基于序列生成的多标签文本分类算法研究
2023-01-11黄立星咸儆醒
黄立星,咸儆醒
(南京恩瑞特实业有限公司,南京 210013)
0 引言
随着序列生成模型在机器翻译领域的深入应用,相关研究人员开始将序列生成模型应用于多标签文本分类领域中[1],通过将文本数据作为输入序列,文本所对应的标签集作为输出序列,从而转化为Seq2Seq问题。尽管目前基于序列生成的多标签文本分类取得了不错的成绩,但其运用到不同场景中仍存在一些不足。例如在序列生成过程中,为了避免编码器层中的中间语义向量由于信息压缩带来的信息损失,常常采用词粒度的注意力来缓解这一缺点[2];然而对于长序列数据,基于词粒度的注意力未能很好地进行中间语义向量编码。针对这些词粒度的缺点,我们通过借鉴HAN层次化注意力机制的思想,将层次化注意力运用于编码器层,进而得到句子粒度的隐藏层状态信息,之后利用解码器层基于句子粒度的隐藏层状态信息进行注意力操作。针对序列生成过程中存在的重复标签生成问题,本文采用引入辅助向量的方法,可有效避免重复标签生成问题;最后基于开源RCV1-V2数据集对提出的改进算法进行了有效性的验证。实验结果表明,基于层次化注意力机制的改进算法以及辅助向量的改进算法进一步提高了分类结果的准确率以及召回率。
1 Seq2seq多标签文本分类模型的设计与实现
Seq2Seq模型基于Encoder-Decoder框架,该模型由编码器(Encoder)和解码器(Decoder)所组成,其中Encoder、Decoder之间的连接由En⁃coder层产生的中间语义向量进行控制。Seq2Seq模型解决了传统RNN模型处理序列问题过程中要求输入、输出序列长度为等长的问题。近年来,Seq2Seq模型被广泛运用于机器翻译、情感对话生成、文本自动摘要、图片自动描述等领域。
基于Seq2Seq模型的多标签文本分类网络结构如图1所示。
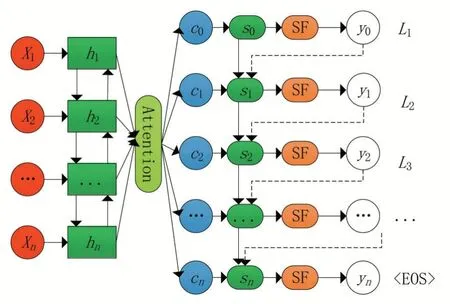
图1 Seq2Seq序列生成多标签文本分类模型示意图
如图1所示,该模型主要由编码器、解码器组成,其中SF表示softmax输出层。为了避免编码器层在处理长序列数据集中存在的信息压缩问题,在解码层进行解码的过程中往往引入atten⁃tion机制。其中编码器层、解码器层的具体定义以及功能将在接下来的小节中进行详细阐述。
1.1 编码器层
首先定义(w1,w2,w3…wn)为文本的单词序列表示,其中wi表示该文本第i个词的one-hot编码表示,通过嵌入层矩阵E∈Rk*v得到wi词所对应的词向量xi,其中嵌入矩阵中的k代表该词的向量维度,v对应词典表的总数。
