基于高困惑样本对比学习的隐式篇章关系识别
2023-01-18窦祖俊徐旻涵陆煜翔周国栋
李 晓,洪 宇, 窦祖俊,徐旻涵,陆煜翔,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
篇章关系识别旨在判断两个语言单元(子句、从句及文本块等,简称“论元”)之间的语义关系,其核心任务是形成可靠的论元表示和关系感知方法,对语义的深度表示和敏锐感知有着极高的要求。因此,篇章关系识别属于自然语言处理(NLP)领域底层的关键基础性研究。其对机器翻译[1]、情感分析[2]、自动文摘[3]和问答系统[4]等NLP应用层研究,有着极高的借鉴甚至辅助作用。
篇章关系识别的处理对象是一个由论元和关系标记形成的三元组{Arg1;R;Arg2}。通常,语序上置前的论元为Arg1,置后的论元为Arg2,关系R为待解的关系标记。面向篇章关系识别研究,宾州篇章树库(Penn Discourse Treebank,PDTB)[5]提供了大规模权威的标记数据,其定义的论元关系体系共计包含三层,其中,层次最高的粗粒度关系类别涉及四项,分别为:对比关系(Comparison)、偶然性关系(Contingency)、扩展关系(Expansion)和时序关系(Temporal)。本文继承前人的主要研究模式,面向四种粗粒度论元关系开展二元和多元分类的研究。
值得注意的是,PDTB根据是否存在连接词,将篇章关系分为显式篇章关系和隐式篇章关系。其中,显式篇章关系在多元分类上的准确率已达到96.02%,而隐式篇章关系的识别的准确率则相去甚远(1)截至2021年末,现有前沿技术的最优性能维持在70.17%的水平。。下文给出的例1即为一个隐式篇章关系的测试样本,其可能的连接词meanwhile(译文:同时)在真实样本中为缺省项,模型无法利用连接词进行直观的关系预判,仅能通过充分理解、表示和感知论元的语义,促进关系判别器做出正确预测。本文将集中在隐式篇章关系识别这一任务上开展研究。
例1[Arg1]:Valley Federal is currently being examined by regulators
(译文: 联邦目前正在接受监管机构的审查)
[Arg2]:meanwhilenew loans continue to slow
(译文:与此同时新贷款继续放缓)
[篇章关系]:Temporal.Synchrony.
现有基于监督学习的论元关系分类方法,往往受限于训练样本数量不足的问题,无法充分发挥其在语义特征编码和感知层面的优势。前人[6-7]往往采用数据扩展的方法,弥补可观测样本总量的缺口。这类方法能够引入知识面较宽、特征多样性较高的外部数据,从而优化监督学习过程,且提升神经网络模型的健壮性。然而,外部数据不仅包含符合关系分类的高质量样本,也包含未经校验且质量偏低的噪声样本。使得数据扩展带来的性能优化存在一定的不确定性(高噪声数据反而误导监督学习)。
针对上述问题,本文尝试将对比学习方法引入论元关系分类模型的训练过程。对比学习可以在类别标记不可见的情况下,依据训练样本本身的属性,对其在高维语义表示空间上的分布特点进行学习和应用。具体而言,对比学习方法能够利用样本间语义属性的近似性度量,自动探寻相似于目标样本的实例以及具有较高差异的其他实例,从而有利于监督在学习过程中调整神经网络模型的内核(即参数矩阵),使之善于在高维语义表示空间中聚拢相似实例,驱离非相似实例。也因此,对比学习不仅有助于数据稀疏情况下的模型优化,也可与数据扩展相互协作,在保证新增正例的额外监督作用下,降低噪声的负面影响。基于这一优势,本文将简单对比学习(SimpleContrastiveLearning,SimCSE)[8]方法引入论元的语义编码和关系分类过程。现有研究[8]已证实,SimCSE能够优化文本的语义编码,提升正负例样本在语义表示空间上的划分。
例2[Arg1]:UAL Corp. is a good example
(译文: UAL公司就是一个很好的例子)
[Arg2]:becauseValued as a buy-out target, the airline stock was trading at nearly $280 a share
(译文:因为被估值公司作为收购目标,该航空公司的股票交易价格接近每股280美元)
[篇章关系]:Contingency.Cause.Reason
例3 [Arg1]:Valued as a buy-out target, the airline stock was trading at nearly $280 a share
(译文: 被估值公司作为收购目标,该航空公司的股票交易价格接近每股280美元)
[Arg2]:ThenWhen the deal ran into trouble, the stock tumbled
(译文:然后当交易陷入困境,该公司股价暴跌)
[篇章关系]: Temporal.Asynchronous.
