基于YOLOv5算法的图像水深自动提取
2023-01-19柳进元张明锋
柳进元,张明锋
(湿润亚热带生态地理过程教育部重点实验室,福建师范大学地理科学学院,福建 福州 350117)
近年来,随着城市的快速发展和极端气候变化,在全球范围内,城市洪水已成为制约人类发展最频繁、最严重的灾害之一.瑞士再保险公司发布的sigma报告显示,2017年全球自然灾害造成的相关经济损失高达3 300多亿美元,大部分的损失来自洪水灾害,洪水灾害的损失占全球每年受灾人口的95%,直接经济损失占总数的73%[1].城市洪灾的发生也会造成重大的生命财产损失,如2021年我国某市特大暴雨,造成全省1 453.16万人受灾,因灾遇难302人,50人失踪[2].
面对城镇突发暴雨状况,如何有效地应对城市洪灾显得尤为重要.城市洪灾的预警和应急需要获取实时且覆盖面广的内涝深度信息[3].目前,城市内涝信息的识别提取主要有以下4种方法: 社交媒体数据[4]、水位传感器[5]、遥感[6-8]和视频图像监控数据[9].其中,水位传感器由于安装成本高,且多安装于江河湖泊水库等较大型水体处,因此它的监测范围难以覆盖整个城市区域[10];通过卫星遥感手段可以监测区域受灾范围,但其只能区分非洪水区和洪水区[11],并不能详细了解到城市道路中内涝的深度信息;社交媒体数据作为一种新型数据源,当洪灾发生时,社交媒体用户会发布大量的视频图像数据,这就为深度学习提供了大量研究数据.随着深度学习的快速发展,卷积神经网络模型(convolutional neural network,CNN)逐渐应用于目标检测任务,这使得基于CNN的目标检测模型算法大量涌现,将其应用在城市内涝研究中既可高效智能地获取水位信息,也具有部署成本低、覆盖范围广等优势.
当前该方面研究已有不少案例.Jiang等[12]利用SSD(single shot multibox detector)提出了一种基于常见参考物的城市内涝自动估计方法,并以河北省2017年7月的一场强降雨为案例,然而该实验缺乏测量工具来验证水位的真实高度.Vitry等[13]利用DCNN(deep convolutional network)将监控设备拍摄的自然水体与洪水进行区分,并可监测洪水水位波动情况,虽然其具有监测范围广的优势,但不能获取当前地点的绝对水位信息.Huang等[14]利用Mask R-CNN对车轮参照物进行识别,之后通过毕达哥拉斯算法测量出路面水深,这种方法虽然精度较高,但由于Mask R-CNN为多阶段目标检测算法,在面对视频数据时,无法做到实时检测.以上学者在城市内涝信息提取方面做出了许多成果,但所采用的检测算法大都以固定尺寸图像作为输入训练数据,增加了数据预处理的工作量,而本文所选用的YOLOv5检测算法可输入任意尺寸的视频图像,在数据预处理方面节省了大量重复操作时间,且由于其检测速度快、准确率高的特点被广泛应用于实际工作场景.
1 数据与方法
为了从街道摄像头所拍摄的视频图像中提取内涝深度信息,需要将街道上随处可见的参照物作为识别对象,常见的参照物有防撞桶、交通锥、垃圾箱、共享单车和车轮等,这些参照物在同一片区域往往具有特定的高度,可当作“标尺”,因此,根据参照物高于水面的高度即可估算局地的内涝深度.本文在街道上测量了部分参照物(图1)的真实高度,如表1所示.其中,共享单车的高度选取车把手到地面的距离,轮胎则选取街道中常见的家用小轿车轮胎.

图1 研究区参照物Fig.1 Study area reference

表1 参照物实际高度Tab.1 Actual height of reference
1.1 YOLOv5算法概述
YOLOv5[15]算法是由Ultralytics LLC 公司在YOLOv4算法的基础上不断改进得到的单阶段检测算法,与其他多阶段检测算法相比,其最显著的优势在于保证了检测精度的同时大幅提升了检测速度,算法的结构和轻体量也使得它可以方便快捷的部署在移动端.YOLOv5算法的网络结构共分为4个部分,如图2所示,分别为输入端(input)、骨干网络(backbone)、多尺度特征融合模块(neck)和预测端(prediction).

