一致性正则化与代理标签的骨骼点云半监督分割*
2023-01-06周长虹蒋俊锋张文玺黄瑞张昊陈
周长虹蒋俊锋张文玺黄 瑞张 昊陈 亮
(1.河海大学物联网工程学院 常州 213022)(2.溧阳市人民医院骨科 常州 213300)(3.上海长海医院血管外科 上海 200433)(4.常州锦瑟医疗信息科技有限公司 常州 213000)
计算机辅助的骨科术前规划中,如图1(a)所示,需要先提取碎骨的内外表面,以每个碎骨外表面为单元进行拼接从而完成骨折高效修复[1](见图2);另一方面,对骨病进行诊断时,也需要对骨骼表面的医学语义区域进行分割。如图1(b)所示,人体股骨可初步划分为股骨头、股骨颈、股骨干等医学语义区域,这些区域的划分对于骨骼畸形测量、骨骼疾病诊断具有重要意义[2]。现有的骨骼分割方法一般采用手动或半自动分割,分割效率低下,且通常依赖骨科医生经验,这会导致病人辐射次数较多、分割精度不高、分割时间较长等问题。

图1 骨骼语义分割

图2 骨折修复
近年来,利用深度学习进行三维物体语义分割已经成为研究热点。深度学习中,监督学习需要大量标注数据训练深度神经网络,由于手工标注费时费力,尤其对于骨骼标注,需要非常专业的骨科医生进行标注,成本较高,因此这也是制约当前骨骼语义智能分割的关键因素。
目前,为了有效提高无标签数据的利用率,半监督学习应运而生。半监督学习是利用小部分有标签数据和大部分无标签数据训练神经网络,从而尽可能提高神经网络的性能。半监督学习主要包括两种方法:一类是一致性正则化方法,另一类是代理标签方法。其中,一致性正则化通常利用“学生-教师”框架[2],对于同一无标签数据的不同增强形式,学生网络和教师网络预测要尽量一致,以此增加网络泛化能力。这类方法问题主要在于,当无标签数据存在噪声时,影响网络的一致性判断。代理标签法利用有标签数据训练的网络预测无标签数据的标签,网络输出置性度较高的作为伪标签数据,但不具备一致性正则化的优点。
针对以上问题,本文面向人体骨骼语义分割任务,并结合以上两种方法的优点,提出一种基于一致性正则化与代理标签的半监督分割方法(Consistent Regularization and Proxy Label,CRPL)。该方法将点云分割网络嵌入到“学生-教师”框架中,对于无标签数据,学生网络预测每个点标签概率进行高阈值过滤计算出代理标签与教师网络计算一致性损失,该方法增加了代理标签的可信度,降低了网络预测偏差。在实验部分针对碎骨内外表面分割与股骨表面语义分割两类任务,对本文方法进行较为全面的评估。
2 相关工作
CRPL方法的相关工作主要包括半监督学习和骨骼点云语义分割两方面研究。相关研究进展介绍如下。
2.1 半监督学习
