基于卷积神经网络的领域适配模型的多工况迁移的轴承故障诊断
2023-01-03钱思宇秦东晨陈江义
钱思宇, 秦东晨, 陈江义, 袁 峰
(郑州大学 机械与动力工程学院,郑州 450001)
滚动轴承是旋转机械中常用的零部件之一。绝大多数机电驱动系统和电机故障是由滚动轴承损坏引起的,这可能导致设备停机造成经济损失或者造成严重的安全事故。因此滚动轴承故障检测变得尤为重要。
轴承振动信号复杂,且轴承在不同运转工况下,相同故障会采集到不同的振动信号。近几年,深度学习方法大量应用于轴承故障诊断领域,然而单一样本(源域)训练出来的模型,只能对源域的数据做出良好判定,很难在其他数据领域也做出良好的故障判定,模型无法在其他工作环境运行。Lu等[1]提出了基于神经网络的领域自适应故障诊断。Pan等[2]提出通过最小化MMD(maximum mean discrepancy)来找出领域共享特征技术。Long等[3]设计一个子空间学习框架,整合MMD到深度神经网络。Wang等[4]使用多种变负载工况信号作为卷积模型输入,训练过程中利用领域鉴别器进行权重调整,实现了变负载环境下的轴承故障诊断。Wen等[5]使用稀疏自动编码器结合MMD,提出DTL(deep transfer learning)模型应用于故障诊断。领域迁移在很多领域可用找到应用,但在故障诊断的工况迁移自适应研究很少。
针对上面的问题,提出一种适应于工况迁移的卷积迁移模型。其特点:①实现从端到端的轴承故障诊断模式,完全不需要对数据进行相关信号处理;②模型相较于其他的模型结构简单,参数规模小,易于训练;③模型在不同工况迁移环境下表现出极好的诊断性能。
1 领域自适应
领域自适应方法[6]的实施流程是提供源域有标签样本和少量目标域无标签样本进行训练,生成源域分类损失和域自适应损失进行模型学习。领域自适应中的数据领域分为两类:源域Ds(xs,ys),服从数据分布p;目标域Dt(xt),服从数据分布q。其中:x为域样本;y为域样本标签;s下标表示源域,t下标表示目标域。其原理:使用领域自适应中评估源域和目标域的数据分布偏移程度的相关方法,计算两个领域的特征数据分布的“偏移量”,作为模型损失函数的一部分,反向调整网络权重,进而不断减小偏移量,目标域的特征数据分布不断逼近源域,最终模型能够正确识别目标域样本的类别。本文的领域自适应分为两步:①全领域自适应;②类别领域自适应。
1.1 全领域自适应
源域样本与目标域样本间存在数据分布偏移,通过全领域自适应,将源域和目标域的数据分布进行整体对齐(将两个域的数据映射到相同的特征空间),使模型一定程度将源域学习到的知识迁移至目标域,提高模型泛化能力。全领域迁移如图1所示。
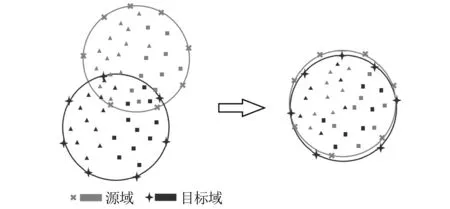
图1 全领域迁移的示意图Fig.1 Schematic diagram of whole domain migration
经过全领域自适应后的模型并不能完全解决目标域样本如何实现正确分类这一问题,因为源域和目标域中相同类别的样本会不同程度分布在不同的子类别领域中,模型仍旧会对部分目标域样本做出虚假判定。本文的解决方法:在全域自适应后再引入类别域自适应,进一步对全域中的子类别领域进行领域自适应。
1.2 类别领域自适应
类别领域自适应将全域自适应得到的领域进行域细化,即进行各类别子域对齐,在对齐过程中,源域样本有真实标签,而目标域样本为目标工况的轴承振动数据,并没有真实标签,故利用模型的源域样本分类器(属于有监督学习)对目标域样本进行标签预测,再进行类别领域自适应(属于半监督学习)。类别领域迁移示意图,如图2所示。

