一种在线实时微服务调用链异常检测方法
2023-01-09饶涵宇
张 攀,高 丰,周 逸,饶涵宇,毛 冬,李 静
(1.国家电网有限公司信息通信分公司,北京 100031;2.南京航空航天大学 计算机科学与技术学院,南京 211106;3.国网浙江省电力有限公司信息通信分公司,杭州 310016)
0 概述
云计算技术的发展加速了大规模应用迁移上云的进程,极大提升了大规模应用的开发、扩展和运维效率[1]。当前,微服务架构由于在传统面向服务的开发模式上进一步去中心化,因此逐渐成为大规模云应用的主流设计架构[2-3],然而微服务实例之间复杂的依赖关系在增加故障发生频率的同时也加大了故障诊断难度[4-5],尤其当微服务调用拓扑中某一微服务发生故障时,故障会随着调用拓扑扩散,而且微服务间共享CPU、内存等资源也会引发故障传播,即使微服务之间没有调用关系,也可能在较短时间间隔内产生大量异常告警[6]。为避免故障在系统内大范围传播,需要尽快尽早地检测和定位故障发生的根因(Root Cause,RT)[7]。目前,微服务系统的监测数据主要包括关键性能指标(Key Performance Indicator,KPI)、日志和调用链[8]。KPI 数据负责监控系统的资源利用率,例如容器或物理机的CPU、内存以及硬盘等硬件资源利用率[9]。日志主要由代码中的日志输出语句输出非结构化的日志条目,通过日志解析方法抽取为结构化的日志模板后检测系统异常[10]。调用链数据是以类似图的结构记录微服务级别的调用关系、执行路径以及性能参数[11]。目前的微服务性能异常检测方法主要是基于KPI 和日志的异常检测,并且只有小部分研究利用了调用链数据。
微服务调用链异常检测可以在系统发生故障时及早检测出受故障影响的微服务实例,并启动故障根因定位,提高故障应对的响应速度,但微服务之间复杂的调用关系和调用链数据的特性给调用链异常检测带来了很大的挑战。第一,微服务之间的调用不仅包含单个服务内部的互相调用,而且包括服务与服务间的跨服务层调用。第二,同一微服务往往对应不同的微服务实例,为了保障业务的持续性,这些微服务实例通常部署在不同的容器或物理机上,跨容器或物理机的调用可能会引入通信时延。第三,微服务架构应用具有多线程、高并发的特性,一个微服务通常会在同一时刻内调用多个子微服务。第四,应用的不断迭代更新通常伴随着微服务调用拓扑的变化,例如新微服务的上线、旧微服务的下线以及微服务原有调用关系的变化。第五,微服务调用关系中会包含大量递归、循环调用。针对上述问题,一些异常检测方法通过构建调用链知识库[12-14],在检测过程中根据匹配算法将新的调用链与知识库中的调用链作对比,进而检测异常调用链。但是,若应用于存在高并发、循环以及递归调用的大规模微服务系统时,该类方法需要构建规模庞大的知识库,并且此类方法通常将微服务性能异常检测和调用路径异常检测分为两个独立的任务,而衡量微服务性能的响应时间不仅由微服务本身决定,还受其所有的子调用微服务的影响,因而此类方法检测效果不佳。此外,通过调用链匹配来检测异常的方法计算复杂度过高,检测过程耗时过长,因此更适用于离线异常检测,而不适用于对实时性要求更高的在线异常检测任务[15]。为了保证在线检测的实时性,一些基于深度学习的异常检测方法[16-17]被提出,但此类方法通常仅能检测一种类型的异常,容易产生异常的漏报,并且往往忽略了调用链中事件序列的上下文信息,导致难以学习到微服务调用路径与响应时间之间的关联关系,因此效果不佳。