得到词向量序列后,将该序列作为编码器层的输入,通过编码器层得到每个单词对应的隐藏状态信息。本文编码器层采用Bi-LSTM网络,Bi-LSTM通过前后两个不同方向对词向量序列进行处理,并计算出每个单词对应的隐藏状态信息,之后通过级联前后方向上的隐藏状态信息,从而得到第i个单词的最终隐藏状态信息。上述过程分别由公式(1)、(2)、(3)进行表示。
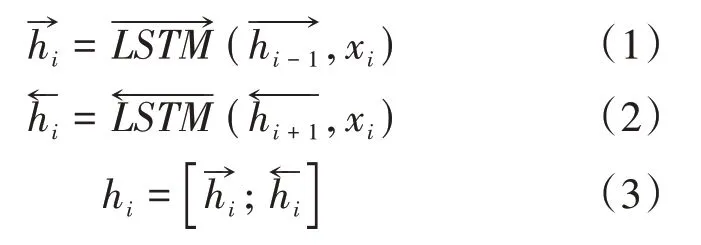
其中hi为单词i的最终隐藏状态信息。
1.2 注意力层
基于Seq2Seq模型输出文本所对应的类别标签时,由于组成文本序列的不同单词对其输出结果影响不同,因此通过注意力层可以关注文本序列中的不同单词。文本序列经过编码器层后,由解码器层与编码器层进行注意力操作从而产生上下文向量,将其作为下一时刻解码器层的输入参数,从而影响类别标签的输出。其计算过程可分别由公式(4)、(5)、(6)进行表示。
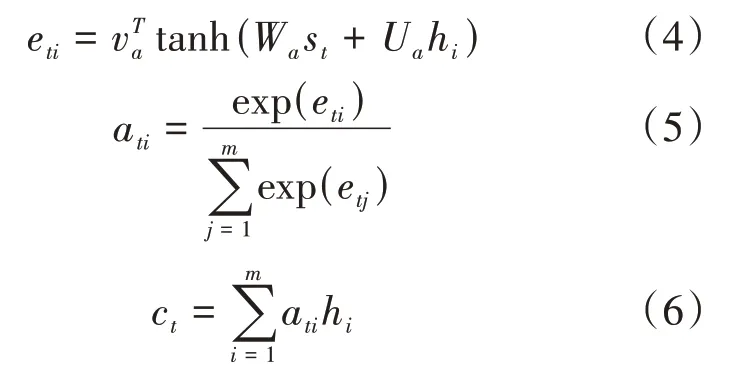
上述公式(4)中eti表示t时刻解码器层的状态信息与编码器层第i时刻注意力值的计算,经过公式(5)之后进行归一化操作,最后通过不同时刻对应的不同权重与编码器不同时刻的隐藏层状态信息进行乘积求和操作,从而得到当前时刻的上下文向量ct。
1.3 解码器层
解码器层得到当前t时刻所对应的隐藏层状态信息st后,通过连接全连接层,同时采用softmax函数作为全连接层的输出函数,之后根据不同的阈值来判断该标签是否属于该文本。其中st可以由公式(7)表示,具体输出过程可分别由公式(8)、(9)进行表示。
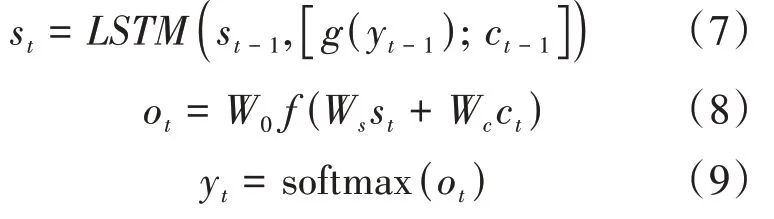
公式(7)中,st-1表示t- 1时刻编码器层中隐藏层状态信息,g(yt-1)表示t- 1时刻输出的标签类别,ct-1表示t- 1时刻产生的上下文向量;公式(8)表示全连接操作;公式(9)表示模型的输出函数。
2 层次化注意力机制
基于RNN模型的序列生成过程中,常常通过引入注意力机制来改善由于文本序列长度的增加而造成编码器层产生的中间语义向量存在信息丢失等问题。现有注意力值的计算主要基于文本序列的注意力分布,通过该分布从而得到文本序列信息的加权平均,将其作为解码器层的输入参数,进行标签序列的生成工作。当前,文本处理领域的注意力值的计算主要基于词粒度,然而现实文本数据中存在大量结构信息,需考虑文本结构信息如何更好地对中间语义向量进行表示。
