基于改进经验小波能量熵的负载侧新能源占比定量研究
2023-01-04鲍家伟王青松
鲍家伟,王青松
(东南大学电气工程学院,江苏 南京 210096)
自然环境与能源紧张问题是现阶段全球经济发展面临的主要问题.基于对生态环境保护的基本要求,同时也基于碳中和的目标,中国电力清洁化不断提速,以风电和光伏发电为主的可再生能源将迎来加速发展.考虑到经济全球化的进程,一些大型企业在购买电能时,注重电能的清洁性,致力于使用低污染水平的电能.因此,这也对电力系统调度提出了更高的数据挖掘要求[1-2].
为了提升宏观经济水平,提升三次产业的发展,要在调度侧能较准确的把握用电属性、用电规模、用能趋势.因此,迫切的需要研究站端负荷宏观辨识方法,实现调度对用能群体及占比的管控[3].
从负载侧定量分析可再生能源发电占比,首先需要对采集到的数据信息进行分析处理,从宽频频谱上提取其特征.傅里叶变换是一个最基本的频域分析方法,它利用三角函数作为基函数,对整体序列进行变换处理,获取整个频域上的全局信息[4].但其无法反映信号局部特征,不适用于分析由于可再生能源接入,而导致的瞬态脉冲、瞬态振荡等变化快,持续时间短的电能质量问题.小波变换是一种多尺度的时频变换,广泛应用于分析突变信号和不平稳信号[5],但有着基函数选取困难等问题.文献[6]利用短时傅里叶变换,加窗处理后,对得到的信号片段分别进行傅里叶变换,获取信号的时频特征.它一定程度上改善了傅里叶变换无法反映局部特性的缺点,但需要固定时频窗口的长度,面对信息量不同的序列处理效果不一.文献[7]提出了自适应无参经验小波变换方法,解决了传统傅里叶变换自适应度差的问题,但是缺乏对特征信息的进一步挖掘.小波能量熵[8-10]是一种对特征量进行二次计算的分析算法,通过对小波变换得到的特征分量进一步分析计算,得到各部分的能量熵作为新的特征量,具有更明显的频谱特征.
目前,涉及到定量分析的算法研究较少,多数是利用机器学习的方法.目前基于特征选择方面应用较多的方法有基于群体的遗传算法[11]、粒子群优化[12]、蚁群优化[13]算法等群体智能算法.文献[14]基于蚁群算法通过对信息素的合理配置得到高容错性的分类定位方法,但应用面较窄.文献[15]通过粒子群算法对小波提取出的特征向量进行动态筛选,准确度提高,但是设计结构复杂.传统BP神经网络(Back Propagation Neural Network,BPNN)具有更强的自适应度[16],但收敛结果较慢,且不适用于处理长时间序列问题.文献[17]提出了双层BPNN结构,利用父系子系两层网络,双重识别分类,但存在训练时间较慢等问题.
基于以上考虑,本文针对低压馈线上可再生能源功率占比问题,提出一种基于改进经验小波能量熵法和长短期记忆神经网络(Long Short Term Memory,LSTM)的定量分析算法.本文先通过经验小波变换(Empirical Wavelet Transform,EWT)对采样的电压电流信号进行预处理,其次依据各经验模态函数(Empirical Wavelet Function,EWF)分量求取其能量熵,分别分析能量熵序列的内部差异性,引入加权系数,经过数学处理得到改进能量熵序列;最后将改进能量熵序列作为LSTM神经网络的训练样本,测试不同新能源占比下算法的判断准确度.通过搭建可再生能源接入的配电网模型,得到模拟数据,将本方法与传统方法进行比对,验证了本文算法定量分析的有效性与准确性.
1 基于改进经验小波能量熵的特征提取方法
改进经验小波能量熵的步骤分为三个步骤,首先是对原始信号进行经验小波分解,其次对各频段下的分量计算得到能量熵序列,最后分析能量熵序列的特征差异性,借助峭度值得到一种改进能量熵的特征提取方法.
1.1 经验小波变换
经验小波变换在傅里叶频谱的基础上,对其进行自适应分割.在获取频域信息后,通过确定极大值点的方式,实现对信号模态的分解.
EWT首先将频谱范围归一化到[0,π]上,并将其分割为k个连续的小段频谱.其次,依据Meyer小波构造尺度函数φi(ω)和经验小波函数Ψi(ω),其中:
(1)
(2)

