The early Japanese books reorganization by combining image processing and deep learning
2022-12-31BingLyuHengyiLiAmiTanakaLinMeng
Bing Lyu|Hengyi Li|Ami Tanaka|Lin Meng
1Graduate School of Science and Engineering,Ritsumeikan University,Kusatsu,Shiga,Japan
2College of Science and Engineering,Ritsumeikan University,Kusatsu,Shiga,Japan
Abstract Many early Japanese books record a large amount of information,including historical politics,economics,culture,and so on,which are all valuable legacies.These books are waiting to be reorganized at the moment.However,a large amount of the books are described by Kuzushiji,a type of handwriting cursive script that is no longer in use today and only readable by a few experts.Therefore,researchers are trying to detect and recognise the characters from these books through modern techniques.Unfortunately,the characteristics of the Kuzushiji,such as Connect‐Separate‐characters and Many‐variation,hinder the modern technique assisted re‐organisation.Connect‐Separate‐characters refer to the case of some characters connecting each other or one character being separated into unconnected parts,which makes character detection hard.Many‐variation is one of the typical characteristics of Kuzushiji,defined as the case that the same character has several variations even if they are written by the same person in the same book at the same time,which increases the difficulty of character recognition.In this sense,this paper aims to construct an early Japanese book reorganisation system by combining image processing and deep learning techniques.The experimentation has been done by testing two early Japanese books.In terms of character detection,the final Recall,Precision and F‐value reaches 79.8%,80.3%,and 80.0%,respectively.The deep learning based character recognition accuracy of Top3 reaches 69.52%,and the highest recognition rate reaches 82.57%,which verifies the effectiveness of our proposal.
KEYWORDS character recognition,deep learning,image processing,Japanese books reorganization,Kuzushiji
1|INTRODUCTION
A huge number of early Japanese books exist,which describe historical politics,economics,culture,etc.Unfortunately,some organisations have not been completed,and some of these books have not been organised.Hence,reorganising these early Japanese books is of great significance for better understanding the history of Japan and preventing the loss of the national culture.Due to the huge number of these books,the reorganisation,including automatic character detection and recognition,and texts digital recording,become an important issue.However,most early Japanese books are written in the‘Kuzushiji’,which is a typeface for simplified characters.The characteristic of the Kuzushiji is un‐uniformed and can be written quickly,and also referred to as‘cursive script’.Furthermore,Kuzushiji is rarely used in current society,and only a few experts can read it,which makes the early Japanese books'recognition more difficult[1].
With the development of artificial intelligence(AI),Convolutional Neural Networks(CNN),a kind of feedforward neural network containing convolutional computation and deep structure,has achieved great success in various domains,including computer vision recognition[2,3],natural language processing[4],service ecosystems[5],environment protection[6],Internet of Things[7],etc.Multiple excellent deep neural architectures have been proposed,such as AlexNet[8],VGG[9],InceptionNet[10–12],ResNet[13],MnasNet[14],ShuffleNet[15,16],MobileNetV2[17],etc.Recently,more and more research studies have focussed on applying CNN techniques for cultural heritage reorganisation and protection and have made impressive progress.Researchers have proposed several deep learning models for object recognition,which have also been extended for realising the automatic organisation of early Japanese books.However,the implementations have not achieved exciting results for the difficulties caused by the characteristics in the Kuzushiji and early Japanese books,which are summarised as three kinds of major problems as follows:
First,the many‐variation characteristic of the Kuzushiji refers that the same character may have several variations,even in the case of the same character written by the same person.Second,the connected character of the Kuzushiji,that is,characters are connected in general,which is also the most significant characteristic of the Kuzushiji.Third,the separate character in the Kuzushiji,which means some characters consist of several unconnected parts,is also a difficult problem.Besides,there are also many other factors such as ageing processing which lead to the characters being broken,blurred,and so on.These characteristics increase the difficulty of character detection and recognition greatly.
This paper aims to solve these problems and construct a Kuzushiji document reorganisation system for reorganising early Japanese books.The method combines image processing and deep learning to automatically detect and recognise the Kuzushiji.The proposal consists of three stages.The first stage is character segmentation using image processing.The second stage is character recognition by deep learning.The last stage is visualisation,which shows the recognition results of early Japanese books in an easy to understand way.
There is little information about the recognition of Kuzushiji in early Japanese books at present,so this is a new attempt as well as a challenge to realise the automatic recognition of Kuzushiji.It will be a great help to the understanding and preservation of ancient Japanese culture.This is the main contribution of our research.
The rest of this paper is organised as follows.Section 2 introduces the early Japanese books and the related work.Section 3 details the construction of our proposed character recognition system which is based on image processing and deep learning;Section 4 shows the procedure for character segmentation;Section 5 details the character recognition and visualisation;Section 6 provides the details about the experimentation;Section 7 presents the evaluation of the proposed character recognition system and makes a discussion;Section 8 concludes the paper with a brief summary and mention of future work.
2|EARLY JAPANESE BOOKS AND RELATED WORK
2.1|Early Japanese books
The ancient people created a glorious history and culture.This cultural heritage is accumulated in a rich number of books and handed down till today.Early Japanese books are one kind of literature that preserve Japanese national culture.At the same time,researchers are trying to collect the early Japanese books for organising the culture.Ritsumeikan University Art Research Centre has createdThe Early Japanese Books Portal Database[18],which digital archives a huge number of early Japanese books.The system also has a search engine for searching the early Japanese books by the index of Title,Author,Establishment year,Place,etc.However,the system has not been able to translate all of the ancient books into current characters directly by now.
TheDataset of Pre‐Modern Japanese Text[19]refers to the opening of digitised images of classical books as open data in the‘Project to Build an International Collaborative Research Network for Pre‐modern Japanese Texts’.It is now centrally provided with open data from theNational Institute of Japa‐nese books[20].As of January 2019,3126 books(609,631 pages)are reorganised as a huge dataset.The other database is theKuzushiji Database[21],which consists of cut characters from images of 44 classical books inThe Dataset of Pre‐Modern Japanese Text,with 4328 classes of characters.TheKuzushiji Databasecreation is very time‐consuming and labour‐intensive.The dataset records the Unicode and theXandYcoordinates of each character in the document image.