尽管对比学习方法(如本文引入的SimCSE)具有上述优势,使其在论元语义编码的训练过程中,有着较高的应用价值。但是,观察发现对比学习在区分困惑负样本的过程中仍存在不足。然而,PDTB篇章关系分类数据集却蕴含着困惑度样本,使得对比学习的直接应用面临可预见的瓶颈。具体而言,PDTB语料中某些目标关系类的样本,与非目标关系类的样本存在较高的语用重叠现象(即用词的一致性较高),其构成了高困惑度样本群。如上述例2和例3所示(假设例2中的论元对属于目标关系类别,例3的论元对则是非目标关系类别)。观测发现,例2中Arg2的文本和例3的Arg1有部分语用重叠,使得两个论元对互为困惑样本。其“困惑”的根源是: ①样本之间存在语用重叠现象,两者在语义上较为相似; ②两个样本的关系类别是不同的。在SimCSE中,目标样本的对比实例来源于批次内的其他样本,这些对比样本中困惑样本的比例较低,使得模型在困惑样本上的区分度较低。
针对这一问题,本文进一步提出了面向PDTB中高困惑样本的对比学习(Contrastive Learning with Confused Samples,CL-CFS)优化方法。该方法将有效利用条件变分自编码器(Conditional Variational Auto Encoder,CVAE)[9]提升对比样本中高困惑样本的占比,其核心思想是借助CVAE生成困惑样本的变种,并将该变种作为目标样本在对比学习中的对比对象。在CL-CFS方法的训练中,不断拉开目标样本和高困惑样本在语义表示空间上的距离,从而提高模型对高困惑样本的辨识能力。在此基础上,本文采用三元组损失函数(Triplet loss)[10]作为对比学习的损失函数。该损失函数可通过间隔值的设置,过滤语义相似度差异较大的简单负样本,增加模型对困惑负样本的关注度。
本文采用篇章关系分析的公开语料集PDTB进行实验。实验结果表明,SimCSE方法获得优于基线模型的实验性能,该方法在Comparison、Expansion以及Temporal关系上在F1值上分别取得2.0%、1.45%、4.62%的性能提升。特别地,本文提出的CL-CFS相较于SimCSE方法获得了进一步的性能提升,其在Comparison、Contingency、Expansion以及Temporal关系上分别取得2.68%、3.77%、1.69%、8.15%的F1值性能提升。总体上,本文的主要贡献包含如下两个方面:
(1) 首次将对比学习机制引入面向论元关系分类的研究,并取得了显著的性能提升。
(2) 根据对比学习的工作原理和PDTB数据的固有性质,开展了适应性研究,研究侧重分析现有对比学习方法在高困惑样本中的缺陷。特别地,提出了CL-CFS方法,充分利用CVAE的变种生成优势,实现了对比学习对象的迁移。同时,结合对比学习的训练过程,提高模型在表征高困惑样本语义上的准确性。
本文组织结构如下: 第1节介绍隐式篇章关系识别的相关工作;第2节介绍基于高困惑样本对比的学习方法;第3节介绍本文所用的数据集、实验设置、实验结果,以及对实验结果的可解释分析;第4节总结全文并展望未来工作。
1 相关工作
现有隐式篇章关系识别的研究主要从两个方向出发: 对现有数据集进行扩展和构建较为复杂的分类模型学习论元的表征。其中模型构建分为基于语义特征的传统机器学习和基于神经网络的论元表示模型。
1.1 基于数据集扩充的隐式篇章关系识别
语料资源规模小的问题一直是隐式篇章关系识别的研究难点之一,该问题使得模型无法获得丰富的论元语义特征。研究者们尝试使用数据扩充的方法来缓解这个问题。
很多研究者按照一定的规则挖掘外部数据资源,尝试为模型提供更加丰富的语义特征。如Xu等[6]用连接词匹配外部数据并将扩充数据里的连接词去掉作为伪隐式语料,同时结合主动学习方法,从伪隐式语料中抽取出信息含量丰富的样本加入训练集,提升了模型的分类性能。朱珊珊等[7]以论元向量为线索,从外部数据资源中挖掘出“平行训练样本集”。该样本集在语义和关系上与原始语料是一致的。Varia等[11]通过构建外部数据集扩展语料,并引入词对卷积,捕获显式或隐式关系分类的论元之间的相互作用。
