一种基于2D-CNN深度学习的钻井事故等级预测新方法
2023-01-13赵春兰范翔宇赵鹏斐
赵春兰 屈 瑶 王 兵 范翔宇 赵鹏斐 李 屹 何 婷
1.西南石油大学理学院 2.西南石油大学计算机科学学院 3.“油气藏地质及开发工程”国家重点实验室·西南石油大学 4.西南石油大学地球科学与技术学院
0 引言
石油钻井是石油、天然气勘探开发的重要手段,随着石油开采的不断提速和钻井新技术的迅速发展,各种钻井事故在钻井施工过程中出现的风险也随之增大,严重威胁着钻井工作者的安全[1]。由于钻井行业具有规模大和高风险的特点[2],为了尽量避免人员伤亡、降低财产损失和保证钻井作业的顺利进行[3],根据钻井事故发生的原因,建立一种新的钻井安全事故预测模型,成为了有效评价钻井事故过程中亟须解决的重要问题。
对于石油钻井安全事故的预警研究,按照钻井事故的种类,可分为单一钻井事故和多种钻井事故[4]。单一钻井事故主要为井涌、井漏以及卡钻等某一种事故,而多种钻井事故则是包含了多种单一钻井事故的预警研究。目前,对于单一钻井事故的研究方法较多,包括时间序列分析[5]、贝叶斯模型[6-7]、模糊专家系统[8]、支持向量机回归[9]、BP神经网络[10-11]等。而关于多种钻井事故的预警研究还较少,因此深入研究多种钻井事故的预测对于油气田开采行业具有重要的现实意义。
为了研究石油钻井行业中多种钻井事故的预测,可从其他行业的多种事故预测方向展开进一步研究。随着人工智能技术的日益发展,关于多种事故预测的研究方法主要分为机器学习和深度学习算法。机器学习是通过各种算法对大量的数据进行训练,从而实现预测与分类;而深度学习属于机器学习的分支,是利用更为深层的网络结构来解决特征表达的学习方法。传统的钻井事故预测大多采用机器学习算法,例如支持向量机[12](SVM)、随机森林[13](RF)以及BP神经网络[14]等。虽然SVM和RF预测模型的准确性较好,但是其训练样本的数据维度较小,且难以解决多分类的预测问题。另外BP神经网络中网络结构的不确定性导致预测精度不佳,且容易陷入局部最小值,降低泛化能力。由于机器学习算法对于预测模型的训练已经不能满足预测精度的要求,而深度学习算法可以通过提高网络结构的计算深度来实现多分类钻井事故的预测,因此考虑将深度学习算法应用于钻井事故预测问题中。
针对上述传统机器学习方法在预测精度、处理多维数据以及多分类预测问题等方面存在的不足,国内外的学者提出了基于深度学习方法的卷积神经网络模型来解决这些问题。谭媛元等[15]提出一种基于主成分分析(PCA)和一维卷积神经网络(1D-CNN)的融合模型,通过对财务指标的反向学习训练,构建三层卷积神经网络模型,实现财务危机预警的二分类问题,新模型的预测准确率达到了81.65%;同时Ghulam等[16]利用二维卷积神经网络(2D-CNN)改进抗癌肽的预测,构建一种新的预测抗癌肽的二分类模型,最终实验结果取得了较好的预测准确性。相较于1D-CNN模型,2D-CNN模型具有较高的计算深度,有利于提高卷积神经网络分类预测的效果。鉴于之前2D-CNN模型在抗癌肽的二分类预测中得到了较好地应用,故本文研究二维卷积神经网络模型在钻井事故等级的多分类预测方面的应用。
为了更好地解决多维钻井数据的多分类问题,提高预测模型的准确性,笔者提出了一种基于2D-CNN深度学习模型的钻井事故等级预测的新方法。利用卷积层挖掘多维风险指标的事故特征,通过增加卷积神经网络的计算深度,来提高钻井事故等级的预测精度,首次将二维卷积神经网络应用于多分类的预测问题中,实现钻井安全事故等级的识别,并对钻井现场作业进行有效的风险评价。
1 方法原理
1.1 信息增益
信息增益(Information Gain,IG)是机器学习中常用的一种度量[17],常用于变量的特征选择,当变量的信息增益值越大时,表明变量对分类做出的贡献越多[18],即变量的重要程度越高。通常,信息增益采用信息熵H(X)和条件熵H(XY)的差值表示,信息增益的表达式为:

式中m、n表示变量X和Y的维度,p(xi)表示变量X发生的可能性,表示给定变量X时变量Y发生的可能性。
1.2 模糊C均值聚类算法
引入模糊数学的思想,采用模糊C均值算法(FCM)对钻井事故类型进行分类。FCM聚类算法是一种无监督的算法,核心思想就是通过不断地更新聚类中心与隶属度函数,直到得到最佳聚类中心则终止[19]。假设样本集为X={x1,x2,…,xn},将其划分为c类,令第i类的聚类中心为ci,第j个样本xj属于第i个聚类中心的隶属度为uij。则FCM算法的目标函数如式(2)[20]:

式中c表示聚类数目,n表示样本总数,m表示模糊加权指数,且表示样本xj和聚类中心ci之间的欧几里得距离。隶属度uij满足式(3)的约束条件:

利用拉格朗日乘子法,引入参数λ,则拉格朗日函数为:
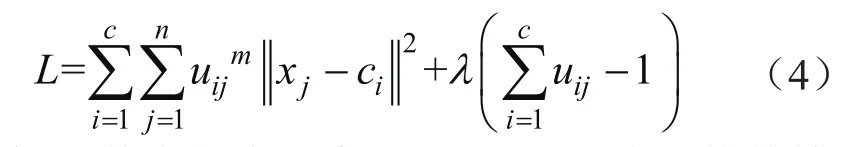
对目标函数中的未知变量ci和uij求偏导使其等于0,得到聚类中心ci和隶属度函数uij的迭代表达式为:

1.3 一维卷积神经网络(1D-CNN)
卷积神经网络(Convolutional Neural Network,CNN)是一种前馈式神经网络,凭借强大的特征提取和识别能力,在时间序列数据和图像数据的分类任务中得到了成功的应用[21]。它不仅能够降低网络模型的复杂度,而且还能通过其特有的卷积、池化操作实现对数据特征的自动化提取,极大地提高了模型对于输入数据的适应能力[22]。由于钻井现场作业的事故风险指标为时间序列数据,因此可以采用一维卷积神经网络(1D-CNN)模型实现钻井事故等级的多分类预测。
通过对BP神经网络中隐含层结构的功能和形式进行改进,将其转化为一维卷积神经网络。BP神经网络与一维卷积神经网络一般都由输入层、隐含层和输出层三个部分组成,区别在于1D-CNN模型的隐含层还包含卷积层、池化层和全连接层。相较于BP神经网络,一维卷积神经网络模型的优势在于:①从输入参数的角度,由于神经元之间的连接方式为局部区域连接,因此有效减少训练参数的数目,降低神经网络的复杂度,提高了模型的计算效率;②从权值异同的角度,1D-CNN模型采用权值共享的方式,使得算法具有较强鲁棒性,且易于训练。BP神经网络和1D-CNN模型的网络连接方式如图1所示。
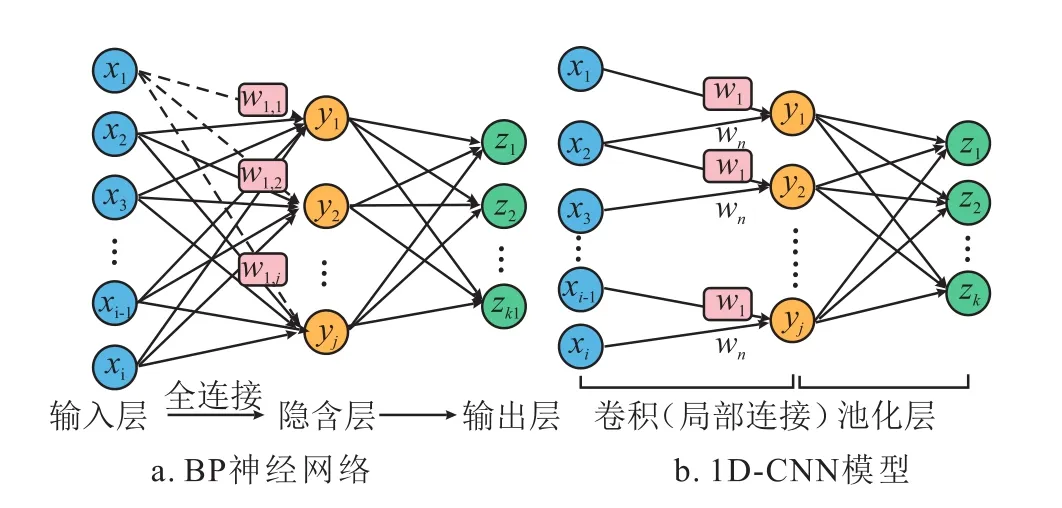
图1 BP神经网络和1D-CNN模型的网络连接方式图
BP神经网络的神经元之间采用全连接的方式,对应的权值和偏置都不同,则隐含层第j个神经元的输出表示为:

由于1D-CNN模型引入了卷积核,因此神经元之间的连接方式变为局部连接,且具有共享权值的特点。再对式(7)的权值部分进行改进,得到一维卷积神经网络中卷积层第j个神经元的输出:

式中wi表示神经元之间卷积核的共享权重;k表示卷积核个数;bk表示隐含层中第k个卷积核对应的偏置。
1.4 二维卷积神经网络(2D-CNN)
根据卷积神经网络中卷积核移动方向的不同,分为一维卷积神经网络和二维卷积神经网络。相较于前者卷积核的单向移动方式,二维卷积神经网络卷积核的双向移动方式能够较好地提取影响事故等级的风险特征,从而提高模型的预测准确性。由此,对1D-CNN的输入形式进行改进,即将一维形式的时间序列数据转化为二维形式的图像数据,则得到2D-CNN模型,其主要结构为卷积层、池化层、输出层3个部分。
通过卷积层提取矩阵特征,其输出值由多个特征面构成,特征面对应的每一个取值都代表一个神经元,特征面中每个神经元上的取值都通过卷积核计算得到[21]。一维卷积神经网络中卷积核是沿x轴的单向移动,而二维卷积卷积神经网络的卷积核是先沿x轴,再沿y轴的双向移动[23],其移动操作如图2所示。

图2 1D-CNN和2D-CNN的卷积层结构图
假设1D-CNN模型卷积核的维度M=4,2D-CNN模型卷积核的维度M×M=2×2。根据式(8)对1D-CNN模型的卷积核和输入数据结构进行改进,得到2D-CNN模型卷积层的计算公式为:

式中yk,j表示第k个特征面的第j个神经元的输出值;wk,s,t表示第k个卷积核中第s行第t列对应的权值;bk为卷积层中第k个卷积核对应的偏置值。
为了提高CNN模型的非线性能力,激活函数选择常用的Relu函数,其具体的表达式为:

接下来采用池化层对提取的特征进行筛选和过滤,通过对上层的数据进行缩放映射来降维,保持数据特征具有缩放不变性,同时防止数据出现过拟合的情况。
最后是输出层,利用Softmax函数回归之后的交叉熵损失函数得到最终分类结果,从而输出预测值,即钻井事故等级对应的分类概率,范围在0到1之间,将概率值最大的类别作为样本所属的钻井事故等级。其中Softmax函数和交叉熵损失函数的表达式分别为:

式中J表示交叉熵损失函数;xi表示全连接层的输出值;yi表示4种钻井事故的真实等级,分别表示特别重大事故、重大事故、较大事故、一般事故;h(xi)表示Softmax函数回归后的值。
2 2D-CNN的钻井事故等级预测模型
2.1 模型思想
对于多种钻井事故的预测研究,虽然传统的机器学习算法基础理论完善,方法简单可行,但在多维数据提取事故特征方面存在一定的局限性。而深度学习算法中的卷积神经网络模型作为常用的处理多维数据的模型,为多维钻井数据的事故等级预测提供了新的思路。由于一维卷积神经网络模型的计算深度较低,使得分类模型的预测效果有待提高。因此为了提高模型的预测精度,将二维卷积神经网络模型应用于钻井事故等级的预测中,以实现钻井现场作业的风险评价。
基于2D-CNN的钻井事故等级预测模型的构建思想如下:首先对原始钻井数据的风险指标和事故类型进行数据预处理,利用FCM聚类算法对事故类型进行分类得到真实的钻井事故等级,再利用信息增益值的大小排序对风险指标进行一次降维;然后将新的风险指标作为2D-CNN模型的输入,通过卷积层的卷积操作以及池化层的二次降维操作,最终输出预测的钻井事故等级,从而解决钻井事故等级的多分类预测问题。
2.2 模型构建步骤
为了解决多维钻井数据的多分类预测问题,笔者提出了基于2D-CNN深度学习算法的新钻井事故等级的预测模型。模型的构建步骤主要分为3步,如图3所示。
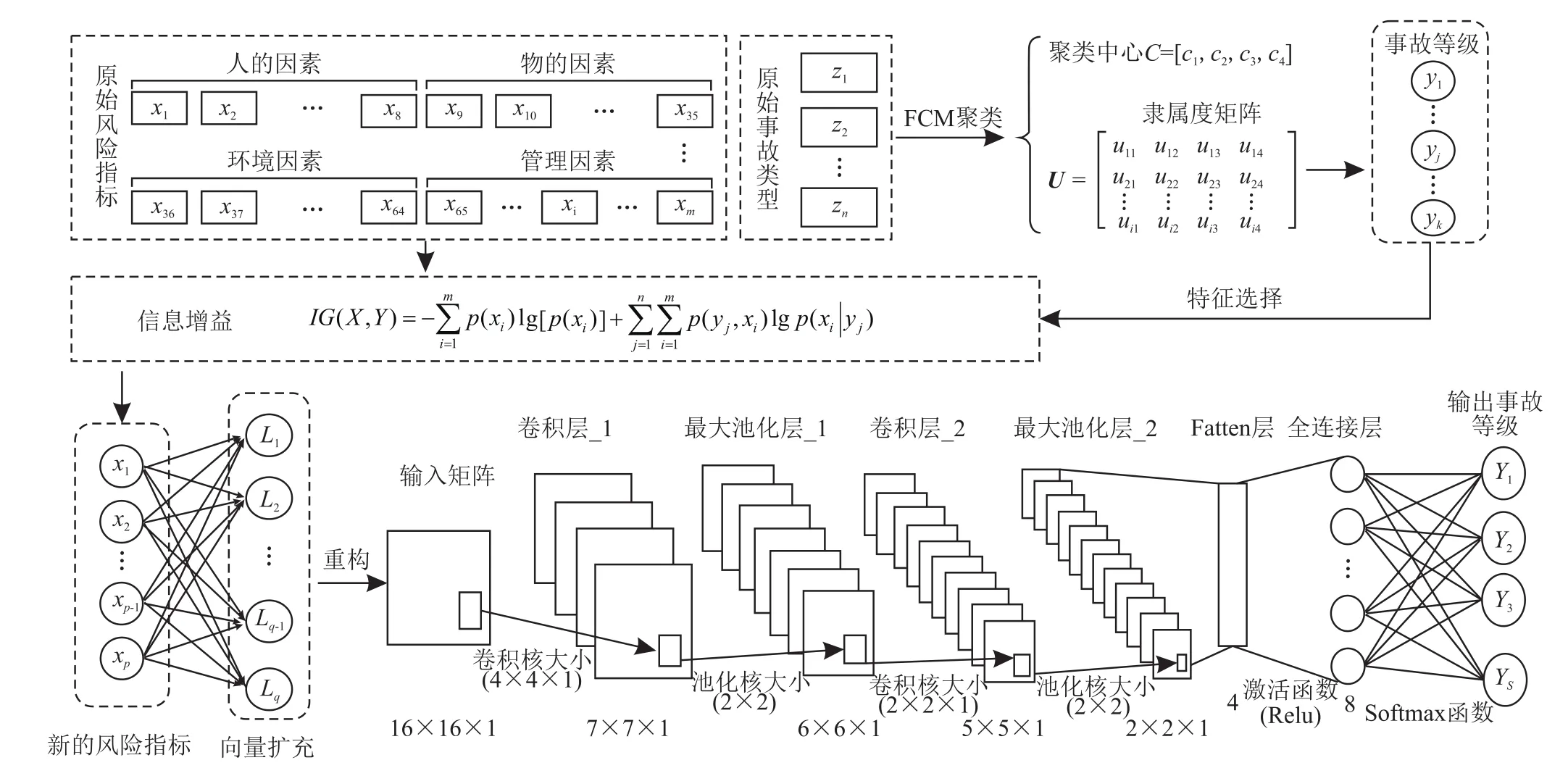
图3 基于2D-CNN的钻井事故预测模型结构图
2.2.1 原始数据完整化处理
通过收集钻井现场作业数据,确定原始三级风险指标和原始钻井事故类型,利用K近邻插值算法对缺失值进行填充以及归一化处理,实现数据完整化处理,以确保后续建模的有效性和准确性。
2.2.2 钻井事故等级划分及特征选择
采用FCM聚类算法对原始事故类型进行分类,根据隶属度矩阵确定钻井事故等级,再利用原始风险指标和钻井事故等级进行特征选择,保留信息增益值大于1的新的风险指标。
2.2.3 构建2D-CNN模型预测钻井事故等级
将新的风险指标进行向量扩充,对新的风险指标向量进行矩阵化处理,在二维卷积神经网络模型中引入卷积核,将新的风险指标矩阵作为2D-CNN深度学习模型的输入,通过卷积层提取风险指标的特征,再经过池化层的二次降维,以及全连接层的计算,最终输出钻井事故分类的预测结果。
3 实例分析
3.1 钻井事故数据说明及预处理
油气钻井现场的风险指标体系具有复杂性、多层次性的特点,导致影响钻井现场作业事故等级的因素较多。通过石油钻探行业工作人员的现场调研,钻井事故数据的一级风险指标分别为人的因素、物的因素、环境因素以及管理因素,13种钻井事故风险类型[24]分别为交通事故、机械伤害事故、火灾、起重伤害事故、其他事故(除上述4类事故以外的事故)、交通事件等。其中,安全事故和安全事件的划分标准为单位人员或非单位人员在现场作业时是否发生人身伤亡、急性中毒或者直接经济损失的事故。钻井事故数据的二级和三级风险指标xi(i= 1,2,…,73)如表1所示,部分三级风险指标含义不作赘述,事故风险类型yj(j= 1,2,…,13)如表2所示。

