基于深度学习的岩体遥感智能解译模型研究
——以黑龙江省苇河镇、亚布力镇、绥阳镇地区为例
2023-01-17李雨柯赵院冬陈伟涛李显巨韩科胤温秋园
李雨柯,赵院冬,陈伟涛,李显巨,韩科胤,曹 会,温秋园,王 群
1.中国地质调查局 牡丹江自然资源综合调查中心,黑龙江 牡丹江 157000;
2.中国地质大学 计算机学院,湖北 武汉 430074
0 前言
随着遥感科技的发展,遥感影像光谱、空间、时间分辨率不断提高,应用领域和需求逐步延伸,对高效率、高精度提取影像信息的要求显得越来越迫切[1].但是受限于遥感数据容量大、难识别、非平稳等特点[2],加之地表复杂的地质条件,传统的人机交互方法花费时间长、解译精度差的问题开始凸显,因此,遥感大数据分析处理方法应运而生[3-4].目前这种分析方法主要有两类:一类是使用关系型数据库的联机分析统计技术方法;另一类是基于机器学习的智能化分析法.其中的深度学习方法在数据的提取和分析方面具有明显的优越性,是目前遥感智能化应用的研究热点[5].
深度学习是一种利用多个隐含层的神经网络来解决特征表达的学习方法,与监督学习、无监督学习、半监督学习、集成学习等机器学习方法相比,在智能提取遥感影像信息方面,精确度和智能化程度更高[6-10].
由于地表岩体地质成因背景复杂,物理化学性质具有各向异性和不连续性,对遥感智能化精确识别提出了更高要求.本研究利用深度学习方法在试验区开展岩体智能解译模型工作,结果显示,该方法效果良好,能够有效满足智能、快速、高精度解译需求.
1 研究区与多源数据
1.1 研究区概况
本研究依托遥感地质调查数据,重点选取苇河镇、亚布力镇和绥阳镇3个1∶50 000标准图幅(图1a、b)为试验区,分别位于黑龙江中东部地区,跨越松嫩地块和佳木斯-兴凯地块,总面积1 092 km2.图幅内岩性主要发育花岗岩、花岗闪长岩、流纹岩、安山岩、玄武岩、片岩,具有较好的代表性.
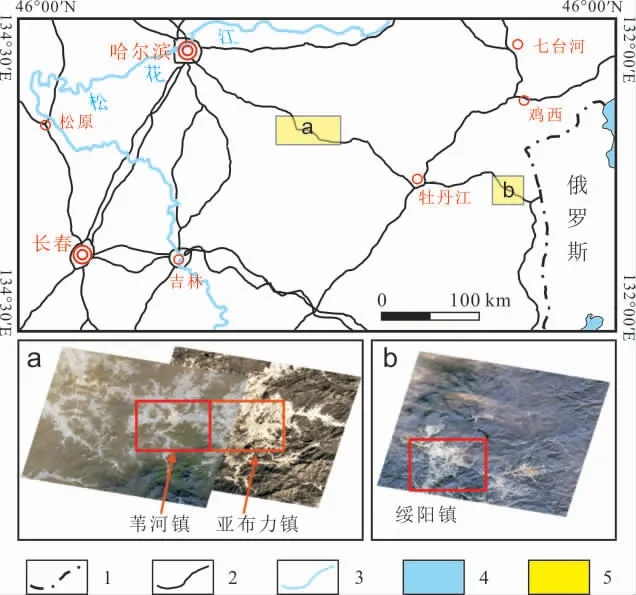
图1 研究区地理位置示意图Fig.1 Geographical sketch map of the study area
1.2 遥感数据及预处理
试验区选取资源三号立体测绘卫星影像为数据源,采用的数据清单见表1,主要包含3景后视、前视、多光谱和正视影像,数据能够完全覆盖研究区.所有数据均没有云、雪覆盖,呈像时间在10月、11月和3月,该时段植被裸露程度较高,能够提升遥感数据信息提取精度.

