几何引导的主动式三维感知与交互
2023-01-13胡瑞珍
徐 凯,胡瑞珍,杨 鑫
几何引导的主动式三维感知与交互
徐 凯,胡瑞珍,杨 鑫
(1. 国防科技大学计算机学院,湖南 长沙 410073; 2. 深圳大学计算机与软件学院,广东 深圳 518060; 3. 大连理工大学电信学部,辽宁 大连 116000)
随着三维感知设备的发展和大规模三维数据的出现,基于三维重建与理解的视觉感知技术得到了大量关注。与此同时,智能图形逐渐改变了传统图形系统在交互中的被动角色,朝着任务引导的、感知驱动的智能体对真实或虚拟环境的主动交互发展。可以说,计算机图形学正在突破“信息表达”这一传统范畴,逐步拓展迈入“信息感知”领域;图形学的交互技术也由传统的人机交互,逐渐延伸和发展出面向智能任务的主动三维交互。其中,数据驱动三维几何分析与建模的理论和方法,特别是在线重建与分析技术,对三维感知和三维交互形成了重要支撑。本文从图形学和视觉融合的视角,结合研究案例,介绍了主动式三维感知与交互,讨论了“主动式”的特点、优势和挑战,并试图探讨这一方向的开放问题与发展趋势。
几何引导;三维感知与交互;主动感知与交互
传统意义上讲,计算机图形学一般被认为是计算机视觉的逆过程(图1(a)):前者聚焦于真实对象的三维表达与呈现;后者则研究从视觉信息推断客观对象。近年来,随着视觉传感设备的迅猛发展和大规模可视数据的爆炸式增长,上述认知正在发生深刻变化。三维传感设备的精准化、实时化和低成本化,极大推动了三维数据获取的发展和普及。因此,基于三维传感数据的视觉技术应运而生。与传统的二维视觉相比,三维输入提供了目标环境或对象的位姿、几何、拓扑、结构等信息,极大丰富了感知素材,提高了感知能力。
三维几何的重建[1]、处理[2]和分析[3-4]一直是图形领域的重要研究方向。海量三维数据的涌现使得数据驱动的三维感知成为可能。通过对大规模三维数据集进行联合分析,学习三维几何的表征,挖掘三维结构的先验知识,以支持在线化、结构化、语义化的三维感知(如三维对象或场景的建模和理解)[5-6]。三维感知结果可直接支持三维空间规划和推理,以驱动智能体与环境或对象的三维交互(例如机器人环境导航和对象抓取)。图1(b)展示了基于数据驱动的几何分析与理解对三维感知与交互的支撑。

图1 传统意义的图形学与数据驱动时代的图形学之间的区别((a)传统意义图形学与视觉;(b)融合三维视觉和智能图形学的三维感知与交互)
交互技术原本就是计算机图形学的重要组成部分。传统意义上讲,图形学的交互主要面向人机交互:交互的主体是人,交互对象一般是由图形学合成的虚拟环境或对象。人机交互系统通过向用户呈现信息和理解用户输入,在信息空间和人的意识、意图之间建立沟通。显然,传统的图形交互系统并不能驱动交互主体,只能被动理解交互意图并为交互主体提供反馈。面向机器人应用,智能图形系统将突破传统图形在交互中的被动角色,以智能任务为牵引,以智能感知为驱动,让智能体在真实或虚拟环境中完成对目标对象的交互,包括交互对象的感知、交互策略的学习、交互方式的优化、交互结果的反馈等等。因此,本文涉及的“主动交互”主要体现了智能图形系统在交互中的角色,突出对智能体的主动交互引导,以区别于传统人机交互的被动交互理解。
因此,计算机图形学研究正在突破“信息表达”这一传统范畴,逐步拓展迈入“信息感知”领域。图形交互技术也由传统的人机交互,逐渐延申至任务的智能体主动三维交互。以数据驱动三维几何分析与建模的理论和方法,对三维感知形成重要支撑,并以此引导智能体与环境的三维交互。与此同时,图形学与视觉、人工智能的深度融合,引入基于三维几何的视觉感知新问题、新方法、新理论,将延伸和拓展图形学的学科内涵和应用范畴,促进学科的交叉融合,推动技术的实际应用。
