基于机器视觉的工厂人员异常行为识别*
2023-01-06李昊朋王景成黄姣茹
李昊朋王景成黄姣茹
(1.西安工业大学电子信息工程学院 西安 710016)(2.上海交通大学自动化系 上海 200240)
1 引言
人体行为识别是目前计算机视觉领域中非常热门和具有挑战性的内容之一,其研究方法分为人工特征[1~2]表示以及深度学习的特征表示[3]。
文献[4]提出的视频监控系统可以把图像中的人体和背景的分布进行分割,分离出的人体部分可以用建模方式进行检测,然而由于网络结构以及数据集的限制,此方法运算的速度和准确度不高。文献[5]提出的双流融合3D卷积技术从两条分支网络得到彩色和深度行为特征,此方法虽然可以达到目前主流行为识别算法的水平,但是受硬件限制较大,难以部署到轻量化的操作环境。
针对上述准确度不高、计算速度较慢的问题,本文提出了融合了目标检测和行为检测的机器视觉检测方法。从YOLO目标检测入手,主要面向多人图像,利用Blaze Pose关键点检测和ST-SVM分类器以及角度识别结合的方法,得到图像特征信息;之后通过制定决策融合策略,对两种图像行为信息进行决策融合,得到最终行为识别结果。
2 系统设计
基于机器视觉的工厂人员异常行为检测包括多人图像分割、人员行为识别和决策融合等几个关键步骤,系统的具体结构框图如图1所示。
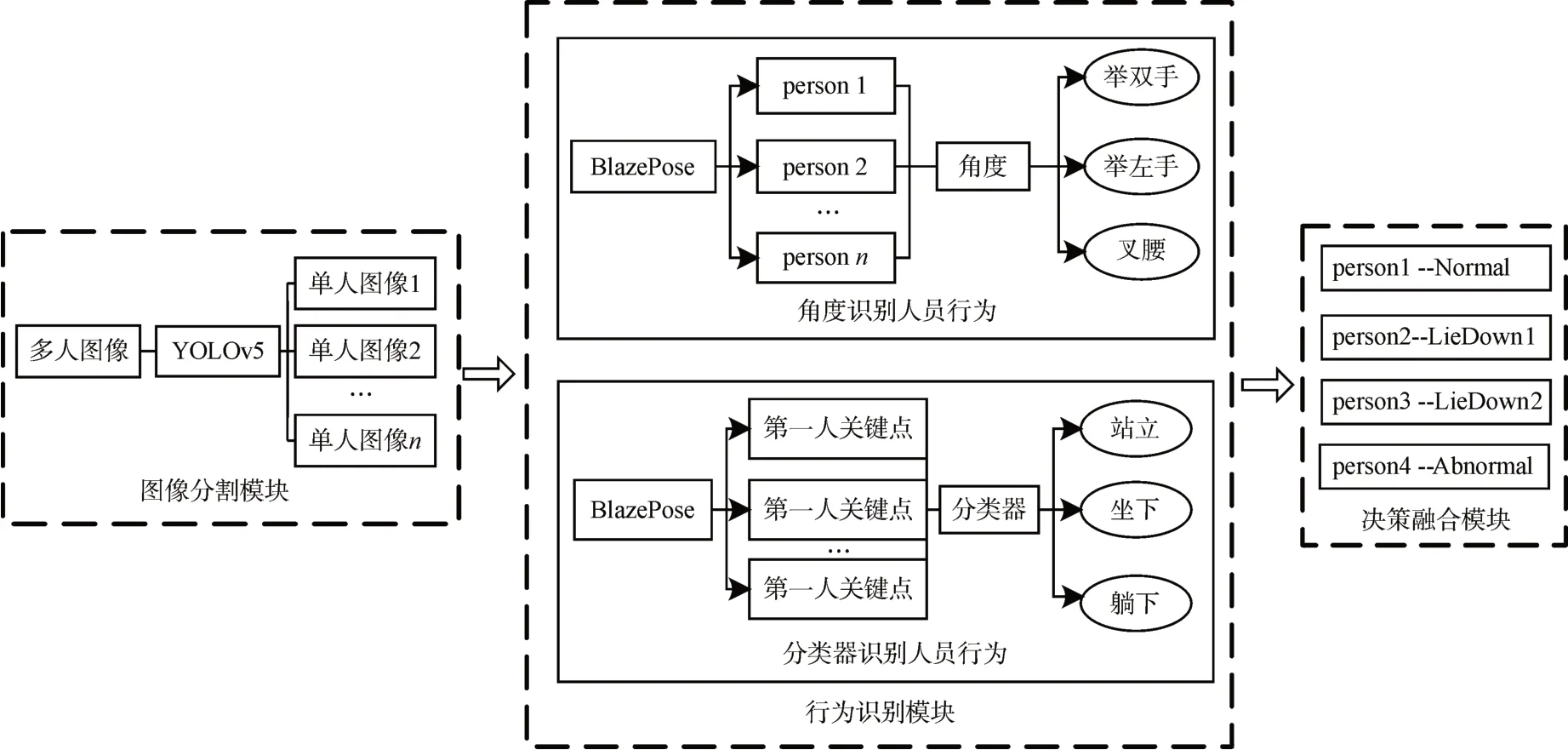
图1 多人行为识别框架图
本文选择使用YOLOv5算法将多人图像分割为单人图像[10~12]。之后使用Blaze Pose识别单人图像中的骨骼关键点,并对提取出的数据进行处理。利用角度判别的方法,得到图像行为1。再将关键点数据归一化后,送入分类器中进行预测,得到图像行为2。最终使用制定的规则对两种图像行为决策合并,得到最终的行为信息(怠工、姿态异常等)。
3 系统原理
3.1 角度行为识别