(3)
β(x)=35x4-84x5+70x6-20x7
.
(4)
重构信号的表达式为
(5)
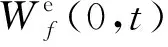
(6)
1.2 小波能量熵
由于EWF分量的数据量大,且特征信息不明显.为了得到后续智能算法的训练样本,采用能量熵的方法,对得到的EWF分量进一步处理.

(7)
求取小波能量熵前,我们先要求取各频段下的小波能量.将原始信号分解为EWF分量后,设信号序列f(n)在各个频段上的分量为EWFj(n),则小波能量为
(8)
由于信息熵所用的概率p满足和为1,因此求取相对能量,即
(9)
故小波能量熵为
ε=-∑jPjln(Pj)
.
(10)
同时,考虑到采样信号为稳态运行下,负载侧的电压电流信号.因此各个周期内的特征信息呈现相似性的特征.为了最大化体现单周期内的特征量,对原始信号做时域上的分段处理,设拆分为k个子序列,对每个子序列进行经验小波分解,并且计算各自的能量熵,得到一个周期内的能量熵序列{Entropy(k)}.
1.3 改进能量熵
考虑到新能源接入电网后,由于新能源接入电网后,虽然会导致电网频率以及谐波特性等特征量发生改变,但波动的幅度仍在一定范围内.因此若直接将各时间段的小波能量熵作为特征参数,会导致不同新能源占比下的特征量差异不大,需要进一步的处理.
现提出一种改进小波能量熵理论:对于一段原始信号,首先计算长度为k的能量熵序列Entropy(k),计算整个时间段下的能量熵Entropymean.设加权系数为A,则处理后的能量熵序列为
Entropymean(k)=A(Entropy(k)-Entropymean)
,
(11)
其中,加权系数A的计算公式如下:
A=Bσ4/(Entropy-μ)4
,
(12)
公式中:B为比例系数,一般取103左右;μ为能量熵序列的均值;σ为能量熵序列的标准差.加权系数的取值,与能量熵序列峭度呈反比.由于峭度反映了数据的陡峭程度,而对于特征信息不明显的能量熵,峭度值较小,为了凸显内部差异性,利用峭度的倒数去凸显内部差异性.同时,使得各类能量熵的内部差异水平维持在同一基准线上,从而提高总体信息的有效性,以及作为训练样本的可靠性.
2 LSTM神经网络
LSTM神经网络是一种特殊的循环神经网络,它是一种具有记忆性的神经网络,适合处理带有时间刻度的序列.特别是针对跨度较长的时间序列问题,能够对较长的历史信息进行记忆.
2.1 LSTM神经网络的内部结构
LSTM神经网络的结构如图1所示.

