基于重构对比的广义零样本图像分类
2023-01-31曹维佳刘宝弟陶大鹏刘伟锋
许 睿 邵 帅 曹维佳 刘宝弟 陶大鹏 刘伟锋
近些年,随着深度学习的兴起,基于深度学习的分类方法取得巨大突破.此类方法往往需要依赖大量的有标签数据.然而,在很多真实场景中,收集标签昂贵甚至不切实际.因此,如何让深度模型可在没有标签或标签不足的条件下依然达到令人满意的精度,受到学者们的广泛关注,进而延伸出对应的零样本学习(Zero-Shot Learning,ZSL)和小样本学习(Few-Shot Learning,FSL).零样本图像分类亟待解决的问题为:如何通过可见类样本中的信息对不可见类样本进行分类,其中可见类样本和不可见类样本没有交叉.为了让该任务更贴合实际应用,研究者又提出广义零样本学习(Generalized ZSL,GZSL),旨在同时对可见类样本和不可见类样本进行分类.
广义零样本图像分类任务中的样本主要包含两种模态信息:视觉模态信息和语义模态信息.视觉模态信息指图像特征表示;语义模态信息指类别属性或类标签表示[1],可见类和不可见类具有共享的属性空间.在此任务中,为了获得较好的视觉模态信息,往往借助预训练模型(如ImageNet[2])提取特征.当前大多数广义零样本图像分类方法首先学习视觉模态信息和语义模态信息之间的映射,即从可见类中学习属性在图像特征中的通用表示,然后以属性为纽带,将共享知识迁移到对无标签样本的分类中.
根据模态映射形式的不同,广义零样本图像分类方法主要包括4类.1)将视觉模态信息映射到语义模态[3-4],学习两个模态信息在语义空间上的关系;2)将语义模态信息映射到视觉模态[5-7],再在视觉模态空间学习;3)将视觉模态信息和语义模态信息映射到共享子空间[8-9],再在子空间进行学习;4)两个模态信息互相映射[10],即把两种模态信息都映射到另一个模态空间,学习两个模态信息的对齐关系.
在这4类模型中,1)、2)、4)类都包含将一种模态特征映射为另一模态信息的过程,即重构图像或语义,这些过程的本质是生成任务,需要使用生成模型.在第3)类模态映射形式中虽然没有直接生成某种模态信息,但是将某种模态信息映射到子空间,同样可用生成模型实现.
综上所述,基于生成模型的方法是零样本学习领域的一个重要研究方向.生成模型的主流方法有两种:变分自编码器(Variational Auto-encoder,VAE)[11]和生成对抗网络(Generative Adversarial Network,GAN)[12].Xian等[13]提出f-CLSWGAN,使用不可见类的语义信息生成不可见类的图像,用于扩充训练样本,在扩充后的样本集上训练分类器,提高模型对不可见类样本的分类性能.由于GAN容易产生模式崩溃问题[14],VAE较稳定,学者们提出一些基于条件变分自编码器的零样本学习算法,如CVAE(Con-ditional Variational Autoencoders)[15]、SE-GZSL(Syn-thesized Examples for GZSL)[16]和Re-ViSE(Robust Semi-Supervised Visual-Semantic Embeddings)[17].但是这些方法未关注模态对齐,忽略不同模态信息尺度不同的问题.
为了更好地进行模态对齐,Schönfeld等[18]提出CADA-VAE(Cross and Distribution Aligned VAE),通过分布对齐损失和交叉对齐损失,学习跨模态共享的隐向量,提升模型效果.然而在基于VAE的模型[14-18]中,通常仅使用约束距离实现各种对齐,编码器重构的样本判别力仍存在不足.对比学习可缓解这一问题.对比学习通过构造相似实例和不相似实例,即正例和负例,习得一个表示学习模型[19-21].通过这个模型,使相似的实例在投影空间中较接近,而不相似的实例在投影空间中距离更远,使模型学习到更有判别性的表示方法,现已成为近年来的研究热点.Chen等[19]提出SimCLR(A Simple Framework for Contrastive Learning of Visual Representations),结合对比学习与数据增强,提高模型的表示能力,在无监督学习的实验中取得媲美有监督学习的结果.Han等[20]提出CE-GZSL(Hybrid GZSL Framework with Contrastive Embedding),结合GAN的生成模型,提出带有对比嵌入的混合GZSL框架,提升模型的分类准确率.上述模型都已证实对比学习的有效性.