图2 类别领域迁移示意图Fig.2 Schematic diagram of classes domain migration
1.3 领域分布距离
目前迁移学习,尤其是域适应中,主要使用MMD来度量两个不同但相关的分布(p,q)的距离。两个分布的距离dH(p,q)定义为式(1)
(1)
式中:H为这个距离是由映射函数φ(·)将数据映射到再生核希尔伯特空间(reproducing kernel Hilbert space, RKHS)中进行度量的;xs为源域数据;xt为目标域数据;E为取平均值。
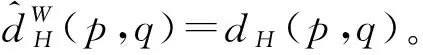
(2)
式中:ns为源域样本数量;nt为目标域样本数量,后续公式中含义一致。
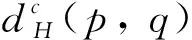
(3)

(4)
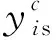

(5)
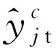
(6)

(7)
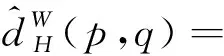
(8)
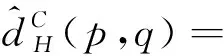
(9)
2 网络模型细节
2.1 主要网络结构
模型使用卷积网络提取振动信号中的故障特征,由于振动数据为一维时序数据,而深度学习中的一维卷积层多用于时序数据、文本数据的特征提取,很适用于本文中的振动时间序列数据。本文使用RELU函数作为卷积层后的激活函数,因其具有:求导简单,激活后的数据具有稀疏性,可一定程度减少网络过拟合等优点。
本文的模型涉及领域迁移,根据自适应批标准化[8]的表述:模型训练时,使用每个批次样本的均值和方差进行标准化,而在模型验证测试阶段,使用验证样本集、测试样本集的均值和方差,这有利于模型进行迁移任务,故本文的模型在每个卷积层后,添加自适应批标准化层。
深度学习中的注意力机制[9]核心目标是从众多信息中选择出对当前任务目标更关键的信息。目前常使用的机制类型有3种:通道注意力、空间注意力、细粒度多特征融合。本文将通道注意力引入故障诊断任务中,提高模型的鲁棒性。算法流程,如图3所示。

图3 通道注意力机制Fig.3 Channel attention mechanism
2.2 模型损失函数
2.2.1 交叉熵损失函数
交叉熵损失函数又名分类损失函数,是分类问题中常用的一种损失函数,用于评估预测类别标签与真实类别标签之间的差异程度。其具体表达式
(10)

