基于改进MFCC和3D-CNN的变压器铁心松动故障声纹识别模型
2023-01-11崔佳嘉马宏忠
崔佳嘉,马宏忠
(河海大学 能源与电气学院,江苏 南京 211100)
0 引 言
电力变压器在运输、使用过程中出现的碰撞、挤压和外部短路故障等将导致铁心松动变形,继而造成严重的事故。因此对变压器铁心状态进行监测,对电网的安全运行具有重要意义。
目前监测变压器铁心松动的方法主要是振动信号监测法[1-2]。根据已有的研究证明,存在缺陷的变压器运行时,振动信号含有更多的高频分量[4],高频分量的峰度值能够反映变压器铁心的压紧程度[5]。基于振动信号的故障诊断方法已经取得了较为成熟的研究成果,但是振动传感器的安装通常是附着于变压器的器身,振动信号的识别方法更依赖于传感器的安装位置及灵敏度。考虑到配电变压器具有分布广、数量多的特点,普遍采用巡检的方式进行故障诊断,在巡检过程中难以获取振动信号,因此基于振动信号的故障诊断方法不适用于配电变压器。
虽然使用振动信号对变压器进行故障诊断存在上述缺点,但是变压器的声纹信号和振动信号具有相关性,因此可以利用声信号代替振动信号对其进行监测和诊断[6]。声纹信号的采集具有传感器非接触,测量便捷的优点,更适合于人工巡检。刘云鹏等[1]提出了基于Mel时频谱—卷积神经网络的变压器铁心松动声纹识别方法,能够较好地识别故障;耿琪深等人[6]提出一种基于Gammatone滤波器倒谱系数和鲸鱼算法优化随机森林的变压器故障诊断方法,能有效地识别铁心及绕组的松动故障;华北电力大学张重远等[7]采用盲源分离的方法针对局部放电故障进行了研究,使用2D-CNN对数据进行了深度学习,但未证明是否可用于铁心松动的故障诊断。上海交通大学王丰华团队[8]采用加权降维的MFCC与传统的机器学习VQ相结合,对铁心压紧程度进行了诊断;已有研究存在的不足是:特征提取采用提取梅尔频率倒谱系数(MFCC)或者线性倒谱系数(LPCC),特征向量有过高的维数,导致计算机运行的速度大大下降;目前对语音信号进行识别使用的识别模型是卷积神经网络,主要采用的是一维或二维卷积神经网络(2D-CNN),2D-CNN虽然可以同时提取时域和频域的信息,但是识别准确率仍有上升的空间。三维卷积神经网络(3D-CNN)目前已被有效地应用于动作的识别,不同于2D-CNN,其还能提取出反映时间变化上的信息。
针对上述问题,本文采用经LLE降维的MFCC作为声纹信号的特征量,降维后的数据维度大大缩减,以降低计算的复杂度,提高计算速度;并首次使用3D-CNN识别模型对变压器铁心不同松动程度进行诊断,进一步提高故障识别的准确率。
1 噪声信号特征提取
1.1 梅尔倒谱系数
1.1.1 噪声信号预处理
噪声信号x(t)的预处理包括分帧、加窗和离散傅里叶变换。截取一段变压器在某工况下的噪声信号,首先对截取的片段作分帧处理,帧长选择太长会影响特征量的准确性,帧长选择太短会提取不到有用的特征量。取每帧N=2 500为50 ms(采样频率为50 kHz),为了使帧与帧之间能平滑过渡,取重叠率为50%。其次,若是直接对分帧后的数据进行离散傅里叶变换,会出现频谱泄露的情况,因此需要对每一帧先作加窗处理,选择加汉明窗ω(n),使信号两端变得平滑减少信号的失真,即