半监督学习包含一致性正则化[2~3]、代理标签法[4]、混合方法[5~6]、生成式方法[7]以及基于图[8]等方法。其中,一致性正则化技术促使模型和数据收到干扰时,网络仍然可以输出相同的分布,关键点在于选择合适的扰动方式。代理标签方法是使用预测模型或它的某些变体生成代理标签来训练模型。混合方法试图在一个框架中整合当前的半监督学习的主要方法,从而获得更好的性能。生成式方法假设所有的数据都由同一个潜在的模型生成,难点在于在具体任务中很难做出准确的模型假设。基于图的方法试图通过构建图连接,来建立标签数据和无标签数据之间的潜在关系进行标签传播,但由于存储成本高难以直接处理大规模数据。
三维模型的半监督学习,按照三维形状的表示方式分为基于多视图[4]、网格[9]、体素[10]、点云[11]等方法。基于多视图的表示方法通过从不同视角获取物体信息,但很难描述物体三维内部特征。网格模型由于面片数量过多,处理起来往往比较复杂。对于基于点云表示方法,由于其简单的表示方法和良好的几何特征被广泛应用于深度学习领域。
2.2 骨骼点云语义分割
骨骼语义分割是将骨骼分成几个有意义的部分。按照是否利用模板,骨骼语义分割可分为两类:一类是无模板[12~13]方法,主要基于骨骼形态特点以及骨骼标志区域的空间位置关系提取参数;二是有模板[14~15]的方法,基于可变形模板[14]和多谱图[15]方法,通过拟合模板与目标骨骼,完成语义区域提取。按照骨骼是否发生骨折,骨骼语义分割可分为面向碎骨内外表面分割和完整骨骼表面语义分割,相比于完整骨骼,碎骨存在形态复杂多变、骨折断裂边界重合、细小碎片丢失等情况,加大分割难度。
利用深度学习方法进行骨骼语义分割已成为当前的研究热点。其中,三维点云分割方法包括PointNet++[16]、PointCNN[17]、DGCNN[18]等,这些都属于监督学习方法,需要大量标注完备的数据。骨骼数据获取十分困难,标注成本较高,半监督学习能有效降低数据标注的成本。目前面向骨骼点云的半监督学习研究尚未见公开报道。
3 本文方法
CRPL方法总体流程如图3所示,神经网络总损失由监督损失和无监督损失构成,其中监督损失由带标签的数据与学生网络输出计算交叉熵函数得到;无监督损失先由学生网络计算出无标签数据的代理标签,然后与教师网络输出计算交叉熵函数。教师网络参数由学生网络通过滑动指数平均[2](Exponential Moving Average,EMA)传递。
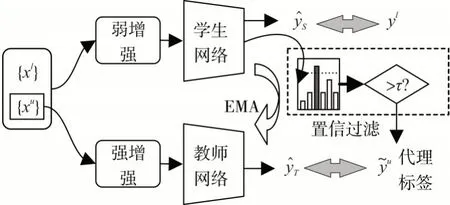
图3 CRPL方法流程
本文总体方法流程如下:
输入:标签集{xl,yl},无标签集{xu}
Step1:预训练阶段
1)由标签数据{xl,yl}得到学生网络输出,由监督损失进行梯度下降,更新学生网络参数。
