多注意力机制金字塔池化金手指划痕分割方法
2023-01-13吴良武周永霞王宇航朱钰萍
吴良武,周永霞,王宇航,朱钰萍
1.中国计量大学 信息工程学院,杭州 310018
2.杭州市蓝弧视觉科技有限公司,杭州 310018
柔性电路板(flexible printed circuit,FPC)是一种广泛应用于生活生产中的电子器件,在电子设备、手机、电脑和医疗设备等领域都得到大量使用。金手指是FPC上用于导电进行信号传输的金黄色导电触片。金手指在生产、搬运过程中容易对表面的镀金造成一定的损伤,造成不同的缺陷,其中划痕是金手指中最常见的缺陷之一。金手指表面的划痕会降低FPC的导电性能减弱信号的传输效果,影响设备的正常使用,所以必须将存在缺陷的元件检测出来,对其进行返工或报废处理。
传统的金手指划痕缺陷检测是人工实现的,通过肉眼鉴别生产出的FPC有无缺陷。人工识别是非常费时费力的,而且长时间地使用肉眼容易造成视觉疲劳,可能会造成对缺陷的误检和漏检。由于缺陷区域较小以及背景的干扰,使用传统的图像处理方法和基于深度学习的分类模型检测后,都存在大量漏检和误检的情况,无法达到工厂的生产要求。
2015年,美国伯克利大学的Long等[1]提出了全卷积网络(fully convolutionl network,FCN),该网络将神经网络末端的全连接层替换成了卷积层,使其可以接受任意大小的图片作为输入。FCN是将卷积神经网络结构应用到图像语义分割中的开山之作,随后的语义分割模型基本都采用了这种结构。FCN提出后不久,基于其改进的语义分割网络U-Net[2]诞生。与FCN相比,U-Net的网络结构是完全对称的,encoder部分和decoder部分是非常相似的;而FCN的decoder部分较为简单,只使用了反卷积操作。刘孝保等[3]首先使用Focal-Loss优化后的U-Net网络对缺陷进行分割和定位;然后结合卷积神经网络(CNN)和反向传播神经网络(BPNN)构建主从特征与分类层;最后通过级联特定模糊规则的模糊神经网络对铝型材表面缺陷进行分割,取得了较好的分割效果;任秉银等[4]针对U-Net对微小缺陷分割效果不佳的情况,在分类网络中加入分割网络并且加入注意力机制对U-Net网络进行改进,很好地完成对手机屏幕轻微划痕的准确检测。
语义分割是对图像中的每一像素进行细粒度的分类,检测效果会更加精准,因此本文选择该方法对金手指表面的划痕进行检测。由于划痕的形状大小不一,目前主流分割模型[1-2,5-6]对划痕的分割效果不够理想;而金字塔结构能够获取多尺度特征信息,于是本文基于PSP-Net[6]模型结构,提出了多注意力机制金字塔池化方法对金手指表面的划痕进行分割。主干网络采用ResNet50[7]来提取特征图,然后将获得的特征图输入到多注意力机制金字塔池化模块(multi-attention mechanism Pyramid pooling module,MAMPPM)进行特征增强,接着与原始特征图拼接后通过一个卷积层得到最终分割结果。实验结果表明,本文提出的方法能够很好地分割出金手指表面的划痕,并且划痕边缘区域的分割效果相比于其他模型更加光滑和细腻,在MIOU和MPA指标上也有较大的提升,优于常用的分割模型;并且目前已在工厂实际生产中进行测试,每1 000份产品中的漏检率大约为5%,基本符合工厂的生产需求。
