基于Spark计算的数据分析应用研究
2023-01-14翟金亭
翟金亭
关键词:Spark;大数据;分析管理;应用研究
1引言
随着互联网、云计算和人工智能的快速发展,人们的日常生活和工作中会产生大量的小文件,如图片、信息等数据文件。这些小文件数据规模越来越大,因此,高效地管理海量小文件数据是非常重要的应用需求。数字数据的数量爆炸使得研究人员和开发人员寻找更加科学合理的新方法,“大数据”应运而生。大数据分析对于管理海量数据具有重要的意义,从已有的数据资源中挖掘更有价值的知识具有重要的作用。大数据在扩展性,复杂性,速度等方面都面临不一样的挑战,扩展性是指以指数形式将数据量由Terabytes发展为Petabytes, Exabyt, Zettabyt, Yottabyt等;复杂性意味着数据具有多样性,可表现为结构化,非结构化以及半结构化,其内容涵盖了多种格式,种类以及结构,如文本、数字、图像、音频、视频、顺序、时间序列、社交媒体数据以及多维数组[1-3]。
近年来,数字数据增长仍然呈指数型增长,需要寻找一种高效的手段对海量数据进行实时处理并提取信息,如分布式数据处理工具Hadoop,Spark计算技术等。国内外学者针对此类问题进行了大量的研究,并取得丰富的研究成果,如2012年Gartner认为,大数据将会成为新技术发展的热点,海量和多样化的信息资产需要一种新的处理模式,而大数据正好可以从海量数据中提取关键信息,使数据信息使用者可以高效使用信息,增强企业洞察危险的能力,优化数据的流程,最终决策也更加准确和科学;Victor在《大数据日寸代——生活、工作与思维的大变革》一书中指出,大数据时代要想得到有价值的信息,就需要从总体数据进行分析,而不是使用少量数据样本分析与实务相关的数据。其更为关注数据之间的相关性,而不是探求数据的因果关系和精确性。
2Spark计算技术的优劣势
能够有效地进行大数据处理研究的Spark技术的框架系统,最初是由Matei Zaharia于2009年在加州大学伯克利分校的AMPLab开发的,并于2010年作为Apache项目成为开源项目,Spark技术主要使用分布式弹性数据集(RDD),旨在促进编写和提高重复、重用数据(交互或迭代算法)的大数据应用程序的执行速度[4]。截至2015年,国内外学者已经开始使用Spark技术进行数据的评估分析,并且一些企业已经开始使用Spark技术存储、探索和分析在企业运行过程中产生的海量数据。2018年,郭育辰基于大数据框架Spark,利用话单大数据进行了诈骗电话的识别和响应模型研究,来降低诈骗分子的成功率,达到保护人民群众财产安全的目的;2018年,毛辰阳利用Spark平台获取好友列表和共同好友,基于话单分析的人物关系可视化分析可疑联系人,为侦察嫌疑人提供技术支持;2019年,吕亮亮基于Spark实现电信客户细分数据分析平台的应用。
2.1Spark计算技术的优势
首先,Spark是一种基于内存的计算,传统的硬盘由于物理性质限制进行提升非常困难,而CPU和内存的发展近年来却是十分迅速。内存的发展遵循着摩尔定律,近几十年来内存价格不断下降,内存量逐渐增加。现在主流的服务器中就有大量几百GB或几TB的内存储量,使得内存数据库的实现成为可能,而Spark正是利用这种计算资源而设计出的一种基于内存的分布式处理软件,以达到取代MapReduce的目的。其次,Spark计算模式的速度具有优越性,研究表明,在内存中运行时比Hadoop快100倍,在磁盘上运行时比Hadoop快10倍。Spark计算模式能够实现对HDFS进行数据的读取功能,并且能够支持YARN、MapReduce模型,还支持SQL查询、流数据、机器学习和图算法等部署模式,支持多种编程语言,Spark提供Java,Scala和Python语言的内置API。
2.2Spark计算技术的劣势
近年来,基于Spark技术在大数据计算分析应用过程中也发现存在一些缺点,对该技术的性能造成一定的影响。在系统架构稳定性方面,Spark技术基于Java语言代码实现数据处理功能,一般情况下,在处理大数据的过程中系统的RAM会出现内存占用率太高的现象,但系统代码回收数据垃圾的效率比较低,严重影响系统架构的稳定性,导致处理过程中会出现报错等错误信息。其次,由于Spark计算海量数据对硬件设备要求比较高,因此,普通常用的服务器无法满足需求,需要更大的服务器集成群完成计算任务,从而有利于更好地改善计算环境,提高使用效率。
3基于Spark计算的数据分析实际应用
3.1基于Spark平台的电信行业用户流失预警
