基于内容可识别的全景图边界规范化操作*
2023-01-03常州纺织服装职业技术学院张茹
常州纺织服装职业技术学院 张茹
在图片、短视频充斥互联网的时代,人们对于高质量图片有着很大需求。由多张图片拼合而成的全景图片往往具有不规则的边界,而人们往往会通过截取或者图片补全获得矩形边界,但如此操作可能会失去很多必要的内容,失去一种宽阔的视场效果,或者会有一些可能无法合成语义的内容[1]。在这个研究背景下,提出了一种内容可识别的图像编辑方法。
1 研究背景
基于如何在缩放图片(长宽比一般与原图有较大差异)的同时减少内容的丢失,这个问题也被叫做Image Retargeting,最早的Seam Carving提出了内容可识别(Content-aware)的方法。由于人们对于图片的不同内容有着不一样的敏感度,所以通过一些不容易被发现的操作就能产生人们视觉上所能接受的图片。这个方法已经被商业软件Adobe Photoshop所引入(内容识别填充)。而Retargeting的研究主要是基于变形/扭曲算法(Warping Algorithm),这些研究的贡献主要集中在如何保存图片内容的一些特征,如形状和直线,用最小的扭曲来保证图片的完整性[2]。在本文中,拟将对更多的图片操作问题进行关于内容可识别方向的研究,涉及全景图像边界规范化(Rectangling Panoramic Images)的操作。
随着图像对齐和拼接技术的推进,创建全景化图像早已经变成一个日益流行的应用程序。由于对齐拼接图像所需要的形变映射(例如,圆柱形映射、球形映射或透视映射)以及相机的随意移动,全景图像缝合呈现不规则边界几乎是不可避免的,很多网民都会青睐发布,共享和打印有矩形边界的照片[3]。例如,在Flickr(flickr.com)上标签为“全景”的照片有99%以上是具有矩形边界的。
如何将不规则的矩形边界的全景图像边界进行规范化的操作?一个简单的解决方案是用矩形裁剪全景图像。但裁剪可能失去很多必要的内容,并失去一种宽阔的视场效果。另一个解决方案是在边框部分中,使用图像补全技术合成缺少的区域。虽然这些技术适合扩展的纹理或简单的结构(如直线),但大部分情况下会有一些可能无法合成语义的内容。有研究,是将裁剪和图像补全结合起来以解决这个问题[4]。
在这项工作中,拟建议采用基于图像识别来规范全景图像的边界。变形是一个有吸引力的策略,众所周知,全景/广角图像难免出现失真的情况。广泛的网民已经习惯了这种失真,例如,在Flickr、photosynth.net、360cities.net等图像分享网站上,有数以百万计的这样的全景照片。摄影师和一些艺术家们似乎很喜欢以轻微的扭曲失真为代价来获得令人印象深刻的宽阔视角的照片。根据观察,不难发现,由一个设计适当的边界规范化算法额外引入的失真不仅是可以被接受,而且是视觉上无法察觉的。
设计这样的变形方法最大的挑战来自于不规则的边界。不正确的拉伸边界矩形可能会带来意想不到的失真,所以内容可识别的方法是极其必要的。但现有大多数基于内容可识别的扭曲技术,或是用于投影映射操作、图像重定向(Image Retargeting),或是视频稳定化,都是基于网格并假定输入图像是矩形的。形状变形方法需要预定义的网格和用户指定的控制点作为输入/输出的限制。基于插值的变形方法则需要用户指定的多边形作为输入/输出而且不是内容可识别的[4]。
本文中拟提出一种全新的内容可识别的全景图像边界规范化的扭曲方法。其关键思想是两个步骤的方法,首先局部的扭曲原图使得它的边界规范化,然后再全局的铺上网格并再次从全局的角度扭曲原图使其边界规范。
第一步,修改Seam Carving算法,把一个不规则边界的图形扩大到矩形。把Seam Carving方法当作是扭曲方法的一种,是因为它替代了边界上该Seam的所有像素。
