基于实体语义扩展的跨境民族文化文本检索
2023-01-18毛存礼郝鹏鹏雷雄丽王红斌张亚飞
毛存礼,郝鹏鹏,雷雄丽,王 斌,王红斌,张亚飞
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650000;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650000;3. 昆明冶金高等专科学校,云南 昆明 650000)
0 引言
跨境民族(1)跨境民族是指居住地“跨越”了国境线,但又保留了原来共同的某些民族特色,彼此有着同一民族的认同感的民族。文化检索任务旨在利用信息检索技术从互联网中获取跨境民族关于节日、饮食、服饰和建筑等文化领域相关的内容,准确地获取跨境民族文化相关的数据对研究同一民族在不同国家文化之间的异同具有重要的意义。
当前文本检索的主流方法多是基于深度学习的语义匹配模型,如Conv-knrm模型[1],其能够捕捉更加细微的实体语义特征,将查询词语和待检索文本更好地关联起来,其在通用领域上取得了很好的效果。而针对跨境民族文化检索任务,基于现有的模型很难准确检索到与查询文本中具有跨境关联关系的民族文化信息。如图1所示,在检索“泼水节”时,传统的文本检索只能检索出与傣族“泼水节”这个词相关的文本。但“宋干节(泰族)”等具有跨境关联关系的相关文本,也应出现在跨境民族文化文本检索的结果中。知识图谱[2]可以较好地表示实体之间的关联关系,通过构建跨境民族文化知识图谱,能够表示出相关实体之间存在的跨境关联关系。
针对以上问题,本文提出一种基于实体语义扩展的跨境民族文化文本检索方法,在Conv-knrm模型的基础上,利用跨境民族文化的知识图谱,将跨境民族文化实体之间存在的关联关系以知识三元组的形式体现;使用TransH模型[4]将这些知识向量化,之后将其融合到查询文本的实体向量中,扩展查询文本中的实体语义信息,提高模型对跨境民族文化检索的准确性。
本文的主要贡献如下:
(1) 提出了一种基于实体语义扩展的跨境民族文化文本检索方法,利用该方法在融合跨境民族文化知识图谱的基础之上,提高了跨境民族文化文本检索的效果。
(2) 在TransH模型的基础上,将实体标签向量与实体向量相融合,丰富了实体的语义信息,增强了实体向量的表征能力。
1 相关工作
目前,跨境民族文化领域的相关工作极其稀少,特别是文本检索等方面。而传统的文本检索已有大量的研究工作,且主要分为两大类: 传统文本匹配模型和基于深度学习的语义匹配模型,具体如下:
(1) 传统文本匹配模型主要包括倒排索引模型[5]以及基于实体的检索、分布式检索等。其核心是通过文档的表面特征对文本进行检索匹配,这类方法的缺点是仅解决词汇层面的匹配问题,而没有考虑语义层面的匹配问题,具有一定的局限性。
(2) 近年来深度学习技术成为文本检索的主流方法,其核心思想是把文本中的每个词语进行向量化表示,然后利用神经网络来提取文本的语义特征,最后通过计算这两个文本语义特征的相似度来判断文本之间是否匹配。这类方法主要包括基于语义表示的文本匹配模型[6-11]和基于交互的文本匹配模型[12-16]。Chen等[11]提出了增强序列推断模型,利用双向长短时记忆网络和注意力机制来推导输入的查询文本与文档,判断这二者之间是否存在语义关联。以上基于表示的文本匹配模型更侧重对语义向量表示层的构建,通过语义特征衡量文本的匹配程度。为了充分考虑句子、词语之间的关系,采用多粒度的表示[17-18]也可以提高模型的性能,如Lai等人[18]提出一种新颖的基于格子网络的卷积神经网络(Convolutional Neural Network,CNN)模型,利用单词中的多粒度信息,丰富语义特征,以解决中文的匹配问题。上述方法均取得了不错的效果,证明融合外部知识有助于提高文本匹配的准确性,但这些方法还存在融合的语义信息不够丰富的问题。而本文提出的融合知识图谱的实体语义扩展可有效缓解这个问题。
2 跨境民族知识图谱结构特点及数据特征分析
本文使用前期工作构建好的跨境民族文化知识图谱来扩展跨境民族文化实体语义信息。跨境民族文化知识图谱中包含傣族、佬族、掸族等民族类别共34个,每个民族下面都有对应的宗教文化和建筑文化等6个类别,这6个类别还有各自对应的小类,共计13个,具体如图2所示。
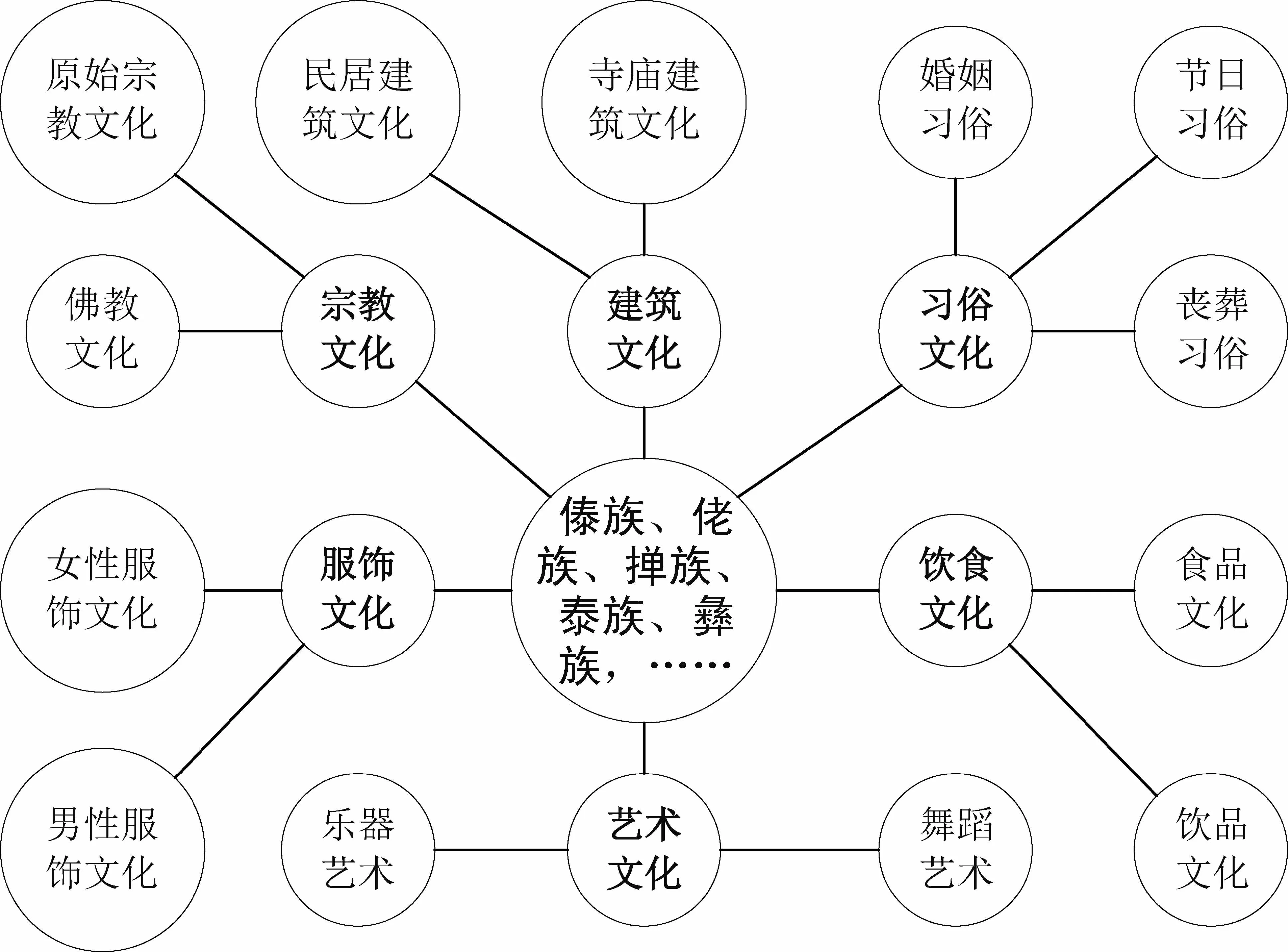
图2 跨境民族文化类别图
在确定跨境民族文化的分类体系后,需要根据各个类别来定义与跨境民族文化相关的属性包括实体的名称、别称、描述内容、 实体标签以及实体存在的一些特征。通过定义实体的这些信息,可以丰富跨境民族文化实体的语义信息。
本文利用Neo4j(2)https://neo4j.com/进行知识图谱三元组的存储,将实体作为节点(Node)来进行存储。如图3所示,对于“解夏节”这个实体来说,它的实体标签类别信息即为“泰族”“泰族习俗文化”“泰族节日文化”等。建立实体与实体之间的关系对跨境民族文化领域知识图谱中的知识进行关联整合,使得跨境民族文化知识图谱更加具有表示性。跨境民族文化领域的实体关系错综复杂,主要可以归纳为: 包含、跨境、位置、同属、属性。最后通过百科词条(3)https://baike.baidu.com/信息和结构化知识的组合就可以得到知识三元组信息。具体例子如表1所示。