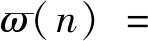
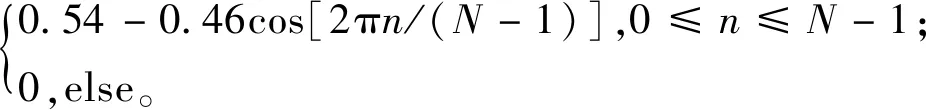
(1)
最后,根据下式再对分帧加窗后的每一帧数据作离散傅里叶变换得到能反应时频关系的复向量Y(k),为
(2)
1.1.2 MFCC特征向量提取
在语音识别技术中,梅尔倒谱系数(MFCC)是最常见的一种语音信号特征提取方法[8]。它是基于Mel频率域的倒谱系数,是根据人耳听觉感知特征变换的频率域,将线性频谱映射到Mel频率域中,再转换到倒谱上。求取MFCC特征向量的步骤包括对预处理后的各帧信号Mel滤波、对数变换及逆变换(离散余弦变换)。
Mel频率和实际频率的转换公式为
(3)
式中:p为实际频率,Hz;fmel(p)为Mel频率。
Mel滤波器是一个由m个三角形滤波器组成的滤波器组。其中心频率为f(m),在Mel频率刻度上,滤波器之间的距离是等宽的。该滤波器组的传递函数为
(4)
其中,f(m)定义为
(5)
式中:fh与fl为滤波器滤波频率的上限与下限;fs为变压器声纹采样的采样频率(fs=50 kHz);N为进行短时傅里叶变化时的帧长。
信号经过滤波器后可得到m个参数Mi(i=1,2,…,m)并取对数,计算公式为
(6)
将计算得到的Mi进行离散余弦变换,即可得到分帧信号的MFCC特征信号,其计算公式为
(7)
梅尔倒谱系数(MFCC),它的物理含义是语言信号的能量在不同频率范围的分布。特征量具体提取步骤是:
1)对声纹信号分帧加窗。本文是将一段2 s的信号首先截取成4段,分别对每段(0.5 s)进行分帧加窗。取每帧N=2 500为50 ms(采样频率为50 kHz),重叠率为50%,并使用汉明窗处理使信号两端变得平滑减少信号的失真,此时每段(0.5 s)可以得到加窗后的二维数组[19×2 500];
2)傅里叶变换。对步骤1)的每一帧作N=4 096的傅里叶变换,得到频率特征的二维矩阵[19×2 049],并计算每一帧的能量得到能量谱E[19×2 049],将每帧的能量相加得到该帧的能量和有F[19×1];
3)计算能量特征参数的和能量总值。将步骤2)得到的能量谱E通过梅尔滤波器组,计算能量特征参数的和能量总值二维矩阵[19×26];
4)计算MFCC特征向量的基础参数(第一组参数)。对每一行作离散傅里叶变化,由于变压器本体噪声的频率集中在低频区,因此只取每帧的前13个数据,即二维数组[19×13],对该数组作升倒谱操作,得到MFCC参数的基础参数也是第一组参数记作feat[19×13];
5)计算MFCC特征向量的第二、三组参数。第二组参数是在已有的基础参数(feat[19×13])下作一阶微分操作得二维数组feat′[19×13],第三组参数在第二组参数下作一阶微分操作得二维数组feat″[19×13],即对基础参数导数的导数;
