四通道无监督学习图像去雾网络
2023-01-09刘威陈成江锐卢涛
刘威,陈成,江锐,卢涛
(1.武汉工程大学计算机科学与工程学院,湖北 武汉 430205;2.武汉工程大学智能机器人湖北省重点实验室,湖北 武汉 430205)
0 引言
图像视觉是人类对外界信息感知的主要来源之一,而雾霭、烟雾等极端环境的影响使采集到的图像和视频质量被严重破坏,造成所含信息缺失、纹理细节模糊以及颜色失真,限制了顶层计算机视觉(目标检测和跟踪、卫星遥感等)领域的发展。因此,图像去雾成为计算机视觉基础任务之一。近几十年来,单幅图像去雾领域吸引大量研究人员进行探索研究,并涌现出许多方法。具体来说,图像去雾方法大致可分为两类:基于图像增强的方法和基于图像复原的方法。
1) 基于图像增强的方法
基于图像增强的方法在不考虑图像退化原理情况下,通过降低图像噪声、增强图像对比度恢复出清晰无雾图像。最具代表性的方法是1964 年Land[1]提出的Retinex 理论,模拟人眼感知的物体颜色和亮度由物体表面对不同波长光线的反射、吸收及透过能力决定。其数学模型表达式为

其中,S(x,y)表示获取的低光照下实际图像,R(x,y)表示场景反射图像,L(x,y)表示照度图像,◦表示逐元素点乘。基于Retinex 理论的图像增强的主要思想是从原始图像S(x,y)中估计出照度图像L(x,y),从而分解出场景反射图像R(x,y)。基于Retinex 理论,黄黎红[2]提出的单尺度Retinex 雾图增强方法,通过增强图像的全局亮度和局部对比度,并对饱和度进行调整,以达到去雾效果,但去雾后的图像出现颜色失真。Yu 等[3]提出的改进多尺度Retinex 雾图增强方法能够有效增强图像内容,以此获得增强后的雾图。Jobson 等[4]提出色彩恢复多尺度Retinex(MSRCR,multi-scale Retinex with color restoration)方法,在光照较暗的环境下能恢复出清晰度高的图像。然而,Retinex 方法只考虑图像阴暗处的增强,而没有对图像明亮处进行处理,明亮区域常常出现光晕现象。直方图均衡化作为一种增强图像对比度的方法,也被运用于图像增强去雾方法的研究。李竹林等[5]对HIS 颜色空间中饱和度分量和亮度分量做自适应直方图均衡化处理,改善了直方图均衡化去雾方法存在的噪声放大和图像失真的问题,获得较好的对比度和边缘细节。Xu 等[6]提出了一种基于对比度受限自适应直方图均衡化的去雾方法,通过最大值裁剪直方图,并将裁剪后的像素平均分配到每个灰度级,在增强对比度的同时抑制噪声。但是,基于直方图增强的去雾方法同样不考虑图像退化原理,容易出现颜色失真和雾残留等问题。
2) 基于图像复原的方法
基于图像复原的去雾方法大多是在McCartney等[7]提出的大气散射模型基础上进行的,主要研究雾图退化的原因。其表达式为
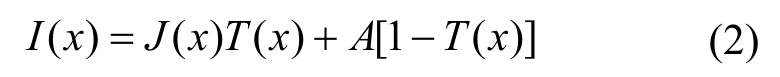
其中,I(x)表示观察到的雾图像,J(x)表示需要恢复的真实场景图像,未知参数A和T(x)分别表示全局大气光值和透射率,J(x)T(x)表示场景光线的直接衰减项,大气光成份A[1 -T(x)]表示间接衰减项。在实际应用中,透射率T(x)通常与场景深度相关,数学模型表达式为

其中,β表示散射系数,d(x)表示目标点到相机镜头的光程距离。图像复原的去雾方法可分为基于先验知识和基于学习2 种。基于先验知识的去雾方法通过先验知识来估计透射率T(x)和全局大气光值A,然后利用大气散射模型(ASM,atmospheric scattering model)进行线性去雾处理。例如,Tarel 等[8]提出了快速图像恢复算法,使用一种基于中值滤波的新算法对雾浓度进行估计。He 等[9]提出了暗通道先验知识,获得真实场景下的去雾结果,但该方法在处理天空区域时容易产生伪影现象。Ju 等[10]通过在ASM 中引入一个新的参数来增强雾图的可见性。然而,这种基于先验知识估计的去雾方式对估计值极其敏感,难以处理分布不均匀的复杂场景中的雾霭。
