基于人工智能技术的物联网大数据挖掘算法
2023-01-07江苏电力信息技术有限公司江苏南京市210000孙澄宇
(江苏电力信息技术有限公司,江苏南京市,210000)封 晶 孙澄宇 董 平 赵 南
物联网技术的飞速发展,推动着大数据挖掘的变革,信息挖掘逐渐从整体化挖掘对象转变为分布式、碎片化的挖掘模式。为实现物联网中海量信息的有效利用,以及促进数据挖掘的集中化发展,提出了具有前瞻性的人工智能大数据挖掘算法,在智能化时代背景下对于我国工业经济的发展和建设具有重要作用。
1 基于人工智能的大数据发掘算法
1.1 数据模型树构建
为满足物联网动态特性以及用户信息获取的准确度,需要构建数据模型用于无法物联网中用户的行为。首先,基于模型树的特征,对物联网中的用户数据进行扫描,以保证数据的全面性。其次,根据物联网网络节点构建用户数据集。最后,从数据集中提取数据量较大的节点,然后进行数据挖掘,针对其他数据节点主要采用排序方法进行处理[1]。基于上述网络节点选择方法,可以获取不同周期的节点数据模型树。
1.2 物联网数据特征检测
构建数据模型树虽然可以明确数据挖掘内容和范围,但是无法保证模型关联度的准确性以期获取的挖掘结果。因此,需要采用数据特征提取算法分析大数据特征,并根据数据属性,获取数据价值维度。假设大数据挖掘集为D,数据集维度为d,则根据大数据属性可以获取大数据属性集合W。
如果数据挖掘子空间为S,则数据属性集合将包含子空间S,并且子空间S中的对象为0∈D。基于数据离群特征,可以获取子空间S中数据对象的邻域(0,S),该邻域为非均匀分布状态。如果在子空间S中随机提取一个对象,那么其离群概率则为Id(0,S)。从数据属性方面来看,该集合中子空间中心位置即为数据对象0,由此得出子空间离群概率距离公式为:
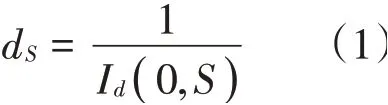
式中:d为距离;Id(0,S)为离群概率。
由于物联网大部分的数据都为不均匀分布,因此需要利用理算数据标准距离与密度的近似值表示离散数据特征:

基于离散特征λ可以获取物联网中离散数据分布情况。针对上述数据值的获取,可以采用信息熵检测方法,在待测数据集Y中,对数据y的分布特征进行分析,基于概率函数p可以获得y数据信息熵E(y):
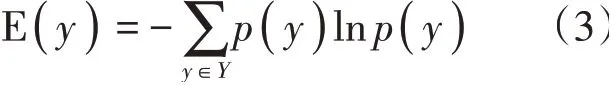
根据信息熵计算结果,可以对待测数据进行排序。并按照从大到小的排序方式,提取出多个信息熵较大的数据作为聚类中心对剩余数据进行检测。数据聚类中心距离计算公式为:

式(4)中,a、b为随机提取的聚类中心,并将其作为核心,对所有数据信息熵进行计算后获得聚类阈值。如果聚类中心距离小于阈值时,则需要重新选择聚类中心,并重复式(4)计算过程中,直至聚类距离计算结果大于阈值为止[2]。
1.3 特征数据的标准化处理
在数据特征检测过程中通常会产生噪声数据或数据量纲差异较差,该情况会影响大数据挖掘质量和效率,因此为保证数据分析的准确性,需要采用标准化方法对检测数据进行处理。
在数据标准化处理过程中,利用标准差对数据进行计算,可以进一步强化数据的特征,有利于保证大数据挖掘的质量。除了利用标准差对数据进行标准化处理外,还可以利用数据平均偏差Gα进行计算,计算公式为:
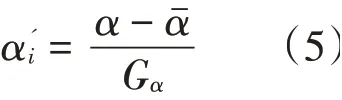
利用上述公式对特征数据进行标准化处理后,可以提高大数据挖掘算法抗干扰性。数据标准差Yα、数据平均偏差Gα、数据均值α计算公式为:
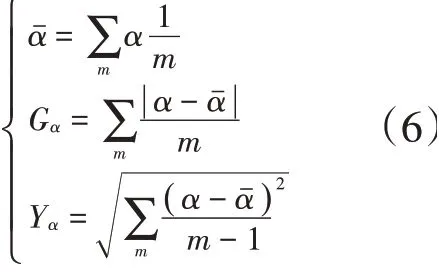
式中,m为迭代次数。在对数据进行标准化处理后,需要采用人工智能技术对大数据进行挖掘。
1.4 基于人工神经网络的大数据挖掘
BP神经网络(以下简称BP网)具有多层传输结构,并且其各层神经元数量可以随意设定,因此将其作为大数据挖掘的主体结构,并将经过标准化处理的数据传输至BP网中[3]。由于BP网结构存在的一定的特殊性,因此需要计算数据信息熵,并求出其平均值E,然后将其作为物联网各层的连接权值ω,其计算公式为:
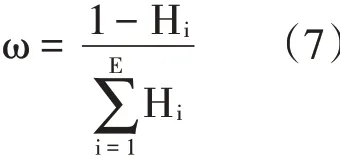
式中:ω为连接权值;Hi为属性熵值,E为信息熵平均值。
在获取到BP网连接权值后,需要根据图2分析流程,对物联网中的数据进行挖掘。
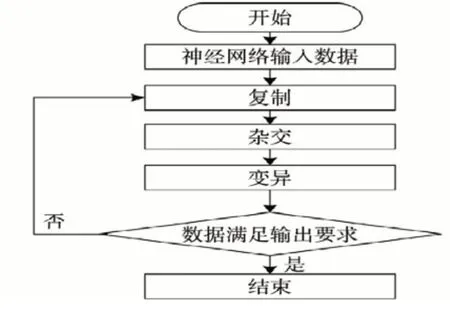
图1 BP网挖掘流程
从图2可知,基于人工智能的物联网大数据挖掘算法,融入了遗传学习算法,并配置了以网络结构和网络分类能力为核心的大数据分类器。利用遗传学习算法对大数据挖掘进行优化,然后输出满足大数据挖掘条件的数据[4]。
2 仿真实验
2.1 获取数据集
为验证基于人工智能技术的大数据挖掘算法的性能,通过仿真实验方法对算法应用效果进行检验。首先,选择具有3500个二维特征的数据,并将其构成数据集。
数据被划分为15类,并且每个数据聚类模糊系数均为1.7,传递点数量为2。为使数据向量维度值保持在0~1之间,需要去除每个维度中参数最小的值,并计算最大值与计算结构之间的商值。该计算过程主要是对数据进行正则化处理。在本次仿真实验中,共设置四个数据集,数据集大小为10%、20%、25%、50%。
2.2 性能指标
在本次仿真实验中主要采用RI和F-measure作为判断人工智能大数据挖掘算法的重要指标,Fmeasure是一种常用的大数据挖掘性能评价指标,其计算公式为:

式中:F为计算结果;R为召回率;P为精度。
计算结果的准确性通常取决于精度和召回率。其中精度具体是指大数据挖掘过程中精准参数所占据的比例;召回率具体是指具有特定类特性的数据数量。I、j量类数据的召回率与精度计算公式为:
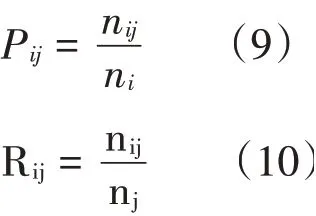
大数据挖掘的质量也可以利用RI指标对其进行评价。首先,计算出数据集X聚类参数和实际聚类参数CT。其次,对无序数据点(xi,xj)进行定义,划分出RI值的集合FP、TP、FN、TN。
RI计算公式为:
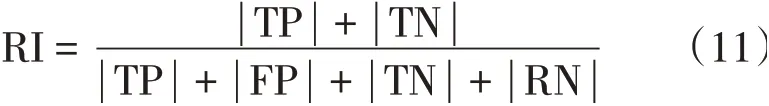
利用公式(11)对RI指标进行计算,可以获取到取值范围在0~1之间的参数,如果RI指标趋近于1,则实际计算结果与挖掘结果相似度越高,并且挖掘算法精度也越高;如果RI指标趋近于0,则实际计算结果与挖掘结果相似度较低,并且算法精度也较低。
3 结论
本文基于人工智能技术,通过特征数据提取、特征数据检测、特征数据标准化处理等方式,在获取和处理挖掘数据信息熵后,融入遗传学习算法对信息熵平均值进行计算,该算法能够进一步提高物联网中大数据挖掘的质量和效率。BP网和遗传学算法的融入,不仅提高了大数据对数据集的处理能力,而且也解决了大数据挖掘过程中信息传递错误的情况。通常仿真实验,验证了基于人工智能技术的大数据挖掘算法在RI结果和F-measure结果确实有所改进,同时也证明了人工智能技术在大数据挖掘中的应用,有利于促进大数据挖掘的持续发展。