本文聚焦于三维几何信息引导的主动感知与交互技术,以数据驱动方法为基础,以智能机器人应用为落脚点,探讨该方向的重要研究问题,介绍作者在该方向的研究案例,并尝试讨论未来趋势和挑战。
1 三维感知与三维交互
1.1 感知与交互的内涵与关联
感知(perception)是外界刺激作用于感官时,脑对外界整体的看法和理解,为人们对外界的感官信息进行组织和解释。认知科学包括获取信息、理解信息、筛选信息、组织信息。以智能体为载体,其获取的信息主要是三维空间的颜色、深度等视觉信息,而在感知过程中如何对这些信息进行理解、筛选、组织就显得尤为重要。在计算图形学领域,三维感知的最终目标可以看成是对三维场景的结构化语义重建,即在对三维场景的几何、结构、语义等多层次信息进行有效提取的前提下进行深度融合与组织,为后续的其他任务所服务。
交互(interaction)是2个对象之间的交流互动,而本文特指的交互对象是智能体与三维环境。人类的日常活动往往是通过与周围环境中的三维物体进行交互实现的,因此,为了让计算机模拟人的思维过程和智能行为,引导智能体与三维环境进行类人交互是其中极其重要的一个环节。具体地,计算图形学领域目前所研究的智能体与三维环境的交互主要包括了智能体在三维空间中的路径导航、对于三维物体的触碰、抓取等方面的探索与优化。
智能感知与智能交互的关联性在认知科学中有很好的对应和解释[7]。智能感知对应于认知科学的“构造式感知”。传感器获取的信息往往具有片面性、间接性和模糊性,需要借助知识和推理来补充和校正获取信息中的不完整和不准确部分。智能交互可类比于认知科学中的“注意力机制”[8],即目标导向的主动式感知和交互过程:面向特定任务,智能体基于在线获取的感知信息和预先习得的先验知识,完成目标环境的理解和任务相关的推理,引导智能体与环境交互来完成任务;同时,以环境理解程度和任务完成状态为驱动,引导智能体进一步的信息感知。因此,智能感知与交互是以感知引导交互,以交互驱动感知,在目标任务导向下感知和交互交替执行、相互推进的过程。
1.2 三维感知与三维交互的内涵
通过构建目标环境的三维表达在感知与交互之间形成关联和互动。由于机器人与对象或环境的交互发生在三维空间,构建目标物体或场景的三维几何表示对三维交互尤为重要,可以类比于人类在大脑中对物体构建的形状恒常性(shape constancy,类似于形状不变性)[9],以及对环境构建的认知地图(cognitive map)[10]。这也解释了为什么基于三维信息的导航和抓取已逐渐成为当前机器人交互研究的主流趋势。如,融合LiDAR和深度信息的视觉系统,在各类机器人、无人车、无人机上已经非常普遍;亚马逊抓取挑战赛(Amazon Picking Challenge)的绝大部分参赛团队均选择了RGBD(图像+深度信息)的视觉方案。
但测度几何一般只能满足局部导航、避障等低层次交互需求,无法支持更高层次的交互。如,当机器人的任务是“打开瓶子倒出牛奶”时,其必须识别出奶瓶(语义标签)并分辨出瓶身和盖子(结构和功能)。因此,高层次任务的完成需要目标环境或对象的结构化、语义化三维表达。同时,由于感知具有不确定性,交互过程必须不断为感知提供反馈,以驱动和引导智能体进一步感知,逐步矫正和完善三维场景表达中的几何、结构和语义信息(图2)。
以结构化、语义化三维表达为基础,实现感知和交互的深度耦合,在二者之间形成反馈闭环,是智能三维感知与交互的重要特征,也是其区别于现有相关研究的不同点。在以往工作中,感知一般是交互的前序工作,二者是串行化的,因而无法充分利用交互中的反馈来引导感知,且在交互过程中也无法得到进一步的感知信息。事实上,人在完成任务,特别是在未知环境中的复杂任务,感知和交互往往是同时进行的,其中的感知-交互耦合就是建立在人脑对目标环境/对象构建的三维空间“认知地图”上的。该思路具有生物启发特性,有较好的可解释性和科学意义。
