基于显著特征增强的跨模态视频片段检索
2022-12-28杨金福刘玉斌
杨金福 刘玉斌 宋 琳 闫 雪
①(北京工业大学信息学部 北京 100124)
②(计算智能与智能系统北京市重点实验室 北京 100124)
1 引言
视频数据可以对已发生的事情进行2次描述,在情景记录、现场重建等工作中发挥重要作用。通过人工方式在海量视频中查找目标内容,成本较高且效率低下。跨模态视频片段检索旨在通过不同模态的知识协同,在视频中快速找到目标内容,受到越来越多的研究人员关注。
近年来,跨模态视频片段检索研究取得了较大的进展,涌现了许多令人印象深刻的方法。按照检索方式主要分为基于匹配的方法[1–7]和基于视频-文本特征关系的方法[8–12],前者关注候选视频片段与文本特征的匹配过程,而后者则是关注视频和文本特征的跨模态交互过程。
基于匹配的方法,通常使用滑动窗口法预先生成足够多的候选视频片段,然后分别与查询文本比对并计算得分。Gao等人[1]使用3维卷积神经网络(Convolutional 3D networks, C3D)[13]提取候选视频片段特征,使用长短记忆网络(Long-Short Term Memory, LSTM)[14]提取查询文本特征,然后利用加法、乘法和全连接运算将两种模态的特征融合,用全连接网络计算每个候选视频片段的得分。为了充分学习模态内的特征关系,Ge等人[2]在计算得分时考虑了候选视频片段中的活动信息以及查询文本中的主谓关系,使用加法、乘法和拼接操作融合不同模态的特征,并利用多层感知机预测候选视频片段的得分。Liu等人[3]设计了一个文本-视频注意力网络用于学习模态间的特征关系,将视频特征和查询文本特征投影到公共的特征空间,结合视频信息给每个单词分配不同的权重,然后与视频特征拼接,使用多层感知机预测候选视频片段的得分。Zhang等人[4]根据候选视频片段的起止时刻对视频特征编码,设计了一种时间邻近卷积来学习视频片段间的上下文信息,并使用哈达玛积运算将其与查询文本特征融合后,通过卷积网络计算候选视频片段的得分。Ning等人[6]考虑到查询文本指向的内容可能出现在候选视频片段之外问题,提出一种利用注意力机制将视频的全局内容编码到每一帧中的方法。