2.2|Problems definition
There are three major problems in Kuzushiji recognition for early Japanese book reorganisation.The first issue is the many‐variation characteristic of a single character.This means that the same character might be written in a variety of ways,even some of them are no longer in use today,which greatly increases the difficulty of interpreting the character.The second problem is separate‐character.Influenced by the structure of Japanese characters,one character can occasionally be identified as two sub‐characters or even multiple sub‐characters.The solution to deal with this problem is a crucial part of Japanese character recognition.And the last issue is connect‐character.Connect‐character is not only in Japan but also in Asian handwritten books.The length of connect‐character depends on the writer's writing habits,with the longest connect‐character being made up of six characters.The three kinds of problems are defined in detail as follows:
Many‐variation:
Japanese character consists of hiragana,Katakana and Kanji.Today,with a few exceptions,there is just one way to write each hiragana.However,each hiragana usually has more or less several interchangeable hiragana names in early Japanese books,which are called Hentaigana.What is more,some Hentaiganas are no longer in use today.For example,as shown in Figure 1a,there are two variations of‘か’on the same page.Besides,the writing of‘か’is not the same for the same person in the same page.Figure 1b also shows two variations of the same character‘し’.
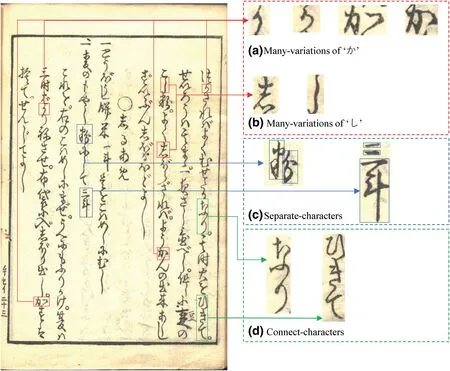
FIGURE 1 Problems of Kuzushiji image
Separate‐character:
One of the characteristics of Japanese writing is that some characters are not written with a single stroke,which results in one character being divided into several parts.As shown in the left of Figure 1c,the character‘粉’can be divided into the left word‘粉’and the right word‘分’.In character recognition,the separate‐character is more likely to be distinguished as several characters,resulting in lower recognition accuracy.In addition to the left‐right character,as shown in the right of Figure 1c,there are also top‐bottom characters that exist.The character‘三’is often separated into several‘一’,causing recognition errors.
Connect‐character:
As the abstract mentions,some characteristics of the Kuzushiji limit the character recognition accuracy,posing difficulties for the Early Japanese book Reorganization System.Connect‐character is a kind of writing form in early Japanese books,which is caused by high‐speed writing.Figure 1d shows two examples of connect‐character.The left figure is a connect‐character of two words‘な”り’,and the right figure is a connect‐character of three words‘ひ”き”て’.Connect‐character as a complete part cannot be recognised,so connect‐character segmentation is a very important part of the character recognition system.
2.3|Related work of early literature reorganisation
The early literature,including books,documents,etc.,is attended by researchers because of its historical value.Researchers are trying to reorganise these literature through image processing,deep learning,etc.Fujikawa et al.,have designed a web application for assisting oracle bones inscriptions’(OBIs)reorganisation[22].OBI is a kind of hieroglyphics,which evaluated Chinese characters.It also means the OBIs are a prototype of some Japanese characters.For overcoming the problem of the dataset limitation in OBIs recognition,Yue et al.,have proposed a Generative Adversarial Network(GAN)based method for data augmentation[23].This research has achieved a certain level.Unfortunately,due to the problem of Kuzushiji,these proposed methods are difficult to obtain a good accuracy on early Japanese book reorganisation.On the other hand,these research studies point out that deep learning may be an effective method for the early Japanese books reorganization.
AlexNet and GoogLeNet have been shown to be effective for early Japanese book character recognition such as oracle bone inscriptions and rubbing characters[24,25].Furthermore,networks have been proposed in which the model simultaneously performs extraction and recognition of an object area from an image by combining segmentation and recognition,for example,YOLO[26],SSD[27].The SSD uses the image identification model and VGG as a base model,and is also shown in the effectiveness of Chinese oracle bones character recognition.However,since the class number of the model is limited in supporting a large number of classes,it becomes an issue for recognising characters with thousands of classes.
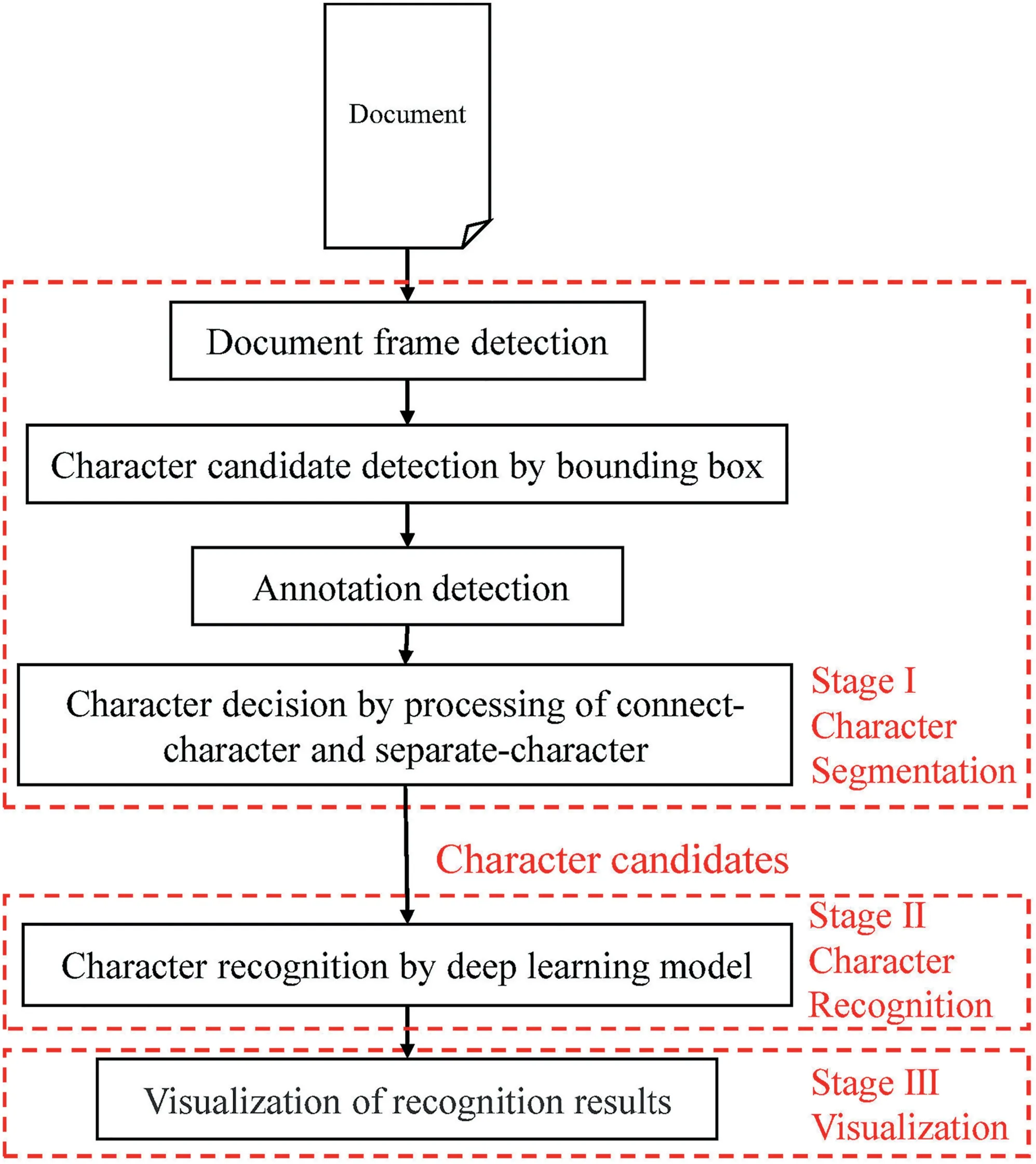
FIGURE 2 Structure of character recognition system
This paper proposes an image processing and deep learning combined method for the Early Japanese Books Reorganization based on the above study.