1 金手指表面划痕分割方法
金手指表面的划痕形状和深浅各不相同,通过高分辨率工业相机在环形光源的照射下获取的图片能够突出划痕的形状和深浅,如图1所示。金手指表面并不是光滑的经过光源的反射后,拍摄得到的图片中背景区域和划痕区域有一定的相似性。因此分割模型需要将划痕区域的特征进行增强,以便更好地将背景和划痕区分出来。

图1 金手指划痕图Fig.1 Golden finger scratched diagram
针对图片存在背景干扰的问题,本文首先采用去除全连接层的ResNet50模型获取图像的特征图,并使用扩张卷积[8]策略来增大感受野以获取更多的特征信息;然后在PSP-Net的金字塔池化模块(pyramid pooling module,PPM)中的每一层引入了CBAM[9]和ECA[10]两种注意力机制,在注意力机制的输出端串联边界细化(boundary refinement,BR)模块[11]实现对划痕边缘区域的精细化,使边缘的分割效果更加准确;采用级联的方式将金字塔不同层建立联系进行特征增强,最后将不同层的输出与最初获取的特征图拼接后通过卷积层得到最终的预测分割图,模型完整结构如图2所示。
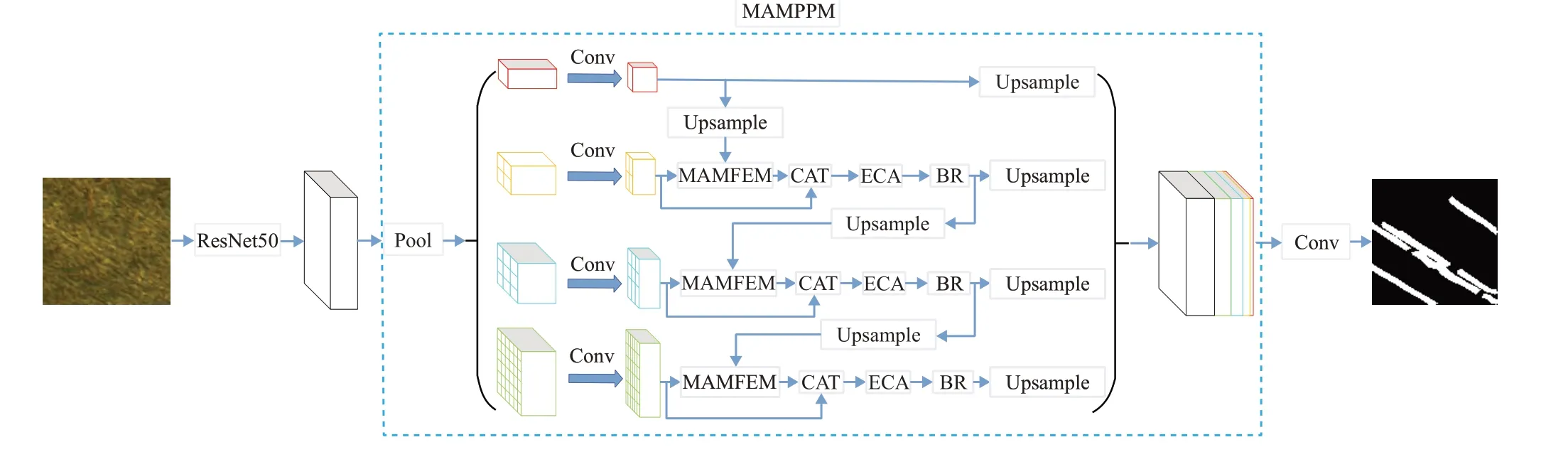
图2 完整模型结构图Fig.2 Complete model structure diagram
1.1 特征提取
考虑到划痕区域会受到背景的干扰,需要一个深度网络提取更多的特征信息,本文采用ResNet50模型获取输入图片的特征图,输入图片的大小为112×112,bath-size为32。
ResNet50总共有50层,模型的最后一层是用于分类的全连接层,语义分割中并不需要该层,因此实际上使用了前49层提取特征。ResNet50的第一部分是一个单独的卷积层,受VGG-Net[12]模型的启发,为了减少网络的参数量,本文采用3层3×3的卷积层堆叠在一起替代原模型中第一层7×7的卷积层。卷积层后是一个3×3的最大池化层,为了保留更多的特征信息,池化层中stride和padding都设为1。模型的第二部分由4个layer共16个bottleneck堆叠构成,bottleneck的结构如图3所示。输入的特征图首先使用1×1大小的卷积核进行降维,经过3×3大小的卷积处理后再通过1×1大小的卷积核对通道数进行还原以保证输出的通道数与输入的通道数一致,降维再还原的过程有效减少了模型的计算量;每个卷积层后都串联了批量归一化层(batch normalization,BN)和ReLU激活函数,BN层能够对输入数据进行归一化处理,防止网络在反向传播中出现梯度爆炸或梯度消失,使得训练过程更加稳定;ReLU激活函数增加了网络的非线性因素同时可以防止梯度消失。