6)MFCC特征向量。将feat、feat′及feat″三个二维数组拼凑得到MFCC最终的特征向量数组[19×39]。
1.2 改进的MFCC特征向量
使用上述方法提取的MFCC特征向量在高维度的情况下,能有效地提取到噪声信号中的信息,但是过高维度的数据会耗费大量的时间,并且增加计算的复杂性,因此考虑使用局部线性嵌入(locally linear embedding,LLE)算法对提取到的高维度的MFCC特征向量进行降维,且保证能保留变压器噪声信号的有效信息。
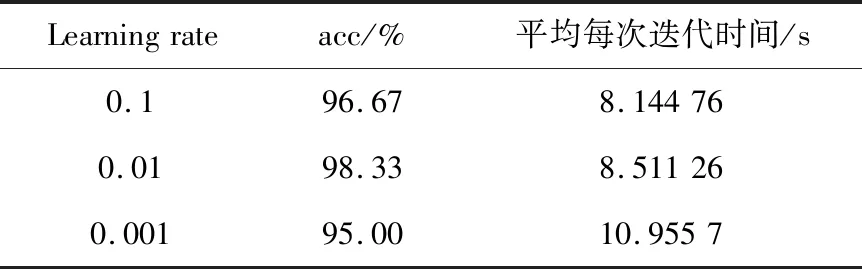
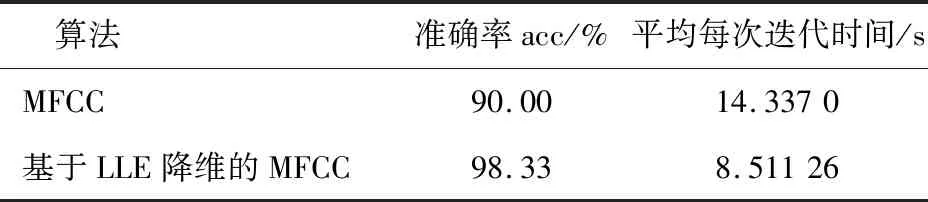
LLE算法的主要思想是高维的数据样本点可以利用局部领域的点进行线性表示,并保持局部领域权值不变,且在低维空间中利用修改权值重新构造原来的数据点,并使得重构误差达到最小[9]。对于数据X={x1,x2,…,xN}∈RD×N是高维欧式空间RD的数据集,通过LLE降维算法可将高维数据(D维)X降维到低维数据(d维)Y={y1,y2,…,yN}∈Rd×N,d 1)寻找数据样本点xi(i=1,2,…,N)的k(k (8) 2)计算重构权值矩阵。构造误差函数ε(W),并使得误差最小,定义为 (9) 式中:xij表示为xi的第j个近邻点(j=1,2,…,k),wij为xi和xij之间的权值,同时满足 (10) 综合式(9)和式(10),即有最小误差函数 (11) 3)将样本点从高维空间映射到低维空间。在低维空间中应满足: (12) 式中:yi为xi映射在低维空间的输出向量;yij表示为yi的第j个近邻点(j=1,2,…,k),同时满足 (13) (14) 则映射在低维空间的输出向量Y=(y1,y2,…,yN),可以用下式求解: Y(I-W)(I-W)TYT=YMYT。 (15) 式中:Ii为N×N单位矩阵的第i列;Wi为矩阵W的第i列。 4)求解输出向量Y。由推导公式可知,Y应由矩阵M的从小到大排列的d个非零特征值的特征向量构成的矩阵。考虑到最小的非零特征值无限趋近于0,因此选择第2至第d+1个特征值对应的特征向量作为LLE降维算法的输出向量Y。 卷积神经网络是一种前馈神经网络,具有局部连接特性和权值共享特性,能够自动对原始数据进行局部空间特征提取,因此被广泛应用于图像识别等领域[10]。研究表明,卷积神经网络可以学习到人工难以提取的深层次的特征,使用CNN有助于提高模型的判别能力和泛化能力。它通常是由多个卷积层、池化层和全连接层组成,每一层网络输入输出的数据均是二维数据,由多个独立神经元组成,有较高的识别精确度。 对于传统的2D-CNN,只能提取二维图像的特征信息,而3D-CNN适用于更高维度的图像数据,在处理过程中增加了时间维度的信息(连续帧),可以同时提取出时间与空间的信息。相比于二维卷积,三维卷积更能捕捉到时序上的特征。