在实际的场景中,一些动作的姿态点有一定的规律,比如当人的双手举起来时,大臂与肩膀的矢量角度会大于0°(以右下为坐标轴正方向),当人叉腰的时候,大臂与小臂的角度会大于60°且小于120°等。如果通过Blaze-Pose的坐标得到一些基于关键点的矢量信息,就可以通过计算矢量之间的夹角,从而获得人员的行为信息[15]。基于Blaze-Pose实现的角度判别行为示例如表1所示。
矢量间的角度计算公式如式(1)所示:


以表1给出的四种行为为例,结合正常人员行为,给出的人员站位情况如图2所示。

表1 基于关键点角度的行为判别
图2(a)为角度识别人员行为的正常人员空间站位,右肩关键点3与左肩关键点1坐标作差可得矢量S1,左肘关键点2与左肩关键点1作差可得矢量S2,两矢量在空间意义上的夹角为θ1,而正常状态下人员的左臂小臂自然下垂时,θ1<0。同理正常状态下右臂与水平夹角θ2也小于零。图2(b)为举左手的人员空间站位,左臂举起,则矢量S1与矢量S2之间的夹角θ1大于0,右臂正常,判定为人员举左手。举右手则与举双手同理。图2(e)为双手叉腰状态的人员空间站立,人员关键点1与关键点2矢量记为S3,关键点2与关键点3之间的矢量记为S4,当做叉腰动作时,两个矢量之间的夹角60°<α3<120°,左臂同理,当两条手臂的夹角同时满足叉腰条件,则判定为双手叉腰[13]。
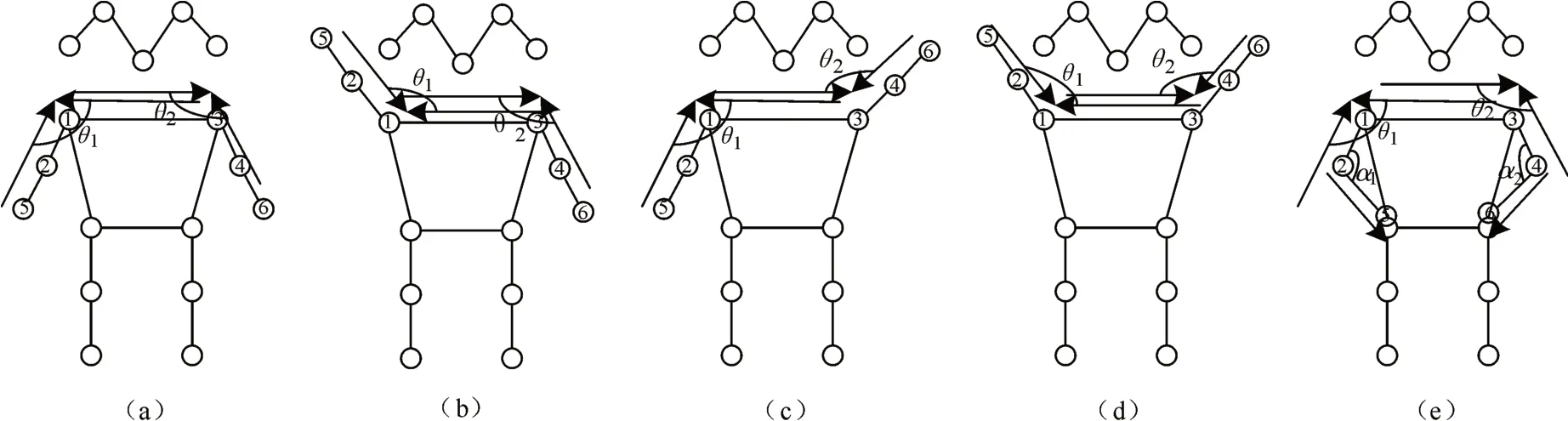
图2 人员空间站位图
3.2 ST-SVM行为识别
目标分类主要用来对提取出的人体关节点数据进行分类,从而判断出人员当前行为。Blaze Pose关于人体的关键点可以检测出33组,但是本文仅需通过分类器检测出人员站立、坐下以及躺下三组基本行为。因此,本文采用双肩、双髋以及双膝8组关键点的输出格式,关节拓扑如图3所示。

图3 用于分类的人体拓扑图
