基于多模态特征融合的驾驶员注视区域估计*
2023-01-06闫秋女张伟伟
闫秋女 张伟伟
(上海工程技术大学机械与汽车工程学院 上海 201600)
1 引言
分心驾驶是交通事故的一个重要原因[1]。导致分心驾驶的主要原因有智能手机、驾驶场景、行人及车载电脑等。随着现代电子技术的快速发展,分心驾驶引起交通事故的概率逐渐增加[2]。近年来,一些非侵入性司机的凝视检测和跟踪系统被提出[3]。由于注视方向与头部姿态之间的密切关系,许多方法都直接将头部方向作为衡量驾驶员注意力的指标[4]。然而仅使用头位姿估计相邻区域的效果较差。Tawari[5]等提出了增加眼睛特征可以显著提高凝视区域的分类精度。Fridman[6]等进一步证明了仅移动眼睛时的凝视区域估计精度要高于频繁移动头部时的凝视区域估计精度。因此,目前先进的驾驶员注视区域估计技术通常使用头部和眼睛特征来判断司机而非分心与否。
目前,头部位姿估计研究方法较为成熟。在特殊传感器的帮助下,Lee[7]等利用人脸模型和水平边缘投影直方图来确定驾驶员头部的偏航角和俯仰角。Friedman[6]等利用方向梯度直方图和线性支持向量机对人脸特征点进行定位,然后利用随机森林算法对注视区域进行分类。Smith[8]等结合学习和基于模型的方法来估计头部姿态。Choi[9]等通过卷积神经网络获得驾驶员头部姿态。
传统的人眼区域特征提取方法主要集中在瞳孔位置检测上。在以往的实验中,获取瞳孔位置需要额外的近红外光源来产生明亮的瞳孔效果,但是这种系统的性能很容易受到光照变化的影响,特别是在现实世界的驾驶场景中。近几年Fridman[10]等提出了从瞳孔位置和眼中心来估计三维注视方向的方法。Yang[11]等使用一系列回归矩阵来训练虹膜检测模型。Vicente[12]等通过瞳孔特征建立三维人眼模型,然而在低分辨率图像中寻找瞳孔的准确位置是一个困难的任务。Fischer[13]等提出了基于外观的卷积神经网络算法实习进行实时凝视估计。
如何利用获得的头部姿态和人眼特征来确定视线方向也是一个难点。Valenti R[14]等利用眼睛位置的转换矩阵来调整驾驶员的头部姿态。在最近的工作中,随机森林算法用于对驾驶员凝视区域估计,然而在实际驾驶场景中,在驾驶场景和驾驶员姿态多样性的影响下,该方法估计效果差强人意。
基于上述问题,本文提出了一种新的人眼特征提取及驾驶员注视区域估计的方法。本文考虑了人眼状态和头部姿态对驾驶员视线估计的影响。首先,采用遮挡自适应网络(ODN)作为人脸关键点检测,并采用POSIT算法对驾驶员头部姿态进行解算并得到驾驶员头部姿态。基于3D人眼模型的方法由2D关键点估计驾驶员视线方向。最后,结合驾驶员头部姿态及人眼凝视方向特征,利用改进的随机森林算法对注视区域进行估计。
2 驾驶员注视区域估计方法
本文提出的驾驶员注视区域估计方法包括四部分:人脸及人脸关键点获取、头部姿态解算、人眼视线方向建模及改进的随机森林算法,总体流程如图1所示。
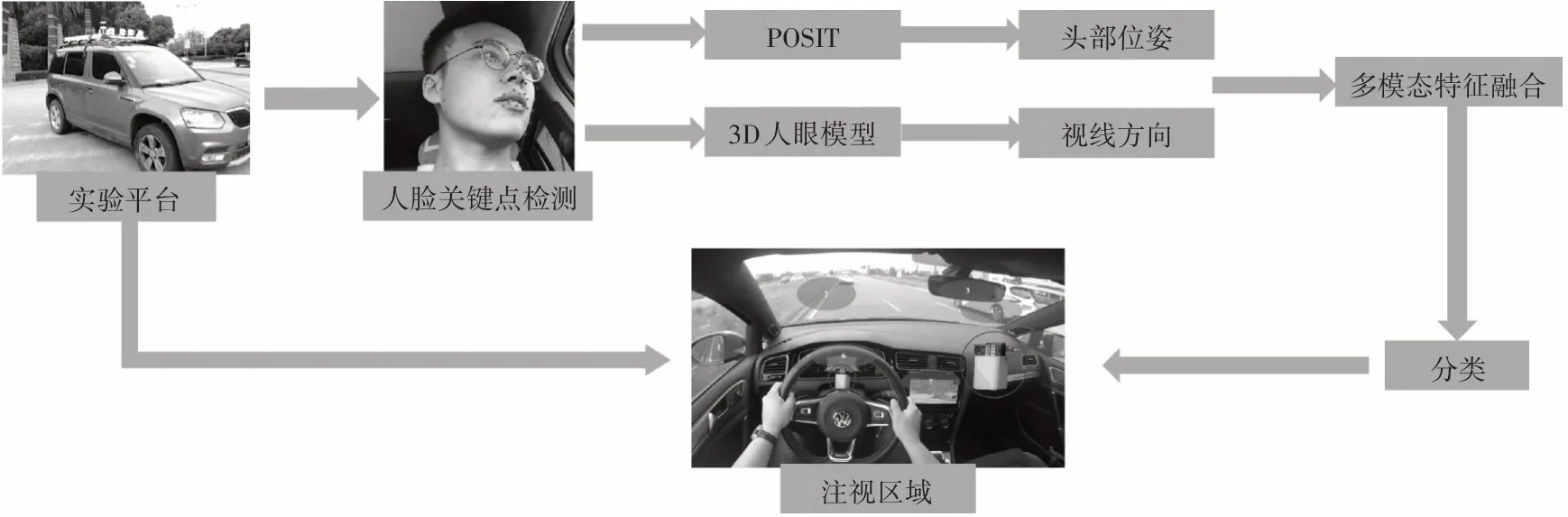
图1 驾驶员注视区域估计方法
2.1 人脸检测及关键点获取
源于遮挡自适应网络[15]和融合全局和局部视觉知识的方法[17]的启发,本文提出遮挡净化人脸检测器。具体来说,将ResNet-18[16]的最后一个残差单元修改为本文所提出的遮挡净化网络框架,以有效地解决人脸遮挡问题。如图2所示,遮挡净化网络框架主要由三个紧密结合的模块组成:几何感知模块、特征恢复模块和低秩学习模块。首先,将已有残差学习块的特征映射Z分别输入到几何感知模块和提取模块中,获取人脸几何信息并得到清晰的特征表示。然后将这两个模块的输出送入低秩学习模块,低秩学习模块通过建模人脸的特征间相关性来恢复缺失的特征。我们利用低秩学习来学习一个共享的结构矩阵,它显示编码特征之间的关系,从而可以恢复缺失的特征并去除冗余的特征。

