基于信息熵的联邦学习异常用电识别
2023-01-08杨冠群郑海杰张闻彬汤琳琳王高洲
杨冠群,刘 荫,郑海杰,张闻彬,汤琳琳,王高洲
(国网山东省电力公司信息通信公司,山东济南 250021)
0 引言
随着电力系统信息化水平的提高,电力行业积累了丰富的用户用电数据。然而,由于输变电设备故障、网络波动、用户窃电等原因,用电数据中存在大量异常数据。异常用电数据识别是指利用相关方法从海量数据中识别出异常数据,帮助电力系统工程师快速定位故障原因、发现可疑的用电异常行为,进而提高电力系统的稳定性,避免异常用电行为对企业和社会造成更大损失。
异常用电数据识别是一种典型的二分类任务,即基于给定的用户用电输入数据预测该用户是否为异常用电用户。数据驱动下的异常用电识别已成为当前主流的研究方法,其中包括基于机器学习的识别方法和基于深度学习的识别方法。基于机器学习的识别方法首先从用户用电数据中提取相关特征,然后基于提取的特征构建异常识别模型[1-2]。尽管基于特征分析和机器学习的异常用电数据识别已取得成功,但是特征构建需要专业的知识背景,且手工构建的特征质量对检测结果会造成较大扰动。目前,深度学习技术已成功应用于各个领域,基于深度学习的异常用电数据识别已成为电力行业数据分析的主要手段。与基于机器学习识别方法不同的是,基于深度学习的异常用电数据识别方法从原始的用户用电数据中挖掘潜在的用电模式及其变化规律,不需要额外提取特征,减小了特征提取质量对识别结果的扰动[3]。常用于用户异常识别的深度学习算法包括卷积神经网络[4]、图神经网络[5]、自注意力机制[6]等。
现有基于深度学习的异常用电数据识别方法要求将存储在各个供电公司的用户用电数据汇集起来,进行模型的统一训练。然而,这种方式存在数据隐私泄露、数据传输困难等问题。为了解决该问题,本文提出一种基于信息熵的联邦学习异常用电识别模型。该模型将联邦学习引入到异常用电数据识别模型训练过程中,用于解决分公司之间存在的“数据孤岛”问题。联邦学习模型在训练过程中不需要将各客户端中分散的原始数据收集起来,而是直接在各个客户端进行模型本地训练,只需汇集各个客户端所产生的中间参数,避免了因原始数据传输而出现数据泄露等问题。此外,由于经济发展水平不同,作为联邦学习客户端的各个供电公司中的用户用电数据分布存在差异,可能会给模型性能带来潜在影响。具体来说,在参数聚合过程中,数据质量较高的客户端中间参数对最终聚合参数的贡献较大,反之亦然。为此,本文提出通过k-近邻评估算法计算各个客户端数据集的信息熵。信息熵作为数据集的一种统计量,能够反映该数据集的分布质量,用于表示各个客户端中间参数在聚合过程中对模型最终参数的贡献。
1 相关工作
1.1 基于机器学习的识别方法
基于机器学习的异常用电数据识别方法主要包括聚类分析[7-8]、回归分析、特征分解[9]等。文献[10]提出一种基于回归方法的用电数据异常检测方法,该方法依据完整性、唯一性、一致性、准确性等评价指标对用电数据进行回归分析,实现对停上电数据缺陷进行辨别与处理。