在VAE的模型中,重构样本可为对比学习提供大量的正例和负例.因此本文将对比学习引入VAE的广义零样本图像分类方法中,并提出基于重构对比的广义零样本图像分类模型.此外,在对比损失之间引入可学习的非线性映射,大幅提高学习表示的质量,学习更有用的表征.本文借鉴SimCLR在对比损失之间引入可学习的非线性投影模块的思想,在预训练特征和语义信息生成特征的投影子空间特征之间构建正例和负例,使模型学习更具有判别性的表示,增强编码器的性能.在传统的标准数据集上,在广义零样本和广义小样本图像分类设置下对本文模型进行广泛的实验评估,验证模型的优越性.
1 基于重构对比的广义零样本图像分类模型
本文提出基于重构对比的广义零样本图像分类模型,在预训练特征的投影和变分自编码器使用语义信息重构的视觉特征的投影之间引入对比学习,其中投影模块提取两部分特征中更本质的表示.对比学习使投影特征之间判别性更强,从而增强VAE的编码性能,充分挖掘预训练的视觉特征.
在零样本学习中,定义训练集
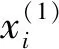
其中:Cu表示不可见类,它与可见类类别不同,即
Cs∩Cu=Ø;
Nts表示测试样本的个数.训练集和测试集样本不同,即
Dtr∩Dts=Ø.
而在广义零样本图像分类中,识别集中不仅包括不可见类,同时也包括可见类,即

本文的目标是根据训练集提供的信息,预测测试集样本的标签.模型整体框架如图1所示.
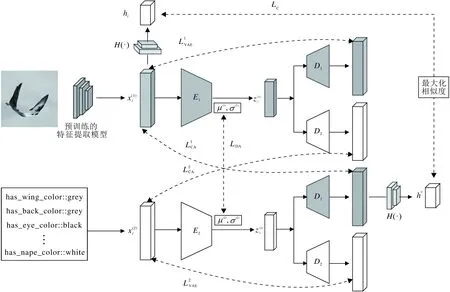
图1 本文模型框架图Fig.1 Framework of the proposed model
1.1 变分自编码器模块
变分自编码器能利用神经网络同时拟合生成模型和推断模型.推断模型是自编码器中的编码层,生成模型是自编码器中的解码层.使用x表示原始数据特征,z表示编码器得到的隐向量.
变分推断的目的是找出隐向量上的真实条件概率分布pθ(z|x).由于分布的相互作用性,可使用变分下限最小化其距离,找到最近的代理后验分布qφ(z|x)以近似.变分自编码器的目标函数为:
L=Eqφ(z|x)[lnpθ(x|z)]-DKL(qφ(z|x)‖pθ(z)).
(1)
其中:公式第1项表示经生成模型解码后数据与原始数据的差异,为重构误差;第2项表示推理模型q(z|x)和p(z)之间的KL散度,度量两个分布之间的距离损失.先验的一个常见选择是多元标准高斯分布.设定编码器预测均值μ和方差σ2,后验分布服从
qφ(z|x)=N(μ,σ2),
通过重参数化技巧[23]生成一个隐向量z.

(2)
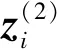
1.2 重构对比模块
为了使变分自编码器学习跨模态的相似表示,本文使用3部分损失对两种模态的对齐进行约束,分别是分布对齐(Distribution-Alignment,DA)损失、交叉对齐(Cross-Alignment,CA)损失和重构特征对比损失.