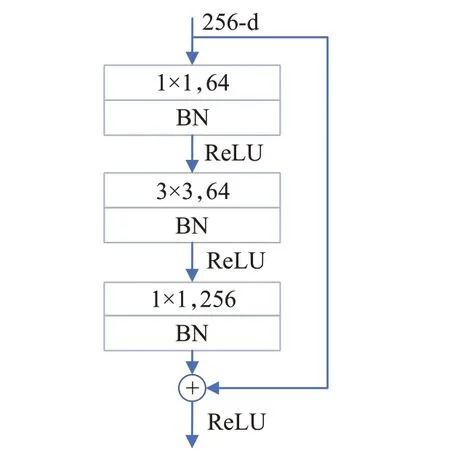
图3 Bottleneck结构图Fig.3 Bottleneck structure
使用降采样方法增加感受野和降低计算量,但是这会降低空间分辨,本文ResNet50的layer3和layer4中采用扩张卷积策略在不降低空间分辨率的情况下增大感受野,使得卷积输出包含较大范围内的信息并且具有较高的空间分辨率以便对目标的定位更加精准。经过layer4之后得到32×3×8×8的4维特征张量。
1.2 多注意力机制金字塔池化
PSP-Net的金字塔池化模块(PPM)将提取的特征图按不同层分别分成1×1、2×2、3×3、6×6共4种包含不同大小的子区域的特征图,如图4显示,接着使用1×1的卷积将不同尺寸的特征图通道数降为原来的1/4,之后全部上采样使其与输入特征图的大小相同并与输入特征图进行拼接,最终将全局和局部特征信息融合到一起。
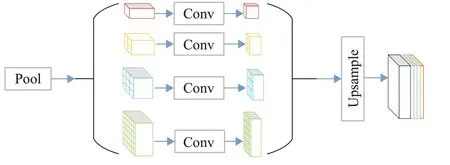
图4 金字塔池化模块Fig.4 Pyramid pooling module
但是4种带有不同局部信息的特征图在上采样过程中会丢失部分信息,并且原模型只是将不同尺寸的特征图简单拼接,没有进一步利用不同层的特征信息。针对上述的不足,本文将金字塔不同层建立联系对划痕区域进行特征增强。具体做法如下:首先将金字塔的第一层通过双线性插值增大到与第二层特征图相同的尺寸;接着与第二层的特征图进行逐元素求点积,求点积后的结果输入到CBAM注意力机制中;输出结果与第二层的特征图逐元素求和,然后将求和结果与CBAM模块和BR模块串联,构成了多注意力机制特征增强模块(multi-attention mechanism feature enhancement module,
MAMFEM),如图5。图中1×1的卷积操作是为了相乘和相加过程中通道数能够保持一致。

图5 多注意力机制特征增强模块Fig.5 Multi-attention mechanism feature enhancement module
本文数据集中代表背景的像素值为0,代表划痕的像素值为1,数据集图片中背景区域占据了图片的绝大部分;又因为第一层的特征图是经过全局平均池化后得到的,所以该特征图中元素的值趋近于0。经过双线性插值上采样后与第二层逐元素求点积使得第二层中的元素的值都减小了,这相当于弱化了划痕的特征信息,不利于对划痕的分割。于是将点积的结果通过CBAM获取重要特征后再与第二层进行逐元素求和,得到的新的特征图中背景区域是两个非常小的数求和之后的结果,依然是一个很小的数,而划痕区域是一个较大的数与一个相对较小的数求和后的结果,结果依然是一个较大的数,并且比原来的值更大,所以通过逐元素求点积再逐元素求和的操作,使得第二层背景区域的特征信息基本不受影响的情况下,增强了划痕区域的特征信息,具体运算流程如图6。图中是金字塔第一层与第二层进行特征增强的示例,金字塔第一层和第二层子区域较大因此包含更多的背景信息,所以数值较小,而金字塔的第三、第四层的子区域相对较小,包含相对较多的划痕信息,因此数值会较大,特征增强效果也会更明显。