3|THE OVERVIEW OF EARLYJAPANESE BOOK REORGANIZATION SYSTEM
This paper proposes an image processing and deep learning combined method for the Early Japanese Books Reorganization based on the above study(Figure 2).
The first stage is character segmentation using image processing,including image frame detection,character bounding box detection,and processing of connect‐character and separate‐character.Because most early Japanese books have a frame around the text,as shown in Figure 1.Hence,to remove noise outside the frame in the image,that is,the stains,damages,page numbers,etc.,we locate frame coordinates according to the feature that the frame has many black pixels.Thus,noises outside the frame are identified and eliminated.Then we perform bounding box detection on text in the image.To reduce the influence of annotations on the text,we eliminate the annotation bounding boxes in the image firstly.Next,for the problems that occur in bounding box detection,that is,connect‐character and separate‐character,we propose solutions,respectively.In this stage,we get all character candidates in the image as test data for the character recognition stage.
The second stage is character recognition using deep learning models.The extracted character candidates from the first stage are to be recognized by deep learning in this stage.Due to the rapid development of artificial intelligence today,many novel deep learning models are constantly proposed by researchers.Hence,we select the optimal model from those novel models based on three factors through the evaluation experiment:training accuracy,test accuracy,and model size.Finally,the selected optimal model is applied for character recognition in our system.
To present the recognition result of each character,the last stage comes to visualise the recognition results in the original image.The visualisation information includes bounding boxes,character recognition results,and character recognition accuracy.
After the three stages of processing,the character recognition results are visualised in the image finally.
4|STAGE I:CHARACTER SEGMENTATION
Many early Japanese books have been kept for a long time,resulting in serious noise such as blurring,smudging,and moth‐eating,which heavily interferes the character recognition accuracy.Hence,character segmentation processing becomes important in the recognition system,which consists of the following processing.We detect the image frame at first to eliminate the problem of noise in the image for saving the computational resources and time in the character recognition stage.Then,bounding box detection is carried out within the text part of the frame,which not only eliminates the interference of noise outside the frame but also avoids recognising the text outside the frame.The third is to solve the problem of bounding box detection,that is,the separate‐character and connect‐character problem,and finally extract the processed characters.
4.1|Document frame detection
Image frame detection is mainly realised by image processing.First of all,the original input image is binarised.Image binarisation is to convert the grey‐scale value of the pixels on the image to 0 or 255,which presents the whole image in the black‐white format.For image processing,binarisation plays a very important role since it not only significantly reduces the amount of noise in image processing but also highlights the contour of the target.Then the four vertex coordinates of the frame are obtained based on the feature that the frame part of the image has significantly more black pixels than the rest,especially the parts corresponding to the four vertices coordinates of the frame:by calculating the horizontal and vertical pixel histograms of the image,the values of the histograms represent the number of black pixels of the concerning locations.The four vertices coordinates of the frame in the image are then located.
We use a piece of Japanese book image to demonstrate the frame detection algorithm.Black pixels are tallied in the horizontal and vertical axes of the image,respectively.Figure 3 shows the black pixel graph of the binary image in two directions.Peaks in the both histograms represent the higher concentration of black pixels in the image,and peaks of the frame are significantly sharper than other peaks.According to this feature,four coordinate points of the frame can be positioned,as shown in the figure,which areThe four coordinates are used to locate the frame position in the image.Only the characters contained within the frame are processed.As a result,the interference of noise in the image is eliminated largely.
4.2|Character bounding box detection
Since it is difficult to detect all characters in the whole image at once directly,we use functions to detect the characters,respectively.First,the FindContours function in OpenCV is applied,which basically sorts all the pixels in the image.The connected pixels are defined as the same class,and discontinuous pixels are regarded as different classes.Then the ContourArea function is used to find four vertex coordinates of each class.Finally,Rectangle functions are adopted to display the four vertex coordinates of each class.The displayed rectangle is defined as the bounding box for each character.As shown in Figure 5(c),the rectangle around the character is a bounding box.Due to the influence of the left‐right structure of Kanji in Japanese characters,two bounding boxes are detected for one Kanji.We put forward corresponding solutions to this problem in the following part.
Bounding box detection is carried out on the characters in the image.It can be seen that for these characters,not all bounding boxes are detected correctly in Figure 5a,b.There are detection errors that can be simply classified into two kinds which are caused by the two problems mentioned above,that is,connect‐character and separate‐character problems.We propose solutions for the two problems and introduce them in the following part,respectively.Before that,we introduce the K‐Means clustering algorithm used in both solutions.
4.3|K‐Means clustering
K‐Means clustering is a simple and classical distance‐based clustering algorithm.It determines the category of each sample by calculating the centre of mass of each cluster.The centre of mass is the centre of all the points in a cluster.We use an example to explain the algorithm.
The implementation steps of the algorithm are shown as follows:
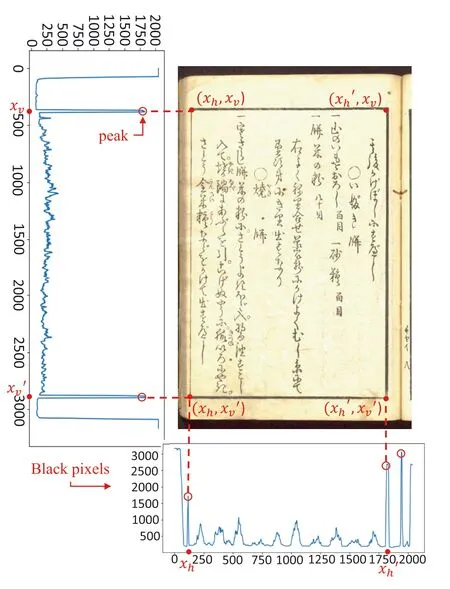
FIGURE 3 Method of Document frame detection
·Step 1:Cluster number determination:The dataset is planned to be clustered intokclusters through K‐Means.Figure 4 explains an example which setsKto 2.Yellow dots are defined as target points.