为解决上述问题,受自然语言处理技术在日志异常检测中的成功应用启发[18-20],本文提出一种在线实时微服务调用链异常检测方法MicroTrace,利用基于注意力机制的双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)网络模型学习正常调用链的行为模式。在模型训练过程中,将调用链看作事件序列,对调用链中的事件进行解析,将事件解析为包含调用类型、调用发起网元以及服务网元的事件模板。利用词汇嵌入式表示算法提取调用链中事件序列的上下文信息,获得事件的语义向量表示,将调用链表示为语义向量序列。提取事件中包含的响应时间,获得与语义向量序列相对应的响应时间序列作为微服务性能异常检测的依据。基于语义向量序列和响应时间序列,采用基于注意力机制的BiLSTM 实现同时检测调用路径异常和微服务性能异常。
1 相关工作
1.1 基于调用链知识库构建的异常检测方法
基于调用链知识库构建的异常检测方法[12]主要通过采集系统正常运行下产生的调用链,从而构建调用拓扑知识库。此类方法在检测过程中,利用匹配算法将输入调用链的调用拓扑与知识库作对比,进而判定是否存在异常。MENG 等[12,15]通过构建调用树知识库,在检测时根据限制自上而下映射(Restricted Top-Down Mapping,RTDM)算法[21]计算输入调用树与知识库中所有正常调用树的树编辑距离,从而判定是否存在调用路径异常。该方法同时通过构建响应时间矩阵并基于主成分分析方法实现了微服务性能的异常检测。JIN等[13]提出一种基于鲁棒主成分分析方法的离线调用链异常检测方法,通过构建标准调用树知识库和响应时间矩阵改善了检测精度。CHEN 等[22]通过构建矩阵草图线性重建包含所有微服务正常响应时间的高维空间,实现了调用链中的微服务性能异常检测。LIU 等[8]构建包含所有正常调用路径的知识库,然后人工设计调用链的向量化表示,利用深度贝叶斯神经网络实现了同时检测微服务调用路径异常和性能异常。但是,此类基于知识库构建的异常检测方法存在计算复杂度高、检测耗时长等问题,因此仅适用于离线调用链异常检测任务。
1.2 基于深度学习的异常检测方法
基于深度学习的异常检测方法[16-17]主要利用循环神经网络、深度生成模型等学习正常调用链数据的行为模式,在检测过程中将偏离此模式的输入数据判定为异常。NEDELKOSKI 等[23]提 出AEVB 方法,通过对调用链中的事件分类,将相同类型事件的响应时间组成时间序列,转化为时序序列异常检测问题,但此方法不能发现存在调用路径异常的调用链。BOGATINOVSKI 等[24]提出一种基于自监督学习的异常检测方法MSP,通过训练一个自编码器对输入调用链中随机遮蔽的事件进行重构,在检测时根据重构结果预测调用链中每个位置上可能出现的事件,但此方法仅能检测微服务调用路径异常,忽略了微服务性能异常。