2.2.2 领域适配损失函数
在工况迁移领域,域适配损失函数也就是在1.3中式(8)和式(9)提到的领域分布距离

(11)
(12)
2.2.3 模型总损失函数
根据式(10)、式(11)和式(12),可以得到模型的总损失函数
losstotal=lossJ+α1·lossWDA+α2·lossCDA
(13)
式中,参数α1,α2用来权衡全域适配损失和类别域适配损失在模型总损失中所占的权重。
2.3 模型细节配置
2.3.1 模型结构
工况迁移模型CNN-DA由特征提取层、分类层、领域自适应模块等构成,具体算法流程如图4所示。
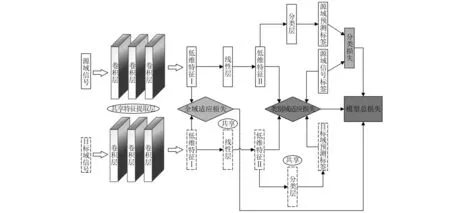
图4 工况迁移模型流程图Fig.4 Flow chart of working condition migration model
源域信号经过模型特征提取层得到低维特征Ⅰ,再经过线性层降维,得到低维特征Ⅱ,将低维特征Ⅱ输入分类层获取预测标签,并与真实标签比对计算出分类损失;同时,目标域信号共享源域的特征提取层,也得到低维特征Ⅰ,将源域与目标域的低维特征Ⅰ输入进全域自适应模块,计算出全域适应损失;目标域的低维特征Ⅰ再经过共享线性层得到低维特征Ⅱ,再通过共享的分类层获取预测标签,类别域自适应模块利用源域低维特征Ⅱ、源域真实标签、目标域低维特征Ⅱ和目标域预测标签,计算得出类别域适应损失。模型的三类损失(分类损失、全域适应损失、类别域适应损失)在每个训练步数同步计算,加权求和为模型总损失,并进行反向梯度优化模型网络层权重。
2.3.2 模型细节
在模型数据输入端,加入随机采样层,能够让网络提取的故障特征更具鲁棒性。网络模型中,除了提取振动信号中高层特征的一维卷积神经网络层外,还添加通道注意力模块,分别加入到卷积模块的首尾两层,用于为特征通道分配不同的权重,以增大有效特征在总特征域的占比,减少无效特征的干扰。模型中的卷积第一层使用宽卷积核提取原始信号的特征,目的在于增大卷积核感受野,相当于信号领域中:较少丢失信号频域分辨率的前提下提高信号的时域分辨率。
3 试验测试
本章中,基于Python-Pytorch搭建深度学习模型,在不同类型的数据集振动信号上进行5次训练和测试,对最终测试结果取平均值,并与其他模型进行性能对比,验证本文提出的卷积神经网络的领域适配模型(convolutional neural network-domain adaptation, CNN-DA)模型的工况迁移能力。
3.1 数据集来源
3.1.1 CW-Artificial数据集
本数据集来自凯斯西储大学[10](Case Western Reserve University,CWRU)滚动轴承人工损伤数据集。CWRU轴承数据采集系统,如图5所示。本测试选取驱动端轴承作为试验对象,型号为SKF6205,属于深沟球轴承,振动信号的采样频率为48 kHz,故障缺陷由电火花单点加工,加工位置为轴承内圈、轴承外圈、滚动体;根据不同的加工直径,分为0.18 mm,0.36 mm,0.53 mm可以造成9种不同的故障缺陷,再结合轴承健康运转状况,构成10种故障类别。

图5 CWRU轴承系统平台Fig.5 CWRU bearing system platform
轴承运转工况分为735 W,1 470 W,2 205 W(负载),工况迁移实验使用735 W,1 470 W,2 205W工况两两组合成6个迁移进行模型训练。由于轴承的运转工况只有负载的变化,不涉及轴承转速、轴承径向载荷等工况变量,故CW-Artificial数据集属于简单工况迁移数据集。本文不对数据进行任何预处理,实现端输入,数据长度为1 600(轴承旋转一周的采样点数),数据采取半周期重叠采样,以扩充数据量。数据集中分为训练集(用于训练模型)、验证集(用于调整模型参数)、测试集(用于验证模型性能)。具体数据集构成如表1所示。
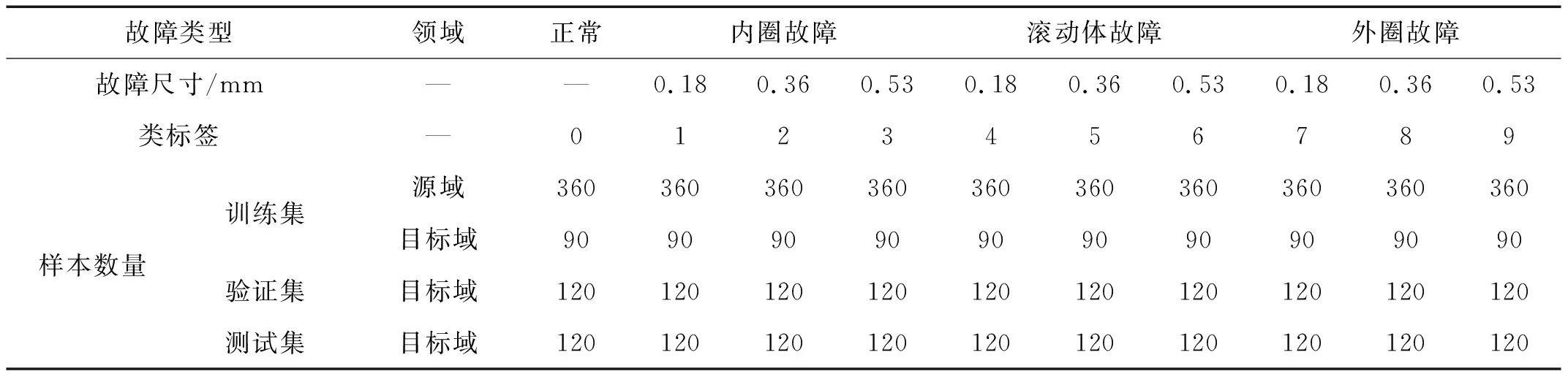
表1 CW-Artificial数据集
工况迁移数据集:源域(A)→目标域(B),代表模型从工况A迁移至工况B。具体工况迁移配置如表2所示。