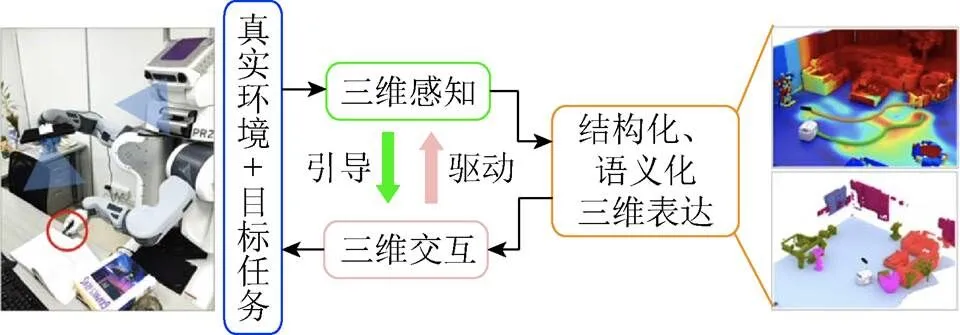
图2 智能三维感知与交互
2 “主动式”的特点、优势与挑战
2.1 “主动”在感知与交互中的体现
智能任务的完成是驱动智能体进行感知与交互的核心动力。智能体接受的智能任务方式,往往是一个抽象的任务描述,如人下达的任务指令和/或简单任务描述。智能体必须将此任务描述转化为一系列在具体环境中可执行的感知和交互动作。其中涉及任务的理解转化和环境实例化。基于先验和知识库,对任务进行解析,形成智能体对目标环境、对象的感知和交互意图,驱动智能体对感兴趣的目标进行有的放矢的感知与交互,同时获得信息反馈,以调整感知交互的目标和策略。面向智能任务的主动式三维感知与交互的主要特色在于智能体在任务的驱动下,实现感知与交互的深度耦合,以感知来引导交互,以交互来增强感知,从而在两者之间形成一个反馈闭环,达到协同促进的目标。
相比于传统的被动式感知与交互(2个任务相独立,采取的是仅以被动获取的信息为输入的单线程模式),主动式三维感知与交互的主要优势在于两者之间形成的正向反馈和促进的循环机制,通过交互补充和校正感知所获取信息中的不完整和不准确部分,并将增强后的信息更好地用于指导后续的交互行为。正是这种反馈增强的机制,使得智能体可以不断地更正和调整,更加“聪明”和高效能地完成智能任务。
2.2 主动式感知与交互的主要难点
首先是智能任务的解析和场景实例化。如何将一个抽象描述的任务解析为机器人可理解、可执行的感知交互序列,并如何将上述感知交互序列在目标环境中进行实例化,形成感知兴趣点(如视点)和交互目标点(如被抓取物体),是驱动智能体进行主动感知与交互首要解决的难题。
其次是感知与交互的耦合、反馈机制。主动感知和交互基于目标任务导向的注意力机制:面向某特定任务,智能体基于在线感知和先验知识,完成感知和交互相关的推理,并基于推理确定性来驱动和引导智能体进一步的感知和交互。在认知科学中,这种任务相关的注意机制属于自顶向下的方式,另一种自底向上的方式是纯粹基于视觉激励的前馈注意机制[11]。在人的认知活动中,两者缺一不可,人的注意力既有任务、目标导引的部分,也有视觉刺激触发的成分,二者结合形成更全面、正确的认知。现有深度学习模型大多只针对某个或几个分析、建模或交互的任务而设计,并未考虑从获取、建模、处理、分析、规划到交互反馈的整个处理管线的完整感知与交互流程,无法实现这些任务的联合学习。因此,如何实现2种注意机制的结合是三维感知和交互需要解决的重要问题。
3 案例研究介绍与分析
3.1 几何引导的自主导航与主动重建
对于未知环境的自主建图与导航是实现智能体对于三维环境的主动式感知与交互的首要任务,也是当前研究热点之一。
如张量场引导的机器人自主导航与三维扫描[12]。在一个未知室内场景中,如何让移动机器人在自主导航的同时实现场景的高质量三维扫描,是当前机器人领域很少触及的难点。一方面,机器人要快速移动到尚未扫描到的地方,同时保证移动过程尽可能平滑。因为移动过程中,突然的转向和卡顿,均会严重影响重建质量。如,机器人在探索中需要避障,为了保证扫描质量,对于障碍物要提前预判,提早规划路线,因为突然转向对扫描质量有很大影响。
为了解决此问题,文献[12]提出一种基于时变方向场的自动场景扫描算法(图3(a))。机器人在扫描的过程中同时重建三维场景,该方法将实时重建的部分场景,投影到地面上,再以二维投影边界的切向作为约束,计算一个方向场。于是,机器人沿着此方向场运动,有2个好处:①由于方向场是以障碍物边界的切向为约束计算的,沿着这个方向场移动,不会撞向障碍物;②方向场是二阶连续的,可以保证机器人的移动轨迹的连续性。这2个方面均是高质量扫描的重要保证。
