基于相关滤波的跟踪算法(简称为:相关滤波跟踪算法)和基于孪生神经网络的跟踪算法(简称为:孪生跟踪算法)。相关滤波跟踪算法:利用信号处理领域的相关滤波用来计算目标模板与后续搜索区域的相关性,实现对目标的持续跟踪。因为相关滤波的计算是频域中完成的,所以运算量大大减少,提高了运算速度。但是大多数相关滤波算法都是使用传统特征提取算法来表征跟踪目标,鲁棒性和准确性不够[1],不能有效应对无人机场景下的目标跟踪任务。
近年来,卷积神经网络(Convolutional Neu⁃ral Networks, CNN)提取的深度特征鲁棒性好、表征能力强,在目标跟踪领域中渐渐取代了传统手工设计的特征。孪生实例搜索算法(Siamese Instance Search Tracker, SINT)[2]创 造 性 地 将孪生神经网络用于度量模板图像与搜索图像的相似度,为目标跟踪领域提供了新思路。考虑到SINT的全连接层对图片尺寸的限制,全卷积孪生跟踪算法(Fully-Convolutional Siamese Net⁃works, SiamFC)[3]设计的全卷积孪生神经网络,避免了候选图像块的多次输入,提高了跟踪速度。同时提出的互相关运算,将模板图像作为卷积核与搜索图像进行卷积,进一步精确目标位置。语义外观双分支跟踪算法SA-Siam[4]发现SiamFC浅层神经网络提取的特征缺乏语义信息,又加入一条卷积神经网络作为语义分支,独立训练的2条分支提取的特征信息是相互补充的,能提升SiamFC的鲁棒性。孪生区域建议跟踪 算 法SiamRPN (Siamese Region Proposal Network)[5]抛弃了耗时的多尺度搜索策略,引入区 域 建 议 网 络[6](Region Proposal Network,RPN)完成对目标的尺度估计和目标定位,实现了精度与跟踪速度的平衡,性能已超过绝大部分相关滤波算法且跟踪速度高达160 frame/s(Frames Per Second, FPS),证明了孪生跟踪算法的巨大潜力,从此成为了目标跟踪的主流算法。RPN模块中预定义一组大小、尺寸不同的锚框(Anchor),快速有效地估计出目标的尺度变化。级联孪生区域建议算法C-RPN[7]认为单个RPN模块的估计能力是有限,于是级联多个RPN模块用于精确目标的尺度估计。Siam⁃RPN++[8]同样在深层网络ResNet-50[9]上使用多个RPN模块,利用不同层的特征信息来提高尺度估计的能力,在多个数据集上取得第一。
针对无人机平台的目标跟踪算法主要有:刘芳等[10]使用自适应分块策略,通过计算前后两帧分块的收缩系数来应对目标的尺度变化。同样针对无人机过程中的尺度变化、遮挡等特点,刘贞报等[11]通过旋转不变约束改进深度置信网络,使得模型能够自动适应目标的形态变化,但跟踪速度仅为12.6 frame/s,不满足实时性要求(≥30 frame/s)。为了解决目标的外观变化,文献[12]利用高斯混合模型建立模板库并更新匹配模板,模板库有效提高了准确率但降低了跟踪速度,不能满足实时性要求。
综上所述,基于锚框的跟踪算法需要跟踪过程中的目标信息作为先验信息,而无人机过程中的目标有着尺寸小、尺度变化大、相似物体多、运动模糊等特点,这些特点是随机出现的,不可能提前预知。因此提出一种基于多尺度注意力模块和特征融合的自适应无人机航拍目标跟踪算法。首先,在ResNet-50网络中平行堆叠具有相同拓扑结构的卷积块以提取目标的多样化特征,在不增加网络深度的情况下增强对跟踪目标的表征能力;其次,设计多尺度注意力模块,全局、局部注意力的结合使用既抑制了干扰信息又提高了对大、小目标的感知能力;然后使用注意力特征融合模块整合浅层的细节信息和深层语义信息;最后,级联使用基于无锚框策略的RPN模块,逐像素预测目标并将预测结果加权融合,精确、自适应地感知目标的尺度变化。实验证明:提出的算法能更有效地感知无人机跟踪过程中目标的尺度变化、外观变化,同时对小目标识别能力和抗干扰能力也有所增强,并且速度达到40.5 frame/s,足以胜任无人机实时跟踪任务。
1 相关工作
1.1 残差模块
He等[9]通过堆叠残差模块(ResBlock)来构建深层网络ResNet,为了避免网络加深而导致产生的梯度爆炸或消失,在ResBlock中设计映射连接(Identity)以确保信息的有效传递,避免网络出现退化现象。残差模块ResBlock如图1所示,由残差部分和映射连接组成,其中分别为第l层残差模块的输入和输出;conv1*1,256,64代表大小为1,输入、输出通道数为256和64的卷积层,conv1*1完成对特征图的通道升维和降维,conv3*3主要提取特征图的特征信息。