表2 CW-Artificial工况迁移
3.1.2 PB-Artificial数据集
本数据集来自帕德博恩大学[11](Paderborn University, PB)滚动轴承人工损伤数据集。PB轴承数据采集系统,如图6所示,试验台由电机、扭矩测量轴、滚动轴承测试模块、飞轮和负载电机组成。本测试选取轴承IBU6203作为试验轴承,振动信号的采样频率64 kHz,故障缺陷由电动雕刻机单点加工,加工位置为轴承内圈、轴承外圈;根据不同的加工长度(1~4 mm),分为损伤等级1、损伤等级2,造成4种不同的故障缺陷,再结合轴承健康运转状况,构成5种故障类别。
轴承运转工况分为N15M07F10,N09M07F10,N15M01F10,N15M07F04,使用4种工况两两组合成12个工况迁移类别进行模型训练。由于轴承的运转工况有负载变化、转速变化、径向载荷变化,工况变量较多,故PB-Artificial数据集属于复杂工况迁移数据集。数据采样长度规则与CW-Artificial数据集一致(即轴承运转一周的采样点数),故采样数据长度为2 560,其他设置也完全一致。数据集具体构成,如表3所示。工况迁移领域说明,如表4所示,A为源域,B为目标域。

1.电机; 2.扭矩测量轴; 3.滚动轴承测试模块; 4.飞轮; 5.负载电机。图6 PB滚动轴承状态监测试验台Fig.6 PB rolling bearing condition monitoring test bench
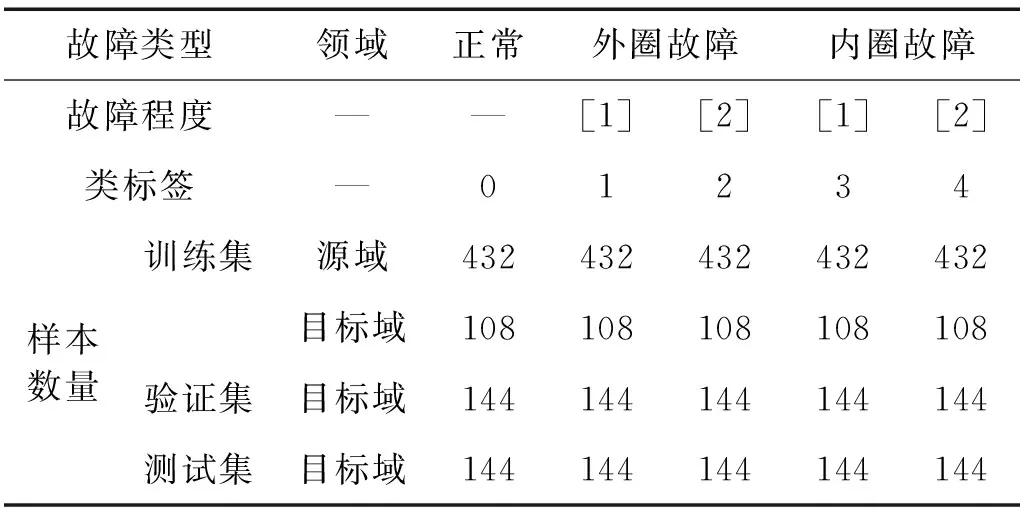
表3 PB-Artificial数据集

