信江智慧航道数据结构优化及大数据管理方法研究
2023-01-04赵文戬江西省赣北航道事务中心
赵文戬 江西省赣北航道事务中心
刘伟 华东交通大学
智慧航道即利用通信、自动控制、人工智能和数据库技术,将现地感知、集中控制和航道管理有机结合,形成“安全、高效、便捷、智慧”的管理新模式。但当前极大丰富的航道数据未能有效整合,传统的数据存储方式无法保存,更不能对海量数据进行分析,数据资源流失;航道数据来源众多,存储方式多样,数据类型复杂,在组织、融合、清洗和转换这些数据时的难度较大;同一部门所掌握的数据共享,不同部门之间数据很少共享,缺乏综合性的数据信息分析平台[1-2]。
综上,构建一个基于大数据平台的航道数据仓库可以更好的实现对海量数据的实时收集和整理,利用先进的信息技术将这些数据转换成有用的信息,对于帮助系统各部门做出更好的决策与指导方案,提高内河航道数据资源利用效率,促进内河航道大数据的社会化应用[4]以及提高信江航行安全具有重要意义。且智能航道作为国家智能交通建设的一部分,本文也可以为智能航道的研究和发展提供借鉴[5]。信江智慧航道数据结构优化及管理方法技术路线图如图1所示。
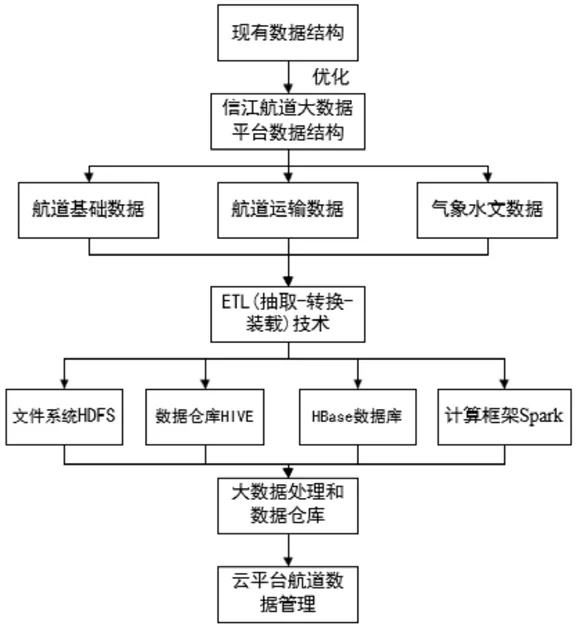
图1 航道数据结构优化及管理方法技术路线图
1.基于大数据技术的信江航道数据结构优化研究
1.1 信江航道现有数据结构分析
信江航道信息化经多年发展,已在基础建设、应急指挥、航运监测方面取得了许多成绩,建立了能满足港航生产、市场管理、运行保障、公共服务等各个领域需求的规模不等的各类信息系统,不同程度的提高了信江航道的运行效率和服务水平。
信江航道大数据平台通过信江航道数据的融合,提供创新性的信息服务,充分挖掘信江航道大数据的价值。信江航道大数据平台不同于以往的数据中心,并不仅仅是将已有的信江航道数据“集中存放”,而是通过从“小数据”到“大数据”的积累,实现信息的高级增值。通过对信江航道大数据服务对象和信息服务的需求分析,对信江航道大数据平台数据结构进行优化。
1.2 信江智慧航道大数据信息服务需求
信江航道大数据平台的需求者希望以大数据为基础,依托大数据技术体系,获得基于大数据的创新性数据服务。
信江智慧航道所呈现出的优点相较于传统航道模式在各个方面都是跨越式的。维护方式:实时监控维护,运行机制:自上而下统一调度指挥,管理模式:数据管理一张图,服务信息:信息化一站式服务信息。
1.3 信江航道大数据平台数据结构
目前的数据和资源中心难以满足信江航道大数据存储、管理、应用的要求,为了实现信江航道大数据信息的增值,提供更好的信息服务,基于信江航道大数据信息服务需求,优化信江航道大数据结构,信江航道大数据平台分为航道基础数据、航道运输数据和气象水文数据三大类主题数据库。
(1)航道基础数据。包括航道名称、编号、航道里程、航道等级,水道位置、航道概况、管理机构、联系人、联系方式。