此外,一些研究者在数据扩充上提供了不一样的思路。基于中英双语语料中存在的“隐式/显式不匹配”现象,Wu等[12]从大量中英双语句子对齐的语料中提取出伪隐式样本,缓解了隐式篇章关系语料规模较小的问题。Lan等[13]将注意力神经网络模型集成到一个多任务学习框架中,利用大量未标记数据辅助隐式篇章关系识别。特别地,Dou等[14]在隐式篇章关系识别中使用自监督学习方法,该研究采用CVAE[9]进行数据增强,并联合注意力机制学习获得较好的性能提升。
1.2 基于论元表示学习的隐式篇章关系识别
由于外部语料扩展数据的方法面临数据获取困难和数据噪声较多的问题,因此,一些研究采用了新的研究思路,从有限的数据集中学习深层的论元语义表征,为模型提供可靠的分类线索。
1.2.1 基于传统机器学习获得论元表征
早期研究工作主要侧重于基于语义特征的传统机器学习模型。如Pitler等[15]以词对、动词类型等为分类特征,首次在PDTB的四大关系上取得了不错的性能。Lin等[16]将上下文、句法结构以及依存结构特征应用于隐式篇章关系识别中。
1.2.2 基于神经网络的论元表示模型
大量研究表明,神经网络能更好地挖掘句法和语义信息。如Zhang等[17]提出一种浅层卷积神经网络,缓解了隐式篇章关系识别中的过拟合问题。Liu等[18]基于卷积神经网络学习论元的表示,同时融合多任务学习思想,以隐式篇章关系分类为主任务,显式篇章关系和连接词分类任务为辅助任务来提升模型的性能。值得注意的是,Qin等[19]提出了一种基于特征模拟的新型连接词开采方案,建立一个对抗网络框架,得到近似扩展了连接词的论元对表示。Bai和Zhao[20]结合不同粒度下的语义表征提高了论元对的表示能力。Dai和Huang[21]构建了段落级神经网络模型,对篇章单元之间的相互依赖性以及篇章关系的连续性进行建模。Nguyen等[22]在Bai和Zhao[20]的基础上,采用多任务学习框架同时预测了关系和连接词,接着将篇章关系和连接词同时嵌入到相同的空间,并通过映射在两个预测任务中实现知识迁移。除此之外,Zhang等[23]提出了一种语义图卷积网络,首次使用图形结构来建模论元对的语义交互,在两个论元的表示上构建交互图,然后通过图卷积自动提取深度语义交互信息。Ruan等[24]使用双通道网络开发了一个传播性注意力学习模型。Li等[25]针对注意力学习模型存在权值分布过于平滑的问题,提出基于惩罚注意力权重方差的方法。Liu等[26]使用多视角余弦相似度匹配论元,并融合多头注意力和门控机制来深入理解论元。
2 基于高困惑样本的对比学习方法
针对现有模型对论元的语义表征不准确以及对PDTB语料中困惑样本区分能力较差的问题,本文提出CL-CFS方法,该方法首先构建正负例样本。其采用CVAE[9]生成高困惑样本作为目标实例的负样本,同时基于SimCSE构建正负例样本。接着,基于CL-CFS的对比损失,使得模型能够学习到正样本对之间的共同特征,并不断区分正负样本之间的差异。本文的研究结果表明,CL-CFS能够使得模型在正负例样本上获得更加准确且在不同类别样本上具有差异化的语义表示。
本节首先介绍模型的整体结构,然后对每个模块的设计思路展开详细描述,并给出整个模型的训练方式。
2.1 总体结构
本文提出基于高困惑样本对比学习的隐式篇章关系识别,图1是总体模型框架图。该模型主要分为以下四个部分: ①本文使用RoBERTa模型对输入的论元对(Arg1和Arg2)进行编码,获得论元对融合上下文的编码表示。②通过本文提出的CL-CFS方法提升模型表征论元语义的准确性,从而获得更加接近论元真实语义的编码表示。③将更新后的论元对表示输入基础篇章关系分类器,通过全连接层和softmax层进行关系分类。④在实验中,本文采用损失联合优化的训练方式,将对比学习的损失和篇章关系分类的损失相加,进行联合优化。