随着电信行业和Spark技术的快速发展以及手机的普及应用,电信行业系统的应用规模越发扩大,行业内应用同时所产生的数据量则呈现指数型增长的趋势。鉴于此,寻求一种有效且能够解决实际问题的大数据处理技术以及方法手段成了目前行业的迫切需求。
随着电信产业的不断发展壮大,其海量的电信数据为Spark技术提供了独特的应用空间。在云计算、大数据背景下,对于行业客户流失的预警分析就显得尤为重要。在电信行业发展的同时,如何控制或减少行业客户流失已经变成电信行业目前的难题。在面对海量数据进行分类预测时,Spark强大的计算能力就显得非常适合。因此,我们引入大数据平台的Spark组件,借助随机森林分类预算法构建用户流失预警模型,分析用户使用情况的细微波动,同时不断改进模型以及模型的参数,调整预测效果。不同的目标客户有着不同需求,针对性地设计专属的营销方法,可以有效减少客户的流失,最大限度地实现对客户的守护。
3.2基于Spark平台及话单分析的人物关系可视化的研究与应用
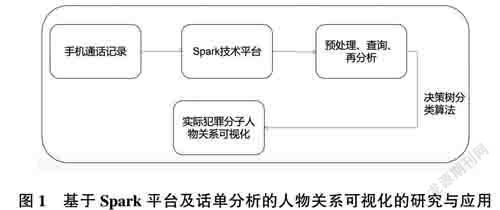
近年来,随着网络的飞速发展,手机技术的革新也越来越快,同时手机的功能和角色也越来越多样化,我们在使用手机的同时,手机信息安全等信息记录安全就显得尤为重要。最近几年,很多犯罪分子会广泛应用手机实施犯罪活动,此时,对手机中各种犯罪信息记录进行分析就成为公安日常办案中不可或缺的重要技术手段。警方可以通过手机分析犯罪嫌疑人的通话记录和相关人物及机主的相关特征,其对破获案件和缉拿犯罪嫌疑人有着不可替代的作用,本文以Spark技术为平台,将通话记录和相关信息作为本次研究的基础数据,对基础数据进行预处理、查詢和分析相关数据,通过决策树分类算法获得犯罪嫌疑人的人物关系,这就可以为警方办案提供有用的线索,如图1所示。
综上所述,基于Spark平台及话单分析的人物关系可视化的研究与应用不仅可以对缉拿犯罪嫌疑人有巨大的帮助,而且可以协助电信行业、辅助电信用户获取隐藏在话单中的有价值信息。
3.3基于Spark话单大数据的诈骗电话识别与响应模型研究
网络技术飞速发展的同时,其也变成了一把双刃剑,很多犯罪团伙会借助网络技术渠道实施网络诈骗,使得人们财产及生命安全面临严重的威胁。由于手机功能的多样化,使得电话诈骗变成最普遍及后果最严重的诈骗方式。但是,电话诈骗存在手段隐蔽、诈骗组织隐秘等特点,对于后期的破解存在难度大且治标未治本的特征。近年来,虽然国家开发了国家反诈骗APP等一些防诈骗软件,但是由于诈骗组织技术的顽劣,依然很难杜绝诈骗事件的发生。此时,如何在诈骗前或中期及时地发现诈骗事件、及时阻止诈骗事件的发生,将对群众和社会的危险降到最低就成了一个较为关键的研究应用热点。本文基于Spark技術,以话单数据作为分析的切人点,对获取的诈骗电话通信记录信息进行离线数据分析,从而构建出诈骗电话识别与响应模型,以实现快速识别诈骗组织实施诈骗犯罪行为时间段内的诈骗电话,为警察以及反电信诈骗平台提供重要的技术依据。
3.4基于Spark技术的电信客户细分数据分析平台实现和应用
201 8年,中华人民共和国工业和信息化部公布了11月通信业经济运行状况,报告中表明当前移动用户的用户人数大约为15.6亿,同比之前上涨速度极快。这也表明了不仅网络速度增加了,而且随之带来了人们生活方式的改革。在电信行业,由于移动用户的变化、用户消费的变化、行业系统的改革、数据量等的变化导致企业的运营发展需要进行不断的更新以求新的变通。面对目前竞争激烈的市场,对于电信公司而言,同等质量的服务背景下,如何做好客户的服务及防止客户的流失显得无比重要,同时客户的细分对于维护客户关系成了很重要的前提和基础。本文基于Spark技术,利用电信运营商的CRM数据、计费数据及客户的兴趣偏好等为切入点,将目标客户进行细分,帮助电信企业实现效益最大化,对电信运营商进行客户维护和防止客户流失具有重要的参考意义。
4结束语
Spark是一种新兴的技术,与Hadoop MapReduce相比,Spark的迭代计算速度更快,应用前景更加广泛。通过总结归纳国内外相关研究文献发现,目前Spark在大数据处理方面的理论及实践都有一定的研究成果,但在系统架构、算法设计等方面仍然存在着很多不足。Spark已成为一种具有高级内存编程模型与可扩展上层库的大数据分析框架,具有先进的内存编程模型,并应用于可扩展机器学习、图形分析、流媒体以及结构化数据处理等领域,但是由于其自身的诸多缺陷,对于大数据量、稳定性方面还需进一步的改进完善。
