一种基于梯度提升树算法的DGA 域名检测方法*
2023-01-16冯中华刘晓毅张文博
冯中华,黄 河,周 佳,刘晓毅,张文博
(1.中国电子科技集团公司第三十研究所,四川 成都 610041;2.中国人民解放军61660 部队,北京 100089)
0 引言
近年来,勒索病毒、挖矿软件、僵尸网络等恶意软件在互联网泛滥成灾[1],已严重威胁到互联网的安全。这类恶意软件的主要特点是被感染主机需接收命令和控制(Command and Control server,C&C)服务器的控制指令,被感染主机与C&C 服务器之间主要通过域名进行传输控制协议/网际协议(Transmission Control Protocol/Internet Protocol,TCP/IP)通信。因此,恶意域名检测成为检测和防御这类恶意软件的重要方式。为了规避安全防护装备的检测和封堵,实现对被感染主机的长期持续控制,C&C 服务器与被感染主机之间的域名采用域名生成算法(Domain Generation Algorithm,DGA)生成[2],实现域名和互联网协议(Internet Protocol,IP)地址快速动态变换。传统恶意域名检测主要采用威胁情报库方式,检测域名是否在恶意域名库中。但随着DGA 域名技术的不断发展和改进,形成了大量的DGA 域名并快速变换[3],因此威胁情报库异常庞大,从而导致检测效率低下,威胁情报库的更新周期也无法跟上DGA 域名的变换速度。DGA 域名的使用使得攻击容易、防守困难[4],给传统的基于威胁情报库的恶意域名检测方式带来巨大挑战。
机器学习技术成为应对DGA 域名的主要途径,常见的有基于长短期记忆网络(Long Short-Term Memory networks,LSTM)和卷积神经网络(Convolutional Neural Network,CNN)等机器学习算法检测DGA 域名[5]。相关的研究有:文献[6]对朴素贝叶斯算法、XGBoost、多层感知机用于DGA域名检测的效果进行了对比;文献[7]通过分析DGA 域名与正常域名之间字符分布的差异,对IP产生的域名进行批量分类;文献[8]通过LSTM 算法分析DGA 域名与正常域名之间的差异,判定每个域名是否为DGA 域名;文献[9]考虑到DGA 域名的请求过程中会产生大量NXDomain,因此对NXDomain 进行分类,有效识别DGA 域名。
梯度提升树(Gradient Boosting Decision Tree,GBDT)算法作为机器学习领域中的一个重要算法,是一种基于决策树的集成算法,通过构造多个弱学习器为基学习器,结果累加作为输出,在数据分析和预测中表现了突出的效果。XGBoost[10]是一个优化的分布式梯度提升库,在梯度提升框架下实现机器学习算法,以高效、灵活、便携的特点,在业界应用广泛,非常适合解决DGA 域名检测这种分类问题。
1 研究思路
梯度提升树算法属于集成算法中boosting 类的一种算法,适用于解决现实中的分类和回归问题。XGBoost 是优秀的梯度提升树算法的工程实现,在业界应用非常广泛。本文采用XGBoost 框架实现的梯度提升树算法,研究利用梯度提升树算法用于检测DGA 域名的实现方法,总体思路如图1 所示。
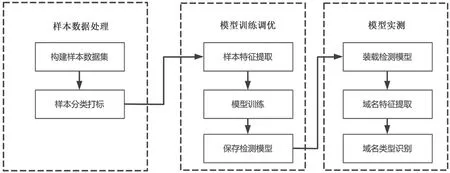
图1 基于梯度提升树的DGA 域名检测方法研究思路
(1)样本数据构建。梯度提升树算法是一种有监督机器学习算法,需要充足的样本数据支撑,收集的样本数据包括正常域名样本数据和DGA 域名样本数据,并根据样本数据类型标注样本分类 标识。
(2)模型训练调优。模型训练调优包括样本向量化处理、样本特征提取、模型训练和模型参数调优等内容。由于域名是字符串,而算法运算处理对象是数值,因此要先进行向量化处理,提取样本特征数据,将文本型样本转换为算法可处理的数值型样本,再基于数值样本进行模型训练调优,生成生产可用的DGA 域名检测模型。
(3)模型实测。利用实际生产环境中提取到的域名对DGA 域名检测模型进行验证,检验训练出的DGA 检测模型在实际网络中的效果。本文主要通过收集互联网中非样本数据中的DGA 域名,提交检测模型进行判定,并根据判定结果验证检测模型的检测准确率。
2 构建域名样本数据
2.1 DGA 域名分析
DGA 域名有很多家族,根据域名生成算法可以分为基于算术、基于哈希、基于词典和基于排列组合4 类。根据360 网络安全实验室(360 Netlab)公开的DGA 域名数据统计分析,当前互联网中最活跃的60 个DGA 域名家族的客户端IP 和DNS 请求统计数据如图2 和图3 所示。

