融合动作特征的多模态情绪识别
2023-01-13孙亚男温玉辉舒叶芷刘永进
孙亚男,温玉辉,舒叶芷,刘永进
融合动作特征的多模态情绪识别
孙亚男,温玉辉,舒叶芷,刘永进
(清华大学计算机科学与技术系,北京 100084)
近年来,利用计算机技术实现基于多模态数据的情绪识别成为自然人机交互和人工智能领域重要的研究方向之一。利用视觉模态信息的情绪识别工作通常都将重点放在脸部特征上,很少考虑动作特征以及融合动作特征的多模态特征。虽然动作与情绪之间有着紧密的联系,但是从视觉模态中提取有效的动作信息用于情绪识别的难度较大。以动作与情绪的关系作为出发点,在经典的MELD多模态情绪识别数据集中引入视觉模态的动作数据,采用ST-GCN网络模型提取肢体动作特征,并利用该特征实现基于LSTM网络模型的单模态情绪识别。进一步在MELD数据集文本特征和音频特征的基础上引入肢体动作特征,提升了基于LSTM网络融合模型的多模态情绪识别准确率,并且结合文本特征和肢体动作特征提升了上下文记忆模型的文本单模态情绪识别准确率,实验显示虽然肢体动作特征用于单模态情绪识别的准确度无法超越传统的文本特征和音频特征,但是该特征对于多模态情绪识别具有重要作用。基于单模态和多模态特征的情绪识别实验验证了人体动作中含有情绪信息,利用肢体动作特征实现多模态情绪识别具有重要的发展潜力。
动作特征;情绪识别;多模态;动作与情绪;视觉模态
人类情绪往往能够影响其日常生活中的行为和表达方式。因此,利用计算机技术自动识别、理解和分析人类情绪并做出响应,建立和谐的人机交互环境,在提高交互效率和改善用户体验方面具有重要的应用价值[1-3]。然而,捕获和理解人类的情绪甚至是情绪模式十分困难[4]。
通过计算机进行情绪分析依赖于心理学相关研究提出的情绪模型理论,情绪表示主要有2种方法:连续维度表示和离散型表示[5]。其中,连续维度表示将情绪状态映射到一个连续的低维度(二维或三维)空间上。已有研究的经典代表是RUSSEL[6]提出的愉悦度-唤醒度(valence-arousal,VA)二维空间。任何情绪数据都可以表示为VA坐标系下的一个坐标点,代表其情绪的愉悦度和唤醒度。虽然此种表示方法能够细致地描述情绪分析结果,但是情绪标注过程较为复杂。在情绪分析上,应用连续维度表示的研究较少[7-9]。离散型表示更为常用,即将情绪状态定义为若干个类别。如,EKMAN[10]定义了人类的6种基本情绪,包括快乐、恐惧、愤怒、悲伤、厌恶和惊讶。
至今为止,国内外研究者在人类情绪分析方面做出了很多尝试,大致可以分为2类:①使用物理传感器设备采集心率和脑电图等生理信号[11-14]相关的数据,分析采集的数据并从中提取特定的情绪模式来检测情绪状态[15]。然而,此种方法往往需要用户佩戴额外的硬件设备;②随着人工智能技术的发展和广泛应用,对多媒体数据进行情绪分析引起了广泛的研究兴趣。除使用常见文本特征和音频特征外,越来越多的研究开始引入多媒体数据中视觉模态的信息,包括图像特征[16-17]和脸部特征[18-19]。
人类在日常生活中进行情绪识别往往基于不同模态的信息,包括脸部表情,语音语调和肢体动作等[20]。有研究表明肢体动作对情绪识别具有重要意义[21]。然而,基于多模态数据进行情绪分析的研究工作通常从文本或语音[22-24]以及从视频图像序列中提取的人脸表情[25-26]等特征中识别情绪。对于肢体动作和情绪识别的相关研究较少的主要原因是缺少带有肢体动作标注的情绪识别数据集。多模态情绪识别数据集(multimodal emotion lines dataset,MELD)[27]包含来自1 433段多方对话场景下的13 000多个文本单句。文本单句具有7种情绪标注(中性、快乐、恐惧、愤怒、悲伤、厌恶和惊讶),并且包括与文本相匹配的语音和视觉模态数据。
本文为MELD数据集添加了肢体动作数据作为新的模态特征研究基础,进而研究了视觉模态中的肢体动作特征在情绪识别任务中的作用。通过肢体动作特征在双向上下文长短期记忆网络(bi-directional contextual long short-term memory,bcLSTM)上的单模态实验结果,肢体动作特征、文本特征和音频特征融合的多模态特征在双向上下文长短期记忆网络上的多模态结果,以及肢体动作特征和文本特征融合的多模态特征在上下文记忆模型(context model with pre-trained memory,CoMPM)上的多模态实验结果,验证了视觉模态的肢体动作特征在情绪识别任务中的有效性。
1 相关工作
1.1 基于文本的情绪识别
作为最传统的多媒体形式,文本信息内含有大量与情绪相关的信息,文本特征单模态的识别效果远超音频特征单模态[27]和脸部特征单模态[28]。因为可以利用文本中丰富的情绪信息,基于文本的情绪识别相关工作出现最早且经久不衰,不断刷新情绪识别任务的准确率[29]。
LI等[30]提出将词汇表与基于机器学习的方法,如朴素贝叶斯和支持向量机(support vector machine,SVM)结合,可以用来检测难以被简单二分类的复杂情绪。还有一些利用深度卷积网络实现文档层面的情绪识别的工作[31],LI等[32]则在此基础上将卷积神经网络(convolutional neural network,CNN)与双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)网络结合,分别提取局部特征和长距离特征,以此提升模型基于文本的情绪识别能力。文献[29]则利用预训练语言模型结合上下文嵌入与前述记忆模块,实现对对话文本的情绪识别。以上研究工作只关注文本数据在单模态情绪识别的作用,本文进一步研究动作数据结合文本数据进行多模态情绪识别的有效性。
1.2 基于动作的情绪识别
许多研究表明,人们可以从非语言表达中分析情绪信息,并利用这些信息准确地推断他人的情绪状态[33-35]。目前,基于非语言表达的视觉模态信息的情绪识别工作大多只关注面部表情特征,然而面部表情特征的提取受限于图像数据质量,在面部图像分辨率较低的条件下无法成功捕获相应特征。
作为非语言表达的重要组成部分,动作与情绪之间的联系也十分紧密,一般来说,身体动作提供的线索比脸部细微的变化更容易被感知。文献[33-34]的研究证实了身体姿态有利于提高人们对情绪的感知力,而文献[35]的研究证明了人们可以根据他人的动态身体动作姿态对情绪进行适当的分类。这都说明基于身体动作的情绪识别研究具有较大的发展空间和潜力。基于动作的情绪识别工作通过研究全身或上半身的图像特征,以及从图像中提取的肢体动作特征与情绪状态之间的关系,提高情绪识别的准确率。根据特征提取的方式,基于动作的情绪识别可以分为2类:基于传统模式识别的方法和基于深度学习的方法。
基于传统模式识别的方法利用手工设计的特征进行情绪识别,如GLOWINSKI等[36]构建了使用与人体上半身运动有关的视觉信息进行情感行为分析的架构,提出基于动作特征得到一种与情绪有关的最简表达并用于情绪识别;而WANG等[37]实现了从身体运动中识别情绪的实时系统,主要包括在随机森林(random forest,RF)分类器的顶层加入了半监督的自适应算法,用于处理低维的3D姿态特征和高维的运动特征和几何特征组成的融合特征;SANTHOSHKUMAR等[38-39]提出使用SVM或随机森林分类器对方向梯度直方图(histogram of orientation gradient,HOG)和Kanade-Lucas-Tomasi方向梯度直方图(HOG-KLT)特征进行分类的情绪识别方法,随后又提出利用包含距离、角度和速度在内的身体运动特征进行识别的方法。此外,利用传感器采集的骨架关节点信息,RAZZAQ等[40]提取出身体关节的运动模式,得到了网格距离特征和网格角度特征并用于情绪识别。
基于深度学习的方法利用深度学习网络自动提取特征进行情绪识别。此类方法通常使用常见的姿态检测模型或底层特征提取方法预处理输入的数据,进而使用深度学习的方法进行预测。LY等[41]利用哈希方法从视频中提取关键帧,再使用卷积神经网络-长短期记忆网络(convolutional neural network-long short-term memory,CNN-LSTM)得到视频中序列信息隐含的情绪类别。SHEN等[42]则综合了通过光流法提取的RGB特征和通过时空图卷积网络(spatial temporal graph convolutional networks,ST-GCN)提取的骨架特征,使用残差全连接网络实现了基于动作的情绪识别。AVOLA等[43]提出了基于3D骨架和深度神经网络(deep neural network,DNN)的解决方法,结合动作的局部和全局的时间特征,可以识别非表演动作中的情绪。以上研究只关注动作数据在单模态情绪识别的作用,而本文进一步研究了动作数据对多模态情绪识别的提升。
1.3 多模态情绪识别
1.3.1 多模态情绪视频数据集
在日常生活中,人们通过多模态信息来传递以及理解情绪。表1展示了多模态情绪识别研究常用的视频数据集。交互式情绪运动捕捉数据库(interactive emotional dyadic motion capture database,IEMOCAP)[44]招募了10位专业演员录制使用剧本的脚本会话和基于假设场景的自发会话,并对手部和头部运动进行捕捉。而CreativeIT[45-46]则要求招募的16位专业演员佩戴专业设备对全身动作进行捕捉,录制内容包括既定文本和动词的两句话练习以及给定脚本的即兴演绎。随着社交媒体的发展,更多数据集尝试从社交网站大量的用户自录制视频中提取数据。多模态观点层面情绪强度数据集(multimodal opinion-level sentiment intensity dataset,MOSI)[47]收集了大量影评等用户自录制视频并赋予带有强度的情感类别标签。多模态观点情绪与情绪强度(multimodal opinion sentiment and emotion intensity,MOSEI)[43]包含情感类别标签和情绪类别标签,数据量大,人物多且表现自然。MELD[27]则从电视剧集中构建了一个带有情绪类别标签的多人对话数据集。