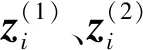
(3)
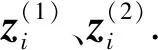
(4)


对于对应的增强样本的嵌入记为
具体来说,对于1个正例和K个负例,K+1分类问题的交叉熵损失计算如下:
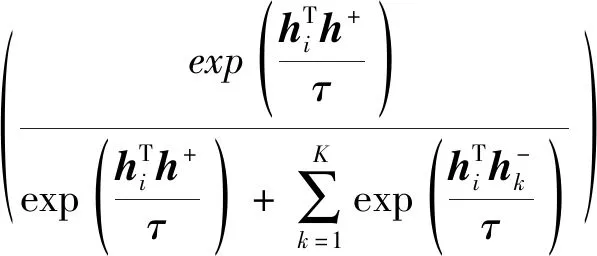
(5)
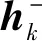
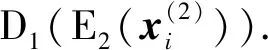
LC(D1,E2,H)=Ehi,h+[Lc(hi,h+)].
(6)
结合变分自编码器模块和重构对比模块,结合式(2)~式(4)和式(6),整个模型的损失函数如下:
L=LVAE+γLCA+δLDA+λLC,
(7)
其中,γ表示分布对齐损失LCA的权重因子,δ表示交叉对齐损失LDA的权重因子,λ表示重构特征对比损失LC的权重因子.
2 实验及结果分析
2.1 实验环境
本节在Caltech-USCD Birds-200-2011(CUB)[25]、SUN Attribute(SUN)[26]、Animals with Attributes 2
(AWA2)[27]、Attribute Pascal and Yahoo (APY)[28]
这4个广泛应用的标准数据集上进行实验.所有数据集都为每个样本提供对应的属性信息(即ai).本文按照标准划分[27]将数据集划分成可见类样本和不可见类样本.具体来说:CUB数据集包含150个可见类样本与50个不可见类样本;SUN数据集包含645个可见类样本与72个不可见类样本;AWA2数据集包含40个可见类样本与10个不可见类样本;APY数据集包含12个可见类样本与20个不可见类样本.在广义零样本图像分类和广义小样本图像分类中,训练集只包含可见类样本,测试集包含可见类样本与不可见类样本.实验数据集详细信息如表1所示.
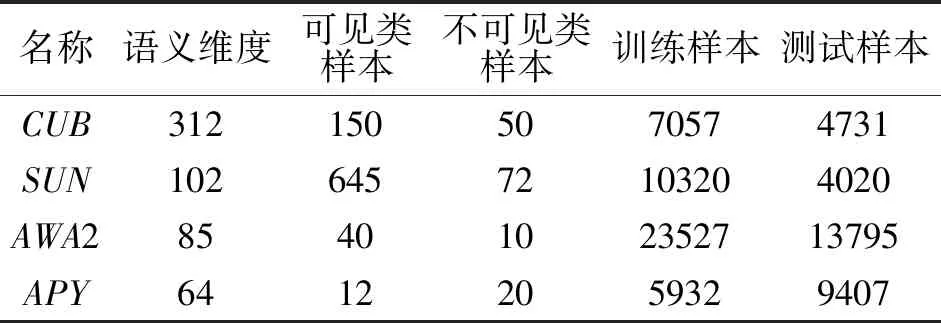
表1 实验数据集Table 1 Experimental datasets
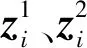
本文模型批量大小设置为50,使用Adam(Adaptive Moment Estimation)优化器.其它参数参考CADA-VAE的实验设置.所有的实验在32 GB内存的Tesla-V100GPU上执行.
遵循文献[27]中提出的评估策略,在广义零样本图像分类情景下,分别评估可见类样本和未可见类样本的top1精度,分别表示为S和U.广义零样本图像分类的性能通过调和平均值
衡量,相比U和S,H为更重要的度量标准,在U和S精度最平衡时H达到最大.
2.2 对比模型
本文选择如下15种相关模型进行对比实验:DeViSE(Deep Visual-Semantic Embedding Model)[5]、文献[7]模型、PREN(Progressive Ensemble Net-works)[8]、f-CLSWGAN[13]、CVAE[15]、SE-GZSL[16]、ReViSE[17]、CADA-VAE[18]、SJE(Structured Joint Embedding)[29]、SP-AEN(Semantics-Preserving Adversarial Embedding Networks)[30]、Cycle-CLSWGAN[31]、ALE(Attribute Label Embedding)[32]、ESZSL(Embarra-ssingly Simple ZSL)[33]、文献[34]模型、文献[35]模型.
