基于YOLOv5的钢材数量识别方法
2023-01-17刘洪宁李容露
刘洪宁,李容露
(大连民族大学机电工程学院,辽宁 大连 116600)
在工业建筑过程中,不可避免会消耗大量的工业建材。传统工业建材计数工作一直由人工完成,手工计数方法易受到统计人员的注意力、反应速度、疲劳等因素的影响,无法满足现代化钢铁企业快速生产需求。近年来,计算机视觉技术蓬勃发展,在图像处理,目标检测领域取得了丰硕成果。卷积神经网络CNN 可以提取到图片数据集更好层次的特征信息,使得视觉处理模型获得更高的准确率,现已被广泛应用于各类工业任务中。在钢材计数这一图像处理任务中,传统图像处理方法首先手动提取钢材特征,再进行比对计数,这就需要根据经验手动设置参数。钢材图像数据具有数据密集、成像背景噪声复杂、目标尺寸较小等多种特性。传统方法不具备较好的泛化能力,难以获得稳定准确的检测效果。基于卷积网络的深度学习模型具有更好的准确性与鲁棒性。采用深度学习的方法训练目标检测模型应用于钢材计数任务中,不但快速准确地完成对工业建材的清点工作,更能将建筑工人从枯燥繁重工作中解脱出来。本文拟采用深度学习的方法,以YOLOv5 为基础模型,构建卷积神经网络对钢材图像进行目标检测,完成钢筋计数任务。
1 基于YOLOv5 的钢材数量识别算法
1.1 目标检测模型搭建
YOLO(You Only Look Once)是由Joseph Redmon 编写的one-stage 目标检测算法,现已更新到第五代版本即YOLOv5。在YOLO 模型出来之前,先前的目标检测系统大多使用分类器对测试图像的不同切片进行评估,即滑动窗口这一十分经典的模型。DPM(Deformable Part Model)等一些早期目标检测算法模型都采用了滑动窗口的方式,并在这些窗口区域上运行分类器。R-CNN(Region-based Convolutional Neural Networks)等采用候选区方法配合CNN 模型进行预测,最后得到1 个特征向量进行分类。无论是滑动窗口还是候选区模型,其本质上是一种图像分割算法。YOLO之前的系统一直被速度慢、计算量大,优化困难等问题困扰。YOLO 算法与传统两阶段的目标检测算法不同,其单阶段的实现端到端的检测任务。YOLO 将对象检测重新定义为一个回归问题,及端到端的直接预测,而不再采取传统的图像分割累加预测的形式。YOLO 的推理速度是传统R-CNN 模型的推理速度的百倍以上。YOLOv5 是目前YOLO 系列最新的实时目标检测算法,YOLOv5 检测精度的提升使得网络在目标检测方面更加具有实用意义。YOLO 算法将单个卷积神经网络CNN 应用于整个图像,将图像分成多个网格,选取每个网格作为预测中心,计算落在该网格内的目标的信息,每个网格经过运算直接输出物体的位置信息和置信度。并且以经验预设的瞄框为基本预测边框,对每个网格中心计算可能有物体的图片区域进行识别。本文算法以YOLOv5 为基础搭建卷积神经网络,网络结构如图1所示。