图1 总体模型框架图
2.2 编码层
对于隐式篇章关系识别语料中的一个论元对Arg1和Arg2,本文首先通过Byte-PairEncoding将其切分为子词序列,如式(1)、式(2)所示。
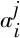
本文使用预训练模型RoBERTa对论元对进行编码,模型的输入X如式(3)所示。输入X经过RoBERTa模型编码后输出的隐状态向量H如式(4)所示。

2.3 增强高困惑样本的对比学习方法
对比学习的核心目标是,通过数据增广方法构建正负样本,同时训练一个能较为准确地分辨正负样本的模型。通过这个模型,使得正样本对在语义表示空间上的距离更加接近,而正负例样本之间的距离尽可能远。基于上述目标,CL-CFS首先构建正负例样本,样本构建的过程如图2所示。接着,利用对比学习的损失使得模型获得能够区分正负例样本的差异化语义表示。
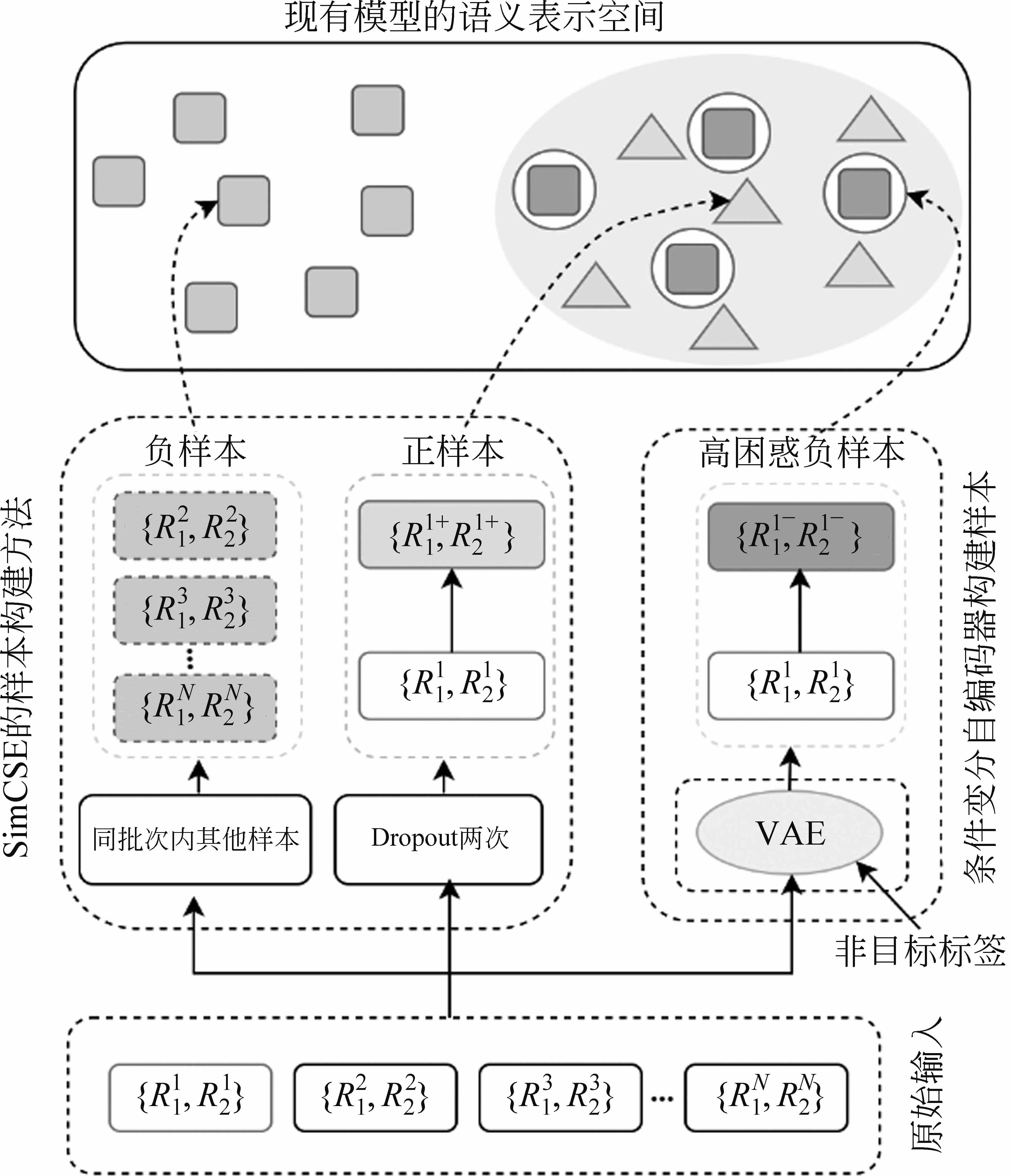
图2 SimCSE和CL-CFS的样本构建
2.3.1 SimCSE构建正负样本

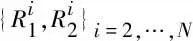
2.3.2 CVAE构建高困惑负样本
从图2可以看出,在现有模型的语义表示空间中,高困惑负样本和对应的正样本距离较近,使得模型难以分辨。SimCSE的负样本选自批次内的其他样本,这些样本具有较强的随机性,且高困惑负样本的比例较低。其中,部分样本与输入样本的标签相同,强行作为负样本使得模型难以收敛。此外,随机选取的负样本通常和原始样本在语义上差别很大,使得模型仅能分辨相似度差异很大的样本。从以上分析可得,基于SimCSE方法的模型在高困惑样本上的辨别能力较低。
因此,本文提出采用CVAE生成高困惑样本作为对比学习中目标样本的负样本。其中,高困惑样本有以下两个特性: ①与原始样本的标签不同; ②与原始样本语义相似。

CVAE采用变分推断的方式来构建样本。与VAE不同,CVAE不再是直接从高斯分布p(Z)=N(0,1)中直接采样,而是从p(Z|Y)中进行采样,Y是标签向量。同时,解码器需要重构的是(Y|R)而不是R。本文将CVAE的编码器表示为后验分布qφ(Z|R,Y),解码器由生成分布pθ(R|Z)来表示。其中,R是输入变量,Z是隐变量,φ和θ是学习参数。CVAE训练中的损失函数如式(7)所示。
其中,第一项是样本的重构损失,F是指均方误差。第二项使用的是KL散度,用来度量隐藏向量与结合样本标签的单位高斯分布的差异。进一步地,为了优化KL散度,CVAE采用参数重构的技巧,不再产生一个隐藏向量,而是生成两个向量,分别是均值和标准差向量。在训练过程中,CVAE通过标签向量的约束改变隐藏变量的均值,进而控制其采样的位置,最后控制生成高困惑负样本。
2.3.3 对比学习正负样本的差异
在对比学习的训练中,通过对比学习的损失函数,使得模型不断学习正负例样本之间的差异。SimCSE中使用的损失函数是噪声对比估计(Noise Contrastive Estimation,NCE)[27],如式(8)所示。

NCE的目标是缩小正样本对之间的距离,拉大正样本和负样本之间的距离。从式(8)可以看出,NCE试图通过温度系数来关注困难负例,但其依赖于参数值的设置。因此,NCE并未真正缓解SimCSE方法构建的负样本有大量噪声的问题。
因此,本文提出使用Triplet loss[10]作为对比学习训练中的损失函数,如式(9)~式(12)所示。
其中,δ是样本之间的cosine相似度,δ1是正样本对之间的相似度得分,δ2指正负样本之间相似度得分。γ代表真实的标签,这里采用无监督的学习方法,因此γ值为1。margin是超参数,其用来设置参与训练的正负样本之间的最大得分间隔。
