一种精简的蘑菇图像分类模型
2023-01-19黄诗瑀黄丽清黄添强陈家祯郑子华
黄诗瑀,叶 锋,2,3,黄丽清,2,3,黄添强,2,3,陈家祯,2,3,郑子华,2,3
(1.福建师范大学计算机与网络空间安全学院,福建 福州 350117;2.数字福建大数据安全技术研究所,福建 福州 350117;3.福建省公共服务大数据挖掘与应用工程技术研究中心,福建 福州 350117)
随着近年来人工智能技术迅速发展,各大深度学习技术社区网站出现了许多预训练模型可供调用,使用者无需关心模型内部的实现细节.高度黑盒化的深度学习模式也带来了一个问题,在实际的图像分类应用中,没有正确评估数据集和模型之间的大小关系,偏好使用大而复杂的模型进行图像分类任务,虽然在训练集上达到了很高的分类精度,但是在验证集和测试集上分类精度较差,同时模型训练计算开销大,训练时间长,占用存储空间多,模型可塑性和维护性差.一些业余的深度学习使用者,并没有足够的算力在短时间内得到想要的模型,也导致了深度学习技术的应用门槛较高.本文对模型进行结构剪枝研究,并依据剪枝策略设计一个高效轻量的蘑菇识别模型MushroomNet-MicroV2(简称MicroV2).
本文的贡献如下:(1)收集并整理了包含9类蘑菇图片的数据集,经过图像增强(裁剪、旋转)处理之后为4 500张;(2)对图像分类网络各部分精度贡献做了比较研究,为卷积神经网络模块构建提供依据;(3)研究了数据集大小对图像分类精度带来的影响;(4)提出一种用于识别小型数据集的微型神经网络MushroomNet-MicroV2,该模型精简高效,可以在苹果M1 CPU等ARM平台上快速训练与部署,发布的PyTorch版本代码网址为https:∥github.com/Huang-Shi-Yu/MushroomNet/.
1 相关工作
现有的主要的图像分类模型包括AlexNet[1]、VGG[2]、GoogLeNet[3]、EfficientNet[4]以及Vision Transformer[5].这些图像分类网络在大型数据集(例如Imagenet)上表现良好,而对于小型数据集,此类网络存在过拟合现象.且大型网络训练缓慢,使得模型不易训练和部署.为了能适应小型数据集的分类任务,学者陆续提出了ResNet[6]、SqueezeNet[7]、MobileNet[8-10]、ShuffleNet[11-12]、Xception[13]等轻量化模型,以实现分类精度和效率之间的平衡.除此之外,常见的模型压缩的方法还有网络剪枝[14-17]和知识蒸馏[18-21].
现有的国内蘑菇图像分类工作:肖杰文等[22]收集了7种共1 675张蘑菇图像,并数据增强至8 375张作为分类对象,使用ShuffleNetV2进行分类,达到了55.18%的Top-1分类准确率;沈若兰等[23]分类9种共6 714张蘑菇图片,在ResNet50和Xception上分别达到了93.46%和95.10%的分类准确率;樊帅昌等[24]使用VGG、GoogLeNet和ResNet系列模型对14 669张图片(包含18种毒蘑菇图片和5种非毒蘑菇图片)进行分类,其中ResNet152性能最佳,在验证集上达到了92.17%的分类准确率,同时作者还比较了不同迁移学习策略(全局预训练和全连接层预训练)对模型性能带来的影响;陈秋月等[25]搭建了13层卷积神经网络,对8类共4 688张蘑菇图片进行分类,达到了95%的分类准确率,但是其数据集内类别不平衡(数量最少的类别有340张,数量最多的类别有900张)导致一些类别正确率较低.