图2 YOLOv5网络结构Fig.2 Network structure of YOLOv5
其中,YOLOv5算法输入端包含 Mosaic 数据增强机制、自适应锚框计算机制及自适应图片缩放机制3个部分.在Mosaic 数据增强机制中先将图像进行随机裁剪、随机缩放和随机分布操作,之后再进行图像拼接,以此丰富图像检测数据集并使得网络的鲁棒性更好,在减少了GPU计算量的同时增加了网络的普遍适用性.自适应锚框算法会自动根据不同的数据集设定初始的锚框,由于初始锚框已有较好的效果,故本实验不改变锚框参数.骨干网络结构主要为Focus结构和CSPNET(cross stage partial network)结构.Focus结构会将图像进行切片操作,先将608×608×3的图像转换为304×304×12的特征图,然后再经过卷积操作后得到304×304×32的特征图.多尺度特征融合模块中应用了特征金字塔网络 (feature pyramid networks,FPN)和金字塔注意力网络 (pyramid attention network,PAN),FPN网络将特征信息从上向下通过上采样的方式传递融合,传达强语义特征,PAN网络将特征信息从下向上传达强定位特征,两者的应用加强了网络特征融合能力.预测端包括Bounding box 损失函数及非极大值抑制 (nonmaximum suppression,NMS)2个部分.YOLOv5 算法将GIOU_Loss函数作为 Bounding box 的损失函数,解决了图像中目标边界框不重合的问题,同时使得预测框回归的速度和精度有所提高.NMS的使用提高了多目标检测和有遮挡检测的识别能力,可获得最优目标检测框.
1.2 城市内涝水深测量原理
城市未发生暴雨洪灾时,街道路面无积水,此时利用目标检测算法可检测出参照物的完整高度,当城市发生洪灾后,街道上的参照物被水淹没,此时可以检测出参照物高出水面的部分,如图3所示,由于街道参照物种类较多,此处以轮胎举例城市内涝的测量原理,公式如下:

图3 水深测量示意图Fig.3 Schematic diagram of water depth
H1=Ymax-Ymin,
当得到参照物预测框的高度差后,城市内涝水深可由如下公式计算得出:
其中,H1为参照物的总像素高度,Ymax为参照物上边框的像素值,Ymin为参照物下边框的像素值,D为街道积水深度,H2为参照物高于水面部分的像素高度,Hr为参照物的实际高度,单位为m.
1.3 实验设计
本次实验以校园内一处游泳池作为实验平台,整个实验主要包括3个部分,分别为摄像机、参照物与水尺.首先,将铝合金水尺固定在池壁上用于记录真实水位变化;其次,将参照物分别摆放好并将摄像机调整到合适的拍摄角度;最后,向水池中注水并打开摄像机进行视频录制,实验的具体场景如图4所示.

图4 实验场景示意图Fig.4 Schematic diagram of experimental scene
本次实验以街道上常见的防撞桶作为水深识别的参照物,录制视频时长为3 h,帧率为30 帧/s,分辨率为1 080 P,由于泳池注水时间漫长,视频中真实水位变化缓慢,所以利用视频剪辑软件将视频按照每间隔60 s以图像的形式输出,每幅图像都有一个帧号.相邻两张图像的帧号间隔为1 800,例如一幅图像的帧号是1 200,那么下一幅图像的帧号就是3 000,最终该视频被转化为180张JPEG格式的图片.
本研究的实验环境配置如下:
硬件环境:处理器为intel xeon(R) Gold 5218,内存为256 G,显卡为Nvidia Quadro RTX4000,显存为8 G.
软件环境:GPU计算软件为CUDA版本1.9.0,深度学习框架为PyTorch1.9.
2 实验结果
YOLOv5检测算法支持识别的目标物品数量达到了80个类别,而本文所选取的街道参照物较为常见,目前包含5类,分别为轮胎、垃圾箱、交通锥、防撞桶、共享单车,因此只需将网络结构设置为yolov5s.yaml;较少的 epochs可以缩短总训练时长;batch-size是指一次训练迭代所抓取的样本数,其过小会导致模型不容易收敛,过大则容易陷入局部最优;经过不断优化调试,最终确定参数如表2所示.

