基于Mean⁃shift聚类和孪生网络的非侵入式负荷辨识方法
2023-01-06石少青张乐平张本松吴昊文连新凯杜书帅
石少青,张乐平 ,张本松,吴昊文,连新凯,杜书帅
(1.中国南方电网有限责任公司,广东 广州 510080:2.南方电网数字电网研究院有限公司,广东 广州 510663:3.河南许继仪表有限公司,河南 许昌 461000)
随着新一代智能电表的推广和应用,非侵入式负荷辨识技术作为一种新兴的智能化负荷监测手段,越来越受到国家电力公司等单位的青睐。电力公司通过智能电表非侵入式负荷辨识技术收集用户侧用电比例构成[1],了解各个负荷的用电特点及潜在用电规律[2],可以充分挖掘用户的互动潜力,进而为实现电网透明化[3]奠定基础。
智能电表非侵入式负荷感知系统主要由数据采集、特征选取和负荷辨识3个模块组成[4]。其中,特征选取和负荷辨识是负荷识别技术的关键。负荷特征是反映负荷运行状态的关键信息,通常可将其分为电量特征和非电量特征。常见的电量特征包括:有功功率[5]、无功功率、电流谐波[6]和V—I轨迹[7]等稳态特征[8],以及尖峰特征、电压噪声等暂态特征[9];而非电量特征则包括时间特征[10]、天气、温度等表达用户用电行为的外界特征[11]。基于这些特征,文献[12]中首先使用聚类算法将负荷按有功功率和无功功率进行分类实现粗辨识,再将二维V—I轨迹图作为卷积神经网络模型的输入,完成精细化识别。在文献[13]中提出了一种融合排列熵算法和Yamamoto算法的暂态特征采样方法,并结合特征权重,采用基于模糊c均值聚类实现非侵入式负荷辨识。然而仅使用电量特征会因为负荷种类的增多而需要不断加入新的特征提升辨识能力,难免会造成计算量过大的问题。文献[14]通过考虑电器运行过程与时间的关联关系,结合负荷运行模式的时间尺度信息和信号幅值构建序列翻译模型,将待分解的能量翻译为状态码,实现负荷能耗分解。
考虑到不同的负荷特征获取方式,负荷辨识方法通常可分为基于负荷事件型和基于负荷运行状态型[15]两种。基于负荷事件的辨识方法提取随负荷状态变化产生的负荷特征变化,并将其作为辨识依据,而基于负荷运行状态的辨识方法将负荷工作时间内的特征状态作为辨识依据。文献[16]在负荷事件的基础上提取负荷特征,然后通过融合Fisher得分和主成分分析算法的Fisher主元分析法剔除掉区分性较差的无效特征,同时降低有效特征之间的关联性,然后采用遗传算法(genetic algorithm,GA)对模型参数进行寻优,从而完成负荷识别。而文献[17]首先采用基于B样条曲线拟合算法提取负荷运行状态的互补特征,然后用支持向量机(support vector machine,SVM)算法构建分类器对负荷进行辨识。一般来说,基于负荷事件的辨识方法无需了解负荷整个运行状态的情况,且负荷特征数据易于获取、方便计算和存储,具有准确率较高的特点。
基于此,本文通过负荷事件检测提取负荷事件的有功-无功功率、时间等特征,并对时间特征进行细化建模。考虑到用户用电行为的规律性,采用Mean-shift聚类对具有相同时间特征的负荷进行聚类,进而引入孪生神经网络进行负荷细分,最终实现负荷辨识。最后,通过实际数据测试验证文中方法的有效性。
1 负荷特征表达
负荷特征是用于区分不同类型负荷的内在特性,合理的选取负荷特征对后续的负荷辨识具有重要意义。本文选取的电量特征包括有功功率和无功功率特征;非电量特征则包括负荷运行时长特征、运行时刻等特征。
1.1 电量特征
1.1.1 有功功率特征
有功功率P作为一种易于获取的稳态特征,能直观地反映负荷的能耗且也是负荷投切时最为明显的特征。在现有智能电表中,负荷辨识模块可直接与计量芯通信读取实时的有功功率值。
1.1.2 无功功率特征
无功功率Q与有功功率P相对应,也是一种表现负荷内在性质的稳态特征。同样地,无功功率可直接从计量芯实时获取。
通常,负荷可根据无功和有功功率将负荷划分为阻性、容性以及感性等类别。
1.2 非电量特征
非电量特征,例如时间、温度、节假日等,是反映用户用电行为的特征,可作为负荷不易区分时潜在的辅助特征。时间特征应用较为广泛[18-19],主要包括负荷运行时长和启动时刻。
1.2.1 负荷运行时长特征
负荷运行时长是对负荷单次运行时间长短的描述,不同的负荷通常运行时间长短不一。图1为某负荷运行时长特征示意图,图中t1为负荷开启事件发生时刻点,t2为该负荷关闭事件发生时刻点,两时刻点的差值即为负荷运行时长L的值。