与上述匹配的方法不同,基于视频-文本特征关系的方法直接预测视频片段的起止时刻。Yuan等人[8]设计了一个多模态协同注意力网络,交替地使用文本特征和视频特征给对方添加注意力,利用全连接网络预测视频片段的边界。Ghosh等人[9]为了提高检索的速度,将视频和文本两种模态的特征在通道维度拼接,使用双向LSTM预测视频片段的起止时刻。Sun等人[10]采用全局-局部的两阶段融合策略进行视频和文本的特征融合,利用两个门控循环单元(Gated Recurrent Unit, GRU)[15]分别预测视频片段的起始时刻和终止时刻。为了学习对象间的特征关系,Rodriguez-Opazo等人[11]设计了一个时空图模型,对视频中存在的对象建模,使用全连接网络生成检索结果。其中,时空图模型具有3个语言节点和3个视觉节点,语言节点包含一个多头注意力机制[16],用于学习3种文本关系:主语-谓语、主语-宾语和谓语-宾语关系,视觉节点分别用于处理人、物体和活动之间的关系。
上述方法的提出推动了跨模态检索领域的不断发展,也验证了注意力机制在跨模态视频片段检索任务中的有效性。借助注意力机制的隐藏层,现有方法可以学习模态内或模态间特征的隐式关系。然而,这些方法缺少对特征显式关系的学习,使得模型的性能无法得到充分的发挥,缺乏直观地解释特征的显式关系和表达特征的差异信息。基于此,本文提出一种新的基于显著特征增强的跨模态视频片段检索方法(Significant Features Enhancement Network, SFEN),通过增强视频的显著特征,提升神经网络对视频语义的理解能力。
2 模型框架
本文研究所设计的模型结构如图1所示,主要包含3个模块:(1) 时间相邻网络(Temporal Adjacent Network, TAN): 学习视频片段的空间关系;(2)轻量化残差通道注意力(Weak Residual Channel Attention, RCA-W):学习视频模态特征的显式关系;(3) 特征融合与视频时刻定位: 融合视频与文本的信息,完成目标视频片段的定位。接下来将对3个模型进行详细介绍。
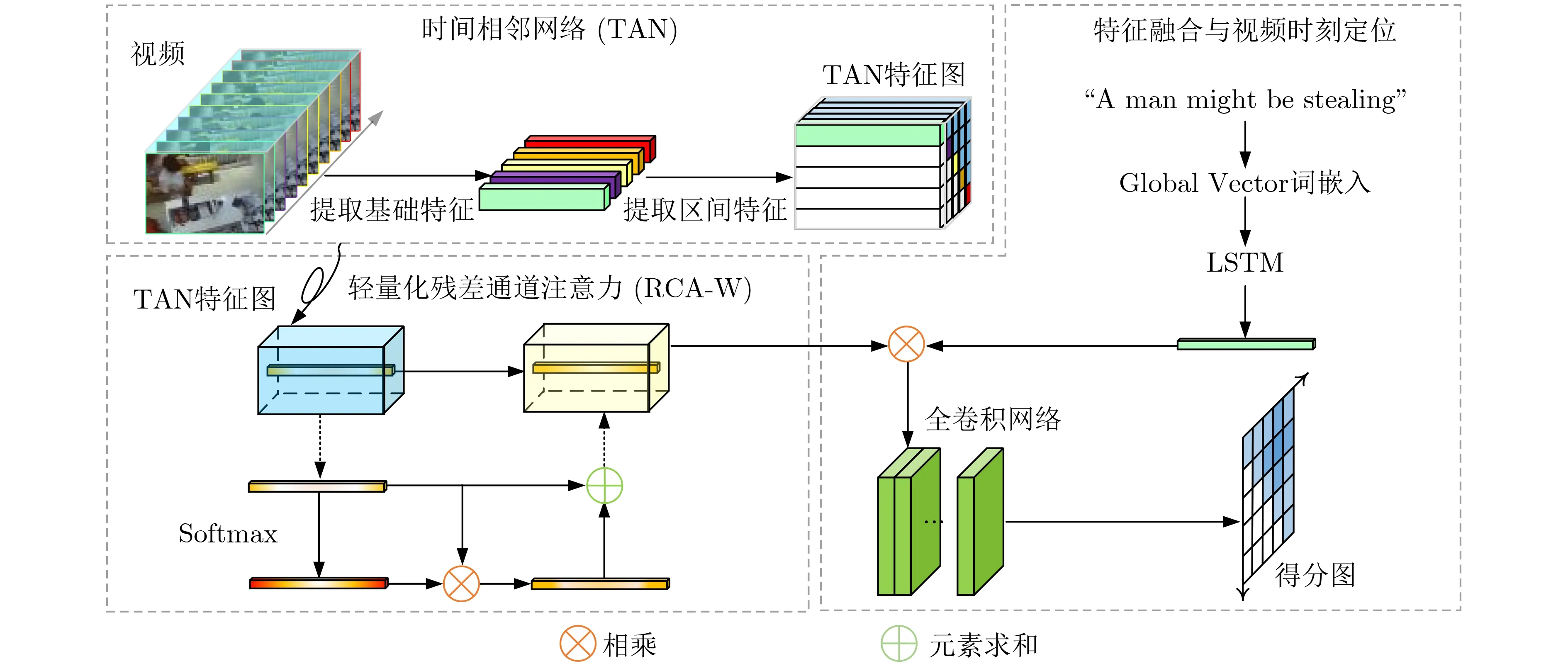
图1 模型整体结构
2.1 时间相邻网络

其中,i∈[0,n −1]代 表视频片段的起始时刻,j ∈[1,n]代表视频片段的终止时刻。由于起始时刻小于终止时刻,所以TAN特征图的左下角为无效区域并以0填充。当输入视频时长为5τ,选取n=5时,根据流程可以构建维度为5 ×5×d的TAN特征图,如图2所示。