3D-CNN的卷积公式为 (16) 将采集的2 s原始数据分为4帧数据,用上述方法生成4组MFCC特征向量,此时数据大小为[4×19×39×1],再将每一组数据经过LLE算法降维,则数据大小缩小为[4×19×39×1],其中4表示数据深度;19表示时间分量;18表示特征维度,1表示输入网络的通道。则三维卷积神经网络的输入数据集制作如图1所示。 本文根据CNN网络输入数据的大小和特点,设计了用于识别变压器铁心松动故障的声纹特征的网络结构,该网络能避免训练过程中出现的过拟合和梯度爆炸现象,且能有较高的识别率。 在搭建CNN结构时,采用激活函数ReLU,它能极大地提高网络的训练速度;为了防止发生过拟合,使之在训练集上训练良好却在测试集上准确率低的现象,因此选择在全连接层进行了dropout操作,它是通过概率随机丢弃部分神经元,使得训练样本在保持输入和输出神经元数量不发生变化的情况下进行参数的迭代;另外,为了防止发生梯度消失,又能够加快学习收敛的速度,采用批规范操作,提高网络的性能。 图1 数据集制作过程Fig.1 Dataset production process 本文使用的3D-CNN是由两层卷积层、两层池化层及两层全连接层组成,均采用“SAME”补零方式。其中,卷积层后接有激活层,激活层选择的是线性整流函数(ReLu),dropout是一种非常有效的提高泛化能力,降低过拟合的方法,因此选择在每一个全连接层后设置dropout层,速率均设置为0.5。由于本文作四分类问题,将最后一层设置为4节点,用softmax函数激活作分类。网络的详细结构如表1所示(batch size表示批尺寸:一次输入网络训练的样本数量)。 表1 3D-CNN网络结构Table 1 3D-CNN network structure 给每一段音频生成经过LLE降维后的MFCC特征向量标记,送入3D-CNN模型中分别训练,用损失值loss和准确率acc来评判模型的优劣,损失值loss用来描述预测值与实际值之间的差距,acc表示正确分类的数量占总预测样本的比例。loss值越小,acc值越大,则判定该模型越适合变压器铁心松动故障的识别。其中,损失函数选择的是传统的交叉熵损失函数(softmax loss)。softmax loss是由softmax和cross-entropy loss 组合而成的损失函数,其损失函数的表达式为 (17) 铁心的噪声能代表变压器运行时的状态信息,在不同的运行工况下或者发生故障情况下,它的噪声信号在时域、频域会出现不同程度的变化,但是这种状态信息的变化非常复杂,难以直接通过某一个数值的变化辨别,因此构造由LLE改进的MFCC-CNN的变压器声纹识别模型,用于变压器铁心松动故障的诊断。 通过第1节的噪声MFCC特征的提取并通过LLE的降维,将预处理后的特征向量作为CNN网络的输入量进行深度学习,形成基于LLE降维的MFCC-CNN识别模型,从而实现变压器的铁心在不同程度松动下的声纹特征的提取与故障的识别。