表1 多模态数据集综合对比
上述多模态数据集中,MOSI仅包含情感类别标签;MOSEI为单一人物独白类数据,画面中仅包含目标人物的头、脖子及肩膀;而IEMOCAP和CreativeIT均为实验室录制的数据集,人物数量较少,应用场景受限,且IEMOCAP仅在头部和手部有少量动作捕捉标记点,提取到的动作信息不完整,CreativeIT虽然使用了动作捕捉设备,但佩戴设备影响了演员动作的自然性。而从表现日常生活的情景喜剧中提取的MELD数据集不仅出场人物数量多,而且人物表现自然,动作更加生活化。此外,MELD数据集提供了原始视频,可用于提取视觉模态的特征。基于上述考虑,本文为MELD数据集添加肢体动作数据作为新的模态特征,并研究肢体动作特征、文本特征和音频特征的多模态特征在情绪识别任务中的作用。
基本离散情绪类别包含快乐、恐惧、愤怒、悲伤、厌恶和惊讶;连续情绪类别包含效价、激励和控制;情感类别包含积极、中性和消极3个分类。
1.3.2 多模态情绪识别方法
多模态情绪识别的关键在于模态信息的融合,根据融合的策略,大致可以分为3类:特征层面的融合、决策层面的融合和模型层面的融合。特征层面的融合直接对来自不同模态的特征进行融合,将其串成一个联合特征向量,再利用一个分类器进行识别,但是如果不同模态的特征在时间域存在较大差异,特征层面的融合表现较差;决策层面的融合先使用各个模态的信息分别进行预测,再将结果综合,无法更有效地利用不同模态融合对于情绪预测的优势;而模型层面的融合先分别使用模型处理各模态特征,再将不同模型得到的隐含层特征表示串联,之后进一步使用模型处理串联后的特征生成最终结果。
文献[16]结合了低维RNN的CNN网络、开源软件openSMILE和深度CNN网络分别提取视频特征、音频特征和文本特征,并使用特征子集选择(correlation-based eature selection,CFS)和主成分分析(principal components analysis,PCA)2种方法对特征进行提取并拼接融合,最终通过训练多核学习网络(multiple kernel learning,MKL)实现多模态情绪识别。而文献[18]将词嵌入得到的文本特征、MTCNN脸部检测得到的视频特征和COVAREP软件得到的音频特征输入动态融合图(dynamic fusion graph,DFG)模型,得到融合后的特征,利用图记忆融合网络(graph memory fusion network,graph-MFN)进行训练,在MOSI和MOSEI数据集上得到了较好的情感分析和情绪识别结果。随后,文献[19]提出了倍增的多模态情绪识别方法(multiplicative multimodal emotion recognition,M3ER),通过预训练的词嵌入得到文本特征,COVAREP软件得到音频特征,脸部识别模型得到视频特征,通过特征选择得到融合特征,再利用改进后的记忆融合网络(memory fusion network,MFN)进行情绪识别结果的预测。文献[17]使用text-CNN,openSMILE和3D-CNN分别提取文本、音频和视频特征,引入了上下文LSTM的变体分别提取与内容相关的各模态高层特征,将各模态特征拼接融合,并据此完成情感分析和情绪识别的任务。
相比于决策层面的融合,模型层面的融合对于各模态特征的融合更为充分,而相比于特征层面的融合,模型层面的融合不易受初始特征差异的影响。基于上述考虑,本文选择模型层面的融合方式实现多模态情绪识别。
2 方 法
本文在经典的MELD多模态数据集中添加动作特征,用于研究动作对情绪识别的作用。具体来说,首先通过OpenPose实现了基于视觉模态数据的肢体动作提取,利用时空图卷积网络得到骨架动作中的肢体运动特征作为视觉模态初始特征。之后通过基于LSTM的单模态情绪识别网络验证单模态初始特征下的结果。融合动作特征的多模态情绪识别任务采用模型层面的融合方法。首先,从单模态情绪识别网络中获得用于多模态情绪识别任务的不同模态的隐含层特征;再使用特征选择得到隐含层特征的最优子集;最后将特征选择得到的各模态隐含层特征拼接融合并在多模态情绪识别网络上进行训练和测试。
2.1 基于视觉模态数据的肢体动作提取
OpenPose是一种实时的多人2D姿态检测方法,由CAO等[48]于2019年提出。该方法使用自底向上的检测策略,首先识别出图中所有的关节点,再对关节点进行划分,以此实现多人人体骨架关节点的估计。该工作的核心是利用区域亲和力场(part affinity fields,PAF)实现关节点的匹配,PAF利用编码肢体位置和方向信息的2D向量场,将多人检测问题转化为二分图匹配问题,并用匈牙利算法求得相连关节点的最优匹配。
该方法在拥挤、尺度变换、物体遮挡和多人关联等真实世界的复杂场景下,都能较为准确的估计人体关节点的2D坐标。因此,许多下游任务均选择OpenPose实现图像数据中的骨架提取,本文也使用该方法提取视频中的肢体动作信息。
2.2 ST-GCN提取肢体动作特征
时空图卷积网络由YAN等[49]在2018年提出,该网络打破了传统的卷积方法需要依赖人工或遍历规则的局限性,可以自动从数据中学习空间和时间特性。模型对于每个关节,不仅考虑其在空间上的相邻关节,还考虑时间上的相邻关节,通过扩展时间邻域的概念,在动作分类任务中达到了较好的实验效果。
考虑到ST-GCN对于骨架动作的时间和空间特征都能较好地捕获,本文使用ST-GCN在Kinetics数据集上预训练好的模型处理视觉模态信息,提取肢体动作特征。Kinetics数据集包含大量不同种类的人体运动序列,大约有30万个序列,平均每个序列10 s左右。在该数据集上预训练的模型能够满足日常生活中大多数应用场景下的动作特征提取需求。
ST-GCN网络使用一个邻接矩阵表示单帧中的骨架内部关节点连接关系,使用一个单位矩阵表示单帧中关节点的自连接关系,则网络输出为


