基于混合注意力原型网络的调制识别算法
2023-01-11庞伊琼许华蒋磊史蕴豪彭翔
庞伊琼,许华,蒋磊,史蕴豪,彭翔
(空军工程大学 信息与导航学院,陕西 西安 710077)
通信信号调制识别技术是电磁频谱管理、通信侦察、电子对抗等领域的关键技术之一。传统的调制识别方法可分为基于决策论的似然比检验方法(likelihood-based,LB)[1]和基于特征提取的模式识别方法(feature-based,FB)[2],但这两类方法都有其局限性。LB方法的分类模型参数是针对特殊环境设置的,任何微小偏差都会使识别准确率下降;FB方法依赖于人工提取的特征,对于特征的表征性要求较高。近年来,深度学习技术展现出了强大的数据处理能力,在图像识别、机器翻译、目标检测等领域都有大量研究的成果。2016年O′Shea[3-4]等首次将深度卷积神经网络(convolution neural network,CNN)用于解决调制识别问题,通过与传统FB方法对比,证明了利用深度CNN对大量密集编码的时序信号直接进行学习是可行的。目前,已经有大量的研究成果[5-7]将深度学习技术应用于调制识别领域,CNN与循环神经网络(recurrent neural network,RNN)[8-10]的组合网络也进一步提高了不同样式调制信号的识别准确率。然而以上基于深度学习的调制识别算法的成功很大程度上依赖于大量的训练数据,但在实际侦察环境中,面对新出现的调制类型,往往无法获得足够的带标签样本,限制了深度学习在调制识别中的应用。因此需要对小样本条件下的调制识别方法进行深入研究。
数据增强[11](data augmentation,DA)和迁移学习[12](transfer learning,TL)是目前针对样本数据量不足的主要解决方法。数据增强借助已有的一些信息生成新数据,扩充训练样本集。文献[13]中通过一个全连接网络对大量无标签数据进行自动标注,当每类信号样本量只有600时就能达到85%以上的平均识别率。迁移学习通常先通过源数据集对网络模型进行预训练,然后采用目标数据集对网络的顶层进行参数微调,适用于目标数据集与源数据集分布相似的问题。通过使用基于参数的迁移学习方法[10,14-15]对网络模型进行预优化,减少了对样本量的需求。文献[10]采用预训练过的AlexNet网络进行调制识别,在目标数据集每类信号样本量只有100时就达到了89%以上的识别准确率。上述方法要达到较好的识别性能仍需至少数百个训练样本,然而侦察环境中有时只能获取十几甚至几个信号样本,远不能满足以上2种方法对样本量的需求,在这种极少量样本条件下,以上2种方法都难以适用。