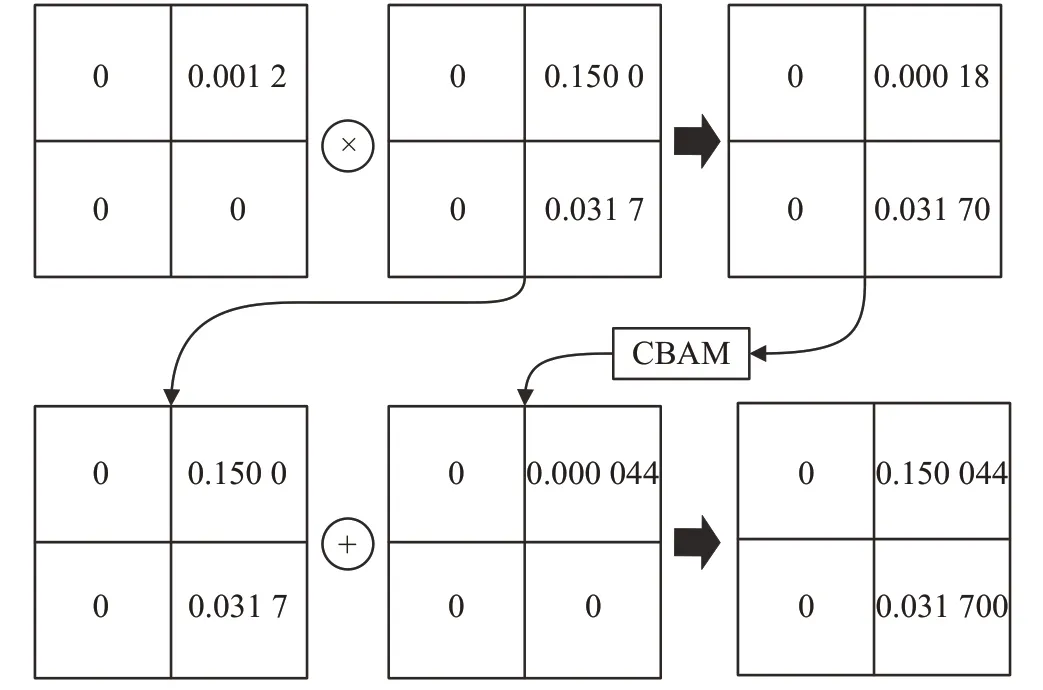
图6 逐元素相乘再相加运算流程Fig.6 Element-wise multiplication and addition operation process
在加入MAMFEM后将输出与第二层的原始特征图拼接,并与ECA模块和BR模块串联得到新的第二层输出。
第一层与第二层融合后的输出按照与第一层相同的方法进行双线性插值得到与金字塔第三层相同尺寸的特征图,输出结果再与第三层进行逐元素求点积以及逐元素求和的操作,最后与第三层原始特征图拼接得到新的第三层输出;然后继续按照相同的方法将新的第三层输出结果与第四层进行融合得到新的第四层输出;最后将金字塔所有层全部上采样,并与带有全局特征信息的特征图进行拼接。整个模块通过级联的方式将金字塔不同层建立联系并进行特征融合,逐层增强划痕区域的特征信息,同时采用不同的注意力机制获取重要的特征信息,顾本文将其称为多注意力机制金字塔池化模块,结构如图7所示。
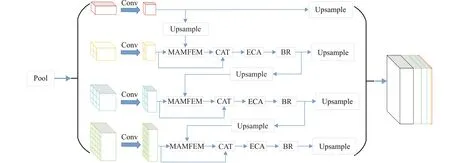
图7 多注意力机制金字塔池化模块Fig.7 Multi-attention mechanism pyramid pooling module
CBAM是一种结合了通道注意力和空间注意力的注意力机制,能够获取每个特征通道和特征空间的重要程度,利用获得的重要程度来抑制当前任务中不重要的特征,结构如图8所示;通过实验发现使用CBAM能够将不重要的特征信息降低多个数量级,而本文数据集图片中背景的占比很大,通过CBAM能够很好地抑制背景对分割的影响。ECA模块是一种超轻量通道注意力机制,ECA-Net作者通过剖析SE-Net[13]中的通道注意力模块后,证明避免降维和适当的跨通道交互对通道注意力的重要性;于是给定输入后在不降低维度的情况下进行逐通道平均池化,通过考虑每个通道和它k个近邻来捕获局部跨通道交互;本文提出的多注意力机制金字塔模块中存在通道拼接的过程,于是便考虑使用ECA模块来捕获重要通道提升分割效果。BR模块能够进一步提高对边缘区域分割的准确性,其结构类似于残差块的结构,如图9所示。
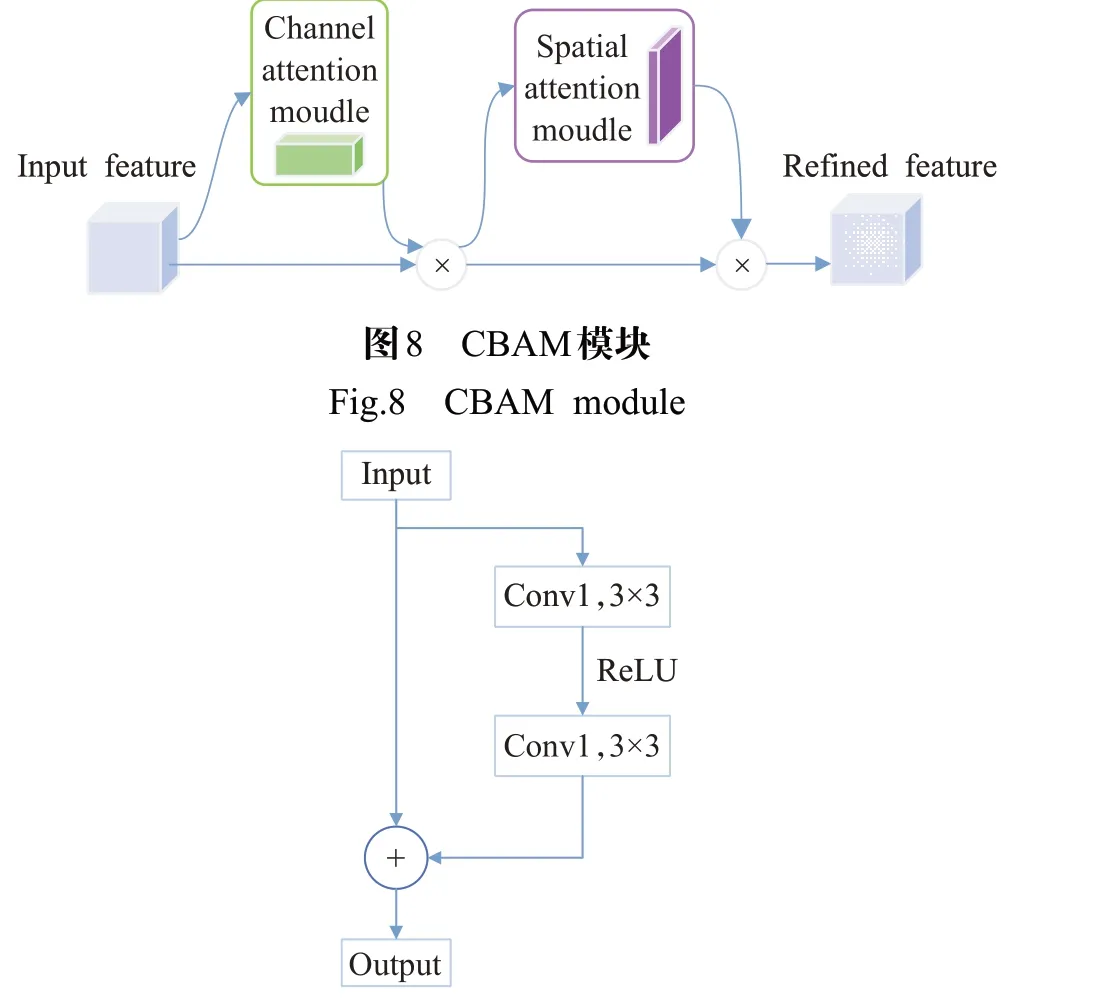
图9 边界细化模块Fig.9 Boundary refinement module
1.3 损失函数
交叉熵可以判定实际的输出和期望的输出的接近程度,交叉熵损失函数在语义分割中使用广泛,公式1是一个二分类的交叉熵损失函数的表达式,其中P表示预测值,y表示真实值。当y=1时,L=-lb P,因为对数函数是单调递增函数,所以L是P的单调递减函数,即预测值P越大(接近1)靠近真实值,那么损失函数L的值就越小;P越小(近0)远离真实值,L的值越大。同理,当y=0时,L=-lb(1-P),此时L是P的单调递增函数,即预测值P越大(接近1)远离真实值,损失函数的值越大;当P越小时(接近0)靠近真实值,L的值越大。但是交叉熵损失函数对于正负样本会公平处理,当正样本占比比较小时,会被更多的负样本淹没,因此当正负样本不均衡时很难挖掘出正样本。