Step2:训练阶段
1)通过EMA传播,计算教师网络参数。
2)根据{xl,yl}与{xu}分别计算学生网络输出ŷs与教师网络输出ŷT。
3)由学生网络输出ŷs与阈值τ计算无标签数据代理标签y͂u。
4)计算损失L=Ll+β(t)Lu,其中学生网络监督 损 失,无监督损失其中,β(t)为无监督权重,Bl、Bu分别为每批训练的标签数据和无标签数据量。
5)根据损失L,梯度下降更新学生网络参数。
4 方法细节
本文训练数据为标签和无标签骨骼三维点云数据,通过“学生-教师”点云分割网络得到骨骼每个点的语义标签,无标签骨骼数据经过学生网络预测得到的结果过滤得到代理标签,与教师网络的输出计算一致性差异,无标签数据训练细节如下。
4.1 代理标签生成
无标签数据的代理标签与教师网络的输出计算无监督损失,每个点的标签为学生网络输出经过置信过滤后选取后验概率最大的作为代理标签。在代理标签的生成过程中不可避免地会有一些不正确的预测。因此,需要进行标签选择以获得合适的代理标签。一般来说,具有较高后验概率的预测更有可能是正确的,常用的方法是设置一个严格的阈值,并选择在其之上的概率所对应的标签。代理标签生成公式如下。

其中,为学生网络点云的预测的概率分布,τ为置信阈值,在本文方法中取0.8。
4.2 “学生-教师”半监督训练
本节中主要介绍了“学生-教师”网络半监督学习损失的构成以及学生与教师网络之间学习原理。细节如下,“学生-教师”网络训练数据由标签数据集,和无标签数据集共同完成,标签数据计算监督损失,无标签数据计算无监督损失,总损失函数如下。
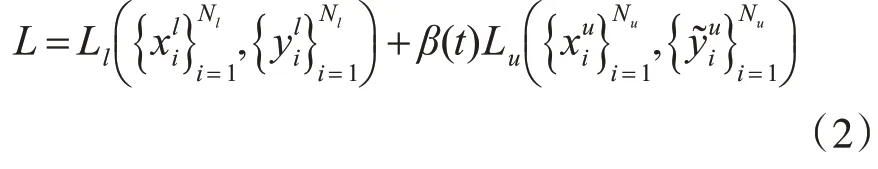
其中,Ll为监督损失,Lu为无监督损失,β(t)表示无监督损失权重,Nl、Nu表示标签数据和无标签数据总数。对于无监督损失权重β(t)的调度对网络性能非常重要。若设置过高,会影响标签数据的训练;反之,将无法利用未标记数据给学生网络带来的增益,影响网络泛化性能。β(t)表示如下。
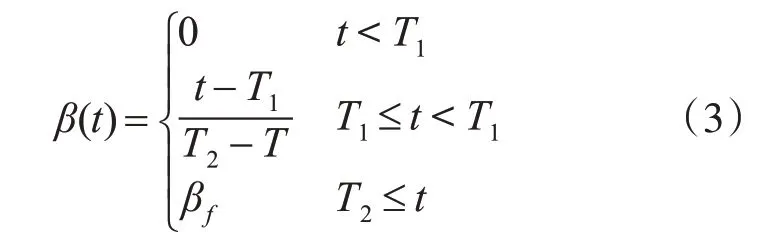
其中,βf=5,T1与T2为网络训练轮数,分别取500和1000。当t<T1,β(t)=0,神经网络在预训练阶段,损失由监督损失构成,可以加快网络收敛速度;当T1≤t<T1,通过缓慢增加β(t)的确定性退火过程,有助于在网络优化过程避免局部极小值,使未标记数据的代理标签尽可能与真实标签相同;当t≥T2,βf=5,网络处于稳定训练阶段。