HAN注意力模型是由Yang等[3]于2016年提出,作者通过考虑文本结构信息,提出一种具有层次化结构的注意力模型,从而更好地对文本语义信息进行表示。文本分类过程中,不同单词和句子对文本信息的表示存在不同的影响,并且同一个单词和句子在不同的语境中也有不同的重要性,因此作者在对单词以及句子建模时分别引入了注意力机制,该模型基于不同句子和单词给予不同的注意力权重,从而得到更好的文本表示。最后作者基于公开数据集对HAN模型的有效性进行了验证,结果显示其提出的模型相较以往的模型效果提升显著。
本文对HAN注意力模型进行改进,通过将多标签文本分类Seq2Seq架构中的编码器层采用HAN模型来进行表示,从而考虑到文本结构化信息对中间语义向量产生的影响,最后由解码器层的状态信息与编码器中以句子为维度的隐层状态信息进行计算,从而获得更好的中间语义信息表示。基于HAN模型的编码器层网络结构如图2所示。
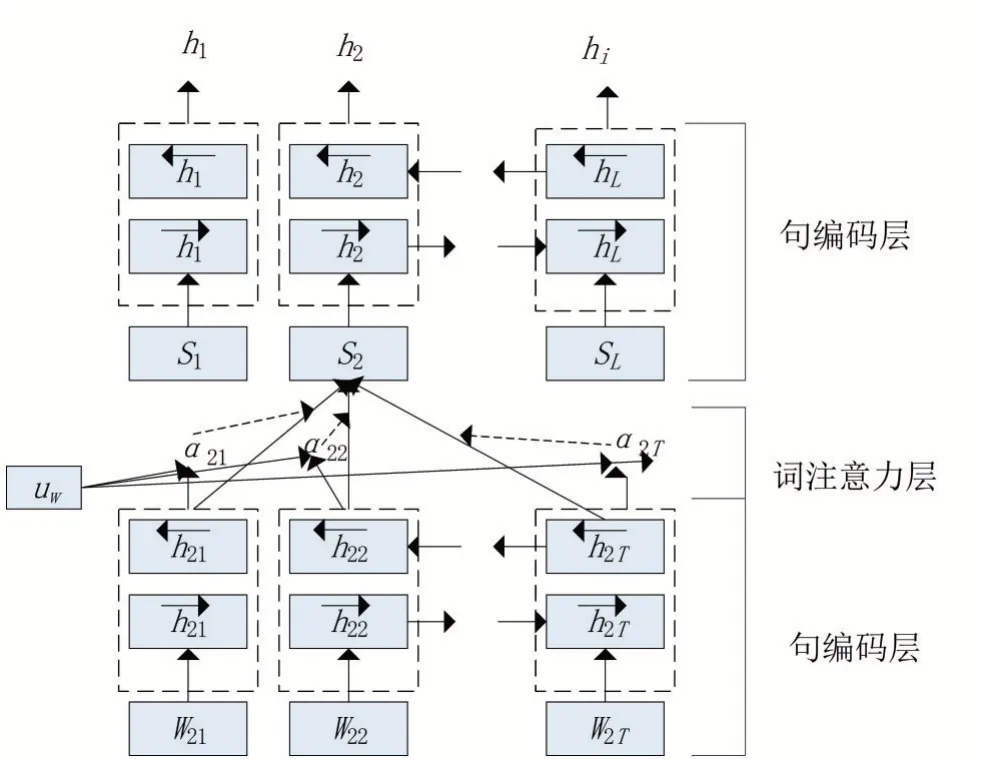
图2 HAN编码器层示意图
如图2所示,该模型结构主要由词编码器、单词级别注意力机制,以及句子编码器所组成,其功能以及过程下面将详细阐述。
2.1 词编码器层
假设一篇文档si由L个句子所组成,给定一个句子包含Ti个单词,wit表示第i个句子中的第t个单词,其中t∈[ 1,T],T表示词典总数。由单词序列组成的句子wit,t∈ [0,T],首先通过嵌入层矩阵we得到xit,xit表示单词wit由one-hot编码到词向量的映射,完成句子中单词对应词向量的映射之后,作为编码器层的输入,为了避免传统循环神经网络处理序列过程中忽略未来上下文信息,本文采用双向LSTM架构作为词编码层的网络结构,通过训练序列向前、向后两个方向的循环神经网络共同决定模型的输出。其中前后两个方向的计算过程由公式(10)、(11)表示。
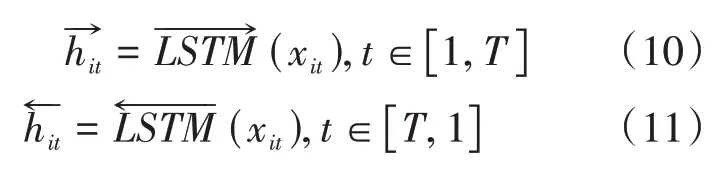
通过将前后两个方向得出的隐藏层状态信息进行关联,从而得到考虑上下文信息之后的隐藏层状态。其过程由公式(12)表示。

2.2 词注意力层
由于一个句子中的不同单词含义并不相同,通过attention机制选择出对句子的含义有重要影响的单词,通过更多关注于这些单词,从而得到句向量更好的表示。首先将句编码器层中不同单词对应不同时刻的隐藏层状态信息hit输入到单层感知机中,得到输出结果uit作为hit的隐含表示。其过程由公式(13)表示。
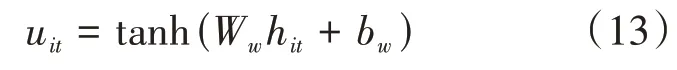