分析式(9)可知,Triplet loss的计算过程是将正例对之间的相似度分数和增强的“高困惑的负样本”相似度分数进行相减,并将差值与margin(本文设置为0.2)进行对比,当分数差值大于margin值时,损失值为0,大于0且小于margin值时,损失为分数差值。换言之,使用Triplet loss可以将与正样本语义相似度得分差值很大的简单负样本从参与训练的样本中筛除。因此,Triplet loss缓解了NCE中出现的简单负样本过多导致的模型收敛过快的问题。进一步地,Triplet loss保留大量与正样本相似度差值较小的困惑负样本作为对比学习的训练数据,提高模型对高困惑负样本的辨识能力。
2.4 分类层


2.5 损失联合优化
如图1的模型框架图所示,本文采用损失联合优化的训练方式,将隐式篇章关系分类的损失和基于高困惑样本对比学习的损失进行联合优化。通过对比学习获得更准确的论元语义表征,在此基础上,共同优化模型的分类损失,使得模型更好地感知论元之间的关系类型。
2.5.1 隐式篇章关系识别的分类损失
基于提升隐式篇章关系的分类能力的目标,我们首先微调RoBERTa模型,获取输入论元对的向量表示,接着将论元对的表示输入全连接层和softmax层后得到输出的预测概率。然后通过计算预测概率与真实类别标签之间的交叉熵损失训练分类模型。交叉熵损失如式(14)所示。

2.5.2 基于高困惑样本对比学习的损失
为了缓解现有模型在高困惑样本上语义表示的偏差,本文提出CL-CFS,使用CVAE生成高困惑负样本,并结合SimCSE生成的正负例样本,一起应用到对比学习的训练过程中。
在模型训练中,CL-CFS采用损失联合优化的训练方式,同时优化基于高困惑样本对比学习中的损失Lt[如式(9)所示]和基于CVAE生成高困惑样本的损失LC[如式(7)所示]。具体地,在优化CVAE生成高困惑负样本以增强对比学习数据的迷惑性的同时,联合优化对比学习的训练损失,使得构建的正负样本发挥更多的作用。因此,CL-CFS的损失函数如式(15)所示。
其中,α,β∈(0,1]表示权重参数,其值越大表明任务在训练中的关注度越高。
2.5.3 损失函数联合优化
基于高困惑对比学习的隐式篇章关系识别的研究目标是通过CL-CFS方法,使得现有模型获得更准确的论元语义表示,并将优化后的论元表示输入分类器,进而感知论元之间的关系。
基于上述训练目标,本文采用损失联合优化的训练方式(如图1所示),共同优化隐式篇章关系分类的损失和基于困惑样本对比学习的损失。因此,整个模型的损失函数如式(16)所示。
其中,LCL-CFS是CL-CFS方法的训练损失,LClassification是隐式篇章关系分类的损失。在实验中,通过调节权重参数和将两者进行融合。
3 实验
本节介绍实验中的相关配置,包括使用的数据集、参数设置、实验设置以及对实验结果的可解释性分析。
3.1 实验数据
本文在PDTB[5]数据集上验证基于CL-CFS的方法在隐式篇章关系识别中的有效性,为了与前人工作保持一致,本文将Sec 02-20作为训练集,Sec 00-01作为开发集,Sec 21-22作为测试集,其中,所有样本的关系类别可能是Comparison(COM.),Contingency(CON.),Expansion(EXP.)和Temporal(TEM.)四种关系其中的一种,每种关系在语料中的分布情况如表1所示。

表1 PDTB四大类隐式篇章关系数据分布
从表1中可以看出,PDTB的数据规模较小,同时在各关系类别上的数据分布上不均衡。例如,Expansion关系的样本数量远远超过Temporal的样本数量。因此,仅仅使用多元关系分类器对所有关系的样本进行整体评测,会对数据量小的样本缺少公平性。基于此,本文进一步对每种关系单独训练一个二元分类器,对测试样本中的每个关系类型分别进行评估。本文针对每个关系类别的样本,随机抽样其他关系类别的样本作为负样本,从而构建二元分类器的训练数据。
3.2 实验设置
为了验证本文提出的基于高困惑样本的对比学习方法可以辅助改善隐式篇章关系识别,本文分为五个部分进行对比实验。