·Step 2:Dataset Initialisation:ktarget points are randomly selected and set as the centre points of mass.The centre of mass is the centre of all the points in the cluster.In this example,the red and blue triangles(k1,k2)are selected as centres of mass randomly,as shown in Figure 4b.
·Step 3:Target points clustering:For each target point,the algorithm calculates the distance between the target point and each centre point,respectively,and lets the target point belong to the shortest distance of the centre point.As shown in the Figure 4b,the distance between target pointPand centre pointk1is calculated asd1,and the distance between target pointPand centre pointk2is calculated asd2.Sinced1is shorter thand2,the target pointp1is set into the cluster of the blue triangle.All the target points are clustered in this way.
·Step 4:Renewing the centre points of cluster:Figure 4d shows the data are clustered into two clusters,and the centre of mass should be renewed.The average of thexcoordinate andycoordinate of each point belonging to the same cluster is calculated and set as the new centre points.Figure 4e shows that the new centres of mass are defined ask′1andk′2,and the distances between pointp3 and the new centre points of mass ared′1andd′2,respectively.All the data points were reclassified again.

FIGURE 4 K‐Means algorithm
·Step 5:Integration:If the distance between the new centre points of mass and the original centre point of mass is less than a threshold value(meaning that the position of the recalculated centre of mass tends to be stable),we consider that the clustering has reached the expected result and the algorithm is terminated.If the distance between the new centre points of mass and the original centre point of mass is greater than the threshold value,repeat steps 3–5 until the centre of mass becomes stable.Finally,all the points are divided into red and blue clusters,as shown in Figure 4f.
Supposing the cluster is divided intoC1…Cm,the goal is to minimise the squared errorE:

whereμiis the centre of mass ofCi,and its expression is as follows:

4.4|Merging of separate‐character bounding boxes
This subsection introduces the algorithm of merging separate‐character bounding boxes.There are a lot of separate characters in the bounding box detection,as shown in the Figure 5a(circles).These separated characters are divided into left and right separated characters(blue circles),and top and bottom separated characters.The majority of separate‐character are left‐right separated characters from the Figure 5a.The proposed solution is illustrated in the case of the example that merges left and right separated characters,and the flow is shown in Figure 5c.
In Figure 5c,as an example,a character‘絹’is detected with two bounding boxes(red boxes).The coordinate origin of part‘糸’is(xij,yij)and coordinate origin of part‘肙’is(xij+1,yij+1).idenotes theithcolumn of the bounding boxes,andjdenotes thejthbounding box in that column;xijandyijrepresent the coordinates of the upper left corner of the bounding box;wijandhijare the width and height of the bounding box,respectively.For easy understanding,we mark the origin coordinates of two bounding boxes with green points and orange points in Figure 5c.In the algorithm,when it is decided to merge two bounding boxes,the smallest and largestxcoordinates are selected from allxcoordinates,which arexij,xij+wij,xij+1,xij+1+wij+1.In this example,the smallest and largestxcoordinates arexijandxij+1+wij+1respectively.In the same way,the smallest and largestycoordinates areyij+1andyij+1+hij+1respectively.The smallestxandycoordinates make up coordinate origin of merged bounding box(blue boxes),which in this example is(xij,yij+1),marked with a red point in Figure 5c.
Each column number is denoted asNi.The array of all bounding boxes is defined asBBij{i∈(0…9),j∈(0…Ni−1)}.
The threshold values in Algorithm 1 are defined asTxandTy.We take 300 characters and arrange them from smallest to largest in width and height,respectively.As the width and height of most characters are clustered within a certain interval,the median width and height of the intervalWandHare selected as the standard.W/2 is used as the standardTxto determine whether the merger takes place in theXdirection,andH/2 is used as the thresholdTyto determine whether the merger takes place in theYdirection.

FIGURE 5 Mergence of separated characters

Algorithm 1 Algorithm for merging separated character bounding boxes
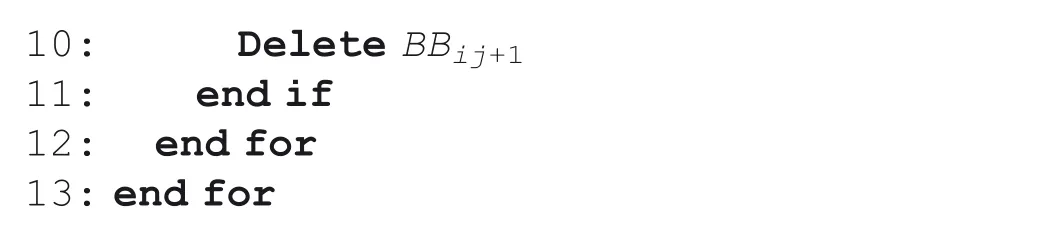
10: Delete BBij+1 11: end if 12:end for 13:end for
Due to the mess of the bounding boxes obtained through OpenCV,all of the bounding boxes need to be reordered.The clustering algorithm K‐Means is adopted for this.K‐Means clustering is a simple and classical distance‐based clustering algorithm.It determines the category of each sample by calculating the centre of mass of each cluster,that is,the centre of all the points in a cluster.
We divide the bounding boxes in the whole image into 10 clusters and mark each cluster with a different colour.The result is shown in Figure 5a.Then,the bounding boxes of each column are arranged based onyvalue from smallest to largest.The centre coordinate of the bounding box isAs for a certain column,thexcoordinate of the centrelineCLiis obtained by averaging from the sum of all thexcoordinates.
Then,the distancedij,that is,the distance from the centre of a bounding box to the centreline,is calculated for each bounding box of each column.As for the two adjacent bounding boxes,they are merged in case that the distance,which is betweendij+1anddij,is less thanTx.Andyvalue between two centre coordinates of adjacent bounding boxes is less thanTy.The coordinates of the bounding boxBBijare replaced with,and the bounding boxBBij+1is removed.
The characters which are separated into top and bottom are merged in the same way.Figure 5b shows the merge result,which demonstrates most of the separated character boxes are merged well.
