基于跨模态Transformer的多模态细粒度情感分析方法研究*
2023-01-06恺董修岗周祥生
陈 恺董修岗周祥生
(1.南京理工大学计算机科学与工程学院 南京 210094)(2.中兴通讯股份有限公司 南京 210012)
1 引言
细粒度情感分析是情感分析领域中的一项重要的子任务,它的目标是确定句子中每个观点实体的情感倾向[1],在近年来成为了一个研究热点[2]。相关的研究工作包括基于传统的特征工程的方法[3],和基于深度学习的方法[4]等。随着近年来预训练语言模型在众多自然语言处理任务中开始流行,文献[5]提出了基于BERT[6]的模型来解决细粒度情感分析任务,该模型在多个数据集上获得了目前最好的实验结果。
然而,随着互联网技术的飞速发展,在线社交媒体成为了人们生活中的重要部分[7~8],人们在其中发布的内容也从单一的文本信息转变为图文并茂、视音频结合的多模态信息。尽管之前工作提出的方法在基于纯文本信息的细粒度情感分析任务上取得了较好的结果,对于这些多模态信息这些方法仍然存在一定的局限性,尤其是无法对模态间的信息交互进行建模,影响最终情感分析的效果。
基于以上的研究现状,一种新兴的多模态细粒度情感分析任务被提出[9],该任务针对多模态的社交媒体数据,根据数据中的文本和图片信息,综合判断文本中每个观点实体的情感倾向。本文针对该任务,提出了一种层次化的跨模态Transformer神经网络模型(Hierarchical Cross-modal Transformer,HCT),通过调整跨模态Transformer的输入来建模文本与图片模态之间的信息交互,以解决目前基于纯文本数据的细粒度情感分析模型无法有效建模多模态数据的问题。本文在两个真实的多模态社交媒体数据集上开展了实验,并与一些经典的细粒度情感分析方法进行对比,证明了提出的模型能够有效提高多模态细粒度情感分析任务中情感倾向判断的准确性。
2 相关研究工作
2.1 细粒度情感分析
细粒度情感分析任务是情感分析领域中的一个经典任务,本文将近年来的相关工作分为如下两类分别进行介绍。
一类是基于特征工程的方法。这些方法主要利用一些外部语义信息,例如Part-of-Speech标签、句法解析标签以及情感词典等,来人工构建针对细粒度情感分析任务的特征模板,并使用传统的机器学习模型基于特征模版进行情感分类[10]。虽然这些方法在当时都取得了较好的结果,但是它们都比较依赖人工构建的特征,人力资源消耗较大。
另一类是基于深度神经网络的方法。文献[11]基于句法解析树构建了一种针对细粒度观点实体的递归神经网络。文献[12]设计了一种基于门控机制的卷积神经网络来动态地控制与观点实体词情感倾向有关的信息流入。另外,文献[13~14]等设计了基于注意力机制的方法,以有效建模文本中的长距离依赖问题。