文献[11]提出一种基于线性判别分析和密度峰值聚类的双判据无监督异常用电检测模型,该模型遵循“特征构造—维度规约—聚类—异常检测”的流程,借助聚类算法对用电模式不同的用户分类后再进行检测,在维度规约模块使用线性判别分析将用户的台区号输入检测模型,提升了模型的检出率和精确率;在异常检测模块设置双判据检测标准,减小了模型对参数摄动的敏感程度。文献[12]针对无大量已知异常用电用户样本的情况,提出一种基于改进模糊C 均值聚类的窃电行为检测模型,该模型首先通过因子分析对用户用电特征(包括用电负荷数据和电能表异常事件)进行维度规约,提升模型检测效率,再利用遗传模拟退火算法对模糊C 均值聚类算法进行改进,进而实现对用户用电特征进行检测。文献[13]针对异常用电行为的时频特性往往具有强随机不确定性的情况,提出一种基于经验模式分解的异常用电检测方法,该方法首先进行相关特征筛选,然后对用户用电量和线损电量序列进行自适应分解,提取高频分量,通过对其变化趋势和相关性进行分析,实现对异常用电行为的检测与识别。
1.2 基于深度学习的识别方法
随着神经网络的发展,深度学习技术在众多领域得到了广泛应用,例如自然语言处理[14-15]、推荐系统[16-17]、计算机视觉[18-19]等。对于异常用电数据识别任务,深度学习方法逐渐得到重视。例如,文献[20]针对电网中的用电异常行为,提出一种基于时间卷积网络的端到端用户用电异常检测模型,该模型主要包括数据预处理、卷积操作、残差连接等模块。通过在真实数据集上对模型性能进行验证,结果表明该模型表现优于支持向量机、逻辑回归等传统检测方法。文献[21]提出一种基于强化学习的异常用电判决方法,该方法首先获取分类器输出的数个用户短期行为的异常概率,然后输入到强化学习模型深度递归Q网络中,实验结果表明,该模型具有较好的泛化性能。文献[22]提出基于实值深度置信网络的用户侧窃电行为检测模型,该模型首先利用因子分析进行数据降维,利用随机欠采样和套索算法应对数据不平衡问题。同时该模型为了优化实值深度置信网络因随机初始化产生的局部最优化问题,通过萤火虫算法对网络参数进行全局寻优。文献[23]提出基于数据内在特性和长短期记忆神经网络(Long Short-Term Memory,LSTM)的用户用电数据异常检测算法,该算法使用多层LSTM神经网络实现高维数据特征提取,从而提高了异常用电数据识别的准确率。文献[24]提出一种基于主成分分析和深度循环神经网络的异常用电行为检测方法,该方法首先利用核主成分分析方法对电力负荷数据进行降维,生成主成分特征子集,然后基于LSTM和门控循环单元构建深度循环神经网络模型,用于检测异常用电行为。
然而,以上方法在构建模型时,都未考虑对用户用电数据隐私进行保护。本文通过引入联邦学习方法,进行基于信息熵的联邦学习异常用电识别研究,弥补了现有方法存在的隐私性问题,同时提出利用信息熵估算算法改进联邦学习中的梯度聚合,以提高模型准确性。
2 模型设计
如图1所示,该模型主要包括以下3个模块:
(1)基于Transformer 的客户端模型训练模块。基于各个客户端分布式存储的私有数据,分别在各个客户端训练Transformer 异常识别神经网络模型,并且不同客户端中的Transformer 神经网络具有相同的拓扑结构。