表4 PB-Artificial工况迁移
3.1.3 PB-Reality数据集
本数据集来自帕德博恩大学[11]滚动轴承加速寿命试验损伤数据集。加速寿命试验台,如图7所示。由一个轴承箱和一个电机组成,电机为主轴提供动力。轴承箱中有4个IBU/MTK/FAG6203型试验轴承,测试轴承在弹簧螺旋机构施加的径向载荷下旋转,所施加的径向力高于轴承在正常工作下的径向力,但不会超过轴承的静态负载能力,以加速轴承疲劳损伤的出现。此外,使用低黏度的润滑油,创造不良好的润滑条件,加速损伤形成。寿命测试造成的轴承损伤大多是疲劳损坏,这种损坏以剥落的形式出现。损伤组合有3种:单一损伤、重复损伤、多重损伤。将损伤后的轴承作为PB滚动轴承状态监测试验台的试验轴承,获取不同工况下的故障振动信号。

图7 加速寿命装置Fig.7 Accelerated life device
工况迁移集的故障类型、采样长度、最终数据集构成以及工况迁移种类均与3.1.2节中PB-Artificial数据集完全一致。PB-Reality数据集也属于复杂工况迁移数据集。
3.2 试验参数设置
模型的相关参数设置和训练参数配置对训练结果影响很大,在模型结构固定的情况下,参数设置决定模型的表达能力。
模型的随机采样层随机丢弃率必须设置合适,过高会导致原始数据变化过大,模型无法训练;过低会丧失设置随机采样层的初衷。根据测试调试,设置为0.25。模型采取5层卷积层用来对数据进行特征提取;卷积第一层的卷积核不应设置过小,根据信号领域的知识,采样窗口视野决定模型的时频分辨率,根据试验,最终设置卷积核大小为64;模型特征提取卷积后续4层卷积核大小设置为7,5,3,3,保证特征细粒程度。每个卷积层后的批标准化层使用自适应设置。特征提取后的Dropout层使用0.2作为随机丢弃率,减小模型发生的过拟合现象。模型具体结构,如表5所示。

表5 工况迁移模型CNN具体参数
模型优化器使用Adam优化器,加速模型寻优过程,减少迭代次数,以节省运算资源。在网络迭代过程中,为避免学习率过大导致迭代路径振荡过大,使用学习率指数衰减策略,以确保模型在迭代循环中能够越来越逼近最优解。学习率指数衰减策略
(14)
式中:LR为初始学习率;epoch为当前训练步;epochs为模型总训练步数;λ为衰减速率参数,取λ=0.75。
训练参数包括批次样本大小(batch size)、初始学习率、网络初始化方法、训练迭代步数和域差异性损失权重α1与α2。根据经验,使用较小的批次样本大小训练模型能够提高模型的泛化能力;另一方面,批次样本设置过小会增加模型的训练时间,综合考虑,选取128为batch size最终参数。初始学习率不易设置过高,一般在0.010~0.001,本文选取LR为0.005。根据本文网络模型中的使用的RELU激活函数,使用Kaiming初始化方法[12]对卷积层参数进行初始化。经过多次试验,训练迭代步数(epoch)取200次,确保网络能够完全收敛,也不花费过多训练时间。根据多次测试验证,域差异性损失权重α1与α2均取值0.2。
3.3 试验结果及与其他方法的比较
为确保试验结果的可靠性,进行5次模型训练后的测试集分类正确率取平均值。除本文自行搭建的模型结构CNN-DA之外,还采用机器学习模型和其他深度学习模型:支持向量机(support vector machine, SVM)、迁移成分分析(transfer component analysis,TCA)、注意力机制-Inception-卷积神经网络[13](inception convolutional neural networks,INCNN)、采用领域鉴别和全域适应的卷积神经网络[14](deep convolutional transfer learning network,DCTLN)、使用领域对抗的卷积网络[15](domain-adversarial Neural Networks,DANN)作为对比,都使用相同的时序数据结构输入。INCNN和DCTLN是当前较为优秀的滚动轴承故障模式诊断深度学习模型。各模型说明,如表6所示。