其实在机器人领域,基于向量场的机器人自动导航已有很多研究,但是基于方向场的导航工作尚属首次。相对于向量场,方向场有以下优点:①方向场由于只有方向没有朝向,因此避免了由于朝向而产生的二义性,所以奇异点比向量场少得多;②方向场具有二阶光滑性,因此通过场对流计算得到的机器人运动路径足够光滑;③方向场有限的奇异点,可以使用流场的分裂线(separatrix lines)连接起来,从而形成场景的一个拓扑结构,基于此可以实现机器人的全局导航;此外,该方法还可以对方向场进行优化,如让邻近的2个奇异点成对消除,或让奇异点尽可能隐藏在障碍物附近,而不影响机器人的运动。
针对移动机器人对大规模未知场景的主动式探索、扫描和重建,需要解决如何高效率探索且高质量重建的问题。文献[13]提出了一种基于最优质量传输理论的多机协同扫描方法(图3(b)),该方法不依赖于特定的机器人平台,相比于以往单个机器人扫描的工作,在高效率的同时得到高质量的重建结果。

图3 路径导航案例((a)基于时变方向场的单机器人自动扫描重建[3];(b)基于最优质量传输理论的多机协同扫描重建[4])
该方法的核心思想是将多机协同重建任务公式化为资源分配问题。通过对当前已扫描重建模型的分析,提取需要额外扫描的区域并规划扫描视角,将其作为重建任务的需求。机器人携带扫描设备,作为重建任务的供给。需求(多个扫描视角)和供给(多个机器人)分别表示为空间中的2个分布,构成了资源分配问题。基于最优质量传输理论(optimal mass transport,OMT),该工作提出了针对协同重建任务的目标函数及其求解方法,求解得到机器人的任务分配,机器人通过完成扫描任务更新模型,从而迭代地完成渐进式重建。
求解资源分配目标函数的核心是如何利用OMT获取近似最优解。该目标函数高度离散化,直接求解往往难以得到最优解。文献[13]提出基于劳埃德算法的近似求解方法,可以高效地求得近似最优解。通过大量模拟实验和真机实验,验证了该方法可在大规模未知场景中驱动多个机器人自动探索、扫描和重建高质量的三维模型,在效率和效果上均超越了以往的多机协同方法。
3.2 几何引导的主动交互与灵巧抓取
触碰抓取作为智能体与三维环境的主要交互方式,一直以来都是机器人领域的一个重要研究分支,而当结合了图形学技术,将感知与交互进行深度融合,以主动触碰来增强语义理解,以几何感知来引导物体抓取,为这一方向的发展提供了新思路和新途径。
针对复杂未知场景的物体分割,文献[14]提出一种主动式场景重建与物体分割方法,通过机器人主动交互实现场景的分割(图4(a))。其主要流程是,首先机器人扫描场景需同时进行在线三维重建。对于重建场景,先做过分割,然后采用graph-cut的方法进行初始分割。针对分割不确定的地方,该方法驱动机器人推动一下,就可以得到物理上的可分和不可分,从而得到准确的分割结果。此外,机器人还可以在线学习,对于推动的东西,可以学习其分割,下次再遇到类似情况,可以直接预测分割结果,而不需要再进行物理交互。
为驱动机器人的主动交互,需要度量场景中的不确定性。该方法主要考虑分割和重建2个方面的不确定性,计算2个因素的联合熵。分割熵的计算相对直接,在graph-cut分割中,每一条被切割的图边均有一个切割概率,分割熵就是基于这些边的切割概率计算。重建熵是该方法的核心技术贡献。重建三维点云时,一般采用的是泊松重建。该方法是基于点云计算的一个泊松场,该场的零值面表示被重建的曲面。泊松场的零值面有一个重要特点,即该梯度刚好反映点云局部的确定性。点云越稀疏,噪声外点越大,梯度越小,则重建不确定性越高;点云越稠密,噪声外点越少,梯度越大,则重建不确定性越低。直观上讲,重建不确定的地方,点云就比较模糊;相反,重建确定的地方,点云比较清晰。因此该方法可以基于泊松场零值面的梯度来计算重建熵。