表1 知识三元组示例表
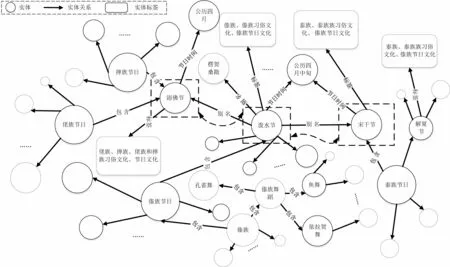
图3 跨境民族文化知识图谱示例图
跨境民族文化知识图谱的实体标签数量共6 603个,知识三元组共863个。其中宗教类别的标签有1 107个,宗教类别的知识三元组有137个,具体如表2所示。通过跨境民族文化知识图谱,将跨境民族文化之间的实体关联起来,为后续扩展实体的语义信息提供基础。
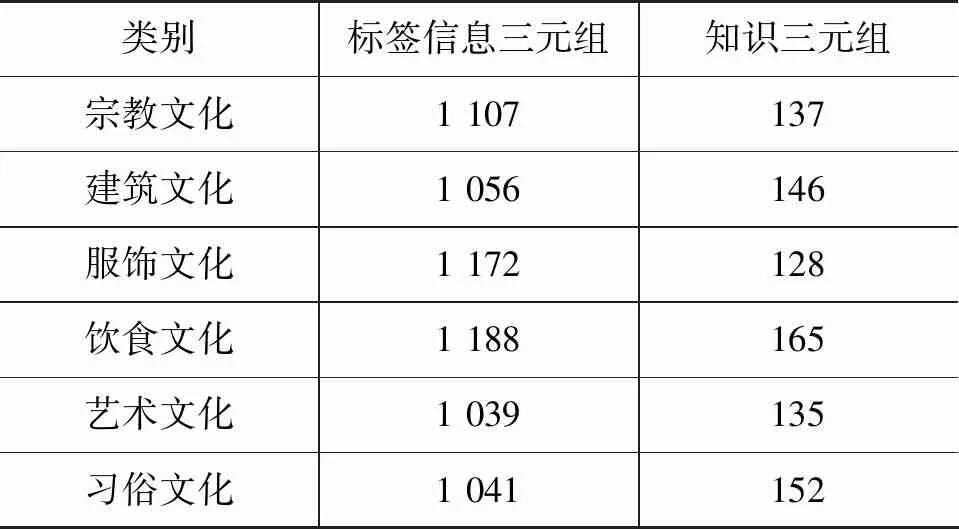
表2 知识图谱数量表
3 基于实体语义扩展的跨境民族文化文本检索模型
针对跨境民族文化文本检索任务,提出的模型架构如图4所示,包含了以下四个部分。
(1)实体语义扩展: 将知识图谱中的三元组以及标签信息随机初始化,再利用TransH模型将实体向量与标签向量拼接后的向量进行训练,得到包含标签信息的实体向量,并将其与预处理后对应的查询文本词向量融合,得到语义扩展后的查询文本词向量。
(2)文本特征提取: 将待检索文本向量化后,使用卷积神经网络对上一步得到的语义扩展后的查询文本向量以及待检索文本向量基于不同大小的卷积核进行N-gram特征提取,分别得到查询文本特征向量及待检索文本特征向量。
(3)文本相似度计算: 对上一步得到的两个特征向量进行交叉相似度计算,得到对应的相似度矩阵。
(4)文本相关性得分计算: 对相似度矩阵中的每一个行向量都进行高斯核的转换,得到其在高维空间的表示。再对转换后的高维向量取对数之后累加得到一个全局的特征向量,在此基础上使用单文档排序方法得到相关性文本排序,取排名最高的前10条作为跨境民族文化文本检索的返回结果。