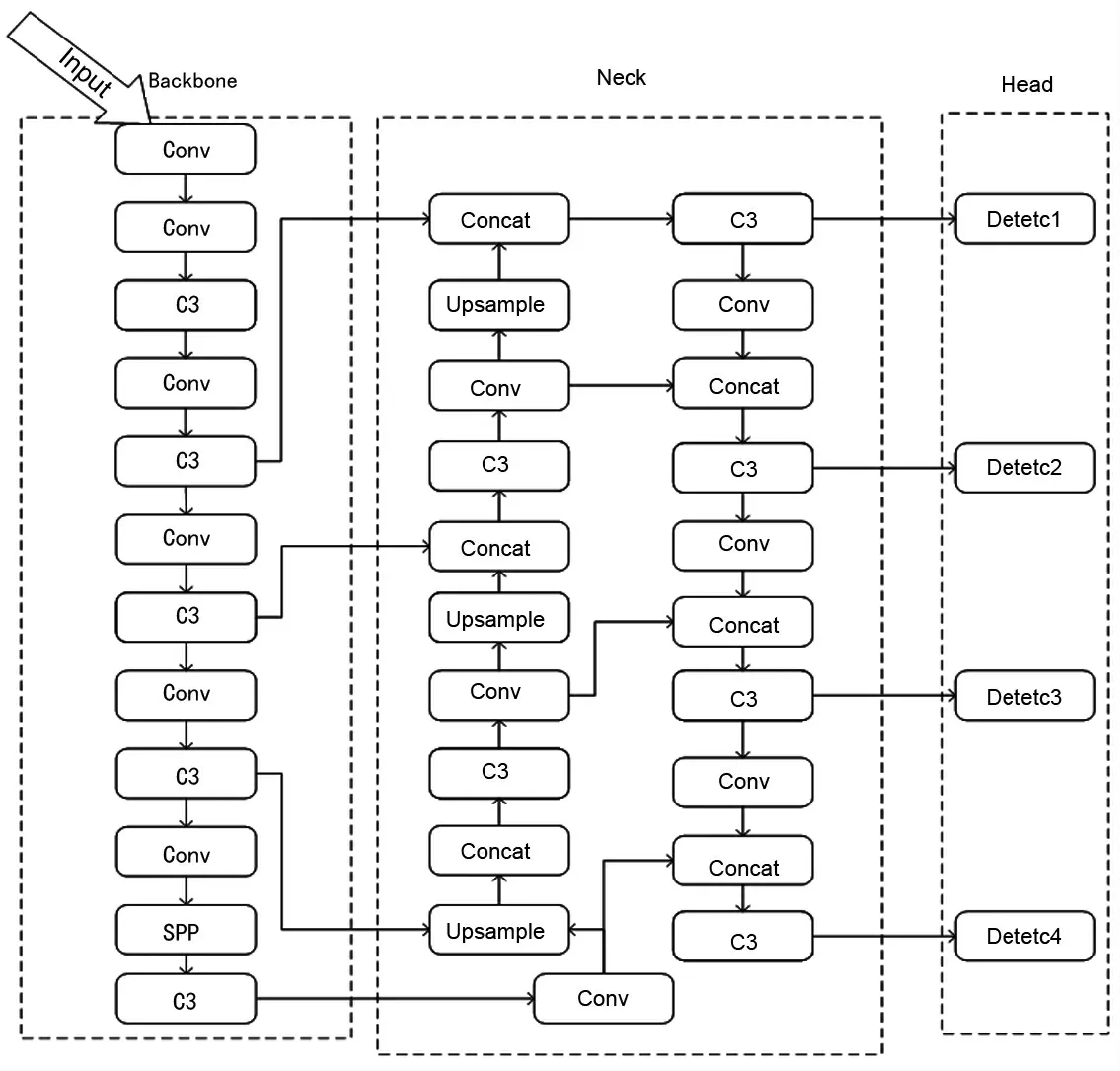
图1 YOLO 网络结构模型
本文针对数据集特性搭建卷积神经网络,分别构建输入端、主干网络Backbone、特征融合网络Neck 和预测端Detection。在输入端对数据进行多项预处理工作。在主干网络部分,层叠搭建瓶颈层C3(CSP Bottleneck with 3 convolutions)和卷积层Conv,C3 是简化版本的Bottleneck 瓶颈层模块,在主干网络的末尾使用SPP 特征池化模块对特征进行解码处理,送入neck网络进行进一步的特征融合。SPP 模块融合局部特征和全局特征融合,丰富特征图的表达,有利于检测精度的提升。在Neck 特征融合网络部分,构建Upsample 特征上采样模块与Concat 特征图融合模块实现特征的多尺度融合,保证钢材数据的特征被网络有效接收。每个模块内涉及到的基本卷积操作都使用了Conv+BatchNormalization+激活函数的标准形式。
1.2 数据集预处理
本文训练数据集为公开发布的钢筋计数图像。仔细分析钢筋数据图像特点,可以看出钢筋图像目标十分密集,单张图片往往存在30~50 左右的钢筋目标。其次,图像中目标数据和背景相似度较高,存在大量的噪声干扰情况。此外,成像背景为工地建筑场地,背景较为复杂。
数据集预处理。为了使得钢材数据集目标特征有效表达,使得模型获得较好的检测精度。首先对钢材数据图像进行mosaic 增强处理,mosaic 数据增强方法通过模糊滤波使得检测物体暴露,模型更容易区分目标和背景的关系,减少噪声干扰。为了避免数据特征不足导致模型精度低的情况发生,可使用坐标旋转,图像拼接等数据扩充方法对数据集进行增强,提高钢材数据集的分布状态质量及目标检测模型的泛化性能。钢材数据集标注使用csv 格式,将标签文件标准化为yolo 格式,将Annotations 文件夹内的xml 文件标注钢筋。
经过数据预处理后,划分训练集与测试机比例8∶2,采用矩形训练的方式送入模型。
K-means 聚类先验框。由于钢材计数数据集的特殊性,为了获得更好的模型精度,使用K-means 聚类得到最适合数据集的锚框。K-means 本质是基于距离的数据划分算法,其认为2 个目标的距离越近,相似度越高,均值和方差大的维度将对数据的聚类产生决定性影响。K-means 算法首先选k 个样本作为初始聚类中心即a=a1,a2...ak,再针对数据集中的每个样本xi,计算其到聚类中心距离,将其分到距离最小的中心簇中并重新计算该簇中的所有样本的聚类中心重复运算直至终止条件。在YOLO 模型中K-means 使用的聚类距离公式如下