上述模型在不同的角度上增强广义零样本和广义小样本的分类性能,其中:CVAE、SE-GZSL、f-CL-SWGAN利用数据增强的方式;DeViSE、SJE、ALE、ESZSL引入线性函数或其它相似度量的方法,增强视觉与语义特征之间的交互;PREN使用一个集成网络;文献[7]模型利用多模态的思想,引入多个神经网络学习非线性嵌入;SP-AEN引入独立的视觉-语义空间嵌入,防止语义损失;Cycle-CLSWGAN将循环一致性引入基于GAN的零样本模型;文献[34]模型对齐类嵌入空间和加权二分图;ReViSE使用自动编码器学习图像特征和类属性之间共享的潜在流形;文献[35]模型提出三元组损失,并应用在零样本学习模型中;CADA-VAE使用编码器将两个模态特征映射到同一个低维空间,学习共享跨模态的隐向量.
2.3 实验结果对比
各模型在广义零样本图像分类和广义小样本图像分类上的性能对比如表2所示,表中黑体数字表示最优值.
由表2可见,本文模型首先与基线方法CADAVAE对比,在SUN、CUB数据集上,本文模型在不可见类上的精度与CADA-VAE持平,在S和H指标上都高于CADA-VAE.在AWA2数据集上,本文模型在所有指标上都远高于CADA-VAE.在APY数据集上,本文模型在U和H指标上高于CADA-VAE,但在S指标上低于CADA-VAE.
值得注意的是,在S指标上本文模型的表现无法达到最高值,这是因为可见类和不可见类的类别不重叠,存在域差异,模型在适应不可见类的分类时往往会降低对可见类的性能.
再对比其它模型,尽管在可见类和不可见类单项的分类精度上,本文模型有时不如其它模型,但在最重要的H指标上,却高于其它模型.
H指标的提升从一定程度上反映本文模型的有效性,这些结果也表明基于重构对比的广义零样本模型具有竞争力.
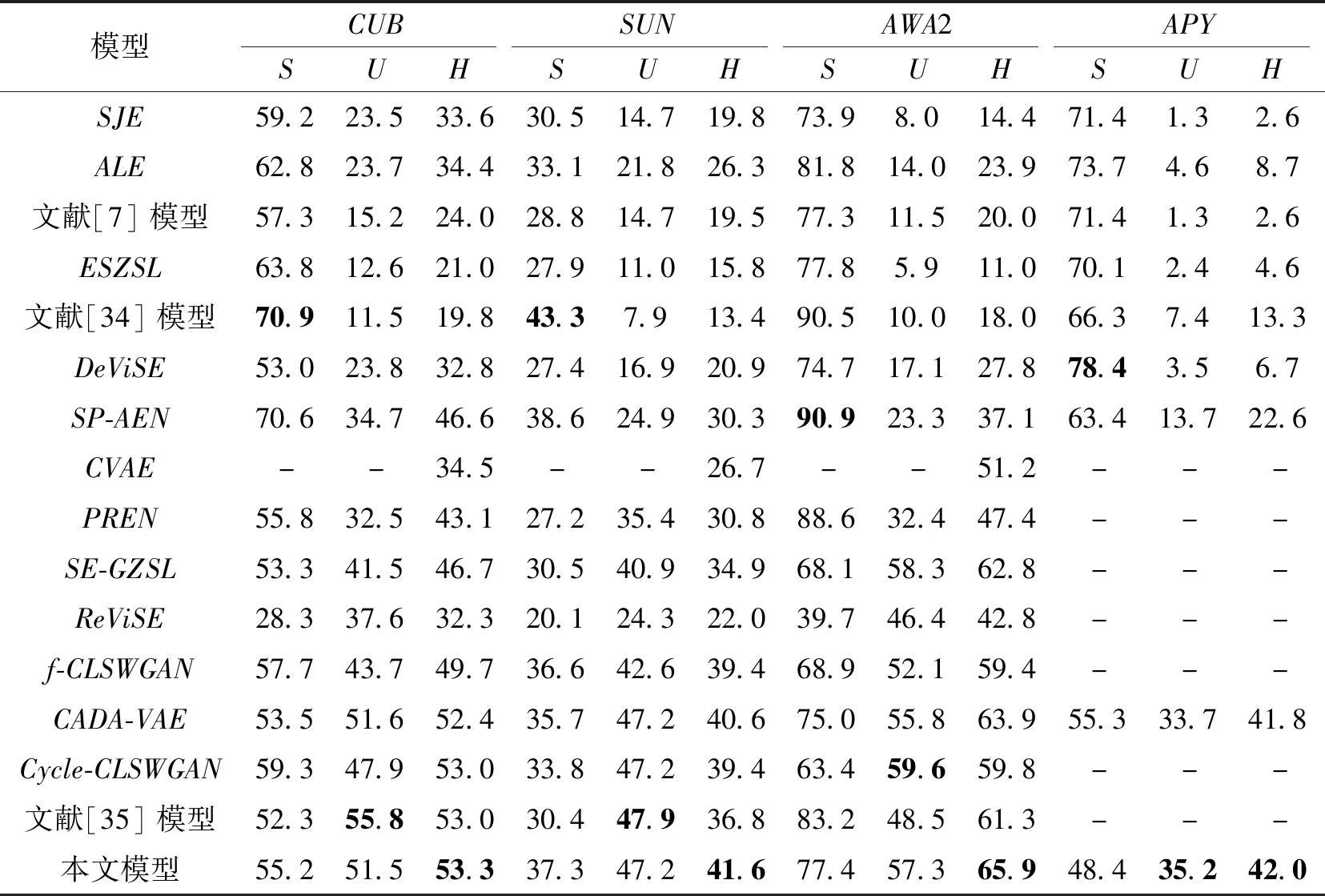
