基于LightGBM的二手车价值评估的研究
2023-01-11张蝶依
李 钰,张蝶依
(1.河北地质大学信息工程学院,石家庄 050031;2.驻马店职业技术学院,驻马店 463000)
0 引言
据公安部统计,截至2021年6月全国机动车保有量达到3.84亿辆,机动车驾驶人却高达4.69亿人,且机动车驾驶人数还在不断增长,仅2021年上半年便新增领证驾驶人1390万人[1]。机动车保有量和驾驶人人数的巨大差异,使得国内汽车市场十分火热。但是由于芯片的短缺导致新车的供给下滑,使得更多的购车者把目光投入二手车市场,同时国家也大力支持二手车市场的发展。从2020年五月份起,二手车增值税从2%下降到0.5%[2],使得二手车交易的税负成本降低;同时公安部等也先后取消二手车限迁政策,进一步增加了二手车市场的活力。
但是在二手车交易中,众多的二手车线上交易网站和线下机构对二手车的定价各不相同,给二手车的交易带来极大困难。针对二手车交易中中介平台等的肆意标价,需要从二手车本身的数据出发,对二手车进行精确的估价,从而保护消费者的合法权益。然而国内对于二手车价值评估模型的研究并不多,吕劲[3]提出了基于特征优化的SVM价格预测模型,利用GBDT模型对特征进行优化组合,再使用SVM模型进行预测。张远森[4]提出了基于神经网络的二手车价格评估模型,与多元线性回归模型做对比得到了小幅提升。上述两种模型的预测精度都不是非常理想。
综上,本文提出了一种基于LightGBM的二手车价值评估模型,通过特征优化选择出对二手车价格影响较大的特征,从而缩减了特征维度也使得模型对价值的评估更加精确。
1 相关方法
LightGBM[5]是微软提出的一种GBDT的高效实现框架,它解决了GBDT无法处理大规模数据的问题。LightGBM基本原理如下:
(1)初始化k棵决策树,将训练样本的权重设为1/k;
(2)训练子模型f(x);
(3)决定该子模型的权重β;
(4)更新权重ε;
(5)得到最终的模型:
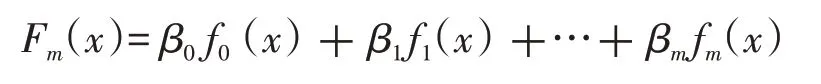
2 基于LightGBM的二手车价值评估模型
本文提出一种基于LightGBM的二手车价值评估模型,通过特征工程对原始数据进行处理,填补缺失值、删除异常值、构造对回归有益的新特征等,从而降低数据的不平衡性,使得数据更加符合待训练模型。
2.1 数据准备与特征工程
本文使用的数据来自天池河北高校邀请赛——二手车交易价格预测的数据集。其中训练集含有200000条数据,测试集含有50000条数据,每条数据包含SaleID、name、regDate等共31个特征字段,其中name、model、brand和regionCode等信息已进行脱敏。

表1 数据集字段表
数据集处理过程:
(1)统计各字段的缺失值,“bodyType”“fu⁃elType”“gearbox”三个字段有缺失值,对缺失值进行填充;
(2)统计各字段的值的分布情况,发现“seller”“offerType”两个字段倾斜严重,故删除;
(3)删除对回归无意义的字段“SaleID”;
(4)构造新特征“usedDate”,由于原数据中只有汽车注册日期和汽车售卖登记时间,两个时间单独对回归任务的意义不大,故构造更有意义的汽车使用时间作为新特征。
2.2 二手车价值评估算法流程
输入为训练集Train、测试数据集Test和LightGBM初始参数X;输出为Test的预测结果
步骤1:对数据进行特征工程,对进行特征工程之后的数据集进行聚类;
步骤2:将每一类拟合一个岭回归,并预测出每一个样本的价格,把聚类后预测价格作为新特征加入到LightGBM的特征中;
步骤3:使用LightGBM进行预测。
3 实验结果与分析
本文使用MAE作为评价指标,MAE定义如下:
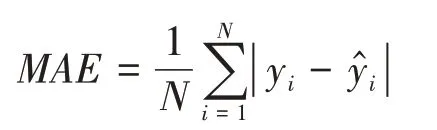
本算法与传统二手车价格预测算法进行比较,结果如下:
通过表2,不难看出本文算法在二手车价格预测任务中取得最优结果,可以对二手车交易定价起到合理的建议作用。

表2 本算法与两种传统模型在MAE上的对比
4 结语
本文介绍了目前求解二手车估价存在的问题,构建了基于LightGBM的融合模型,通过与两种具有代表性的二手车价格预测模型进行比较,提升效果均超过10%。
本研究尚有不足之处,如二手车定价仅考虑到车辆本身因素,并没有结合当下政策以及买家信息,不能做到更加实时个性化的定价。但对于二手车价格预测任务仍具有一定借鉴价值。