表1 钻井事故风险评估指标表

表2 钻井事故风险类型表
由于各个钻探公司收集到的原始钻井现场作业数据中存在大量缺失数据,故采用K近邻插值算法进行数据完整化处理。设置适当的K值为3,即将最近邻的3个样本对应维度数据点的均值作为该缺失数据点的估计值。将缺失值进行数据清洗后,整理得到2015年1月至2019年12月内59个钻井现场作业的月度样本数据。
由于钻井风险指标的数据维度较大,因此原始数据在输入2D-CNN模型进行训练之前,需要对数据进行归一化处理,通过最大最小值归一化将原始数据转化为[0,1]之间的数据,实现损失函数的较快收敛。
3.2 钻井事故等级划分
由于影响钻井风险指标的因素较多,根据13种钻井事故类型,对59个钻井事故样本数据进行聚类。利用FCM聚类算法中聚类中心ci和隶属度函数uij的更新迭代公式,得到4种钻井事故等级的分类结果,分别为特别重大事故、重大事故、较大事故、一般事故。则FCM聚类算法的基本流程如下:①初始化参数,设置聚类类别个数为c=4,迭代次数为50次,并指定模糊加权指数m=2;②在满足隶属度权重和为1的约束条件下,计算隶属度矩阵U[式(6)];③根据隶属度矩阵U计算聚类中心c[式(5)];④判断是否达到预设的迭代次数,若未达到,则返回步骤②,若已达到,则说明已达到最优化的目标函数J[式(2)];⑤根据最大隶属度原则,确定各样本所属的4种类别标签。
利用Matlab软件对59个钻井事故样本数据进行模糊C均值聚类,当迭代次数达到50次时,目标函数值趋于稳定,如图4-a所示,通过样本的最大隶属矩阵值确定各样本对应的钻井事故等级。根据钻井事故的严重程度得到分类结果:特别重大事故(16种)、重大事故(15种)、较大事故(15种)、一般事故(13种),则各样本对应的分类结果如图4-b所示。