图1 负荷运行时长特征示意图Fig.1 Feature of load running time
对于常见的家用电器,大致可将其分为两类,其中建模方式以高斯和均匀分布为主,如表1所示。因此对负荷的运行时长L,其概率密度分布可描述为

表1 负荷运行时间分布Tab.1 Distribution of time length
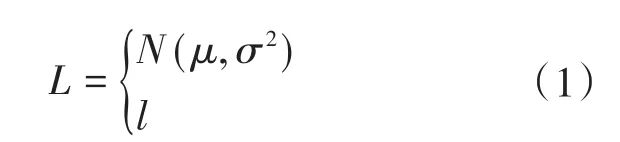
式中:N(μ,σ2)为高斯分布;l为常数,代表均匀分布。
一般而言,负荷运行时长的统计依赖于负荷自身的特性以及用户的用电行为。本文在负荷事件检测的基础上,对某家庭用户各负荷运行时长进行了统计,如图2所示,其中各图形上方的数字表示各负荷的平均运行时长。

图2 负荷运行时长特征统计结果Fig.2 The length of statistical time of load running
从图2中可以看出,各负荷运行时长之间具有一定的区分性,例如空调通常是长时间运行,电视机平均运行时长在2 h左右,而微波炉、电水壶、电磁炉以及洗衣机的运行时长较短,仅为几min或十几min,且分布相对较为集中。
1.2.2 负荷运行时刻特征
负荷运行时刻特征通常与用户作息、行为习惯有较大关联。图3为统计某家庭用户各负荷运行时刻特征统计热力图,图右侧刻度条颜色表示对应的运行次数。图中色块的位置反映各负荷处于运行状态的时间段,颜色越深代表负荷在该时间段内使用频率越高。例如,冰箱几乎处于全天运行状态,而热水器通常在晚上19∶00—20∶00之间运行。此外,从图中也可以看出空调的运行时段也较为固定,均为夜里22∶00以后开启到次日早晨关闭,这与用户睡眠时间有关,而电视机则通常在中午和晚上运行。这些也从侧面反映了用户对负荷的使用习惯。因此,可将一天24 h分为若干个时间段,并用二值函数表示在某时间段(t1,t2)内是否有负荷事件发生,即
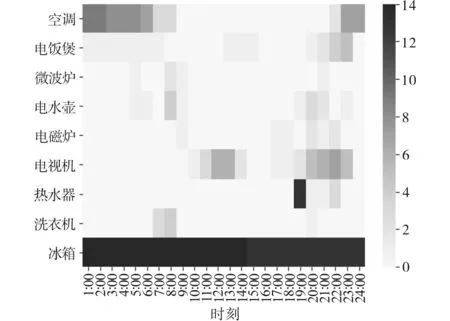
图3 负荷运行时刻特征统计结果Fig.3 Statistical running time of load

lt=1表示发生负荷事件;lt=0表示未发生负荷事件。
1.2.3 间歇性变化特征
除了上述一些特征之外,还存在一些工作波形特征。图4所示为洗衣机工作时所展现的波形曲线特性。不难看出,该特征具有较好的区分性,因此在非电量特征中可直接进行负荷判别,即