航道图形数据。包括航道名称、编号、航道里程,信江航道图、图形编号、更新时间。
(2)航道运输数据。包括航道名称、编号、航道里程,航道等级、航道维护水深、航道宽度,浅滩险滩、碍航物类型、碍航物位置、禁航区域。
助航设施数据。包括助航设施名称、编号、类型、位置,维护单位、联系人、联系方式。
(3)气象水文数据。气象数据。包括风、浪、能见度、雷电、降雨等。水文数据。包括水位高低、水流量、含沙量、汛期与结冰期和水量补给方式等。
2.信江航道数据ETL(抽取-转换-装载)技术
2.1 ETL技术
ETL包括数据提取、转换和加载,是用在实现质量较高、数据精简的数据仓库所需要的关键环节。总体流程是对不同业务系统中的现有分布式数据首先进行提取,经过转换之后,再进行清理和加载的过程,使这些数据符合智能系统方方面面的需要。
2.2 航道数据抽取
数据提取指从各式各样的网络类别或者不同的操作系统中提取所需的数据,有时也会在各类的数据库以及纷杂的数据格式或者各式各样的应用程序中提取所需要的数据。这里涉及到的数据不仅仅只有和数据库系统相关的数据,还有其他一些数据,比如网站中的数据和文本文件中的数据。
2.3 数据转换与清洗
数据转换即对数据库数据的变换(数据库数据进行合并、聚合、过滤、转换等方面),对数据库数据进行再次格式化和计算,数据库中重要数据的重构和数据统计以及数据位置标定。
数据清洗的作用是检查出不符合规则的数据库数据,交相应业务单位进行整改,然后再进行提取。数据预处理中应当需要处理的数据库数据有三类:不完整的数据库数据、错误的数据库数据和重复的数据库数据。关系到数据仓库的创建以及其他方面等进一步的工作,所以数据库数据一定要具备良好的准确性、可靠性和安全性。
2.4 数据装载与元数据管理
2.4.1 数据装载
数据库数据加载的主要任务是根据上一步数据处理过程依据物理数据模型方面知识和规则,将上一步处理结果加载到需要创建的数据仓库的各个数据表中,其中的一些流程需要人为的干预,主要目的是正确有效的同步数据到数据仓库中。
2.4.2 元数据管理
元数据是用于管理和描述数据库数据的数据。总体来看,在数据库中,元数据是对数据库数据本身及其服务器环境的具体描述和数据库数据定义的一般形式数据。元数据对于ETL不可或缺的意义集中如下:
(1)对数据仓库中数据源的位置和属性定义;
(2)源数据和对应目标数据之间的规则确定;
(3)相关业务逻辑的确定;
(4)在计算和加载数据库数据之前应当需要的其他准备工作。
通过建立元数据模型和建立数据管理系统完成对元数据的管理。
3.支撑云平台的数据仓库管理技术
3.1 基于大数据处理技术和仓库技术概述
本课题研究基于典型大数据处理生态系统构建了航道大数据分析管理平台。
3.1.1 数据仓库HIVE