图1 LSTM神经网络的内部结构
LSTM的关键是细胞状态,它类似于传输带,是位于结构图最顶部的直线.细胞的状态在这条线上移动,只需经过少量的线性操作.这样,细胞信息在经过一个单元后,自身信息不会被过多修改.LSTM的优越之处在于能够选择性的修改细胞的状态,而这个功能是通过门来实现的,门能够有选择性的让信息通过.门由一个Sigmoid神经网络层和一个点乘法运算组成.
LSTM单个单元的运行可分为以下四步:
(1)LSTM需要决定丢弃细胞状态中的部分信息,通过前一时刻的输出ht-1和当前时刻的输入xt,利用Sigmoid函数决定保留信息量的大小;
(2)决定在细胞状态中存储的信息量.首先,作为“输入门层”的Sigmoid层同样输出0-1间的值,决定要记住的信息量;其次,信息通过tanh层,创建候选向量Ct,输送给细胞的状态中;
(3)更新Ct的值.通过遗忘系数ft,得到需要遗忘的信息.加上候选向量,得到新的细胞状态Ct;
(4)使新的细胞状态经过tanh层,将值归一化到-1与1之间;将两个外部输入通过Sigmoid层决定输出的细胞信息量.将两个量的乘积作为最终的输出量.
2.2 LSTM神经网络的搭建
本文的目的是定量分析新能源占比,但搭建的并不是训练参数与具体占比数值间的严格模型,而是简化版的分类模型.实际思路是将新能源占比按照一定区段划分,下限是0%,上限是50%,等差地划分为n类.通过网络训练,得到采样数据对应的类别.
本次仿真基于MATLAB平台,借助神经网络编辑器,配置训练所用的LSTM神经网络,结构与参数配置如图2所示.
如图2(a)所示,第一层为输入层,输入的特征向量维度为6(三相电压电流数据);第二层为双向LSTM神经网络,即前向LSTM与后向LSTM的综合,更有效地处理双向的信息;第三层为全连接层,数据种类暂时设定为5(每10%设定为一类);第四层为Softmax函数,将原先输出映射到(0,1)上;第五层为分类器,实现本次训练的故障分类功能.
神经网络训练的配置如图2(b)所示.求解器采用Adam(Adaptive Momentum),它是一种自适应动量的随机优化方法;最大循环次数设定为1 000次;学习率设定为0.001;小批量规模(MinBatchSize)设定为50,即采用50大小的小批量规模,均匀划分数据集;设定每次循环时,都将打乱一次数据集.

图2 神经网络配置图
3 经验小波分解的效果分析
为了验证经验小波分解的有效性,通过函数表达式得到仿真信号,检验经验小波分解能否有效地分析信号的特征信息.
3.1 采样信号的模拟
由于新能源大规模接入,导致电能质量波动程度变大,因此选取常见的电能质量扰动的数学模型进行分析.而在电网稳定运行的情况下,谐波问题发生的频次最大.因此选取谐波扰动作为模型对象,表达式如公式(13)所示,代表叠加了3次~13次的奇次谐波.
(13)
同时,为了模拟实测电信号,加入高斯白噪声模拟白噪干扰,即在输出电流中叠加一定比例的正态分布噪声信号,波形如图3所示.

图3 模拟谐波干扰信号
3.2 经验小波分解效果分析
经验小波分解需要确定分解阶数N,来划分不同的频段.如果设定的阶数过大,会导致分解信息冗杂,无法捕捉关键特征信息;若设定阶数过小,会导致部分模态混杂,导致特征信息不明确.因此,考虑实际情况,设定分数阶数为8.分解结果与原波形信息如图4所示,第1行为噪声信号,第2行~第7行是奇次谐波信号,第8行为基波.可以看出,模态分解的效果很好,按照设定的频次将谐波信号完全分离了出来,证明了其有效性.
在得到分解后的EWF分量后,我们不难发现,对于谐波问题这种特征明显的信号,EWT的分解结果在分解结束选取合适的情况下,即为各个谐波分量.通过对各分量幅值相位的研究,可以较为便捷地获取特征信息.但是实际系统中,采样信号所蕴含的信息是复杂且耦合的,并不是单一的谐波问题,因此并不能全部转换为求取频域信息的问题.因此,我们需要对得到的EWF分量做进一步处理.
一般来说有两种处理思路,一种是分析整个时段上的EWF分量,转化为单一特征值,或者将整段数据作为智能算法的样本.这种思路会造成特征信息的不敏感,且加重了智能算法的负担.另一种就是本文采取的思路,借用加窗的思想,将整个时段分隔为等长的片段,分别进行后续的数据处理,得到一组特征更明显、保留数据量更丰富、且后续训练样本容量更精简的方法,即改进能量熵法.