图2 DGA 家族客户端IP 数量统计

图3 DGA 家族DNS 请求数量统计
由于不同家族采用的DGA 算法不同,其域名呈现的特征也不同,根据360 网络安全实验室的数据统计,互联网常见的DGA 家族域名特征如表1 所示。
2.2 样本数据组成
对于有监督机器算法而言,样本集构建非常关键。为训练出有效的检测模型,域名样本数据要足够丰富和有代表性,并且有利于样本打标处理,才能让检测模型学习到有效的特征数据,提高检测的准确率。本文研究的目的主要是识别恶意域名,不区分恶意域名的家族,样本数据集包括白样本和黑样本,白样本是信誉度高的合法域名,黑样本是已知的用于网络攻击的恶意域名。域名样本数据集构成如图4 所示。
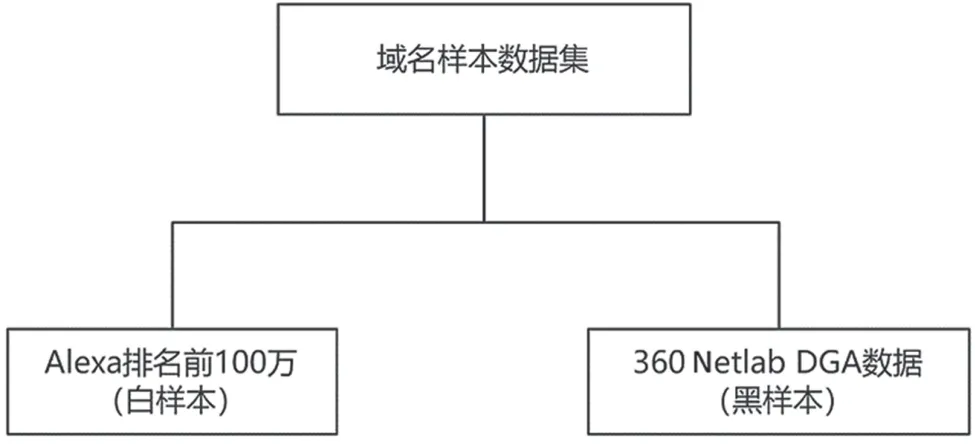
图4 域名样本数据集构成
白名单数据本文采用Alexa 的域名数据。Alexa为全球知名的专门从事世界网站排名的公司,其数据集包含了多达几十亿网址的排名,域名数据有一定的权威性,本文选择其排名前100 万的域名作为白名单样本数据,如图5 所示。

图5 Alexa 网站排名数据示例
黑名单数据采用360 Netlab 公开的DGA 域名数据,截至2022 年9 月已收集了190 多个DGA域名家族总计一百多万的域名数据。360 Netlab 的DGA 域名数据集包含DGA 家族、域名和验证起始时间等信息,格式如图6 所示。

图6 360 Netlab DGA 域名数据示例
2.3 样本标签处理
在进行检测模型训练前,需要对数据进行预处理,对每条域名进行分类标识。本文主要讨论DGA域名的检测方法,不对DGA 域名家族进行分类,其中,域名分为合法域名(用0 标识)和恶意域名(用1 标识)两类,预处理时白样本分类标识全部设为0,黑样本分类标识全部设为1。
3 检测模型训练与验证
检测模型训练与验证针对前面准备的域名样本数据集,通过域名向量化处理、特征提取、模型训练、模型验证、参数调优等一系列工作,最后输出可用的DGA 域名检测模型,流程如图7 所示。

图7 检测模型训练流程
3.1 域名向量化处理
域名向量化处理是指通过一定的方法将文本形式的域名转换为梯度提升树算法可处理的数值矩阵,向量化转换的结果将直接影响检测模型的效果。目前,向量化转换的方法有很多,包括域名长度、元音字母比例、唯一字符比例、平均Jarccard系数等。DGA 最初产生的域名以随机字符串为主,因此通过长度统计、字符比例等统计特征来识别效果明显,但近几年DGA 算法生成的域名从字符分布上与正常域名拟合度非常高,统计特征与正常域名区分度不高。考虑到所有域名都是字符串,本文采用词袋模型对样本库进行建模,利用CountVectorizer 将域名样本数据集进行N-Gram 转换处理,实现域名样本向量化。转换关键参数设置如表2 所示。