为了改善物体的抓取效果,文献[15]提出了基于深度几何表达的抓取优化算法(图4(b))。对于给定的RGBD图像,该方法首先通过一个生成模型显式地重建了物体的三维几何,再通过投影得到相应局部视角,两者共同作为抓取预测网络的输入得到最终的抓取姿势。相比于先前的不考虑物体几何的抓取预测方法,该方法的抓取成功率有明显的提升。此外,得益于完整的几何表达,该方法对于其他视角的抓取姿势的生成也具有更好的泛化性,并能用于指导更优抓取姿势的规划。
高自由度抓取是机器人灵巧操作的重要研究问题,具有广阔地应用前景。文献[16]提出基于交互几何表征学习的高自由度灵巧抓取(图5)。该工作将机械手与物体之间的夹取交互表示为交互二分面(interaction bisector surface,IBS)。IBS源自于生物信息学领域,近年被引入到图形学领域,用于描述场景中物体之间的交互关系以实现场景理解与建模。IBS可以很好地刻画高自由度机械手的每一个手指与物体之间的细粒度空间交互关系,是一种非常有效的交互状态表示。结合深度强化学习,可以有效建模和学习抓取过程中二者间的动态交互,从而以较高的样本效率学习高自由度抓取控制策略。此外,基于这种几何表征习得的控制模型具有较好的动态适应性和跨类别泛化性。
3.3 三维感知与交互的在线学习与规划
智能体的交互任务往往涉及智能决策,需要进行在线的策略学习和动作规划。如,在装配和物流行业,基于机器人的拆、码垛就是一个典型的涉及在线决策规划的任务。但是,目前机械臂的智能化水平仍然较低,未对操控过程进行合理优化,而更多是根据预设的指令进行操作。因此,如何利用智能图形技术,通过获取到的几何信息来自主引导机器臂的操控效率和操作步骤的优化逐渐受到关注。

图4 几何引导的主动交互与灵巧抓取((a)主动交互场景分割[5];(b)基于深度几何表征学习的抓取优化[6])

图5 基于交互二分面的动态交互表征学习实现高自由度灵巧手抓取过程规划
在物流仓储场景中,无序混合纸箱码垛机器人有着大量的应用需求。对于乱序到来的、多种尺寸规格的箱子,如何用机器人实现自动、高效地码垛,在节省人力的同时提升物流周转效率,是物流仓储自动化的一个难点问题。其核心是求解装箱问题(bin packing problem,BPP)这一经典的NP难题,即为每一个纸箱规划在容器中的摆放位置,以满足最大化容器的利用率。求解BPP问题的传统方法大多是基于启发式规则的搜索。在Online BPP问题中,机器人仅能观察到即将到来的个箱子的尺寸信息(即前瞻个箱子),可称其为BPP-k问题。对按序到来的箱子,机器人必须立即完成规划和摆放,不允许对已经摆放的箱子进行调整,同时要满足箱子避障和放置稳定性的要求,最终目标是最大化容器的空间利用率。Online BPP问题的复杂度由箱子规格、容器大小、箱子序列的分布情况和前瞻数量等因素共同决定。由于仅知道部分箱子序列的有限信息,以往的组合优化方法难以胜任。
文献[17]提出使用深度强化学习求解这一问题(图6(a))。强化学习是一种通过自我演绎并从经验中学习执行策略的算法,很适合求解Online BPP这种基于动态变化观察的序列决策问题。同时,堆箱子过程的模拟仿真非常“廉价”,因而强化学习算法可以在模拟环境中大量执行,并从经验中学习码垛策略。然而,将强化学习算法应用到Online BPP上有几个方面的挑战,首先,如果将水平放置面划分成均匀网格,BPP的动作空间会非常大,而样本效率低下的强化学习算法并不擅长应对大动作空间的问题。此外,如何让强化学习算法更加鲁棒、高效地学习箱子放置过程中的物理约束(如碰撞避免、稳定支持等),也是需要专门设计的。