基于LLE降维的MFCC-CNN识别模型实现的具体步骤为: 1)搭建变压器铁心松动故障试验模拟平台,采集铁心在松动不同程度下的变压器噪声信号; 2)给采集的噪声数据规范为统一的数据长度并添加数据标签; 3)提取每一段信号的MFCC特征并使用LLE算法对其降维并制作成输入网络的数据集; 4)搭建3D-CNN网络结构,将步骤3)制作的数据集输入网络进行训练,并调整网络参数至最佳; 5)使用测试集测试训练好的模型。 为了验证基于LLE降维的MFCC-CNN识别模型的变压器铁心松动故障的识别效果,搭建了变压器铁心松动故障试验平台,采集铁心在不同松动程度下的噪声信号。 试验对象为一台S13-M-200/10变压器,根据国标GB/T 1094.10—2003对该变压器噪声测量的标准和要求,采用电容式麦克风作为声传感器对变压器铁心不同松动情况下的噪声进行测量,采样频率为50 kHz,频率响应为20 Hz~20 kHz。试验在变压器厂厂房中进行,厂房空间较为空旷,几乎不存在声波反射的情况。试验环境如图2所示。 图2 试验环境Fig.2 Test environment 在设置铁心不同松紧程度时,将变压器油抽出后吊心,铁心的压紧程度是通过改变螺栓的预紧力来确定的,首先使用扭力扳手确定铁心的额定预紧力,再通过调整不同的预紧力达到模拟铁心不同松紧程度的目的,模拟过程如图3所示。在低压侧加400 V电压,对变压器做空载运行如图4所示,分别采集变压器铁心未松动、松动40%、松动80%、松动100%时若干个声纹信号。 图3 模拟铁心松动故障Fig.3 Simulated core looseness fault 图4 空载运行控制图Fig.4 No load operation control diagram 分别采集铁心在未松动情况下的样本82个,松动40%时的样本129个,松动80%时的样本129个,松动100%时的样本140个(每个样本的截取时间为2 s)。将变压器铁心在同一种松动程度下的数据归为一类,并统一添加标签,使用卷积神经网络进行无参特征量的训练学习。为了验证模型的泛化能力,随机在样本中抽取80%作为训练集,剩余20%则作为测试集。同时,在每一次训练卷积神经网络时,都将样本数据重新打乱排序,以保证模型的有效性。 限于篇幅,本文以图2中②号传感器采集的声纹信号测试结果为例进行计算分析。图为试验变压器在铁心未松动、松动40%、松动80%及松动100%时的声纹信号的频率分布图。由图可见,在铁心处于不同松动程度时,变压器的声纹信号的频谱特征各不相同。 从图5可以看出,铁心在未松动时(正常状态下),声纹信号的频率主要集中在100、200、300 Hz等偶次谐波,并伴随少量奇次谐波的存在;在铁心发生松动时,声音信号的能量在不同频率范围的分布发生了改变,具体表现为:各频率分量的幅值均发生改变,且明显出现了500、600、800、1 000 Hz等分量。对不同松动程度的声纹信号作3层小波包分解,分解出0~2 500 Hz的8个频率带,其各个频段能量所占的比例分布图如图6所示。从图6中可以明显看出,随着松动程度的不同,各个频率带的能量比例会发生不同程度的变化,这为声纹识别提供了可能。 