人类善于用以往学习的经验指导对新事物的学习,例如首次见到老虎的儿童可能会将其描述为一只脑袋上有“王”字的“大花猫”,“大花猫”作为已知概念有助于儿童快速掌握“老虎”这个新事物。受此启发针对元学习的研究应运而生。元学习[16]也称学会学习,即令模型可利用以往任务中学过的知识或经验去快速学习新的任务,近年来在解决小样本问题方面取得了很大的进展。在训练过程中,元学习可以通过对每一项历史任务的学习,积累一定的知识经验,如网络的参数更新策略[17]、初始化参数[18]等,这使得学习新任务时更加容易,从而在极少的训练样本支持下也能保证算法精度。度量学习[19]在解决小样本问题时将已知样本和待测样本映射到合适的特征度量空间,通过指定的距离函数计算2个样本间的距离,从而度量它们之间的相似性。
本文结合度量学习与元学习的思想,提出一种基于混合注意力原型网络的调制识别算法。在原型网络框架下设计了由CNN与长短时记忆(long short-term memory,LSTM)网络级联的特征提取网络,同时为进一步提高网络性能,在特征提取网络中引入了卷积自注意力模块(convolutional block attention module,CBAM)。该原型网络通过特征提取网络将带标签信号样本和待识别信号样本映射至统一的特征度量空间,在该空间内将同类信号的均值作为类原型代表该类信号,并通过比较待识别信号与不同类原型之间的欧式距离来确定最终识别结果。为实现元学习目的,算法采用一种基于Episode的训练策略优化模型参数,即通过从训练集中随机抽样出大量不同的小样本学习任务来模拟测试场景的识别任务。模型通过训练将学习到一个合适的特征度量空间,进而在面对新类型的调制信号时只需要极少量样本就可以实现快速分类。
1 相关工作
1.1 原型网络
原型网络的基本思想是创建每个类的类原型点,并根据类原型点与测试点之间的欧氏距离进行分类。具体地,给定支持集DS和查询集DQ,则类原型为DS中每类信号样本的平均特征向量,其中第k类信号的类原型可表示为
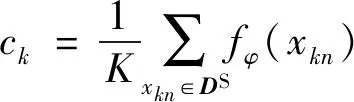
(1)
式中:fφ表示特征提取网络;φ为网络参数;xkn表示第k类的第n个样本;K表示DS中第k类样本的样本量。
假设x为来自DQ的待识别样本,通过计算样本x的特征向量与各类原型间的欧式距离,并将所得距离利用Softmax函数进行归一化处理,样本x属于第k类样本的概率为
(2)
式中,d表示一种距离度量函数,一般为欧氏距离。
训练过程中利用负对数概率损失函数J(φ)=-lnpφ(y=k|x)计算损失,并使用随机梯度下降法最小化训练损失。
1.2 训练策略