最近几年,随着神经网络和深度学习的不断发展,基于学习的去雾方法逐渐成为主流。Cai 等[11]最早使用卷积神经网络(CNN,convolutional neural network)对透射率进行估计,利用CNN 提取雾霭特征,解决了手工提取特征的难点。Ren 等[12]提出一种多尺度深度神经网络来学习更多的特征以提高雾天恢复效果。为摆脱对模型参数的估计,Liu等[13]提出端到端的可训练卷积神经网络去雾算法,由预处理、主干网和后处理3 个模块组成。由于雾图相关派生图对雾霭特征具有不同的理解和表达能力,对雾图相关派生图加以充分利用能极大地发挥去雾模型的去雾效果。由此,研究者提出雾图相关派生图融合的方法[14-17]。其中,Ren 等[16]通过融合雾图导出的3 个相关派生图,建立门控融合的去雾方法。
上述方法在图像去雾领域取得了一定的效果,但大多是基于端到端的配对训练。由于真实配对雾图数据集难以采集,大多使用合成雾图进行配对训练,导致这些方法缺乏对真实场景的去雾能力。为此,研究人员从无监督的角度出发,探索在不给定配对数据标签情况下实现雾图清晰化[18-21]。Li 等[18]利用层接纠缠的思想将雾图视为无雾图像层、投射率图层和大气光层的纠缠,提出了零样本的去雾算法。然而,这种零样本的方式产生的每个图层不可控,导致去雾效果较差。Engin 等[20]将循环生成对抗网络(CycleGAN,cycle generative adversarial network)[21]用于图像去雾,提出非配对训练的图像去雾方法,但非配对训练中缺乏像素点之间的约束,造成生成去雾图像质量低。此后,研究者在CycleGAN 框架下进行改进,提出多种非配对去雾方法。Yang 等[22]认为真实场景中的雾霭随着密度和深度变化,提出了一种自增强的图像去雾框架。考虑以上去雾方法存在的问题,本文基于CycleGAN非配对训练的原理,提出了一种四通道无监督学习图像去雾网络。该网络由去雾网络、合成雾网络和注意力特征融合网络3 个子网络,以及判别器网络构成。通过组合3 个子网络构成4 条不同的通道,形成多组对抗损失和循环一致性损失,从而增强网络学习真实雾天数据域与清晰无雾数据域之间的映射关系。本文的主要贡献如下。
1) 提出了一种四通道无监督训练模型实现单幅图像去雾。该模型有效解决了真实配对训练数据获取困难的问题,并且改善了无监督学习中特征提取不精确、生成图像不可控的问题。
2) 提出了特征注意力和通道注意力相结合的注意力特征融合网络,具有自适应地融合雾相关派生图像的能力,从而充分利用不同派生图像之间结构、纹理和色彩信息的自相似性。
3) 通过大量实验说明了本文方法在各种场景中恢复雾图的有效性,与现有最先进的方法相比,本文方法获得了更好的视觉效果和客观评价指标。
1 相关工作
1.1 生成对抗网络
生成对抗网络(GAN,generative adversarial network)由Goodfellow 等[23]提出。通过判别器和生成器两部分,以博弈学习的方式有效学习训练图像的分布,使生成器产生逼真的图像来欺骗判别器。GAN 在合成图像方面取得令人满意的效果,因此在计算机视觉领域被广泛使用。受GAN 生成图像的启发,图像去雾领域也大量使用基于GAN 的变种实现图像复原。Zhang 等[24]提出基于GAN 的联合判别器来细化估计的透射率和去雾图像。Li 等[25]基于条件生成对抗网络(CGAN,conditional generative adversarial network)实现端到端可训练神经网络的雾图清晰化。肖进胜等[26]提出使用生成对抗网络实现雾霾场景图像与清晰图像之间的相互转换。Shao等[27]利用GAN 框架建立的域自适应去雾方法减小合成雾图域与真实雾图域之间的差距,从而提高了对真实雾的去除能力。本文的目标是利用循环非配对训练的框架,实现由去雾网络直接恢复清晰去雾图像。