Hive是一个根据Hadoop关系型数据库的基础框架,一种能够在HDFS中存储文件、查询和专门分析这种大规模数据库数据的控制机制。它可用于提取、转换和加载大量数据。Hive通常采取使用简单的类似SQL的查询计算机语言(HQL)的形式。借助对语法结构的解析和转换,最终生成一连串MapReducelast任务进行数据处理,全方位为用户予以了与传统RDBMS无异的部分。
3.1.2 HBase列式存储数据库
HBase是根据HDFS构建的面向列的存取数据库系统,全方位予以高稳定性、高性能、列存储文件、可扩展性、数据实时自动读写等性能。与HDFS一样,依托分布式部署,Hbase能够借助廉价商用服务器的不断改进,在原有基础上进一步提升计算和存储文件的潜力。
3.1.3 基于内存的计算框架Spark
Spark 是UC Berkeley大学AMP 实验室开源的类似MapReduce的计算框架,它是一个基于内存的集群计算系统,Spark形成了自己的生态系统(以Spark为基础,上层包括Spark SQL,MLib,Spark Streaming和GraphX)并成为Apache的顶级项目。
3.2 航道数据管理平台方案
3.2.1 航道数据管理平台功能需求分析
结合航道数据管理的需求,本课题将功能需求可分为三层,分别为大数据云平台基础层,大数据软件计算层、大数据应用层。
3.2.2 基于虚拟化技术的云平台构建
大数据的管理和应用过程,是一个体系化的综合过程。大数据技术的核心技术,是分布式存储和分布式计算技术。大数据管理和应用体系的总体情况如图2所示。
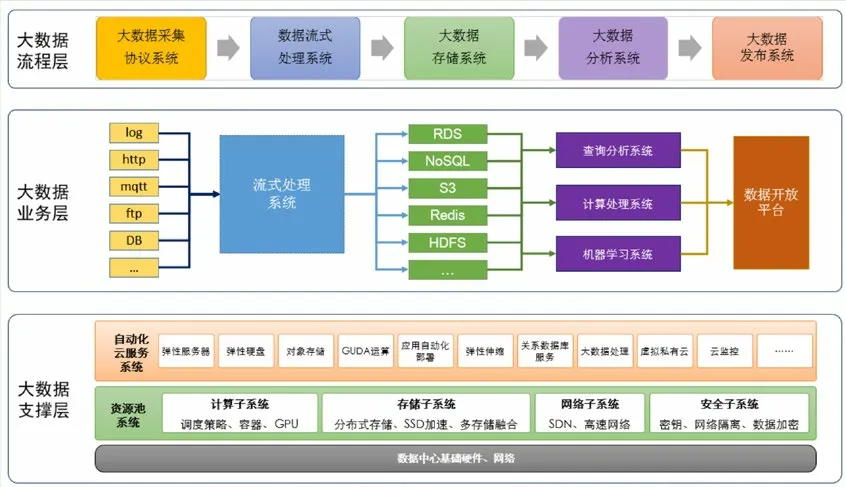
图2 基于虚拟化技术的云平台架构
3.2.3 基于云平台构建大数据处理平台
大基于云平台的虚拟大数据计算集群(以下简称集群),是用于大规模交通数据分析的基础计算平台。考虑到目前大数据环境中Spark擅长数据挖掘和分析,而Storm的流处理能力更强,以及项目的研究性和对象的不确定性,所以同时部署Spark和Storm两种实时数据分析方案,共享相同的数据源。系统具体架构如图3所示。
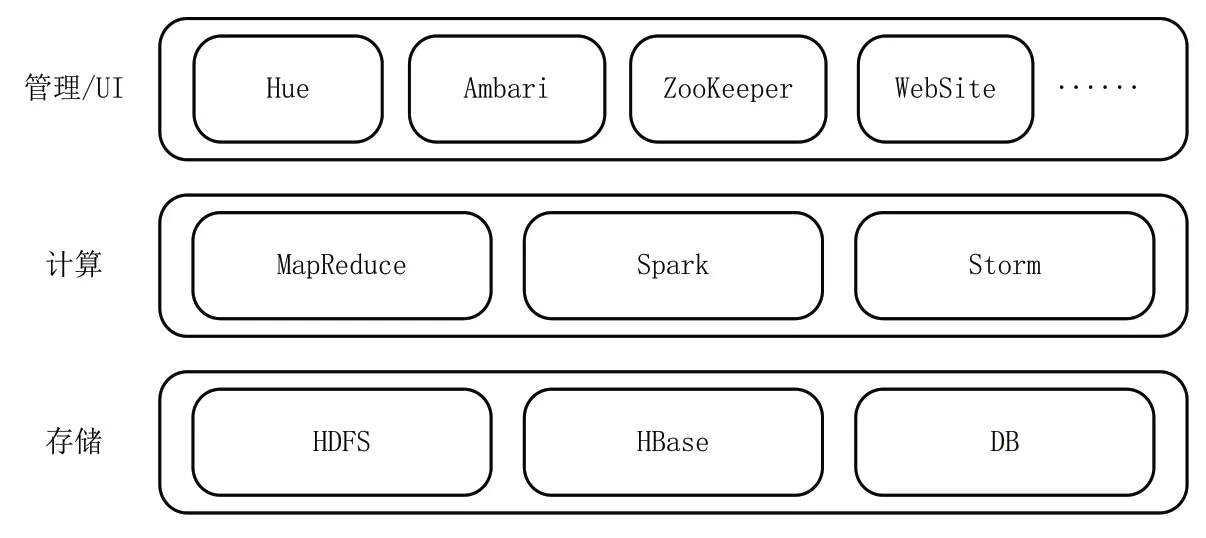
图3 基于云平台构建大数据处理平台框架
4.结论
针对航道数据,设计三类特色数据仓库的主题域。以数据服务对象为核心的航道数据结构优化设计,以服务对象为中心,以信息服务内容为牵引,整合多种来源数据,形成了适合大数据分析的数据管理结构。
研究云计算环境下航道数据仓库的存在形式、组织管理和运行方法。在云平台基础上规划了航道大数据的平台的计算机集群规模。在此基础上利用Ambari构建了基于Hadoop的HDFS文件系统的大数据处理平台,部署了Hive数据仓库、HBase数据库。
信江智慧航道建设将产生大量异构且传统处理方法难以处理与分析的数据,基于本文数据结构优化和大数据管理方法研究,信江智慧航道将在数据处理和管理方面更加智慧化和数字化,并为航道智能化建设提供了解决方案和参考方法。