表1 试验区使用的资源3号数据Table 1 Data from ZY-3 satellite images used in test areas
采用资源三号前后视立体像对影像提取数字高程模型(DEM)数据,再进行伪洼地填充等后处理,得到精度为5 m的成果数据.基于DEM数据和有理多项式系数,对资源三号全色和多光谱影像进行正射校正.接着以全色影像为基准,采用二次多项式对多光谱影像进行几何纠正.其中,纠正误差控制在0.5个像元之内,重采样选用立方卷积方法.最后采用Gram-Schmidt光谱锐化(GS)方法融合上述处理后的全色和多光谱影像,从而得到2.1 m的融合多光谱影像.
1.3 岩体数据集构建
利用项目影像数据,考虑到岩体在遥感影像上连续性的空间展布特征,按500×500像元制作了安山岩(98幅)、花岗岩(265幅)、石英闪长岩(87幅)、中性火山岩(53幅)4类岩性场景数据集,共503幅,作为参考数据集(图2).

图2 典型遥感岩体场景Fig.2 Typical rock scenes by remote sensing
根据试验区岩体调查和解译数据,采用资源三号影像数据,分别构建了真彩色、假彩色和DEM场景数据,尺寸为500×500像元和210×210像元.根据16 bit的多光谱图像和DEM图像,得到8 bit的图像及其裁剪后的真彩色、假彩色和DEM图像(表2),包含有真实地理坐标和无真实地理坐标两个版本.

表2 试验区场景数据集Table 2 Scene datasets of test areas
2 研究方法
2.1 岩体预测学习模型确定
实验环境的构建及主要实现功能分为以下步骤:搭建软件运行平台的系统环境Ubuntu 16.04;遵循系统环境稳定性的原则,分别配置和安装对应版本的NVIDIA Cuda Version 10.0、cu DNN Version 10.0、Open CV Version 3.4.1;安装Anaconda3、Py Charm等Python语言编译环境,并配置Numpy等语言扩展程序库;创建数据集;编译代码并按照一定的窗口大小对数据影像进行随机裁剪;网络训练及数据集扩展,模型验证、测试、结果预测及精度评价.
将数据集按8∶2划分为训练和测试集.具体的技术路线如图3所示.首先分别提取人工设计特征、中层视觉特征和深度特征;然后输入SVM(支持向量机)、ANN(人工神经网络)和Softmax分类器,从而得到混淆矩阵;接着开展分类精度评价.人工设计特征包括GLCM(灰度共生矩阵)、HOG(方向梯度直方图)和CH(层次聚类);中层视觉特征包括BoVW(视觉词袋模型)、超级位置模型SPM(level=1)和SPM(level=2);深度特征包括超分辨率测试序列(VGG)、Xception和ResNet网络提取的特征.SVM算法使用默认参数,未调参;ANN算法包含2个隐含层和1个输出层,隐含层神经元为300,输出层神经元为4,Dropout设为0.2,具体如图4所示.人工设计特征和中层视觉特征均输入了SVM和ANN算法,深度特征输入了Softmax算法,从而得到5组分类结果.OA(总体精度)、Kappa和F-score评价各种模型的总体性能,采用统计检验探测不同模型之间是否具有统一意义上的显著性差异.