动作特征的提取流程如图1所示,对于一段原始视频,本文使用OpenPose从中提取人体骨架关节点信息,再利用串联在一起的9个时空图卷积单元进行计算,最后保留输入SoftMax层之前的向量作为后续实验的肢体动作特征。
2.3 特征选择
特征选择是多模态情绪识别任务中常用的方法,通过保留对识别结果更有帮助的特征,删去无关或冗余的特征,将初始特征集合简化为更易于处理的特征子集,实现对模态特征的降维。特征选择方法可根据优化策略分为3类:①过滤法(filter)按照特征发散性或相关性对特征进行整体评分,通过预设的阈值或待选择的特征个数对特征进行筛选;②嵌入法(embedded)需要结合机器学习的算法和模型识别结果,计算各个特征的权重,按权重大小选择特征;③包装法(wrapper)则是在初始特征集合上递归地修剪冗余或不重要的特征,直到获得最佳特征子集。
为了对多模态情绪识别任务中的肢体动作特征进行降维,本文选择包装法中较为典型的递归特征消除法(recursive feature elimination,RFE),一种寻找最优特征子集的贪心算法。RFE通过对肢体动作特征进行降维,实现了数据维度的缩减,高效利用了计算资源,使模型达到了更好的识别效果。
具体地,将原始肢体动作特征集合记为motion={|=1,2,···,}为特征数目,即每一样本具有600维初始特征,每一样本对应的情绪标签为。为尽可能保留原始特征,本文采用回归模型(linear regression model)作为特征消除法的基模型,记为M。具体步骤如下:
步骤1.随机初始化训练集的特征子集motion_subÌmotion。