表2 实验参数Tab.2 Experimental parameters
根据以上参数进行模型训练,测试训练模型耗时161 min,之后将待验证视频数据输入模型,平均每张图片的检测时间约为0.015 s,且随着模型的迭代次数增加,模型的损失率逐渐下降,准确性逐渐提高,具体如图5所示.
其中,Box为YOLOv5算法使用GIOU_Loss函数作为预测框的损失均值,越小预测框越准;Objectness为目标检测损失均值,越小目标检测越准;Classification为分类损失均值,越小分类越准;val则为验证集上的损失均值;Precision为分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例;Recall为分类器认为是正类并且确实是正类的部分占所有确实是正类的比例;mAP是用Precision和Recall作为两轴作图后围成的面积,值越高效果越好.由图5可知,本文所采用的YOLOv5算法具有运算效率高、准确度高的特点,可以做到实时检测视频图像.
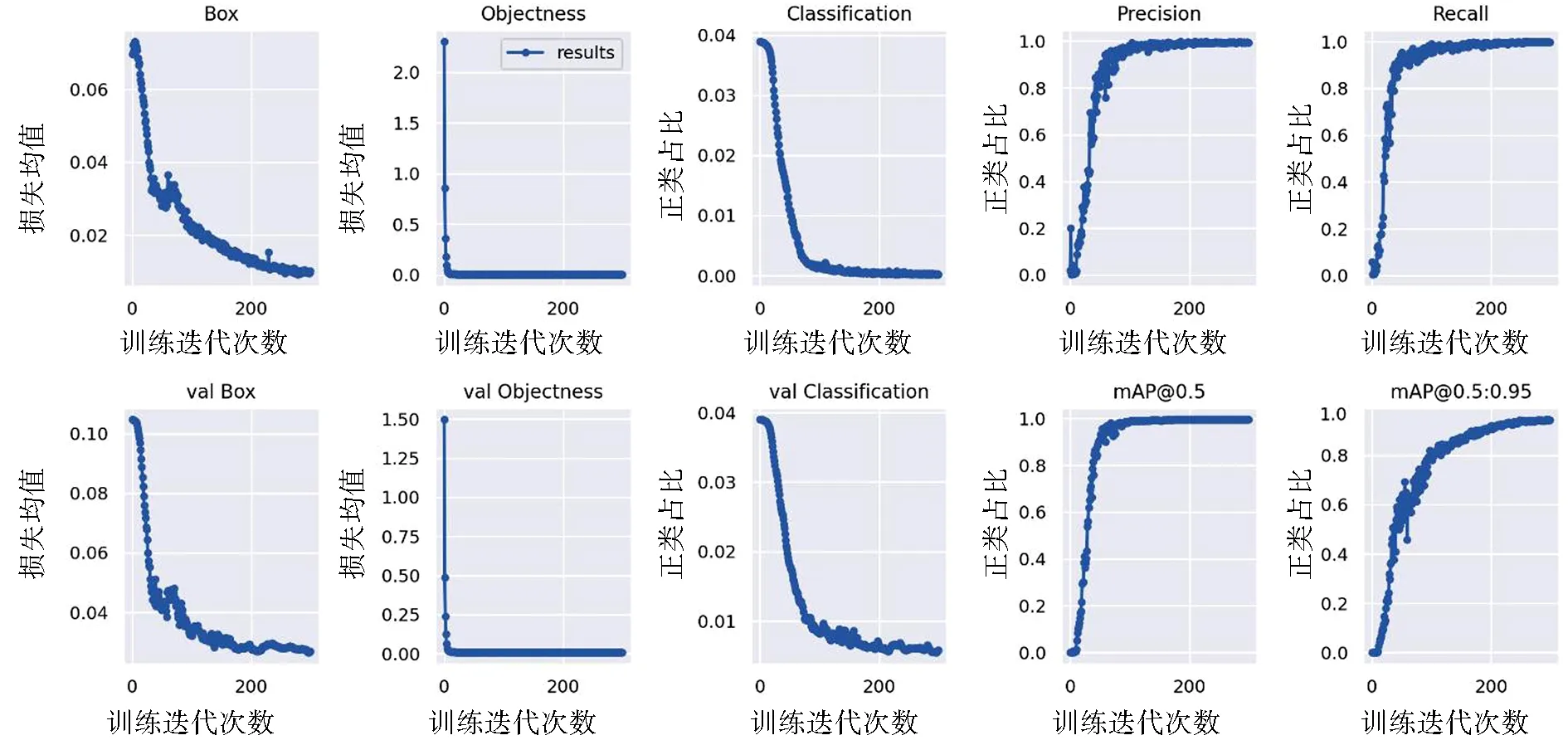
图5 损失率与准确性Fig.5 Loss rate and accuracy
2.1 标检测的准确性