现有的国外蘑菇图像分类工作:Zahan等[26]收集了8 190张蘑菇图像,先用对比度增强方法对数据预处理,随后用InceptionV3、VGG16和ResNet50对45种蘑菇进行3分类,分为可食用、不可食用和有毒,训练过程引入迁移学习,在3个分类模型上分别达到上达到88.4%、84.44%和58.65%的精度;Kiss等[27]收集了29 100共106类蘑菇图像,使用迁移学习训练EfficientNet—B5,并引入Noisy Student和类别增长策略,进行消融实验,比较了不同网络结构(EfficientNet—B0和EfficientNet—B5)和各种训练技巧对最终模型精度造成的影响,最终分类模型达到92.6%的精度;Ketwongsa等[28]收集了5种共623张蘑菇图像,并数据增强至2 000张图像,随后用GoogLeNet、AlexNet和ResNet50上执行二分类任务(有毒和可食用),分别达到99.5%、99.0%、99.5%的验证精度,提出的模型达到了98.5%的验证精度,同时还比较了各模型的运行时间,所设计的模型可以在NVIDIA GTX3060上以4.37 min完成10轮训练,虽然该工作精度很高,但是数据集内只有5类图像且数据增强方式没有公开,没有介绍模型设计依据.
2 研究方法
本文基于蘑菇数据集,着重探究卷积神经网络的性能和效率平衡点,分析卷积神经网络模型的卷积层、池化层和全连接层3个部分以及激活函数对分类精度和效率的影响,并设计精简的模型结构,在短时间内完成训练,获得存储占用小的模型,并达到误差可接受(相比大模型不低于5%)的分类结果.
2.1 卷积层和池化层
输入一定大小的图片,卷积核k以一定的间隔s滑动,用于执行对图像的上采样、下采样操作,并将数据用于下一层的计算.在卷积过程中,局部感受场以滑动的方式覆盖图像中所有元素,下一层的神经元可以呈现出本层的单个局部感受场(即特征),可以使用Padding操作填充边缘,以达到控制结果图像尺寸的目的.在PyTorch中,输出图像边长o的和输入图像边长i的大小关系如公式(1)所示.
(1)
卷积之后进行池化操作,池化操作使得模型具有输入不变性,即输入图像经过平移、旋转、缩放等方式处理之后依然可分类正确的特性.同时池化层使模型参数量迅速减少.池化层的特征压缩,使得浅层卷积提取的特征多为细节特征,例如斑点、纹理;中层卷积提取的特征多为局部特征(菌柄、伞褶);深层卷积提取到的则为全局特征(蘑菇轮廓).本文使用最大池化(MaxPool),在局部感受场区间内采集最大值,突出图像特征.经过卷积和池化操作之后,输出的特征图张量大小取决于全局池化层(AvgPool)的结构.
2.2 全连接层
卷积和池化层完成特征提取和降维后,展平成一维向量X输入全连接层.每一层的神经元都和下一层的所有神经元相连,神经元的学习参数包括权重w和偏置b.单个神经元的输入和输出关系如公式(2)所示,最后一层输出的向量维度表示分类数,取最大分量表示最终类别.
y=σ(wx+b).
(2)
本文设计的全连接网络中使用2种正则化方法减缓过拟合.(1)dropout:dropout在网络训练时随机地选出神经元致其失效,失效神经元不再进行信号的传递.本文搭建的神经网络在全连接层的第1层与第2层之间,第2层与第3层之间设置了dropout机制.(2)L2权重正则化:该方法通过在学习过程中对大的权重进行惩罚以抑制过拟合.本次实验为损失函数加上权重的L2范数,假设权重张量W=(w1,w2,w3,…,wn),L2范数的表达式如公式(3)所示,记λ为控制正则化强度的因子,L2范数的权值衰减表达式如公式(4)所示.对于所有权重,权重衰减方法都会为损失函数加上权重惩罚项Lweight,求权重梯度的计算中,都会为误差反向传播法加上正则化的导数λL2,PyTorch中使用weight—decay超参数作为λ进行权重参数惩罚.
(3)
Lweight=0.5λ·L2.
(4)
2.3 激活函数
在模型的层与层之间使用激活函数,增加模型的非线性表征能力.sigmoid和ReLU的表达式如公式(5)和公式(6)所示.
(5)