图4 负荷运行间歇性变化特征示意图Fig.4 Vairation feature of load during running
2 负荷时间特征统计及细分
考虑到用户用电行为通常具有统计规律,因此时间特征是除电量特征以外能够有效地提高负荷辨识准确率的特征。本文首先对负荷时间特征进行统计以及细化建模。
2.1 负荷运行时长特征分段
采用负荷运行时长特征进行分类,最为直接的方式是按运行时长的长短进行划分。为了确定具体的运行时长的细分类型数和分类阈值,本文对所有负荷的运行时长采用核密度估计方法,得到负荷时长特征概率密度分布函数f(x)。对f(x)进行积分,并令积分结果满足:

根据ε值的不同,可将负荷按运行时长分为若干个类型,使得每个类型包含的负荷种类数大致相等,同时得到时长阈值x的值。
2.2 负荷运行时刻特征分段
考虑到负荷在一天中的运行时刻具有不确定性,可能存在多负荷同时运行的高峰期(晚上下班后),也存在几乎无负荷运行的低谷期(在白天的工作时间),因此负荷运行时间特征的分段往往不是均匀等距的,需要根据具体的场景进行划分。
对于不同用户的不同用电行为规律,为进一步确定具体划分时间段的时间点,本文采用一种最优化的方法,规定所有负荷所占的时间段数总和最少即为最优的时间区间划分结果,这能很大程度地将不同运行时刻的负荷区分开来。
令NTi表示第i个负荷占用的时间段数,i∊1~s,s为总的负荷类型数,则目标函数的表达式如下式所示:
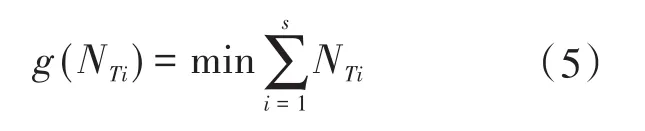
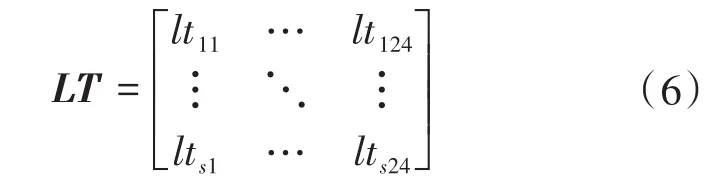
对于具有s类负荷的环境而言,可以用稀疏二值矩阵LTs×24表示各负荷的运行时段(下标24代表一天24 h),矩阵中1代表存在负荷运行,0代表不存在负荷运行,结合式(2)可将某一天的各负荷运行时刻分布情况表示为
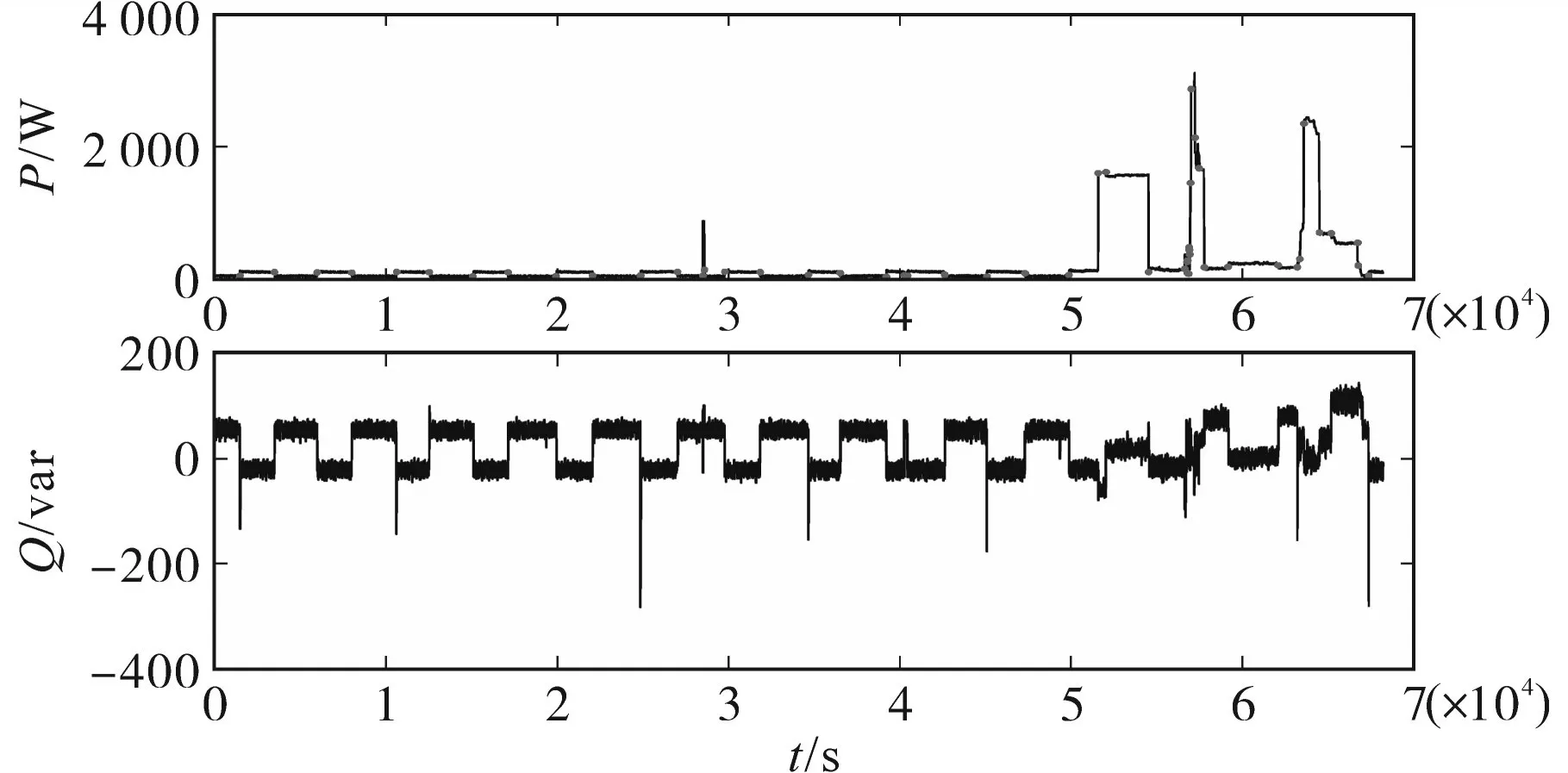
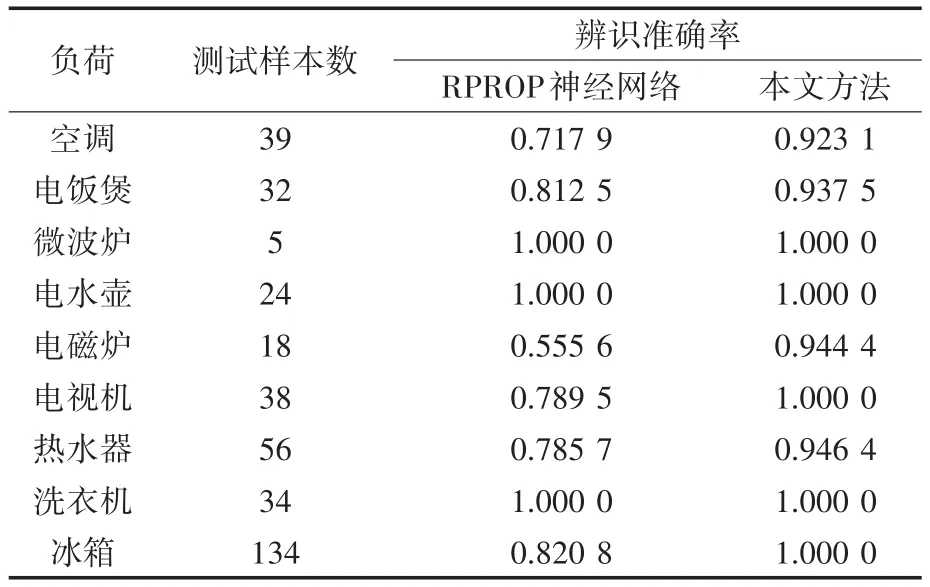
其中,矩阵的每一行代表各负荷存在运行状态的时间段,每一列代表该小时内运行的负荷类型。若将时刻tm1,tm2,…,tmt(1 式中:j为时刻点,j∊[1,24]。 定义符号函数sgn(·)为 将式(7)、式(8)计算结果代入式(5)即可求得m1,…,mt的值。 在智能电表非侵入式负荷辨识研究中,时间特征和电量特征具有一定的差异性。