图4 基于实体语义扩展的跨境民族文化检索模型
3.1 跨境民族文化实体语义扩展
3.1.1 跨境民族文化实体三元组
为了将知识图谱中实体间的关联关系和实体标签信息融合到文本中,本文将查询文本中的实体与跨境民族文化知识图谱中的实体进行匹配,返回包含该实体知识信息及标签信息的实体向量。
3.1.2 向量化表示
由于在跨境民族文化知识图谱中存在很多同义不同词的实体,如知识三元组[“泰族”,“食品”,“露楚”]中的“露楚”与另一个知识三元组[“泰族”,“食品”,“泰式和果子”]中的“泰式和果子”所表示的语义是一致的。而相比于TransE模型,TransH模型能够更好地表示具有复杂语义信息的实体。因此本文使用TransH模型对知识三元组和实体标签信息进行向量化表示。
TransH知识嵌入模型是Wang等人[4]于2014年提出的模型,其核心思想是对每一个关系定义一个超平面Hs和关系向量dr,然后把头实体向量head和尾实体向量tail分别投影在Hs上得到相应的头实体投影向量h和尾实体投影向量t,对于加入实体标签的正例三元组需要满足式(1)。

其中,Lhead为头实体标签向量,Ltail为尾实体标签向量。再经过transH模型训练后得到正确的包含实体标签信息的实体向量VE,如式(4)所示。
3.1.3 语义扩展

3.2 跨境民族文化文本特征提取
其中,w为每个卷积核的初始化权重矩阵,i为第i个词语,l为卷积核的宽度,Mi,i+l为第i到第i+1个词语的词向量矩阵。
利用m个不同的卷积核K1,K2,…,Km获取不同的特征图,然后加入一个随机初始化的偏置向量,再经过一个非线性激活函数,得到m维的L-gram特征向量矩阵,计算如式(7)所示。

对于每个长度为l的N-gram向量,通过卷积操作把文本的词向量转化为L-gram的特征向量表示AL,如式(8)所示。
其中,M为词向量矩阵,x为文本分词后词语的个数。
3.3 跨境民族文化文本相似度计算
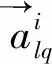
3.4 跨境民族文化文本相关性得分计算
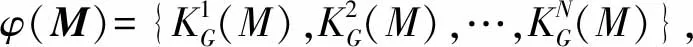
其中,μk表示第k个高斯核的均值,δk表示第k个高斯核对应的参数。得到高阶特征φ(M)后,再将其相互拼接得到最终用来计算相关性得分的特征向量ψ(M),计算如式(11)所示。
其中,ψ(M)的维度是N×lmax,lmax为卷积核的最大宽度。再利用Learning to rank层来将文本间的相关性特征向量ψ(M)进行线性计算,以此得到查询文本和待检索文本之间的相关性得分,如式(12)所示。
其中,wr和br表示超参数。在模型训练的过程中,定义了标准的Pointwise loss来对模型进行训练,Pointwise loss的计算如式(13)所示。
其中,n为待检索文本的数量,xi为第i个待检索文本的真实标签。通过以上计算可以得到查询文本和待检索文本的相关性得分,根据相关性得分将一个查询文本对应的多个待检索文本进行排序,再取排名最高的前10条作为跨境民族文化文本检索的返回结果。
4 实验结果及分析
4.1 实验数据集
本文使用的数据分为两部分: 一是构建的跨境民族文化知识图谱数据,其中包括了40种类别,知识三元组863条;二是句对数据214 591条,句对的平均长度为145个字符,平均每条句对数据中包含3~4个跨境民族文化实体。具体情况如表3所示。
句对数据来源于百科网站(4)https://baike.baidu.com/的InfoBox数据、各个民族网站上的数据,采用人工的方式标注正例和负例。