由于钢材数据集的特殊性,对数据集进行3 种尺度的划分,即期望模型使用3 种小尺度的锚框拟合目标,每类物体3 个预测框,聚类结果为(18,18),(21,21),(25,24),(28,29),(33,28),(33,34),(38,38),(45,44),(54,53)。
2 实验结果分析
2.1 实验环境
实验环境为服务器Ubuntu 20.04,6 张NVIDIA GeForce GTX 1080 Ti(11G)深度学习环境为Pytorch 1.9.1+CUDA 11.1+cudnn 8.0.5。训练batch_size=12,学习率设置为0.02,共训练200 epoch。
2.2 实验方法
本文以交并比(Intersection over Union)、准确率(Precision)、召回率(Recall)、平均精度均值mAP(mean Average Precision)、完全参数量、GFlops(Giga Floating-point Operations Per Second)计算量和模型体积作为评估模型性能的指标,以此客观评价本文算法的性能。mAP 以准确率和召回率为基础计算多个类别AP 的平均值,mAP 值越大则认为算法精度越好。完全参数量为模型训练时需要计算的全部参数,GFlops 代表每秒10 亿次的浮点运算数。GFlops 计算量是衡量算法计算复杂度的重要指标。
2.3 实验结果分析
实验结果由表1可知,训练100 个epoch 作为基础,并且以相同环境下测试数据集作为算法返回结果。

表1 本文模型测试性能表
通过实验结果可知,本文算法平均检测精度可达98.7%以上,模型较好的完成了钢材计数任务。但是由于数据图像的尺寸,数量及规模较小,图像数据非均匀分布等原因。模型训练曲线出现了一些震荡收敛情况。后续可改进数据集质量避免这一情况发生。本文算法的Loss 曲线,Precision-Recall 曲线及mAP 曲线如图2所示。
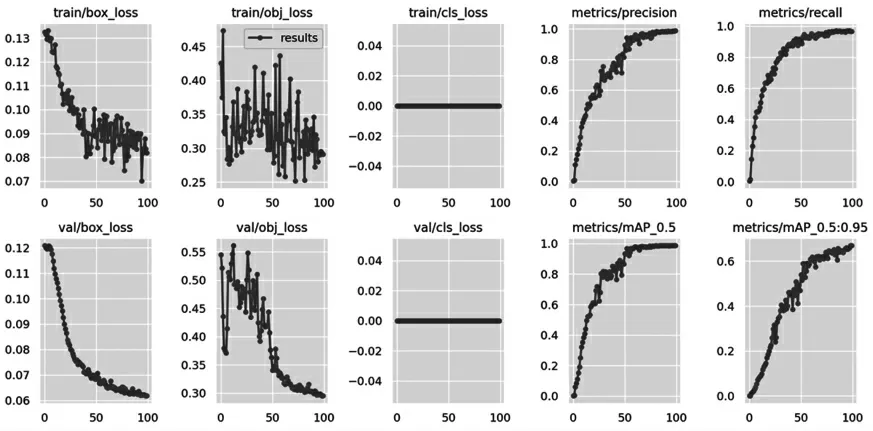
图2 模型Loss,Precision-Recall 以及mAP 曲线
本文算法模型训练完成,得到包含最优网络结构参数的模型权重文件大小仅为14.4 M。终端设备可通过迁移学习方法部署模型,将会大大的减少内存资源的占用。对训练完成的算法模型进行测试,测试结果如图3所示。

图3 模型检测结果
3 结束语
本文提出了一种基于YOLOv5 的钢材图像计数算法。实验结果表明,本文算法平均检测精度可达98.7%以上,模型准确率可98.9%,该模型较好完成了钢材计数检测任务,且具有一定鲁棒性。后续模型研究可以考虑扩充数据集,提高数据集质量获得更好的训练效果。或对网络结构优化,引入注意力机制或者多尺度融合机制提升模型拟合能力。为了更好部署于边缘终端设备,可考虑搭建轻量化卷积网络训练模型,方便部署,加快推理速度。