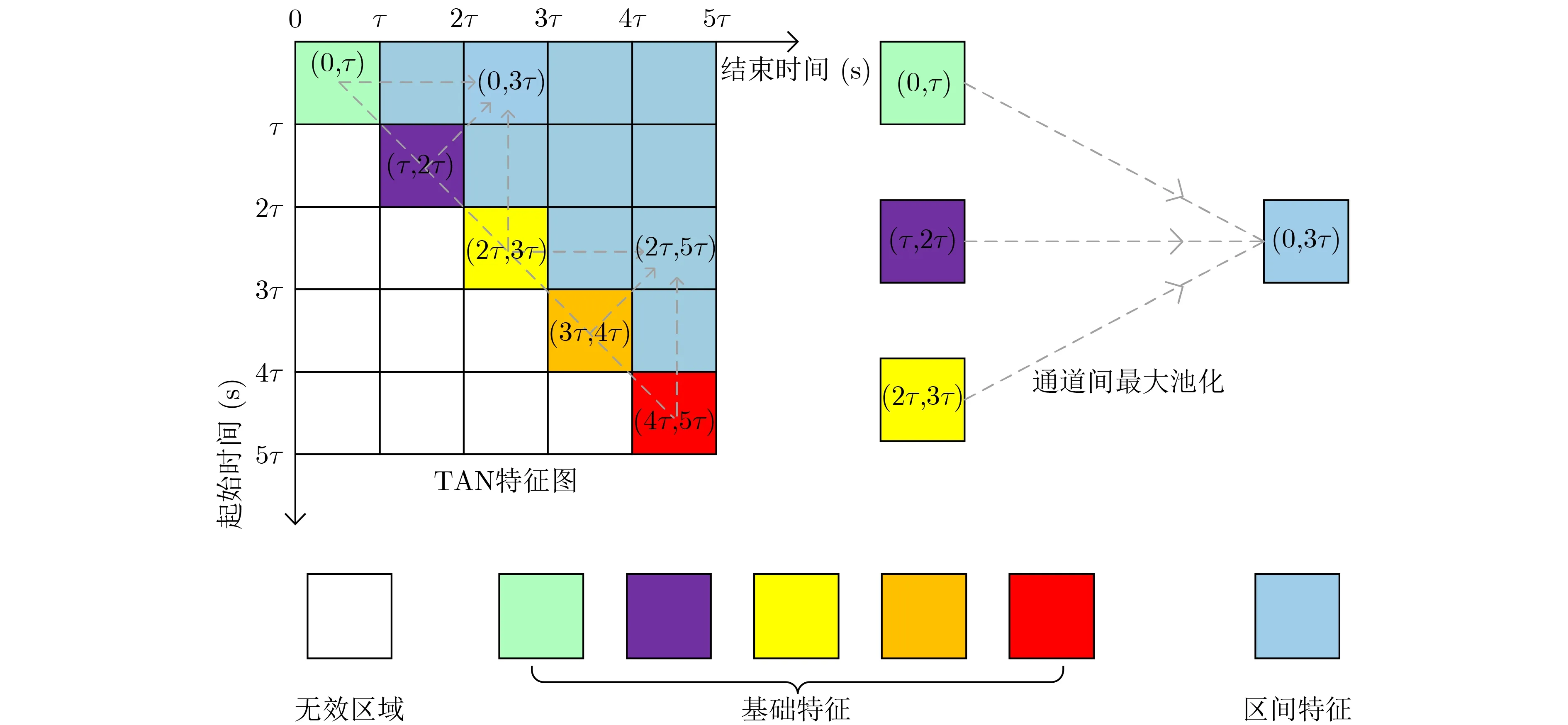
图2 TAN特征图构建示意图(n=5)
2.2 轻量化残差通道注意力
注意力被解释为一种将计算资源分配给具备最大信息量区域的机制,可以学习特征的依赖关系,在深度学习中有广泛的使用。Hu等人[17]提出了挤压和激励模块(Squeeze-and-Excitation, SE),使神经网络能够学习通道间的特征关系。Woo等人[18]提出了卷积注意力(Convolutional Block Attention Module, CBAM),在SE的基础上加入了空间注意力,学习特征的空间关系。Zhang等人[19]提出了残差通道注意力(Residual Channel Attention,RCA),在传统的通道注意力上添加残差连接,以自适应地学习通道的特征关系。Wang等人[20]提出了有效通道注意力(Efficient Channel Attention,ECA),可以无降维地学习局部跨通道交互关系。Wang等人[21]提出了非局部神经网络(Non-local neural networks, Non-local),可以捕获长距离的特征依赖关系。上述注意力机制在模型中额外引入了隐藏层,帮助神经网络学习特征的隐式关系,在目标检测、实例分割等任务中取得了较好的效果。在视频任务中,出于对模型实时性的考虑,本文提出了一种轻量化残差通道注意力RCA-W,在仅增加少量推理时间的情况下,可以学习视频特征的显式关系,提升神经网络对视频语义的理解能力。
RCA-W采用残差网络(Residual Network,ResNet)[22]的恒等映射结构学习特征关系,形式上定义为
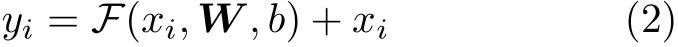
其中,xi ∈{x1,x2,...,xn×n},yi ∈{y1,y2,...,yn×n}分别表示输入和输出特征图的通道信息,F=xi·σ(W xi+b)表 示包含注意力机制的前馈路径,W是路径的权值,b是偏移值,σ是权值分配函数,F+xi表示xi通过恒等映射路径与非线性层的输出直接相加。在式(2)中,xi与F的维度必须相同,否则需要使用线性投影进行尺寸匹配