RoBERTa-base(基准系统)对输入论元对Arg1和Arg2进行分词,并将分词结果与特殊分类字符[CLS]和特殊分隔字符[SEP]拼接,共同输入RoBERTa预训练模型中,获得论元对的编码表示,然后将论元对的表示输入全连接层进行关系分类。
SimCSE将当前输入样本分两次输入RoBERTa模型中进行编码,获得原始论元对的向量表示以及增强的正样本表示。接着将当前输入论元对所在批次的其他样本作为负样本。然后,通过对比学习的损失函数NCE进行训练。
CL-CFS首先,基于CVAE生成高困惑负样本,然后采用SimCSE的样本构建方法分别获得正样本和批次内的负样本。进一步地,将构建的正样本、批次内负样本以及高困惑负样本共同作为对比学习的数据。同时,本节实验在对比学习中采用NCE作为训练损失函数。
Triplet loss的作用本节实验分别将SimCSE以及CL-CFS方法中的损失函数NCE替换为Triplet loss,并与使用NCE损失函数的实验结果进行对比。
CVAE中的条件设置本节实验为了验证使用CVAE生成高困惑负样本时,引入不同的标签向量作为CVAE的限制条件对实验结果的影响。该实验分别设置3组对比实验: ①无标签向量(即相当于使用VAE)。②目标关系类别,即与原始样本标签相同的标签向量。③非目标关系类别,即与原始样本标签不同的标签向量。
3.3 参数设置
本文使用RoBERTa-base模型来获得输入样本的向量表示。其中,设置RoBERTa的隐层向量维度d为768,单个论元的最大长度m设置为126。在模型的训练中,本文的关系分类任务使用交叉熵作为损失函数,并采用基于Adam的批梯度下降法优化模型参数。此外,将批处理大小N(Batch size)设置为8,学习率为5e-6。为了缓解过拟合的问题,模型在每层之后使用了dropout,随机丢弃的比率设置为0.2。在损失函数NCE损失函数Ls中,温度系数τ的值是0.05。在Triplet loss损失函数Lt中,margin值设置为0.2。在CL-CFS的训练过程中,本文联合优化基于CVAE生成高困惑样本的损失LC和引入高困惑样本对比学习中的损失Lt。 其中,Lt的损失权重α设置为8,LC的损失权重β设置为0.01。
3.4 实验结果与分析
3.4.1 总体实验结果与分析
根据第3.2节的实验设置,本节将多组对比实验在PDTB的四大关系类型中的每个二元分类任务上的表现进行验证。其中,本文采用F1值(F1-score)作为二元分类的评价指标,具体的分类性能结果如表2所示。

表2 对照实验的性能对比 (单位: %)
表2中的第一组对照实验(第3~4行)显示,与RoBERTa-base基准模型进行对比,隐式篇章关系识别联合SimCSE,并采用NCE作为损失函数的方法,在Comparison、Expansion以及Temporal关系上分别获得1.23%、0.53%、3.84%的F1值性能提升。但是,在Contingency关系相对基础模型在F1值上却下降了0.47%。实验结果说明,SimCSE在一定程度上改善了现有模型在论元的语义表征能力上的瓶颈。但是,结合SimCSE进行训练也会给基线模型带来一定的干扰。进一步地,使用Triplet loss替换NCE损失函数。从实验结果上看,Triplet loss在对比学习的训练中的表现是优于NCE损失函数的。相对于NCE,Triplet loss在Comparison、Contingency、Expansion以及Temporal关系上分别获得1.80%、1.72%、0.92%、1.14%的F1值性能提升。这侧面说明了Triplet loss可以通过间隔值margin筛选出更有效的正负样本对参与模型的训练,从而提升模型性能。