(2)基于差分隐私算法的客户端梯度上传模块。利用局部差分隐私算法,将各个客户端的Transformer 异常识别神经网络参数的梯度进行加密,并上传到服务器端中。与上传模型参数不同的是,上传参数梯度需要传输的数据量少,具有更高的通信效率。
(3)基于信息熵加权平均的服务器端梯度聚合模块。在服务器端对来自不同客户端的模型参数梯度进行基于信息熵的加权平均聚合,得到包含各个客户端训练信息的聚合梯度。基于得到的聚合梯度对模型参数进行更新,随后将服务器端更新后的模型分发到各个客户端中,替换原有的神经网络模型。
重复以上步骤(1)-(3),直至模型收敛,完成最终的异常用电识别模型构建。

Fig.1 Information entropy-based federal learning model for identifying abnormal electricity consumption图1 基于信息熵的联邦学习异常用电识别模型
2.1 基于Transformer的客户端模型训练
Transformer[25]神经网络模型以其强大的序列建模能力在众多任务上得到了广泛应用。在客户端模型训练过程中,选择Transformer 作为异常用电识别神经网络,用于建模用户用电序列。Transformer 神经网络拓扑结构如图2所示。
在第n个客户端中,用户u的用电序列记为X=[x1,x2,…,xl,…,xL]∈RL×D,其中L表示用电序列长度,D表示特征维度。Transformer 中的注意力机制采用查询—键—值(Query-Key-Value,QKV)模式进行注意力得分计算。对于输入序列X,首先对其进行线性变化,将其映射到不同的向量空间中,即:
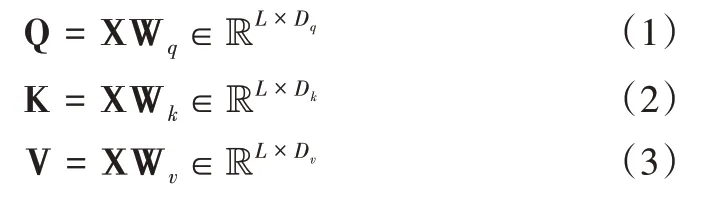
式中,Wq∈RD×Dq,Wk∈RD×Dk,Wv∈RD×Dv分别为查询—键—值的线性映射参数矩阵,且Dq=Dk=Dv;Q、K、V分别为查询矩阵、键矩阵、值矩阵。采用缩放点积的形式进行注意力计算,即:
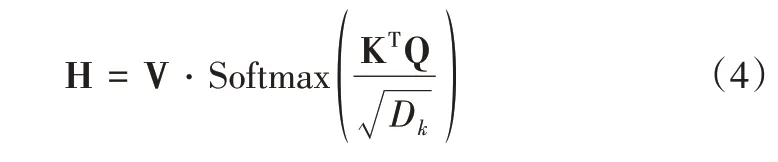
式中,Softmax(·)表示归一化函数,H 表示注意力机制的输出矩阵。在多头注意力机制中,假设有H 个头,则多头注意力机制的输出如下所示:
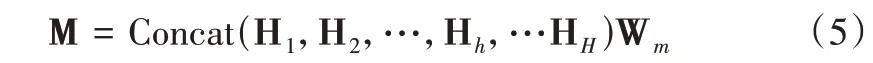
式中,Concat(·)表示向量拼接操作,Hh表示第h个注意力头的输出向量,Wm表示训练参数,M 表示多头注意力机制的输出矩阵。为避免模型在训练过程中出现梯度消失的情况,将残差连接和层归一化作用于M,即:
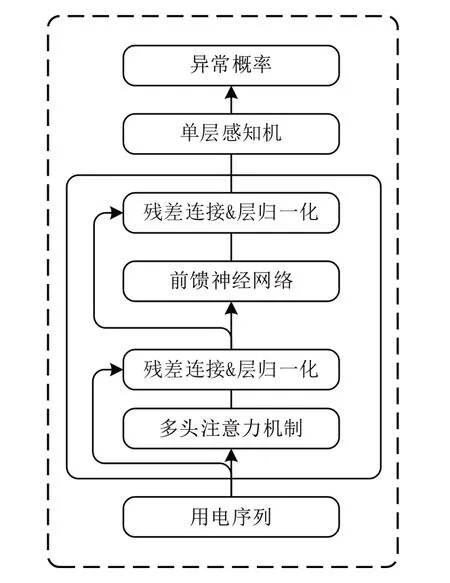
Fig.2 Transformer neural networks图2 Transformer神经网络
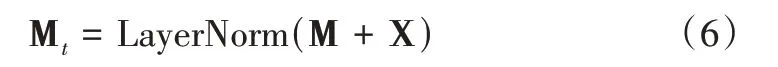
式中,LayerNorm(·)表示层归一化操作,Mt表示中间向量。如图2 所示,前馈神经网络用于解决层数加深所带来的信息损失问题,即:
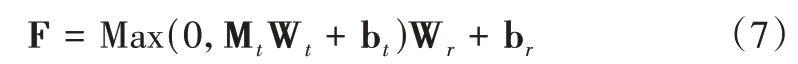
式中,Wt、Wr、bt、br表示可训练参数,F 表示前馈神经网络输出矩阵。之后再次进行残差连接和层归一化操作,即:
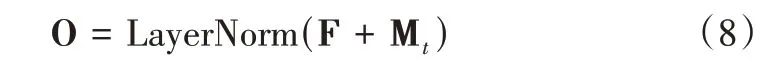
式中,O 表示经过残差连接和层归一化之后的输出矩阵。将其输入到输出层为1 的单层感知机中,对用户用电序列输出矩阵进行压缩,得到用户表示向量如下:
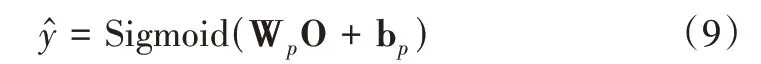
式中,Wp、bp表示可训练参数表示输入用户用电序列所对应的异常概率值。在模型训练过程中,给定预测的异常概率值和真实值y,本文采用交叉熵损失构建以下优化目标函数,即:
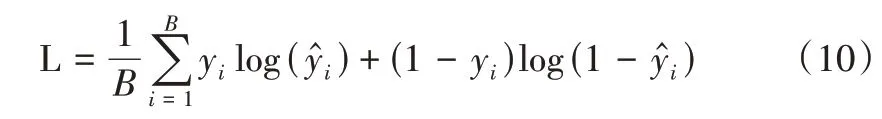
式中,B表示客户端训练批大小,L 表示损失值。
2.2 基于差分隐私算法的客户端梯度上传
客户端梯度上传是指将各个客户端中的模型参数梯度通过加密后上传到服务器端,用于梯度聚合和模型更新。与传统方法所要求的数据集中式存储不同的是,基于联邦学习的方法只需要服务器端收集加密之后的模型参数梯度,原始数据依旧分布式地存储在各个客户端,不进行原始数据传输,从而大大提升了通信效率与安全性。以客户端n为例,根据公式(10)计算其损失值Ln,客户端中Transformer 神经网络模型的参数集合记为Φn=,则客户端n的模型参数梯度gn可通过以下方式计算:

对于梯度gn,本模型采用局部差分隐私(Local Differential Privacy,LDP)[26]方法进行梯度加密,以保证上传梯度的安全性。局部差分隐私方法通过在模型参数上添加满足差分隐私的噪声数据,以实现联邦学习中的隐私保护目的。局部差分隐私是建立在严格数学理论基础上的强隐私保护模型,目前已成为联邦学习研究工作中一种主流的参数加密手段,其有效性得到了广泛认可[27]。LDP 加密方式可表示成以下形式:
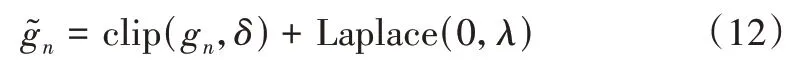
式中,clip(gn,δ)利用缩放系数δ限制梯度gn的大小,以避免出现梯度爆炸的情况;Laplace(0,λ)表示均值为0的拉普拉斯噪声,其中λ用于控制所施加噪声的强度。联邦学习中的差分隐私算法通过向梯度添加噪声,不仅可保证梯度在传递过程中不被逆向破解,保证梯度的安全性,而且可将其看作一种梯度噪声注入正则化手段,防止模型出现过拟合现象[28]。之后将客户端n中加密后的梯度上传到服务器端用于梯度聚合。
2.3 基于信息熵加权平均的服务器端梯度聚合
服务器端梯度聚合是指将客户端上传到服务器端的加密梯度按照某种方式聚合起来,以获取包含全局梯度信息的聚合梯度,用来进行梯度更新。联邦学习的性能很大程度上取决于聚合策略。目前,研究者大多使用FedAvg[29]模型中的梯度聚合策略,即:

式中,wn表示第n个客户端上传的参数,|Dn|表示第n个客户端中数据块n的数据量,|D|表示全局数据量,w表示聚合之后的全局模型参数。