2.2 多模态情感分析
多模态情感分析任务是情感分析领域中一个新兴任务,该任务提出的目的是为了利用其他模态(图片、音频)的信息来对文本模态进行补充,从而提升情感分析的准确性。
目前多模态情感分析任务的相关工作主要针对多模态对话数据展开,主要为粗粒度的句子级情感分析模型。文献[15]提出了一种基于层次化卷积神经网络(CNN)的方法,该方法针对多轮对话数据,首先进行语音识别,然后将识别后的语义特征与文本特征拼接后再进行分类。文献[16]提出的方法首先通过预训练的CNN网络抽取文本特征,然后采用了多核学习(multiple kernel learning)的方式来融合文本、语音和视频三种模态的信息。文献[17]分别设计了张量融合网络(tensor fusion network)和记忆融合网络来建模多轮对话中的多模态信息融合。
然而,它们都是粗粒度的句子级情感分析方法,不能直接利用来解决细粒度的情感分析任务。因此,十分有必要提出一种方法来解决多模态细粒度情感分析问题。
3 层次化跨模态Transformer(HCT)模型
HCT模型的结构如图1所示。在本节中,首先对多模态细粒度情感分析任务进行定义,然后详细介绍本文提出的HCT模型中包含的三个模块以及模型的优化方法。
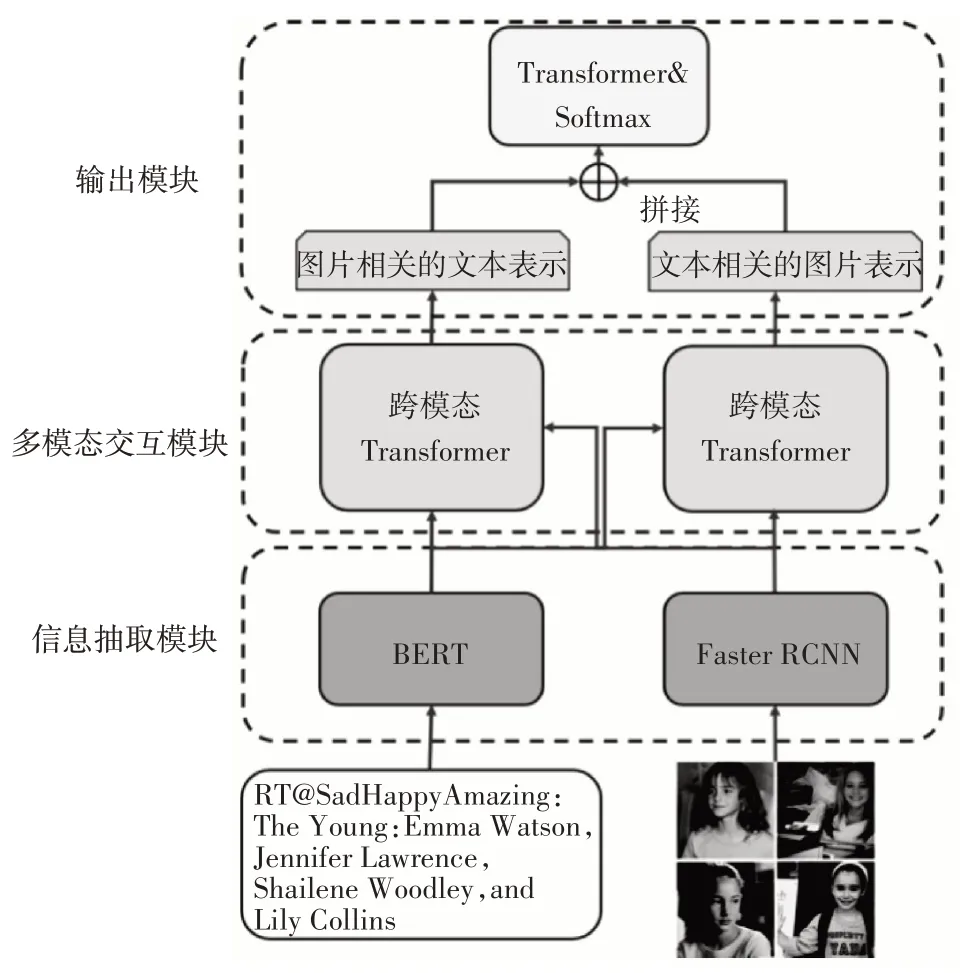
图1 HCT模型结构图
任务定义:多模态细粒度情感分析任务中的每一个样例都包含一条由n个词组成的文本,记为S=(w1,w2,…,wn);以及一张图片,记为V。其中文本中包含r个不同的观点实体,记为(t1,t2,…,tn)。该任务以文本、图片对(S,V)作为输入,判断文本中r个不同的观点实体的情感倾向y∈Y,其中Y是该任务的标签体系,包含正类、中立以及负类三种不同的情感标签。
3.1 信息抽取模块
该模块分为文本信息抽取和图片信息抽取两部分,本节将对这两部分分别进行介绍。
3.1.1 文本信息抽取
由于预训练语言模型在多种NLP任务中表现出了较好的效果,本文采用BERT作为文本编码器来对文本进行编码。
首先,受文献[9]的设置启发,本文将输入的文本信息S分为两部分,分别为观点实体词以及对应的上下文,其中上下文中的观点实体词使用$T$来替代。然后利用BERT中的[SEP]标签将这两部分拼接起来记为S',构成BERT的输入。我们将S'送入BERT编码后,获得输入文本的隐层表示:,其中n是输入文本中包含的单词的个数,d为每个单词的向量维度。
3.1.2 图像信息抽取
本文使用了Faster RCNN[18]这种具有较好性能的目标检测模型来对图片进行编码。该模型对图片中物体的检测过程主要包含两部分:1)首先通过区域候选网络(Region Proposal Network,RPN)来检测图片中如人、汽车等具有语义特征的物体;2)判断这些被检测出的物体的类别。