表2中的第二组对照实验(第5~6行),使用本文提出的CL-CFS方法。相较于SimCSE方法,CL-CFS在Comparison、Contingency、Expansion以及Temporal关系上分别获得1.59%、1.96%、1.53%、1.80%的F1值性能提升。实验结果说明,基于SimCSE的模型在部分具有迷惑性的样本上的语义表征能力存在不足。而CL-CFS使用CVAE为原始样本构建高困惑负样本,并加入对比学习的数据中,能够在一定程度上提升现有模型对于论元的语义表征能力。与第一组对照实验一致,本组实验使用Triplet loss替换NCE。相较于使用NCE,CL-CFS在F1值上获得了明显的性能提升。尤其是Temporal和Contingency,在F1值上相对于基准模型分别提升了7.13%和3.14%。再次验证了Triplet loss在对比学习中的有效性。
表2中的第三组对照实验(第7~9行),首先尝试不使用限定条件的CVAE生成样本,接着分别使用目标关系标签以及非目标关系标签向量作为CVAE的限定条件来生成高困惑负样本。从实验结果可以看出,相较于使用目标关系标签,采用非目标关系标签的CVAE在对比学习训练中的性能表现更好。说明通过限定CVAE中的条件可以在一定程度上控制其生成样本的类别。同时,与不使用标签向量作为限制条件相比,使用目标关系标签会为CL-CFS的训练带来负收益,尤其是时序关系,其性能指标相差3.16%。造成这个实验结果的原因是,在对比学习中,采用与目标关系类别相同的样本作为目标样本的负样本,通常会给模型带来较大的干扰。
同时,第三组对照进一步说明SimCSE效果较差的原因。SimCSE在负样本的选取中,使用目标样本所在批次内的其他样本作为负样本。而批次内的样本很可能存在与目标样本类别相同的样本,进而给对比学习的训练带来干扰。
3.4.2 与前人实验结果的对比与分析
本节将CL-CFS与前人的先进模型进行对比,其中涵盖了PDTB的四种主要关系的四元分类和单个二元分类任务的性能对比。这里采用宏平均F1值(Macro-averagedF1)和准确率(Accuracy)作为四元分类评价指标,具体如表3所示。

表3 CL-CFS与现有先进模型对比结果 (单位: %)
表3展示的实验结果表明,相较于数据扩充方法的Varia等[11]以及Dou等[14]进行对比,CL-CFS获得了具有可比性的性能。Varia等利用显式篇章关系语料进行数据扩充。具体地,Varia等提出联合学习隐式和显式关系的词对和N-gram, 并使用卷积神经网络来改善隐式篇章关系识别。从表3可以看出,Varia等在Temporal关系上的性能最具优势。然而,CL-CFS在Temporal上的F1值(表3中*号所示)比Varia等的方法高5.01%。这个对比结果表明,CL-CFS能够在不依赖外部语料的前提下,从现有语料中挖掘更深层的语义特征。与Dou等提出的方法进行比较,CL-CFS在Comparison,Expansion以及Temporal关系上性能表现更具有优势,分析可得,Dou等采用CVAE的方法对隐式篇章关系识别的任务进行改进。这样的方法增强了现有训练数据语义的丰富性,但是并没有针对性地解决现有模型在高困惑样本上辨别度较差的问题。特别地,在Expansion关系上,CL-CFS的性能低于Dou等。分析发现,Dou等的最终实验在使用CVAE的基础上,引入了显式篇章关系语料进行迁移学习,而CL-CFS方法并不依赖于任何外部数据。
Liu等[26]基于论元表示学习的研究方向,取得较优的整体性能。其利用上下文感知多视角融合的方法来提升模型的分类能力。CL-CFS与Liu等在F1值上进行相比,在Contingency和Expansion上分别提升2.99%和1.38%。在Comparison和Temporal关系上,尽管CL-CFS方法低于Liu等的模型性能,但也获得了非常具有可比性的性能。同时,Liu等的模型比CL-CFS的复杂程度更高。其采用多视角余弦相似度匹配论元,然后将论元对输入到具有门控单元的多头交互注意力机制中获得论元表示,并且对获得的论元表示使用了卷积操作。而本文通过数据增广的方法构建正负样本,并通过对比学习的损失函数进行训练。模型的复杂度较低,可迁移能力较强。