BOGATINOVSKI 等[16-17]将 调用链异常检测作为日志异常检测的辅助任务,但都仅利用了调用链中部分信息,因此效果不佳。为了实现同时检测调用路径异常和性能异常,减少异常的误报和漏报,NEDELKOSKI 等[25]提出一种基于多模态LSTM(Multiomodal-LSTM)方法,但此方法忽略了调用链中事件序列的上下文关系,并且模型结构也无法有效学习到微服务调用路径与性能之间的关联关系,因此检测效果不能达到最优。
2 微服务调用链异常检测方法
为了实现在线实时的微服务调用链异常检测,本文提出MicroTrace 方法,主要包含调用链数据解析、事件语义向量化以及调用链异常检测3 个部分。MicroTrace 总体框架如图1 所示。
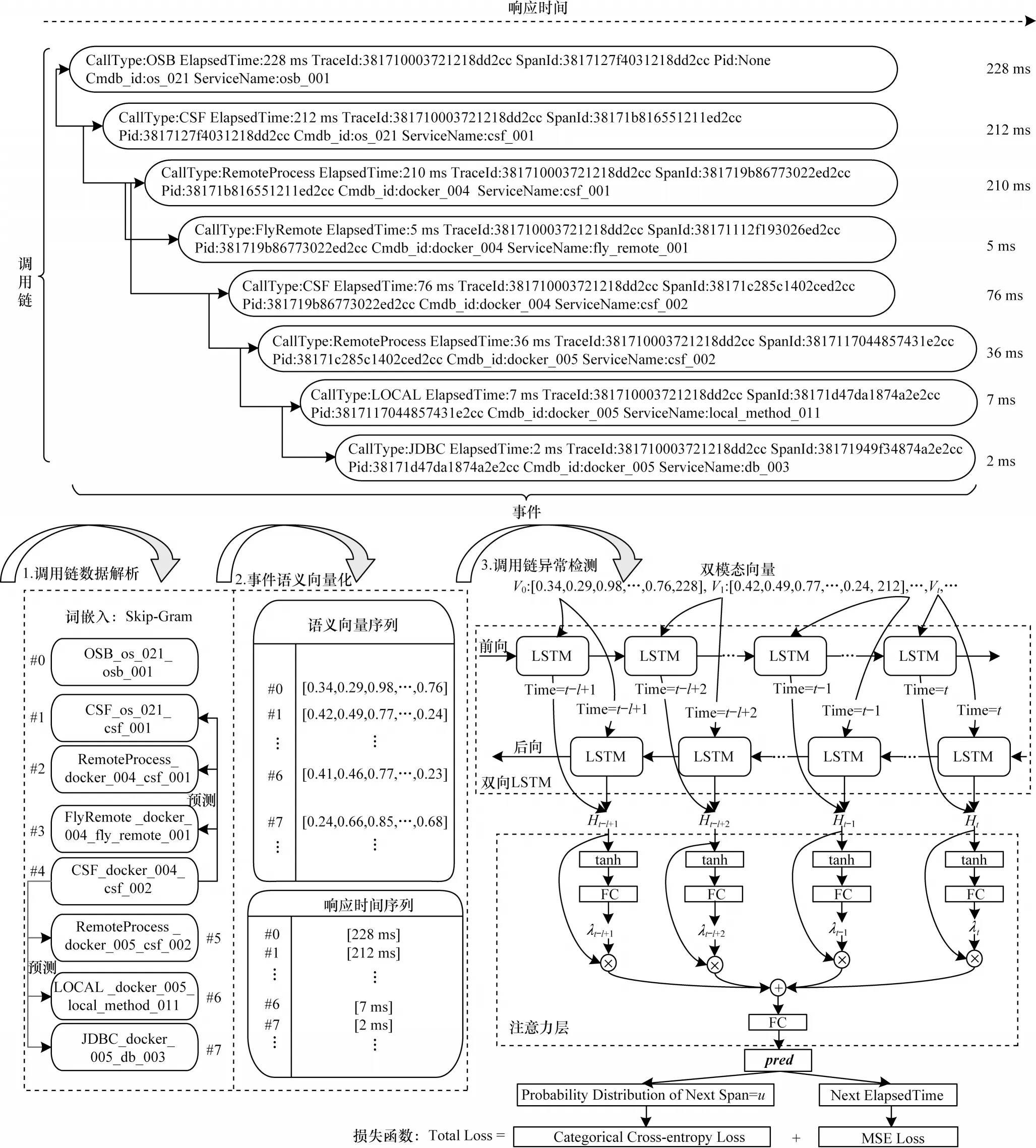
图1 微服务调用链异常检测方法总体框架Fig.1 Overall framework of anomaly detection method for microservice call chains
2.1 调用链数据解析
调用链记录了业务应用内部微服务之间的调用关系以及微服务本身的响应时间。调用链由一系列带有时间戳的event(称为事件)构成[11],表1 为微服务调用链数据示例,给出了一条调用链中的部分数据。本文将调用链T表示为按时间戳StartTime 排序的事件序列[e0,e1,…,eN-1],即T=[e0,e1,…,eN-1],其中N代表调用链T的长度。在表1 中,CallType 代表调用类型,StartTime 代表调用发起时间,即时间戳,ElapsedTime 代表被调用的微服务的响应时间,TraceId 代表此条调用链的唯一标识,SpanId 代表该事件在调用链中的唯一标识,Pid 代表该事件在调用链中的父事件的SpanId,Cmdb_id 代表发起此次调用的网元唯一标识,ServiceName 代表响应此次调用的服务网元(包含微服务和数据库等)。为保证在语义向量化步骤中能以数值向量的形式准确地描述事件的行为,本文采用CallType、Cmdb_id以及ServiceName 3 个字段对事件进行分类,并将上述3 个字段组成正则表达式CallType_Cmdb_id_ServiceName 作为事件类别的标记,称为事件模板。例如,表1 中序号为#0 的事件模板可以表示为OSB_os_021_osb_001。本文还提取出事件中的微服务响应时间并组成响应时间序列[η0,η1,…,ηN-1]。

表1 微服务调用链示例Table 1 Example of microservice call chain
在完成调用链数据解析后,一个长度为N的调用链T就可以被表示为按时间戳排序的两条序列,分别是事件模板序列Tρ=[ρ0,ρ1,…,ρN-1]以及响应时间序列Tη=[η0,η1,…,ηN-1]。
2.2 语义向量化