1.2 注意力机制
注意力机制具有引导深度神经网络关注感兴趣特征而忽略不重要信息的能力,已在计算机视觉和自然语言处理领域广泛应用,在底层视觉任务(超分辨率、低光照增强、去雾和去雨等)中也得到成功应用。Dai 等[28]使用二阶段注意力自适应地调整通道特征,以此获得更具分辨率的表达。Deng等[29]引入注意力融合多个深度模型实现单幅图像去雾。Qin 等[30]提出一种端到端的特征融合注意力网络直接恢复无雾图像,该网络由通道注意力和像素注意力组成。本文目的是探索将注意力机制引入非配对训练网络中,利用注意力机制强大的特征提取能力来自适应地融合生成去雾图和雾派生图,从而有效补偿非配对训练中样本多样性而造成的生成图像不可控性。
2 本文方法介绍
本节将对本文提出的四通道无监督图像去雾模型进行详细介绍,分析去雾网络、合成雾网络、注意力特征融合网络这3 个子网络,以及判别器网络对整体去雾模型结构的必要性和有效性,并分别介绍它们的设计细节。
2.1 总体模型结构
受CycleGAN 使用2 个生成器和2 个判别器实现不同域之间相互转换思想的启发,本文构建如图1所示的四通道无监督单幅图像去雾网络,其中包括3 个子网络,分别为去雾网络GD、合成雾网络GS和注意力特征融合网络FA。顺序组合不同子网络构建以下4 条映射通道:去雾通道,由去雾网络和合成雾网络组成,即GD→GS;去雾结果颜色-纹理恢复通道,由注意力特征融合网络和合成雾网络组成,即FA→GS;合成雾通道,由合成雾网络和去雾网络组成,即GS→GD;合成雾结果颜色-纹理恢复通道,由去雾网络和注意力特征融合网络组成,即GD→FA。本文方法的新颖之处在于通过这4 条通道形成一个相互对抗博弈的学习关系,进而实现从有雾图像域到无雾图像域的映射转换。多通道映射的关系强化了网络的约束能力,使生成图像具有更高清晰度、对比度和更清晰的纹理细节。

图1 四通道无监督单幅图像去雾网络
图1 的右上部分由去雾通道和去雾结果颜色-纹理恢复通道构成,实现对去雾网络GD的约束与优化。去雾通道映射和去雾结果颜色-纹理恢复通道映射分别表示为



同样,图1 的左下部分由合成雾通道和合成雾结果颜色-纹理恢复通道构成,实现对合成雾网络GS的约束和优化,使其产生更加逼真的雾图,从而提高去雾网络GD从雾图域到无雾图域的转换能力。合成雾通道映射和合成雾结果颜色-纹理恢复通道映射分别表示为其中,yr为真实无雾图输入,yr→f和yr→ff分别为GS合成雾图和GD生成的无雾图,为合成雾图yy→f的相关派生图,为2 个不同通道的重构无雾图。同样,合成雾图yr→f与真实雾图xr通过判别器Dff构成另一生成对抗损失,而2 个重构无雾图与真实无雾图yr构成循环一致性fogfree损失,以此来共同对合成雾网络GS进行约束。
2.2 去雾网络
端到端的图像生成算法是图像与图像间内容和风格的转换,CNN 具有学习图像深层特征的能力,通过深层特征对图像风格和内容进行表达,可以实现图像之间的风格转换。本文采用一种新颖的密集连接编码-解码方式实现从雾图到无雾图的转换,去雾网络结构如图2 所示。