4.5|Annotation detection
In early Japanese books,some kanji have annotations on the right side,which is usually the hiragana of the character.These annotations are also detected by bounding box detection,as shown in Figure 5a.Annotations can be detected due to their small font size and distance from the centreline of each column.Bounding boxes with smaller areas and larger distances from the centreline are regarded as annotations and deleted.The image of a deleted annotation bounding box is shown in Figure 5b,and it can be seen that most of the annotations have been removed.
4.6|Separation of connect‐character using K‐Means clustering
Influenced by writing habits,many early Japanese books have a lot of connect‐characters.In the character recognition process,many connect‐characters are recognized as one character,which increases the difficulty of character recognition.In this dissertation,we adopt K‐Means to separate these connect‐characters,and the method achieves a good result.
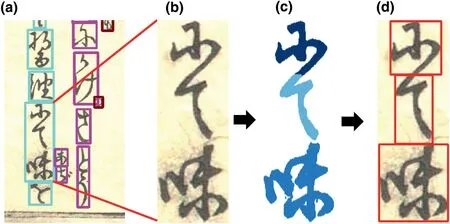
After character bounding box detection,the separate‐characters are merged,then we separate connect‐character.Figure 6c shows results of connect‐character being separated using K‐Means clustering.It can be seen that the three connected characters are well separated.And then,the four coordinates of each character are calculated to draw a new character bounding box in Figure 6d.Finally,the separated characters are extracted with the new character bounding box.With this method,all of the connected characters in the image are separated into single characters correctly.
The premise of using K‐Means clustering algorithm is to get the number of clusters to be divided into,that is,kof K‐Means.Since the number of connected characters is not a certain number,it is necessary to estimate the number of connected characters.
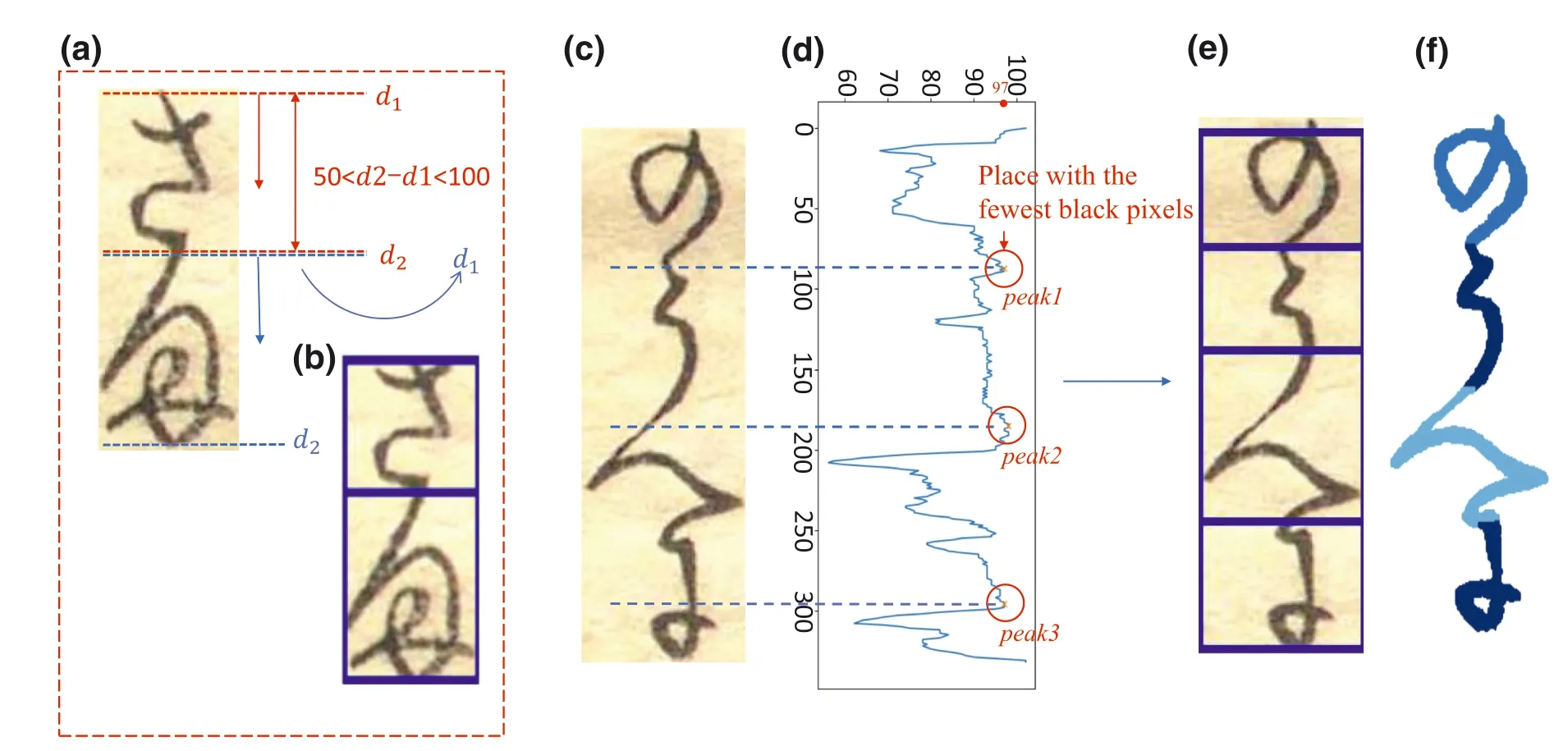
We propose a simple method to estimate the number of characters in the image shown in Algorithm 2.First,the black pixels of each line in the image are calculated from top to bottom.We draw black pixel graph in the y‐coordinate direction of Figure 7c.The graph is shown in Figure 7d and we can clearly see the number of black pixels in each line.In a grayscale image,the black pixel value is 0 and the white pixel value is 255,so the fewer black pixels have a higher black pixel value.We found peaks in the black pixel graph and recorded the histogram values of these peakspeak1,peak2,andpeak3,which are 97,98,and 97 respectively.We take the average of these peaks as the thresholdt.
In Algorithm 2,when the black pixel is greater than 1,the position is denoted asd1in Figure 7a.The calculation is continued and when the value of black pixels is less than thresholdt,then the position is noted asd2.Since the size of a character is between 50 and 100 pixels,it is considered a character in case the distance betweend2andd1is greater than 50 and less than 100 pixels.Then the value ofd2is taken as the new value ofd1for the following calculation,continuing to calculate down the black pixel value.kis the estimated number of characters in the image.Figure 7b shows that the estimated number ofkin Figure 7a is 2.