为了衡量不同单词对于句子含义的重要性,本文采用词向量与随机初始化向量uw之间的相似度来进行表示,之后通过对句子中每个单词相似度进行softmax操作,得到归一化向量权重ait,其中ait表示第i个句子中第t个单词的重要程度。其过程可以由公式(14)表示。
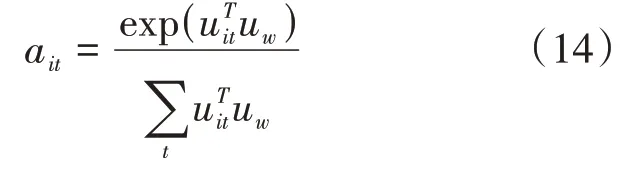
其中ww,uw,b作为模型训练参数,通过训练过程中反向传播算法得出。得到不同单词对应的attenion权重后,可以将句子的向量表示由组成句子的单词进行表示,对应其单词不同时刻的隐藏状态信息加权求和。其过程由公式(15)所示。
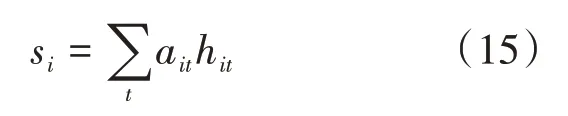
2.3 句子编码器
得到句子向量si的表示之后,采用同样类似的方式得到基于句子粒度的隐藏层状态信息,其中不同句子在不同时刻下隐藏层的状态信息可由公式(16)、(17)、(18)表示。
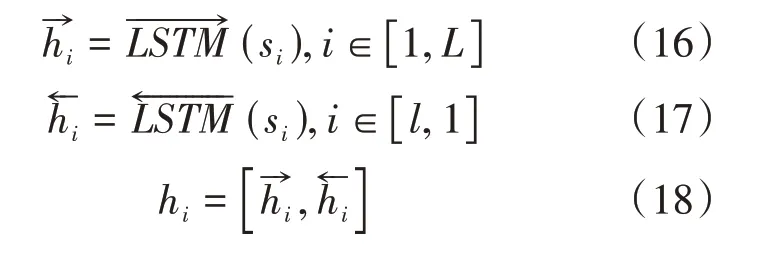
得到不同句子在其不同时刻的隐藏层状态信息之后,解码器在解码过程中,通过解码层中的隐藏层状态信息与编码器中以句子为粒度的不同时刻隐藏层状态信息进行注意力机制的操作,从而从传统关注于词粒度的重要性转化为基于句子粒度的重要性。
2.4 解码限制
由于训练数据的特点或模型参数训练不充分的因素,基于Seq2Seq模型的序列生成过程中,其解码过程会出现重复输出某个字符等问题。机器翻译过程中常常需要考虑到重复字符的出现问题;然而在处理多标签文本分类场景下,通过将多标签文本问题转化为序列生成问题,如果序列生成重复标签,意味着该标签为无用标签。为解决重复标签生成问题,本文拟采用在解码阶段加入限制,来避免重复标签的生成问题。
从公式(20)中可以得出序列生成输出标签的概率分布,通过引入辅助向量vt,其中在t时刻预测输出标签时,如果前面已经预测出了标签li,将li标签对应的vt向量中索引位置i值设置为负无穷大,其余位置为0,通过softmax函数对负无穷的计算结果为0,从而避免解码过程中出现重复标签的问题。

其中vt向量维度对应标签集数量,i表示标签索引。
3 实验验证
3.1 实验数据采集
为了验证本文所提改进算法的有效性,本文采用RCV1-V2数据集[4]。该数据集为开源的新闻故事手工分类而成,可供后续研究者研究之用。其中每个新闻故事可以分配多个主题,总共有103个主题。
3.2 实验结果分析
3.2.1 层次化注意力的影响
为了验证层次化注意力机制对多标签文本分类效果的影响,在生成标签序列过程中的编码器层分别采用使用层次化注意力机制和未使用该机制来进行实验的对比工作。其中基于层次化注意力的改进模型本文简称为HSGM、普通序列生成模型为SGM[5],同时以BR、CC、LP等常见多标签文本分类算法作为参考基准模型。最后基于Hamming-Loss、F1等指标进行模型评估。