通过Blaze Pose获取到人体关节点坐标后,将归一化后的坐标作为分类数据,通过SVM分类器进行分类。但是SVM算法本质上是一个二值分类器,不适合用于多分类任务中。因此,需要构造合适的SVM多类分类器,常用来构建SVM多分类器的方法有直接和间接法两种。本文采用间接法中的基于决策树的SVM(ST-SVM)对人员行为进行分类,首先将所有类别分为两个类别,接着再将子类进一步划分为两个次级子类。反复循环,直到所有节点都只包含一个单独的类别为止。
3.3 行为决策融合
本文选取实验场景为洛阳中航光电矩形弹簧SMT组装车间,此车间秉承“质量第一、持续改进和打造精品”的质量方针,无论是对工序还是对员工的生产要求都极高,选取此场景作为实验场景符合本文涉及课题的要求。
文中融合决策由工厂内分发调查问卷,以及实地考察过后调整得到。在整理的策略中选出具有代表性的四种作为参考,如表2所示。

表2 部分融合行为决策
SMT车间组装矩形弹簧工位较其他工位略简单,适合做场景内的人员行为分析,表中规定时间为厂区内的正常上班时间,即8:00-11:00,14:00-20:00,在此时间段内,员工若是在规范工位正常工作,则判定为无异常行为,表现形式为Normal;而若是通过图像检测到人员在正常上班时间内,坐下并身子后仰、站立叉腰或者趴在桌子上,则判定为怠工,表现形式分别为LieDown1和LieDown2;若是检测到人员有趴在桌子上或者躺下的行为,则判定为Abnormal。
针对各异常行为的处理,可以通过异常行为层级来进行。异常行为越严重,其异常层级就越高,对此工位人员的处理方式也会越严厉。
比如LieDown1可能是工位内人员久坐后无意伸的一个懒腰,此时并不需要将其记录到异常行为中;而Abnormal行为的情况比较严重,有可能是员工在上班时间休息,也有可能是员工在正产工作中摔倒,此时就需要车间的管理人员立即做出处理。异常行为层级可以有效地避免人力资源浪费的问题。
4 实验结果与分析
4.1 ST-SVM结果分析