Algorithm 2 Algorithm for estimating k value Input:Black pixel,pi;Height pixel of image,H;Threshold value,t;Count number,k;Output:k value 1:Calculate the value of black pixels on line i,denoted as pi 2:for i=0…H do 3:if pi>1 then 4: d1⇐i 5: i⇐i+1 6:end if 7:if pi Direct segmentation of connect‐characters by this method has problems as shown in Figure 7e.In order to solve these problems,we combine the proposed method with the clustering algorithm to segment connect‐characters.The estimation number of connect‐character using the proposed method in Figure 7e is 4,and the segmentation results of characters by K‐Means clustering algorithm are shown in Figure 7f.So we estimate the number of connect‐character by the proposed method first,then the connect‐character can be segmented well by K‐Means clustering algorithm. As one of the key technologies of AI,deep learning has made great progress and outperforms previous technologies with breakthroughs in various domains recently,such as natural language processing[4],image recognition,heritage protection[28],Internet of Things[7],the elderly care[29],and so on.Both academia and industry have been focussing on theresearch and application of deep learning.The technique is to learn the internal rules and representation levels of sample data,and the information acquired in the learning process is of great help to the interpretation of data such as character,image,and sound.The ultimate goal is to make machines analyse and learn like humans,to be able to recognise objects intelligently. FIGURE 6 Separation of connected characters FIGURE 7 K value estimation In the character recognition stage,we choose the deep learning models first.Nowadays,with the rapid development of artificial intelligence,a variety of deep learning models are constantly proposed by researchers.We need to select the most optimal deep learning model for training early Japanese books according to the characteristics of books.Then we make the training dataset,which is early Japanese books character dataset.In order to ensure the training accuracy,the training dataset needs to be checked several times.Next,ground truth is made for all characters in each image as a criterion for judging whether the character is correct.Finally,all characters in an image are tested using the trained deep learning model,and the recognition accuracy of the entire image is finally obtained by comparing it with the ground truth. As for the visualisation of the recognition to represent the results on the original image,image processing is adopted for the task.The information visualised has three parts:character bounding box,recognition result,and recognition accuracy.This information clearly demonstrates whether the character is correctly recognised and helps to find the reason for the wrong recognition of the character. The data used in the experiments is from books collected in theCentre for Open Data in the Humanities(CODH)[30].There is a lot of open data in CODH that can help Kuzushiji recognition research.Dataset of Pre‐Modern Japanese textprovides image data of 701 pre‐modern books in a downloadable format.By assigning Digital Object Identifier(DOI)to each book,image data can be uniquely identified even when there are multiple books with the same title.Dataset of PMJT Character Shapes contains 3999 character types and 403,242 characters of early Japanese characters(called Kuzushiji). In order to verify the effectiveness of our proposed method,we conducted experiments with two early Japanese books,which are‘mochi ga shi soku seki’(No:100249416,hereafter referred asBook1)and‘go zen ka shi hi den syo’(No:100249376,hereafter referred asBook2),respectively.We randomly select 15 images fromBook1and select 45 images fromBook2as experimental data.The reason for choosing different numbers from the two books is thatBook1contains a large number of mixed pictures and characters,as shown in Figure 8.While our proposed method is aimed at early Japanese books with only text,so there are few images to choose inBook1.Therefore,in order to increase the persuasion of the experimental results,we select 45 images fromBook2as experimental data,and a total of 60 images are used for experiments.The operating system used in this experiment is Ubuntu20.04.1 LTS,and the programing language is Python. In order to test the effectiveness of the proposed bounding box detection method,we use 60 images fromBook1andBook2to carry out bounding box detection experiment.For the first,we use OpenCV to detect bounding boxes of the image.In terms of the two problems found in the detection,that is,separate‐character and connect‐character problems,we employed the corresponding solutions as introduced in Section 4.We conduct experiments on the image using the proposed method,and the result is shown in Figure 9.Most bounding boxes can be completely detected,as shown in the example above,and a few are wrongly detected. We use the same 60 images fromBook1andBook2to carry out character recognition experiment.The experimental flow chart is shown in Figure 10.Firstly,the preprocessing of training data and test data is carried out,that is,the reorganisation of training data and the labelling of test data.The training data used in the experiment is reorganised from theKuzushiji dataset,and the test data is extracted characters from the image with the proposed method.80% of training data is used for training the model,and the remaining 20%is used as validation data to calculate the validation accuracy.Then,the trained model is tested on the test data. 6.2.1|Preprocessing FIGURE 8 Image of mixed text and picture FIGURE 9 Result of bounding box detection Reorganisation of training dataset:It took a long time for the Japanese language to become what it is today.There are many variations of the same character in early Japanese books.In Japanese syllabary,there are at least two variations to write hiragana,and some have as many as dozens of ways.For example,the hiragana‘か’in Figure 11a has as many as 12 ways.The Hiragana in Japanese is developed from the Kanji,for example,the character‘安’,which has evolved into‘あ’.Similarly,many Kanji with the same pronunciation have gradually been replaced with the same Hiragana.Three variations of the same Hiragana‘あ’appear in the same book as shown in Figure 11b.The red,yellow,and blue boxes are the three different variations of Hiragana‘え’in Figure 11c.Hiragana‘え’is developed from Kanji‘衣’,so‘衣’is a variant of Hiragana‘え’.The Kanji‘江’,which has the same pronunciation as‘え’,also appears as‘え’in early Japanese books,so‘江’is a variant of‘え’.In theKuzushiji dataset,different variations of the same Hiragana are mixed,as shown in Figure 11b,c,which increases the difficulty of the convolutional neural network model training and significantly reduces training accuracy.So we reorganised the data in theKuzushiji datasetto categorise different writing ways of the same character. We have reclassified all of the 468 classes to be 1123 classes by extending the variations of the same character to be different classes.We make a training dataset based on early Japanese books,with a total of 1123 classes containing 52,932 characters.The members of each class of characters are limited to no more than 100,which ensures sufficient data as well as avoids redundancy which may lead to more training consumption.At present,there is no automatic method to separate the mixed characters,so we separate the different variations of the same character manually.Moreover,because the training data of the deep learning model must be guaranteed,so we checked all data in the book many times to ensure the data is correct.It really took us a long time and a lot of effort. FIGURE 1 0 Flowchart of character recognition FIGURE 1 1 Examples of different variations for one character Labelling of test dataset:In CODH,there are correct character interpretations of the experimental image,which are used to make the label of the test data,that is,ground truth.The noise and erroneous images in the test,their labels represented by‘N’,were directly identified as erroneous characters when used for character recognition. 