图2 遮挡净化网络结构
本文提出的几何约束模块为Bi-CNN结构:CNN stream-A(SA)和CNN stream-B(SB)。在不影响卷积层接受域的前提下,在SC和SD的前后设有1×1的卷积层。为了获取多尺度特征,在CNN stream-A和CNN stream-B中间分别包含3层3×3的卷积层和3×3的卷积层。在该模块中,结合多层卷积特征的由粗到细的机制,采用后一个卷积层(细层)与前一层(粗层)的特征向量之间的相互关。捕捉到局部子类之间的细节差异并提高该模块的识别能力。与几何约束模块类似,本文提出的遮挡净化模块也是采用Bi-CNN结构,包括CNN Stream-C(SC)和CNN Stream-D(SB)两个子结构,Sc结合残余块避免输入信号的衰减;SD作为一个遮挡感知结构,自适应地预测每个位置的遮挡概率。SD最后一层卷积层输出一个单通道的特征映射,通过Sigmoid激活函数归一化生成概率映射。我们通过element-wise multiplication将概率映射集成到Sc特征映射输出,给遮挡位置甚至背景位置分配小的权重。最终得到人脸加权特征图。由于遮挡净化模块过滤了遮挡区域的特征和背景中不相关的信息,使得混合特征表示不完整。最后我们采用低秩学习的方法来学习显式编码人脸内在特征相关性的共享结构矩阵,从而恢复缺失的特征。
在本文使用的遮挡净化框架中,几何感知模块、特征恢复模块与两个主要信息相关,分别是遮挡感知和几何关系。具体地说,不同的面部成分之间存在着强大的不变的几何关系,如对称关系、邻近关系、位置关系等,这些关系可以被提出的几何感知模块捕捉到。另一方面,特征恢复模块可以滤除背景中的遮挡区域和无关信息。根据几何特征,一个分量丢失的信息可以通过其他分量来推测。遮挡特征恢复模块和低秩学习模块属于对立与互补的关系,是有益的适用于人脸的特征学习。从上面可以看出三个模块的结构关系促进OFN解决遮挡问题。通过上述方法的人脸关键点检测结果如图3所示。其中红色原点表示遮挡恢复的人脸关键点。