表2 各模型在4个数据集上的分类性能对比Table 2 Classification performance comparison of different models on 4 datasets %
为了进一步验证本文模型的有效性,在广义小样本图像分类的0个、1个、2个、5个和10个样本分类任务中与CVDA-VAE进行对比,结果如图2所示.由图可知,除了在少数的情况下,相比CADA-VAE,本文模型会产生一些波动,在其它的所有设置中,本文模型都优于CVDA-VAE.该现象表明本文模型在同等监督样本条件下,精度高于CADA-VAE.需要注意的是,本文的广义小样本图像分类和传统小样本学习以任务为单位的学习设置不同.传统小样本学习的任务通常对5个类进行分类,本文是在广义零样本图像分类的框架下对数据集所有测试类别进行分类,这个类别数通常远大于5.
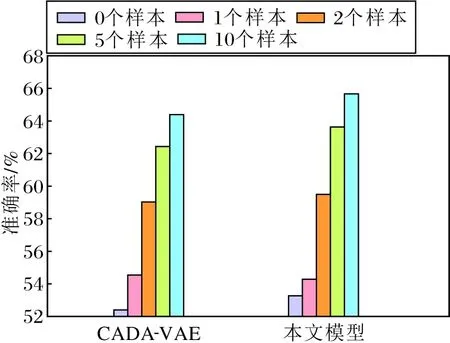
(a)CUB
2.4 实验结果可视化
本文模型与CVDA-VAE在AWA2数据集上6个类别样本的t-SNE(t-Distributed Stochastic Neighbor Embedding)投影的可视化结果如图3所示.

(a)原始视觉模态(a)Original visual mode
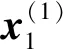

2.5 消融实验结果
本节进行消融实验,对比CADA-VAE、删除投影模块的本文模型、包含投影模块的本文模型.各模型在4个数据集上的准确率对比如表3所示.
由表3可看出,在4个数据集上,包含投影模块的效果都优于不使用投影模块.不使用投影模块,在CUB、SUN、AWA2数据集上本文模型的性能都优于CADA-VAE,在APY数据集上有所下降.但是投影模块可修正在APY数据集上产生的下降,甚至比CADA-VAE提升0.2%.因此投影模块对提高模型性能至关重要.