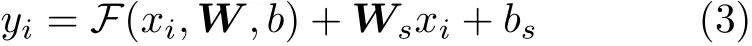
考虑到W,b和σ会增加计算量,影响模型的实时性。于是令W=1(·),b=0(·),σ=softmax(·),得到


2.3 特征融合与视频时刻定位


3 中心交并比
交并比(Intersection over Union, IoU)是一种常用的评价方式,在模型的训练和性能评测中应用广泛。在视频片段检索任务中,IoU计算的是“候选视频片段A”和“真实视频片段Agt”交集与并集的比值
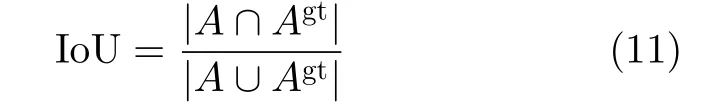
已有研究表明使用传统的IoU参与模型训练时,存在收敛慢和回归不准确的问题,计算交并比应当考虑多方面的几何因素[23–25]。这些工作从不同的角度分析了IoU算法的瓶颈并进行了改进,在目标检测、语义分割等任务中取得了较好的结果。然而,在视频片段检索任务中仍然缺少一种更适用的交并比计算方式。受到上述工作的启发,本文提出一种中心交并比(Center Intersection over Union,CIoU),用于辅助完成模型的训练任务。CIoU在IoU算法的基础上考虑了视频片段中心时刻的位置因素

4 损失函数
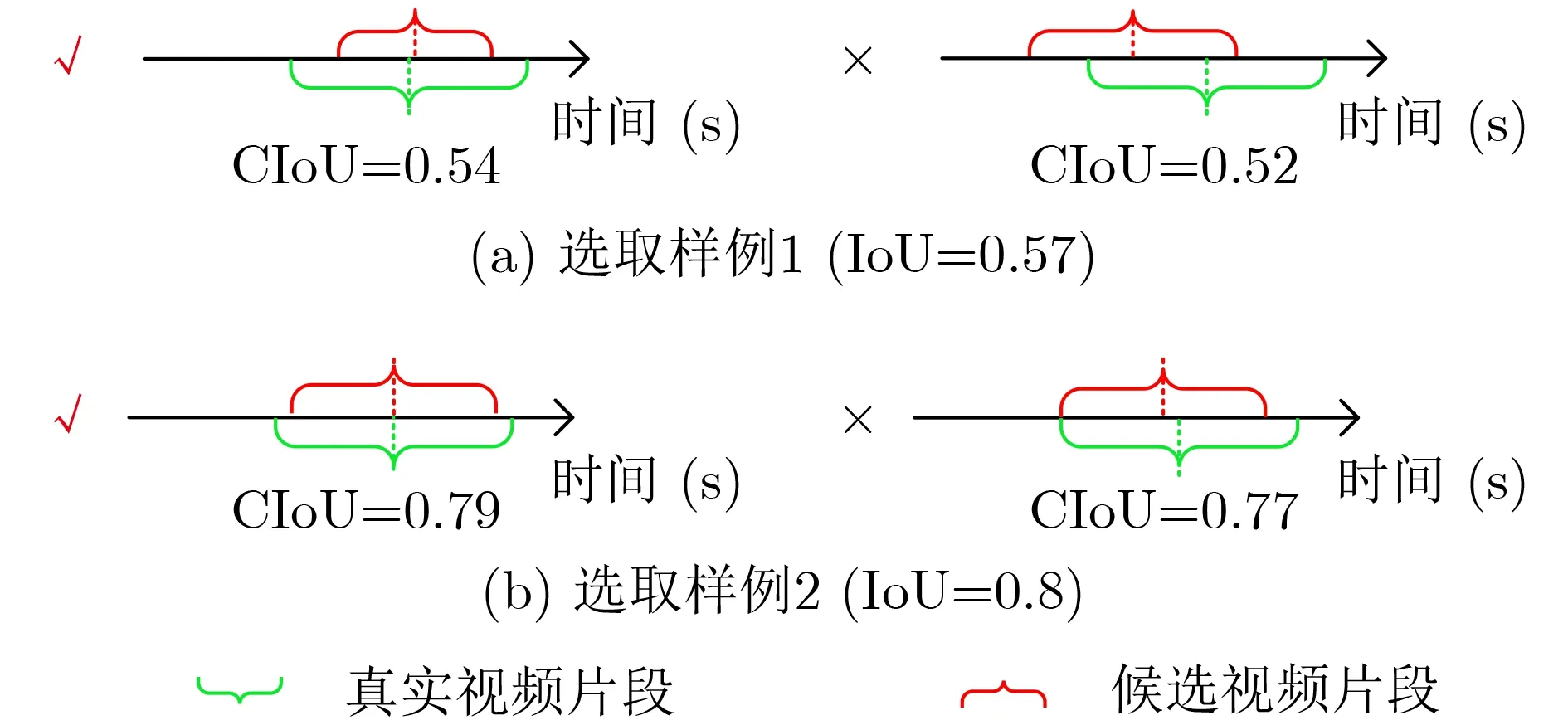
图3 使用CIoU选取候选片段的示意图
损失函数由视频片段定位损失和中心时刻回归损失组成。定位损失参考文献[4]的方法,将预测片段定位到满足IoU阈值的区间。对于每个候选视频片段,与真实片段计算CIoU值oi,使用非极大抑制算法确保作为正样本的候选片段仅与单个描述文本匹配。根据阈值omin和omax,计算这些候选视频片段的得分yi
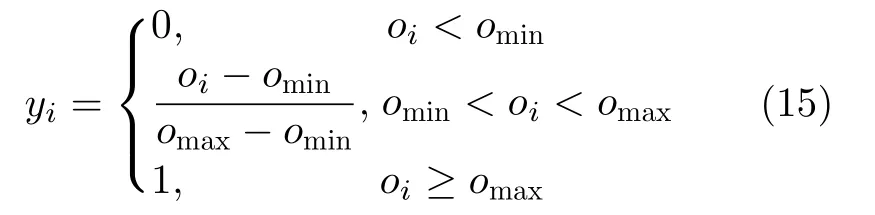
以yi作为监督训练的标签,与模型前向推理的得分pi计算交叉熵损失,作为视频片段的定位损失
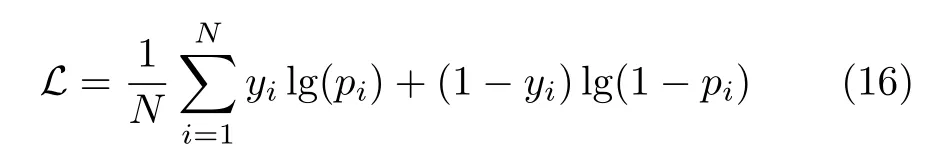
其中,N为候选片段的个数。接着,计算得分排名前k的预测片段与真实片段中心偏差的二范数,得到中心时刻回归损失
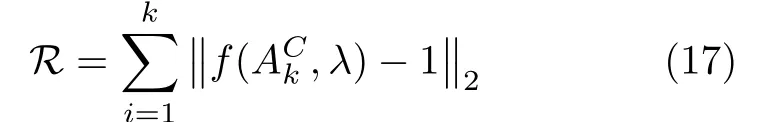
完整的损失函数为两项加权之和
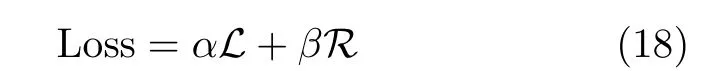