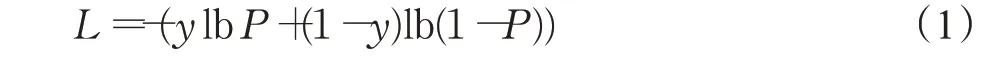
Dice系数是一种用来度量集合相似度的函数,如公式(2)所示,用于计算两个样本的相似程度。公式(2)中|X⋂Y|表示X和Y的交集,|X|和|Y|分别表示X、Y的元素个数,分子中的系数2是因为分母中存在重复计算X和Y的共同元素,S的取值范围为[0,1];在语义分割任务中X表示ground truth,Y表示predictions。Dice系数的另外一种形式如公式(3)所示,在计算Dice Loss[14]时通常使用公式(4)这种形式,其中TP表示将正类正确预测为正类的个数;FP表示将负类错误预测为正类的个数;FN表示将正类错误预测为负类的个数;smooth是一个极小的数,可以防止分母预测为0,并起到平滑loss的作用。Dice Loss在训练过程中更倾向于挖掘正样本(前景区域),解决正负样本不均衡问题。

本文训练使用的图像中,前景(划痕区域)的占比较小,属于样本不均衡问题[15],因此将Dice Loss作为本文模型训练时的损失函数之一。但是Dice Loss在正样本为小目标时存在震荡的情况,会造成训练过程不稳定,而交叉熵损失函数训练过程则较为稳定,所以本文最后将两种损失函数相结合作为本文模型的损失函数。PSP-Net中添加了辅助分支来优化学习过程,本文保留了辅助分支,并在多次实验后将辅助分支的权重设为0.8,最后结合Dice Loss和交叉熵损失函数得到本文最终的损失函数,见公式(5):

公式(5)中的Aux_CE_Loss表示采用交叉熵损失函数形式的辅助Loss,Aux_Dice_Loss表示采用Dice Loss形式的辅助Loss。本文在选取损失函数时尝试使用过Focal Loss、Lovasz Loss等适用于样本不均衡的损失函数,但是在训练过程中出现了nan或是训练效果不佳的情况,不适用于本文的方法。
2 实验分析
2.1 实验数据集和实验环境
本文使用的数据集是杭州蓝弧视觉科技有限公司使用工业相机在搭建的机台上拍摄得到的,并在原图的基础上裁剪出分辨率为112×112共1 000张包含划痕的图片,部分数据集原始图片见图10。本文使用Labelme标注工具制作分割标签图,然后使用ImageEnhance进行数据增强,生成包含6 000张彩图和6 000张标签图的数据集。本文的数据集采用VOC2007格式,分割的类别数为2,因为标签图中背景的像素值为0,划痕的像素值为1,所以生成的标签图看上去是全黑的图片,经过OpenCV处理后,部分数据集标签图片见图11,图中红色区域代表划痕,黑色区域代表背景。数据集按9∶1的比例分成训练集和验证集。

图10 划痕数据集原始图Fig.10 Original image of scratch dataset

图11 划痕数据集标签图Fig.11 Label image of scratch dataset