为了利用事件序列中的上下文信息,本文基于自然语言处理思想,采用词汇嵌入式表示方法Word2vec[26]提取事件序列中的上下文语义信息并将事件模板转换为固定维度的数值型向量(称为语义向量化)。由于事件模板的种类较少,本文省略了原Word2vec 算法中的负采样过程。Word2vec 主要包含跳字(Skip-Gram)模型和连续词袋(Continuous Bag-of-Words,CBOW)模型两类,本文采用跳字模型来实现事件模板的语义向量化,如图2 所示,主要包含事件模板预处理以及语义信息提取两个步骤。
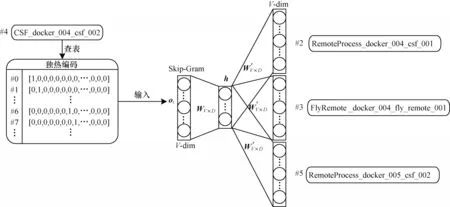
图2 语义向量化框架Fig.2 Framework of semantic vectorization
2.2.1 事件模板预处理
在完成调用链数据解析后会得到一个事件模板集合S={ρ0,ρ1,…,ρV-1},其中V代表事件模板种类。本文利用独热编码(one-hot encoding)将集合S中的事件模板e映射为维度为V的向量o,得到集合S对应的独热编码向量集合O={o0,o1,…,oV-1},其 中oi∈RV,i∈[0,V-1]。
2.2.2 语义信息提取
描述事件模板的语义向量需要满足可区分性和可对比性两个需求。可区分性指语义向量可以高度区分不同的事件模板。例如事件模板CSF_os_021_csf_001 和JDBC_docker_005_db_003 有不同的行为模式,因此两者的语义向量应该具有较小的余弦相似度。可对比性指相似事件应该有相似的语义向量。例如,事件模板CSF_os_021_csf_001 和CSF_os_022_csf_001 不仅在事件的行为模式上相似,在调用链中的位置也经常有交集(两者都经常作为OSB_os_0xx_osb_0xx 的下一个调用),因此两者的语义向量应该具有较高的余弦相似度。为满足以上两点需求,给定一条调用链的事件模板序列Tρ=[ρ0,ρ1,…,ρN-1],通过查询集合O将Tρ映射为To=[o0,o1,…,oN-1],其 中,oi∈RV,i∈[0,N-1]。在跳字模型中,采用一个事件模板ρi预测它的上下文ρb来完成事件模板的语义向量化,具体过程如下:
首先,将ρi对应的oi映射到低维空间中:

其中:h∈RD代表oi的低维表示,且D<V。
然后,根据式(2)和式(3)由事件模板的低维表征h预测ρb:
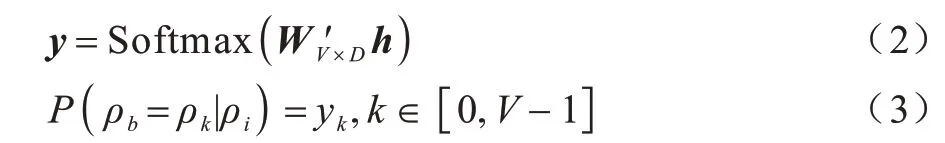
其中:y为跳字模型的输出;P(ρb=ρk|ρi)为跳字模型在给定ρi的条件下,预测上下文ρb=ρk的概率。模型的优化目标为最大化给定事件模板ρi生成上下文事件模板的概率,等同于最小化式(4)表示的损失函数:
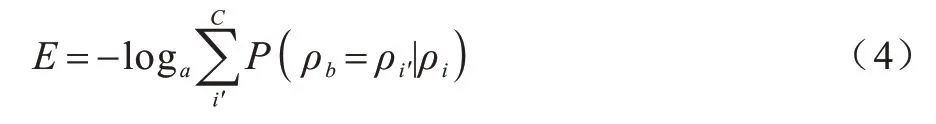
其中:C为ρi对应的上下文事件模板的个数。
最后,在模型收敛后,可由式(5)得到事件模板ρi对应的语义向量vi:

2.3 异常检测