图1 动作特征的提取流程

步骤4.重复步骤2和3,直至所有特征都经过基模型M验证,motion_sub即为最佳特征子集。
2.4 情绪识别网络
考虑到受数据集中数据质量的影响,脸部特征不易提取,故本文选择文本特征、音频特征和肢体动作特征进行情绪识别研究。
在提取初始特征时,使用1D-CNN网络提取文本特征;开源工具openSMILE提取音频特征;ST-GCN网络提取肢体动作特征。
在模型选择方面,本文首先使用了文献[17]提出的bcLSTM模型,该模型可以很好地保持非因果的时间动态特性[50],在处理多模态情绪识别任务中表现较好,且可扩展性强,可以较为便捷地扩展到其他模态。bcLSTM模型示意图如图2所示。
在单模态情绪识别任务中,bcLSTM模型对于文本模态使用CNN-LSTM网络对每句话对应的特征提取上下文相关的表示后加以训练,对于语音模态和视觉模态分别使用每句话对应的音频特征向量和肢体动作特征向量输入LSTM模型进行情绪识别。
在多模态情绪识别任务中,bcLSTM模型使用双向RNN网络对内容进行处理,采用两步递阶过程进行训练。首先取得前述单模态任务中各模态用于分类的隐含层特征向量,再依照2.3节描述的特征选择方法将从视觉模态中提取的隐含层特征样本集从高维特征空间映射到低维特征空间,最后将各模态特征拼接融合,应用于多模态情绪识别任务。

图2 bcLSTM模型结构图
此外,为了进一步验证视觉模态的肢体动作特征可以提升情绪识别任务的准确率的结论,本文选择了基于MELD数据集的情绪分类任务中效果最好的开源模型CoMPM,对其添加肢体动作特征进行多模态情绪识别。
CoMPM是由文献[29]在2021年提出的基于自然语言处理方法进行情绪识别的模型,主要包含2个模块:上下文嵌入模块(context modeling,CoM)和预训练记忆模块(pre-trained memory,PM)。上下文嵌入模块用于捕捉所有先前话语对当前说话者情绪的潜在影响,而预训练记忆模块仅利用当前说话者的前述话语作为先验知识进行预测。在此基础上,本文为模型添加了动作特征提取模块,使用LSTM网络对输入的肢体动作特征向量进行特征提取。最终将3个模块的输出特征综合后进行多模态情绪识别。改进后的CoMPM模型示意图如图3所示。
对于CoM模块,使用特殊符号

在PM模块中,使用

图3 改进的CoMPM模型结构图
Fig. 3 Structure of improved CoMPM model
在动作特征提取模块中,输入为当前话语对应的视频段落v,首先通过LSTM模型得到高维特征,再通过特征选择和全连接层,得到对应输出m。融合后的输出向量为各模块的输出之和,即