第二步,将网格铺在Seam Carving所输出的矩形图像上。有了第一步的移位表,就可以把网格扭曲回到原来不规则边界的图。然后,整体地优化网格使得它可以在保留包括形状和直线在内的图的感知属性扭曲到一个矩形。此方法是全自动的——基于内容且不要求事先有任何映射的信息。
2 基于内容识别的全景图边界规范化的算法
设计的扭曲算法包含两步:运用广义Seam Carving算法的局部扭曲(Local Warping)和基于网格的整体扭曲(Global Warping)。
(1)局部扭曲(Local Warping)是提供了一个初始的矩形化的(全景)图片。它的主要目的是要在原始的输入全景图上铺一个不规则的网格。
(2)整体扭曲(Global Warping)是在优化所铺的网格,使得可以保持图片内容的一些特征,如形状和直线。
2.1 局部变型
局部扭曲是Seam Carving算法的一种广义形式。原始的Seam Carving算法是插入一条贯穿图像的水平方向或竖直方向的Seam,以至于图片会从水平方向或竖直方向拓展一个像素。如果允许一个Seam不是贯穿于图像的,那么就能改变图像的边界形状并让它规范化(Rectangling)。已经有很多文献提出可以用Seam Carving把一个规则边界的图形裁剪成一些特定的形状(比如圆或椭圆)[5]。
Seam Carving中,看起来很像一个和本文研究的问题完全相反的任务(假设输入图像的不规则边界是目标边界)。定义“边界条”为一系列在目标规则边界图像一侧(上、下、左、右)连通的缺少的像素序列,每次选择最长的一个边界条,然后插入一个Seam。对于边界条在右边的情况,插入一条竖直方向的非贯穿的Seam,这条Seam的起始点和终止点和所选到的边界条的起始点和终止点分享同样的y方向坐标,然后再把所有的在这条Seam右边的像素点往右移一个像素,而边界条在左边、上边、下边的情况也可以类似的处理,重复用这种方法插入Seam直到矩形边界没有任何缺少的像素[5]。
为了找到这样非贯穿的Seam,运行Seam Carving算法去寻找一条在“子图”(Sub-image)中贯穿图像的Seam。例如,某一“子图”有着和边界条的起始点和终止点同样的y方向坐标,然后在这个“子图”上应用Seam Carving算法(在设计实现中,采用的是Improved Seam Carving),因为这个“子图”会包含缺少的像素,给这些像素分配无限大的代价来避免Seam走过这些像素,从填充未知区域这个角度来说,插入一条Seam会减少图像中缺少的像素的个数(该个数等于Seam上的像素个数),从扭曲这个角度来说,插入一条Seam相当于重新计算了一个位移表( Shift Map )u (x),用x = (x,y)去定义一个输出像素的坐标,用 u = ( ux, uy )去定义位移的值,像素的值可以通过扭曲输入图得到如式(1)所示:

这里Iin和Iout代表输入图像和当前的输出图像。
2.2 全局变型
为了生成矩形边界图像的同时可以保持如直线和形状这些高层次的属性,则需要优化一个基于网格的全局能量函数。
首先,在不规则边界的输入图上生成网格,先要在局部变形的矩形边界的结果图上铺上标准的网格。在本文的实验中,选择400个格子的网格,然后再利用局部变形的位移表,把标准的网格的顶点转换到原图中,这样就可以得到一个铺好网格的输入全景图了,全局变形就是基于这组网格。接着,设计可以对规范边界图中的形状和直线有约束作用的能量函数。这里将用相对更加简洁、参数更加少的能量函数。
引入参数V记录网格顶点 Vi= (xi,yi)T的集合,即V = {vi}。定义输入图中的网格为V,希望优化关于输入图中的网格V的能量函数。
2.2 .1 保持形状(Shape Preservation)