且变压器声纹能量集中在低频部分,从梅尔频率的定义可以看出,梅尔滤波器加强了低频部分,削弱了高频部分,所以将变压器声纹信号映射到梅尔频率域上,可以突出变压器声纹信号中富含信息的低频部分,有助于对声纹信号中有用信息的提取。 图5 铁心不同松动程度的声纹频率分布Fig.5 Distribution of voiceprint frequency of iron core with different looseness 将变压器噪声信号通过3.1采集并制作成数据集后,分别提取信号的MFCC特征量,再对特征向量LLE降维。采集变压器各种状态下的稳定声纹信号2 s并截取成4段(每段0.5 s),对每段作相同处理:取每帧长为50 ms,重叠率为50%。由此提取到的MFCC特征向量的每一帧的时间帧数为19,每一帧频率的维数为39,此时数据的大小为[4×19×39×1] ,4代表的是将1个样本数据分成4段,[19×39]代表每一帧数据的大小,1代表通道数。 将上述的特征向量使用LLE降维,降维后的每一个样本的数据大小为[4×19×18×1],选择降维后的维度是18的原因是,当维度低于18时,降维后的数据将提取不到有效的特征量,导致后续的3D-CNN计算不收敛,泛化性极低,因此选择将数据降到18维。取某一帧数据提取MFCC后降维前后的计算结果如图7所示,数据尺寸被大大缩小。 图6 不同松动程度声纹的各个频段能量所占比例分布图Fig.6 Distribution of energy proportion of each frequency band of voiceprint with different looseness 在模型训练过程中,卷积神经网络超参数的选择会直接影响网络的训练结果。本文选择调整的超参数为批尺寸(batch size)和学习率(learning rate)。 4.2.1 批尺寸优化 不同的batch size直接影响的是完成一次完整样本的训练所需要的次数,batch size值越大,处理一次完整样本的速度就越快,则当需要达到相同精度时其需要迭代的次数也越多。在这个过程中,会存在一个最优的数值,此时模型的训练结果最佳。本文选取batch size分别等于10、20、30、60,训练结果如图8、图9所示。 图7 特征量将为前后对比Fig.7 Comparison before and after dimensionality reduction of feature quantity 图8 不同批尺寸下的准确率曲线Fig.8 Accuracy curve under different batch sizes 从图8可以明显看出,当batch size=10、20、30时,训练过程中准确率波动很大,且在图7的loss曲线中,没有呈现稳定下降趋势,因此当批尺寸选择10、20或30时,可能会导致模型最终不能收敛。而当batch size=60时,在训练过程中,当迭代次数达到43以后,准确率已稳定在1,且loss值在迭代过程中总体呈现出稳定下降的趋势。