图2 中,在编码阶段对输入的雾图采用核为7 × 7和3 × 3的卷积得到初始化特征,2 个卷积的步长为1,滤波器数量为64,然后使用卷积块进行编码。为增加卷积特征信息的流动性,更加有效地利用各层卷积特征,本文采用密集连接[31]的思想来设计卷积块,通过最大池化,3 层核为3 × 3、步长为1 的卷积以及ReLU 激活函数构成密集连接卷积块。其中,最大池化增加了特征感受野。每经过一次卷积块,特征图通道数扩大一倍,尺寸(宽、高)大小缩小一倍。本文使用3 次卷积块进行编码,最终的编码特征图通道为512,尺寸大小为原始输入图的。通常,增加网络层的深度可以提高网络的表达能力,但是,同时也会导致梯度消失。为了避免增加网络层深度而造成梯度消失,本文使用6 次残差块进一步细化编码特征。残差块中使用批归一化(BN,batch normalization)进行标准化。在解码过程中,本文设计的反卷积块由一层核为3 × 3、步长为2 的反卷积,2 层核分别为3 × 3和1 × 1、步长为1 的卷积以及ReLU 激活函数构成。同时,为了能充分利用编码阶段浅层特征包含的纹理细节、色彩信息以及深层特征富含的语义信息,采用跳跃连接拼接编码层特征。每经过一次反卷积块,特征图通道数缩小一半,尺寸扩大一倍。本文使用3 次反卷积块进行解码,最后经一层核为7 × 7、步长为1、滤波器数量为3 的卷积以及TanH 激活函数生成去雾图像。
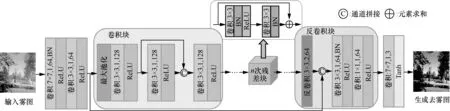
图2 去雾网络结构
2.3 合成雾网络
在本文无监督训练的循环结构下,合成雾图的质量对去雾网络实现从有雾图像域到无雾图像域的转换起到关键的约束作用,并将直接影响去雾网络的去雾图效果。由于真实场景雾霭的分布呈现随机性与非均匀性,难以使用CNN 直接拟合实际场景雾图。例如,Engin 等[20]利用CycleGAN 原理,提出的Cycle-Dehaze 去雾网络模型,使用纯网络来设计去雾生成器和合成雾生成器,但由于CycleGAN 生成图像的不可控,导致最终的去雾效果不佳。本文引入未知参数可训练的大气散射模型对雾图进行拟合,生成雾霭分布最佳的雾图,进而约束去雾网络。如式(2)所示,大气散射模型需要对透射率T和全局大气光值A进行估计,本文的合成雾网络使用参数可训练的方式分别对T和A的值进行估计。合成雾网络结构如图3 所示。
图3 中以清晰无雾图像J为输入对透射率T进行估计。首先,使用ResNet50 预训练模型的前5 层提取初始特征,得到初始特征图。通常,全连接层具有较好的全局语义表达和位置感知能力,而卷积操作能有效提取局部特征。为更加精确地估计透射率,本文结合全连接与卷积操作对特征图信息进行提取。采用全局平均池化代替全连接层,对特征图每个通道进行处理;同时分别使用1 × 1、3 × 3和5 × 5的卷积核对特征图进行卷积操作。接着对不同感受野下的卷积特征进行叠加求和。为了使网络关注卷积求和后的有效信息,最后,将全局平均池化结果与求和结果进行点乘得到最终提取的特征信息,经过3 次核为3 × 3、步长为2 的反卷积,一次核为3 × 3、步长为1、滤波器数量为1 的卷积以及Sigmoid 激活函数处理后生成透射率图T。在全局大气光值的估计方面,本文以输入图像J中每个像素点的RGB 三通道中最大值作为输入,通过6 次尺寸不变的卷积操作和Sigmoid 激活函数获得全局大气光值A。其中,第一次卷积核大小为7 × 7,其余卷积核大小为3 × 3,前5 次滤波器数量都为64,最后输出滤波器数量为1。使用本文合成雾网络生成的透射率图以及对应的合成雾图像如图4 所示,其中,清晰图像来自公共数据集RESIDE。
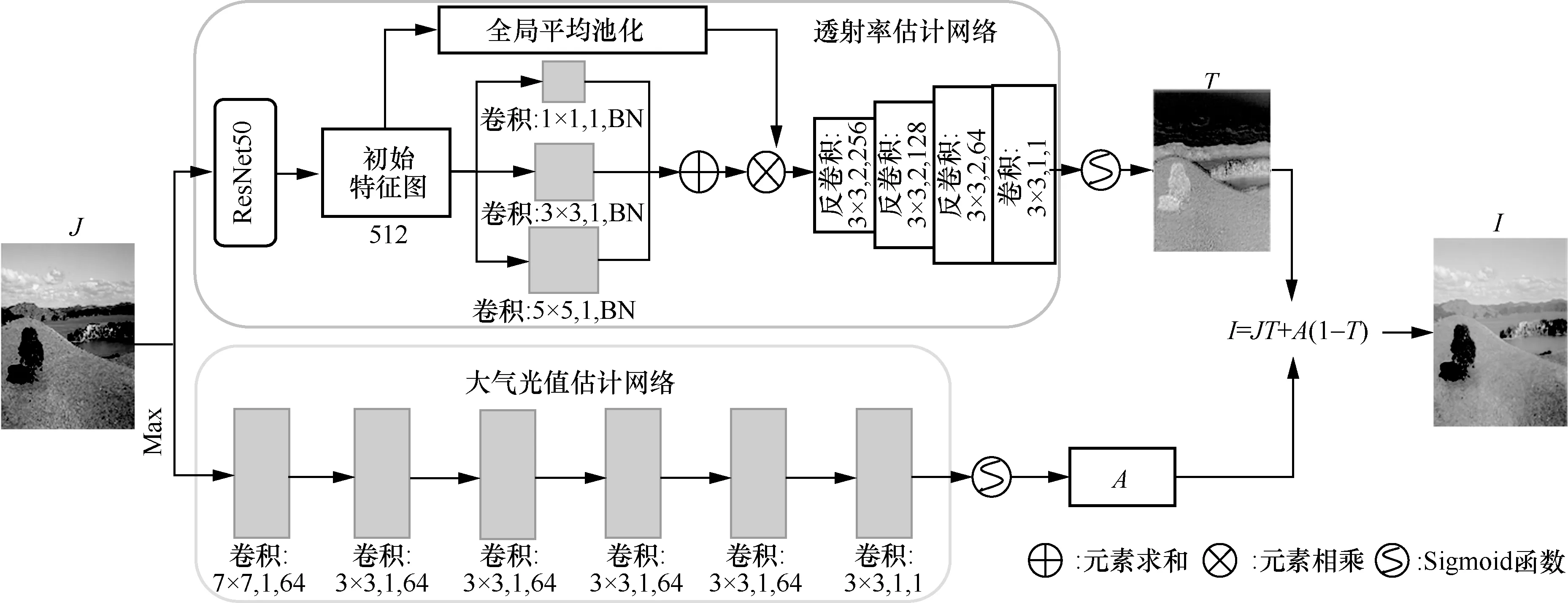
图3 合成雾网络结构

图4 透射率图以及合成雾图像
2.4 注意力特征融合网络