在这里,形状保持的能量[项E]s鼓励每个单元格的变换是相似变换(Similarity Transformation)。希望每一个具体如式(2)所示:
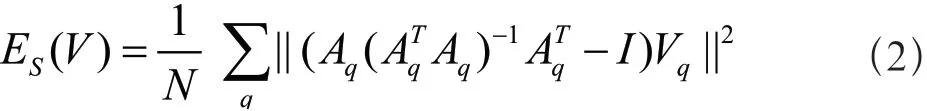
其中,N表示单元格的个数,q是单元格的索引。I是单位矩阵。Aq和Vq分别是8×4的矩阵与8×1的向量,其表达式如式(3)所示:

这里,用(x0,y0),…, (x3,y3) 定义变换后单元格四个格点的坐标,并用(),…, ()表示读入时四个格点坐标。SE是关于V的二次函数。
没有向保持形状项介入任何显著性权值(Saliency Weight)。因为全景图中经常涵盖了多样的内容、也不存在特别显著的物体。
2.2.2 保持直线(Line Preservation)
保持直线项鼓励直线经过变换后还是直线,平行线还保持平行。接下来,用网格将这些直线分割开成若干线段,每一条线段都仅在一个格内。将角度区间[-π,π)均匀的分成M=50组,量化出每个线段的方向。为了保持直线的属性和平行性,鼓励所有被分为同一组的线段,它们的旋转角度θ将会一致。保持直线这个能量项LE包含所有的这样的角度=1。
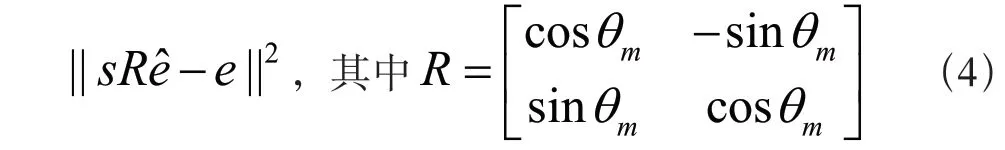
给定一条线段,可以用两个端点的差向量计算出它的方向向量e和大小。如果把一条线段的两个端点表示成四个格点qV的双线性插值,发现e可以用qV线性表示。定义该线段的输入方向向量为ˆe。给定一个目标旋转角度,想要最小化给直线的扭曲函数,如式(4)所示。R是一个旋转矩阵,s是该线段的放大量。关于s的最小化量为:s = (-1eTRTe 。把它带入上述扭曲函数,就可以得到一个关于e的二次方程 ||Ce||2,这里矩阵C是因为e是一个关于Vq的线性函数,所以,上述扭曲函数也可以写为关于Vq的线性函数。
保持直线项LE定义为所有直线段扭曲函数的平均值,如式(5)所示:
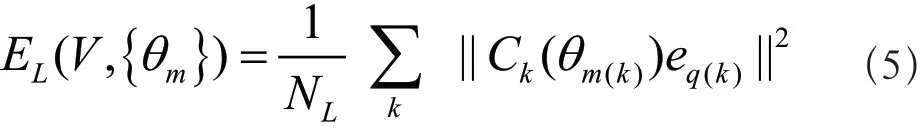
其中LN是直线段的个数。第k条直线段在第个单元格中。而矩阵)函数EL是关于V的二次函数。
2.2.3 保证边界(Boundary Preservation)
要把处在网格边缘的格点限制在长方型边框上。设计能量函数如式(6)所示:
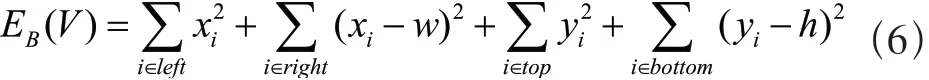
其中,w,h分别是输出图像的宽和高。这里注意到仅限制边界上的顶点两个方向坐标中的一个,如在上边界的顶点是可以左右随意动的。
要优化的能量函数如式(7)所示:
其中,λB= 108来保证图片内容完整性。其余两个参数,经过试验,发现保持直线项的权Lλ是主要决定性的参数。发现当充分大的时候,该算法就会运行的很好,比如使用这意味着保持直线的重要性要大于保持形状的重要性。同时说明人眼对于弯曲的直线比扭曲的形状更敏感,所以绝对定为λL=λB= 100。
2.3 优化方法
使用调整法来最小化能量函数 E (V ,{ θm})。初始化由局部扭曲的结果,跑迭代10次下面这个算法:
(1)固定{θm}:此时E是关于V的一个二次函数,于是可以通过解线性方程来最优化E。因为V仅仅包含几百个未知数,所以这一步花费时间是很少的。
(2)固定:因为{θm}是彼此独立的,所以可以分别优化每个mθ。此时最小化的式子可以简化为如式(8)所示:
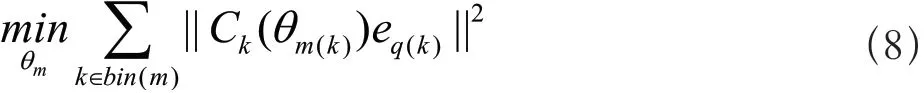
这个式子可以被优化地通过迭代的牛顿法解决。然而,采取一种启发式的更为简单的非迭代式算法。因为可以发现所有的在第m组的线段都分享这个公共的旋转角度mθ,以至于mθ会越来越接近于所有组内直线的角度和的相对的角。所以每次可以简单的计算每个组内直线的角度ke和的相对旋转角度,然后取个平均作为mθ。发现这个是最小化上述式子的很好地解决策略。