图4 经验小波分解结果与原始信号的对比
4 仿真算例分析
4.1 仿真模型的搭建及实验配置
为研究低压馈线上分布式新能源所占比例与频谱特性,在Simulink中搭建含多种新能源并网的仿真模型,模型结构如图所示.其中,主网的电压等级为750 kV.在35 kV母线处,接入风电场与光电场.其中,风机为双馈异步风力发电机,单台风机的额定输出功率为1.5 MW;光伏电池的型号为SPR-415E-WHT-D,额定输出功率为10 MW.10 kV低压馈线上接入三相RLC负载,负载功率为200 MW.

图5 Simulink仿真模型
由于本文的目的是定量分析新能源占比,首先应该得到不同占比下低压馈线处的电信号.本次实验选择三相电压电流数据作为分析样本,共6组信号.
本文固定负载功率为200 MW,通过改变风机组的投入台数以及光伏阵列的组件数,实现低压馈线处新能源占比的变化.基于对实际情况的考虑,共进行500组仿真,新能源占比从0.1%按0.1%的增幅,增长到50%.
通过功率采集模块,得到光伏输出功率P_PV,风机输出功率P_wind,以及负载侧功率P_load,每次仿真计算新能源占比为
ratio=P_PV+P_wind/P_load
.
(14)
以占比为10%以及40%的一组数据为例,低压馈线处的单相电流的波形如图6所示(取一个周期内的A相电流信号分析):

图6 10%占比与40%占比下单相电流波形对比
不难发现,新能源占比不同时,低压馈线处的信号畸变程度差异不大,因此无法直观地定量分析.需要后续的特征提取手段挖掘其特征信息.
4.2 改进经验小波能量熵的效果分析
由于本次仿真为离散仿真,设定的步长为5e-6,故取一个工频周期内的4 000个数据点分析.将4 000个点分为40组,每组100个点,分别对其组成的时间序列进行小波变换并求取能量熵.通过这种方式,将一组电流数据变为40个点的能量熵序列.由于每组仿真得到6组电压电流数据,故组成6×40的特征矩阵,代表40个6维的列特征向量,作为神经网络的训练对象.具体的流程如7图所示.

图7 改进经验小波能量熵法的流程图
将500组训练数据划分为5类水平,新能源占比为0%~10%,10%~20%,20%~30%,30%~40%,40%~50%,分别记为R1、R2、R3、R4、R5.各类任取一组数据,分析其能量熵数据,如图8所示.

图8 不同新能源占比下的能量熵序列
从图中可以发现,改进能量熵的峰值集中在起始阶段以及中点阶段,其他阶段较为平稳,说明新能源波动幅度在这三个阶段比较明显.因此,若想提高算法的运算速度,减小储存负担,可以对波形进行分段处理,截取关键片段进行特征提取,可以有效提高后续的训练速度.
同时,观察同一阶段下不同水平的波形信息,可以发现在起止阶段,随着新能源占比提高,改进能量熵呈现上升的趋势,末尾阶段的变化幅度最为剧烈.在中间阶段,能量熵呈现出小范围的正弦性特征,变化方式也与起止阶段类似.因此,说明改进能量熵挖掘了各类水平下的信号特征信息.
4.3 LSTM神经网络分类的结果分析
本文的分类算法选用传统BPNN神经网络与LSTM神经网络,通过改变输入侧数据来比较各类方法的性能.采取三组对照实验:(1)传统能量熵+BPNN;(2)传统能量熵+LSTM神经网络;(3)改进能量熵+BPNN;(4)改进能量熵+LSTM神经网络.
将生成的500组数据分为300组训练样本与200组测试样本,每类数据各60组训练样本与40组测试样本.BPNN的隐含层配置为200,最大循环轮数为200,学习率设置为0.001;LSTM神经网络的隐含层配置为100,最大循环轮数设置为100,学习率设置为0.001,各组训练成果如表1所示.