5 实验与分析
5.1 数据集和评估标准
本文在跨模态视频片段检索任务常用的数据集TACoS[26]和ActivityNet Captions[27]上对所提方法进行评估,以便与目前主流的方法进行比较。
TACoS[26]数据集在MPII Compositive[28]数据集的基础上进行构建,该数据集的主要特点是具有固定场景和固定视角,内容为厨房的烹饪行为,存在大量的人体动作。数据集共有127个视频样本,包括训练集、验证集和测试集,分别包含75,27和25个时长不同的视频。每个视频划分了若干个视频片段,与之对应的标注文件标明了视频片段在完整视频中的起止时间、帧数和文本描述。TACoS数据集用于训练、验证和测试的视频片段数量分别为10146,4589和4083。描述文本的平均长度为6.2个单词,视频平均时长287.1 s,每个视频的平均活动次数21.4次。
ActivityNet Captions[27]数据集包含约20000个未剪辑的视频和100000个描述文本,总时长超过了600 h。将数据集划分为训练集、验证集和测试集3部分,分别有10022, 4924和5043个不同的视频。这些视频包括了50000多个视频片段和等同数目的描述文本,平均时长为2 min,带有文本描述的视频片段平均为36 s,是跨模态视频片段检索任务中最大的数据集。
为了公平地评估算法性能,同当前的主流评价方法,使用召回率对模型进行评估:{Rank@n,IoU =m}, 即计算前n项预测结果在阈值IoU =m下的召回率,其中m∈{0.1,0.3,0.5,0.7}。
5.2 实验参数
(1) TAN特征图:在TACoS[26]上实验时,选取n=128 ,构建维度为1 28×128×512的TAN特征图;在ActivityNet Captions[27]上实验时,由于训练集的平均时长相对较短,所以选取n=64,构建维度为6 4×64×512的TAN特征图。
(2) 标签阈值:为了公平验证使用CIoU选取的训练样本更有利于模型训练,样本的监督训练标签采用与基于匹配的方法相同的阈值生成,即在TACoS[26]上的实验设定omin和omax分别为0.3和0.7,在ActivityNet Captions[27]上的实验设定omin和omax分别为0.5和1.0。