表2 域名N-Gram 转换关键参数设置
域名样本N-Gram 转换处理核心代码如图8 所示。

图8 域名向量化转换核心处理代码
CountVectorizer 在对域名样本进行N-Gram 处理时,将统计词在所有样本中出现的词频,并根据词频排序,选择频度最高的前N个词作关键词,形成词汇表和词频稀疏矩阵,作为后续梯度提升树算法模型训练的输入数据。域名向量化处理后提取的部分特征名称和特征值如图9 和图10 所示。

图9 从域名样本集提取的词汇表示例

图10 向量化稀疏矩阵数据示例
3.2 检测模型训练
模型训练的主要工作基于前面N-Gram 模型转换生成的向量化域名样本库,对梯度提升树算法模型进行反复训练调优,得到DGA 域名检测模型。
模型训练阶段需先将向量化样本数据通过调用train_test_split 函数拆分为训练集和验证集,然后基于训练集训练算法模型,再通过验证集评估模型 效果。
在模型训练开始阶段,采用XGBoost 分类器的默认算法参数值进行DGA 域名检测模型训练,并利用验证集对检测模型进行验证。
默认算法参数训练得到的检测模型验证结果和特征统计情况如图11 和图12 所示。

图11 默认参数模型训练验证结果统计
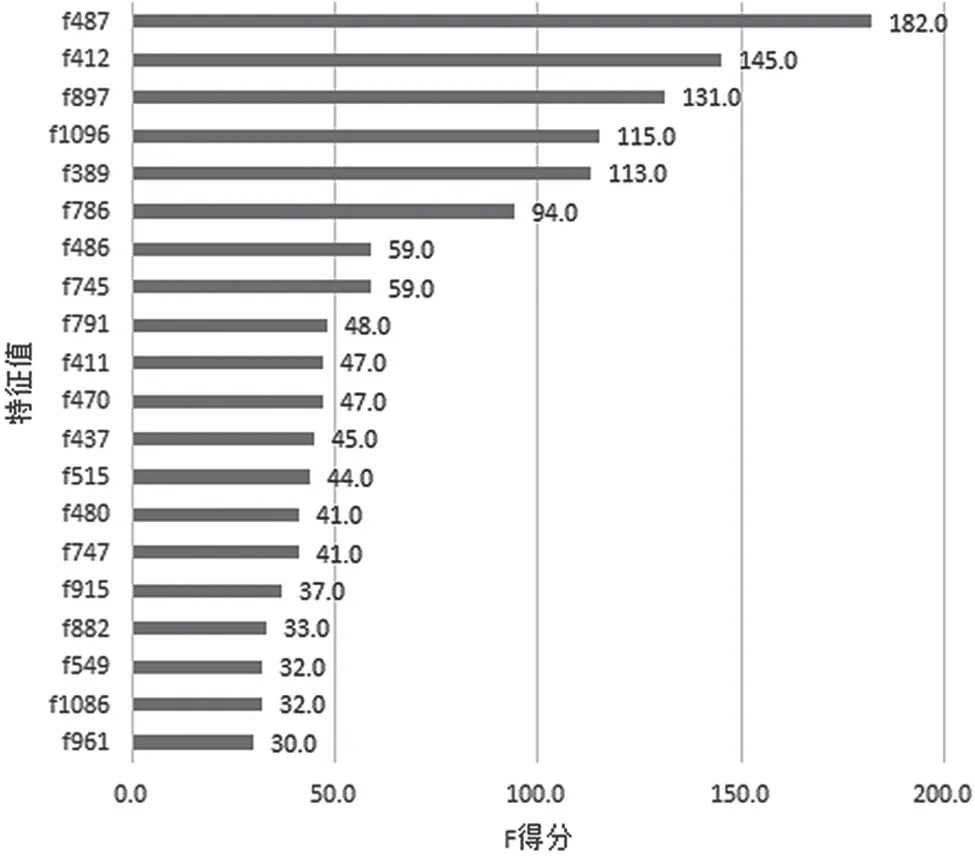
图12 默认参数模型训练特征提取统计
从上述验证结果可以看出,梯度提升树算法在不做任何调优的情况下,训练得到的DGA 域名检测模型的综合准确率已达95%,合法域名检测准确率为93%、召回率为98%、F1 分数为95%,DGA域名检测准确率为98%、召回率为93%、F1 分数为95%,分类效果还是比较理想。
3.3 检测模型调优
检测模型调优的主要工作是调整算法参数反复训练和验证,直至找到理想的参数设置。梯度提升树算法包括分类算法和回归算法,其重要参数分两类,第一类是Boosting 框架的重要参数,第二类是弱学习器即CART 回归树的重要参数。本文主要是用梯度提升树算法对域名进行分类,相关重要参数说明如表3 所示。