除了微服务之间复杂的调用关系会对调用链异常检测带来困难以外,如何同时检测调用路径异常和微服务性能异常也是调用链异常检测要面临的挑战之一[8],因此本文采用基于注意力机制的BiLSTM作为调用链异常检测的最后一环。在完成数据解析和语义向量化之后,长度为N的调用链就被表示为语义向量序列Tv=[v0,v1,…,vN-1]和响应时间序列Tη=[η0,η1,…,ηN-1],为了同时检测调用路径异常和微服务性能异常,本文将上述序列按元素拼接为双模态向量序列TV=[V0,V1,…,VN-1]作为BiLSTM 的输入,其中Vi=[vi,ηi]。
本文将调用链异常检测建模为下一个事件模板预测以及时序数据预测任务。BiLSTM 接收长度为l的子序列Tl=[Vt-l+1,Vt-l+2,…,Vt]作为输入,从前向和后向两个方向挖掘子序列中包含的信息,并且每个LSTM 块都会输出一个隐向量H。由于不同的事件对于多分类的结果有不同的影响,并且在预测调用链中靠近根节点的事件时,通常要在子序列中填充占位符,因此在得到BiLSTM 的输出后,采用注意力机制自动地为子序列中不同的事件施加不同的权重。
首先,由每个LSTM 块的输出H得到每个时刻事件的权重:
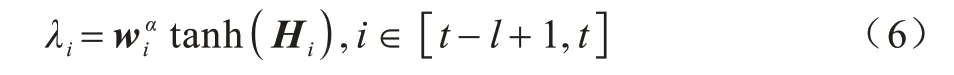
其中:为注意力层中第一个全连接层的参数。
然后,由每个时刻对应的LSTM 块的输出H以及对应的权重λ得到注意力层的输出:
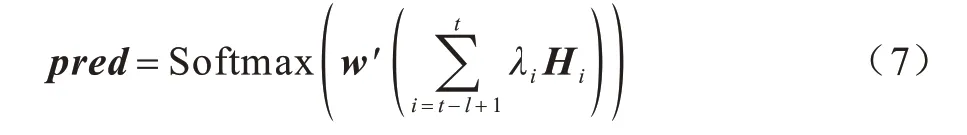
其中:pred=[u,ηpred];w'为注意力层中第2 个全连接层的参数。
最后,将u作为模型输出的事件模板预测结果,ηpred作为模型预测t+1 时刻对应的事件响应时间,即:
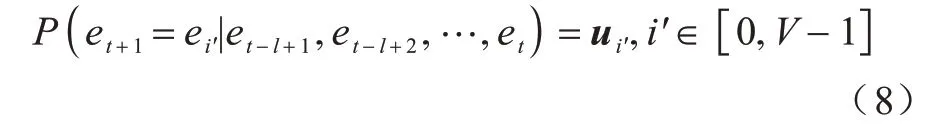
获取在系统正常运行一段时间内产生的调用链数据并将其按照一定比例分为训练集和验证集。在模型训练阶段,同时采用多分类交叉熵损失(针对事件模板预测)以及均方误差损失(针对响应时间预测)之和作为模型的总体损失函数,在此损失函数的引导下采用RMSprop(Root Mean Square Prop)[27]更新模型参数,并对模型参数采用L2 正则化。待模型收敛后,将验证集输入模型中,首先利用模型的响应时间预测值ηpred与t+1 时刻的观测值ηt+1计算均方误差r:

然后计算r的均值μ以及标准差σ,根据坎特立不等式(Cantelli inequality),对于∀ε≥0:
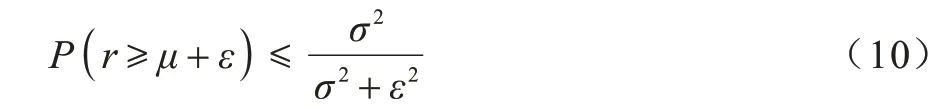
将ε=βσ代入式(10)中得到:

由于验证集中包含的都为正常的调用链数据,因此多数预测值和观测值之间的均方误差r会很接近均值μ,在微服务性能异常检测过程中采用rthreshold=μ+βσ作为判断r是否异常的阈值,如果模型的预测值ηpred与实际观测值ηt+1的均方误差r>rthreshold,则可判断此事件中响应的微服务存在性能异常。
在调用路径异常检测过程中,由于收敛后的模型学习了正常调用链的行为模式,模型的预测值u实际上为在给定历史事件子序列后下一个可能出现的事件的概率分布,因此本文根据模型预测的各事件出现概率大小,选出最有可能出现的m个候选事件,如果实际观测值不在这m个候选事件中,则判断为异常。