由于气候差异、消费水平及用电习惯的不同,作为联邦学习客户端的各个供电公司中的数据质量存在差异,呈现出非独立同分布的特点(Non-Independently and Identically Distributed,Non-IID),导致各个客户端训练出来的模型性能也有所差异。如式(13)所示FedAvg 模型中的聚合策略仅根据各个客户端上的数据量与全局数据量之间的比值确定其参数在聚合过程中的权重,即数据量越大,该客户端贡献越大。然而,客户端的数据量无法反映该客户端中的模型性能,依据数据量比值确定其聚合权重,存在一定的不合理性。通常情况下,数据集的样本分布情况往往反映出数据质量,样本分布规律性越强,数据质量越高,进而训练出的模型性能越好[30]。
为解决上述问题,提出利用信息熵估算算法量化各个客户端中的数据分布情况。信息熵是一种常用的衡量给定变量分布规律的统计量。如图1 所示,本模型采用Kozachenko-Leonenko k 近邻算法[31]估算数据集的信息熵,具体计算公式如下:

式中,εi是客户端n中样本ti到其第k个邻居的欧式距离,本模型中k取为1;样本ti为客户端n中第i个用户(样本)用电序列的向量均值;D为样本特征维度;M为样本数量;cD=πD/2Γ(1 +D/2),其中Γ(·)为Gamma 函数;ψ(·)为Digamma 函数;Hn为估算得到的客户端n数据集的信息熵。Γ(·)和ψ(·)函数定义如下:
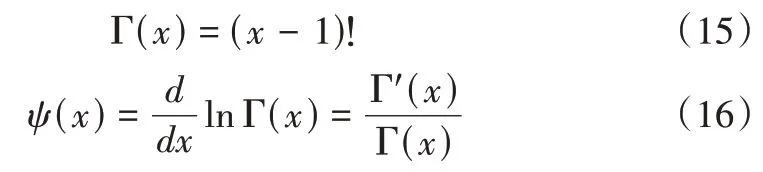
信息熵越小的数据集,数据混乱程度越低,样本分布规律性越强[32],进而训练出来的模型性能越好,其模型参数聚合权重越高。因此,利用信息熵的倒数对相应客户端的梯度进行加权聚合,聚合公式如下:
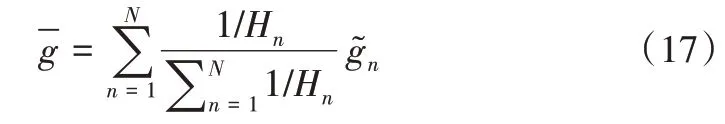
在服务器端中维护一个与各客户端具有相同网络拓扑结构的Transformer 模型,该模型中的可训练参数集合为Φs。服务器端参数更新是指利用聚合梯度对可训练参数集合Φs进行更新,更新方式如下:

式中,η表示学习率。将更新后的模型参数Φs更新到服务器端的模型中,并将更新后的模型分发到各个客户端。客户端中更新后的模型会基于本地数据进行新一轮迭代训练。重复上述步骤直至模型收敛,完成模型训练。训练完成后,基于服务器端中更新的模型进行异常用电数据识别与模型性能测试。
3 实验验证与分析
3.1 数据集介绍
本文在真实数据集上进行实验,以验证所提出方法的有效性。数据集来自于某电力总部的用户用电信息采集系统,数据统计如表1所示。
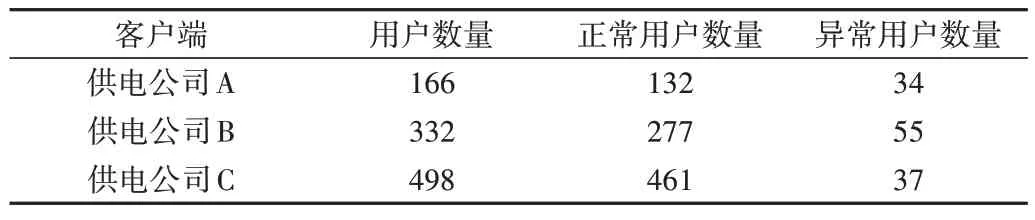
Table 1 Dataset description表1 数据集介绍
从系统中抽取来源于3 个不同供电公司共计996 个用户(包括126 个异常用户,870 个正常用户)的用电数据,采集频率为24 次/天,采集范围为2019 年9 月1 日-2019 年9月14 日,因此用户序列长度为336。序列数据特征包含温度、风速、人口数、用电功率、电压等信息,共计32 个特征维度。训练集和测试集的比例设置为3:1,即将各个客户端中的数据按照3:1 的比例划分为训练集和测试集。随后汇总各个客户端中的测试数据,将其输入到服务器端训练好的模型中进行模型性能测试。
3.2 基线模型介绍