支持向量机的训练数据集为工位内单人的拍摄视频,针对分类的行为仅设置了站立、坐下和躺下三种,由于拍摄的视频为60fps,因此每隔30帧选用一张图片。其中站立行为选用3000张图片,坐下行为和躺下行为各选用2500张图片,并选用不同工位员工,各三种不同的行为作为数据集。并按照一定的比例将数据集随机划分为训练集、交叉验证集和测试集。
训练和交叉验证过程的损失值和准确率如图8所示。将学习率设置为0.0001,Batch Size(每次训练抓取训练样本数)设置为32,Epoch设为100。
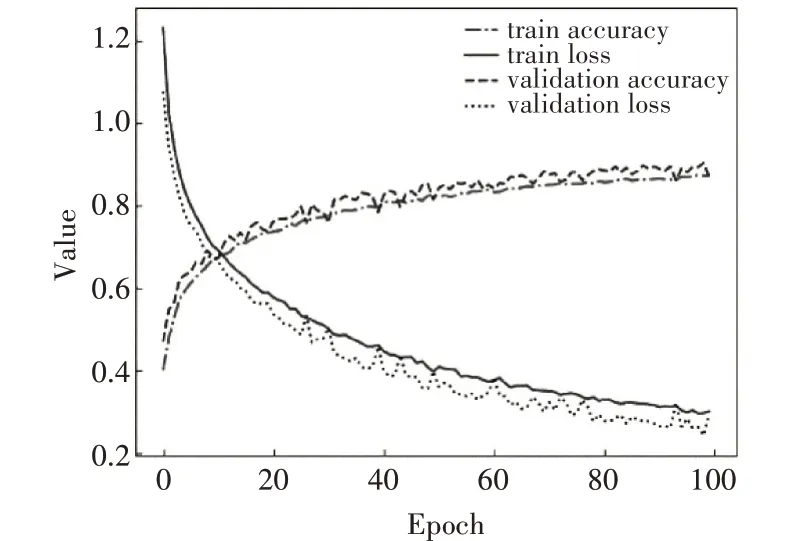
图4 损失值和准确率
为了方便比较,在使用ST-SVM训练的同时,同时采用经典SVM分类、随机森林(RF)和逻辑回归分类(LR)三种分类方法对现有数据进行识别对比。
本文采用召回率(R)、准确率(A)和F1指数对模型的识别结果进行评价[14]。计算式如下:
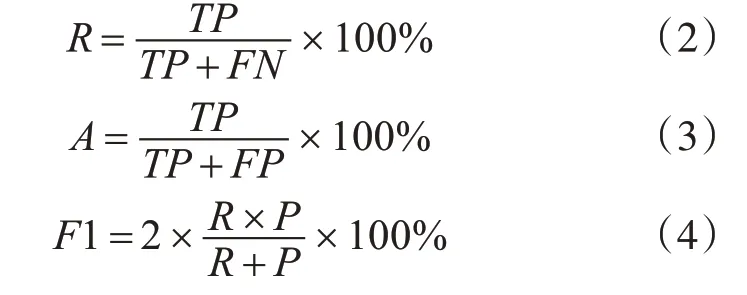
ST-SVM的测试数据集有1600张图片,其中图片已全部标注,站立行为有600张,坐下和躺下行为各有500张。对测试数据集进行分类,可以得到三种行为的分类数据,如表3、表4和表5所示。
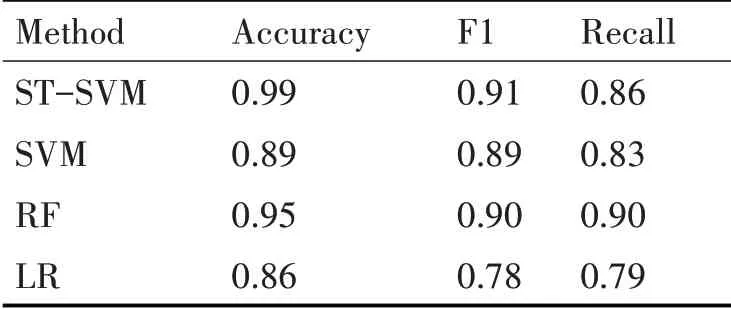
表3 站立行为分类数据
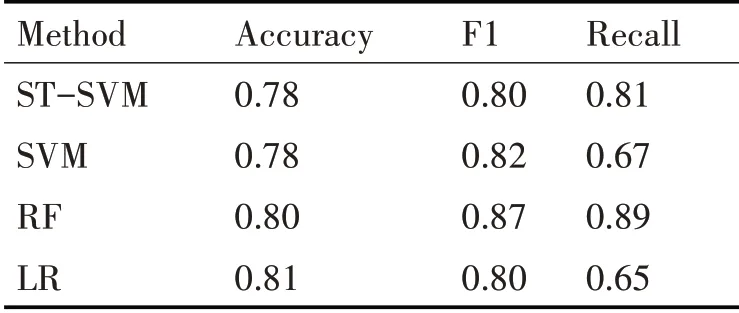
表4 坐下行为分类数据

表5 躺下行为分类数据
4.2 行为决策融合
为了尽可能增加场景的多样性,选取两个工位,各三个视角的监控视频作为实验数据。同时为了保证实验无偏差进行,选用正常和非正常工作时间不同时段的视频作为实验数据。而为了保证实验的正确性,实验从各个视频一共截取了1000张图片作为数据集。
首先使用人工标注的手段,根据表2制定的人员决策规定,将每一张图片中的人员行为手动标注出来,默认人工标注的行为准确率可达到100%。