本文设计的多路映射结构是为了增强去雾网络从雾图域到无雾图域的转换能力,而本文提出的注意力特征融合网络是形成多路映射的关键,其目的在于将雾相关派生图的特征融入去雾图像中,以进一步恢复去雾图像的颜色、纹理细节信息。受文献[15-17]的启发,本文采用白平衡图、对比度增强图和伽马校正图作为雾相关派生图像。其中,白平衡图能够恢复场景中的潜在颜色,实现图像精确反映真实场景中的色彩状况。对比度增强图使雾霭区域具有全局可见性,但是容易导致较暗区域趋近于黑色。伽马校正图可以实现增强原始图像的可见度,同时避免出现严重黑色区域。生成去雾图与3 种雾派生图各自含有利于图像清晰化的特征和自相似性上下文信息。本文设计一个注意力特征融合网络来有效地融合这些有利特征以生成清晰去雾图像,注意力特征融合网络结构如图5 所示。

图5 注意力特征融合网络结构
图5 中以去雾网络的去雾图和雾相关派生图作为输入。为了将3 个雾相关派生图中的高对比度、潜在场景颜色信息以及纹理细节传递给去雾网络,本文应用了权重机制。首先,将3 个派生图与生成去雾图进行通道拼接,采用一个核大小为7 × 7、步长为1、滤波器数量为64 的卷积进行初始化;然后,通过使用一组特征注意力模块和通道注意力来自适应学习各输入图的特征权重,由特征权重与对应的输入图相乘,叠加求和后得到融合特征;最后,经过一个核大小为7 × 7、步长为1、滤波器数量为3 的卷积以及激活函数Tanh 生成去雾图像。特征注意力模块的设计如下。首先进行核大小为1 × 1的卷积和批量归一化(BN,batch normalization)处理。引入级联与并联相结合的卷积模式提取特征信息,3 × 3和5 × 5的卷积核具有不同的感受野,通过拼接不同感受野下级联卷积特征,并以核为1 × 1的卷积和批量归一化细化拼接特征。再与初始卷积叠加求和得到有效特征。最后通过2 层核为3 × 3的卷积以及ReLU 和Sigmoid 激活函数自适应生成有效特征的权重,使用此权重与有效特征点乘实现注意力提取有效特征。在特征注意力模块中,所有卷积的滤波器数量都为64,且步长都为1。本文使用3 次特征注意力模块提取输入图的有效特征。对于通道注意力的设计,采用核为1 × 1、步长为1 和滤波器数量为12 的卷积对最终提取的有效特征进行卷积操作;随后使用全局平均池化和最大池化将通道的全局空间特征压缩为2 个不同空间特征表达;接着,将这2 种空间特征表达输入一个含有2 层核为3 × 3的卷积和ReLU 激活函数的共享网络中,得到特征向量输出;最后,使用元素求和合并输出的特征向量,经Sigmoid 激活函数生成各输入图的最终特征权重。
2.5 判别器网络
本文使用了2 个判别器Dff和Df。判别器网络具有分辨真实图像和生成图像的作用,通过判别器构造生成对抗损失可以促进生成网络生成的图像特征信息分布逐渐趋近于真实图像。Dff是用来区分真实无雾图yr和由GD、FA生成的去雾图xr→ff、,而Df是用来区分真实雾图xr和网络GS合成的雾图yr→f。本文判别器网络采用传统CycleGAN中判别器的设计结构,由6 层卷积和一系列BN、ReLU 激活函数组成。其中,从开始到结束每层卷积滤波器数量分别为64、128、256、512、512 和1,并且前4 层步长为2,最后2 层步长为1,所有卷积核的大小都为4 × 4。
3 损失函数
本文基于无监督训练的循环框架实现端到端的图像去雾,为了使网络可控地生成高对比度、颜色保真度和纹理细节清晰的去雾图,本文使用生成对抗损失、循环一致损失和循环一致性感知损失对网络进行必要的约束。
1) 生成对抗损失
本文构建多个生成对抗损失是为了使去雾网络GD和注意力特征融合网络FA生成的去雾图像更接近真实无雾图像域,以及合成雾网络GS合成的雾图更接近于真实雾数据域。其中,判别器Dff旨在对齐真实无雾图像域与生成去雾图像之间的特征分布,而判别器Df旨在对齐真实雾数据域与合成雾图之间的特征分布。去雾网络GD和注意力特征融合网络FA的生成对抗损失分别为
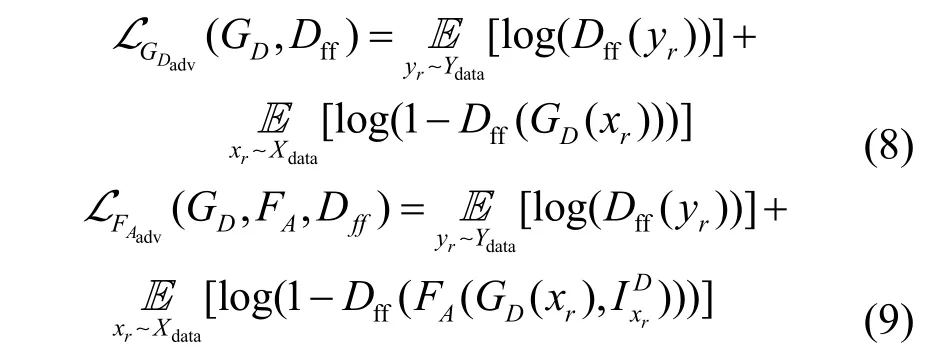
其中,Xdata和Ydata分别为真实雾和无雾数据域,xr和yr分别为真实雾图和无雾图,为雾图xr相关派生图。GS和Df构成的生成雾对抗损失为