MicroTrace 模型训练算法如算法1 所示。
算法1MicroTrace 模型训练算法

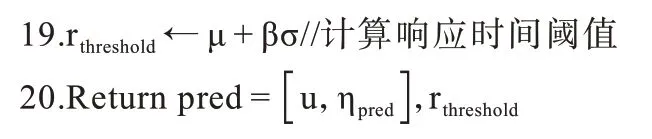
3 实验结果与分析
3.1 数据集
采用AIOps2020 挑战赛公开的预赛数据集,该数据集是由某大型运营商提供的真实数据,共分为黄金业务指标、调用链数据和KPI 数据三部分,其中,黄金业务指标反映了业务系统的整体状态,记录了业务系统的平均响应时间、每分钟接收请求数量、每分钟成功响应请求数量以及响应请求成功率。调用链数据记录了该微服务架构的业务系统中各微服务之间的调用关系和执行路径。KPI 数据记录了物理机、虚拟机和容器的关键性能指标数据,例如内存利用率、CPU 利用率等。本文采用标记为2020_04_20中的调用链数据作为训练集,标记为2020_05_22、2020_05_23 以及2020_05_24 中的调用链数据作为测试集。训练集和测试集的黄金业务指标如图3 所示,其中实线为业务系统的平均响应时间(average_time),虚线为响应请求成功率(success_rate),圆点为故障注入时间节点。从图3 可以看出,在2020_04_20 训练集中系统运行平稳,而在2020_05_22、2020_05_23 以及2020_05_24 测试集中由于故障注入导致系统运行状态产生波动。数据提供方注入故障的类型包括容器CPU 利用率故障、容器内存利用率故障、数据库类型故障以及主机或容器网络类型故障等。测试集的部分故障注入类型以及时间如表2 所示。
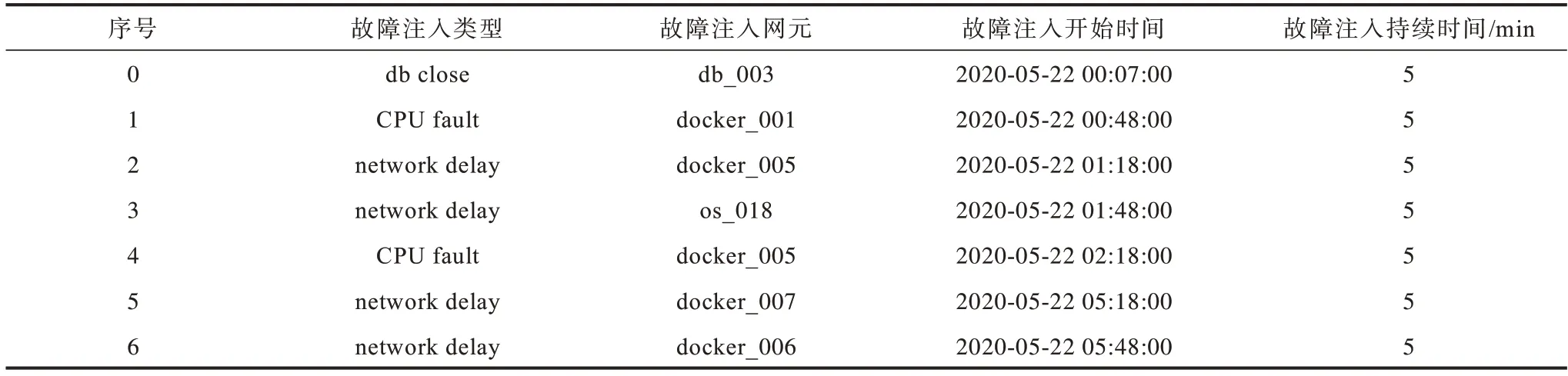
表2 故障注入类型及时间Table 2 Fault injection type and time
3.2 对比方法与评价指标
选取DeepLog_A、MSP[24]、AEVB[23]以及Multimodal-LSTM[25]4 种当前最优方法作为对比方法,其中DeepLog_A 为DeepLog 的变体,为减少计算量,将DeepLog[10]中执行路径异常检测模块命名为DeepLog_A作为对比方法之一。
采用查准率(P)、查全率(R)以及F1 度量值(F)作为衡量检测效果的指标。查准率表示在检测出的异常中真异常的比率。查全率表示在所有真异常中被模型标记为异常的比率。F1 度量值为综合考虑查准率和查全率的性能衡量指标,计算公式如式(12)所示:

3.3 检测效果对比
图4 给出了本文MicroTrace 与4 种对比方法的实验结果。从图4 可以看出,MicroTrace 查准率、查全率以及F1 度量值均达到96%以上,相对于检测效果次优的Multimodal-LSTM 的F1 度量值约提升了6.8%,这主要归因于MicroTrace 利用语义向量化有效提取了调用链数据中事件之间的因果关系,通过异常检测模型充分考虑了微服务的响应时间与调用路径之间的关联关系,同时检测出了调用路径异常和微服务性能异常,然而DeepLog_A、MSP 仅能检测调用路径异常,AEVB 仅能检测微服务性能异常,因此在面对同时存在两种异常的实验场景下检测效果欠佳。