本文对时间特征采用Mean-shift聚类,得到用户在相同时间特征下所使用的负荷,同时利用孪生神经网络,通过与数据库负荷匹配辨识出所使用的负荷类型。 Mean-shift算法作为一种非参数化聚类算法,其基本思想是假设不同簇类的数据集符合不同的概率密度分布,通过找到任一样本点密度增大的最快方向,那么样本密度高的区域对应于该分布的最大值,这些样本点最终会在局部密度最大值处收敛,且收敛到同一局部最大值的样本点就被认为是同一簇类。相比于其他聚类算法如K-means算法,Mean-shift算法无需预先设置聚类中心数,其可以借助数据分布概率密度自适应地选取聚类中心数[20],这对一天内使用的负荷类别的快速确定具有重要意义。 假定给定d维空间的n个样本点xi(i=1,…,n),空间中任一点x的Mean-shift漂移向量的基本形式为 式中:y为在空间尺度h内的变量;K为n个样本点中分布在区域Sh内的个数;Sh为以x为中心、h为半径的高维球域区域。 在聚类的过程中,按照下式不断地计算漂移向量进行迭代,最终获得聚类中心。 为了优化聚类效果,引入核函数K(xi-x)[21],则均值偏移向量更新为 式中:ω(xi)为样本xi的权重,由其概率分布决定。 在聚类之后,本文采用如图5所示的孪生网络的方法对负荷进行细分类。 图5 孪生网络结构图Fig.5 Siamese network framework 孪生网络主要用来衡量两个输入的相似程度,其有两个输入(X1和X2),将两个输入分别输入两个神经网络(Network1和Network2),通常两个神经网络的结构和参数一般是相同的,它们分别将输入映射到新的空间形成新的特征,并最终通过计算距离来评价两个输入的相似度。 图5中,X1,X2为负荷特征和数据库中负荷特征;GW表示神经网络模型,下角W表示权重,GW的作用就是将电量和非电量特征数据X转换为一组特征向量;EW则用于衡量特征向量之间的距离,距离越小,则代表越相似。 本文采用弹性BP神经网络[22](resilient back propagation,RPROP)作为孪生神经网络中的GW。假设分类对象为Ψi(i=1,2,…,p),每个对象Ψi对应有q个样本Ψij(j=1,2,…,q),其中样本特征维数为r,即 则特征集的个数为p×q,此时将这些样本输入神经网络,得到p×q个输出矢量: 式中:u为输出层数据维度。 则生成的特征矩阵为 为了降低计算量,对矩阵Y进行主成分分析。