(6)
图 1展示了sigmoid函数和ReLU函数的原函数和导函数图像.传统的sigmoid函数两边导数值较小,当激活函数的梯度小于1时,在反向传播时可能会因网络层数过多会引起梯度弥散导致其越来越小,传送到足够深的层数时,该层的权重值由于梯度过小,几乎不会发生改变,增加训练轮数时模型性能不会得到明显的改进.而ReLU函数能在一定程度上克服传统sigmoid激活函数的梯度弥散问题.ReLU激活函数在输入大于0时,直接输出该值,在输入小于等于0时,一律按照0处理,同时其具有加快训练速度的作用.对比sigmoid类函数主要变化是:单侧抑制、相对宽阔的兴奋边界和稀疏激活性.

图1 Sigmoid/ReLU激活函数及其导数图像Fig.1 Sigmoid/ReLU activation functions and derivative graphs
ReLU函数输入值为负时,输出始终为0,其一阶导数也始终为0,导致神经元不能更新参数.为了解决ReLU函数这个缺点,在ReLU函数的负半区间引入Leaky值,称为Leaky—ReLU函数,其函数表达式如公式(7)所示.相比ReLU函数,Leaky—ReLU的导数值总是不为0,减少了静默神经元的出现,所有的神经元都会参与学习过程.相比Leaky—ReLU,ELU激活函数的单元激活均值可以更接近0,类似于Batch Normalization的效果,但是只需要更低的计算复杂度.虽然Leaky—ReLU函数也有负值部分,但是不保证在输入为负的情况下能够抵抗噪声干扰.反观ELU在输入小值时具有软饱和的特性,该特性能够提升对噪声的鲁棒性.ELU的激活函数如公式(8)所示.
(7)
(8)
2.4 MushroomNet模型结构设计
MushroomNet模型的参数信息如表 1所示,模型结构如图2所示.每一个卷积块都包括卷积层和池化层,卷积层结束之后使用池化层进行特征压缩.模型从小到大可以分为Micro(微型)、Slim(小型)、Middle(中型)、Large(大型).Micro模型只有一个卷积块,模型规模每提升一级,多一个卷积块且通道数翻倍.在输入数据上,Micro模型和Slim模型输入64×64像素的图片,中型和大型模型输入100×100像素的图片数据.

图2 MushroomNet 结构框架Fig.2 MushroomNet frameworks

表1 MushroomNet模型结构参数信息Tab.1 MushroomNet model structures parameters
在所有MushroomNet模型中,第1个卷积块遵循VGG设计思想,连续使用2个3×3像素的卷积层,第一个卷积层将通道数由3提升至32,第2个卷积层保持通道数不变.随后的每一个卷积块,均把通道数翻倍.在全连接层中根据通道数进行设计,经过1个全连接层通道数减半.从图片输入到输出一共要经过3次下采样,由于小模型层数较少,在卷积层中使用无边缘填充的降尺度卷积.
2.5 MushroomNet模型结构优化
为了比较模型各部分对于分类的重要程度,选择2.4节所述的Micro模型再次进行修改,以模型各部分的功能作为修改依据.首先卷积层用于特征提取,特征的复杂程度决定了卷积层的规模,若图像特征较多也应设置更多卷积核和卷积层,以便于从多尺度更加精细地提取特征.其次池化层用于特征压缩,将指定区域(感受野)内的特征简化并减小图像尺寸,使得模型开始关注更高级的语义特征.最后全连接层用于特征分类,通过神经元的前向计算以输出类别向量,取最大分量作为最终预测类别.
本文尝试以下4种Micro模型的修改方案,在Larger FC中使用更多全连接层神经元增强分类能力;在More channels中加入更多通道数增强模型表征能力;在Clip1和Clip2中减少卷积,并使用更大的Stride以验证卷积对特征提取的贡献和引起的模型代价.修改后的Micro模型结构参数见表 2.本文模型和现有一些模型分类精度和效率对比参考实验3.3节和实验3.4节.同时还比较了几个激活函数对模型性能的影响,分别在网络每层之间引入ReLU函数、Leaky—ReLU函数和ELU函数,具体实验结果见3.5节.