本文算法针对极少量带标签样本下的调制识别难题,给定训练集Dbase和测试集Dnovel,其中Dbase内包含多种类型的调制信号,且每类调制信号都拥有大量带标签信号样本;Dnovel由支持集DS和查询集DQ组成,即Dnovel={DS,DQ},DS中每类调制信号含有少量带标签样本,DQ中为未知的待识别信号样本。测试集中查询集DQ和支持集DS的样本标签空间相同且与训练集Dbase的样本标签空间不相交。在测试时网络模型需要在只有DS中少量带标签样本的条件下识别出DQ中未知信号的调制样式,即DS和DQ组成一个识别任务。若DS中包含C类调制信号,且每类信号都拥有K个样本,将此类任务称为C-wayK-shot任务。
为充分利用训练集内的带标签样本,采用一种基于Episode的训练策略,即在训练时模拟测试过程中的小样本设置,从训练集中采样多个小样本的任务对网络进行优化,使训练好的模型可以泛化到测试环境中。具体地,针对C-wayK-shot任务,在每次训练迭代过程中,网络模型都从Dbase中随机地选择C种类别信号组成样本集DV,然后从DV的每类信号中随机抽取K个样本组成元支持集DTS,DTS模拟测试阶段的支持集DS,最后再从集合DV-DTS(DV中不属于DTS的样本)中的每类信号中随机抽取NQ个样本组成元查询集DTQ,DTQ用于模拟测试阶段的查询集DQ。通过这种训练策略优化得到的模型对测试阶段新类型的信号样本具有良好的泛化性能。训练过程中损失函数J(φ)的迭代计算伪代码如表1所示。

表1 训练伪代码
2 基于混合注意力原型网络的调制识别算法
2.1 算法模型
本文算法整体框图如图1所示,算法模型可分为2个模块:特征提取模块和类原型度量模块。为提取到信号样本更具代表性的特征,其中特征提取模块设计为由CNN和LSTM级联的特征提取网络(CLN),CLN可充分提取信号不同维度的特征;同时通过在CLN中引入CBAM使得网络在特征提取过程中更加关注对分类有益的特征。模型通过特征提取模块将信号样本映射至统一的特征度量空间,由类原型模块进行距离度量并确定待识别信号的调制样式。
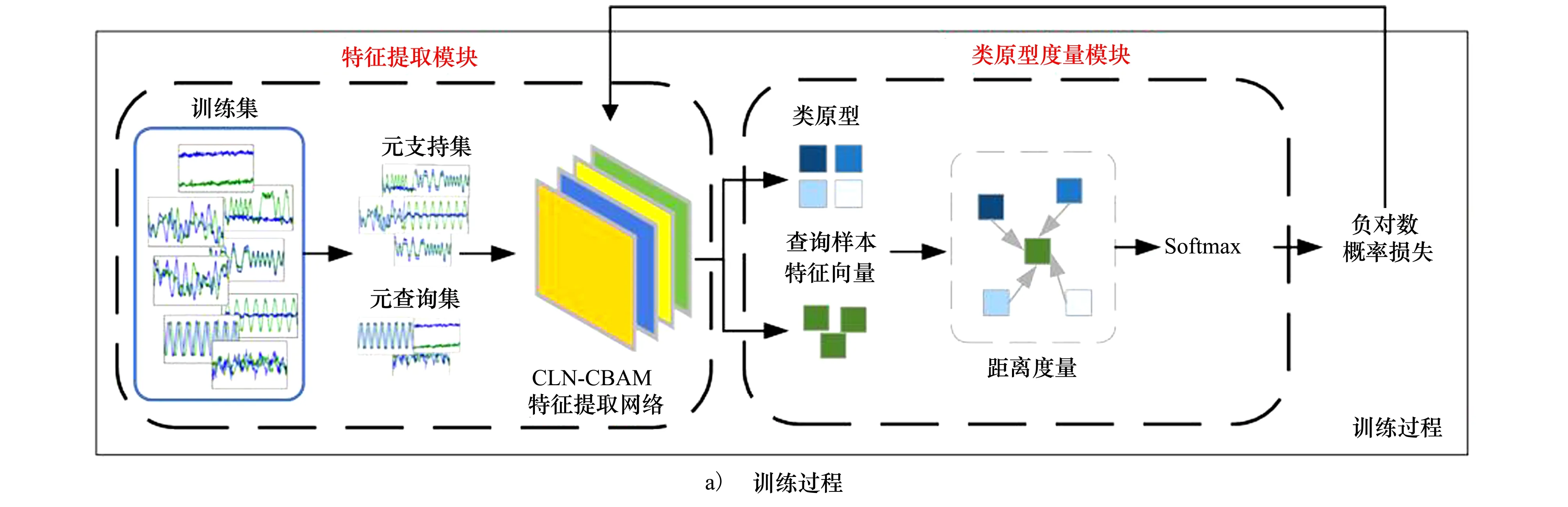
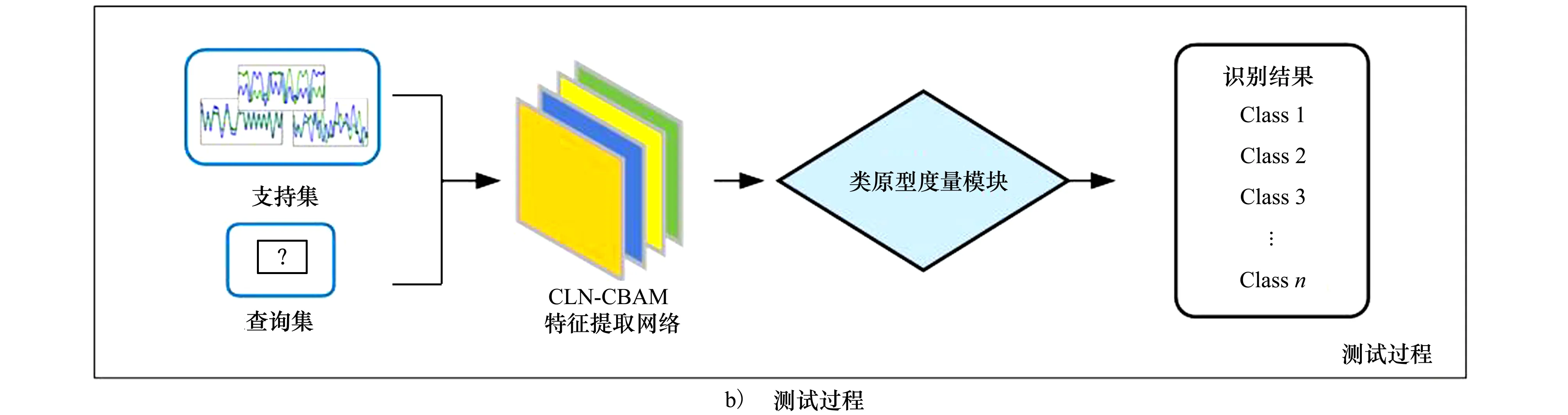
图1 混合注意力原型网络算法整体框图
本文算法的实现可分为训练和测试2个过程。根据元学习思想,算法在训练过程中采用一种基于Episode的训练策略,该策略不针对特定信号的识别进行训练,而是利用在每次训练迭代过程中随机选取的几类信号组成识别任务去训练网络,使网络学习如何将原始信号转化为更易于分类的表示,即在训练过程中学习分类的经验。通过大量不同识别任务优化得到的模型对新任务具有良好的泛化性能,根据以往的经验可在测试过程中只有极少量带标签样本条件下实现对新类信号的识别。
2.2 CLN-CBAM特征提取模块
针对信号序列内的时序特征,本文设计由CNN和LSTM搭建的特征提取模块CLN,可充分提取信号不同维度的特征,同时在CLN网络中引入CBAM模块,组成CLN-CBAM特征提取模块,其中CBAM模块可以从通道域和空间域2个维度建立特征权重向量,使网络更加关注对分类有益的特征。