图4 钻井事故等级的分类结果图
3.3 风险指标的确定
根据各个钻探公司从钻井现场收集到的风险指标和安全事故类型每月发生次数的历史数据,利用式(1)的信息增益值对三级事故风险指标进行特征选择,根据信息增益值的大小排序,保留增益值大于1的风险指标,得到25个显著影响钻井事故等级预测的事故指标。信息增益值的排序结果如表3所示。

表3 各风险指标的信息增益值表
3.4 模型参数设置及预测流程
2D-CNN模型采用监督学习的训练方式,训练过程分为前向训练和反向训练两个阶段。首先确定二维卷积神经网络的结构,设置初始参数和迭代次数,将结构重组后二维形式的特征矩阵作为模型的输入,并进行前向训练,模型的训练样本中钻井事故预测等级与实际值进行对比得到预测准确率;然后进行反向传播,使用优化算法不断更新权重矩阵,从而提高模型的预测准确率。
笔者基于2D-CNN网络的钻井事故预测模型由2层卷积层、2层池化层以及2层全连接层构成。在第一层二维卷积层中,卷积核个数为1,窗口大小为4×4,步长为2,在卷积层后设置激活函数Relu,可以向深度网络中加入非线性;为了防止模型训练过程中出现梯度消失的问题,在卷积层后面添加批量归一化处理(即BN层);之后采用最大池化层,设置步长为1,池化尺寸为2×2,以上卷积层和池化层的填充方式均为不填充模式(Valid);接下来是第二层卷积层,将卷积核的大小设为2×2,步长为1;第二层池化层的参数与上述相同;为了防止模型过拟合问题,加入一个丢弃层(Dropout),设置概率(p)为0.5,即舍弃掉50%的信息;再通过扁平层(Flatten)操作,将三维向量特征压缩成一维时序向量特征。最后接入2个全连接层,输出4种钻井事故等级的预测结果。
2D-CNN模型训练时,将59个钻井样本的数据集按照8∶2的比例划分为训练集和测试集。训练过程中,设置迭代次数(Epoch)为100,训练批次大小为4,学习率为0.001,卷积层中激活函数采用激活函数(Relu),输出层采用激活函数(Softmax)和交叉熵损失函数,优化算法为自适应矩估计算法,通过梯度下降的方式不断调整模型的参数,得到最优的2D-CNN预测模型,最终输出分类结果。其中,2D-CNN预测模型的结构和参数如表4所示。