表2 修改后的Micro模型结构Tab.2 Altered Micro model structures
2.6 模型可解释性技术
积分梯度法[29]是Sundararajan等于2017年提出的,类似的技术还有Grad-CAM显著性特征图可视化[30].显著性特征图的输出结果呈现团块状,而积分梯度输出结果呈现点状,有利于观察纹理信息对于分类的作用,因此本文选择积分梯度,该方法可以在保证敏感性、完整性和实现不变性的基础上,增强模型可解释性.
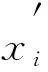
(9)
(2)完整性原则.完整性是指输入各分量的归因,求和之后等于最终模型预测改变量.同时模型最终预测,是一个量变引起质变的过程,是输入图像各像素共同作用的结果.在本文对分类器的归因任务中,检查了蘑菇图像相对于基线改变的归因,可以直观地根据归因图的区域亮度判定蘑菇各部分对于最终分类的影响.如公式(10)所示,所有像素点的积分累计后,即为输出的改变量.
(10)
(3)实现无关性原则.积分梯度方法的归因结果只跟输入和输出有关,和具体网络实现无关.若具备相同的输入和输出,归因结果是一致的,本文中选择积分梯度方法,因为它能排除底层网络实现对归因结果的干扰,直接根据输入和输出获得正确的归因图.
3 实验
3.1 实验设置
本实验基于PyTorch实现,使用NVIDIA GTX2080TI训练模型,训练过程中使用Adam优化器,正则化参数设置为0.000 1,学习率设置为0.001,dropout设置为0.5,batch—size为64,epoch设置为30轮.模型性能评价指标使用模型精度ACC和交叉熵损失cross—entropy—loss.
3.2 数据集
在互联网上爬取图片制作蘑菇数据集,先筛选和裁剪处理获得蘑菇图片2 250张(9类×250张),随后使用旋转、对比度调整等方法以扩充数据集至4 500(9类×500张),最后进行图像尺寸变换以适应特征提取网络的输入大小,数据集相关信息如表 3所示,数据集中图片样例如图 3所示.划分训练集和验证集时按类别8∶2进行随机划分,即训练集为3 600张图片(9类×400张),验证集为900张图片(9类×100张).

表3 数据集信息Tab.3 Datasets information

图3 数据集(Mushroom-LQ)展示Fig.3 Dataset (Mushroom-LQ) display
3.3 模型规模对比实验
实验结果如表4所示,数据取第30轮.在MushroomNet系列模型中,模型结构越复杂识别精度越高,从Micro模型到Slim模型提升最明显(50%至77%),而Middle模型精度到达86%之后,增大模型规模带来的性能提升逐渐变小(Large模型:88%),且增大模型规模带来的代价是极高的.相比Large模型,VGG11的训练时间多了528 s,且参数量多了480.7 M,然而验证精度却持平.因此有必要研究模型各组件对精度提升带来的影响,实现有规则地构建特征提取模型.

表4 模型性能和效率Tab.4 Model performance and efficiency
3.4 模型结构消融实验
以Micro模型作为baseline,探讨模型各部分对分类精度和效率的影响.数据集使用64×64像素低分辨率的Mushroom—LQ,其余设置参照3.1节,实验结果如表 5所示,接下来从分类精度和训练和存储效率方面对结果进行分析.
(1)分类精度.增加全连接层的神经元(Larger FC)使得模型验证精度提升明显(0.50→0.88),因为Baseline中全连接层神经元较少,无法在全连接层有效地进行模型表征,导致分类能力较差.增加通道数(More channels)对于精度影响极小(0.50→0.53),因为低分辨的蘑菇数据集较简单,无需更多卷积核进行表征.减少1层卷积(Clip1)导致精度下降(0.50→0.48),而完全去除卷积(Clip2)影响较大(0.50→0.39),说明在Baseline中1层卷积提取到的特征已经接近饱和.
(2)训练和存储效率.全连接层中引入更多神经元(Larger FC),会使模型性能显著提升(0.50→0.88),引入了更多的参数(189.3 K→1.3 M),但模型训练时间略微增长(41 s→42 s,因为GTX2080TI有Cuda加速,差距较小,在ARM平台差距会拉大).在特征较为简单的蘑菇图像中,更多通道(More channels)并不会带来更好的模型性能表现,但是会引入额外的参数量(189.3 K→396.4 K),实验只采用了64的通道数,参数量相比基准Micro模型上升207.1 K,而3.3节实验中的Large模型还增加了2层128和256的通道数,模型参数量直达10.7 M,同时更多通道也会带来训练时间的提升,通道数越多,提升越明显.更多的卷积层没有带来更强的性能,参照Micro+Larger FC和3.3节实验中的Large模型,反而训练时间(41 s→99 s)和参数量(1.3 M→10.7 M)提高了许多,相反更少的卷积层拥有更低的参数量(152.7 K和18.3 K)和更快的训练时间(41 s和39 s).
综合表 4和表 5,Micro+Larger FC是这些模型中兼具精度(0.88)、训练速度(41 s)和低存储(1.3 M)的模型,本文将用它继续后面的实验并称其为MicroV2模型.