实验使用的硬件环境为RTX 2080Ti显卡、Inteli7-9800x处理器和32 GB内存。软件环境为Windows10操作系统、OpenCV3.4.1、Python3.7、tensorflow-gpu2.1和pytorch1.4.0开发环境。
2.2 实验参数和评价指标
本文使用的深度学习框架为pytorch,总共训练140个epoch,采用Adam优化器,初始学习率为10-4,学习率调整策略为StepLR;StepLR中的步数设为1,冲量为0.9,即每训练完一个epoch后学习率变为上一个epoch的学习率乘以0.9。训练过程采用基于迁移学习[16]的策略:前40个epoch的batch-size为32,接 着50个epoch的batch-size改为16,最后50个epoch的batch-size为8,在每次更改batch-size大小的同时,学习率也需恢复成初始学习率10-4。
本文选取平均交并比(MIOU)和平均像素准确度(MPA)作为模型的评价指标。交并比(IOU)是两个集合(真实值与预测值)交集与并集的比例,MIOU是计算每一类的IOU然后求平均,能够很好地反映分割的精度,计算公式见公式(6):
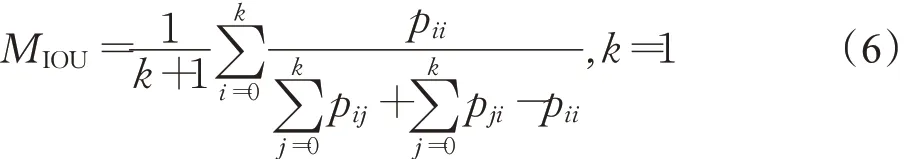
式中k+1表示类别数(包括k个目标类和1个背景类),i表示真实值,j表示预测值,pij表示将i预测为j;像素准确度(PA)表示正确分类的像素点和所有像素点的比例,MPA是计算每一类正确分类的像素点数和该类的所有像素点数的比例然后求平均,计算公式见公式(7):

式中k+1表示类别数(包括k个目标类和1个背景类),pij表示把本属于i类的却预测为j类的像素点总数。
2.3 实验对比与分析
2.3.1 训练策略对比
本文训练中采用了迁移学习的思想,冻结前40个epoch,batch-size为32训练得到的权重,将Batch-size减小为16后使用前40个epoch训练得到的权重继续训练,对模型进行微调(fine tune),经过50个epoch训练后进行相同的操作:冻结训练得到的权重,将batch-size减小为8后使用前面冻结的权重继续训练50个epoch。采用迁移学习策略训练和采用不同batch-size大小训练的结果对比见表1。由表1可以看出,本文提出的模型采用迁移学习的训练方法后,在MIOU和MPA指标上都有显著的提高,验证了本文训练策略的有效性。

表1 采用迁移学习策略训练结果对比Table1 Comparison of training results using transfer learning strategies 单位:%
2.3.2 消融实验分析
为了验证本文方法的有效性和改进的必要性,通过设定不同的消融实验来进行验证,实验结果见表2。
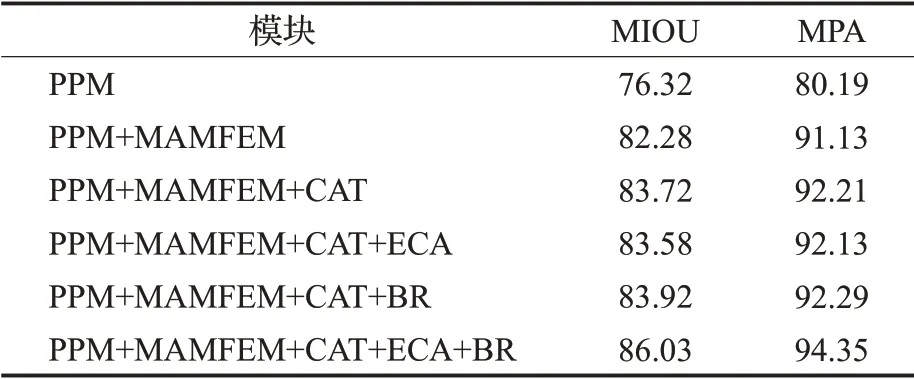
表2 消融实验对比Table 2 Comparison of ablation experiments单位:%