图3 人脸关键点检测结果
2.2 驾驶员头部姿态解算
在获得人脸关键点坐标后,需要解算驾驶员头部位姿。本文采用的POSIT算法[18]基于普通的针孔相机成像模型。该算法主要通过非共面空间点与其二维图像的对应关系来解决目标的位姿问题。在驾驶员头部解算的任务中,POSIT算法根据驾驶员面部特征点在图像中的位置,计算头部旋转姿态在特定坐标轴上的值。与其他的头部姿态估计算法相比,POSIT算法简单并且处理速度迅速,可以达到检测视频流的每一帧。POSIT算法的核心计算公式为
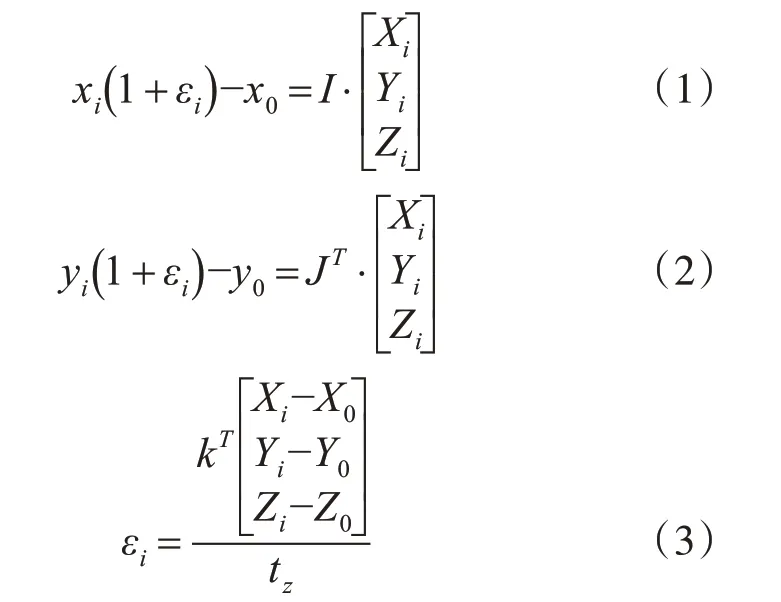

图4 头部姿态估计结果
2.3 驾驶员视线方向估计
如图5所示,本文采用基于3D人眼模型的方法估计[19]驾驶员视线方向。该模型需两个主要的假设:其一,眼球是球形的,因此相对于头部模型眼睛的中心为刚性点[20];第二,眼睛是睁开的,因此所有眼睛轮廓点都可以认为是刚性的。由OFD遮挡净化人脸检测器和SDM跟踪器检测器[19]可得到包括瞳孔在内的所有眼部关键点。对2D人眼图像中眼睛轮廓点构造三角形网格,并确定瞳孔位于哪一个三角形网格中。然后,计算包含瞳孔的三角形网格内瞳孔的质心坐标。最后,利用二维网格与三维网格的对应关系,在三角形质心坐标系下计算三维瞳孔点。在得到瞳孔的三维位置后,我们可以通过3D眼中心和3D瞳孔所在的直线得到驾驶员注视方向。