令Y的协方差矩阵的最大特征值对应的特征矢量为t,则在第一主元方向的投影所得数据为 即第i类对象的第j个样本对应于第一主元方向上的投影数据αij。假定当第n个主元成分上投影的方差和占总方差超过某个阈值(文中设置为0.90),则确定了对应的n个特征向量,从而生成特征集。 为了判别神经网络输入属于具体某个负荷类别,将数据库中负荷类别特征作为孪生神经网络输入,其中孪生神经网络输出的距离度量采用K-means分类方法。 图6给出了本文方法的具体流程框架。在该框架中,首先对负荷事件通过时间特征进行聚类,获得相应的负荷类别,然后通过孪生神经网络,将与数据库中与之具有相同时间特征的负荷进行匹配,最终得到负荷辨识结果。 图6 本文方法模型结构图Fig.6 Frame chart of proposed method 为了验证文中方法的有效性,本文以某一家庭用户作为具体的研究对象,连续对该家庭用户监测30 d的负荷数据进行离线分析,并从中分析提取出负荷运行的特征数据,构建负荷特征数据库。用户使用的负荷包括空调、电饭煲、微波炉、电水壶、电磁炉、电视机、热水器、洗衣机和电冰箱。为此,本文将该9种负荷作为研究对象进行辨识,表2给出了该用户负荷有功-无功功率特征和间歇性特性数据库,运行时长和投切时刻统计图见图2、图3。文中设置Meanshift算法中时长尺度为10 min,投切时刻尺度为相差30 min。 表2 负荷特征数据库Tab.2 Database of load signature 4.1.1 负荷运行时长分段阈值 按照1.2.1中的方法,为确定具体的运行时长分类阈值,图7给出了负荷时长特征概率密度分布结果。为了获得时长分类的界限,本文对概率密度函数进行积分,取积分结果中值处作为负荷运行时长分界线。为了方便表示,令t0表示时长分类阈值点,设置式(4)中ε=1/2,计算得到分类阈值t0≈40 min,由此可将t0作为负荷事件分类的运行时长阈值,即短时长为0 图7 负荷运行时长特征统计示意图Fig.7 Statistical length of running time 4.1.2 负荷运行时刻特征分段阈值 在统计获得负荷特征数据库的基础上,对用户某一天的用电数据作为测试数据进行实验。 首先,对该用户的日用电功率曲线进行负荷事件检测,并提取负荷事件的有功-无功功率特征和时间特征信息,测试数据如图8所示,负荷事件特征信息如表3所示。由时间特征分类可知,该日负荷事件分为5类,与之匹配的在数据库中得到的负荷类别如表4所示。