由表2可以看出PSP-Net中的PPM在加入MAMFEM之后,模型在MIOU以及MPA指标上立马有了显著的提升,相比于原始的模型分别高出了5.96个百分点和10.94个百分点,这是MAMFEM将金字塔的不同层建立连接实现特征增强的效果,表明MAMFEM的使用对模型性能提升的有效性。MAMFEM后加入concat操作,与原金字塔池化得到的特征图进行拼接,使得原来金字塔层的特征信息得到保留,更加丰富的语义信息在模型性能上也带来了一定的提升,可以看到在concat操作后,MIOU和MPA分别提升了1.44个百分点和1.08个百分点,指标的提升表明了concat操作的有效性。通过表2中第四行和第五行的数据可以看出,单独加入ECA模块后模型的分割效果非但没有得到改善反而变差了;这是因为ECA模块是将k个邻域的通道进行交互来捕获重要通道,concat操作将两个不同的输出首尾相连,但是连接处区域的通道几乎没有相关性,因此在连接处的跨通道交互会破坏原来的通道,如图12红色区域所示;虽然其他区域的通道没有遭到破坏,但是随着一层一层的级联,金字塔底层被破坏的通道数和受影响的通道数会增加,导致分割效果变差;而通过增大k增大交互的范围,使得连接处靠近左侧的通道与左侧通道相关性增强,靠近右侧的通道与右侧通道相关性增强,可以减轻对通道破坏,实验结果表明本文方法在k取7时效果最好。

图12 ECA模块实现原理图Fig.12 ECA module implementation schematic diagram
由表2第六行可知,concat后加入BR模块提高了对边缘区域的分割能力,分割效果有了一定的改善。表2第七行的数据表明将ECA和BR模块串联后使用,模型的分割能力有了较为明显的提升;虽然单独加入ECA模块会破坏部分通道,但是串联类似残差块的BR模块后,被破坏的通道得到了一定的改善,同时ECA模块对重要通道的捕获效果得到保留以及BR模块对边缘区域分割准确度的提高,使得分割能力有了较大的提升。
2.3.3 对比实验分析
为了验证本文方法的优越性,分别选用了U-Net、PSP-Net及Deeplab v3+[17]3个分割模型对金手指划痕训练集进行训练并将训练结果使用验证集进行测试对比。经过实验,各模型测试得到的MIOU和MPA见表3。从表3可以看出本文的方法在MIOU指标上是最高的,达到了86.03%,相比较于U-Net以及PSP-Net有了大幅提升,分别高出了14.36个百分点、9.67个百分点,对比当前较为流行的Deeplab v3+模型同样也有明显的提升,高出了5.78个百分点;通过表3的数据对比,本文的方法在MPA指标上同样是最高的,达到了94.35%,对比U-Net、PSP-Net、Deeplab v3+分别高出了20.19个百分点、14.11个百分点和9.26个百分点。
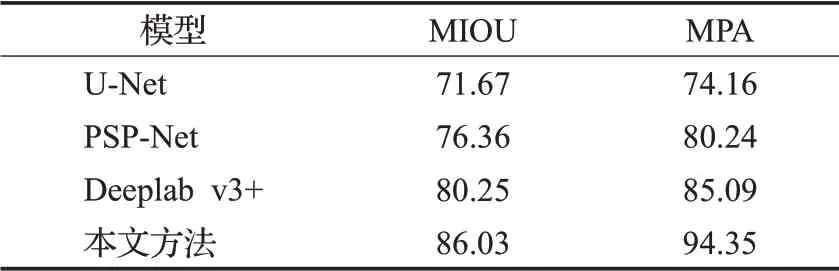
表3 MIOU和MPA对比Table 3 Comparison of MIOU and MPA单位:%
表3的数据对比可以看出,本文提出的方法可以显著提高分割的精确度。