为了提升算法的学习效率,同时保证码放的物理可行性和稳定性,该方法在Actor-Critic框架基础上引入了一种“预测-投影”的动作监督机制。该方法除了在学习Actor的策略网络和Critic的Q值(未来奖励的期望)网络之外,还让智能体“预测”当前状态下的可行动作空间(可行掩码,feasibility mask)。在训练过程中,依据预测得到的可行掩码将探索动作“投影”到可行动作空间内,再进行动作采样。这样的有监督可行性预测方法,一方面可以让强化学习算法快速学习到物理约束,另一方面也尽可能避免训练中箱子放置到不可行位置而提前终止序列,从而显著提升训练效率。在实际应用场景中,机器人往往无法预先看到传送带上即将到来的所有箱子,故无法对整个箱子序列进行全局最优规划。因而现有的BPP方法无法被直接用于真实物流场景。事实上,人可以根据即将到来的几个箱子的形状尺寸,很快地做出决策,并不需要、也无法做到对整个箱子序列的全局规划。该问题的求解对于开发真正实用的智能码垛机器人有重要意义。在一项用户调查中,该方法的摆放性能甚至超越了人类。在包含总共1 851个高难度随机箱子的序列中,人类获胜的次数是406次,平均性能表现是52.1%,而强化学习获胜的次数是1 339次,平均性能表现是68.9%。

图6 装箱问题的在线优化与规划((a)在线装箱优化[7];(b)转移装箱优化[8])
作为装箱问题的一个变种,文献[18]研究了转移装箱问题(transpose and pack,TAP),如图6(b)所示。给定一组堆叠的货物箱子,转移TAP的目标是逐个转移这些箱子并将其紧凑地装箱到目标容器中,其为一个没有中途缓存空间的拆垛与码垛问题。由于初始堆叠带来的箱子可接触性限制,该问题必须在装箱问题本就庞大的搜索空间中增加转移规划的维度,即找出一个最优的转移顺序。该方法使用优先级图表示物体转移的约束条件,并通过在强化学习训练中奖励有效且稳定的转移装箱方案,训练了一个神经网络对解决方案的模式进行编码和学习。该网络能在小规模样本训练的基础上,很好地拓展到对较大规模问题实例的求解,具有非常强的实际应用价值。
4 结束语
三维感知与交互主要研究的是对于三维场景的视觉感知(包括几何、结构、语义等多层次信息的获取与理解)和交互反馈(包括智能机器人或者虚拟角色在三维空间中的路径导航、触碰抓取等多方面操控的探索与优化),是图形学和虚拟现实的一个重要研究分支,也是图形学、人工智能和机器人等多门学科进行交叉融合的前沿研究方向。本文尝试从4个方面探讨该方向的开放问题和发展趋势。
(1) 三维感知的全栈可微分优化。机器学习技术的引入,特别是三维几何深度学习的兴起,极大促进了数据驱动三维几何分析与建模的发展。然而,三维深度学习追求“端到端”可学习性,往往忽视了传统几何分析与建模的处理管线,带来样本效率低、模型泛化能力受限、可解释性差等问题。更重要的是,现有深度学习模型大多只针对几何建模或理解的某个任务而设计,缺乏从获取、处理、重建到分析、理解的整个几何计算管线的完整建模,无法面向智能感知任务进行联合学习和优化。如,如何借助几何分析(“知”)的学习梯度来自动优化和调整前端的三维获取过程(“感”),实现以“知”引导“感”的可微分优化感知与建模,进而打通智能任务对主动感知过程的优化和引导。如何将深度学习融入三维几何获取、重建、分析和理解的完整管线中,实现“全栈可微分”的主动式三维环境感知与建模,是值得深入探索的研究方向。
(2) 目标环境的几何-结构-语义联合表达构建。为支持面向智能任务的环境感知和交互,需要基于三维感知和建模的结果来构建和维护目标环境的结构化、语义化三维表达。该表达的基础是场景/对象的三维几何表示。在几何表示的基础上,通过数据驱动的场景分析,可以进一步得到环境的结构表达。结构涵盖了场景/对象的组成部分以及各部分之间的空间拓扑关系。结构信息可用于支持结构关系层面的中层次交互任务,如拆卸和安装等。基于几何和结构表示,还可以进一步实现数据驱动的语义分析,得到目标环境的整体或局部语义标签、功能解析、属性关联,以支持语义功能层面的高层次交互任务。如,让智能体在理解人的意图后执行高级语义任务。因此,如何实现融合几何-结构-语义的目标环境联合表达,以及该联合表达的动态更新,是实现智能三维感知与交互的基础。