将1000张实验图片输入进模型进行检测,并以人工标注的行为为目标进行拟合。
针对实验结果,使用精确率、召回率和F1指数对各种行为进行评价,评价指数如表6所示。
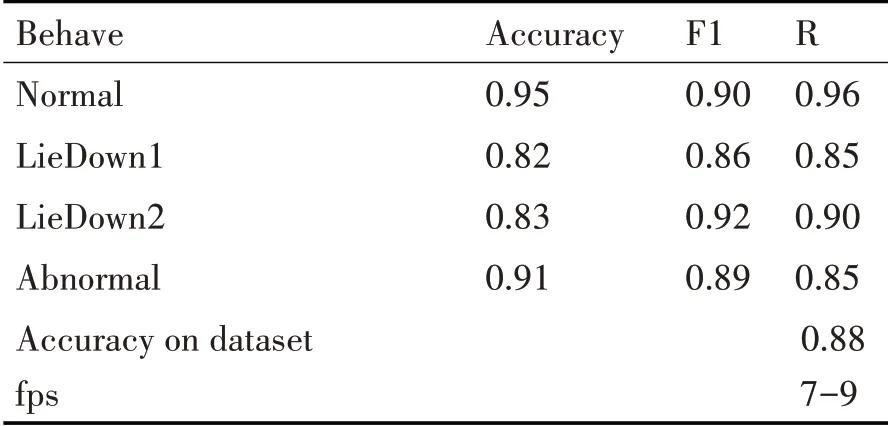
表6 定义行为识别精度
由表6可知,正常工作的精确率可达到95%以上,而对于比较复杂的姿态异常,检测准确度只有91%。
对于标注的1000张图片的混淆矩阵如图6所示。纵坐标为真实类别,横坐标为预测类别,Normal、LieDown1、LieDown2和Abnormal四种行为用0,1,2,3表示。
通过混淆矩阵可以看出,四种决策行为基本上都可以检测出来,怠工行为1和怠工行为2检测稍有偏差,有一些误判;而正常工作和姿态异常偏差和误判相比之下并没有那么严重。
除了本文的方法,常见的行为识别方法还有HOG特征提取+SVM分类[16]以及3D卷积[5]两种。
应用本文挑选的1000张图片作为数据集,对两种方法进行复现,其识别率和运行速度与本文方法对比数据如表7所示。

表7 各方法平均识别率对比
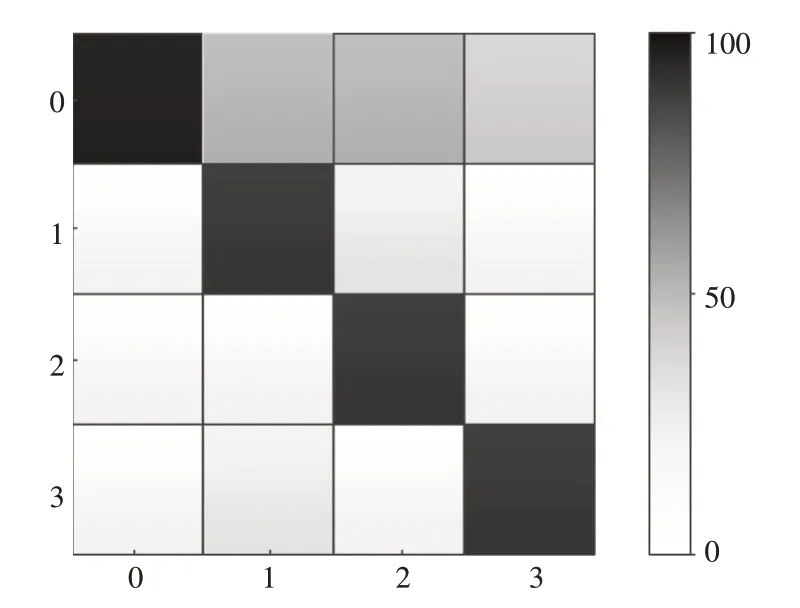
图5 测试结果混淆矩阵
本文提出的行为识别类似基于检测的两阶段方法,虽然精度比HOG高1%,比3D卷积高4%-5%,但是速度远达不到要求。
使用本文方法的识别结果序列如图6所示。

图6 策略融合后的检测结果
5 结语
本文针对工厂内人员的异常行为进行分析,首先使用YOLOv5将多人图像分割为单人图像,之后使用Blaze Pose获得人体关键点,并用角度识别和分类器识别获得图像行为,在制定融合决策之后,可以实现对工厂内多人行为的正常工作、怠工和姿态异常等行为进行识别,但是与3D卷积等一阶段的识别方法相比,精度虽然有所提升,可是速度却达不到要求。因此,如何在继续保证精度的前提下,提升系统的检测速度,将是下一步的研究方向。