2.2.1 卷积注意力模块
CBAM注意力模块是一种简单且高效的注意力模块,其是轻量级的通用模块,运算开销很小,故可集成到任何前馈CNN架构中,并与基础卷积网络一起进行端到端的训练,CBAM的整体结构如图2所示。CBAM是一种结合通道(channel)和空间(spatial)的注意力机制,每个子注意力模块通过增加关键特征的权重比值,抑制冗余特征,提高深度神经网络的性能。通道注意力模块和空间注意力模块如图3~4所示。
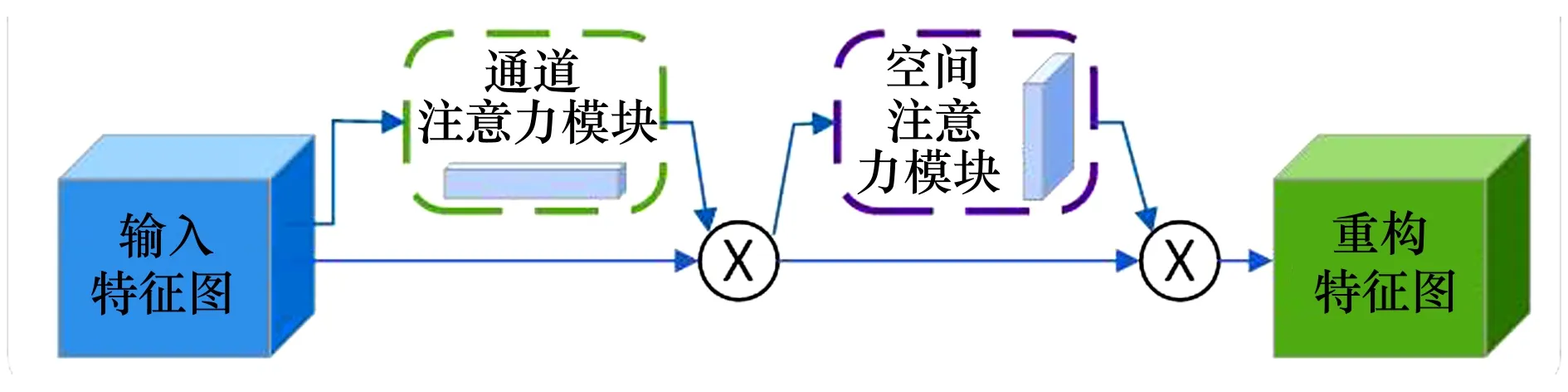
图2 CBMA注意机制整体结构

图3 通道注意力模块
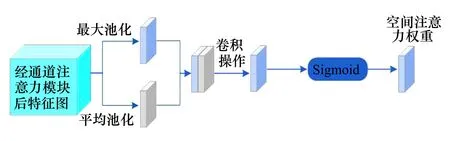
图4 空间注意力模块
2.2.2 CLN-CBAM特征提取网络
本文所提特征提取网络CLN-CBAM结合了不同神经网络的性能优势,并引入了卷积注意力模块,有助于原型网络算法识别准确率提升。CLN-CBAM网络中包含5个卷积块,卷积块由1个卷积层、1个批量归一化层、1个ReLU激活函数和1个最大池化层组成。为防止网络在训练过程中出现过拟合,在最大池化层后设置1个Dropout层,并在每个卷积块后插入CBAM模块。本文仿真所用数据为通信信号的I、Q 2路分量,数据格式为[1 024,2],基于此卷积核大小分别设置7×2,5×2,3×2,2×1,2×1,卷积核数量分别为16,32,64,128,256,最大池化层核大小都设置为3×1。卷积块完成特征提取后,将特征序列展开成一维数据送入全连接层,最后再通过LSTM输出特征。网络结构如图5所示。
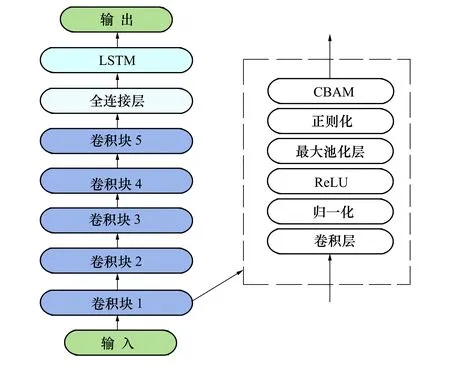
图5 CLN-CBAM结构图
2.3 算法实现流程
本文算法利用训练集模拟测试阶段的识别场景,训练完成的网络可泛化到测试过程的C-wayK-shot任务,具体实现步骤如下:
步骤1信号样本采样。从训练集中随机选取C类样本,并从每类样本中随机抽取K个样本组成元支持集DTS,再从每类剩余样本中随机抽取NQ个样本组成元查询集DTQ。
步骤2特征映射。由CLN-CBAM特征提取网络将DTS和DTQ中的样本映射到低维的特征度量空间,得到DTS和DTQ中信号样本的特征向量。
步骤3类原型度量。将DTS中每类信号的平均特征向量作为类原型,并计算DTQ中样本特征向量与各个类原型的欧氏距离,将欧氏距离输入Softmax函数,计算查询样本属于每个类的概率,由负对数概率损失函数计算损失对网络进行训练。
步骤4由测试集(测试集与训练集标签空间不相交)对网络进行测试。将含有少量带标签信号样本的支持集DS和待识别信号样本送入训练好的特征提取网络,由类原型度量模块确定待识别信号的调制样式。
3 实验仿真与结果分析