表3 实验数据详情
使用LTP识别出大部分查询文本中的实体信息,再人工标注出实体识别工具未识别出的跨境民族文化实体。标注情况如表4所示,当句子1与句子2各个实体之间均存在对应的关联关系时,人工打上标签1;反之则打上标签0。最终得到正例数据和负例数据各100 000条。
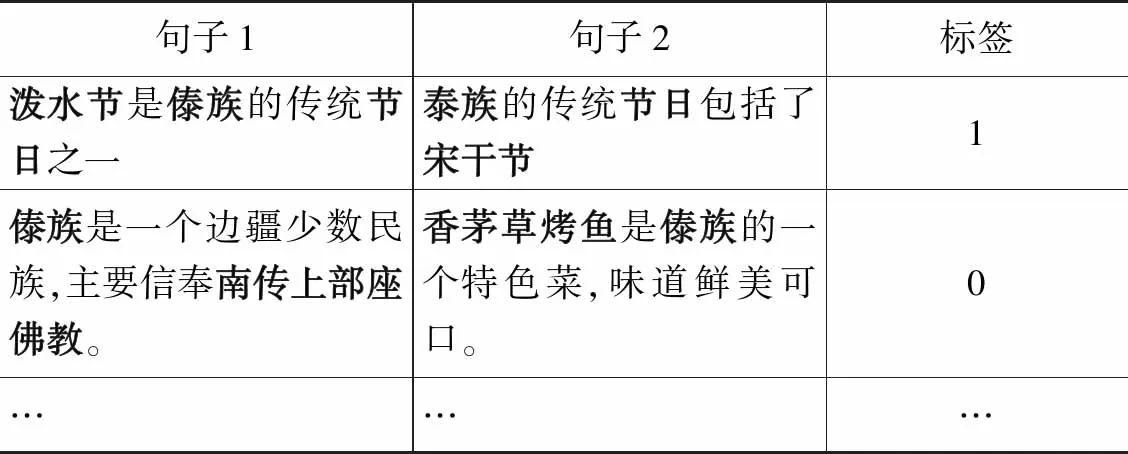
表4 实验数据示例
4.2 实验参数设置
为了获得最优的文本检索模型,实验过程中,通过不断的调节实验参数,以确保模型在参数最优的情况下进行训练,具体的参数设置如表5所示。

表5 模型参数设置
4.3 实验评估指标
为了证明本方法的有效性,本文通过MAP[20](Mean Average Precision)来对模型进行评估。MAP的计算如式(14)所示。

4.4 实验结果与分析
实验1: 基于交互的不同方法实验结果对比
为了验证本文方法的有效性,在相同语料的情况下,与基于交互的文本匹配方法进行对比,设计了3组实验,实验结果如表6所示。
(1)K-nrm模型: 由Xiong等[12]人在2017年提出的一种基于文本词向量交互的文本匹配模型。
(2)ESIM模型: 由Chen等[11]人在2017提出的一种基于文本局部特征与序列特征之间的交互的文本匹配模型。
(3)MatchPyramid模型: 由Pang等[13]人在2016年提出的一种基于单词之间交互的文本匹配模型。