半监督训练过程中“学生-教师”网络之间参数传递过程描述如下。首先,学生网络的参数由梯度下降法更新得到;然后,教师网络模型参数由学生网络通过EMA传递得到,并不与学生模型共享参数。神经网络训练过程中每个步骤都进行了EMA传播。与Temporal-Ensembling[3]等传统半监督学习相比,EMA有以下优势:1)学生网络之间有了更快的参数反馈循环,从而提高测试准确率;2)适用于大型数据集以及在线学习。EMA平均权重计算如式(4)所示。

其中,超参数α=0.999,表示平滑系数,即EMA权重。表示训练阶段第t步的教师网络参数,St为学生网络模型参数。当α=0,表示教师网络参数与学生网络参数相同。
在数据增强方面,本文采用了一种非对称式数据增强方式。学生网络采用了采样、平移、翻转的弱增强策略,学生网络本身的预测能力保证了代理标签的质量和数量;对于教师网络,在弱增强基础上增加了缩放与扰动的强增强策略,教师网络在训练过程中,需要保持一定的一致性差异来帮助学生网络更好地进行参数学习。经过对不同网络进行合理的数据增强,可以有效提高网络泛化能力。
5 实验分析
5.1 数据集
本文人体骨骼数据从江苏省常州市溧阳人民医院采集。实验数据具体描述如下:骨骼数据为CT影像扫描数据,男女比例为4∶6,年龄范围为30岁~80岁;分别使用了300例胫骨碎片与完整股骨数据作为本文的实验数据;所有的病人均签署了知情同意书。
5.2 实验环境与参数设置
本文实验基于PyTorch 1.7.1框架,实验平台为VSCode Linux x64,Python 3.7搭建在Ubuntu20.04 LTS系统上,测试环境为NVIDIA Quadro P4000(8G),系统内存为32G。所有模型的超参数设置相同,具体设置如表1所示。
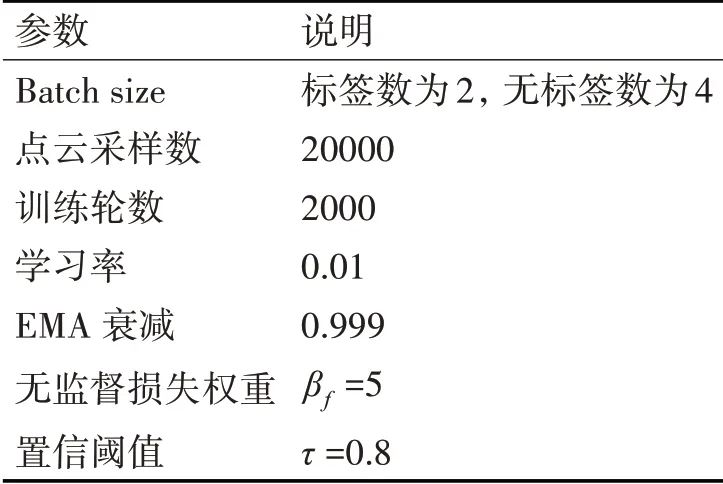
表1 CRPL超参数
5.3 实验分析
5.3.1 分割精度评估
利用平均类别交并比(mean Intersection over Unio,mIoU)衡量骨骼语义分割的准确度,计算出每个类别的交并比然后对其求平均,交并比计算公式如式(5)所示。

其中,TP表示交集,表示网络分割正确的点数。TP+FP+FN表示并集。FP表示网络分割错误的点数,FN表示网络漏分割点数。
本文网络预测精度如表2所示,结论如下:
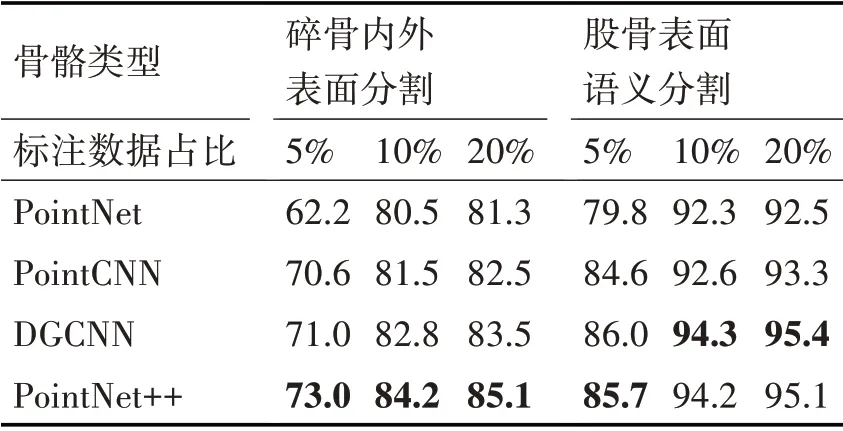
表2 点云网络分割精度对比(mIoU)
1)相同标注占比情况下,PointNet分割精度最低,DGCNN在股骨表面语义分割任务中平均高于PointNet++0.23%,但在碎骨内外表面分割任务中与PointNet++平均相差1.67%。因此,PointNet++相对于其他网络具有较好的数据兼容性;
2)同一点云网络下,对于两种分割任务,当标注占比由5%提升到10%,分割精度平均提高10%,由10%提升到20%时,分割精度平均提高0.8%。当标注占比达到10%左右,半监督学习网络达到了很好的分割性能。