式(1)为残差模块的具体原理,映射连接将网络学习x[l]到x[l+1]映射的过程巧妙地转化为学习残差部分的映射。随着网络层数的加深,相比于学习整个映射过程,网络更容易学习残差部分的映射,有效提升网络的训练效果。
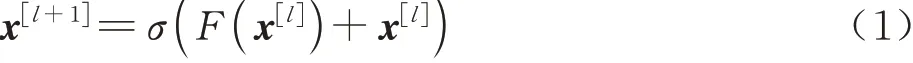
图1 残差模块Fig. 1 ResBlock
1.2 注意力机制
人类形成的视觉往往不是一次性处理整个场景得到的,而是通过一系列的局部观察将注意力放在感兴趣的目标上[13]。神经网络中的注意力机制类似于人类的视觉过程,通过一系列操作为特征图进行权重分配,感兴趣的目标区域获得更大的关注度,实现特征信息的筛选,抑制无关信息的干扰,将神经网络的注意力时刻保持在感兴趣的目标上。注意力主要分为空间注意力和通道注意力,分别从空间和通道维度筛选特征信息。
空间注意力帮助网络关注目标在哪里(Where):非局部注意力[14](Non-local attention)是受到图像处理中非局部均值滤波的启发,为神经网络设计的自注意力机制,能帮助捕获时空长程依赖。Non-local即自注意力机制,其核心思想如式(2)所示:首先考虑特征图的所有位置xj与当前位置xi之间的关系f(xi,xj),再对所有位置的关系进行加权求和得到当前位置的值yi。但是非局部注意力的计算量大,限制其广泛使用。
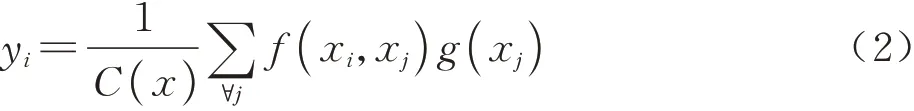
式中:f(xi,xj)用于计算两点之间的相似性;g(xj)是一个一元函数,用于信息变换;C(x)是归一化函数,保持变换前后的信息整体不变。
通道注意力更多的是帮助网络关注目标是什么(What):SE[15](Squeeze-and-Excitation)模块原理如式(3)所示,首先使用全局平均池化(Global Average Pooling, GAP)压缩空间维度的特征信息,获得每个通道的全局空间表示zc,两层全连接层再利用这个空间表示学习到通道权重s。SE模块使网络有效学习到不同通道的重要程度,同时因其计算量小,至今仍广泛应用在计算机视觉的各个领域。
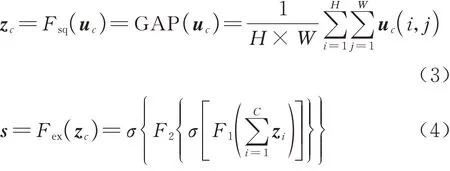
式中:uc(i,j)为每个通道c上的特征图,其中i,j为特征图上像素点坐标,c∈C;H、W是特征图的高度和宽度;Fsq、Fex分别代表对特征图的压缩(Squeeze)操作、激励(Excitation)操作;zc为压缩后的全局空间表示,其中每个通道上的空间表示为zi;F1、F2是全连接层操作;σ(⋅)为激活函数。
2 基于多尺度融合的自适应孪生跟踪算法
基于孪生神经网络的跟踪算法将跟踪任务看作目标模板与搜索图像的相似度度量问题,如式(5)所示,主要由3个部分组成:以孪生神经网络ϕ(⋅)为主的特征提取部分、以深度互相关运算“*”为主的相似度度量部分和区域建议网络(RPN)模块构成的跟踪结果生成部分。特征提取部分由模板分支与搜索分支组成,模板分支输入视频序列第一帧z,提取目标特征作为模板特征ϕ(z),搜索分支输入视频后续帧x,提取搜索区域的特征作为搜索特征ϕ(x);互相关运算用于整合两条分支的特征信息,计算搜索特征图与模板特征图的相似度,生成相似度响应图f(z,x);跟踪结果生成部分根据响应图来预测搜索图像上的目标位置,一般认为最大响应位置即为目标预测位置,RPN模块然后在预测位置进行目标尺度估计和边界框回归。
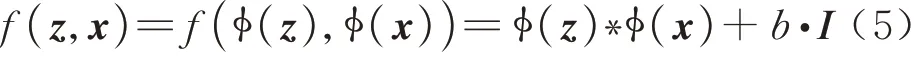
式中:b为响应图每个位置上的偏差值;I为单位矩阵。
算法的网络结构如图2所示,首先使用平行堆叠了多个卷积的ResNet-50,以提取多样化特征 信 息(Diverse Feature ResNet-50, DFResNet);其次设计多尺度注意力模块(Multi Scale Attention Module, MS-AM),有效保留了不同尺度的目标特征,提升对大、小目标的识别能力;然后在多尺度特征信息的基础上提出注意力特征融合模块(Attention Feature Fusion Mod⁃ule, AFFM),整合不同层的注意力特征信息,保留了丰富的语义信息和细节信息;最后级联使用基于无锚框策略的RPN模块(Anchor-Free Re⁃gion Proposal Network module, AF-RPN)完成跟踪目标的分类、回归,提高对目标的自适应感知能力。
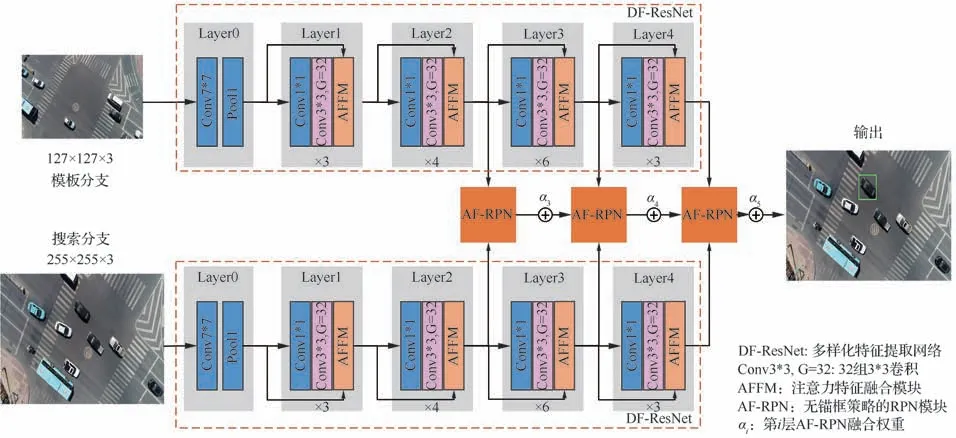
图2 网络结构Fig. 2 Architecture of network
2.1 多样化特征提取网络DF-ResNet