6.2.2|Optimal model determination Training accuracy of four models:In the field of computer vision,deep learning has been the dominating technique with various architectures.An enormous amount of research effort has been made on designing and optimising deep learning architectures[31]and has made a lot of achievements.We chose four of the most representative neural network models,that is,InceptionV3 model[12],Xception model[32],Densenet121 model[33],and MobileNetV2 model[17],to carry out the experiment. Due to the large classes of characters in early Japanese books and complex glyphs,it is difficult to obtain good training results by using simple convolutional neural networks(such as LeNet[34]and UNet[35])to train character data.In recent years,many excellent models have been continuously proposed by researchers,and the complexity of the models is gradually increasing.Due to the huge data from early Japanese books,we need to choose a model with light‐weight architecture as well as high accuracy.The models we choose are both better compared with the original models. InceptionV3 modifies the Inception block on the basis of InceptionV2,greatly improving the accuracy.The network mainly adopts decomposition convolution,that is,decomposing large convolution factors into small convolution and asymmetric convolution.The number of parameters is also reduced by decomposing convolution.In addition,the Batch Normalisation(BN)layer is added to the auxiliary classifier to improve the accuracy and plays a regularisation effect.Xception is also proposed by Google,and it is a direct evolution of InceptionV3.In Xception,separable convolution is used to replace the convolution operation in the original InceptionV3.The model efficiency is improved without increasing the complexity of the network.In terms of DenseNet,all layers are directly connected under the premise of ensuring maximum information transmission between the middle layer and layer of the network.In this way,the transmission of feature is strengthened such that features are utilised more effectively.In addition,the number of parameters is reduced to a certain extent and the network is easier to train.MobileNetV2,which is proposed by Google,adopts Linear executors and Inverted residuals to modify the modules in MoblieNetV1 model,making the model smaller and achieving higher accuracy. The four deep learning models are trained on the training dataset.Figure 12 shows the training results and Table 1 lists the final training accuracy of the four models.It is obvious that the training accuracy of the four models is no less than 98%.According to the experimental results,the four models are sufficient for the task.Xception achieves the highest accuracy with the value of 99.4%.In addition,considering the complex structure and numerous parameters,we do not modify the convolutional layers and the other structures of these models,but adjust the learning rate and training epochs according to our own needs in the training phase. Test accuracy of the four models:An image of early Japanese books is adopted to test the character recognition accuracy with respect to the four deep learning models.For each character in the image,there may be 1117 recognition results.In terms of the test dataset,all of the recognition results are sorted FIGURE 1 2 Training accuracy of the four models TABLE 1 Comparison of the four models on a single test image from the largest to the smallest,and the first three results are taken as theTop3 accuracy of the character.The results are compared with the true label of the character.As long as one of the three results is consistent with the label,the character recognition is judged to be correct.Similarly,the first result is theTop1 result for the character.If it is consistent with the true label,the character is recognised correctly.For this stage,the training accuracy on the training dataset,as well as theTop1 andTop3 test accuracy on the single image,are shown in Table 1.As can be seen in Table 1,theTop3 recognition accuracy of the four models is all above 64.3%,and theTop1 recognition accuracy is all above 48.0%.MobileNetV2 reaches the highestTop3 recognition accuracy which is 76.0%,as well as achieves the bestTop1 recognition accuracy of 67.8%.In a strange way,Xception,which achieves the highest training accuracy,came in second.Whereas,the MobileNetV2 with the lowest training result achieves the best test accuracy. Selection of optimal model The selection of the optimal model is based on three criteria:training accuracy,testing accuracy,and model size.Regarding the training accuracy,since the training accuracy of the four models is above 98%,which all meet our requirements for the model training accuracy,it does not play a great role in determining the optimal model.The second aspect is testing accuracy,with MobileNetV2 achieving 76% accuracy compared to 64.3% for DenseNet121.The testing accuracy varies widely between the four models.The gap between the lowest accuracy and the highest accuracy is 11.7%,highlighting MobileNetV2's advantage in text prediction.The third aspect is model size.It can be seen from Table 1 that MobileNetV2 has the smallest size among the four models and occupies the least memory,and InceptionV3 has the largest size which is six times as large as that of MobileNetV2.The model has a small size,few parameters,fast running speed,and high prediction accuracy,indicating that MobieNetV2 model is the most optimal model for early Japanese book recognition among the four models.So we choose MobileNetV2 as the optimal model for the experiment. The final result of recognising an early Japanese book image through our proposed three‐stage method is shown in Figure 13.Each bounding box,character recognition accuracy,and character recognition result is visualised on the image.The bounding box on the left is depicted in blue and the character recognition results are shown in red in Figure 13.It can be seen that noise beyond the frame and annotations beside the text in the image are neglected,but only the text in the image is recognised,demonstrating the effectiveness of our proposal. We evaluate the proposed character recognition system intuitively based on analysing the two experimental results.Of the60 images,the first 15 are selected fromBook 1and the last 45 fromBook 2.The reasons for the difference in the number of images selected fromBook 1andBook 2have been mentioned above. FIGURE 1 3 Result of character recognition 