然后,与数据库中的时间特征采用Mean-shift聚类后,得到聚类匹配结果如表5所示。显然,从数据库中聚类得到的结果可以发现,时间特征上相似的负荷设备可能存在多个,因此需要进一步细分。 表3 负荷事件特征信息Tab.3 Information of feature of load event 表4 负荷时间特征匹配信息Tab.4 Information of time feature of load in matching 表5 时间特征Mean-shift聚类结果Tab.5 Reuslt of Mean-shift clustering of load event 图8 测试数据日负荷事件检测结果Fig.8 Detect result of test data in one day of home 为了最终判断负荷类型,将电量特征和时长特征作为孪生网络中弹性BP神经网络1的输入,同时,将数据库中训练的负荷类别的特征信息输入到BP神经网络2,通过生成的特征进行K-means聚类,最终得到的匹配结果如表6所示,与实际负荷投切运行结果一致。 表6 孪生神经网络匹配聚类结果Tab.6 Matching reuslt of siamese neural network 为了进一步验证本文方法的有效性,本文与文献[22]中的神经网络负荷辨识方法进行比较,其中输入特征为有功、无功,辨识结果如表7所示。从表中可以发现,在没有时间特征细分情况下,单一地采用神经网络进行负荷辨识,因特征存在混叠导致其错误率较高;而本文方法首先通过对时间特征的细分,并采用Mean-shift算法与数据库中的负荷进行聚类,选择具有相似的时间特征,然后通过孪生神经网络进行细分,实现了较高的辨识准确率。在该用户场景下,其平均辨识准确率为0.976 3。 表7 对比分析结果Tab.7 Reuslts of comparsion 针对实际家庭用电场景中用户使用的负荷类型辨识问题,文中提出了基于Mean-shift聚类和孪生网络的负荷辨识方法,该方法按家庭负荷时间特征分布情况统计结果,将负荷事件按运行时长和运行时刻特征通过Mean-shift聚类方法,获得相似时间特征的负荷,然后采用孪生网络进行负荷匹配辨识,提高辨识准确率。实验结果证明,该方法可有效弥补因有功-无功特征混叠而引起的负荷辨识准确率低的问题。在下一步工作中,我们也将通过采集其他不同家庭用户负荷特征,将文中算法进行应用推广。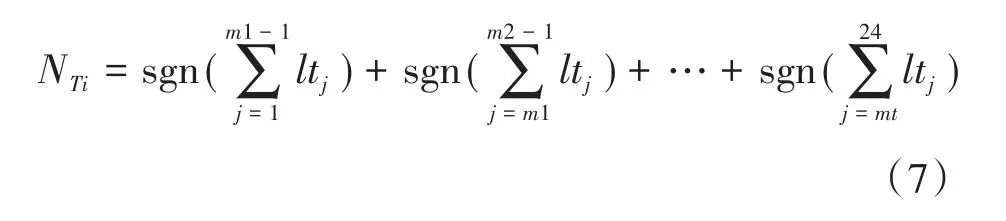