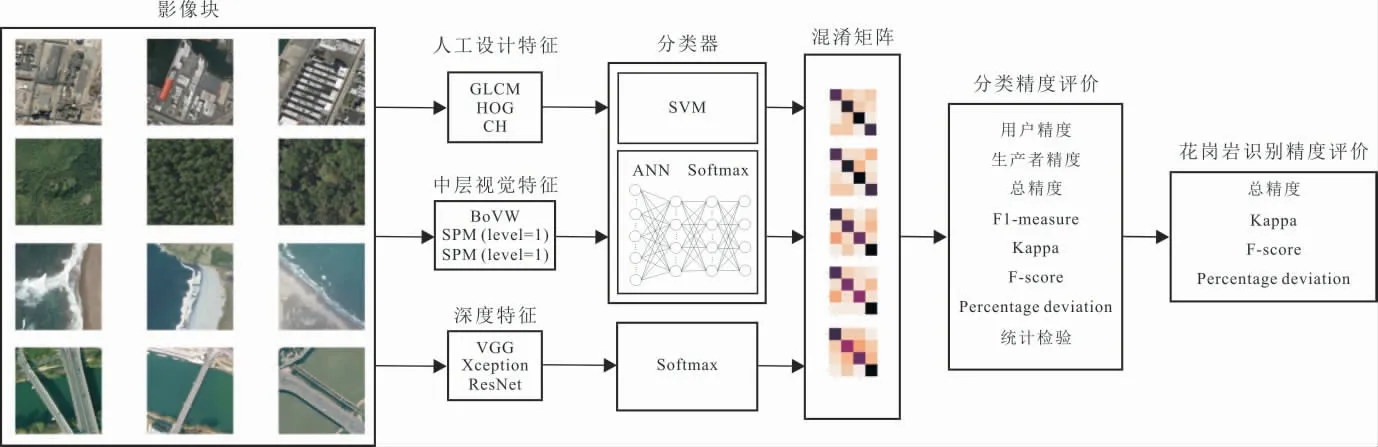
图3 岩体遥感智能解译路线Fig.3 Intelligent interpretation route of rock mass remote sensing images

图4 ANN算法结果图Fig.4 ANN algorithm result diagram
选取基于人工设计特征和中层视觉特征的最优模型,与基于深度特征的模型进行对比分析.模型总体性能见表3,不同模型总体性能的概率(PD)见表4.总体上,基于CH特征的模型明显优于深度学习模型;而深度学习模型略微优于基于中层视觉特征的模型.相比于VGG模型,基于CH特征的模型OA、Kappa和F-score分别提高了25.00%、72.47%和79.71%;相比于Xception模 型,分 别 提 高 了29.03%、67.39%和59.30%;相比于ResNet模型,分别提高了31.15%、62.93%和37.98%.而相比于基于BoVW特征的模型,VGG、Xception和ResNet模 型 的OA分 别 提 高 了10.34%、6.90%和5.17%,Kappa分别提高了31.26%、35.25%和38.95%,F-score的PD分 别 为-1.95%、10.61%和27.71%.
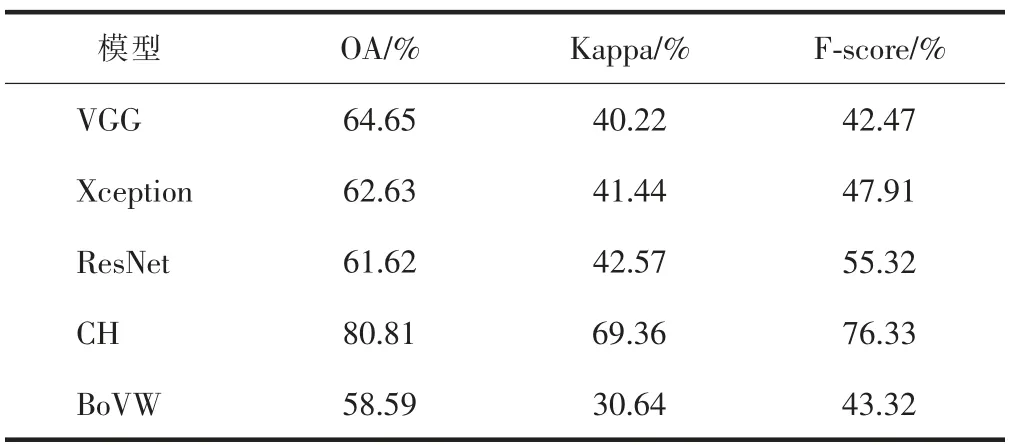
表3 不同模型的总体性能Table 3 Overall performance of different models
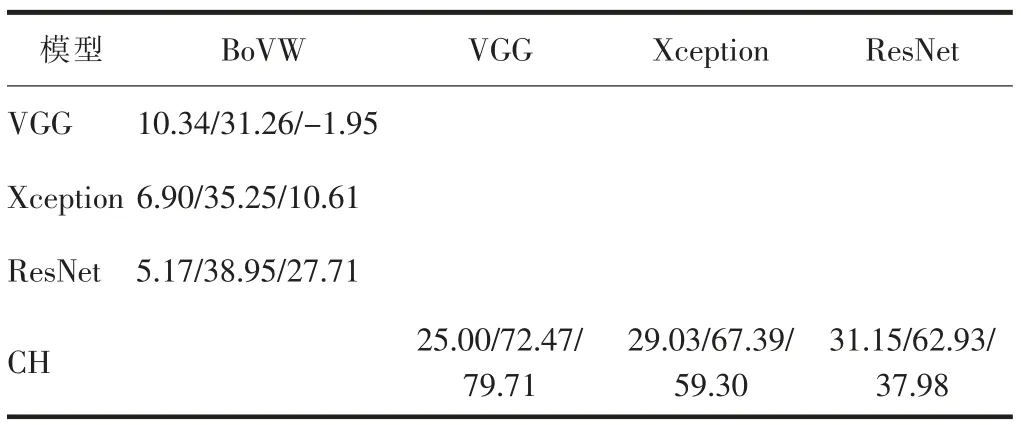