(3) 超参数:实验涉及k,α和β3个超参数。模型训练时,计算前k个预测片段与真实片段中心偏差的二范数,作为中心时刻回归损失,在TACoS和ActivityNet Captions上分别设置为1和4;α和β用于调整视频片段定位损失和中心时刻回归损失的权重,在TACoS上分别设置为1.0和0.8,在ActivityNet Captions上分别设置为1.0和0.6。详细的超参数选取流程见5.6节。
5.3 实验细节
在TACoS[26]上实验时,使用文献[29]提供的数据集特征,其中视频特征维度为 1 28×4096,使用1维卷积将视频基础特征的通道调整至512,构建维度为 128×128×512的TAN特征图。使用Global Vector[30]模型对描述文本进行词嵌入,得到300维的词向量,然后使用3层神经元个数为512的LSTM提取文本特征。用于生成得分图的全卷积网络包含8层卷积,前7层为 3 ×3卷积,最后一层为1×1卷积。模型的学习率和训练批次大小分别为0.001和8。
在ActivityNet Captions[27]上实验时,使用文献[30]提供的视频特征和文本标注,其中视频特征维度为6 4×2048。由于ActivityNet Captions[27]中视频的时长相对较短,所以构建TAN特征图时,把128×128 的维度缩减至6 4×64,通道维度使用1维卷积调整为512。训练时,初始学习率设置为0.00025,在第4次迭代时衰减至原来的1/2,其余实验设置保持不变。
5.4 实验结果与对比分析
本文在TACoS[26]和ActivityNet Captions[27]数据集上进行了实验,并与主流的跨模态视频片段检索方法进行了对比。如表1和表2所示,有基于匹配的:时间回归模型(Cross-modal Temporal Regression Localizer, CTRL)[1]、运动感知模型(Activity Concepts based Localizer, ACL)[2]、语言-时间注意力模型(Language-Temporal Attention Network,LTAN)[3]、2维相邻卷积模型(2D Temporal Adjacent Networks, 2D-TAN)[4]、记忆注意力模型(Attentive Cross-modal Retrieval