表1 不同算法的训练效果对比
由表1所示,改进能量熵+LSTM的训练效果是最好的,它的循环次数为1 000次,训练时间为33 s,均为最低的;并且它的准确率达到了98.6%,为4种方法中最高的.同时不难发现,传统能量熵法的训练准确率远远不及改进能量熵法.在选定神经网络不变的情况下,采用改进能量熵后,准确率均有3%~7%的提升.除此之外,采用LSTM神经网络,对总训练时长也有显著影响.BPNN由于其本身特性,不适合处理长时间序列,因此在效率和准确率方面均不如LSTM神经网络.在给定训练数据的情况下,LSTM训练时长相较于BPNN分别缩短了12 s以及9 s,足以证明其性能的优越性.
通过上述分析可知,相比于BPNN神经网络和传统小波能量熵法,本文提出的改进小波能量熵和LSTM神经网络算法具有很大的优越性.该算法对隐含层配置层数要求低,循环次数少,训练时间短,但准确率依旧保持很高水准,足以证明改进能量熵法的有效性.
利用该方法对测试样本进行分析,测试效果如图9所示,横坐标代表测试组别,纵坐标代表占比类别;各类占比的测试准确率如表2所示.从表中能够发现,总体准确率为97.5%,说明该方法的有效性和可靠性.但是各类预测准确率的差异性较大,其中,测试样本数较小有一部分的因素.图9横坐标代表测试的组别,每40组是一类;纵坐标有3种取值:0代表预测准确,1代表预测占比偏大,-1代表预测占比偏小.从图9中可以看出,判断错误的点全部集中在各类组别的分层处.由于本次分类是按照新能源占比作为依据,因此R1和R2交接处的特征信息是连续的,产生误判在可接受范围内.如果将占比范围细分,例如以5%为间隔,划分为10类.可以预想到的是,模型训练准确率会有小幅度下降,但同时会提升定量分析的实际意义.

表2 各占比类别的测试准确率对比

图9 不同新能源占比下的测试结果
4.4 讨 论
从上述仿真及训练的结果可以看出,本文所提的方法相比较于传统的算法,准确率有一定提升,训练时间也较短,说明具有一定的可靠性.但是,受限于仿真数据的容量与机器的性能,本文对占比分段的跨度较大,达到了10%.因此,导致在同一类数据组中,预测的正确率分布不均,在占比临界处存在一定的误判.如果条件允许,在获取更多的数据后,再利用改进能量熵的特征差异性集中在部分数据段的特点,缩小训练样本中特征向量的长度,减少冗余信息,应该能够进一步提高预测准确率,降低训练时间.
5 结 论
针对高比例可再生能源接入背景下,定量分析低压馈线处可再生能源功率占比问题,本文提出一种基于改进经验小波能量熵和LSTM神经网络的定量分析方法,通过搭建仿真模型模拟现场数据,进行大量训练测试,主要得到以下结论:
(1)基于改进经验小波能量熵的特征提取方法,能够有效解决由于新能源大量接入,导致电能质量出现复杂扰动而导致的频谱分析困难的问题,特别是改进能量熵算法,改善了传统能量熵法不适用于低峭度数据处理问题.
(2)通过传统机器学习算法对可再生能源占比进行定量分析,存在训练时间长,准确率低等问题.因此本文利用结论1的数据,搭建LSTM神经网络,并且在MATLAB/Simulink中进行仿真;仿真表明LSTM神经网络能够成功识别不同占比下的电压电流数据,复杂度和训练时长低,平均准确率有所提高.
(3)下一步的研究重点是提高定量分析的精确度,并且有效解决可再生能源占比分界处识别成功率较低的问题.