浅 层 特 征 网 络Alexnet[16]和VGG[17]通 常 提取物体的外观特征和细节信息(颜色、纹理和轮廓等),而缺少物体的语义特征信息。相比于形象的外观特征信息,抽象的语义特征信息表征物体能力更强、鲁棒性更好。特别是无人机视角下的场景复杂,含有较多的背景干扰和相似物体,浅层特征信息难以应对上述情况,限制了SiamFC[3]、SiamRPN[5]等算法的性能提升。提取语义信息的通常做法是增加网络的深度或者宽度(ResNet-101),但是这样大幅增加网络参数会严重影响运算速度,不适合无人机目标跟踪任务。而文献[18]指出:相比于增加网络层数,增加网络的基数(Cardinality)更能有效地提高网络的特征描述能力,同时还不会增加网络参数量。因此本文选择在网络层数较深的ResNet-50上增加基数来提高网络性能。
借鉴文献[18-19]的分组-转换-融合(Split-Transform-Merge)的设计思想,如图3所示:考虑到残差模块中的conv3*3才是特征信息的主要提取部分,因此将残差模块中的conv3*3替换成平行堆叠多个相同拓扑结构的卷积层组。图4(a)为普通卷积的卷积过程,可以看出:输出特征图的一个通道需要输入特征图的所有通道参与计算。图4(b)为平行堆叠操作的实现过程,通过分组卷积(Group convolution)将通道数为64的conv3*3分为32组通道数为4的conv3*3。不同的卷积层组可以看作是不同的子空间(Subspace),每个子空间学习到的特征信息是各有侧重、互不相同的,即提取了目标的多样化特征信息。
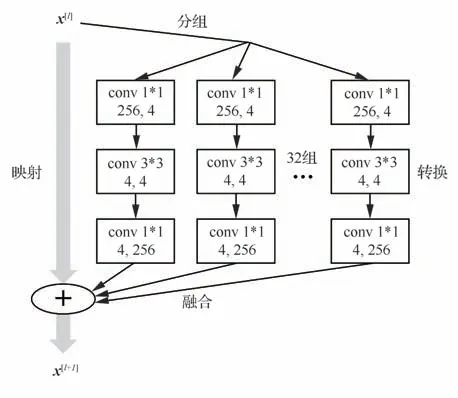
图3 DF-ResNet的ResBlockFig. 3 ResBlock of DF-ResNet
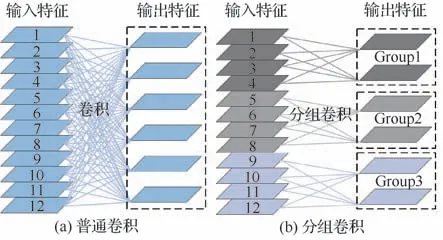
图4 卷积过程Fig. 4 Convolution process
图5为部分卷积层组的可视化结果,每个卷积组代表着一种特征,有的倾向于直线特征、而有的则倾向于圆形特征,并且相邻通道的卷积层组的特征类似。若图像中的某块区域越像该卷积层组,则该区域的卷积结果就越大。证明了子空间学习思想是合理的,每个子空间代表着不同的特征信息并且这些特征信息很多都是不相关的,不需要组合所有通道进行学习,只需要相邻通道的子空间来学习相关的特征。因此DFResNet的特征描述能力得到有效增强,相当于间接增加了网络深度并且还不会降低跟踪速度,能够有效地应对无人机跟踪过程中的外观变化、复杂背景和相似物体干扰等挑战。
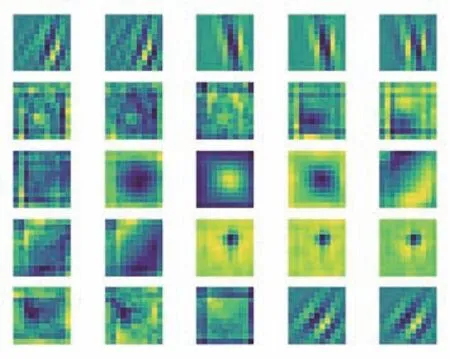
图5 卷积层组可视化Fig. 5 Convolutional group visualization
2.2 多尺度注意力模块MS-AM
由于无人机的视角范围广、场景大,视野中容易包含许多与跟踪目标相似的干扰目标。改进的DF-ResNet提取了跟踪目标的多样化特征信息,能增强对目标的表征能力。而DF-ResNet的不足之处在于:①对特征图上每个空间位置给予相同的重视程度,不能有效区分跟踪目标与其他目标;②文献[8]发现特征图是具有正交特性的,即不同通道上的特征图代表了不同语义信息的物体。而DF-ResNet特征图的各个通道对于后续相似度计算的贡献度都是一样的,不适用于跟踪特定目标的跟踪任务。对于跟踪任务来说,空间和通道维度上的特征图都需要有选择性地分配权重和筛选。DF-ResNet提取了许多干扰目标的特征信息,跟踪算法如果未能有效区分跟踪目标与干扰目标的特征信息,容易将干扰目标错认为跟踪目标,从而产生跟踪漂移现象。
注意力模块因其能自适应分配权重、有选择性地筛选特征图信息,从而帮助网络更好地关注感兴趣的目标,能有效弥补DF-ResNet的不足。以SE[15]模块为代表的全局通道注意力模块,因其全局平均池化(Global Average Pooling,GAP)会造成空间上特征信息的丢失,不利于感知小目标[20]。文献[21-22]都选择级联使用通道、空间注意力来提高算法对目标的多尺度感知能力,但是会过多地增加算法的计算负担。考虑到无人机视角下目标尺寸小、特征信息少以及计算能力有限的特点,借鉴文献[20]设计了一种轻量化多尺度注意力模块(Multi-Scale Attention Module,MS-AM),提高对目标的多尺度感知能力。多尺度注意力模块的结构如图6所示,包括全局通道注意力(Global Attention)和局部空间注意力(Local Attention)。
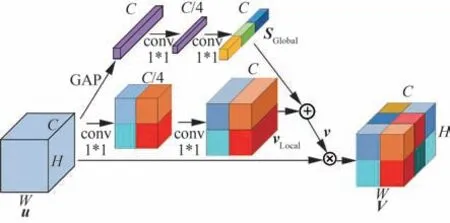