不同批尺寸最终训练模型在测试集上的表现效果如表2所示,当batch size=60时,准确率最高达到96.88%;对于每个模型都选择迭代100次,从表2中平均每次迭代所需时间可以看出,批尺寸的选择对计算时间影响不大。因此根据准确率与损失函数曲线选择batch size=60。 图9 不同批尺寸下的损失函数曲线Fig.9 Loss function curve under different batch sizes 表2 不同批尺寸的训练结果Table 2 Training results of different batch sizes 4.2.2 学习率优化 学习率(Learning rate)作为监督学习以及深度学习中重要的超参数,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。本文选取Learning rate分别等于1,0.1,0.01,0.001,训练结果如图10、图11所示。 如图10所示,当learning rate=1时,训练过程中准确率在0.2以下浮动,且呈现不收敛趋势;learning rate=0.1时,随着迭代次数的增加,准确率和损失值还存在大幅度的波动,使得模型训练不稳定;而对于learning rate=0.01和0.001,当learning rate=0.001时,迭代次数在25次以后,训练集的准确率维持在1,而learning rate=0.01虽然在迭代次数36以后准确率维持在1,但是在图9损失函数曲线中,可以观察到learning rate=0.01的曲线在learning rate=0.001的下方,且在测试集中,模型采用学习率为0.01的准确率为98.33%,而模型采用学习率为0.001的准确率为95.00%,且在表3中平均每次迭代的时间也达到近11 s.因此为该卷积神经网络选择的学习率为0.01。 图10 不同学习率下的准确率曲线Fig.10 Accuracy curve under different learning rates 图11 不同学习率下的损失函数曲线Fig.11 Loss function curve under different learning rates 表3 不同学习率的训练结果Table 3 Training results of different learning rates 将上述调参后的3D-CNN使用MFCC直接进行卷积神经网络计算和基于LLE降维的MFCC进行训练的结果如表4所示。直接使用MFCC提取的特征量维数是39,而经过LLE降维的MFCC的特征量维数是18,因此在网络训练过程中计算量将大量下降,就会缩短每次迭代所需要的平均时间。从表4中可以看出采用改进后的基于LLE降维的MFCC的特征量并使用调参后的3D-CNN训练的准确率可以从90%提高到98.33%,且平均每次迭代的时间大大缩短。 