表5 模型消融实验结果Tab.5 Model ablation study results
3.5 激活函数比较实验
使用3.4节MicroV2模型,在3.1节Mushroom—LQ数据集上做测试.实验结果如表 6所示,使用ReLU激活函数的改进版本,模型训练误差和验证误差变低,而精度和训练时间并无明显变化.

表6 MicroV2模型的激活函数比较Tab.6 Activation functions comparison in MicroV2 model
3.6 数据集比较实验
使用3.4节MicroV2模型,在3.1节4种数据集上做测试.全连接层前加入了AvgPool,因此无需考虑特征网络和全连接层向量对齐问题,即此时的MicroV2模型适合3.1节所述的各种尺寸的数据集.实验结果如表 7所示,HQ数据集上训练时间长而精度略低,因为MicroV2模型卷积层较简单,无法提取高分辨图像中的复杂特征(尤其是纹理信息),MQ和LQ精度差距不大(0.01),但是时间相差32 s.half—LQ比LQ精度降低了0.10,说明数据增强的重要性.

表7 MicroV2模型在各数据集上的表现Tab.7 MicroV2 model performance in various datasets
3.7 积分梯度归因
使用梯度归因技术输出MicroV2模型在分类各种蘑菇时的可视化归因图,归因结果见图 4,一幅原图对应一幅归因图像.归因图中某区域的绿色越亮,表示该区域在分类中起到的作用越明显.从归因结果可以看出,在本文数据集上训练的卷积模型能够正常学习到蘑菇的特征,同时在分类时,优先考虑伞盖特征,只有在伞盖特征相比伞柄不明显(杏鲍菇、金针菇的伞盖很小,黄牛肝菌伞柄颜色鲜艳)时,才会考虑使用伞柄作为主要特征分类.

图4 模型分类结果和归因图Fig.4 Model classification results and attribution images
3.8 MicroV2在各计算平台的测试
将3.4节实验中的MicroV2模型和Mushroom—LQ数据集迁移到PC平台和嵌入式平台,测试其性能以及训练时间.由表 8可知,本文设计的MicroV2模型不仅能在配备有NVIDIA GTX2080TI的服务器上快速训练,也能在MacBook等设备上得到可接受的训练时间(143 s)和精度(88%),甚至在嵌入式设备(RK3399)上也能以3 029 s的时间完成训练.综上所述,MicroV2模型实现了低成本和灵活的模型训练.

表8 MicroV2在各平台的精度和效率测试Tab.8 Accuracy and efficiency testing of MicroV2 on various platforms
4 总结
本文基于蘑菇数据集提出一种兼顾效率和性能的MushroomNet-MicroV2模型,相比传统大型模型,该模型能够在可接受的精度误差下实现快速训练(Apple M1:142 s),并极大程度减少参数量(1.3 M).在Mushroom—LQ数据集上达到了88%左右的准确度.同时通过消融实验,比较了网络模块和数据集对模型精度带来的影响,说明在小数据的场景下,提高性能的最佳方式是增加全连接层的连接节点数以及使用数据增强方式扩充数据集.从效率和成本考虑,在实际应用场景中,应根据数据特征和复杂度选择合适大小的模型.
未来的工作将从分类精度的角度出发,可在原有的基础之上扩大数据集,在数据集中加入一些蘑菇局部特征的图片,引导模型学习.还可以依据模型在每一种类蘑菇的数据集上的表现,来调整数据集的选取,对于数据集的预处理可以更加多样化,让分类精度进一步提高.从模型效率的角度出发,引入一些其他模型加速策略(例如迁移学习),或是从内部模块上简化模型计算(例如深度可分离卷积).