表4 2D-CNN预测模型的结构和参数表
利用2D-CNN模型对钻井事故等级进行预测,预测模型主要由输入层、卷积层、池化层及全连接层构成,其模型的预测流程如图5所示。
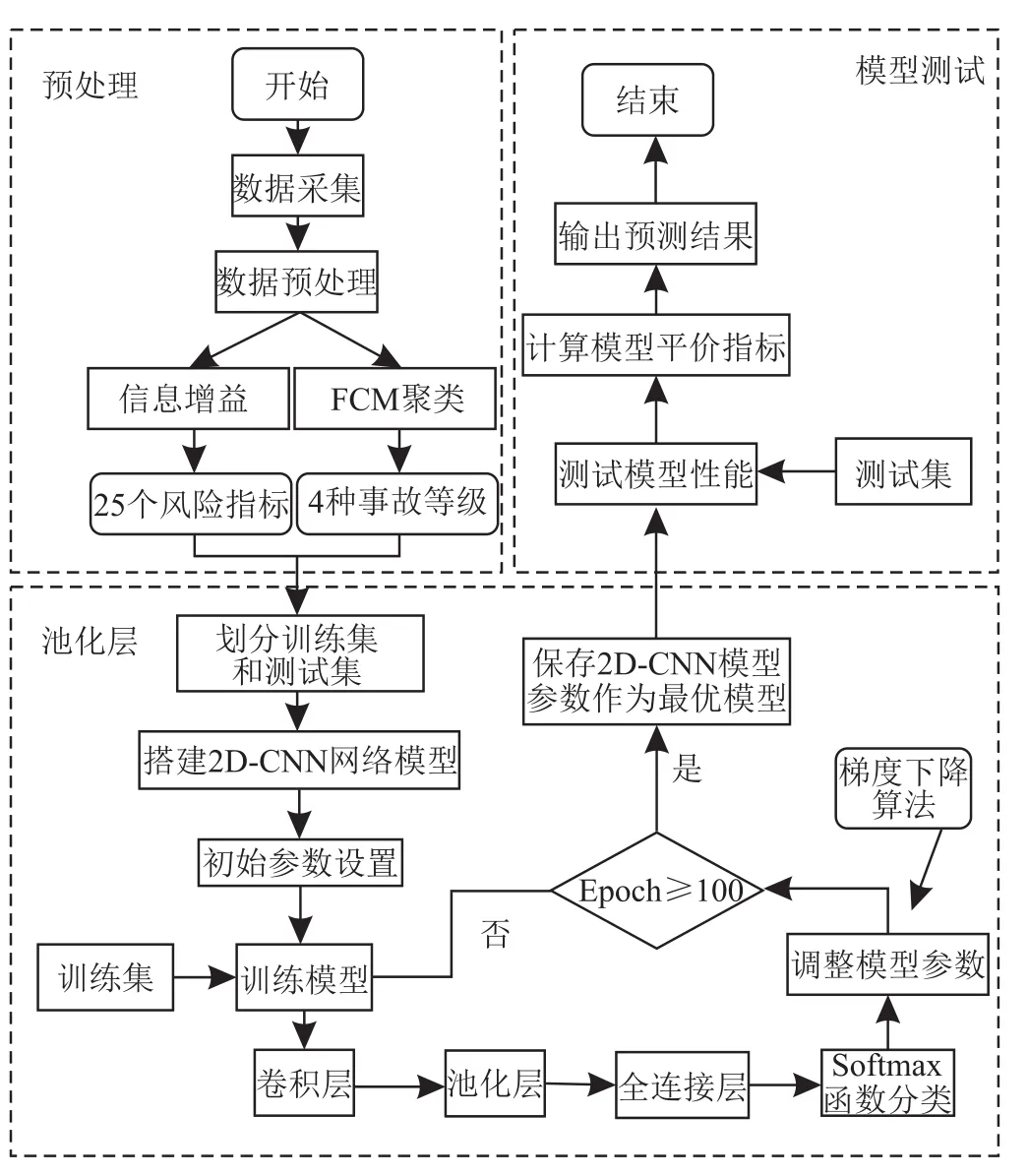
图5 基于2D-CNN模型的钻井事故预测流程图
基于2D-CNN的多维钻井事故预测模型的具体流程如下:①采用信息增益值和FCM聚类算法实现数据预处理,确定25个风险指标和4种钻井事故等级;再将输入数据划分为训练集和测试集,利用独热编码对测试集的事故等级进行数字化处理;②训练集对神经网络进行训练,通过2D-CNN模型的卷积层提取信息并学习事故特征,并采用BPTT算法将训练误差反向传播,不断更新模型参数;③利用Softmax函数得到事故等级的分类概率,为避免模型过拟合,通过梯度下降的方式不断调整模型的参数,得到预测模型的最优参数;④判断网络的迭代次数是否达到预先设定的100次,如果是,则运行下一步,否则重复第2步;⑤测试集验证已训练好的模型性能,计算评价指标,输出预测结果,则计算结束。
3.5 模型评价指标
笔者采用准确率(Accuracy)、灵敏度(Sensitivity)及特异性(Specificity)3种指标来评价预测模型的性能,并且用混淆矩阵详细地说明每种事故等级的分类结果。准确率是分类正确的事故等级占总测试样本的比例;灵敏性是正例中被分类正确的比例;特异性是负例中被分类正确的比例。其中,准确率是评价模型性能中最直观的指标,而灵敏度越高说明漏检的概率越小,特异性越高说明误诊率越小。则准确率、灵敏性及特异性的计算公式为:

式中F1、F2、F3分别表示评价预测模型的准确率、灵敏度及特异性;TP、FN分别表示正样本中被正确识别为正样本的数量,被错误识别为负样本的数量;TN、FP分别表示负样本中被正确识别为负样本的数量,被错误识别为正样本的数量。
3.6 实验结果对比分析
本文利用2D-CNN模型对钻井现场作业事故进行预测,将特征选择后的风险指标输入到模型中,经过卷积神经网络卷积层、池化层以及全连接层的操作后,通过Softmax函数得到各个样本的钻井事故等级的概率值,将概率较大的类别作为样本对应的事故等级,最终输出事故预测结果。采用训练集和测试集的损失和准确率来衡量预测效果的好坏,损失和准确率的变化曲线如图6所示。

图6 训练集和测试集的损失/准确率的变化曲线图
利用2D-CNN模型对钻井事故等级进行分类,当迭代次数达到60的时候,损失和准确率的整体曲线趋于平稳,测试集的准确率达到了91.67%,损失值为0.409,表明2D-CNN模型在钻井事故预测方面表现出较高的准确率。
表5为2D-CNN模型中分类结果的数量对应的混淆矩阵以及钻井事故等级的灵敏度、特异性以及总体的评判结果。结果表明2D-CNN模型的灵敏度为0.92,特异性为0.92。其中,一般事故、较大事故、特别重大事故的灵敏度和特异性均为1,因此不存在漏检和误诊的情况。

表5 2D-CNN模型分类结果表
为了进一步验证基于2D-CNN钻井事故预测模型的有效性,将其与BP神经网络模型和1D-CNN模型进行对比分析。采用Python软件的Keras模块,在不改变模型整体结构的同时,对模型的输入层进行修改,使其适用于钻井事故预测的多分类问题。采用相同的数据集对钻井事故等级进行预测,选取准确率、灵敏度以及特异性作为衡量预测效果的评价指标,不同预测模型的对比结果如表6所示。

表6 不同预测模型的评价指标比较表
由于1D-CNN模型和2D-CNN模型的准确率明显高于BP神经网络模型,说明卷积神经网络的卷积核能够较好地学习风险指标之间的特征,提取较为显著的指标进行预测,从而提高了钻井事故等级预测结果的准确性。最终根据表6实验结果可知,笔者建立的基于2D-CNN深度学习方法的钻井事故预测模型的准确率为0.917,灵敏度为0.918,特异性为0.915,均优于BP神经网络模型和1D-CNN模型,并且在测试集上的损失值最小。
根据图7不同模型钻井事故等级的实际情况与预测情况的对比结果,相比于其他模型,2D-CNN模型测试集上钻井事故等级的预测情况与实际事情整体变化趋势更加符合,存在误判的情况较少,说明该模型具有较好的预测能力,适用于钻井事故等级的预测。

图7 不同模型测试集上实际情况和预测情况对比图
4 结论与建议
本文提出一种新的基于2D-CNN深度学习算法的预测模型,解决了钻井安全事故等级预测的多分类问题,其预测结果对钻井作业现场作业的事故风险评价具有重要参考价值。基于本研究的结果,得出以下结论并提出相关建议。
1)采用FCM聚类算法对多种钻井事故类型进行分类,得到4种钻井事故等级,再通过信息增益值的大小排序对多维风险指标进行特征选择,确定了25个新的影响事故等级预测的风险指标,合理选择风险指标有利于提高钻井事故多分类的预测精度。
2)将双层2D-CNN深度学习方法应用于钻井事故等级预测,预测准确率为0.917,灵敏度为0.918,特异性为0.915,优于BP神经网络模型和1D-CNN模型,并且在测试集上损失值最小。由于2D-CNN模型具有较深的计算深度,提高了模型的预测精度,因此该模型适用于钻井事故等级预测的研究。
3)针对多维钻井数据的多分类问题,提出了基于2D-CNN的深度学习模型,在小样本量的钻井事故等级预测方面具有较好的准确性和有效性,而在样本量较大的预测问题中精度会得到明显的提高,因此该方法为样本量较大的多维钻井数据的事故预测研究提供了一种新的思路。