(3) 感知-交互的联合优化和反馈增强。由于感知与交互的耦合特性,如何在一个统一计算框架下实现面向智能任务的感知交互联合优化和反馈增强,是值得研究的重要方向。一个可能的思路是,面向某个特定任务,智能体对目标环境进行探索式环境感知,通过在线数据驱动分析理解完成感知推理,基于推理结果和任务策略实现基于注意力机制的交互规划,进而驱动和引导智能体对目标环境的进一步感知和交互,同时完成任务策略的学习更新,直到任务完成。
(4) 虚实融合环境下的感知-规划-交互闭环。基于强化学习的交互策略学习已经在一些挑战性任务上取得了成功,如抓取、导航、运动合成等。但是,强化学习面临样本效率低、策略迁移困难等难题,极大地制约了其在复杂任务学习方面的应用。特别是面向智能任务的从感知到规划再到交互的端到端策略学习上,上述问题更加凸显。为此,通过场景感知不断构建和更新真实目标环境的虚拟镜像,基于真实和虚拟样本同时训练交互策略,在虚实同步的平行环境中实现感知-学习-规划-交互的闭环,可有效降低强化学习的采样代价,也有助于学习易于迁移的策略。当前,数字孪生与强化学习的结合受到了工业和学术界越来越多的关注。此处,基于实时三维感知建立和维护虚实同步的学习环境是数字孪生学习的基础。因此,感知将承担学习环境建模(包括几何、物理、语义、功能等多方面的建模)和智能交互引导的双重角色。
[1] ZOLLHÖFER M, STOTKO P, GÖRLITZ A, et al. State of the art on 3D reconstruction with RGB-D cameras[J]. Computer Graphics Forum, 2018, 37(2): 625-652.
[2] PATANE G. STAR - Laplacian spectral kernels and distances for geometry processing and shape analysis[J]. Computer Graphics Forum, 2016, 35(2): 599-624.
[3] MITRA N J, PAULY M, WAND M, et al. Symmetry in 3D geometry: extraction and applications[J]. Computer Graphics Forum, 2013, 32(6): 1-23.
[4] HU R, SAVVA M, VAN KAICK O. Functionality representations and applications for shape analysis[J]. Computer Graphics Forum, 2018, 37(2): 603-624.
[5] XU K, KIM V G, HUANG Q X, et al. Data-driven shape analysis and processing[EB/OL]. [2022-07-10]. https://arxiv.org/abs/1502.06686.
[6] CHAUDHURI S, RITCHIE D, WU J J, et al. Learning generative models of 3D structures[J]. Computer Graphics Forum, 2020, 39(2): 643-666.
[7] GORDON I E. Theories of visual perception[M]. 3rd ed. Hove, East Sussex: Psychology Press, 2004: 117-142.