3 基于内容识别的全景图边界规范化的实现和速度分析
已假设了目标的边界是矩形,但是如果这个矩形不是一个适当的长宽比例,输出的图像会显得被拉伸过。这个问题在透视映射(Perspective Projection)的情况下尤其明显。为了减少这种拉伸,需要在全局变形后再更新目标的矩形信息。对于每一个单元格,可简单地计算它的X方向的放大系数 SX= (Xmax- Xmin)/(-)。Y 方向上也使用类似的方法计算得到。再用更新的目标矩形比例再次运行全局变形这一步,这一步降低了拉伸所带来的失真。
因为变形的位移表大多数都是平滑的,故可以在小比例的图上计算。首先将输入图缩小到一个固定的大小(实验中用的是100万像素)。让局部变形和全局变形都在这张图上运行,然后再通过双线性插值位移表来放大结果的矩形边界图像。
在实现中,算法处理的是一个千万级像素的图片、在配置CPU为Intel Core i7 2.9GHz 和8GB内存的个人电脑上,1.5s内就得到了结果,这个运行时间主要由最后的插值高像素图所导致。而这样的图用Photoshop中的“内容识别填充”填补缺少的部分(占18%的像素)要用19.1s。
4 实验结果
在各种各样的实例中展现了设计的结果,该方法成功在没有引入明显的失真而保持了原图的内容,在360°全景图中非常实用,相信扭曲变形方法在这样的实例中是备受青睐的。
我们还把实验结果和Photoshop中“内容识别填充”这种补全方法做了对比,可以看到补全技术在缺少相应语义内容的时候具有很大的局限性,会把一些语义内容当作纹理处理,还能看到裁剪后的结果,都严重影响了视角的范围。
5 结语
本文提出了一种新的内容识别扭曲方法可适用于将全景图像边界规范化。对于全景图像边界规范化的问题,扭曲策略在各种各样的情况下能起到很好的效果,特别是当不规则的边界是由随意的相机运动造成的。
引用
[1]CHEN J M,CHEN L P,SHABAZ M.Image Fusion Algorithm at Pixel Level Based on Edge Detection[J].Journal of Healthcare Engin eering,2021,2021(Pt.7):5760660.
[2]XIAO J X,EHINGER K A,OLIVA A,et al.Recognizing Scene Viewpoint Using Panoramic Place Representation[C]//Computer Vision and Pattern Recognition (CVPR),2012 IEEE Conference on, 2012:2695-2702.
[3]QI S Y,HO J.Seam Segment Carving:Retargeting Images to Irregularly-Shaped Image Domains[C]//European Conference on Computer Vision.Springer,Berlin,Heidelberg,2012.
[4]HE K,JIAN S.Statistics of Patch Offsets for Image Completion[C]// European Conference on Computer Vision.Springer,Berlin,Heidelberg, 2012.
[5]DARABI S,SHECHTMAN E,BARNES C,et al.Image Melding: Combining Inconsistent Images Using Patch-based Synthesis[C]//ACM Transactions on Graphics,2012(4CD):1-10.