表4 不同模型总体性能的PD值Table 4 PD values of overall performance for different models
统计结果(表5)表明:1)VGG和ResNet模型显著优于基于BoVW特征的模型,即卡方和p值分别为9.60和0.02,12.96和0.00;2)Xception模型和基于BoVW特征的模型之间没有统计意义上显著性的差异,卡方和p值分别为0.52和0.92;3)基于CH特征的模型显著优于VGG和ResNet模型,卡方分别为17.87和12.95,p值均为0.00;4)基于CH特征的模型与Xception模型之间没有显著差异,卡方和p值分别为3.67和0.30.
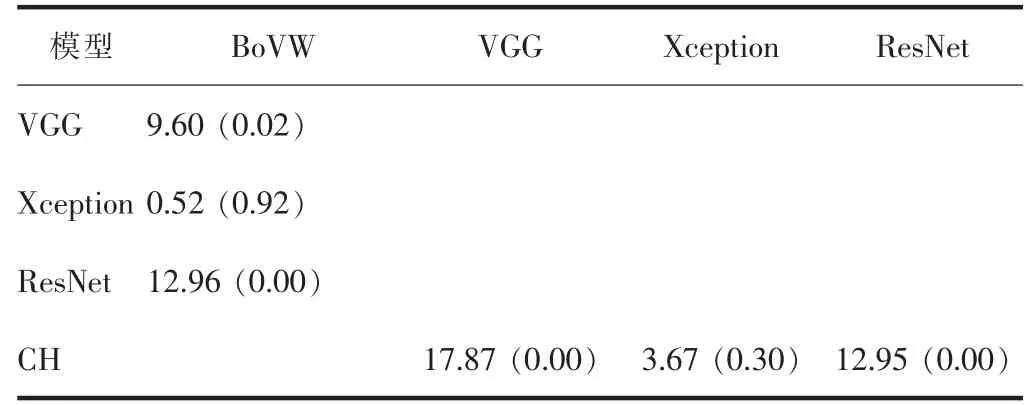
表5 不同模型统计检验结果Table 5 Statistical test results of different models
尽管基于CH特征的模型明显优于深度学习模型,但大多数情况下深度学习模型的特征提取能力更强.可以基于分类实验的结果优选特征提取能力强的深度学习预训练模型,用于后续智能解译模型构建.
2.2 模型构建
鉴于岩体类型具有地形异质性的特点,以及精细的土地覆盖分类数据对岩体分类和边界的指示意义,拟构建基于多源多模态数据和多流CNN(卷积神经网络)的岩体分类模型(图5).首先使用多光谱和地形数据及精细的土地覆盖分类数据,提取像元邻域特征;然后构建多流CNN分支,分别提取深度特征并分类;最后采用自适应方法融合多流CNN分类结果,从而得到岩体分类结果.各个分支采用深度卷积神经网络模型和参数迁移策略构建;精细的土地覆盖分类则采用单独的模型得到.