表3 投影模块的消融实验结果Table 3 Ablation experiment results of projection module %
2.6 参数敏感性分析
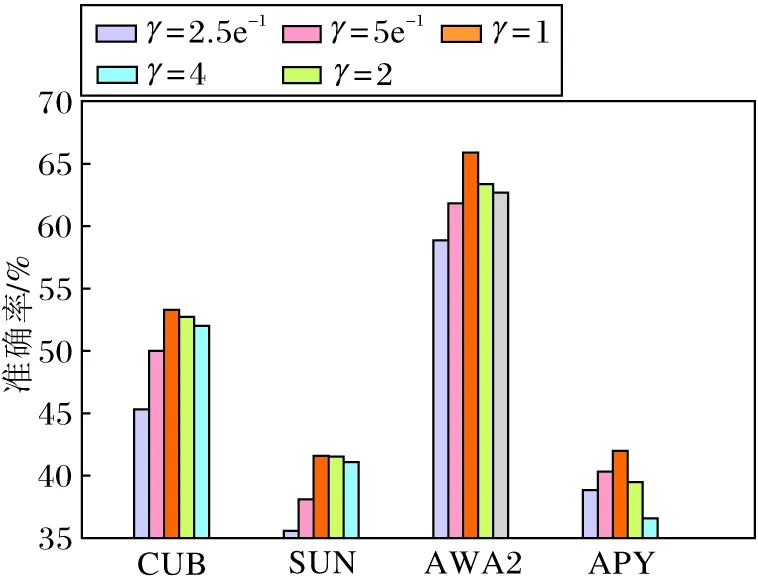
通过1.2节的描述可知,式(7)中3个权重因子γ、δ和λ可影响模型性能,因此设置
γ=2.5e-1,5e-1,1,2,4;δ=2.5e-1,5e-1,1,2,4;λ=1,5,10,15,20.
对比实验结果如图4所示.
由图4(a)可看出,随着γ的增大,模型性能先提升后缓慢下降,在γ=1时可得到最优值.这说明交叉对齐损失对模型整体效果有所提升,但对参数值相对不敏感.
由图4(b)可看出,随着δ的增大,模型性能先提升后迅速下降,在δ=1时得到最优值.这说明分布对齐损失对参数非常敏感,尤其在参数增大时会导致模型性能急剧下降.
由图4(c)可知,并不是所有的权重都能提升模型性能,权重的选择非常重要.在CUB数据集上,性能上下波动,λ=1时获得最优值.在SUN数据集上,性能有一个峰值,λ=15时获得最优值.在AWA2数据集上,λ=10时获得最优值.
在最优值附近本文都使用更小的间隔1测试模型性能,在CUB数据集上,在λ=1附近进行细调,在λ=2时得到表2中53.3%的最优值,在SUN、AWA2数据集上,最优值附近无法得到更优结果.在APY数据集上,λ=5时可得到最优值.虽然在图4(c)中可能会得到差于CADA-VAE的结果,但是在较大的参数范围内都可实现性能提升,由此表明本文模型的鲁棒性.
(a)γ
3 结 束 语
广义零样本大多考虑使用度量表示视觉信息和语义信息映射的效果,很少使用对比学习约束双模态信息的映射,本文提出基于重构对比的广义零样本图像分类模型,将对比学习应用在预训练特征的投影和语义信息重构的视觉特征的低维投影特征之间.投影模块过滤语义模态和视觉模态中互不相关的噪声信息,提取更本质的信息作为对比学习的输入.对比学习在保证变分自编码器本身重构性能的基础上提升编码器提取特征的判别性能.因此本文模型可较好地适用于广义零样本任务,并在4个中等规模标准数据集上得到比CADA-VAE更高的准确率,以及在广义小样本图像分类任务大部分设置中获得性能的改善.尽管本文模型获得比基线方法更具竞争力的效果,但未同适用于视觉和语义特征提取的模型Transformer结合,今后将进一步研究和Transformer结合的方法,获得更好的信息表示,提高模型性能.