表6 基于交互的不同方法实验结果对比
从表6可以看出,本文模型与其他三个模型相比较MAP指标分别提升了12%、10.8%和5.8%。K-nrm模型直接采用文本词向量交互的方法来构建相似矩阵,因此,文本词向量的质量影响模型匹配效果的好坏,且使用查询文本中词语之间的交互去表示文本之间的联系的效果较差。在跨境民族文化领域,实体与文本特征之间的交互对于检索任务存在着正向影响。而ESIM模型则没有考虑词语与文本特征之间的交互,故检索效果欠佳。MatchPyramid模型仅实现了词语之间的交互,而缺少实体之间的关联关系,导致模型性能不佳。本文模型与上述几个模型相比添加了N-gram的卷积,增加了模型的层次性,可以捕捉到更加细微的语义实体,因此本文模型在跨境民族文化文本检索的任务上有着更好的表现。
实验2: 基于语义相似度计算的方法实验结果对比
为了验证本文的有效性,在同等语料的情况下,与基于语义相似度计算的文本匹配方法进行比较,设计了4组实验,实验结果如表7所示。
(1)DSSM模型: 由Huang等[6]人在2013年提出的一种基于DNN的文本匹配模型。
(2)ABCNN模型: 由Yin等[7]人在2015年提出的一种基于带有注意力机制的CNN的文本匹配模型。
(3)CLSM模型: 由Shen等[8]人在2014年提出的一种基于CNN特征提取的文本匹配模型。
(4)DIIN模型: 由Palangi等[9]人在2015年提出的一种使用LSTM和CNN提取特征的文本匹配模型。

表7 基于语义相似度计算的方法实验结果对比
由表7可以看出,本文的模型优于基于语义相似度计算的模型,与DIIN模型相比较提升效果较为有限,原因是本文模型的结果均是经过去掉最好结果与最差结果后,将剩余结果取平均值得到,实验最优结果与其相比要高约0.9%。DSSM模型的词向量是基于词袋模式通过字向量拼接得到的,对于跨境民族文化同义不同词的实体来说,字向量拼接会使这些实体语义相差更大,导致模型效果不佳。ABCNN模型,则是通过将句子之间的相互联系加入到CNN中来提升检索效果。但由于跨境民族文化查询文本序列信息语义的不充分,导致其在跨境民族文化检索任务上效果较差。CLSM模型利用CNN模型,很难得到距离较远的两个词语之间的联系,导致模型的检索效果较差。DIIN模型虽然充分利用了文本中的字向量和词向量,但针对跨境民族文化领域的实体关联较弱,降低了检索的准确性。本文模型针对跨境民族文化知识图谱,利用TransH模型将实体标签信息融合到实体向量中,再将这些实体语义信息融入到查询文本中,因此本文模型在跨境民族文化文本检索任务上的效果有了明显提升。
实验3: 消融实验
为了验证本文使用的TransH模型进行实体语义表示对于跨境民族文化文本检索模型的有效性,选取Dai等人[1]所提出的Conv-knrm模型作为本文的Baseline模型并进行了消融实验,实验结果如表8所示。可以看出,本文方法与Baseline相比提高了5.4%。该方法扩展了查询文本中的实体语义,充分地对文本的语义信息进行了匹配,而基线模型仅针对文本之间的N-gram特征进行交互,没有考虑到实体语义信息不充分的问题,而且对于跨境民族文化领域存在的同义不同词现象,无法将不同实体关联起来,使得基线模型对跨境民族文化检索的准确率降低。

表8 消融实验
实验4: 检索效果对比
图5是本文方法利用跨境民族文化知识图谱对实体语义扩展后的效果对比,图5(a)是没有利用知识图谱扩展的检索效果,图5(b)是本文模型的检索效果,可以看出扩展后检索“宋干节”的相关文本时,与其相同的节日“傣族泼水节”的相关文本(图中斜体部分)内容也会被检索出来,提高了跨境民族文化领域的文本检索效果。

图5 融合知识图谱后检索效果对比
5 结束语
本文针对跨境民族文化的文本检索任务,提出一种基于实体语义扩展的跨境民族文化文本检索方法。利用前期工作构建好的跨境民族文化知识图谱和实体标签对查询文本中的实体进行语义扩展,缓解查询文本语义信息不充分导致检索不准确的问题。实验结果证明,本文方法得到了较好的效果。目前本文主要解决了查询文本和待检索文本之间的相似度问题,而没有具体考虑文本排序的相关方法,未来工作中将结合相应文本排序方法以提升模型整体性能。