各模型的分割效果图如图13所示。从左到右分别是原始图、标签图、U-Net分割效果图、PSP-Net分割效果图、Deeplab v3+分割效果图以及本文方法分割效果图。U-Net的分割效果如图13第三列所示,U-Net缺少类似金字塔的结构获取多尺度信息,划痕的特征信息较难获取,导致分割效果相对较差,有些区域没能分割出来,有些则是将背景错分为划痕。由图13第四列可以看出,PSP-Net在分割效果上比较粗糙,划痕存在分割断断续续的情况,边缘区域分割也不够精细,造成有些边缘区域出现了锯齿状,与标签图的光滑边缘差别较大;PSP-Net中缺少注意力机制和边界细化模块,不同金字塔层之间也没有关联,对于浅划痕区域、与背景相近的区域和边缘区域的特征信息较难提取,使得分割效果不佳。Deeplabv3+分割效果则相对较好,如图13第五列所示,Deeplab v3+模型中使用了空间金字塔池化模块,能够获得多尺度的信息,并且该模型引入了新的Decoder模块:在上采样过程中首先使用双线性插值恢复到原始图像四分之一大小的特征图,接着与Encoder中相同大小的特征图拼接,并采用3×3的卷积进一步融合特征获取更多的低层特征,最后再使用双线性插值得到与原图像相同大小的分割图。但是Deeplab v3+的分割图在有些较浅且与背景相似度较高的划痕区域,还是存在分割不完整以及边缘区域分割不够精细的情况;这是因为缺少了注意力机制对重要特征进行挖掘以及缺少边界细化模块提高对划痕边缘区域分割的准确度。
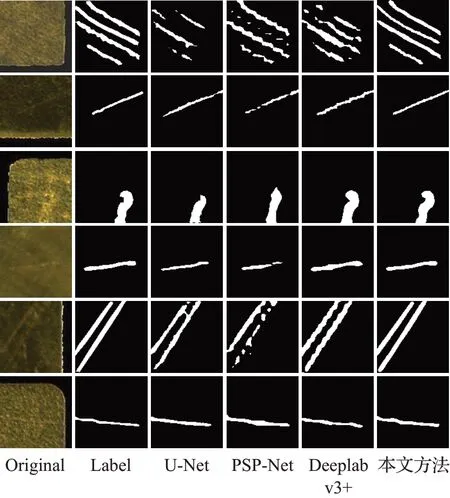
图13 不同模型分割效果Fig.13 Different model segmentation renderings
本文提出的方法,一方面通过金字塔池化获取了多尺度信息,不同尺度的特征图包含了不同的特征信息,小尺度的金字塔层包含了更多的背景信息而大尺度的相对包含了更多划痕区域的信息,通过双线性插值级联后,增强了划痕区域的特征信息。另一方面,本文模型使用不同的注意力机制来重点获取更多划痕的特征信息,边界细化模块进一步提高划痕边缘像素点的分割准确度,使得边缘的分割效果更加光滑,见图13第六列。
3 结束语
本文针对传统图像处理方法以及基于深度学习的分类模型由于划痕形状大小不一,检测效果不佳的问题,采用PSP-Net的模型结构并提出了多注意力机制的金字塔池化模块(MAMPPM)实现对划痕的语义分割。实验结果表明,本文提出的方法,在采用级联的方式连接不同金字塔层实现不同尺度的特征融合并加入注意力机制与边界细化模块后,可以增强模型对划痕区域以及边缘区域的信息提取能力,能够有效分割出不同形状和大小的划痕。对于划痕的分割,本文仍然存在不足,需要改进的方面主要有:(1)对于浅而细的划痕存在分割不完整,分割精度有待提高,对于距离相近的两条划痕分割存在黏连的情况,因此对于边缘的分割还可以更精细;(2)本文数据集是在环形光源拍摄得到的,不同光源的成像效果不同,因此可以采集不同光源下的图片获得更多的划痕样本,扩充数据集提升分割的准确度。