图6 多尺度注意力模块Fig. 6 Multi-scale attention module
全局注意力主要由全局平均池化(GAP)和conv1*1组成:式(6)为通过全局平均池化来压缩输入特征图u的空间信息,得到全局特征向量zc,而后式(7)通过2层1*1卷积conv1*1,学习特征向量之间的非线性关系,生成全局通道注意力权重SGlobal;如式(8)所示,局部注意力使用2层conv1*1对输入u进行通道的降维和升维,压缩通道上的特征信息,生成局部空间注意力特征图vLocal。
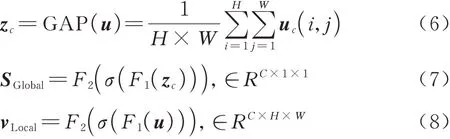
式中:uc(i,j)为每个通道c上的特征图,其中i、j为特征图上像素点坐标,c∈C;F1、F2是conv1*1;σ(⋅)为ReLU激活函数。
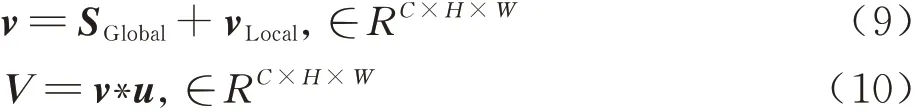
式(9)将全局通道注意力权重SGlobal与局部空间注意力特征图vLocal相加,得到多尺度注意力权重v,并通过式(10)将注意力权重v与输入u加权相乘,得到多尺度注意力特征图V。全局通道注意力和局部空间注意力的结合使用,在通道上抑制其他类别的目标特征信息、空间上抑制相似目标的特征信息和尽可能地保留小尺寸跟踪目标的特征信息,增强了对跟踪目标的辨别能力、多尺度感知能力和抗干扰能力。
2.3 注意力特征融合模块AFFM
孪生跟踪算法的核心思想是模板匹配,简单高效地从搜索图像中找到跟踪目标,但跟踪过程中目标会出现运动模糊、外观变化和光照变化等情况导致目标后续状态与初始模板存在较大差异。考虑到深层特征中具有抽象的高级语义信息,能鲁棒地表征物体,保证算法在各种场景下的泛化能力。以及浅层特征中包含形象的细节信息,如形状、颜色等信息,有助于目标的精准定位[23]。因此在多尺度注意力模块的基础上进行深浅层特征融合,有效整合浅层的细节信息合深层的语义信息,提高跟踪算法的鲁棒性与定位准确性[20]。注意力特征融合模块(Attention Fea⁃ture Fusion Module,AFFM)如图7所示。
首先式(11)将残差模块的输入x[l]和输出x[l+1]相加并作为多尺度注意力模块的输入,使得生成的注意力特征图能同时具有语义信息和细节信息,式(12)然后将注意力权重vAFFM分别作用于x[l]、x[l+1],筛选不同层的特征图上的有用信息,最后将深浅层的注意力特征图进行相加,得到注意力特征融合模块的输出VAFFM。
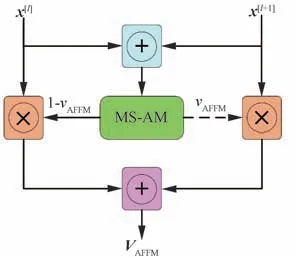
图7 注意力特征融合模块Fig. 7 Attention feature fusion module
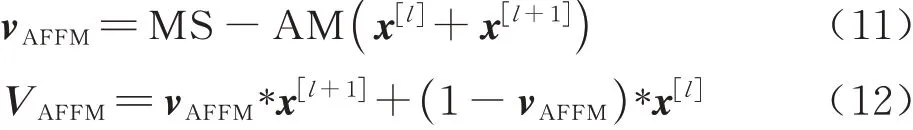
相比于直接融合不同层特征信息的特征金字塔[24],注意力特征融合模块不仅能融合多层特征信息,而且在注意力模块的帮助下能够灵活地分配融合特征图的权重,在融合阶段对无关特征信息进行抑制、更多地保留了跟踪目标的语义信息和细节信息,算法能有效应对运动模糊、外观变化等挑战,同时对目标的精确定位能力也得到增强。
2.4 基于无锚框策略的RPN模块AF-RPN
文献[25]指出通用目标跟踪任务的出发点应该是跟踪算法能依靠的先验信息只有初始帧的目标信息,而RPN模块中预先定义了一组尺度(Scale)、比例(Ratio)不同的锚框(Anchor)进行尺度估计,这些锚框的先验信息都是从视频中分析得到的,是违背了跟踪任务的出发点,并且跟踪性能对锚框的这些参数很敏感,需要人工精心设置。因此为了跟踪算法能摆脱对目标先验信息的过多依赖,在RPN模块中使用文献[26]的无锚框策略完成目标尺度的自适应估计。
如图8、式(13)和式(14)所示,基于无锚框策略的RPN模块(AF-RPN),其边界框回归分支不再对锚框的尺寸(长、宽、中心点位置)进行回归,而是预测目标像素点与真实框(Ground-truth)之间的偏移量l,t,b,r;之前的分类分支是通过计算锚框与真实框的面积交并比(Intersection over Union, IOU)来判断锚框内的目标是否为正样本,因此无锚框策略需要一种新的正负样本判别方法:式(15)将相似度响应图的像素点(i,j)映射回搜索图像,映射坐标为(pi,pj)。然后对(pi,pj)进行分类:如图9所示,落在椭圆E1之外为负样本;落在椭圆E2内则为正样本;落在椭圆E1和椭圆E2之间则忽略该点。如式(16)所示:椭圆E1的中心点坐标为(gxc,gyc)、短半轴和长半轴的长分别为椭圆E2的中心点坐标为(gxc,gyc)、短半轴和长半轴的长分别为最后,式(17)对属于正样本的点(pi,pj)进行回归,从而计算得到与真实值的偏移量l,t,b,r。式中为分类结果和回归结果,其 中w、h、4k分 别 为 特 征 图 的 宽 度、高 度、通道数。