Network,ACRN)[5]、交互聚合模型(Interaction-Integrated Network, IIN-C3D)[6],基于视频-文本特征关系的:协同注意力回归模型(Attention Based Location Regression, ABLR)[8]、全局-局部两阶段融合模型(Multi-Agent Boundary-Aware Network,MABAN)[10]、时空关系模型(Discovering Object Relationship Network, DORi)[11]和分段提议模型(Query-guided Segment Proposal Network,QSPN)[12],以及跨模态哈希方法(Cross-Modal Hashing Network, CMHN)[31]。
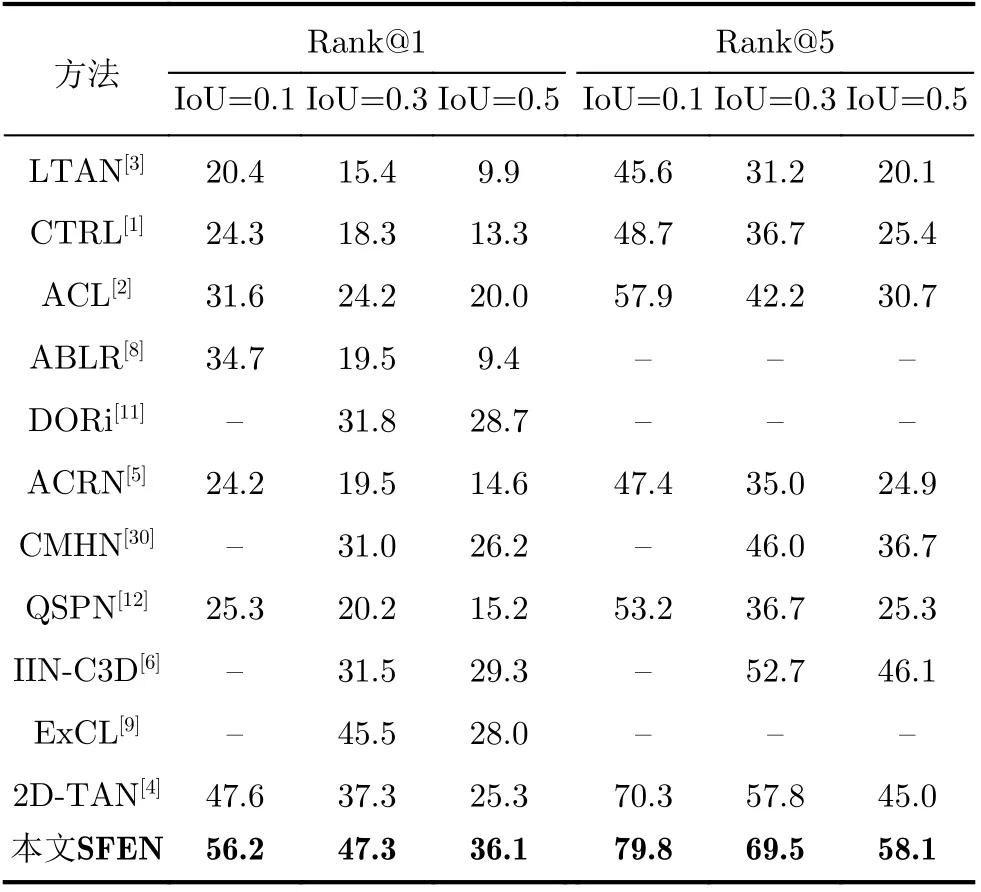
表1 SFEN在TACoS数据集上的召回率
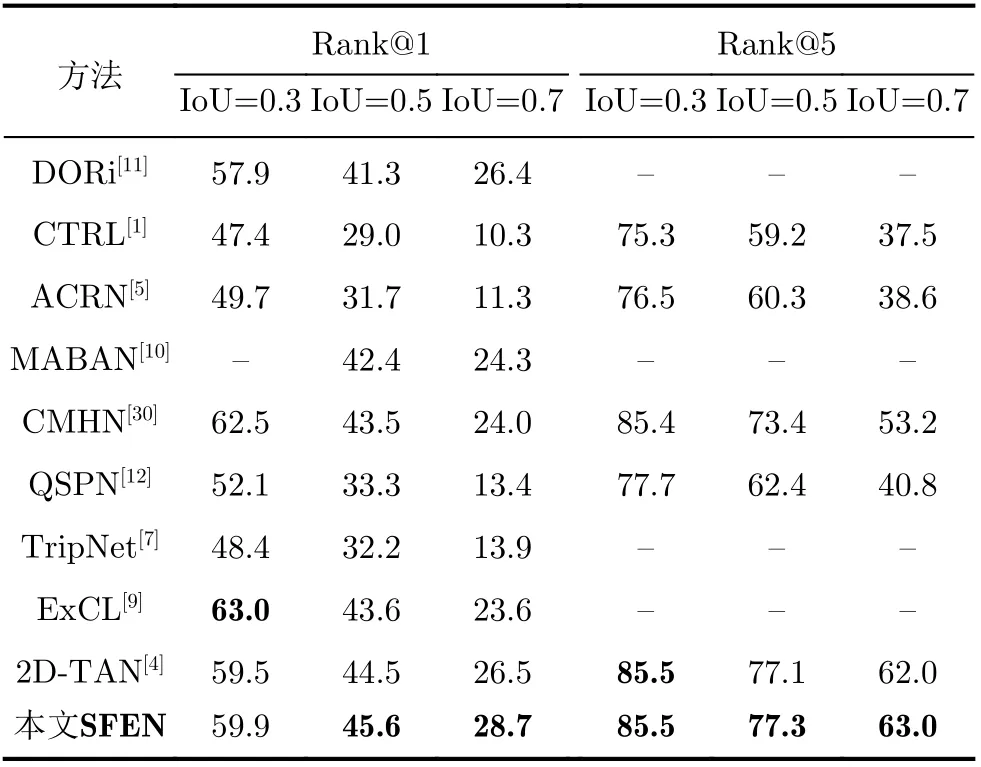
表2 SFEN在ActivityNet Captions数据集上的召回率
首先与基于匹配的方法进行对比,该类方法从预先生成的候选视频片段中挑选得分最高的作为检索结果,使得检索的准确度受到了候选视频片段生成算法的影响,而本方法SFEN可以对检索结果的中心时刻进行调整,此外,本方法还增加了对视频特征的显式关系学习,因此优于该类方法。其次与基于视频-文本特征关系的方法进行对比,结果表明本文方法更优,分析其原因,此类方法通过注意力的隐藏层,学习的是模态内的隐式关系,而本文方法通过所提的轻量化残差通道注意力,还可以学习模态内的显式关系。CMHN[31]方法虽然基于哈希学习,将候选视频片段和查询文本编码成哈希向量投影到汉明空间中,使用汉明距离计算相关度,但其本质仍属于基于匹配的方法,同样受到了候选视频片段生成算法的影响,因此本文方法表现更好。
5.5 消融实验
本节评估了中心交并比CIoU、注意力RCA-W和中心回归损失R对模型的影响。如表3所示,使用CIoU训练的模型具有更好的表现,尤其在IoU=0.7的评估条件下,召回率提升了超过2个百分点。如图4所示,为了与传统的IoU策略对比,训练时将CIoU的λ分别设定为1~5的整数,在多个评估条件下计算模型的召回率。