实验选取RadioML2018.01A公开调制信号集[4]验证本文所提算法性能。该信号集由24种调制信号组成,各个信号包括I、Q 2路数据,数据格式为[1 024,2],信噪比分布从-20~30 dB,间隔为2 dB。本文算法训练和测试阶段所用信号样本的标签空间不相交,随机选取14种调制信号作为训练集,另外10种作为测试集,在信噪比为-20~30 dB的条件下进行实验仿真。训练集、测试集调制样式如表2所示。

表2 实验数据集
实验模型在python深度学习神经网络pytorch框架下进行搭建,硬件平台为基于windows 7、32 GB内存、NVDIA P4000显卡的计算机。实验模型采用端到端的训练方式,Adam优化网络,初始学习率为0.001,测试阶段从测试集中采样1 000组相互独立测试任务来计算算法的识别准确率,并采用所有测试任务识别准确率的平均值来表示算法最终的识别性能。
3.1 支持集样本量(K值)对识别性能影响
为验证元支持集/支持集内每类信号样本量(K值)对本文算法识别准确率的影响,本节在K值分别为1,5,10,15,20时进行对比实验。网络训练集和测试集如表2所示,特征提取模块为CLN-CBAM网络。本节仿真实验针对5类调制信号的识别任务,即5-wayK-shot任务,元查询集/查询集样本量NQ设置为10。不同样本量下算法测试识别准确率随信噪比的变化情况如图6所示。
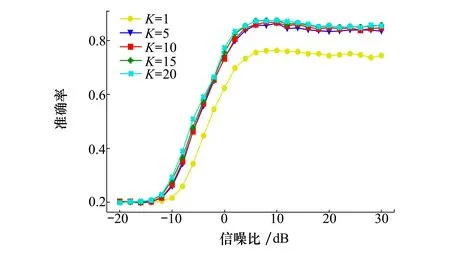
图6 不同K值下算法识别准确率变化曲线
本文所提原型网络通过比较待测信号样本特征向量与支持集内各类信号类原型间的距离确定识别结果,信号类原型取支持集内各类调制信号样本特征向量的平均,故改变支持集中信号样本量(K值)会对算法的识别准确率产生影响。如图6所示,随着支持集内信号样本量K的增加,算法的测试识别准确率也在进一步提升。这是由于在特征度量空间中支持集内的每类信号都存在一个类原型点,各类原型点间相互远离,原型网络将每类信号样本特征向量的平均值作为该类信号的类原型估计点,随着样本量K值增加,会减少真实类原型点与类原型估计点间的偏差,降低信号识别时产生的期望风险,有助于提升算法的识别准确率。从图6可以看出,当支持集内信号样本量K较小时,K值的增加对网络识别性能提升有较大影响,然而当K值大于5后,增加样本量对算法识别性能的提升效果趋缓。例如在测试信号信噪比为20 dB时,当支持集内每类信号样本量K值从1增加到5时,算法的识别准确率提升了9.01%,但当K值从5增加到10时,算法识别准确率仅提升了1.23%,这表明本文算法更适宜解决带标签信号样本只有几个的调制识别问题。
3.2 样本类别量(C值)对识别性能的影响