表4 改进算法前后对比Table 4 Comparison before and after the improved algorithm 使用2D-CNN作为识别模型进行变压器铁心故障诊断时,并不采用“连续帧”来制作数据集,而是将每个2 s的数据样本直接提取MFCC特征向量,再使用LLE对其进行降维。为了验证3D-CNN识别模型比2D-CNN识别模型的优越性,采用与表1相同数量的卷积层和池化层。计算结果表明,采用2D-CNN模型同样能收敛,但最终在测试集上的准确率为93.33%,平均每次迭代时间为9.153 81 s,相较于表中显示的基于LLE降维的MFCC提取的特征量并使用3D-CNN模型的识别效果准确率达到98.33%,平均迭代时间只有8.511 26 s,那么随着样本数量的增加,2D-CNN训练所需要的时间要比3D-CNN大幅度增加,因此采用3D-CNN更有优势。 1)采用LLE算法降维后的MFCC作为变压器声纹信号的特征向量,能够完整地保留其主要特征信息,并大幅降低模型的计算量,从而提高模型的识别速率,将平均每次迭代时间从14.337 0 s降至8.511 26 s; 2)使用经LLE降维的MFCC作为特征量,消除MFCC的特征向量中不能反应运行状况的冗余的特征向量,较直接使用MFCC作为特征量的准确率从90.00%提高到98.33%。 3)构建了相同网络结构的2D-CNN和3D-CNN,并使其训练同一批数据集,计算显示在准确率和识别速率上,3D-CNN更具优势。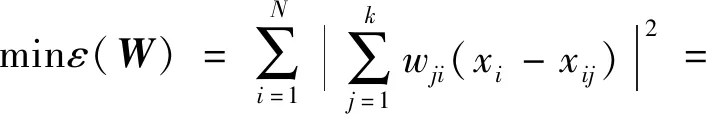
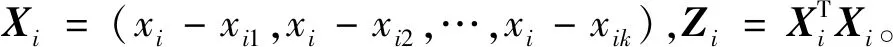
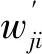
2 基于三维卷积神经网络的模式识别
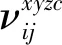
2.1 数据集制作
2.2 网络结构及性能指标

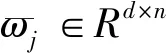
2.3 LLE改进的MFCC-CNN的模式识别
3 试验描述
3.1 试验平台搭建



3.2 声纹数据分析
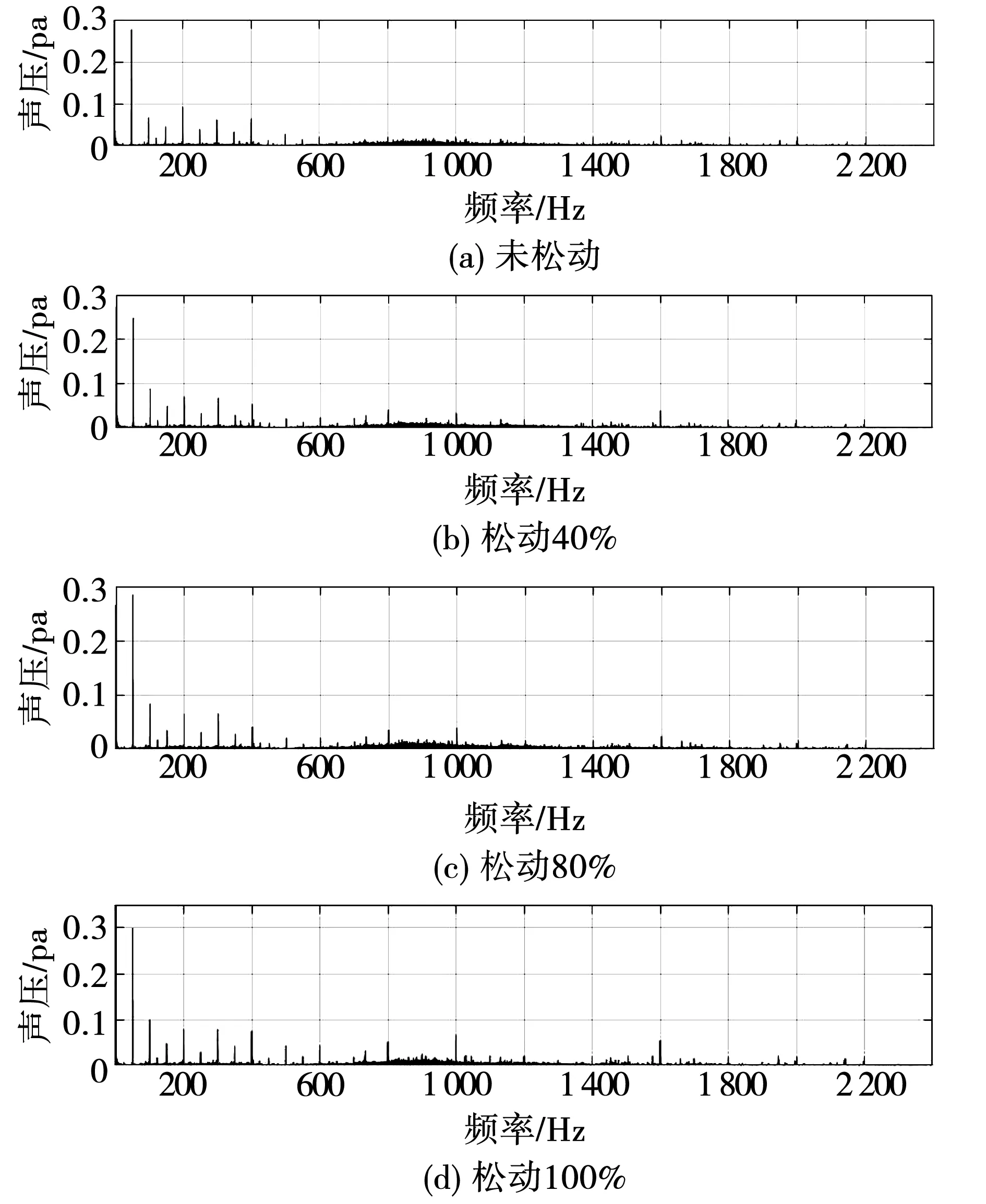
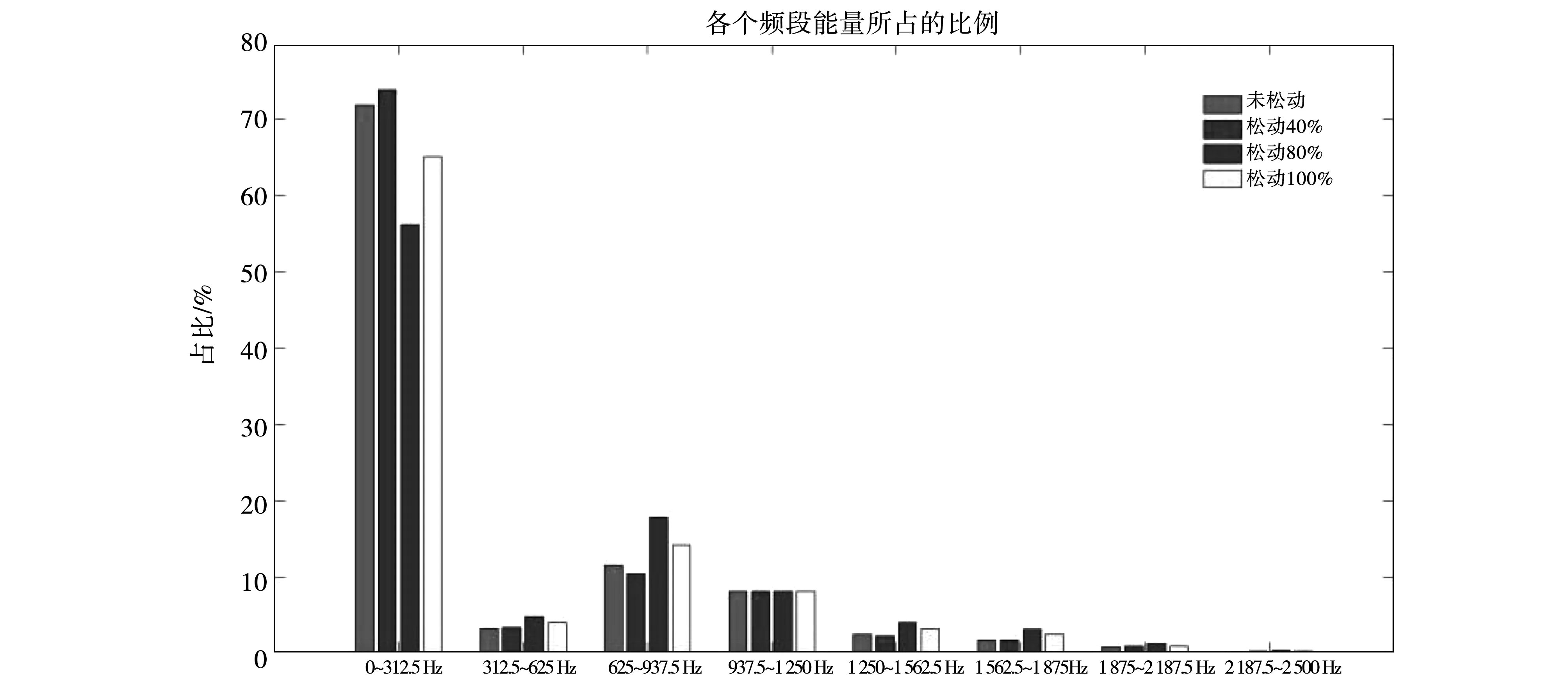
4 结果分析
4.1 基于LLE降维的MFCC特征提取
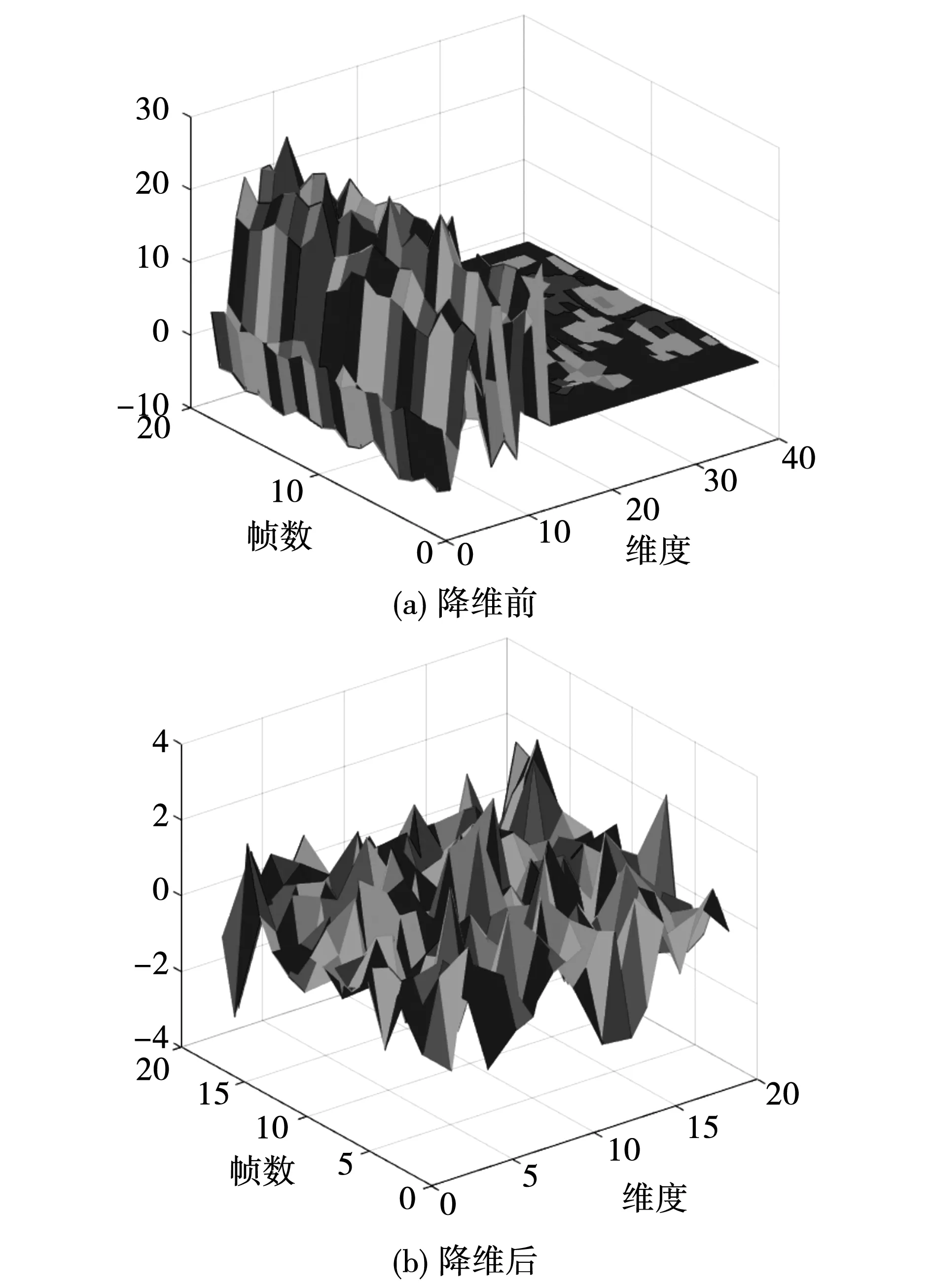
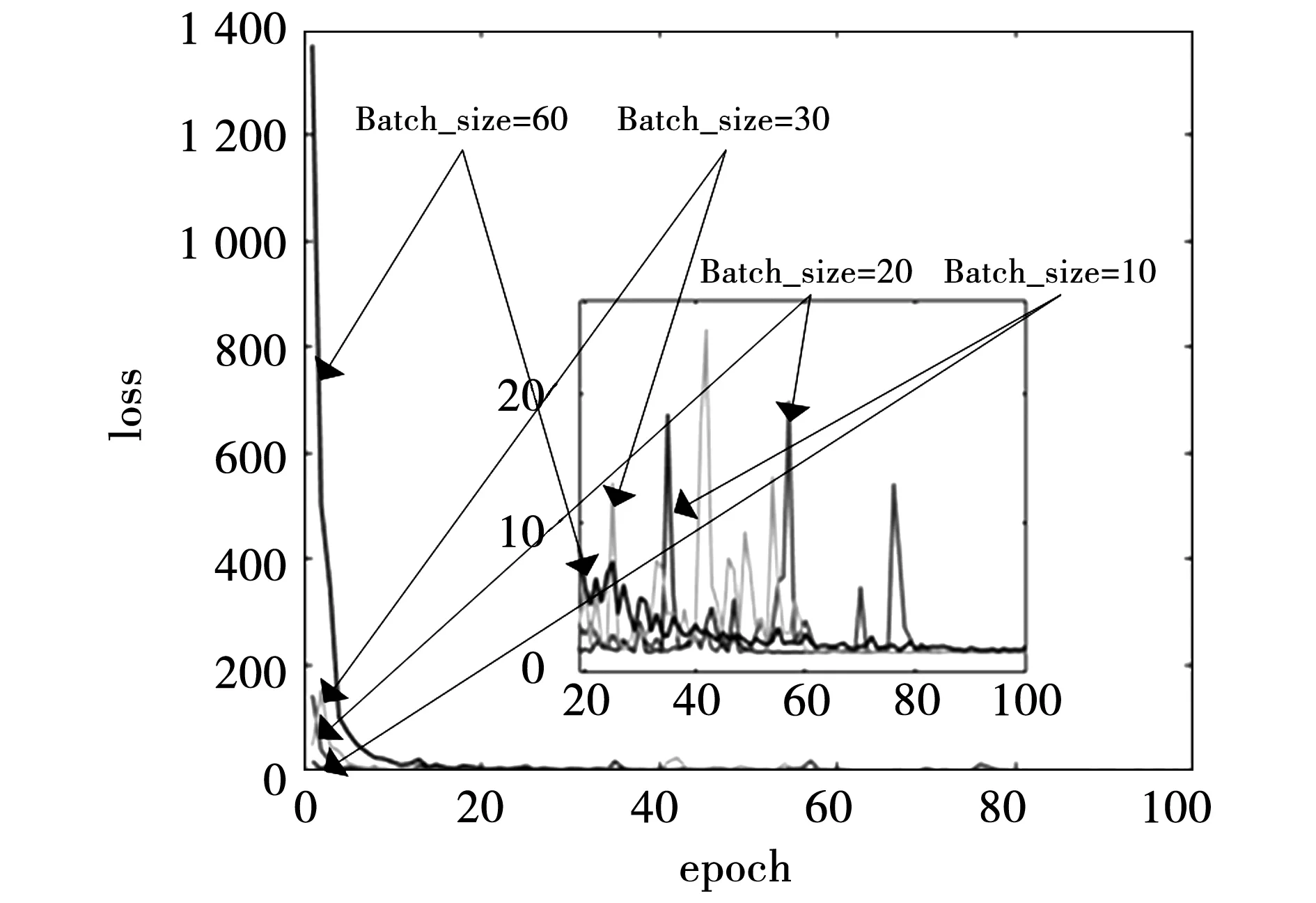
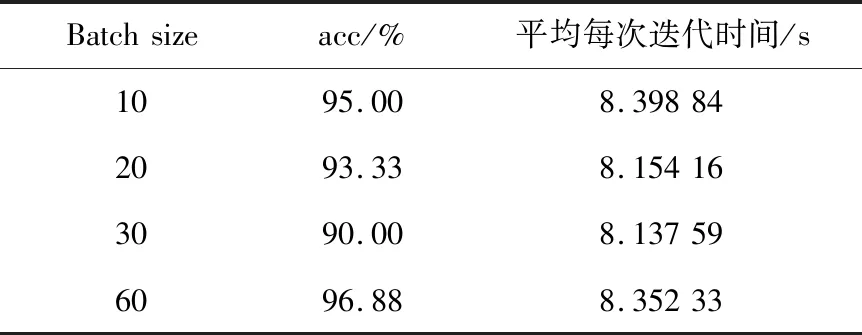
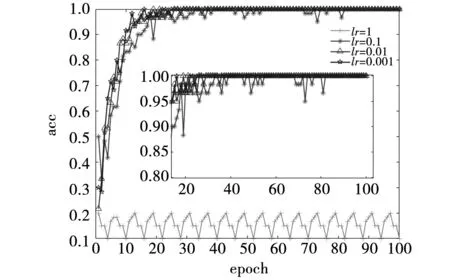
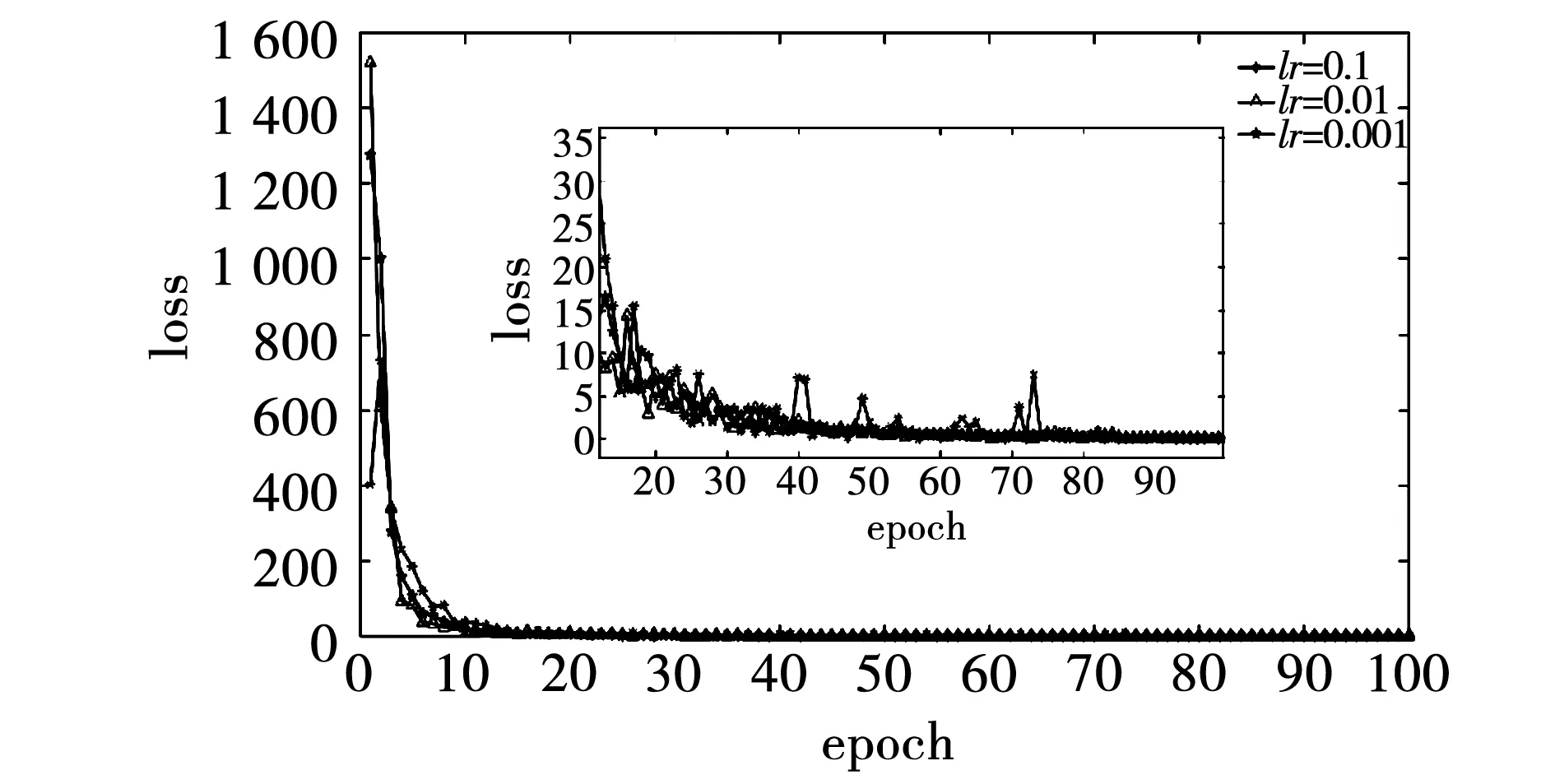
4.2 超参数优化
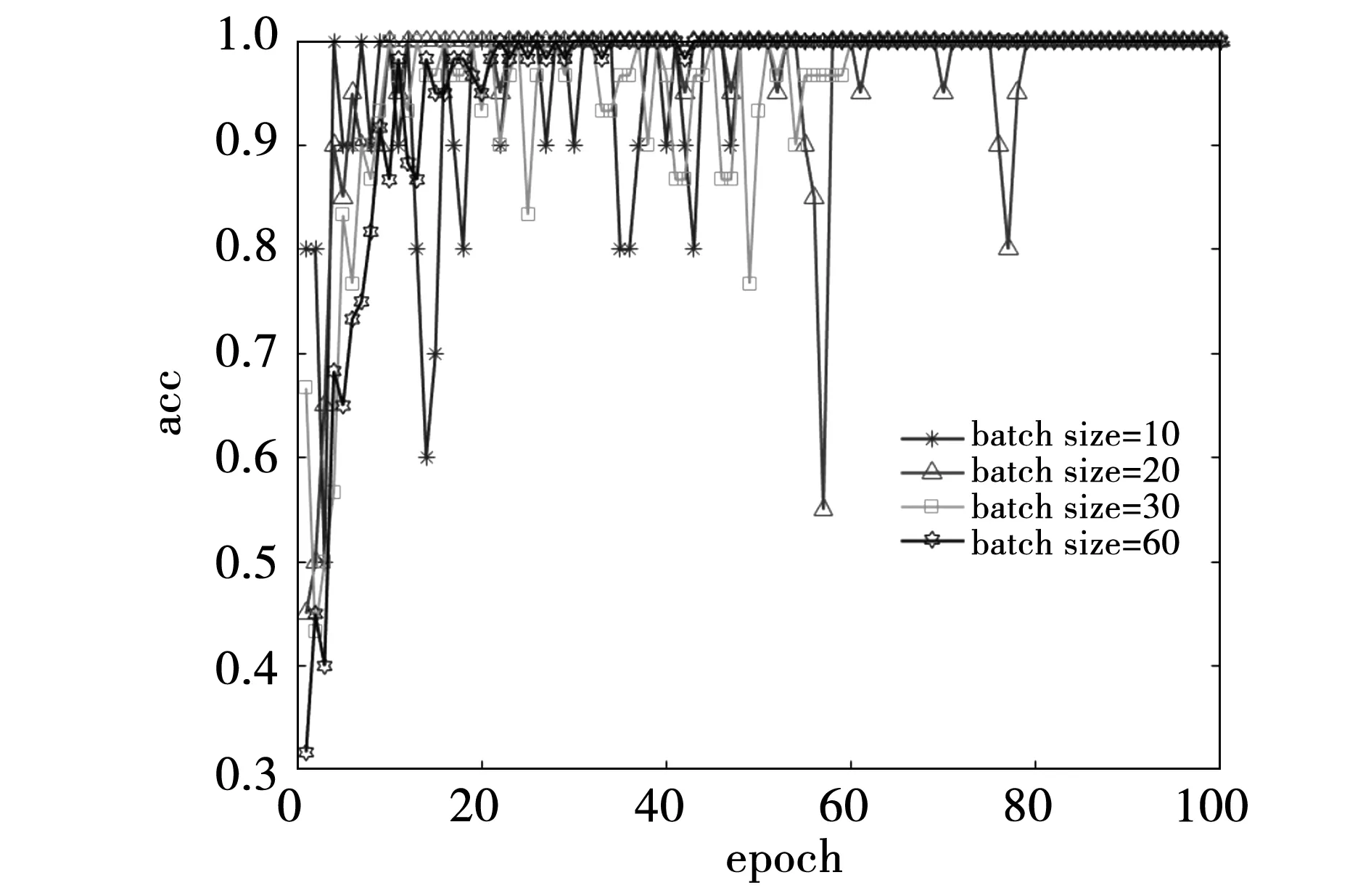
4.3 3D-CNN识别结果
4.4 与2D-CNN比较
5 结 论