从表3可以看出,本文也在四元分类任务上与前人先进模型的性能进行对比,其中,本文提出的CL-CFS方法在四元分类任务上获得了目前最好的实验性能,其中,Macro-F1值相对SOTA模型提升1.52%,Acc值提升2.1%。
3.5 联合优化损失的权重设置
如2.4节所述,本文使用损失联合优化的训练方式进一步优化CL-CFS方法。一般地,损失联合优化时,每个损失的权重参数设置会对联合优化的结果造成影响。因此,本节描述实验中调节损失权重的细节。同时,本节进一步分析不同的权重参数设置对实验结果的影响情况。在2.5.2节中提到,本文联合优化基于高困惑样本对比学习中的损失Lt[如式(9)所示]和基于CVAE生成高困惑样本的损失LC[如式(7)所示]。在联合优化过程中,Lt的权重为α,LC的权重β。 本文将LC权重β设置为0.01,Lt的权重为α设置为8。其原因是,Lt和LC的取值范围在共同优化时应该处于相近的数量级。但是,Lt使用的Triplet loss的取值范围是0到间隔值(本文设置为0.2),其数量级远小于使用均方误差的LC。 因此,基于高困惑样本对比学习中的损失LC的权重β,其数量级应该远低于α。 同时,本文进一步对α设置了如下几个数值(分别是1,2,5,8,10)进行对照实验,具体实验结果如图3所示。

图3 调节损失Lt的权重α
图3展示了调节对比学习的损失Lt的权重α的过程,并反映了不同的权重α,为模型的性能带来的变化。其中,横坐标表示Lt的权重α,纵坐标表示模型的性能评估指标F1值(F1-score)。如图3所示,权重值α从1开始逐渐增加,模型在隐式篇章关系任务的四大关系上的性能不断提升,并在α为8时达到峰值。这说明在损失联合优化中,增大模型在对比学习中关注度可以有效改善模型对论元的语义表征不准确的问题。但是,当α增大为10时,模型的效果开始退化,说明过度关注Lt,可能导致模型的其他任务失衡。
3.6 显著性检验分析
为了检验CL-CFS在性能提升上的显著性,同时排除实验结果的偶然性。本节进行显著性检验分析[28]。根据对SimCSE和CL-CFS重复进行多次实验(每组实验5次)的实验结果,计算SimCSE和CL-CFS与基准模型RoBERTa在评价指标F1-score上的显著性得分p值,如表4所示。

表4 显著性得分(p值)
在显著性检验中,当p值小于阈值时(本文将阈值设置为0.05),说明两个模型的实验结果存在显著差异,即选取的模型性能提升显著。且p值越小,效果越优。从表4可以看出,SimCSE在PDTB的四大关系(Comparison、Contingency、Expansion以及Temporal)上计算的p值都小于0.05。同时,本文提出的CL-CFS在PDTB的四大关系数据集上计算的p值比SimCSE方法计算的p值更小。这说明CL-CFS方法相对于SimCSE方法在模型的性能提升上具有更加明显的优势。
4 结论
本文针对隐式篇章关系识别任务的研究瓶颈,提出了基于高困惑样本对比学习的隐式篇章关系识别。在引入SimCSE方法的基础上,本文提出使用CVAE构建高困惑负样本,缓解现有模型在与原始样本语义相似的负样本上区分能力较差的问题,同时提升了现有模型表征论元对语义的准确性。实验结果表明,本文提出的CL-CFS方法优于SimCSE。同时,对比目前主流的方法,CL-CFS在扩展关系上以及四元分类性能上优于目前的先进模型,在时序关系上也获得了与先进模型具有可比的性能。
但是,隐式篇章关系识别的性能离实际应用的标准还有较大的差距,其根本原因是现有语料资源有限,导致微调预训练模型的训练方法中无法获得丰富的语义特征。我们下一步的工作是利用prompt来激发目前应用的微调模型在预训练模型中“遗忘”掉的知识,分别尝试手动设计、自动学习的方法来构建prompt的输入模板。