在支持集内每类信号包含5个样本时,验证样本类别量C值对于网络识别准确率的影响,设置任务支持集内信号类别量C为3,5,10,元查询集/查询集内信号样本量NQ值为15,当算法特征提取模块为CLN-CBAM,对比C-way 5-shot测试任务平均识别准确率,不同类别量(C值)下信号识别率随信噪比变化曲线如图7所示。

图7 不同C值下算法识别准确率变化曲线
从图中可以看出随着支持集样本类别量C值增加,网络识别性能下降。当测试任务支持集内包含10类调制信号样本时,在信号信噪比为20 dB时算法识别精度只有75.52%,相较于支持集中含3类调制信号时减少了15.45%。这是由于支持集内样本类别的增多会增加网络模型的学习难度,提升在度量空间判断2个信号特征相似性的复杂度,使得网络训练不易收敛,进而导致算法识别性能下降。
3.3 不同特征提取网络下算法识别性能分析
为验证本文所提CLN-CBAM特征提取网络对于本文原型网络算法识别性能的影响,实验设置CLN、CLN-CBAM、ConvNet、Resnet18[20]、Resnet18-CBAM、Resnet34[20]6种不同网络作为本文算法模型的特征提取模块。采用表2所示数据集,在5-way 5-shot任务下进行训练测试,元查询集/查询集样本量NQ设置为15,不同特征提取模块下实验测试平均识别准确率随不同信噪比水平的变化如图8所示。采用不同特征提取网络所需训练的网络参数量以及训练时间如表3所示。
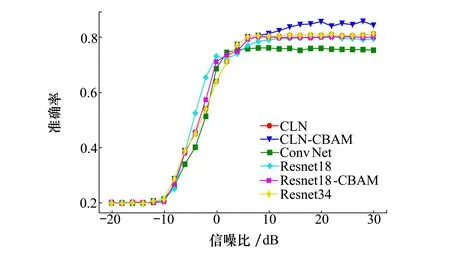
图8 不同特征提取网络下原型网络的识别性能

表3 网络参数量和训练时间
由图8可得,当信噪比大于10 dB时,采用本文所提的CLN-CBAM特征提取网络的算法识别性能最优。主要原因在于本文所提特征网络结合了CNN与LSTM的性能优势,可同时提取到调制信号的空间特征与时序特征,对比ConvNet特征提取网络,采用CLN特征提取网络的算法识别准确率在信噪比为20 dB时提升了4.67%,同时为使所提特征向量更具代表性,本文在CLN特征提取网络中引入了CBAM模块,使得网络在提取信号样本特征时能够更加关注对分类有益的部分,实验结果表明在测试信号信噪比为20 dB时,CLN-CBAM特征提取网络算法针对5-way 5-shot测试任务的平均识别准确率为85.68%,相较于CLN特征提取网络下的算法识别准确率提升了5.01%。由表3可知,对比Resnet18、Resnet18-CBAM、Resnet34特征提取网络,CLN-CBAM所需训练的网络参数和训练时长都更少,但采用CLN-CBAM特征提取网络的算法识别性能更优,这是由于Resnet网络只能提取信号样本的空间特征,特征向量代表性较低,增加特征提取网络复杂度无法有效提升算法的识别性能。
3.4 不同小样本学习算法性能对比分析