5.3.2 方法效率
通过对点云网络的复杂度分析来评估本文方法效率,包括空间和时间复杂度。细节如表3所示。
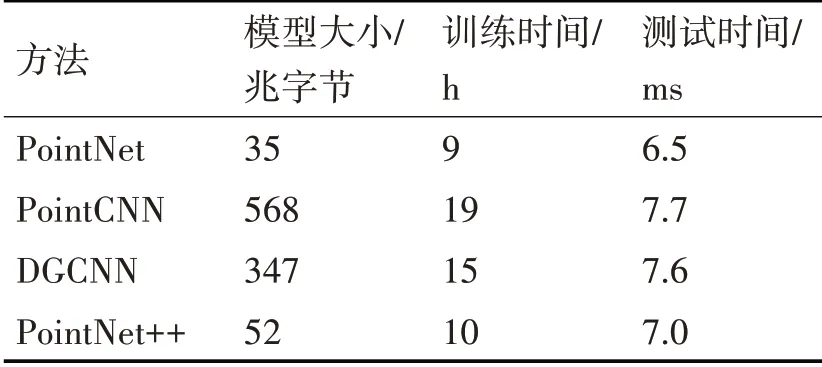
表3 方法效率评估
从表3可以得出以下结论:1)PointNet网络方法效率最高,PointCNN最低;2)四种网络测试时间相近,平均为7.2,平均训练时间为13.25;3)综合分割精度和方法效率,PointNet++方法效率高于DGCNN,分割精度高于PointNet。PointNet++优于其他三种网络。下文实验均采用PointNet++点云分割网络,标注占比10%进行半监督学习分析。
5.4 对比实验分析
为了验证本文提出的方法的有效性,本文与4种半监督学习方法模型进行了比较。其中,一致性训练方法包括Pimodel[3]、Temporal-Ensembling[3]、Mean Teacher[2],代理标签法选择Pseudo-Label[19]。在两种骨骼数据集下分别评估CRPL方法的有效性,其中监督学习指使用300例数据训练没有无标签数据训练的结果。
结合图4与图5,得出以下结论:1)随着标注数据占比的增大,神经网络参数拟合性能越来越好,准确率逐渐增加。当标注数据占比达到10%时,半监督学习准确率上升幅度变缓,预测精度达到了一个很好的效果;2)在两种数据集上,CRPL表现优于其他四种方法。
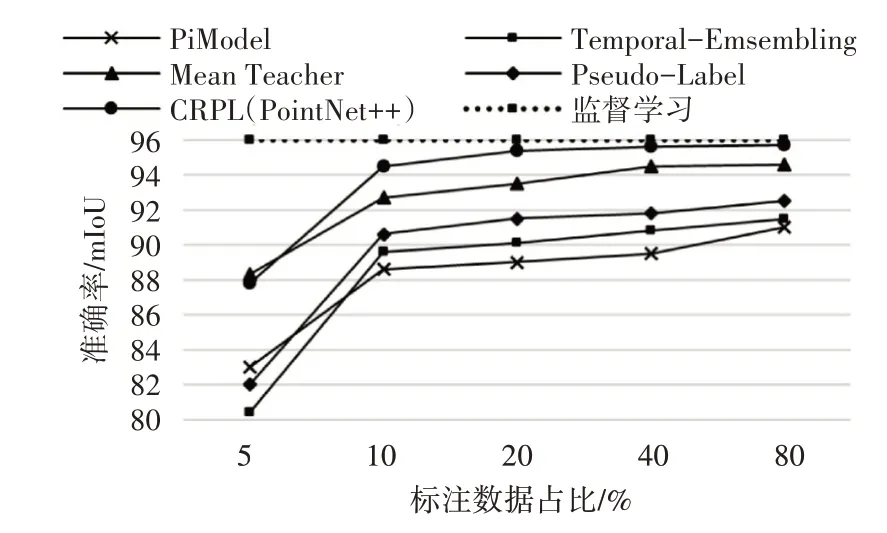
图4 股骨表面语义分割

图5 碎骨内外表面分割
5.5 消融实验研究
置信阈值的大小决定学生网络所产生代理标签的质量以及数量。通过改变阈值来探索阈值大小对分割精度的影响。如图6,当置信阈值取值在[0.55,0.8]范围,准确率呈现出上升的趋势。当置信阈值取值在[0.8,0.9]范围呈下降趋势。这是因为随着阈值的增加,点云代理标签点的确定性也会随之增加,表明高质量的代理标签能提高模型预测准确率。但阈值过大也会使学生网络生成的代理标签数量减少,从而降低网络分割性能。因此,通过选择阈值平衡代理标签的质量与数量,对网络分割效果具有重要意义。
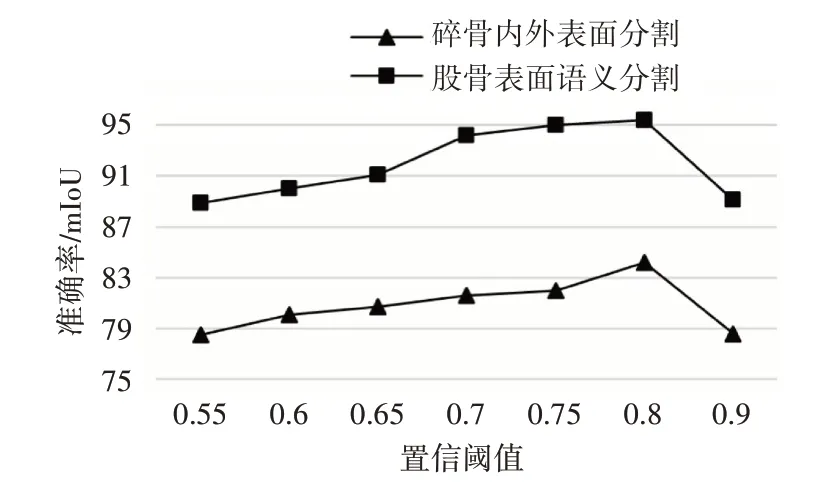
图6 阈值对网络精确度影响
6 结语
针对骨骼数据标注困难问题,本文提出了一种基于点云的三维骨骼半监督点云学习方法,该方法的核心思想是将“学生-教师”点云分割网络作为骨干网络,结合一致性正则化和代理标签思想,有效利用无标签数据训练神经网络。经过实验表明,该方法优于传统的一致性正则化和代理标签法,利用10%标注数据即可基本接近监督网络性能,高效地完成了骨骼自动化分割任务。