2.2.1 基于大尺度邻域和深度卷积神经网络的岩体提取模型
使用遥感地质解译数据和遥感影像构建本次实验的训练样本数据集,样本都是48×48的邻域影像数据;在模型的构建阶段,利用迁移学习,结合ImageNet数据和样本池中的数据对VGG16模型进行预训练和微调;最后使用训练好的模型对全图的像元进行预测,依据遥感地质解译数据对预测的标签进行评估.算法流程如图6.将该模型直接迁移给图5中第一个分支,另两个分支直接迁移VGG16的结构.

图5 基于多源多模态数据和多流CNN的岩土体分类模型流程图Fig.5 Flowchart of rock-soil mass classification model based on multisource,multimodal data and multistream CNN

图6 基于邻域数据的深度学习岩体分类算法流程图Fig.6 Flowchart of deep learning rock mass classification algorithm based on neighborhood data
使用遥感地质解译数据在每一类目标区域中随机选择样本点,将样本点作为图片的中心点,在原始影像数据上裁剪48×48的邻域数据,保存为jpg格式的图片,同一类别的数据保存在一个文件夹中.由于部分点在图片的边界,裁剪过程中会发生越界,需要进行剔除,所以实际的数据相对于计划样本数有所减少.
本方法使用5个指标进行性能评估:混淆矩阵、总体分类精度(Overall Accuracy)、精确率(Precision)、召回率(Recall)、Kappa系数和F-score.
ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库,大约包含1500万张照片,2.2万个类别,每张图片都是经过严格的人工筛选和标记,利用VGG16通过学习ImageNet数据集提取图像特征的方法,获得预训练的模型.
真彩色训练集是进行独立训练的,使用图像增强等方法增加训练的数据,最终保存验证集精度最好的模型.实验的硬件平台为RTX 2080 Ti GPU,实验框架为Python=3.6,kares=2.3.1和tensorflow=1.13.1.
利用训练好的模型,对影像数据的每一个像元进行预测,得到一个和原始影像的宽和高相同的图片,作为全图的预测标签图.在此过程中,需要把每一个像元作为48×48邻域的中心进行预测.该邻域的标签,即为该像元的标签值.为了使得最终输出标签的数目与原始影像的像元数目一致,需要对影像的上下左右各填充24个像元,填充值设置为0.
2.2.2 精细土地覆盖分类模型
精细的土地覆盖分类数据采用基于波段组合和多模态数据的多流CNN融合模型获取(图7).首先基于多光谱数据的真彩色和假彩色影像及DTM等多波段组合和多模态数据,提取像元邻域特征;然后构建多流CNN分支,分别提取深度特征;最后融合多流深度特征,从而实现基于波段组合和多模态数据的多流CNN融合模型.

图7 基于波段组合和多模态数据的多流CNN融合模型Fig.7 Multistream CNN fusion model based on band combination and multimodal data
3 结果与评价
3.1 精细土地覆盖分类结果
将研究区土地覆盖类型划分为14个二级类,并构建相应的训练、验证和测试集.
模型训练和构建过程中的主要超参数为:epoch,1000;step_per_epoch,568;多光谱输入尺寸,15×15像元邻域;DEM输入尺寸,15×15像元邻域;batch size,50.
测试集精度评价结果为:总精度,88.30%;Kappa系数,86.33%;F1分数(精度和召回率的调和平均数),87.71%.
3.2 岩体分类结果
基于真彩色影像数据,最终得到岩体分类结果预测图.与实际岩体分类结果对比(图8)显示,预测结果图的整体目测效果较好,整体的区域预测分布正确,但是部分类别中存在“椒盐现象”.