7.1.1|Evaluation of bounding box detection accuracy We evaluate the accuracy experiment of bounding box detection,and calculate theRecall,PrecisionandF‐valueof the experiment.Recall,PrecisionandF‐valueare calculated as follows: whereCNdenotes the correct number of bounding box detection,TNdenotes the total number of bounding box detection,andACdenotes all characters in an image.Recallrepresents the percentage of bounding boxes that should have been detected correctly.Precisionrepresents the proportion of the correct bounding boxes detected in the detected bounding boxes.F‐valuerepresents the weighted average ofRecallandPrecision,and whenF‐valueis high,it indicates the effectiveness of the test method. Table 2 shows the specific experimental data of bounding box detection of 60 experimental images,that is,the values ofTN,CN,andACof each image.In order to observe the experimental data more intuitively,we draw theRecall,Pre‐cision,andF‐valueof the experimental image into a broken line chart.Figure 14 shows the experimental results of the 60 images. The averageRecall,PrecisionandF‐valueof 60 images are calculated to be 79.8%,80.3%and 80.0%,respectively.That is,nearly 80% characters in an image can be correctly detected.Image No.46 has the highestF‐value,withRecall,Precision,andF‐valueachieving 91.15%,94.50% and 92.79%,respectively. 7.1.2|Evaluation of character recognition accuracy We record all experimental data of 60 images in the character recognition experiment in Table 3 and draw the data in broken line charts in Figure 15.The averageTop3 andTop1 of the 60 images are 69.52% and 59.88%,respectively.This means that nearly 70% of the characters in an image are recognised correctly inTop3.The highest character recognition accuracy inTop3 reaches 82.57%,which is the No.46 image.Due to the noise in the image,recognition accuracy is limited. The two experiments,the bounding box detection experiment and the character recognition experiment,illustrate the feasibility of our proposed method.Through the analysis of the experimental results,we find that the difference in the character recognition results among the pages of the same book is up to 22.64%.By analysing the experimental results,we believe that there are four causes as follows: First,stains,moths,or damage to the image,inevitably occur for the early Japanese books over a lengthy period of preservation,which will also make the image recognition accuracy too low.The experimental results show that the difference between the noisy early books and well‐preserved early books is very large. Second,the result of the bounding box detection stage is not good enough.The character recognition is heavily influenced by the accuracy of bounding box detection.Due to the complexity and diversity of characters,more or less characters may be incorrectly recognized as other characters,resulting in lower recognition accuracy.And the quantity of characters on different images also affects experiment results.Furthermore,some characters may be mixed together,as shown in Figure 16c,character‘か’and character‘べ’is mixed together,leading the final character recognition result to be incorrect. FIGURE 1 4 Recall,Precision and F‐value of bounding box detection TABLE 3 Top3 and Top1 validation accuracy of character recognition FIGURE 1 5 Top3 and Top1 validation accuracy of character recognition Third,a circled number expressed with Kanji appears in every image leading to poor recognition accuracy.For example,the kanji number‘七十四’circled in Figure 16a.Because there is no training data for this kind of character,they cannot be correctly recognised in character recognition. Finally,annotations still have an impact on the final results in a small number of experiments.On the one hand,certain annotations are judged as characters since they are too close to the text and are not eliminated.On the other hand,in the separate‐merge‐character part,the annotation is blended with the text,which affects the recognition result. Image No.46 has the best recognition accuracy in terms ofRecall,Precision,andF‐value.It can be seen that the detection accuracy of the bounding box has a significant impact on the character recognition accuracy.Then,we investigate the relationship between bounding box detection accuracy and character recognition accuracy.The correlation coefficient of the two factors is 0.42,which indicates that they are significantly correlated.In future research,we plan to refine the detection of bounding boxes to improve the character recognition accuracy.In addition,aiming at the four factors we analysed above that affect the final character recognition accuracy,it would be studied to propose corresponding solutions in the next step. FIGURE 1 6 Examples of incorrectly recognised characters We propose an automatic character recognition system for early Japanese books by utilising image processing and deep learning.The effectiveness of the proposal is verified by the experimental results.The proposal mainly consists of three stages.The first stage is bounding box detection in the image based on image processing.For the two detection difficulties,that is,connect‐character and separate‐character,we put forward targeted solutions so that all of the characters in the image can be correctly detected.The second stage is character recognition by utilising deep learning which has made great success in the field of object recognition.The final stage is visualisation,which depicts the recognition results of the image.In the bounding box detection experiment,the finalRecall,PrecisionandF‐valuereached 79.8%,80.3%and 80.0%,respectively.The finalTop3 average recognition accuracy in the character recognition experiment reaches nearly 70%.The efficiency of our proposal is demonstrated by the experimental results. ACKNOWLEDGEMENT Part of this work was supported by the Art Research Center of Ritsumeikan University. CONFLICT OF INTEREST The authors declare that there is no conflict of interest. DATA AVAILABILITY STATEMENT The data that support the findings of this study are openly available online. ORCID Hengyi Lihttps://orcid.org/0000-0003-4112-72975|STAGE II and III:CHARACTER RECOGNITION AND VISUALIZATION
5.1|Stage II:Character recognition
5.2|Stage III:Visualisation
6|EXPERIMENTATION
6.1|Experiment I:Accuracy of bounding box detection
6.2|Experiment II:Character recognition





6.3|Output of the character recognition system
7|EVALUATION AND DISCUSSION OF THE EXPERIMENTAL RESULTS
7.1|Evaluation


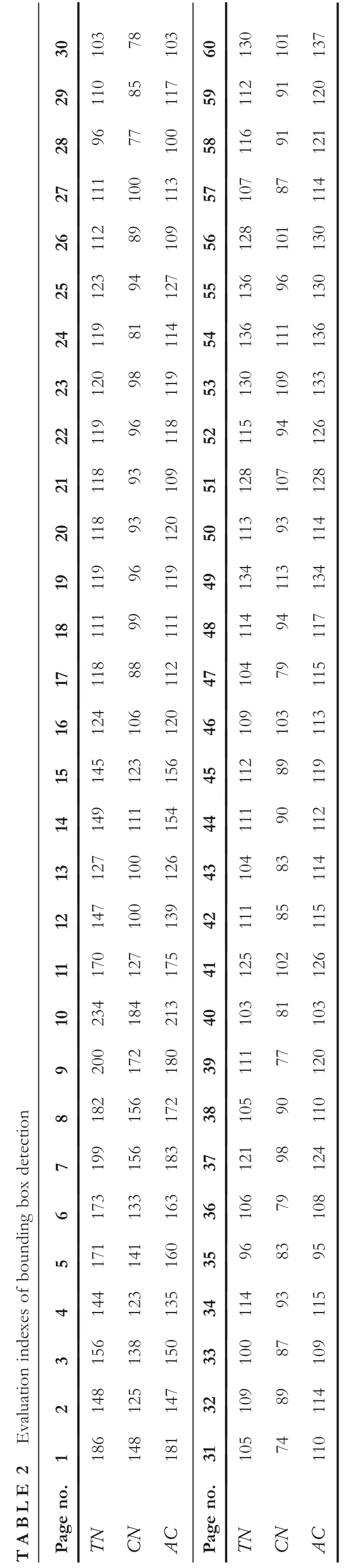
7.2|Discussion
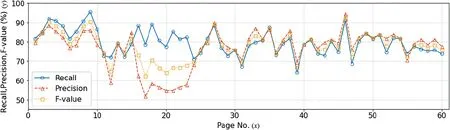
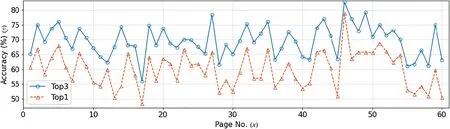

8|CONCLUSION
杂志排行

CAAI Transactions on Intelligence Technology的其它文章
- Modelling of a shape memory alloy actuator for feedforward hysteresis compensator considering load fluctuation
- Apple grading method based on neural network with ordered partitions and evidential ensemble learning
- An improved bearing fault detection strategy based on artificial bee colony algorithm
- Parameter optimization of control system design for uncertain wireless power transfer systems using modified genetic algorithm
- Passive robust control for uncertain Hamiltonian systems by using operator theory
- Humanoid control of lower limb exoskeleton robot based on human gait data with sliding mode neural network