表6 各模型说明
模型在各个数据集上的各种工况迁移的具体测试结果如图8所示,平均迁移诊断性能如表7所示,所有数据均为5次训练测试取平均值。
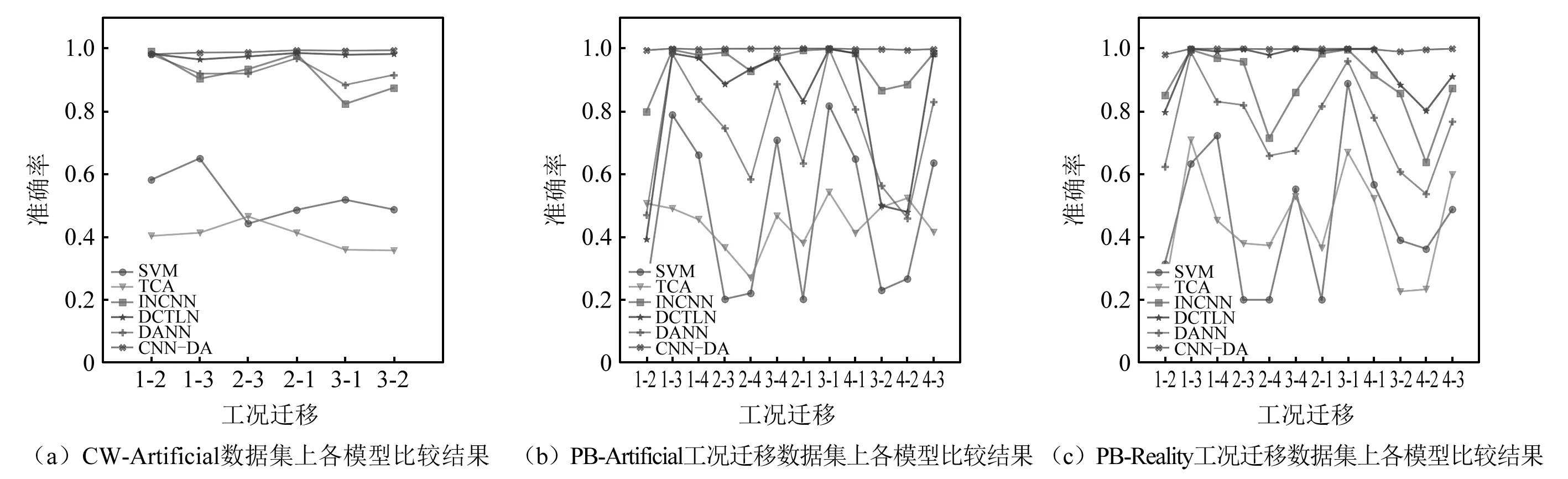
图8 各模型在3种数据集上测试结果Fig.8 The results of each model were tested on three data sets
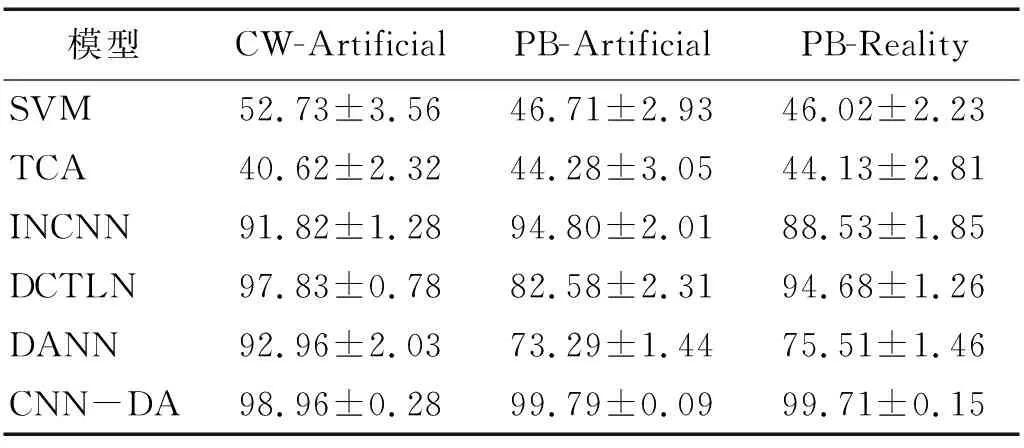
表7 各模型在各数据集上的平均诊断正确率
试验结果如图8和表7所示:图8(a)中共有6种不同工况迁移轴承故障诊断结果;图8(b)和图8(c)中共12种不同工况迁移轴承故障诊断结果;表7中表示各类模型在不同数据集上的平均迁移诊断结果。从图表中可以看出:提出的CNN-DA模型在不同数据集各种工况迁移变化下,均保持最可靠、最稳定的故障识别性能,平均准确度都在98.5%以上,不同程度优于其他对比模型。作为对比的深度迁移模型DCTLN和DANN在3个数据集下表现不一:DCTLN模型在CW-Artificial和PB-Reality数据集上达到97.83%和94.68%的平均准确率,但在PB-Artificial数据集上表现欠佳;而DANN模型仅在CW-Artificial数据集上表现良好,达到92.96%的平均准确率,在另外两个数据集上迁移效果极差,平均准确率均在75%左右。传统的迁移学习算法TCA和简单机器学习算法SVM在所有任务中的表现均低于深度学习算法,其平均准确度只有50%左右。以上分析证明:本文提出的基于全领域和类别领域相结合的领域自适应算法能够有效利用无标签的目标域数据,提高跨工况领域的轴承故障诊断准确度,在不同环境下具有良好的诊断性能。
为更好理解提出的模型,使用TSEN(t-distributed stochastic neighbor embedding)[16]可视化方法对提出的CNN-DA模型和未使用领域自适应算法的CNN(convolutional neural networks)模型对PB-Reality数据集的1-2工况(该工况迁移下对比模型的迁移识别效果均不好,可视化结果对验证本文模型的领域自适应效果更具说明性)迁移的训练过程进行各网络层二维可视化,如图9、图10所示。图中所示:图9(a)~图9(j)、图10(a)~图10(j)子图为模型各层可视化结果,图9(k)、图10(k)为领域标记。图9 CNN-DA模型的各网络层中,原始信号在特征空间中混杂在一起,随着模型特征提取层的作用,模型逐渐对故障类型进行细分聚类,且源域和目标域的相同故障类别样本逐渐聚类一起;图9(j)中,1,2,4故障类别聚集在一起,0,3故障类别聚类失败,说明网络提取到了不同领域之间的不变特征,但在少数故障类别下源域和目标域的样本无法聚集交叉在一起,欠缺一定的鲁棒性。作为对比,图10未使用领域自适应的CNN模型的图10(j)中,源域和目标域的所有故障类别全都混杂在一起,无法进行很好的区分,产生严重的错误对齐现象。通过上述的可视化过程,可以证明:本文提出的全域、类别域相结合的领域自适应算法能够有效提取源域和目标域之间的领域不变特征,缓解目标域错误分类对齐的现象。