[8] LUCK S J, FORD M A. On the role of selective attention in visual perception[J]. Proceedings of the National Academy of Sciences of the United States of America, 1998, 95(3): 825-830.
[9] LI Y F, PIZLO Z. Depth cues versus the simplicity principle in 3D shape perception[J]. Topics in Cognitive Science, 2011, 3(4): 667-685.
[10] BARRY C, DOELLER C F. Neuroscience. 3D mapping in the brain[J]. Science, 2013, 340(6130): 279-280.
[11] BUSCHMAN T J, MILLER E K. Top-down versus bottom-up control of attention in the prefrontal and posterior parietal cortices[J]. Science, 2007, 315(5820): 1860-1862.
[12] XU K, ZHENG L T, YAN Z H, et al. Autonomous reconstruction of unknown indoor scenes guided by time-varying tensor fields[J]. ACM Transactions on Graphics, 2017, 36(6): 1-15.
[13] DONG S Y, XU K, ZHOU Q, et al. Multi-robot collaborative dense scene reconstruction[J]. ACM Transactions on Graphics, 2019, 38(4): 84.
[14] XU K, HUANG H, SHI Y F, et al. Autoscanning for coupled scene reconstruction and proactive object analysis[J]. ACM Transactions on Graphics, 2015, 34(6): 177.
[15] YAN X C, HSU J, KHANSARI M, et al. Learning 6-DOF grasping interaction via deep geometry-aware 3D representations[C]//2018 IEEE International Conference on Robotics and Automation. New York: IEEE Press, 2018: 3766-3773.
[16] SHE Q J, HU R Z, XU J Z, et al. Learning high-DOF reaching-and-grasping via dynamic representation of gripper-object interaction[J]. ACM Transactions on Graphics, 2022, 41(4): 1-14.
[17] ZHAO H, SHE Q J, ZHU C Y, et al. Online 3D Bin packing with constrained deep reinforcement learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(1): 741-749.
[18] HU R Z, XU J Z, CHEN B, et al. TAP-Net: transport-and-pack using reinforcement learning[J]. ACM Transactions on Graphics, 2020, 39(6): 232.
Geometry-guided active 3D perception and interaction
XU Kai, HU Rui-zhen, YANG Xin
(1. School of Computer Science, National University of Defense Technology, Changsha Hunan 410073, China; 2. School of Computer and Software, Shenzhen University, Shenzhen Guangdong 518060 China; 3. Department of Telecommunications, Dalian University of Technology, Dalian Liaoning 116000, China)
With the proliferation of 3D sensors and the development of large-scale 3D data, visual perception based on 3D reconstruction and understanding has
much attention. Meanwhile, intelligent graphics also leads a breakthrough in active interaction, becoming task-driven and targeting both virtual and real environments. In this sense, computer graphics, which is traditionally a field of information expression, is now expanding into the territory of information sensing. The interaction of computer graphics is also moving towards active interaction driven by intelligent tasks. Alongside this trend, data-driven analysis and modeling of 3D data, especially the corresponding online techniques, have been playing a critical role. This article expounded on active 3D perception and interaction from the perspective of the fusion between graphics and vision, along with several concrete research examples. A special emphasis was put on the advantages and challenges of being active for 3D perception and 3D interaction, and tentative explorations were made on the open problems and trends along this direction.
geometric guidance; 3D perception and interaction; active perception and interaction
TP 391
10.11996/JG.j.2095-302X.2022061049
A
2095-302X(2022)06-1049-08
2022-08-08;
:2022-10-15
国家自然科学基金项目(62132021,61972067);科技创新2030项目(2022ZD0210500)
徐 凯(1982-),男,教授,博士。主要研究方向为几何建模、三维视觉、数据驱动的图形学。E-mail:kevin.kai.xu@gmail.com
8 August,2022;
15 October,2022
National Natural Science Foundation of China (62132021, 61972067); National Key Research and Development Program of China (2022ZD0210500)
XU Kai (1982-), professor, Ph.D. His main research interests cover geometric modeling, 3D vision, data-driven graphics. E-mail:kevin.kai.xu@gmail.com