为验证本文方法的有效性,本实验选择7 个常用的异常用电用户识别模型作为基线模型与本文方法进行对比。基线模型包括LDA+DPeaks[11]、FCM[12]、EMD[13]、TCN[20]、DRQN[21]、RDBN[22]、LSTM[23]。其中,LDA+DPeaks、FCM、EMD 为基于机器学习的异常数据检测模型,TCN、DRQN、RDBN、LSTM 为基于深度学习的异常数据检测模型。为全面评价模型性能,本实验选用5 个评价指标对模型性能进行验证,分别为:正确率(Accuracy)、召回率(Recall)、F1值、受试者工作特征曲线下面积(AUROC)与精确率—召回率曲线(AUPRC)。为保证实验结果的准确性,本文在测试数据集上对每个模型进行了5 次实验,实验结果取平均值。
3.3 实验设置
实验运行环境如下:操作系统为Ubuntu 18.04.3 LTS,随机存储器(RAM)为128 GB DDR4@3200MHz,中央处理器(CPU)为Intel(R)Core(TM)i9-9980XE CPU @ 3.00 GHz,图形处理器(GPU)为2*NVIDIA TITAN RTX,主要环境库为Scikit-learn 0.22、Python 3.7.0、Pytorch 1.10.1、Numpy 1.21.2、Pandas 1.1.5。
实验超参数设置如下:序列长度为336,迭代次数为1 000,训练批大小为100,学习率为0.000 1,特征维度D、Dq、Dk、Dv为32,多头注意力机制头个数为4,缩放系数为0.005,噪声强度为0.015。部分超参数采用网格搜索方式确定。
3.4 实验结果分析
实验结果如图3、表2 所示。图3 展示了各个客户端中模型训练损失值变化曲线及其平均值曲线,表2 展示了本文模型与多种基线模型在5 种不同评价指标下的异常用电用户识别性能。
从图3 可看出,当更新次数达到200 次时,模型趋于收敛,此时模型在训练集上达到最优性能。从表2 可看出,本文模型在5 个指标上均达到最优性能,其中Accuracy 为0.958 2,Recall 为0.454 3,F1 为0.535 4,AUROC 为0.692 6,AUPRC 为0.358 1。具体来说,以LDA+DPeaks、FCM、EMD为代表的机器学习异常用电检测模型相对于TCN、DRQN、RDBN、LSTM 深度学习模型而言,缺乏挖掘序列数据中上下文关系的能力,因此基于机器学习算法的检测模型整体表现不如深度学习模型。相比于TCN、DRQN、RDBN 等神经网络模型,LSTM 中的门控机制能够捕获用户用电序列中的长程依赖信息,提高对序列数据的建模能力。以上实验结果表明,本文提出的模型不仅在性能上优于基线模型,同时能够以联邦学习的方式进行模型构建,保护数据隐私。

Fig.3 Model training loss curves图3 模型训练损失曲线
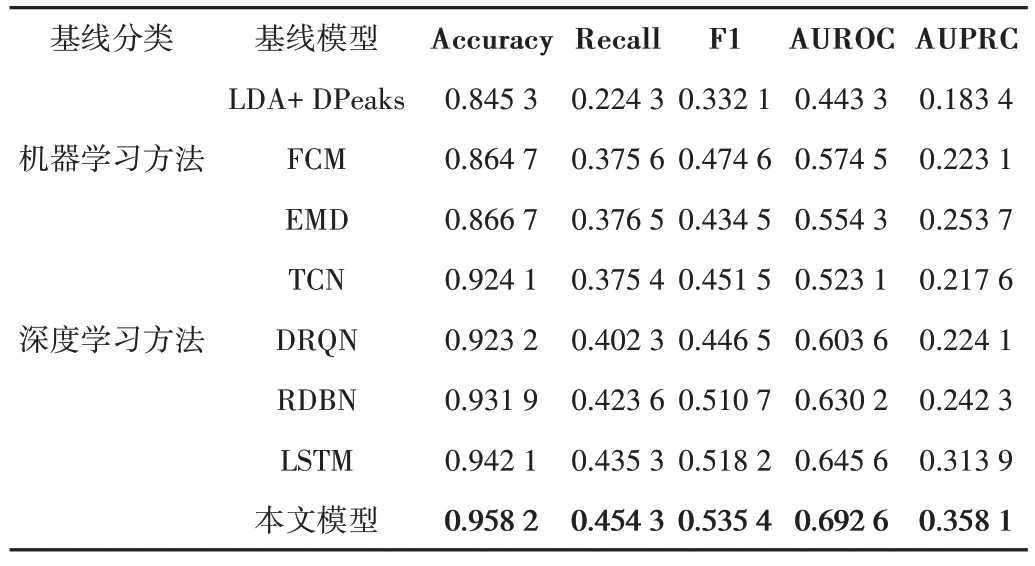
Table 2 Comparison of experimental results表2 实验结果对比
3.5 消融实验