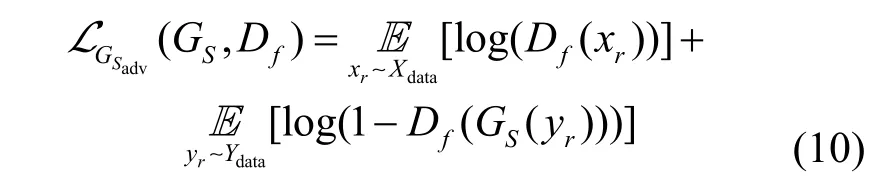
2) 循环一致性损失
生成对抗损失能对特征分布进行约束,但不能实现像素点到点的约束,为保证生成图像在结构特征和纹理细节与原图的一致性,本文引入循环一致性损失。从雾图到无雾图再到重构雾图的循环中,循环一致性fog 损失表示为
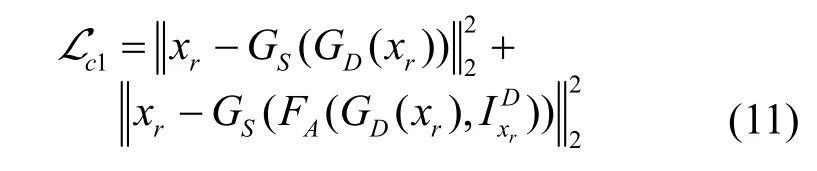
同理,从真实无雾图到合成雾图再到重构无雾图的循环中,循环一致性fogfree 损失表示为
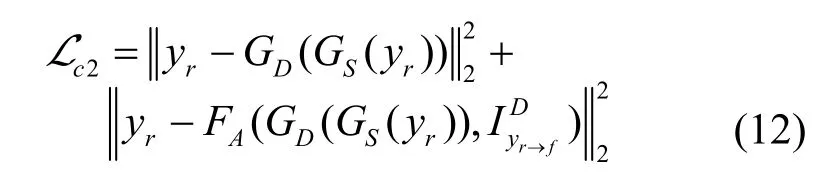
3) 循环一致性感知损失
Engin 等在Cycle-Dehaze 证明,在被浓雾严重损害的图像区域,循环一致性损失不足以恢复所有纹理信息。因此,本文同样引入循环一致性感知损失,从图像特征空间上进行比较,学习雾图中更多的纹理细节信息。本文使用预训练VGG19 的第2和第5 池化层提取浅层和深层特征的组合来保留输入图像结构信息,循环一致性感知损失为
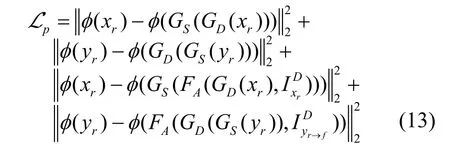
其中,φ表示参数固定的VGG19 的第2 和第5 池化层提取的特征。综上所述,融合生成对抗损失、循环一致性损失和循环一致性感知损失,得到最终的总损失表示为
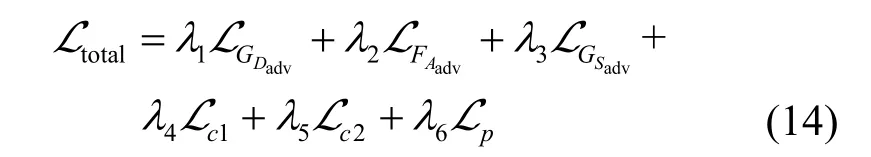
其中,λ1~λ6为正权重。为优化去雾网络模型,最终需使网络满足
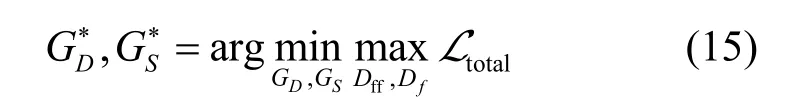
4 实验结果及分析
为了充分说明本文方法的可行性和有效性,本文采用定性主观评价和定量客观评价进行比较分析。在客观评价中,本文采用被广泛使用的峰值信噪比(PSNR,peak signal-to-noise ratio)和结构相似性(SSIM,structural similarity)的有参评价指标,以及Choi 等[32]提出的雾感知密度评估器(FADE,fog aware density evaluator)和Mittal 等[33]提出的自然图像质量评估器(NIQE,natural image quality evaluator)的无参评价指标。其中,PSNR 和SSIM 值越大,表示去雾恢复效果越好;FADE 值越小,表示去雾能力越强;NIQE 值越小,表示去雾图像生成质量越好。本文采用现有最先进的去雾方法DCPDN(densely connected pyramid dehazing network)[24]、DehazeNet[11]、GCANet(gated context aggregation network)[34]、DAD(domain adaptation for image dehazing)[27]、MSBDN(multi-scale boosted dehazing network)[35]、IDE(image dehazing and exposure)[10]、ZID(zero-shot image dehazing)[18]、YOLY(you only look yourself)[19]和D4(dehazing via decomposing transmission map into density and depth)[22]与本文方法进行定性和定量的比较。
4.1 训练和测试细节