图5 驾驶员注视方向估计
2.4 改进的随机森林算法
将上述驾驶员头部姿态特征及人眼注视方向特征融合,采用改进的随机森林算法用来预测注视区域。为了解决随机森林难以处理连续值的问题,改进的随机森林算法在分类前对连续值进行无监督聚类、决策树的分叉采用完全随机的原则、并且每棵决策树的训练集是通过随机抽样得到的。待训练的随机森林包含M棵树并且每棵树TM来自原始训练集的不同样本集进行训练。视线估计训练数据集定义为N为训练样本子集的数量,xi为特征空间中第i个包含头部姿态特征及人眼注视方向特征的深度特征向量,yi为三维空间中第i个注视区域。首先,随机选取k个训练子集,每个样本子集独立完成随机森林中建树过程;构造决策树时随机选取出nf个特征按照信息增益率去完成分叉工作;每一个样本子集都按照上述方法建立决策树及生长;最终所有生成的决策树一起构成了改进的随机森林。
3 实验结果与分析
3.1 ND-DB数据集
为了获得一个充分有效的图像数据集,我们建立了如图6所示的真实驾驶情况写的驾驶员注视区域的数据集——ND-DB数据集。邀请15个驾驶员(其中9个驾驶员配戴眼镜)进行实验。在实验过程中,驾驶员根据提示注视8个不同的区域。每个区域的凝视时间为20s,数据库包含15段视频,100710张照片。在实验中,通过注视估计来判断驾驶员的注意力分散状态。如图7所示,共有八个凝视区域,第八个凝视区域为“闭眼”。

图6 数据集部分图片示例

图7 真实驾驶条件下凝视区域
3.2 驾驶员注视区域分类结果
对ND-DB数据集进行分类,以测试该方法在实际环境中的作用。本实验通过宏观平均精度、微观平均精度及混淆矩阵三个评价指标[20]对分类性能进行评价。根据提取头部姿态特征和人眼特征,利用含有150棵决策树来估计注视区域。最终实验各区域的宏观平均精度为93.87%,混淆矩阵的具体结果为如图8所示。
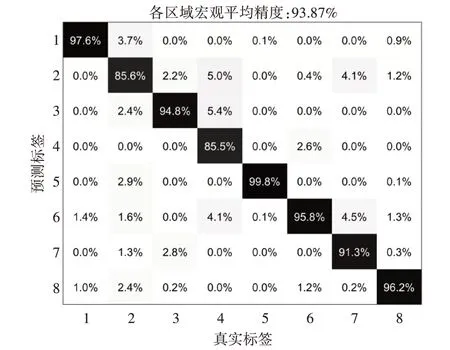
图8 驾驶员注视区域混淆矩阵
3.3 驾驶员注视区域准确率及实时性分析
我们在四个不同的数据集:CAVE、MPⅡGaze、EYEDIAP及ND-DB上对本文提出的方法和其他先进的方法进行比较。如图9所示柱状图显示了所提方法在以上数据集上的宏观平均精度从左向右递增。显然,这与ND-DB的适用性有一定的关系。同时,根据折线图,所提方法在每个数据集上获得最高的宏观平均精度。总地来说,本文在获得宏观平均精度和微观平均精度方面优于其他方法。

图9 不同数据集上宏平均精度和微平均精度与其他方法的比较结果
为了分析本方法的实时性,本文统计了以上四种方法的计算用时。实验中采用的计算机配置是Intel Core i7-9700 CPU,NVIDIA GTX1660。人脸关键点检测使用了Caffe框架实现,头部姿态解算使用了CVPOSIT()方法。实验测试了ND-DB数据集上5分钟的视频,平均帧率可达12.5FPS,各检测阶段的平均耗时如表1所示。从表中可以看出头部姿态解算和注视区域估计的耗时较少;人脸关键点的获取耗费较长时间,系统整体运行速度可以达到实时要求。

表1 时间性能分析
4 结语
本文对真实驾驶场景下估计驾驶员人眼注视区域,并降低设备的硬件要求,提出了一种基于多模态特征融合的驾驶员注视区域估计的方法。首先,应用本文提出的遮挡净化人脸检测器获取人脸及人脸关键点。然后采用POSIT算法对驾驶员头部姿态进行解算并得到驾驶员头部特征。随后,基于3D人眼模型的方法由2D关键点估计驾驶员视线方向。最后,结合驾驶员头部姿态及人眼凝视方向特征,利用改进的随机森林算法对注视区域进行估计,对于真实驾驶世界数据集有较好的性能。实验结果表明,本文提出的方法真实驾驶场景数据集ND-DB及其他实验室场景数据集,具备较强的鲁棒性和较高的驾驶员注视区域估计准确度。