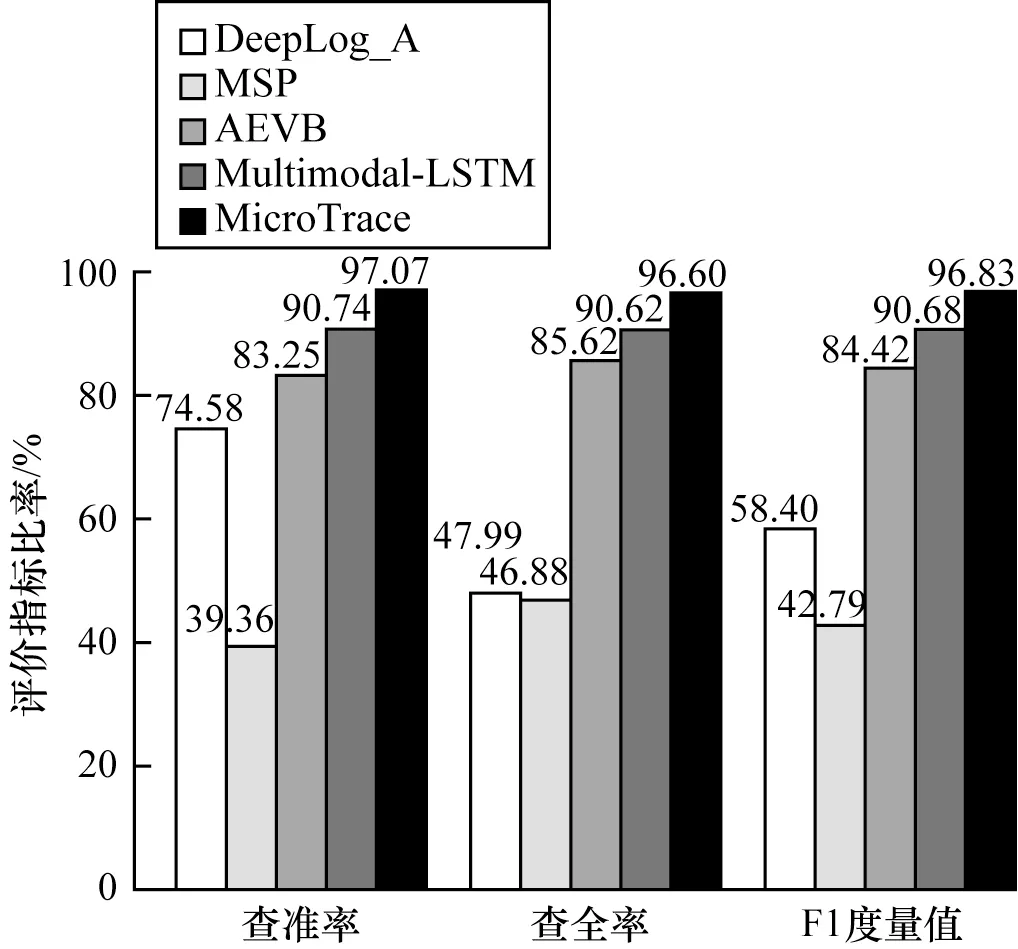
图4 5 种异常检测方法的检测效果对比Fig.4 Comparison of detection effect of five anomaly detection methods
结合图3 和表2 可以看出,在注入db close(关闭数据库)、db connection limit(数据库访问限制)等故障时,系统响应请求成功率会在故障期间降为0。此类型故障可类比于将系统中某一个微服务的所有实例全部下线,从而导致所有需要调用此微服务的调用链被截断,进而产生异常的调用路径。表3 和表4给出了在2020-05-22 00:07:00 向db_003(数据库)注入db close 故障时产生的两种类型的异常调用链的部分信息,分别将其称为AT_1 和AT_2。AT_1 和AT_2 都为系统发生故障时产生的一条完整的调用链,可以从表3 和表4 看出两者都在调用db_003 时发生了截断,导致一条调用链仅包含极少数事件(正常调用链通常包含几十个甚至几百个事件),即产生了调用路径异常。然而将表3 和表4 中的异常调用链和表1 中正常调用链数据相比可以发现,AT_1 中的事件响应时间与正常调用链中的事件响应时间明显不同,而AT_2 中的事件响应时间却和正常调用链中的差距很小,因此如果仅检测响应时间异常,AT_2类型的异常调用链极有可能会被漏报从而导致查全率下降,这也是AEVB 检测效果不佳的原因之一。在注入CPU fault(CPU 类型故障)、network delay(网络延迟故障)等故障时,系统的平均响应时间通常会有较大幅度的增加,并有可能会导致系统响应请求成功率下降,此类故障可能会使系统中产生调用路径正常但响应时间异常的调用链数据,然而仅考虑调用路径异常的检测方法(比如DeepLog_A 和MSP)在面临此类型异常时会产生漏报或误报。MicroTrace 可以同时检测出调用路径异常和响应时间异常,因此在所有方法中检测效果达到了最优。
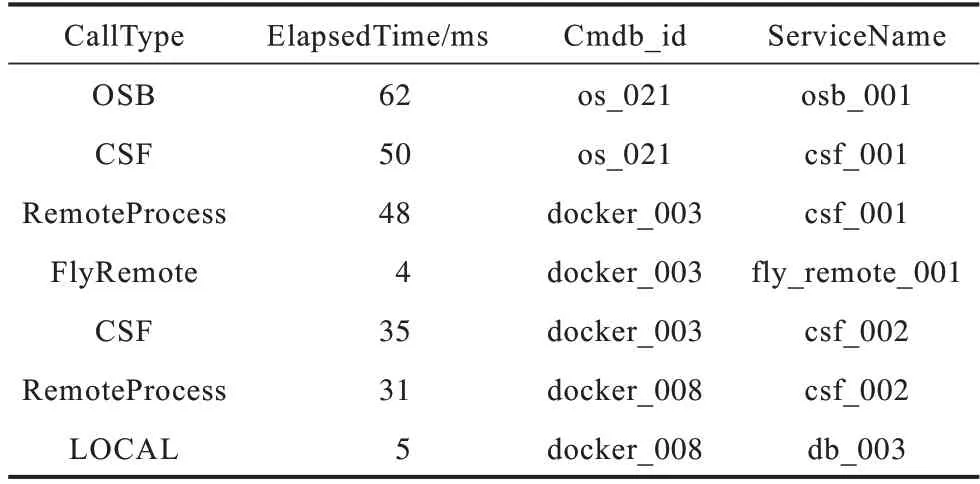
表3 AT_1 异常调用链Table 3 Anomalous call chain AT_1
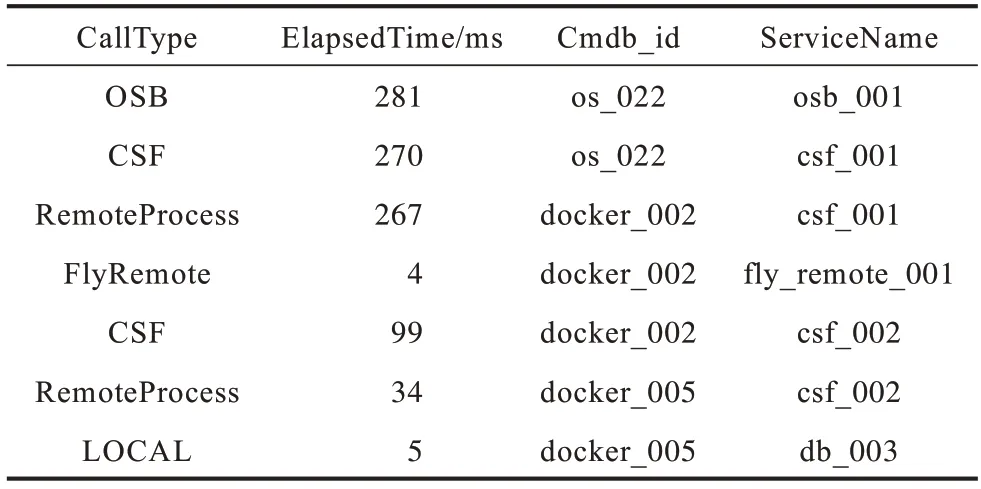
表4 AT_2 异常调用链Table 4 Anomalous call chain AT_2
3.4 模型超参数分析
为验证MicroTrace 对于超参数的鲁棒性,设计模型对于预测候选事件参数m和时间窗口大小l的鲁棒性实验,其中,第1 个实验固定l=10,m∈{7,8,9,10,11,12},第2 个实验固定m=9,l∈{5,6,7,8,9,10},实验结果如图5、图6 所示。
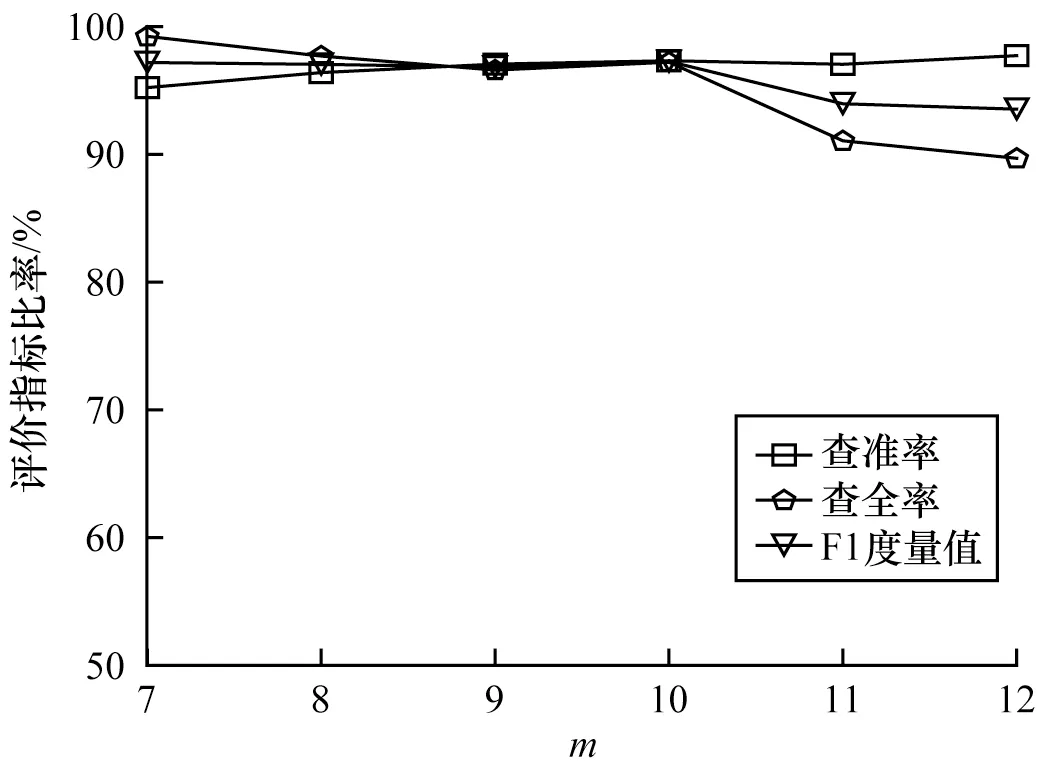
图5 超参数m 的实验结果Fig.5 Experimental results of hyper parameter m