3 Mean-shift负荷事件聚类和孪生网络判断
3.1 Mean-shift聚类

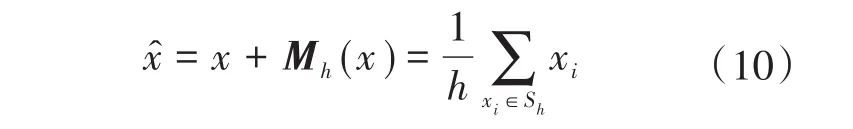

3.2 孪生网络判断负荷类型
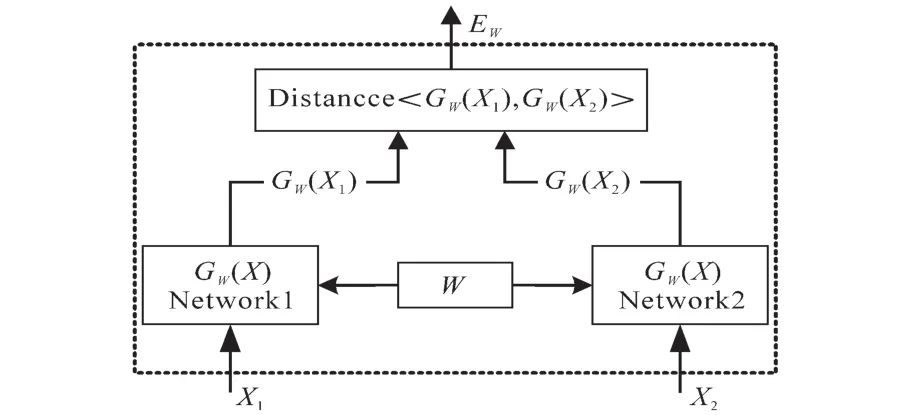
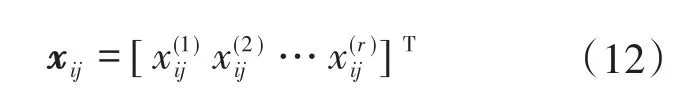



3.3 实现流程

4 实验结果与分析

4.1 参数设置

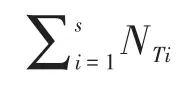
4.2 测试案例分析


5 结论