其中,kt为PM模块各句输出通过追踪模块后的输出。
最终的情绪识别结果通过在输出向量与线性矩阵的点积上使用SoftMax函数得到,即

3 实 验
3.1 数据预处理
本文使用了多人情绪数据集MELD,该数据集包含1 433段对话和超过13 000个句子,提供包括话语、说话人物、时长、对应视频、情感标签和情绪标签在内的信息。数据集内的情感标签分为积极、中性和消极3类,而情绪标签则分为快乐、恐惧、愤怒、悲伤、厌恶、惊讶和中性共7类。
MELD数据集是从美剧《老友记》中截取的部分情节片段。构建数据集时首先将剧中对话以句子为单位进行切割,根据场景变化对属于不同场景的句子划分到不同对话段中,随后召集3位标注人员对每句话进行情绪标注,丢弃3位标注者的情绪标签不一样的数据,以此构建了多模态情绪数据集MELD。由于数据集中存在完全不包含人物的片段以及长度不超过5帧的片段,考虑到本文的工作重点集中在与肢体动作特征有关的情绪识别上,所以对数据集进行筛选,去除上述不符合要求的片段。
筛选后的数据集共包含1 381段对话,其中训练集1 004段,验证集109段,测试集272段。筛选后的数据集内各情绪类别样本分布如图4所示,可以发现恐惧和厌恶情绪对应的样本比较少,这是因为《老友记》是一部经典的系列情景喜剧,主要展现几位主演在友谊、爱情、事业乃至家庭等问题上的喜怒哀乐,能体现恐惧和厌恶情绪的场景较少,故对应的样本也相对不足。
3.2 实验设置
3.2.1 计算环境
本节使用基于tensorflow2.9和CUDA 10.2搭建的实验环境训练并评估模型在MELD数据集上的表现。模型在一张24 G内存的Nvidia TITAN RTX显卡上进行训练。
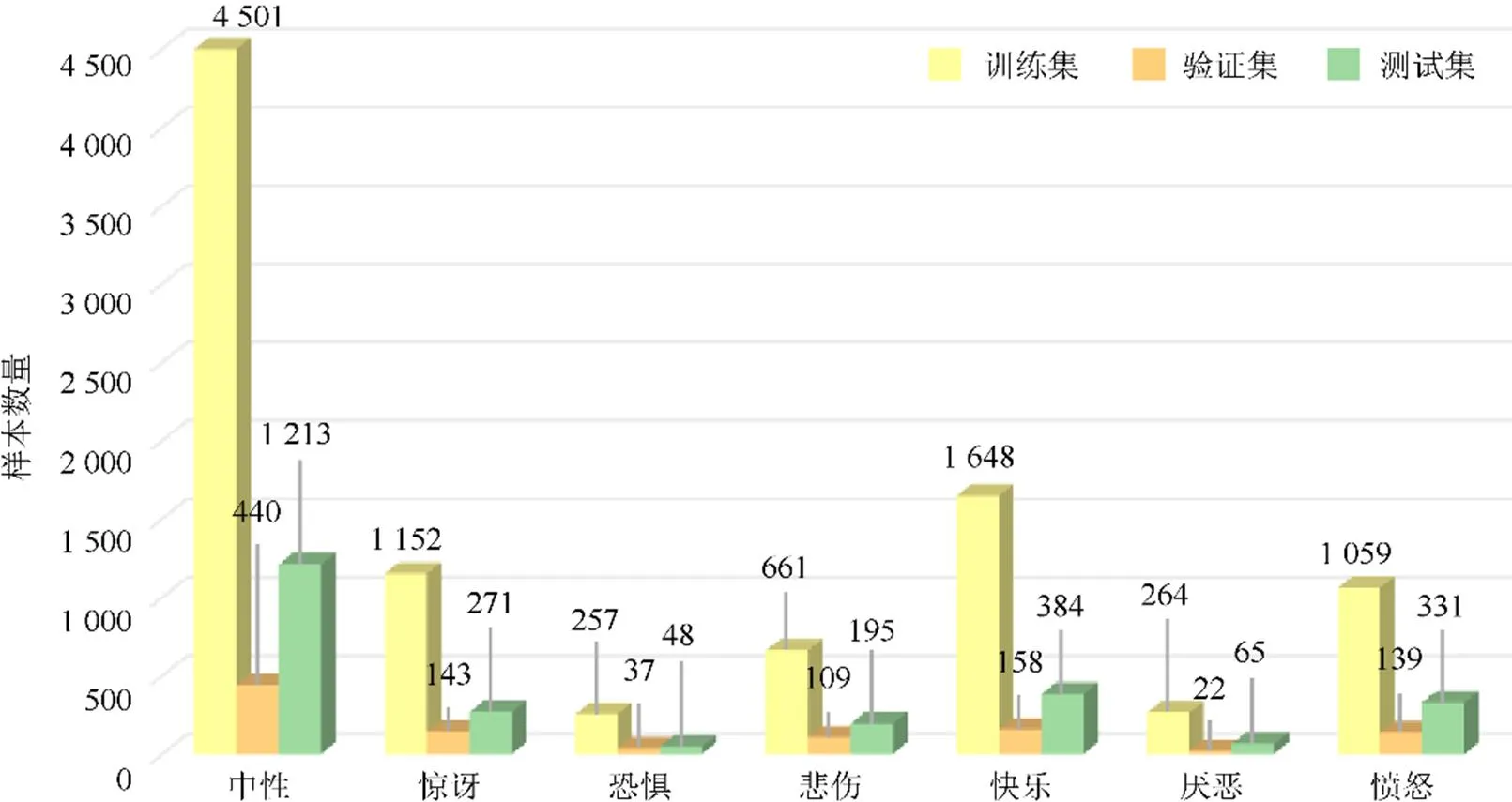
图4 各情绪类别样本分布
3.2.2 特征提取
在提取初始特征时,对于文本模态,使用一个预训练的300维GloVe向量初始化每个词并使用1D-CNN网络提取100维的文本特征。对于语音模态,本节使用开源工具openSMILE提取到由底层描述符和多种声音和韵律特征组成的6 373维特征,并采用基于L2的特征选择方法对音频特征进行降维处理。
对于视觉模态,首先使用OpenPose提取画面内人体18个骨架关节点的信息,OpenPose得到的信息可以视作一个包含二维坐标及其置信概率的三元组。对于多人场景下目标人物的处理,ST-GCN采用选取关节平均置信概率最高的两个人的策略,但由于本文使用的数据中目标人物通常处于前景,与背景人物相比存在下半身关节点的缺失,若仅根据关节平均置信概率存在误判的情况,且绝大多数多人场景中的对话发生在2个主要人物之间。因此,本文选择一定平均置信概率以上的人物中2个肩关节点距离最大的人物。而为了排除单目标人物场景下背景人物的干扰,根据经验,对于选取的2个人物中肩宽差距在3倍以上的,只保留肩宽较大的人物,以排除无关人物对结果的干扰。
一段多人物的视频片段在根据上述策略处理后可表示为一个(帧数,人物数,关节点数,关节点坐标及置信概率)的张量,其中人物数为1或2。使用ST-GCN网络对该张量进行计算,并提取输入SoftMax层前的向量,得到每个人物关节点在每4帧内对应的肢体动作特征,则每个视频片段可以表示为一个(帧数/4,人物数,关节点数,256)的肢体动作特征,再对肢体动作特征在帧和关节点维度上取平均值,则每个视频片段提取到一个维度为(人物数,256)的肢体动作特征。对于人物数为1的视频片段,采用将单一人物特征重复2遍的方式使维度对齐。最后将动作特征张量扁平化,得到每个视频片段对应的512维的肢体动作特征。
3.2.3 评估指标
本节使用准确度(accuracy)和各情绪分类的1得分的加权平均(weighted-avg)评估整体识别结果,使用各分类的1分数评估各类别的识别结果。准确度定义为

1分数定义为

其中,
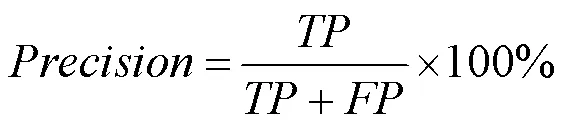

其中,为测试中的真正例数;为假正例数;为真反例数;为假反例数。
3.3 基于肢体动作特征的情绪识别
在更新后的MELD数据集上按照3.2节描述的实验设置进行训练和测试,得到单模态情绪识别结果。表2展示了分别使用肢体动作特征、音频特征和文本特征,对快乐、恐惧、愤怒、悲伤、厌恶、惊讶和中性7类情绪类别进行单模态情绪识别的实验结果。