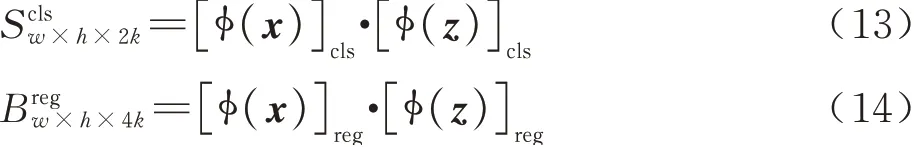
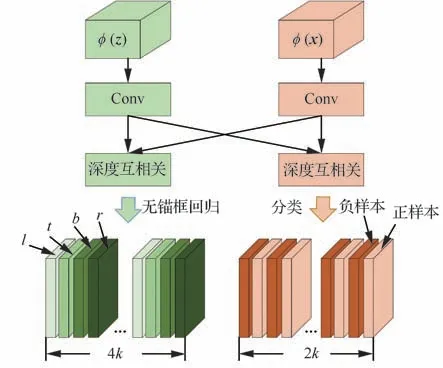
图8 AF-RPN模块Fig. 8 AF-RPN module
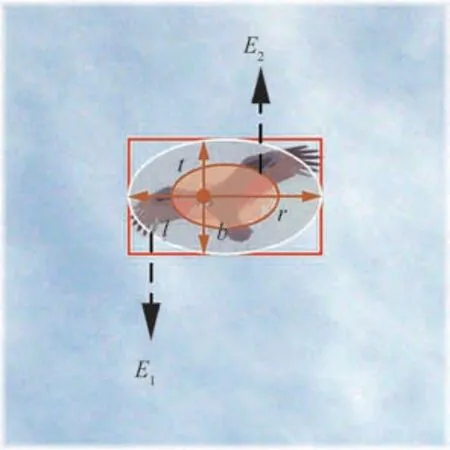
图9 正负样本分类与边界框回归Fig. 9 Positive-negative classification and bounding box regression
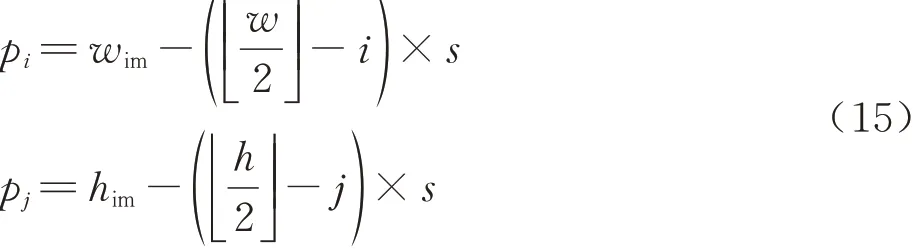
式 中:映 射 坐 标 为(pi,pj);响 应 图 坐 标 为(i,j);w、h为响应图的宽度和高度;wim、him为搜索图像的宽度和高度;s为网络的总步长。
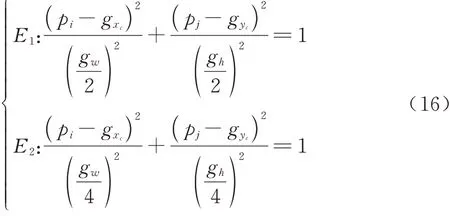
其中:gw、gh,(gx1,gy1)、(gxc,gyc)和(gx2,gy2)分别为真实框的宽、高,左上角坐标、中心点坐标和右下角坐标。则有:
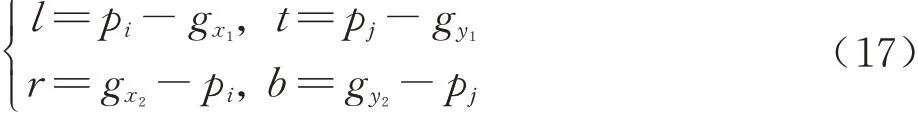
跟踪过程中目标的尺度变化情况是随机、未知的,跟踪算法难以通过预先定义的锚框准确估计出目标的尺度。因此AF-RPN模块避免了锚框的使用,而是直接在搜索图像上逐像素地区分正负样本和预测目标位置,能够自适应地感知目标的尺度变化。同时避免引入过多超参数,算法能灵活、通用地跟踪未知场景下的目标。
同时为了充分利用注意力特征融合模块AFFM整合的语义信息和细节信息,如图2、式(18)和 式(19)所 示,在DF-ResNet的Layer2、Layer3和Layer4上级联使用多个AF-RPN模块并将结果进行加权融合,同时利用浅层特征中的细节信息对目标精确定位和深层特征中的语义信息稳定地表征跟踪目标,有效应对跟踪过程中的小目标、运动模糊等情况。参考文献[8],本文加权融合的权重是相同的,从而给予了各层相同的重视程度,充分和平衡地利用了语义信息和细节信息。
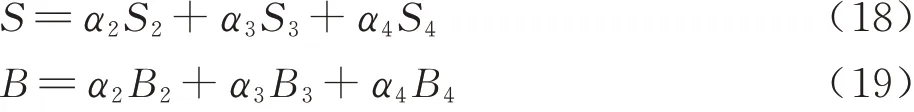
式 中:Si、Bi和αi为 第i层AF-RPN的 分 类 输 出、回归输出和融合权重;S、B为网络输出的最终结果。
2.5 跟踪算法流程
算法流程如图10所示,主要步骤如下:
1) 输入视频序列。
2) DF-ResNet提 取视频序 列 第1帧中目 标特征,作为模板特征。
3) DF-ResNet提取后续帧中的搜索区域特征,作为搜索特征。
4) 多尺度注意力模块(MS-AM)为特征图重新分配权重,得到加权特征图。
5) 注意力特征融合模块(AFFM)将不同层的加权特征图进行融合,整合细节信息与语义信息。
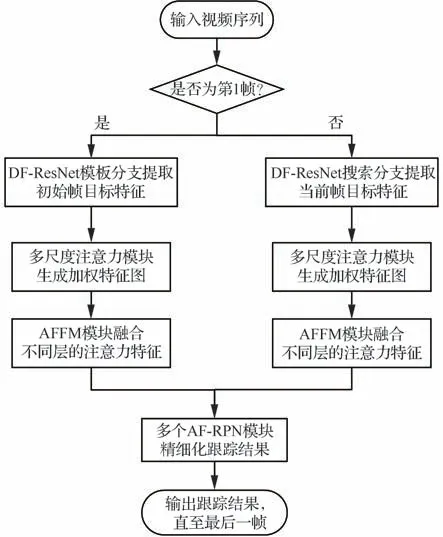
图10 算法流程Fig. 10 Flowchart of algorithm
6) 级联多个基于无锚框策略的RPN模块(AF-RPN)逐步完成对目标位置、边界框大小的精确评估。
7) 输出目标的预测结果。
8) 重复步骤3)~7),直至视频结束。
3 实验与分析
3.1 网络分析
3.1.1 有效性
首先通过对比实验来分析各个模块对于网络的提升效果,验证各个模块的有效性。表1为各模块在数据集UAV123[27]上的跟踪成功率:①使用AlexNet网络、RPN模块的标准方法Sia⁃mRPN[5],成功率为55.7%;②在SiamRPN上使用多样化特征提取网络DF-ResNet替换原来的AlexNet网络,成功率为58.6%,提高了2.9%,说明DF-ResNet能更有效地表征目标,从而提高了跟踪效果;③在提取的多样化特征信息基础上使用多尺度注意力模块,保留不同尺度的目标特征信息、抑制干扰信息,将跟踪率提高至60.9%;④没有了多尺度注意力模块的特征融合模块AFFM,直接将细节信息和语义信息相加,跟踪成功率为60.5%,证明了语义信息和细节信息的融合能有效地增强跟踪鲁棒性和定位准确性;⑤基于无锚框策略的RPN模块能够逐像素地预测目标,自适应感知目标变化,跟踪成功率比标准方法增加了4.6%、为60.3%;⑥本文组合各个模块将成功率提升至61.7%、最大幅度地提升了跟踪效果,证明各个模块能够协同配合、发挥各自优势,互补地构建一个高效的无人机跟踪算法。

表1 对比实验结果Table 1 Comparison of results of ablation experiments