本次实验选取防撞桶作为城市内涝水深参照物,将人工手动量算的参照物像素高作为观测值,将YOLOv5算法自动检测的参照物像素高作为模拟值,部分图像的参照物测量数据如表3所示.通过观察实验数据发现人工量算的参照物像素高和YOLOv5算法检测的参照物像素高较为接近,如图6所示.本实验选取均方根误差(RMSE)和平均绝对百分比误差(MAPE)作为结果准确性依据,实验结果展示RMSE值为1.832像素,MAPE值为1.165%.例如,本实验中一副图像里防撞桶的实际高度为0.8 m,手动检测的像素高为280,而YOLOv5算法检测的像素高为275,则它们的误差约为0.01 m,这种误差是可以接受的,并且未来随着监控摄像头分辨率的提高,此种误差会进一步缩小.
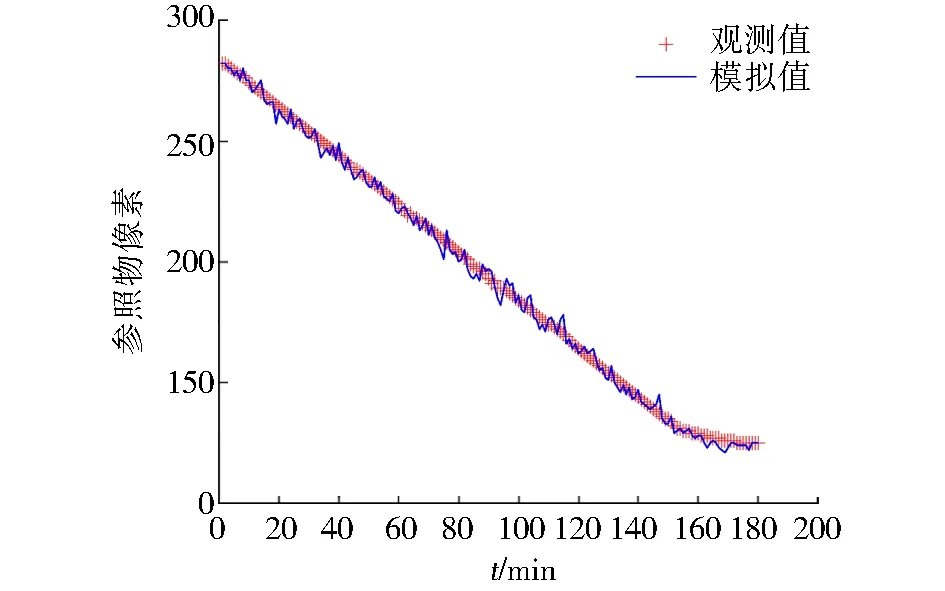
图6 参照物像素高度对比Fig.6 Reference pixel height comparison

表3 参照物高度测量数据Tab.3 Reference height measurement data
2.2 城市内涝深度估算的准确性
通过上述实验可以得到参照物在洪水期前后的像素高度变化,在此基础上调用水深计算公式得到计算结果,本实验将手动量算的像素高所计算的水深记为观测值,通过YOLOv5自动检测的像素高所计算的水深记为模拟值,部分图像的水深数据如表4所示,通过观察计算结果发现人工量算的水深和YOLOv5算法检测的水深较为接近,具体如图7所示.选取均方根误差(RMSE)和平均绝对百分比误差(MAPE)作为结果准确性依据,实验结果展示RMSE值为0.007 m,MAPE值为2.738%.