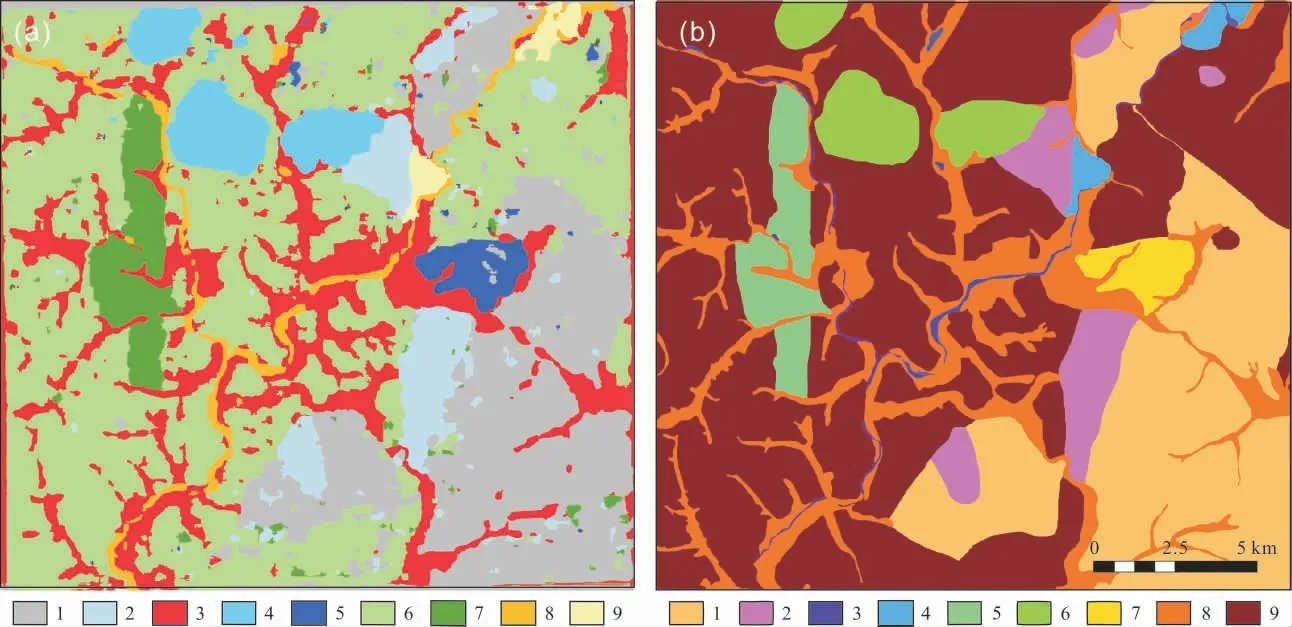
图8 岩体分类结果与实际岩性对比Fig.8 Comparison of rock mass classification result and actual lithology
利用Recall、Precision、F1、Kappa和Acc作为精度评价的指标(表6),总精度达到84.4%.

表6 岩体模型精度评价结果Table 6 Accuracy evaluation result of rock mass model
4 结论
(1)深度学习模型总体性能优于基于中层视觉特征的模型,信息提取能力优于基于人工设计特征的模型,可作为岩体预测学习模型.
(2)由于岩体具有地形异质性特点,以及土地覆盖分类数据对岩体类型和边界的指示意义,采用深度卷积神经网络模型和参数迁移策略构建多流CNN的岩体分类模型,并结合精细的土地覆盖分类模型,从而得到岩体分类数据,结果显示总精度达到84.4%,能够为地质工作者提供辅助决策依据.
利用深度学习方法开展高分辨率遥感地质智能解译研究意义重大[11-14].其中的CNN模型被广泛应用在图像识别等领域,取得较好效果[10-12].但是,该模型也存在易于过拟合需要大量样本提高模型泛化能力的缺陷[15].本研究文尝试使用迁移学习策略对样本数量进行扩容,较好地解决了小样本问题,提高了模型的解译精度.今后将继续研究深度学习中不同模型的结合,并开展不同研究区、不同季节的测试研究,从而提升模型的泛化能力.