表3 GBDT 分类器调优参数说明
梯度提升树算法的参数之间会相互影响,为高效找到模型参数组合,需利用网格搜索和交叉验证方法。网格搜索和交叉验证方法根据预设的参数范围,自动调整模型参数设置,并对模型进行验证分析,经比较后给出最优参数设置。参数优化调整核心代码如图13 所示。

图13 网格搜索和交叉验证参数调优代码
鉴于计算资源限制,本文只对部分关键参数进行了调优验证,XGBoost 分类器的最优参数设置组合如表4。

表4 XGBoost 优化参数设置
将XGBoost 分类器的参数设为上述过程找到的最佳参数搭配生成调优后的检测模型,利用验证集对调优后的检测模型进行验证,检测模型的综合准确率提升到98%,合法域名检测准确率为98%、召回率为99%、F1 分数为98%,DGA 域名检测准确率为99%、召回率为98%、F1 分数为98%。检测模型验证结果如图14 和图15 所示。
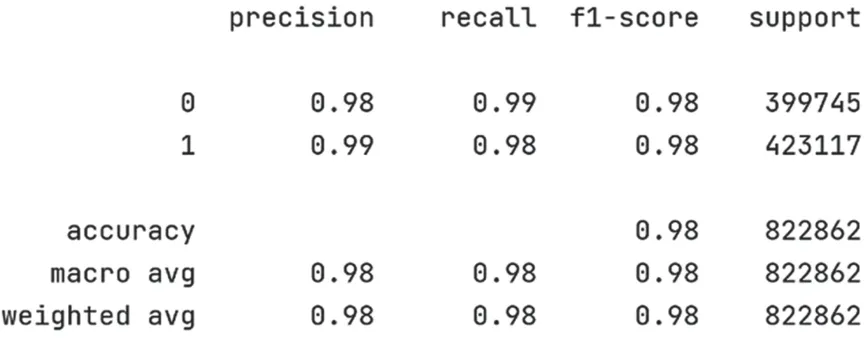
图14 优化模型验证结果统计

图15 优化模型特征提取统计
3.4 检测模型实测
为验证深度学习得到的DGA 检测模型在作业环境的实际效果,本文从互联网收集了不在本次构建的样本集中的DGA 域名,交检测模型进行判定。针对2 万多个DGA 域名进行检测,准确率达100%。验证结果如图16 所示。
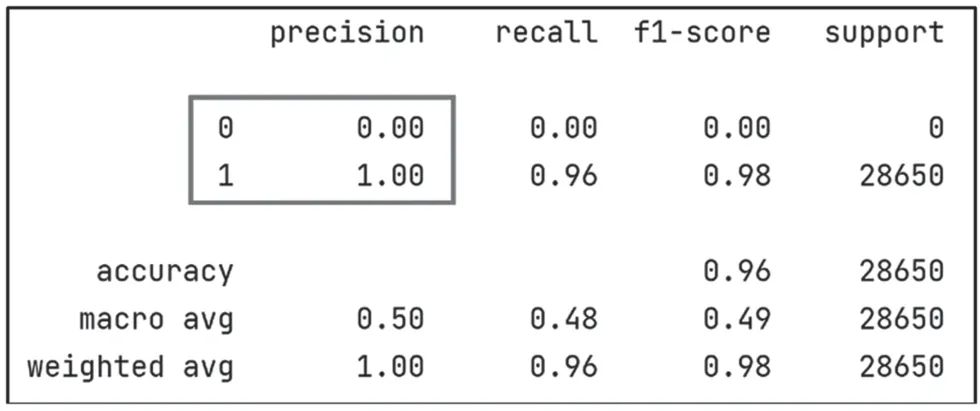
图16 检测模型实测结果
4 结语
随着机器学习和人工智能技术的蓬勃发展,机器学习和人工智能技术逐渐深入到人们生活的方方面面,也不断应用到网络安全威胁检测中。DGA 域名是与C&C 服务器通信的主流手段,DGA 域名检测成为检测和防御僵尸网络、勒索病毒的重要方式。本文基于梯度提升树算法,探索机器学习在DGA域名检测的实现方法,有重要的现实意义。
本文基于公开的DGA 域名和网站排名信息构建域名样本数据,对梯度提升树算法模型进行训练和调优,得到基于梯度提升树算法的DGA 域名检测模型,实现了DGA 域名的高效检测,可作为DGA域名研究治理的参考实现方法。该检测方法实验室验证效果良好,但鉴于作者能力和样本数据的限制,检测模型的检测能力还需要在实际网络中长期 验证。