在模型训练之前需对数据集进行数据预处理,其中词表大小设置为5000,如果文档中存在词表范围以外的单词,则用“unk”字符进行表示,同时每篇文档由20个句子、每个句子对应20个单词进行文档单词截取或补全。HSGM模型训练的相关参数设置如下:词向量维度为256维,句子向量维度为400维,句子维度为512维,同时以句子为粒度的隐藏层中维度、解码器层隐藏层信息维度分别为256维和512维。词粒度、句子粒度、解码器层均采用双向LSTM网络作为基础模型,之后采用反向传播算法以及随机梯度下降算法对模型进行训练,最终实验结果如表1所示。
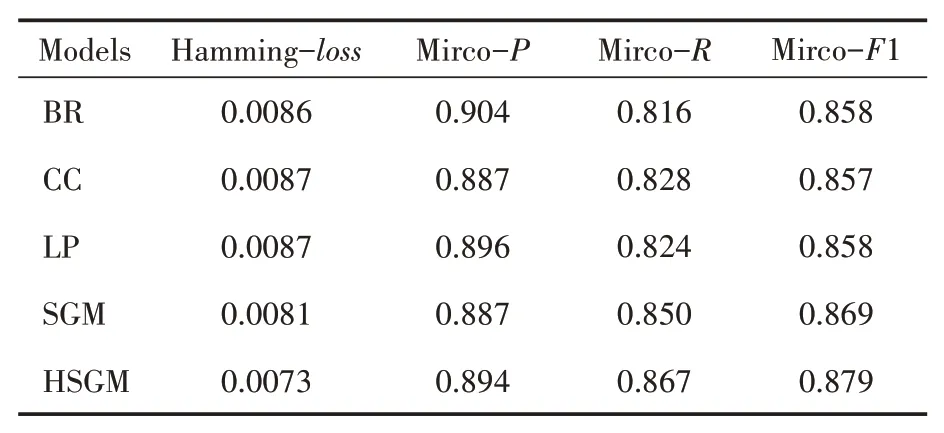
表1 层次化注意力实验对比表
由表1可知,基于传统的BR二分类算法在其精确率以及F1相关指标上表现不错,对比当前常用多标签文本分类算法以及本文提出的基于层次化注意力机制分别在RCV1-V2数据集中通过相关评估指标验证改进算法的有效性,从表中可以得出Mirco-Precision提高了0.7%,Mirco-F1指标提升了1%。从表中可以看出基于层次化注意力机制可以进行更好的中间语义向量的生成,从而提高多标签文本分类的精确率以及F1指标。
3.2.2 辅助向量的影响
为了验证引入辅助向量算法的有效性,本文首先采用经过结构化注意力改进算法的Seq2Seq模型作为分类基础模型。其次,在此基础上通过对比引入辅助向量以及未引入辅助向量来验证辅助向量算法对多标签文本分类结果的影响,定义引入辅助向量的模型为VSGM,最终实验结果如表2所示。
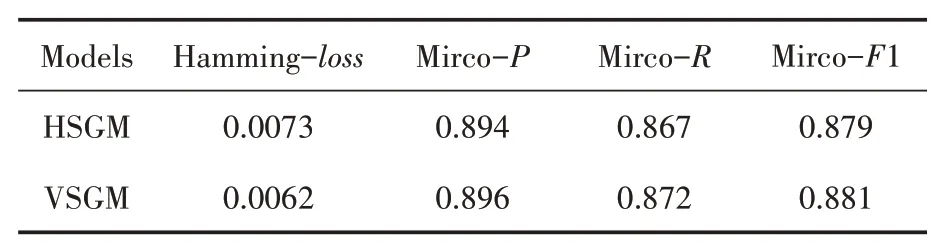
表2 辅助向量实验对比表
通过表2可以看出,引入辅助向量后多标签文本分类指标Hamming-loss降低了0.11%,Mirco-P提升了0.2%,同时Mirco-F1指标提升了0.2%。综上所述,引入辅助向量的方法可以进一步提升分类模型的精确率以及召回率。
4 结语
本文通过借鉴HAN模型的思想将层次化注意力机制运用于编码器层中,将文本结构信息作用于构建隐藏层状态信息的过程中。针对标签序列生成过程中出现重复标签问题,通过引入辅助向量,在解码过程中加入解码限制,有效地避免了重复标签问题。最后基于开源RCV1-V2数据集,通过对比当前常用多标签文本分类算法以及本文所提改进算法的评分指标,验证了本文所提改进算法的有效性。