为验证本文所提算法相较于其他小样本调制识别算法的性能优势,本节选取基于数据增强(data augmentation,DA)和基于迁移学习(transfer learning,TL)的小样本调制识别算法以及另外3种元学习算法进行对比实验,分别为关系网络(relation network,RN)[21]、匹配网络(Matching Networks,MN)[22]以及模型无关元学习(model agnostic meta learning,MAML)[23]。选取16APSK、32QAM、FM、AM-SSB-SC、4ASK 5类调制信号组成信号样本集,为保证实验结果的可靠性,将该样本集作为DA和TL算法的数据集以及本文算法和RN、MN、MAML算法的测试集,将其余19类调制信号用于元学习算法的训练阶段。当测试信号信噪比为20 dB时,不同算法下的最高识别准确率以及实现最高识别准确率时所需样本量如表4所示。本文算法与对比算法针对5类调制信号在训练/支持集每类信号样本量为“5-shot”时的测试识别准确率随信噪比的变化情况如图9所示。

表4 不同小样本调制识别算法性能对比

图9 不同小样本调制识别算法识别准确率对比
从图9中可以看出,TL和DA算法的识别性能明显低于4种元学习算法,相较于本文算法,当测试信号信噪比为20 dB时,TL和DA算法在“5-shot”时识别准确率分别降低了37.81%和53.3%,主要原因在于TL和DA算法在信号样本量只有几个时训练无法收敛,从而导致算法识别性能的显著下降。由表4可知,TL和DA算法要实现最优的识别性能至少需要数百个训练样本,无法解决只有几个带标签信号样本条件下的调制识别问题。同时对比本文算法与RN、MN以及MAML 3种元学习算法,本文算法取得了最优的识别效果,分析其原因在于,RN和MN方法属于基于度量的元学习方法,不同之处在于,RN通过神经网络度量样本间的相似度,MN采用余弦距离度量样本间的相似度,而本文原型网络算法采用欧氏距离度量样本间的相似度,欧氏距离属于Bregman散度,利用Bregman散度的性质[19],可使不同类调制信号样本集合在特征度量空间内的差异性最大,故可取得更好的识别效果。MAML通过对多个任务的学习为网络寻找到一个最优的初始化参数,使得网络在面对新类别信号的识别任务时能够快速适应,但MAML算法在面对新类信号识别任务时需要对网络进行微调,由于样本量较少,难以适用参数量较大的网络,这限制了网络识别性能的进一步提升。从实验结果可知,在测试信号信噪比为20 dB时,本文算法相较于MAML算法的识别准确率在样本量为“5-shot”下提高了29.97%和18.45%。
3.5 数据集样本类别对网络的影响