图9 使用领域自适应的CNN-DA模型可视化Fig. 9 Visualization of CNN-DA model using domain adaptation
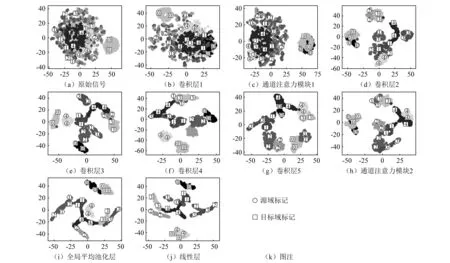
图10 未使用领域自适应的CNN模型可视化Fig.10 Visualization of CNN model without domain adaptation
4 结 论
本文提出的一种新的复杂工况迁移下的CNN-DA模型,它们是基于普通卷积神经网络、注意力机制、全域与类别领域自适应搭建而成的高性能模型。主要结论:
(1)模型实现从端到端的诊断模式,不需要对原始诊断数据进行任何处理,避免了繁琐的传统诊断人工提取故障特征;诊断信号通过模型诊断直接输出故障结果。
(2)模型的结构简单,参数规模小,以最少的参数训练和先进的迁移算法保证可靠的故障诊断性能。
(3)CNN-DA在两类(人工损伤/真实损伤)3种数据集上训练后进行测试,在各种类型工况迁移下,均取得优异的迁移诊断结果,平均诊断率均在98.5%以上,不同程度领先其他深度网络模型。