表2 单模态情绪识别实验结果(%)
从表2可知,文本模态特征用于情绪分类任务的效果最好,加权平均得分超过了55%,这是因为其包含的内容最为丰富,且较为统一,易被模型学习。实验结果表明语言文字在情绪识别中有重要作用。语音模态特征具有独特性,即不同的人在以相同情绪讲相同内容的话时,语音语调也存在差异。该特性加大了模型学习的难度,导致语音模态特征的分类结果准确度低于文本模态特征。虽然人讲话时的肢体动作中包含了对应的情绪信息,但相较于前2种模态特征,从视频中提取对应的信息具有其固有的难点:首先需要排除画面中无关人物的干扰,对说话人进行精准的定位;其次,根据WALTERS和WALK[51]对动作和情绪之间关系的研究,部分情绪,如快乐、悲伤和愤怒,在肢体动作上的表现更为明显,而厌恶等情绪在动作上的表现幅度较小。这些因素都加大了从动作中捕捉关键情绪信息的难度。尽管如此,单模态情绪识别实验结果显示,仅使用肢体动作特征也可以在一定程度上完成情绪识别任务,表明肢体动作特征内隐含人物情绪信息,使用肢体动作特征识别情绪的方法具有一定潜力。
加权平均是由各分类的1分数结合类别权重计算得到。
3.4 多模态情绪识别
按照3.2节描述的实验设置,在更新后的MELD数据集上分别使用2个模型进行训练和测试,得到多模态情绪识别结果。表3展示了在bcLSTM模型中使用文本、语音双模态信息和文本、语音、视觉三模态信息,以及在CoMPM模型中使用文本信息和文本、视觉双模态信息对快乐、恐惧、愤怒、悲伤、厌恶、惊讶和中性7类情绪类别进行识别的结果。
分析表3数据可发现,恐惧与厌恶2种情绪的识别结果较差,其原因是数据集内各类别数据分布的不平衡。从图4中可以看出:超过45%的例子均为中性标签。尽管在bcLSTM模型中通过引入类别权重作为超参数适当解决了这一问题,但图5的2种模型中多模态情绪识别的混淆矩阵可以看出,模型在学习过程中倾向于赋予中性情绪类别更高的权重,其他类别中分类错误的例子大多被误判为中性类别。