本文算法仿真实验所用数据集由24类调制信号组成,其中包含19类数字调制信号和5类模拟调制信号,数字调制信号又分为调幅、调相、调频等多种不同调制信号,不同类的调制信号具有不同的特点,识别难度也相对不同。由于本文所提原型网络算法在训练阶段和测试阶段所用信号样本的标签空间不相交,故训练集和测试集中样本类别的选取也会对网络识别准确率产生一定影响。根据各类调制信号的特点将数据集划分为4种不同分集进行对比实验,为使实验结果更具代表性,每次划分数据集都选取5类调制信号组成测试集,10类调制信号组成训练集,具体划分方式如表5所示。
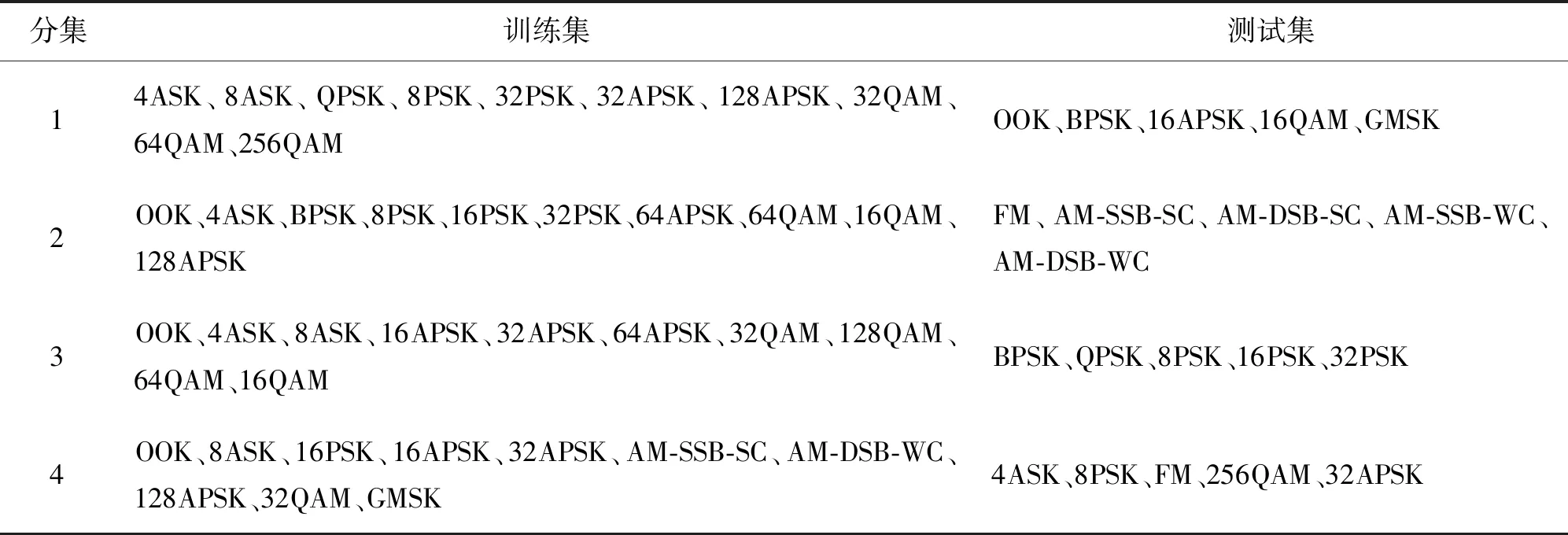
表5 实验数据集分集
本次实验设置特征提取模块为CLN-CBAM网络,验证在5-way 5-shot学习任务下测试集的识别准确率,当信噪比为20 dB时,实验结果如图10所示,4种不同分集的识别准确率分别为92.67%,82.63%,79.46%,82.78%,不同分集之间识别准确率有一定差异。由表5可知,分集1,2,3的训练集都是由数字调制信号组成,而分集3的测试识别准确率最低。分集3的测试集由5种不同进制的相移键控(phase shift keying,PSK)调制信号组成,不同进制PSK信号间相似度较高,容易造成混淆,提高了识别难度。分集1的测试集是由不同类数字调制信号组成,各类信号相似度较低,且与训练集中的数字调制信号有一定相似度,故分集1的测试识别准确率最高。分集2测试集都为模拟调制信号,测试识别准确率相较于分集1有明显下降,但由于不同模拟调制信号特征间有一定差异,故相较于分集3测试识别准确率有一定提高。分集4由随机挑选出来的调制信号组成,训练集与测试集都包含数字调制信号与模拟调制信号,在信噪比20 dB时,测试识别准确率可达82.78%。由实验结果可知,本文所提算法可适应训练集与测试集样本类别不同的场合,特别地,当训练集与测试集样本类别差距较大时,该算法也能较好完成小样本的调制识别任务,并且使用样本类别丰富度更高的训练集有利于识别准确率的提高。
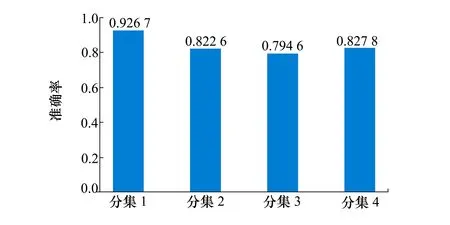
图10 数据集样本对识别准确率的影响
4 结 论
本文针对极少量带标签样本条件下的调制识别难题,结合度量学习与元学习的思想,提出一种混合注意力原型网络的调制识别算法。根据调制信号样本特征设计了由CNN与LSTM级联的CLN特征提取网络,并在当中引入CBAM模块,可使网络提取到的信号特征更具代表性。实验结果验证了本文所设计的CLN-CBAM特征提取网络可进一步提高原型网络算法的识别性能。同时为更好地从少量数据中学习,算法以元学习的方式进行训练,即利用训练集模拟测试时的识别场景,学习信号分类的经验。训练完成的网络模型具有很好的泛化性能,在测试时面对新类信号,即使只有几个带标签样本也能保证算法的识别性能算法。仿真实验结果进一步验证了本文算法解决小样本调制识别问题的可行性。本文算法信号识别率还有一定提升空间,后续将在此基础上进行更深入的研究。