3.1.2 轻量化
为了进一步验证MS-AM中全局通道注意力(Global Attention,GA)和局部空间注意力(Lo⁃cal Attention,LA)对网络的提升作用,本文以ResNet-50为基础测试2个子模块在数据集Ima⁃geNet[28]上的分类准确度。如表2所示:添加全局通道注意力之后的网络分类准确率为76.8%,比直接增加了网络层数的ResNet-101的准确率更高;添加局部空间注意力之后的网络性能进一步提升,准确率为77.7%,比ResNet-50高2.3%、比ResNet-101高1.1%。参数为29.9 M(1 M=1×106)、远 远 小 于ResNet-101的44.55 M,比ResNet-50增加了4.34 M。可以看出:全局和局部注意力都能提升网络性能,且二者结合使用的效果最好。因此相比于增加网络层数,多尺度注意力模块更能有效地提升网络性能,并且参数量更少,适合无人机的目标跟踪任务。
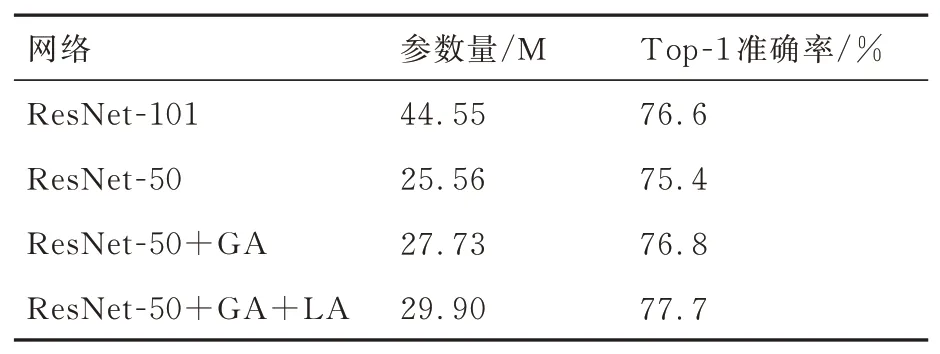
表2 轻量化分析Table 2 Lightweight analysis
3.1.3 可视化
为了直观展示和验证多尺度注意力模块MS-AM和注意力特征融合模块AFFM的有效性,将 其 加 入DF-ResNet中,使 用Grad-CAM++[29]展 示DF-ResNet的 分 类 准 确 度。Grad-CAM++是一种模型分类结果可视化方法,通过计算特征图中空间位置上的梯度的像素加权,度量每个像素对模型分类结果的重要程度,生成的类激活热力图(Class Activation Map,CAM)能直观展示CNN模型认为与类别标签对应的图像区域。热力图中某个区域的温度越高,则类别激活值就越大,代表着该区域是该类别的可能性更大。
图11为ResNet-50和DF-ResNet的类激 活热力图。图11(a)中有狗和猫2个类别的物体,有MS-AM和AFFM模 块存在的DF-ResNet对 感兴趣目标(猫)的辨别能力得到增强,干扰目标(狗)的激活值明显降低。图11(e)和图11(f)表明DF-ResNet由于有能够提供细节信息的AFFM模块的存在,分类结果更加准确。因此MS-AM和AFFM能够有效筛选目标特征,从而增强网络对目标的辨别能力、抑制干扰目标,应用于跟踪算法中能提升跟踪准确度。

图11 类激活热力图Fig. 11 Class activation map
3.2 实验平台及参数设置
实验平台:①操作系统为 Ubuntu18.04;②CPU为Intel Core i7-9700 @3.6 GHz;③GPU:2张NVIDIA GeForce RTX 2080Ti,内存11 G。
训练数据集:中科院专门为目标跟踪设计的GOT-10k[25]数 据 集,由10 000个 视 频 片 段 和150万个人工标注的边界框组成,包含现实世界中560多个类别的运动目标和80多种运动模式;包含38万个视频片段,560万个人工标注的边界框,23个类别的日常物体的YouTube-BoundingBoxes[28];有30个 基 本 级 别 的 类 别,200个 子 集 的ImageNet VID和ImageNet DET[29];包含91个对象类型,328千张图像,总共有250万个标注的COCO[30]。训练时会从相同的视频序列里随机选取一个搜索图像和模板图像,组成图像对输入到网络中训练,模板图像的大小为127 pixel×127 pixel,搜索分支图像大小为255 pixel×255 pixel。
研究区出露地层为长城系星星峡岩群、下泥盆统阿尔彼什麦布拉克组、中泥盆统阿拉塔格组、下石炭统甘草湖组和第四系[9](图1b)。侵入岩主要为华力西中期晚石炭世花岗岩[10]。区内断裂构造极为发育,主要断裂阿其克库都克断裂、卡瓦布拉克断裂为NW—SE向,次级断裂多为NE—SW向分布。
参数设置:多个AF-RPN的融合权重为α3=α4=α5=0.333;使用随机梯度下降法(Stochastic Gradient Descent,SGD)训练网络,epoch=20、其中每个epoch训练图片数量为800 000对,batch size=22即 每批次处 理图像11对;前10个epoch训 练AF-RPN、后10个epoch对整个网络进行端对端训练;前5个epoch的学习率从0.001预热至0.005,后15个epoch的学习率从0.005指 数 衰 减到0.000 05,衰减权重为0.00 01,动量为0.9。损失函数是分类的交叉熵损失(Cross entropy loss)和回归的IoU损失函数的总和。