表3 多模态情绪识别实验结果对比(%)
注:加粗数据为最优值

图5 多模态情绪识别结果的混淆矩阵((a) bcLSTM模型;(b) CoMPM模型)
此外,从表3可以看出,引入肢体动作特征后多模态情绪识别结果中各情绪准确率的变化方向不同,是因为不同的情绪在肢体动作上体现的程度不同。惊讶和开心情绪的识别准确率在2种模型上均有所下降,是因为这2类情绪更多体现在文本或声音的变化中,在肢体动作中的表现幅度较小,融合肢体动作特征后引入了无关冗余特征,造成了准确率的下降。但在生气和厌恶这2类情绪中,肢体动作表现幅度较大,引入肢体动作特征可以为模型提供更多信息,故而在2种模型上的对应情绪识别准确率均有所上升。
综合表3中各分类和总体结果来看,在bcLSTM模型中,三模态信息融合后的情绪识别结果与双模态信息融合后的结果,在准确度上高出2.2%,在加权平均上高出1%。而在CoMPM模型中,双模态信息融合后的情绪识别结果与文本模态的结果相比,在准确度上高出1.9%,在加权平均上高出1.3%。在2个模型上的对比实验结果表明引入肢体动作特征的多模态情绪识别模型比原有模型表现更好,说明从视觉模态提取的肢体动作特征包含原有各模态特征未捕捉到的信息。融合后的多模态模型涵盖了更丰富的相关特征,因此加强了模型识别对话中情绪的能力。
4 结束语
本文利用多人对话数据集MELD的视觉模态数据提取肢体动作特征,并提出了融合动作特征的多模态情绪识别方法。进一步通过实验验证肢体动作特征及包含该特征在内的多模态特征在情绪识别任务中的识别效果。从实验结果可知,利用肢体动作特征能实现一定程度上的情绪识别,而引入肢体动作特征辅助的多模态情绪识别的效果也得到了提升,表明肢体动作特征在情绪识别任务上具有良好的发展潜力。通过具体分析各情绪分类识别结果,进一步发现不同情绪在动作特征中的体现程度不同,生气和厌恶2类情绪在动作中体现的更为明显,表明对特定情绪(如愤怒)的识别准确度要求更高的场合,引入动作特征能更有效准确地识别对应情绪。下一步工作将尝试优化肢体动作特征提取方法,使其能够更精准地捕捉到说话人的肢体动作信息,并挖掘更有效的利用肢体动作特征实现情绪识别的方法。
[1] DAVIDSON R J, BEGLEY S. The emotional life of your brain: how its unique patterns affect the way you think, feel, and live-and how you can change them[M]. New York: Plume, 2013: 1-279.
[2] LOEWENSTEIN G, LERNER J. The role of affect in decision making[M]//The Handbook of Affective Science. Oxford: Oxford University Press, 2003: 619-642.
[3] NOROOZI F, CORNEANU C A, KAMIŃSKA D, et al. Survey on emotional body gesture recognition[J]. IEEE Transactions on Affective Computing, 2021, 12(2): 505-523.
[4] ZHAO J, GOU L, WANG F, et al. PEARL: an interactive visual analytic tool for understanding personal emotion style derived from social media[C]//2014 IEEE Conference on Visual Analytics Science and Technology. New York: IEEE Press, 2014: 203-212.
[5] CALVO R A, MAC KIM S. Emotions in text: dimensional and categorical models[J]. Computational Intelligence, 2013, 29(3): 527-543.
[6] RUSSELL J A. A circumplex model of affect[J]. Journal of Personality and Social Psychology, 1980, 39(6): 1161-1178.
[7] BRADLEY M M, LANG P J. Measuring emotion: the self-assessment manikin and the semantic differential[J]. Journal of Behavior Therapy and Experimental Psychiatry, 1994, 25(1): 49-59.
[8] PALTOGLOU G, THELWALL M. Seeing stars of valence and arousal in blog posts[J]. IEEE Transactions on Affective Computing, 2013, 4(1): 116-123.
[9] PALTOGLOU G, THEUNIS M, KAPPAS A, et al. Predicting emotional responses to long informal text[J]. IEEE Transactions on Affective Computing, 2013, 4(1): 106-115.
[10] EKMAN P. An argument for basic emotions[J]. Cognition and Emotion, 1992, 6(3-4): 169-200.
[11] SARKAR P, ETEMAD A. Self-supervised ECG representation learning for emotion recognition[J]. IEEE Transactions on Affective Computing, 2022, 13(3): 1541-1554.
[12] ALARCÃO S M, FONSECA M J. Emotions recognition using EEG signals: a survey[J]. IEEE Transactions on Affective Computing, 2019, 10(3): 374-393.
[13] COUTINHO E. Predicting musical emotions from low-level acoustics and physiological measurements: music and speech[EB/OL]. [2022-05-07]. https://livrepository.liverpool.ac. uk/3000588/1/Paper_MER.pdf.
[14] PETRANTONAKIS P C, HADJILEONTIADIS L J. Emotion recognition from brain signals using hybrid adaptive filtering and higher order crossings analysis[J]. IEEE Transactions on Affective Computing, 2010, 1(2): 81-97.
[15] CHANEL G, ANSARI-ASL K, PUN T. Valence-arousal evaluation using physiological signals in an emotion recall paradigm[C]//2007 IEEE International Conference on Systems, Man and Cybernetics. New York: IEEE Press, 2007: 2662-2667.
[16] PORIA S, CHATURVEDI I, CAMBRIA E, et al. Convolutional MKL based multimodal emotion recognition and sentiment analysis[C]//2016 IEEE 16th International Conference on Data Mining. New York: IEEE Press, 2016: 439-448.
[17] PORIA S, CAMBRIA E, HAZARIKA D, et al. Context- dependent sentiment analysis in user-generated videos[C]//The 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: Association for Computational Linguistics, 2017: 873-883.
[18] BAGHER ZADEH A, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]//The 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg: Association for Computational Linguistics, 2018: 2236-2246.
[19] MITTAL T, BHATTACHARYA U, CHANDRA R, et al. M3ER: multiplicative multimodal emotion recognition using facial, textual, and speech cues[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(2): 1359-1367.
[20] NOROOZI F, CORNEANU C A, KAMIŃSKA D, et al. Survey on emotional body gesture recognition[J]. IEEE Transactions on Affective Computing, 2021, 12(2): 505-523.
[21] JAIMES A, SEBE N. Multimodal human-computer interaction: a survey[J]. Computer Vision and Image Understanding, 2007, 108(1-2): 116-134.
[22] EL AYADI M, KAMEL M S, KARRAY F. Survey on speech emotion recognition: features, classification schemes, and databases[J]. Pattern Recognition, 2011, 44(3): 572-587.
[23] YANG Y H, CHEN H H. Ranking-based emotion recognition for music organization and retrieval[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(4): 762-774.
[24] KARADOĞAN S G, LARSEN J. Combining semantic and acoustic features for valence and arousal recognition in speech[C]//2012 3rd International Workshop on Cognitive Information Processing . New York: IEEE Press, 2012: 1-6.
[25] LIN J C, WU C H, WEI W L. Error weighted semi-coupled hidden Markov model for audio-visual emotion recognition[J]. IEEE Transactions on Multimedia, 2012, 14(1): 142-156.
[26] HEISELE B, HO P, POGGIO T. Face recognition with support vector machines: global versus component-based approach[C]// The 8th IEEE International Conference on Computer Vision. New York: IEEE Press, 2001: 688-694.
[27] PORIA S, HAZARIKA D, MAJUMDER N, et al. MELD: a multimodal multi-party dataset for emotion recognition in conversations[EB/OL].[2022-05-20]. https://arxiv.org/abs/1810. 02508.
[28] XIE B J, SIDULOVA M, PARK C H. Robust multimodal emotion recognition from conversation with transformer-based crossmodality fusion[J]. Sensors, 2021, 21(14): 4913.
[29] LEE J, LEE W. CoMPM: context modeling with speaker's pre-trained memory tracking for emotion recognition in conversation[EB/OL]. [2022-06-15]. https://arxiv.org/abs/2108. 11626.
[30] LI D, RZEPKA R, PTASZYNSKI M, et al. A novel machine learning-based sentiment analysis method for Chinese social media considering Chinese slang lexicon and emoticons[C]//The 2nd Workshop on Affective Content Analysis (AffCon 2019) Co-located with 33rd AAAI Conference on Artificial Intelligence (AAAI 2019). Palo Alto: AAAI Press, 2019: 88-103.