本文训练数据集来自RESIDE 数据集[36],其中真实雾图15 000 幅、清晰图像13 500 幅;用于验证的雾图1 000 幅。在网络模型训练中指定图像大小为256 ×256,学习率为 2 × 10-4,批量学习大小(batchsize)为3,迭代次数(epoch)为15,采用Adam优化器。根据经验,本文设置λ1=λ2=λ3=10,λ4=λ5=5,λ6=1。为得到最优的去雾效果模型,在每次迭代中每循环3 000 次进行一次验证,选择最优模型保存。此外,本文采用Pytorch 框架和一块GPU为NVIDIA GeForce GTX 3060 进行72h 训练。需说明的是,本文方法在测试阶段仅需启动去雾网络。
4.2 实验结果
4.2.1 合成雾图去雾结果分析
本文采用 RESIDE 数据集中包含的 SOTS(synthetic object testing set)、ITS(indoor training set)以及Zhang 等[37]提出的HazeRD 这3 个合成雾公共数据集对不同去雾方法进行主观和客观的去雾结果评价。本文方法与其他方法对合成雾图的去雾结果对比如图6 所示。
从图6 的主观视觉分析,DCPDN 方法去雾结果出现颜色失真、边缘信息丢失的现象,而且对雾霭的去除能力弱。DehazeNet 方法有较好的边缘纹理,然而去雾结果残留了大量的雾霭,并且对比度和亮度都较低。GCANet、DAD 和MSBDN 这3 种方法的去雾结果虽然能较好地保留图像纹理细节和色彩信息,但是在处理较浓的雾时依然有雾霭残留(如图6 中最后一行的去雾结果)。IDE 方法的去雾结果呈现较高的亮度,但存在色偏现象,并且表面依然存在一层薄雾。本文方法在有效去除雾的同时保留了较好的纹理细节和颜色信息,且具有高亮度和对比度,去雾结果与清晰图像更加接近。从图6 的有参评价指标分析,本文方法面对不同场景下的雾霭时,去雾结果的PSNR 和SSIM 值都优于其他大部分去雾方法。
为能更加客观表现不同方法的去雾效果,本文定量求解不同方法在SOTS、ITS 和HazeRD 这3 个合成雾公共数据集上去雾结果的PSNR、SSIM、FADE 和NIQE 平均值,结果如表1 所示。从表1中可见,DCPDN 方法在3 个数据集上的所有评价指标都表现较差,印证了图6 中的主观评价结果。本文方法去雾结果的有参评价指标(PSNR、SSIM)和无参评价指标(FADE、NIQE)均优于其他方法。上述主观评价和客观评价的对比充分说明,本文方法在合成雾天数据集中具有较强的雾图恢复能力,并能很好保留原图纹理、颜色和结构信息。

图6 不同方法对合成雾图的去雾结果对比

表1 不同方法在合成雾公共数据集上去雾结果的评价指标
4.2.2 真实雾图去雾结果分析
相比于合成雾图,真实场景中雾霭的分布不均匀,且受各种因素的影响,使成像后的真实雾图难以拟合雾霭分布规律。为说明本文方法能很好地去除真实场景雾霭,本节将使用 5 幅真实雾图(R1~R5)进行去雾性能分析。不同方法对真实雾图的去雾结果对比如图7 所示。从图7 的主观视觉分析,使用DCPDN 方法去雾结果呈现低对比度、低饱和度,且出现区域性变黑(如R1和R2尤为突出)。DehazeNet、GCANet 和MSBDN 这3 种方法对真实场景中雾霭的消除能力较差,去雾后的结果依然存在明显雾霭。DAD 方法能够去除真实场景中的雾霭,但去雾结果整体表现出较低亮度和对比度,视觉感知上效果较差(如R2所示)。IDE 方法的去雾结果有较高亮度,但其容易出现过度锐化(如R2过度锐化)和色偏现象(如R5严重色偏)。对比其他方法去雾结果,本文方法在有效恢复清晰图像的同时保留完整边缘细节和颜色信息,并且在对比度和亮度上呈现出较好的视觉效果。

图7 不同方法对真实雾图的去雾结果对比
从定量角度分析,对不同方法的真实雾图去雾结果进行无参评估,结果如表2 所示。从表2 可以看出,本文方法的去雾结果在FADE 和NIQE 这2 个指标上优于其他方法,表明本文方法对真实雾天具有较强的去雾能力和较好的图像质量恢复能力。

表2 不同方法对真实雾图去雾结果无参评价指标