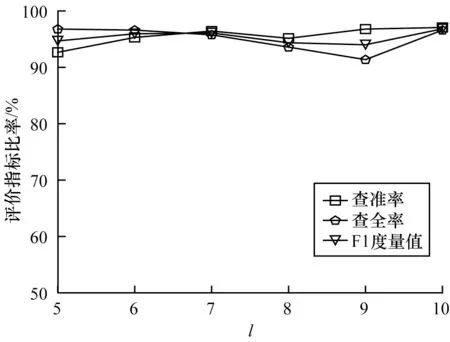
图6 超参数l 的实验结果Fig.6 Experimental results of hyper parameter l
从图5 可以看出,随着m的增加,模型查准率会逐渐上升,查全率会逐渐下降,但F1 度量值波动不大,这是因为随着m的增加模型对调用链中的事件异常行为的容忍度会越来越高,致使检测结果中的假阳性数量减少,假阴性数量增加,导致查准率增大,查全率减小。从图6 可以看出,随着l的增大,模型查准率、查全率和F1 度量值波动不大,证明了本文方法对于超参数的变化并不敏感,具有较强的鲁棒性,便于在真实系统环境中部署。
3.5 消融实验分析
为验证MicroTrace各组成部分对检测效果的影响,设计了该方法的3 种变体,分别命名为MicroTrace_Alpha、MicroTrace_Beta 和MicroTrace_Gama,其 中,MicroTrace_Alpha 相对于原方法仅利用了调用链数据中事件之间的依赖关系来检测调用路径异常,MicroTrace_Beta 相对于原方法仅利用了调用链数据中的微服务的响应时间来检测微服务性能异常,MicroTrace_Gama 相对于原方法删去了事件模板的语义向量化过程,仅采用独热编码对事件模板进行向量化。所有上述方法均采用默认参数,即m=9、l=10,实验结果如表5 所示,其中最优指标值用加粗字体标示。
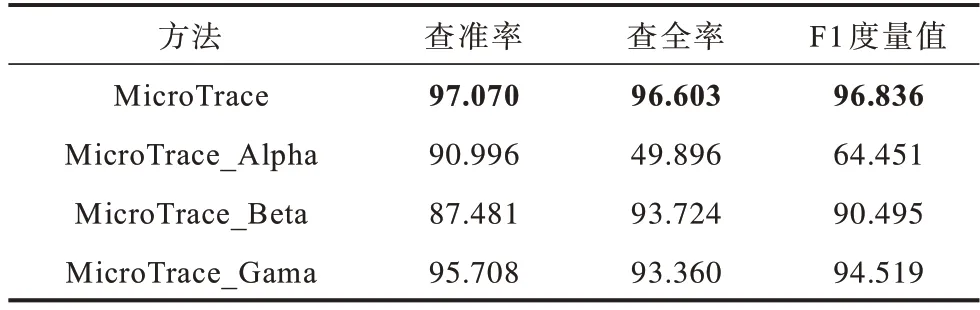
表5 消融实验结果Table 5 Ablation experiment results %
从表5 可以看出,MicroTrace 在查准率、查全率以及F1 度量值上均优于其他变体方法,验证了该方法的各模块对于检测效果的贡献。例如,MicroTrace 的F1度量值相对于其他3种变体方法分别提升了50.2%、7.0%以及2.5%,这体现出同时检测调用路径异常和性能异常的策略可以减少模型的误报和漏报。MicroTrace_Alpha 的检测效果远劣于MicroTrace_Beta,这是因为大部分故障会表现为服务延迟增加或者请求超时[14],即导致调用路径异常的故障通常也会同时表现为性能异常。MicroTrace 相对于MicroTrace_Gama 的检测效果有较小幅度的提升,这证明了在事件模板向量化的过程中考虑事件之间的依赖关系有助于异常检测模型更好地学习到调用路径与响应时间之间的关联关系。
4 结束语
本文提出一种在线实时微服务调用链异常检测方法MicroTrace,将调用链建模为自然语言序列,采用词汇嵌入式表示算法提取调用链中事件序列中的上下文信息,并利用基于注意力机制的BiLSTM 模型学习正常调用链的行为模式,实现了同时检测调用路径异常和微服务性能异常。通过在真实调用链数据集上的实验结果证明了该方法的有效性,相比于现有方法减少了异常的漏报和误报数量。下一步将针对异常的微服务集合研究根因定位算法,并在此基础上设计微服务系统故障诊断闭环解决方案,实现系统故障的自动定位与诊断。