3.3 在UAV123上的实验结果与分析
UAV123[31]数据集为测试无人机航拍目标跟踪算法的基准数据集,由无人机拍摄的123个高分辨率视频序列组成,包含9个目标类别、12种常见挑战,视频平均长度为915帧。包含场景有城市景观、道路、建筑、田野、海滩、港口和码头等;包含目标:汽车、卡车、船只、人员、团体和空中交通工具等;目标的活动模式有:步行、骑自行车、滑水、驾驶、游泳和飞行等。拍摄场景复杂多变、跟踪目标类别广泛、运动模式复杂多元,能整体评估跟踪算法。
3.3.1 定性分析
首先在UAV123中选取具有代表性的5个视频序列(如表3所示),然后在这基础上定性分析本文算法(Ours)与8种主流跟踪算法的跟踪结果,8种算法分别为:①额外训练一个滤波器进行尺度估计的判别式尺度空间跟踪算法[32](Dis⁃criminative Scale Space Tracker, DSST);②多专 家 鲁 棒 跟 踪 算 法[33](Multiple Experts using Entropy Minimization, MEEM);③使用多尺度搜索策略跟踪的尺度自适应与多特征跟踪算法[34](Scale Adaptive with Multiple Features tracker, SAMF);④空间正则化相关滤波算法[35](Spatially Regularized Discriminative Correla⁃tion Filters, SRDCF);⑤全卷积孪生跟踪算法的SiamFC[3];⑥孪 生 跟 踪 区 域 建 议 算 法Siam⁃RPN[5];⑦结构化支持向量机(SVM)进行自适应跟踪的Struck[36];⑧干扰物感知的孪生区域建议算法DaSiamRPN[37]。使用的对比算法结果均来自数据集官方公布结果和算法作者提供结果。跟踪结果如图12所示。
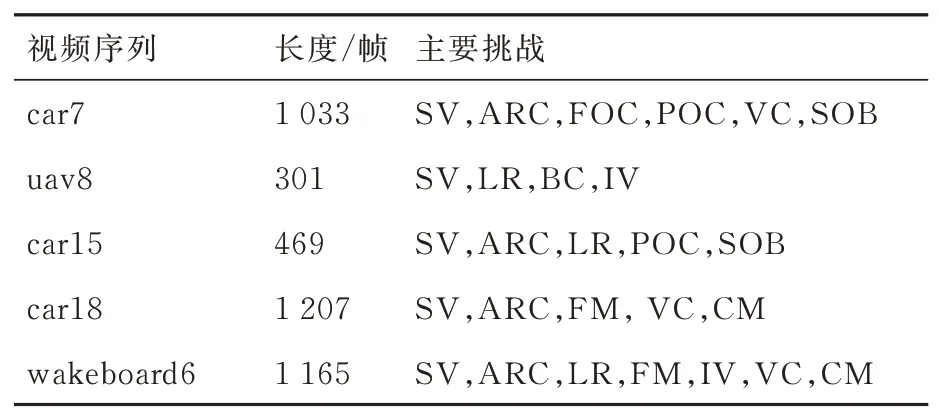
表3 5个代表性序列Table 3 Five representative sequences
图12(a)序列car7:跟踪目标为运动的汽车,第369帧时无人机由于视角变换不及时,出现跟踪目标被障碍物遮挡的情况,只有SRDCF、Da⁃SiamRPN和本文算法能成功跟踪上重新出现的目标,其余算法均将遮挡物当作跟踪目标。第766帧时,随着车辆的转弯,边界框的纵横比变换大,只有本文算法能准确地标注出跟踪目标。本文算法因为DF-ResNet使用多个子空间来学习目标的多样化特征,能更有效地表征目标,因此提高了对跟踪目标的辨别能力。

图12 算法在数据集UAV123的跟踪结果展示Fig. 12 Tracking results of algorithms in UAV123 dataset
图12(c)序列car18:目标由远至近地快速运动,导致跟踪过程中目标的尺度变化大且迅速。使用多尺度搜索策略的相关滤波算法和孪生跟踪算法的尺度适应能力明显不足,尺度变换过大时不能完全标注出跟踪目标,第105帧和144帧时只有本文算法准确地标注出跟踪目标。相比于基于多尺度搜索策略和锚框的尺度估计算法,本文算法使用的无锚框策略能够逐像素预测目标,从而提高算法对目标尺度变化的自适应感知能力。
图12(d)序列car15:无人机从高空跟踪行驶中的车辆,目标尺寸小且相似目标多。第230帧时相似目标与跟踪目标重合之后,由于二者的特征信息少且相似,SiamFC、DSST、SAMF算法出现跟踪失败的情况,第425帧的遮挡情况也未能干扰本文算法的持续跟踪。本文算法的多尺度注意力模块中局部空间注意力在抑制干扰信息的同时更多地保留了小目标的空间信息,提高对小目标的识别能力和对相似干扰的抑制能力
图12(e)序列wakeboard6:该场景中包含的背景信息容易影响算法的跟踪性能,第65帧SAMF已经出现跟踪失败的情况。第507帧时随着相机视角的突然变化,大部分算法丢失了跟踪目标,只有SiamFC和本文算法能准确找到跟踪目标。到了第1 081帧时目标在空中的翻转动作造成尺度快速变化,SiamRPN和SiamFC未能及时跟上变化,只框出了部分目标。结合了全局和局部注意力的本文算法能有效抑制背景信息的干扰,因此识别复杂背景下的跟踪目标性能更加稳定。
3.3.2 定量分析
为了进一步验证算法的整体性能,采用一次通过评估模式(One-Pass-Evaluation, OPE),通过成功率(Success)和准确率(Precision)对算法进行评估[38]。成功率是指成功率曲线与坐标轴围成的面积(Area Under Curve, AUC),其中成功率曲线上的每个点代表着重叠率(Intersection Over Union, IOU)大于某个阈值的帧数百分比;准确率,即 中 心 定 位 误 差(Center Location Error,CLE)。计算被跟踪目标中心位置与真实中心位置之间的平均欧氏距离,当距离小于阈值(一般为20个像素)时,被视为跟踪成功。准确率由成功跟踪的图片数量和视频序列数量的百分比得到。