为了进一步验证本文提出的无监督去雾方法在真实场景中的去雾效果的优越性,本文与近年来最先进的无监督去雾方法进行对比,结果如图8 所示。从图8 可以看出,ZID 方法的去雾结果在颜色和结构上损失严重。YOLY 和D4 方法虽然能够保留完整的纹理结构,但去雾的结果中依然存在大量的雾霭并且对比度较低。本文方法在有效去除雾霭的同时保留了清晰的纹理细节,具有高亮度和对比度。从客观评价指标来看,本文方法生成图像的感知质量也是最优的。

图8 无监督去雾方法对真实雾图去雾结果对比
在实际应用中不同方法模型的参数量和运行速度是衡量其实用性的重要指标,为了说明本文方法在场景应用中的竞争力,本文在测试阶段与多种去雾方法进行模型参数量和运行时间的比较,结果如表3所示。从模型参数量上看,相比于大多数神经网络的方法,本文方法参数量较小。从算法运行时间上看,本文固定输入图像的分辨率为512像 素 ×512像素,本文方法生成每幅图像的运行时间最短。
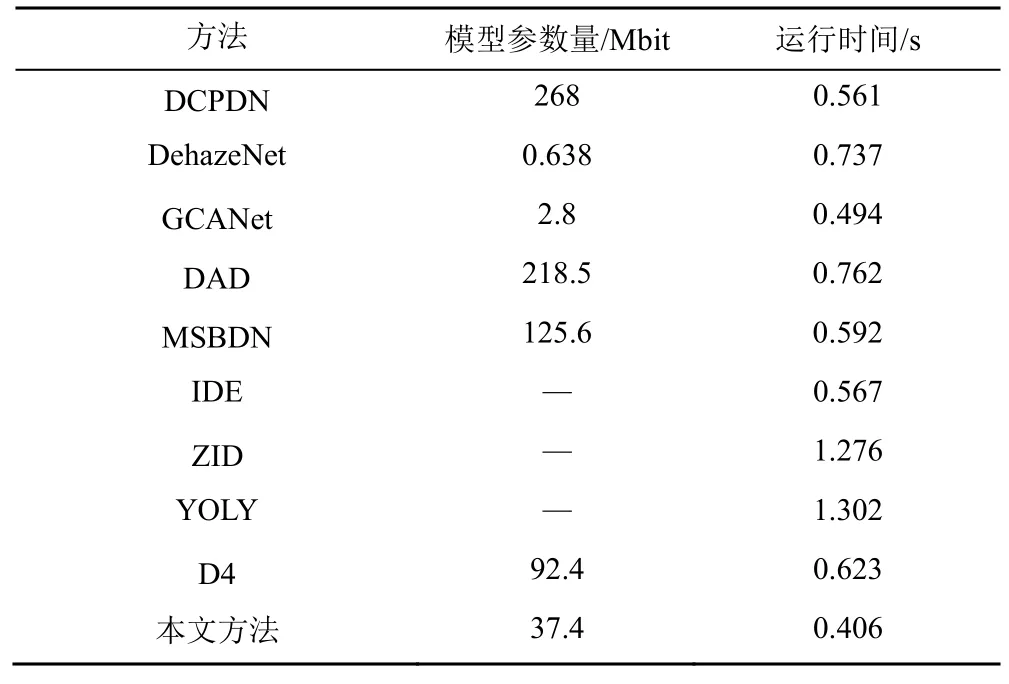
表3 不同方法模型参数量和运行时间对比
4.2.3 消融研究
为了验证本文方法中引入模块的有效性,本节进行消融研究,包括以下5 个实验:实验1,使用传统CycleGAN 生成器网络直接去雾;实验2,在CycleGAN 的基础上引入感知损失函数,即Engin等提出的Cycle-Dehaze;实验3,将实验2 中的生成器网络替换成本文提出的去雾网络;实验4,在实验3 中引入ASM 构成本文提出的合成雾网络;实验5,以实验4 为基础,将本文提出的注意力特征融合网络嵌入去雾网络。消融实验结果如图9 所示,包含2 幅雾图(I1和I2)和5 个消融实验去雾结果图以及对应区域的放大图。
图9(b)仅使用CycleGAN 生成器网络去雾,生成去雾结果整体结构、纹理细节和颜色信息破坏严重(如图9(b)中图I1的放大区域);而图9(c)引入VGG 感知损失后,在色彩恢复上得到极大改善,但缺乏像素级之间的约束,去雾效果呈现出边缘纹理失真现象。图9(d)使用本文提出的去雾网络代替图9(c)中的生成器网络,此网络通过密集和跳跃连接方式在有效提取特征的同时能充分利用网络浅层信息。图9(d)去雾结果的色彩信息和纹理细节的恢复都优于图9(c)。为了进一步优化非配对框架造成的不可控性,在图9(d)的基础上引入ASM 构建一个合成雾网络,进而约束去雾网络,去雾结果如图9(e)所示,图9(e)的边缘恢复以及雾霭的去除程度都优于图9(d)。将本文提出注意力特征融合网络嵌入去雾网络,从图9(f)所示的去雾结果来看,尽管保留了较好的纹理细节,但多种雾图派生图的引入导致雾霭去除效果不佳。由此得出,在双通道的循环框架中添加注意力融合派生图特征对去雾网络起不到约束作用。图9(g)是本文设计的四通道无监督单幅图像去雾网络,主要由密集-跳跃连接的去雾网络、引入ASM 的合成雾图网络以及融合多类雾派生图的注意力特征网络组成。相比于图9(b)~图9(f),图9(g)具有清晰的纹理细节、颜色信息以及高亮度和对比度,从NIQE 评价指标也可看出,本文方法去雾结果的客观评价值是最优的。由此证明了本文提出去雾方法的有效性。

图9 消融实验结果
5 结束语
本文基于CycleGAN 框架提出了一种四通道无监督学习图像去雾网络,有效解决了有监督学习配对数据获取难和无监督学习图像生成质量低的问题。具体来说,为了能更好地约束去雾网络来改善和恢复去雾图像的质量,本文利用去雾网络、合成雾网络和注意力特征融合网络组合成相互约束的4条通道,以此构建多重损失函数。特别在注意力特征融合网络中,本文引入几种雾相关派生图来引导特征-通道注意力关注更多雾图相关上下文信息,从而提高去雾结果的纹理和结构信息。实验表明,本文方法在合成数据和真实场景雾图上都能有效去雾,并且生成去雾结果在纹理细节、对比度和清晰度上相比于现有去雾方法都有所提升。