[31] LIU F G, ZHENG L L, ZHENG J Z. HieNN-DWE: a hierarchical neural network with dynamic word embeddings for document level sentiment classification[J]. Neurocomputing, 2020, 403: 21-32.
[32] LI W, ZHU L Y, SHI Y, et al. User reviews: sentiment analysis using lexicon integrated two-channel CNN-LSTM family models[J]. Applied Soft Computing, 2020, 94: 106435.
[33] COULSON M. Attributing emotion to static body postures: recognition accuracy, confusions, and viewpoint dependence[J]. Journal of Nonverbal Behavior, 2004, 28(2): 117-139.
[34] TRACY J L, ROBINS R W. Show your pride: evidence for a discrete emotion expression[J]. Psychological Science, 2004, 15(3): 194-197.
[35] DAEL N, GOUDBEEK M, SCHERER K R. Perceived gesture dynamics in nonverbal expression of emotion[J]. Perception, 2013, 42(6): 642-657.
[36] GLOWINSKI D, DAEL N, CAMURRI A, et al. Toward a minimal representation of affective gestures[J]. IEEE Transactions on Affective Computing, 2011, 2(2): 106-118.
[37] WANG W Y, ENESCU V, SAHLI H. Adaptive real-time emotion recognition from body movements[J]. ACM Transactions on Interactive Intelligent Systems, 2016, 5(4): 18.
[38] SANTHOSHKUMAR R, KALAISELVI GEETHA M. Vision-based human emotion recognition using HOG-KLT feature[M]//Lecture Notes in Networks and Systems. Singapore: Springer Singapore, 2020: 261-272.
[39] SANTHOSHKUMAR R, KALAISELVI GEETHA M. Human emotion recognition using body expressive feature[M]// Microservices in Big Data Analytics. Singapore: Springer Singapore, 2019: 141-149.
[40] RAZZAQ M A, BANG J, KANG S S, et al. UnSkEm: unobtrusive skeletal-based emotion recognition for user experience[C]//2020 International Conference on Information Networking. New York: IEEE Press, 2020: 92-96.
[41] LY S T, LEE G S, KIM S H, et al. Emotion recognition via body gesture: deep learning model coupled with keyframe selection[C]//The 2018 International Conference on Machine Learning and Machine Intelligence. New York: ACM Press, 2018: 27-31.
[42] SHEN Z J, CHENG J, HU X P, et al. Emotion recognition based on multi-view body gestures[C]//2019 IEEE International Conference on Image Processing. New York: IEEE Press, 2019: 3317-3321.
[43] AVOLA D, CINQUE L, FAGIOLI A, et al. Deep temporal analysis for non-acted body affect recognition[J]. IEEE Transactions on Affective Computing, 2022, 13(3): 1366-1377.
[44] BUSSO C, BULUT M, LEE C C, et al. IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42(4): 335-359.
[45] METALLINOU A, LEE C C, BUSSO C, et al. The USC CreativeIT database: a multimodal database of theatrical improvisation[J]. Multimodal Corpora: Advances in Capturing, Coding and Analyzing Multimodality, 2010: 497-521.
[46] METALLINOU A, YANG Z J, LEE C C, et al. The USC CreativeIT database of multimodal dyadic interactions: from speech and full body motion capture to continuous emotional annotations[J]. Language Resources and Evaluation, 2016, 50(3): 497-521.
[47] ZADEH A, ZELLERS R, PINCUS E, et al. MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos[EB/OL]. [2022-06-10]. https://arxiv.org/ abs/1606.06259.
[48] CAO Z, SIMON T, WEI S H, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1302-1310.
[49] YAN S J, XIONG Y J, LIN D H. Spatial temporal graph convolutional networks for skeleton-based action recognition[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 1.
[50] LEE J, TASHEV I. High-level feature representation using recurrent neural network for speech emotion recognition[C]// Interspeech 2015. Baixas: International Speech Communication Association, 2015: 1.
[51] WALTERS K, WALK R D. Perception of emotion from body posture[J]. Bulletin of the Psychonomic Society, 1986, 24(5):1.
Multimodal emotion recognition with action features
SUN Ya-nan, WEN Yu-hui, SHU Ye-zhi, LIU Yong-jin
(Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China)
In recent years, using knowledge of computer science to realize emotion recognition based on multimodal data has become an important research direction in the fields of natural human-computer interaction and artificial intelligence. The emotion recognition research using visual modality information usually focuses on facial features, rarely considering action features or multimodal features fused with action features. Although action has a close relationship with emotion, it is difficult to extract valid action information from the visual modality. In this paper, we started with the relationship between action and emotion, and introduced action data extracted from visual modality to classic multimodal emotion recognition dataset, MELD. The body action features were extracted based on ST-GCN model, and the action features were applied to the LSTM model-based single-modal emotion recognition task. In addition, body action features were introduced to bi-modal emotion recognition in MELD dataset, improving the performance of the fusion model based on the LSTM network. The combination of body action features and text features enhanced the recognition accuracy of the context model with pre-trained memory compared with that only using the text features. The results of the experiment show that although the accuracy of body action features for emotion recognition is not higher than those of traditional text features and audio features, body action features play an important role in the process of multimodal emotion recognition. The experiments on emotion recognition based on single-modal and multimodal features validate that people use actions to convey their emotions, and that using body action features for emotion recognition has great potential.
action features; emotion recognition; multimodality; action and emotion; visual modality
TP 391
10.11996/JG.j.2095-302X.2022061159
A
2095-302X(2022)06-1159-11
2022-07-28;
:2022-10-15
清华大学自主科研计划(20211080093);博士后面上资助(2021M701891);国家自然科学基金(62202257,61725204)
孙亚男(1997-),女,硕士研究生。主要研究方向为计算机视觉。E-mail:sunyn20@mails.tsinghua.edu.cn
刘永进(1977-),男,教授,博士。主要研究方向为计算机图形学、计算机辅助设计和情感计算。E-mail:liuyongjin@tsinghua.edu.cn
28 July,2022;
15 October,2022
Tsinghua University Initiative Scientific Research Program (20211080093); China Postdoctoral Science Foundation (2021M701891); National Natural Science Foundation of China (62202257, 61725204)
SUN Ya-nan (1997-), master student. Her main research interest covers computer vision. E-mail:sunyn20@mails.tsinghua.edu.cn
LIU Yong-jin (1977-), professor, Ph.D. His main research interests cover computer graphics, computer aided design and affective computing. E-mail:liuyongjin@tsinghua.edu.cn