具体地,对于给定的图片V,本文使用在Visual Genome数据集[19]上预训练的Faster RCNN网络来抽取图片中所有的物体特征,然后根据Faster RCNN检测过程中每个物体的置信度,选择k个置信度最高的物体作为图片的表示:
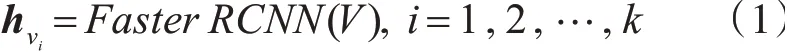
其中ℎvi∈R2048是经过Faster RCNN检测得到、平均卷积池化后的第i个物体的隐层表示。
最后,将经过Faster RCNN得到的物体隐层表示进行拼接,并通过线性变换将图片表示的维度映射到和文本表示同一维度,从而得到最终的图片表示:
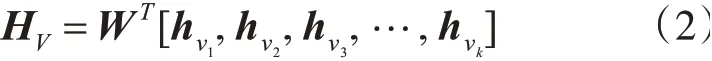
其中W∈R2048×d是线性变换的参数,HV∈Rd×k是最终的图片表示。
3.2 多模态交互模块
在获得了文本表示和图片表示后,本文设计了一种基于跨模态Transformer的多模态交互模块,该模块的作用是为了建模文本与图片之间的交互来获得文本相关的图片表示以及图片相关的文本表示,以促进模态之间的信息融合。
多模态交互模块的核心由跨模态Transformer构成,该结构如图2所示。以文本相关的图片表示为例,首先,本文引入多头跨模态注意力机制(MCA),通过设置文本表示HS为查询(Query)向量,图片表示HV为键(Key)和值(Value)向量,以获得用图片特征表示的文本信息。具体来说,对于MCA的第i个头,计算方式如下:
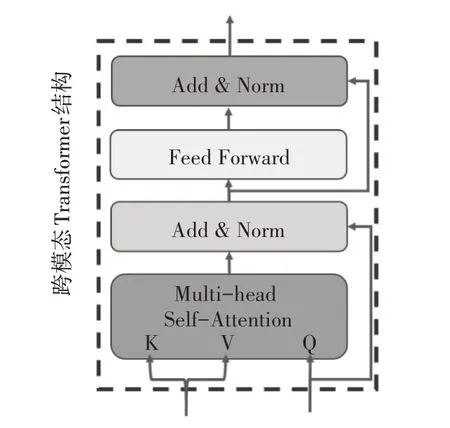
图2 跨模态Transformer结构图
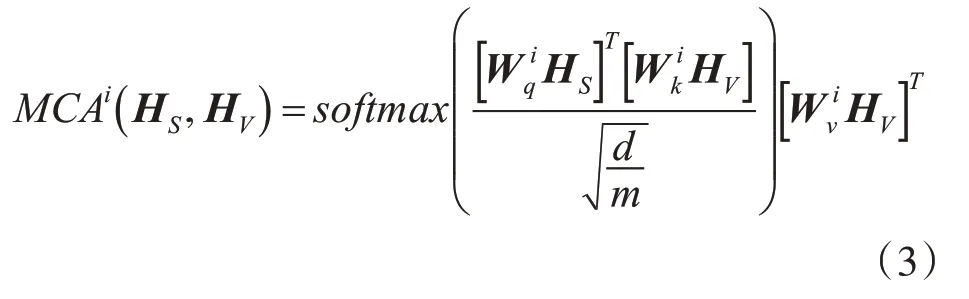
其中,m表示注意力头的数量表示第i个头中的参数。将m个头的输出结果进行拼接和线性变换,从而获得MCA的输出:
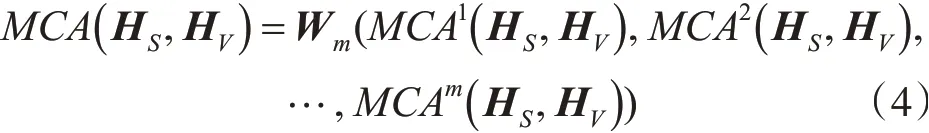
其中,Wm是多头跨模态注意力机制中线性变换的参数。接下来,和标准Transformer类似,将MCA的输出送入层归一化(Layer Normalization,LN)层以及前馈神经网络中,并且添加残差连接,以提升深度神经网络的稳定性以及非线性能力:
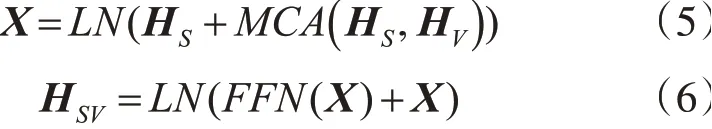
其中,HS→V即为经过跨模态Transformer后获得的经过模态融合后的文本相关的图片表示。
为了使得网络能够获得更好的信息抽取以及抽象能力,本文通过叠加跨模态Transformer层,让下层的输出作为上层的输入,从而构建出更加深层的网络:

图片相关的文本表示也同理,通过将图片设置成查询向量,文本设置成键向量以及值向量,送入与式(3)~式(7)结构相同但是参数不同的跨模态Transformer结构中,从而获得图片相关的文本表示,其中l是该部分跨模态Transformer的叠加层数。
在获得文本相关的图片表示以及图片相关的文本表示后,将这两部分表示拼接送入标准的Transformer结构中以建模这两部分表示的交互:
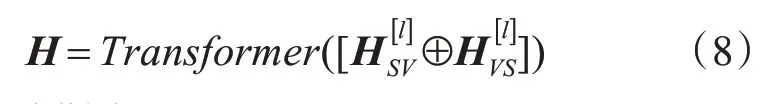
其中H∈Rd×(k+n)是最终的多模态融合表示。
3.3 输出模块
在获得多模态融合表示H后,我们将H的第一列向量送入softmax层进行情感分类,从而得到最终的观点实体词的情感倾向概率分布:
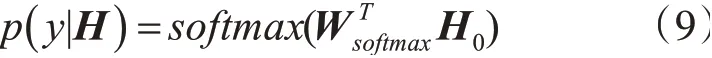
为了优化模型中的参数,本文设置了如下的交叉熵损失函数作为目标函数,通过使得目标函数最小化来让模型中的参数达到最优:

4 实验结果与分析
本文基于两个真实的多模态细粒度情感分析任务数据集进行实验,并且与若干种具有代表性的方法进行对比,以证明提出的方法的有效性。
4.1 实验设置
如表1所示,本文采用了两个真实的多模态细粒度情感分析数据集来展开实验,这两个数据集被命名为Twitter-15和Twitter-17,分别从2014年-2015年和2016年-2017年的Twitter平台中进行采样。这两个数据集中观点实体的情感倾向由文献[9]进行标注,相关的简单统计如表1所示。本文用正确率(ACC)、准确率(P)、召回率(R)和宏平均(F1)来衡量模型的性能。
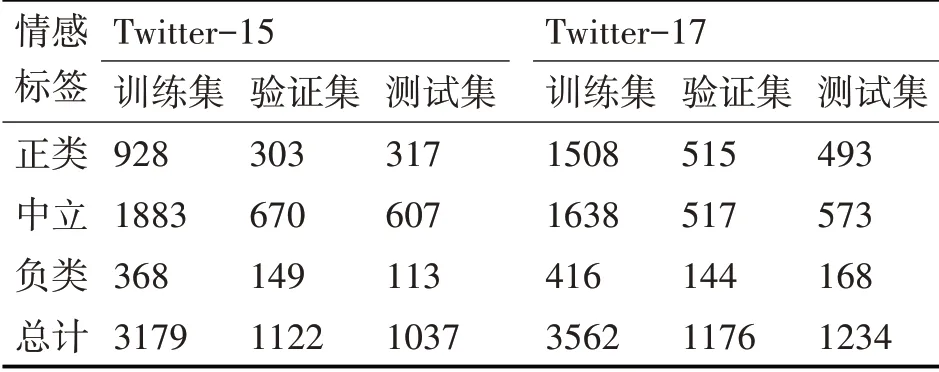
表1 数据集相关统计
本文使用经过预训练的uncased BERT base模型[6]对文本信息进行编码,使用以ResNet-101作为骨架网络的Faster RCNN模型对图片信息进行编码[18],根据Faster RCNN中目标检测的置信度来对抽取的特征进行排序,选择置信度最高的36个特征作为图片表示。
4.2 实验结果及分析
本文设置了如下方法进行比较:1)Faster RCNN-Target通过直接对观点实体词和图片进行编码,然后送入跨模态Transformer结构进行交互。2)AE-LSTM[19]是一种将观点实体词的表示加入输入的LSTM网络结构。3)MemNet[20]是一个包含局部以及全局位置信息的多跳记忆化网络。4)RAM[21]是一种使用多重attention机制的RNN网络。5)MGAN[22]是一种多重粒度的深度网络模型。6)BERT[6]是一种基于Transformer的预训练语言模型,该模型的预训练任务包括完型填空任务以及下文匹配任务。7)MIMN[23]是一种基于LSTM的多模态神经网络模型。8)ViLBERT[24]是一种基于Transformer的多模态预训练模型。9)ESAFN[25]是一种与观点实体词相关的注意力融合神经网络模型。