为验证所提出的基于信息熵加权平均的服务器端梯度聚合方法的有效性,进行以下消融实验。在保证其他模块不变的情况下,将本文提出的梯度聚合方法与FedAvg算法中的梯度聚合方法进行对比,通过实验验证本文提出的基于信息熵加权平均梯度聚合方法的有效性。从表3的实验结果可知,本文提出的基于信息熵加权平均的梯度聚合方法优于FedAvg 中基于客户端数据量比值的梯度聚合方法。

Table 3 Ablation for gradient aggregation method表3 梯度聚合方法消融实验
3.6 参数影响分析
为研究本文提出的基于信息熵的联邦学习异常用电识别方法中参数的敏感性,分析模型在不同超参数设置下的异常识别性能,本文进行了模型超参数分析实验。本实验对注意力机制参数矩阵的隐层特征维度Dk(Dk=Dq=Dv)和多头注意力机制头个数H进行分析,实验结果如图4、图5所示。
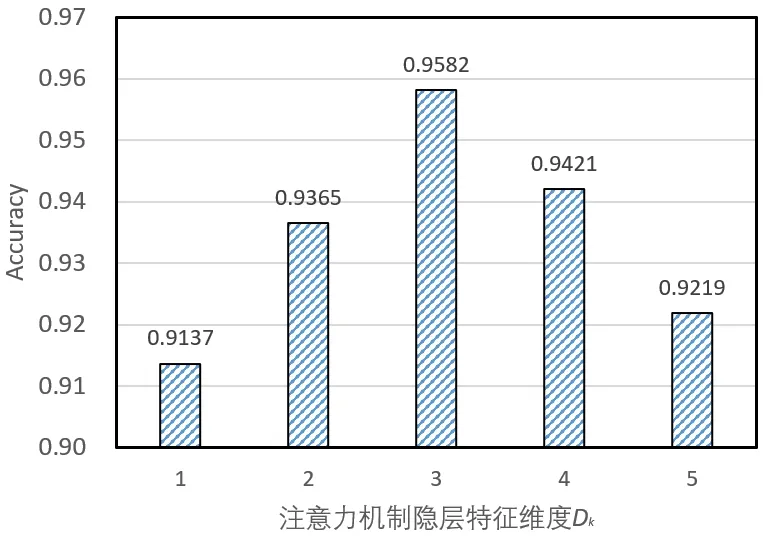
Fig.4 Sensitivity analysis for hidden feature dimension图4 隐层特征维度敏感性分析
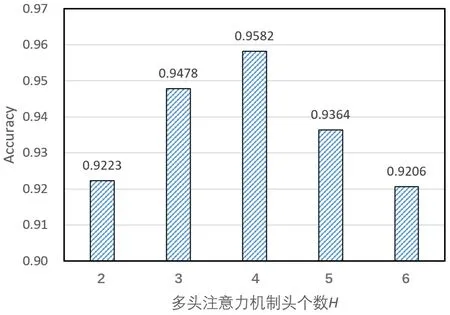
Fig.5 Sensitivity analysis for multi-head attention mechanism图5 多头注意力机制头个数敏感性分析
由图4 可知,随着隐层特征维度的变化,异常识别性能会有不同程度的波动,当维度为32 时,模型取得最佳性能。当维度过小时,输入数据包含的特征有限,因此性能出现衰退;当维度增大时,容易导致模型出现过拟合的情况,使模型过度训练,无法获得最佳异常用电用户识别性能。由图5 可知,设置不同的多头注意力机制头个数,模型具有不同的性能表现,表明本文提出的模型对多头注意力机制头个数具有一定程度的敏感性。具体地,当H=4时,模型表现最佳;当H>4 时,模型性能出现衰退。出现这种现象的一个潜在原因在于,当多头注意力机制头个数增加时,模型参数增加,导致模型训练不够充分。
4 结语
为识别出异常用电数据,同时保证用户用电数据的隐私性,本文提出一种基于信息熵的联邦学习异常用电识别模型。该模型引入联邦学习到异常用电数据识别中,避免了集中式模型训练所带来的潜在数据泄露的风险。同时,为提高基于联邦学习的服务器端梯度聚合效果,引入Kozachenko-Leonenko k 近邻算法估算数据集的信息熵,根据信息熵进行服务器端梯度加权聚合。实验结果表明,本文提出的基于信息熵的联邦学习异常用电识别模型能够在保证数据隐私的情况下,取得比现有方法更优异的异常用电用户识别效果。
本文研究重点在于如何解决联邦学习实际面临的客户端不均衡数据在服务器端参数梯度聚合过程中的贡献评估问题。然而,在现实应用中,客户端数据所具有的不均衡特点可能会导致各个客户端在本地模型训练时存在效率差异,进而导致时延问题,影响总体模型训练效率,该问题是实现高效联邦学习所面临的重要挑战。本文将在下一步研究中对该问题进行研究,目前已形成初步的研究思路,即对各个客户端的数据特点、计算能力、网络通信等资源进行全面量化,根据客户端资源量化指标对模型训练过程进行反馈控制,以实现模型训练超参数的差异性配置,解决分布式客户端所面临的“木桶效应”,提高联邦学习模型的训练效率。