1)整体性能评估:9种算法的整体评估结果如图13所示。本文算法(Ours)的成功率和准确率分别为61.7%和81.5%,比第2名DaSiamRPN分别提高4.8%、3.4%,比SiamRPN分别提高6.0%、4.7%。可以发现:当成功率阈值变高和准确率阈值变低时,本文算法明显优于其他算法,说明即使在跟踪任务的要求变高时,本文算法也能展现出良好的跟踪效果。证明多样化特征信息提取网络(DF-ResNet)、多尺度注意力模块(MS-AM)、注意力特征融合模块(AFFM)和基于无锚框策略的RPN模块(AF-RPN)能够协同配合,互补地构建一个高效的无人机航拍目标跟踪算法。同时速度达到40.5 frame/s,满足实时性要求(≥30 frame/s),足以胜任无人机实时跟踪任务。
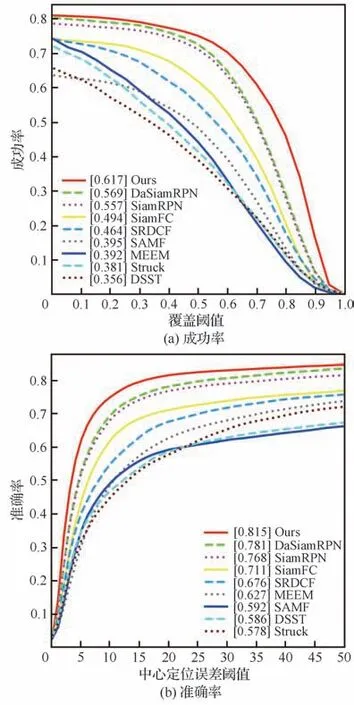
图13 算法在数据集UAV123的整体性能评估Fig. 13 Overall performance evaluation of algorithms in UAV123 dataset
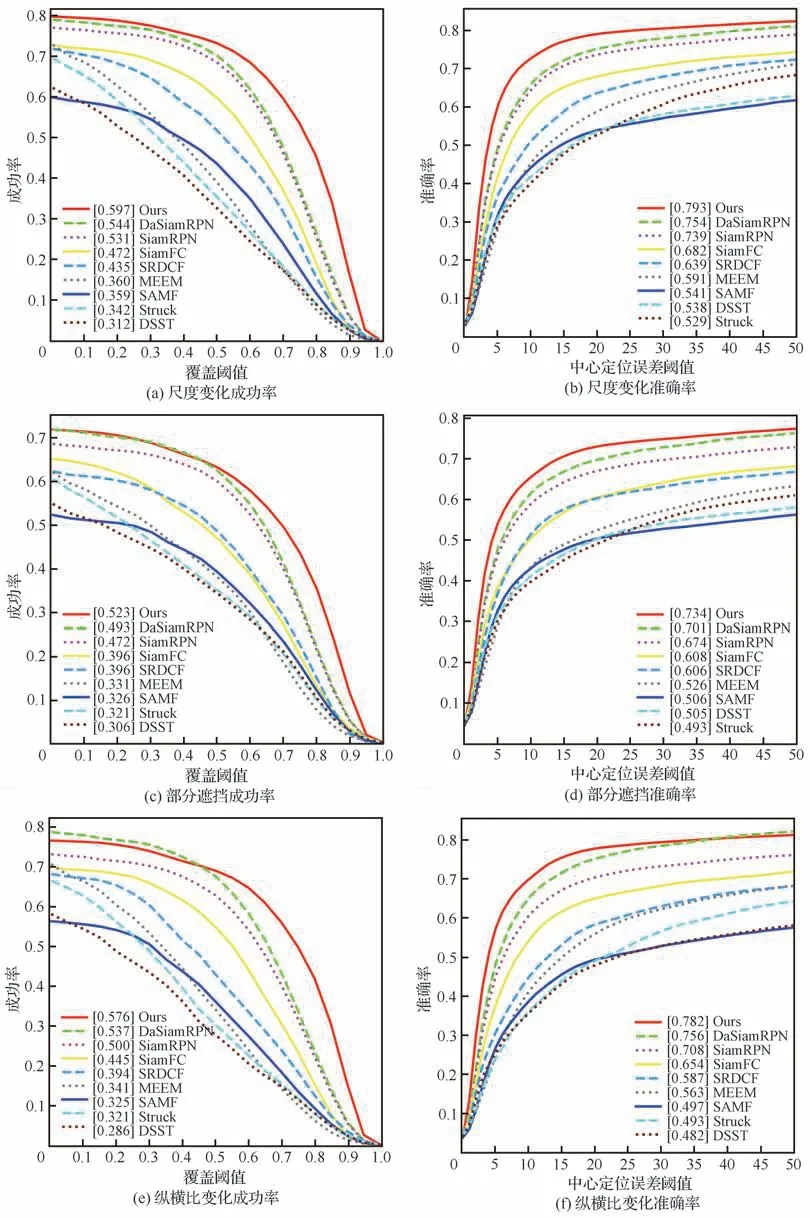
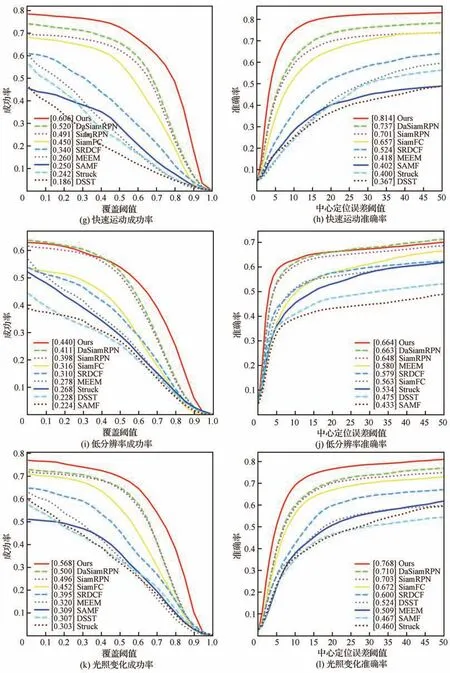
图14 算法在UAV123数据集上不同属性的评估结果Fig. 14 Evaluation results of different attributes of UAV123 with algorithms
2)各个属性评估:UAV123数据集提供了各个视频序列的挑战属性,更加全面地评价算法的性能。UAV123数据集中出现次数最多的挑战为目标的尺度变化和部分遮挡,分别为89%和59%,符合无人机目标跟踪的实际情况。如图14所示:本文算法在尺度变化挑战上的成功率和准确率为59.7%、79.3%,在部分遮挡挑战上的成功率和准确率为52.3%、73.4%,在9种算法中排名第一,证明本文算法更加适合无人机目标跟踪任务。此外在纵横比变化、快速运动、低分辨率等挑战上也取得了较好的效果,证明本文设计的各个模块能够有效应对无人机跟踪过程中的多种挑战,从而提高算法的整体性能。
3.4 在无人机航拍视频上的测试与分析
为了验证本文算法在实际无人机场景中的跟踪效果,本文算法应用于无人机航拍视频中进行测试,其中视频分辨率为3 840 pixel×2 160 pixel,帧速为30 frame/s,拍摄高度为120 m。部分跟踪结果如图15所示。
序列1 跟踪目标为在道路上滑行的人。目标的快速运动、特征点少且存在背景干扰,未能影响算法的跟踪效果。可见本文算法在实际应用中也有着良好的小目标识别和抗干扰能力。

图15 算法在无人机航拍视频的跟踪结果展示Fig. 15 Tracking results of algorithms in UAV aerial video
序列2 跟踪目标的快速运动导致其尺度变化大且迅速,本文算法能及时感知出目标的尺度变化并准确标注出跟踪目标。在696帧无人机随着跟踪目标的运动而调整飞行姿态,拍摄视角迅速变化,本文算法仍未产生跟踪漂移现象。第1 571帧时算法准确判断出跟踪目标与相似目标。
序列3 由于无人机位置调整不及时,导致第93和第181帧跟踪都出现了不同程度的遮挡情况,算法仍根据部分目标信息准确判断出跟踪目标的位置,并在第220帧时目标重新出现之后,准确识别出整个目标。
4 结 论
提出了一种基于多尺度注意力和特征融合的自适应无人机目标跟踪算法,主要工作为:
1)利用分组-转换-融合的子空间学习思想,设计了多样化特征提取网络DF-ResNet,能够提取目标的深层语义特征和多样化特征,增强对目标的表征能力,有效应对目标的外观变化、运动模糊等挑战。
2)提出了一种多尺度注意力模块MS-AM和注意力特征融合模块AFFM,结合全局、局部注意力的MS-AM在筛选特征的同时保留对大、小目标的尺度感知能力,在此基础上AFFM融合了不同层的特征,有效整合浅层细节信息和深层语义信息,有利于目标的精确定位与分类。
3)提出了一种基于无锚框策略的区域建议模块AF-RPN,代替预先定义的锚框,逐像素的区分目标与背景,实现对目标尺度的自适应感知能力。并在AFFM模块的基础上级联多个AFRPN,有效利用了互补的细节信息和语义信息来实现对跟踪目标的鲁棒跟踪和精确定位。