实验结果如表2所示,实验显示本文提出的方法在Twitter-15和Twitter-17数据集上均获得了最好的结果。基于所有的实验结果,本文能够做出如下总结:1)只采用图片信息的方法表现最差(Faster RCNN-Target)。这可能由于对于多模态细粒度情感分析任务而言,图片信息虽然能够对文本信息产生补充,但是仍然无法起主导的作用。2)添加了图片信息后的方法比大多数未添加图片信息的方法的表现要好。这点说明图片能够为文本提供信息补充,从而提升模型情感分类的准确性。3)ViLBERT模型的结果表明,它能够比大多数只利用文本信息的模型表现要好,但是比BERT要差,说明对于多模态细粒度情感分析任务而言,需要有针对性地设计模型。4)本文提出的方法在两个数据集上的表现均为最优,说明本文提出的模型结构能够有效建模图片和文本模态间的信息交互,从而提升多模态细粒度情感分析的性能。

表2 主要实验结果以及对比
另外,如表3所示,本文观察了实验中各个模型的情感预测结果,并对具有代表性的样例进行分析。表3(a)中的例子表明,我们的模型在综合考虑图片中的脸部表情等元素后,能够有效预测出观点实体词的情感倾向,而仅仅利用文本信息的BERT模型无法有效判断;表3(b)中的例子表明,本文提出的方法能够根据图片中的中立元素以及人的表情等来辅助文本进行情感分类,而BERT模型容易被纯文本信息所误导。

表3 样例分析
最后,本文探究了跨模态Transformer的叠加层数对于情感分类结果的影响。如图3所示,我们将跨模态Transformer的叠加层数分别设置为1~4,实验结果表明,跨模态Transformer的叠加层数对情感分类的影响并不显著,但是当叠加层数为1时模型取得了最好的结果。
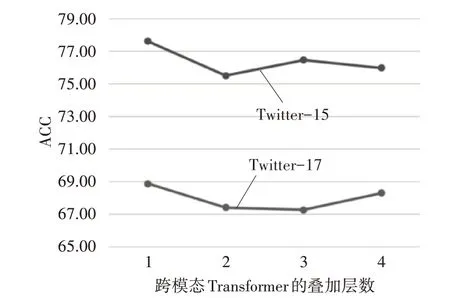
图3 跨模态Transformer叠加层数对实验结果的影响
5 结语
本文针对多模态细粒度情感分析任务提出了一种层次化跨模态Transformer神经网络模型(HCT)。该模型首先抽取图片中具有高级语义信息的特征,进而通过跨模态Transformer结构建模文本与图片间的信息交互以融合多模态特征,最终完成多模态细粒度的情感分析任务。
本文通过实验与现有的情感分析模型进行对比,验证了本文提出的模型在两个真实的多模态细粒度情感分析数据集上的有效性。未来我们将探索如何减小图片噪声的引入带来的影响,从而进一步在多模态细粒度情感分析任务上获得提升。