表4 水深计算数据Tab.4 Water depth calculation data
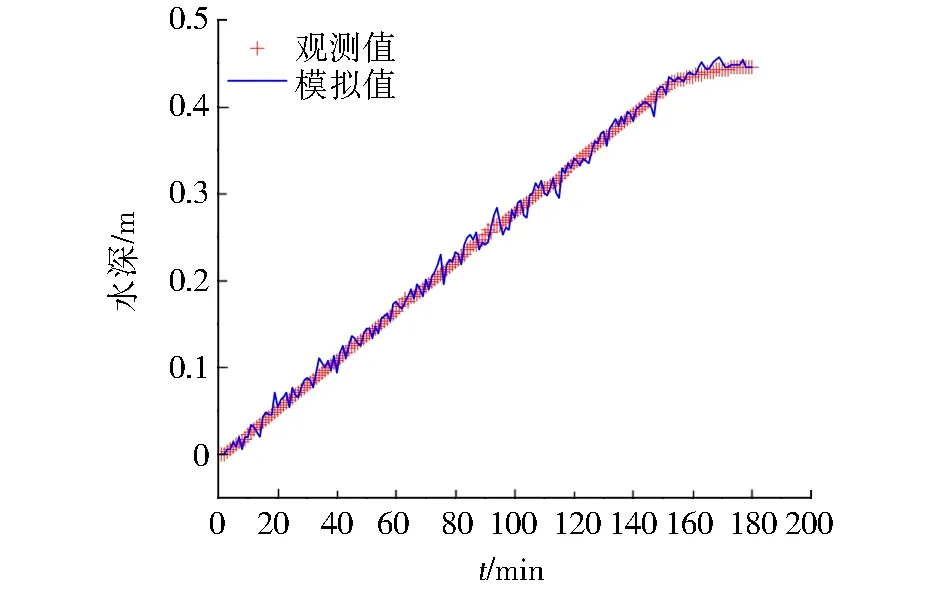
图7 水深计算对比Fig.7 Comparison of water depth calculation
3 讨论
通过观察实验结果,在测量参照物像素高度实验中,将人工量测数据与YOLOv5自动检测数据作对比,其RMSE值为1.832像素,MAPE值为1.165%;在图像水深估测实验中,将人工计算数据与YOLOv5自动监测作对比,其RMSE值为0.007 m,MAPE值为2.738%.整个模型训练共耗时161 min,之后将待验证视频数据输入模型,平均每张图片的检测时间约为0.015 s.由此本文提出的基于YOLOv5图像水深自动提取算法具有检测速度快、准确性高等优势.然而本文存在以下几个方面的不足:(1)本次收集的视频数据环境较为单一,仅在实验水池中拍摄视频,未来还需要在更多的场景中进行实验研究,增加实验环境的多样性;(2)本次实验拍摄条件较为理想,仅有水池中的水纹波动干扰,视频画面清晰,未来需要在真实暴雨场景中进行实验,增加雨滴噪声对视频图像的干扰,且有必要选取不同时刻下的暴雨视频以改变画面亮度;(3)在城市内涝灾害时期,数以万计的摄像头所产生的视频图像数据量相当巨大,单靠一台计算机运行处理无法高效提取水深信息,需要借助巨大算力设备来运行,未来可建立分布式计算机运行系统,让多台计算机协同计算运行以应对这一挑战;(4)真实场景中通常有行人或车辆掩盖到参照物,使得参照物的预测框变大、变小甚至无法识别,这可能会影响到目标检测结果的准确性进而影响内涝估测的深度.遇到此类问题一个有效的解决方法是根据人为经验来手动估算参照物的预测框高度或者丢弃此预测值.
4 结论
本文提出了一种基于YOLOv5图像水深自动提取算法,使用了道路中常见的几类物品作为城市内涝水深的参照物,之后在实验水池中注水以模拟真实街道内涝场景,最后经过水深算法自动提取水深信息,并将人工量测数据与YOLOv5自动检测数据作对比并使用均方根误差和平均绝对百分比误差作为实验精度验证指标,实验结果显示2种数据具有显著相关性,说明该算法在初步测试阶段效果良好,后期经实地进一步调试验证后便可为监测城市内涝水深提供技术支持.
基于YOLOv5图像水深自动提取算法具有检测速度快、准确性高等优势,不需要专门的仪器或实地测量,就可以低成本的部署监测,这具有极大的吸引力,其监测结果可应用于城市内涝的预报和预警,对城市未来的防灾减灾工作具有重要实践应用价值.