图4绿色曲线表示使用传统IoU策略训练的模型,通过对比可以看出使用CIoU训练的模型具有更高的召回率,特别是当λ=4时取得了最好的表现。接着,分析RCA-W对模型的影响,如表3所示,使用RCA-W的模型在所有评估指标上均有提升,这是因为RCA-W使模型具备学习视频特征显式关系的能力,可以更好地学习视频语义信息。为了验证RCA-W的轻量性,本文对所提方法的时间复杂度和计算量进行了分析,结果如表4所示,其中K为卷积核的大小,Cin和Cout分别为输入通道和输出通道的维度,N为卷积的运算次数,Z为卷积层的个数。此外,当评估指标相对松懈时,中心回归损失R对模型性能的提升也产生了一定效果。

表4 SFEN的时间复杂度和计算量
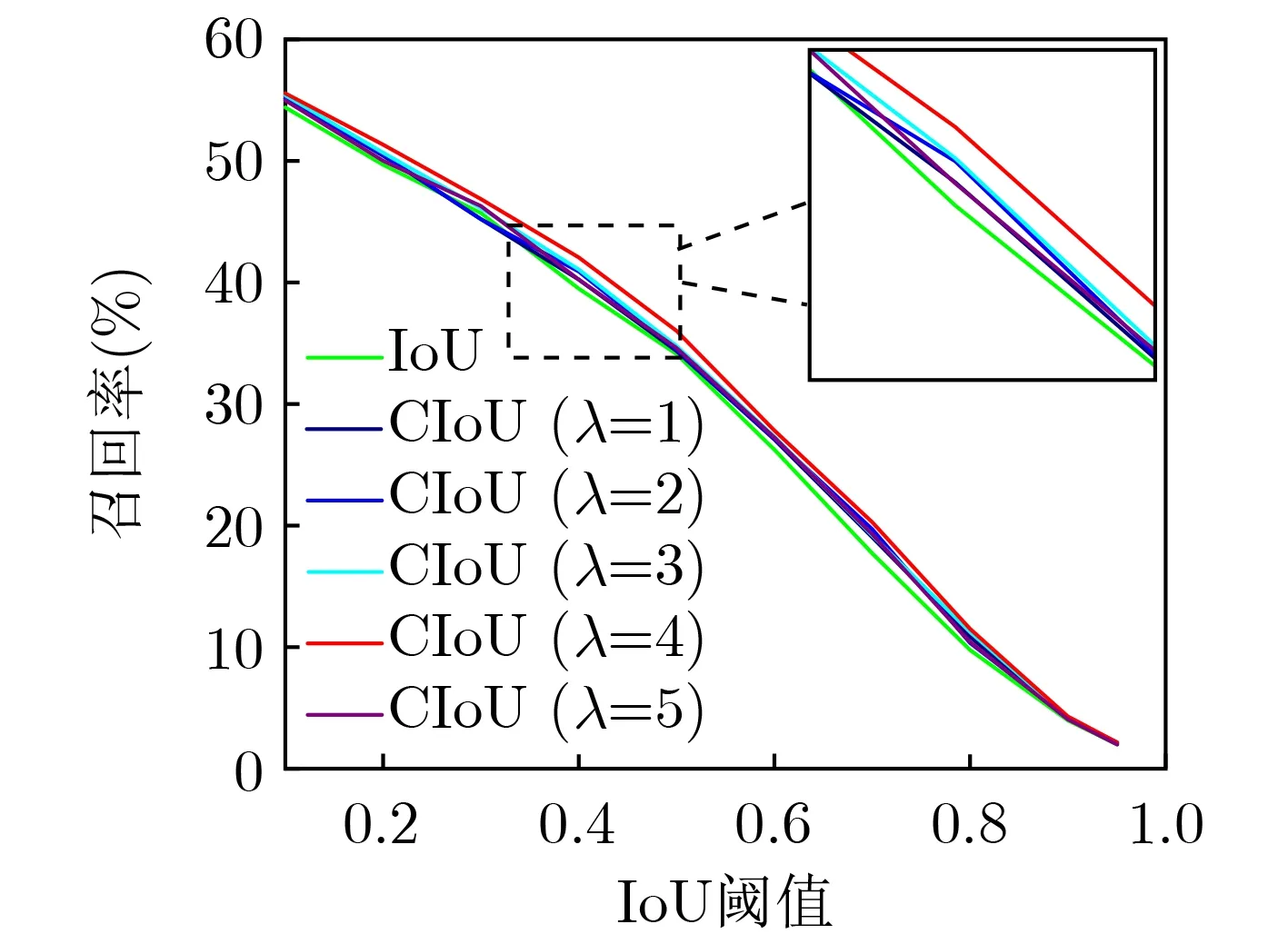
图4 CIoU与IoU的对比实验图(Rank@1)

表3 SFEN的消融实验结果
本文以TACoS数据集为例,将所提的RCA-W与前文探讨的Non-local[21], SE[17], RCA[19]和ECA[20]注意力模型进行了对比实验。如表5所示,RCA-W在召回率、推理时间、模型大小和所需计算量均优于上述模型。首先与Non-local[21]对比,本文的方法更优,分析其原因,Non-local通过计算特征图中两个位置之间的交互捕捉远程依赖,相当于构建了一个与特征图尺寸相同的卷积核,捕捉了全部候选视频片段之间的空间特征,但是这种方式更适用于图像分类、目标检测等任务,在视频片段检索中,感受野过大可能融合较多不相关的视频信息,使模型训练更加困难。与SE[17]相比,本文方法优于SE,原因是SE虽然也关注了通道维度间的特征关系学习,但其侧重于通道特征的隐式关系,而本文方法更注重通道中显著特征的表达,关注特征的显式关系。同样与RCA[19]对比,本文方法表现更好的原因是RCA会在TAN特征图上进行一个全局平均池化,使视频片段融合整个视频的信息,当视频的时间序列较长时,这种方式会产生和Non-local同样的问题,增加模型的训练难度。此外本文方法表现也好于ECA[20],因为ECA是通过每个通道及其相邻区域来捕获局部跨通道交互信息,而本文方法不仅关注了相邻通道间的空间信息,还关注了通道内的特征关系。此外,通过图5可以看出,使用RCA-W学习视频特征显式关系的模型在收敛速度上也优于其他方法。
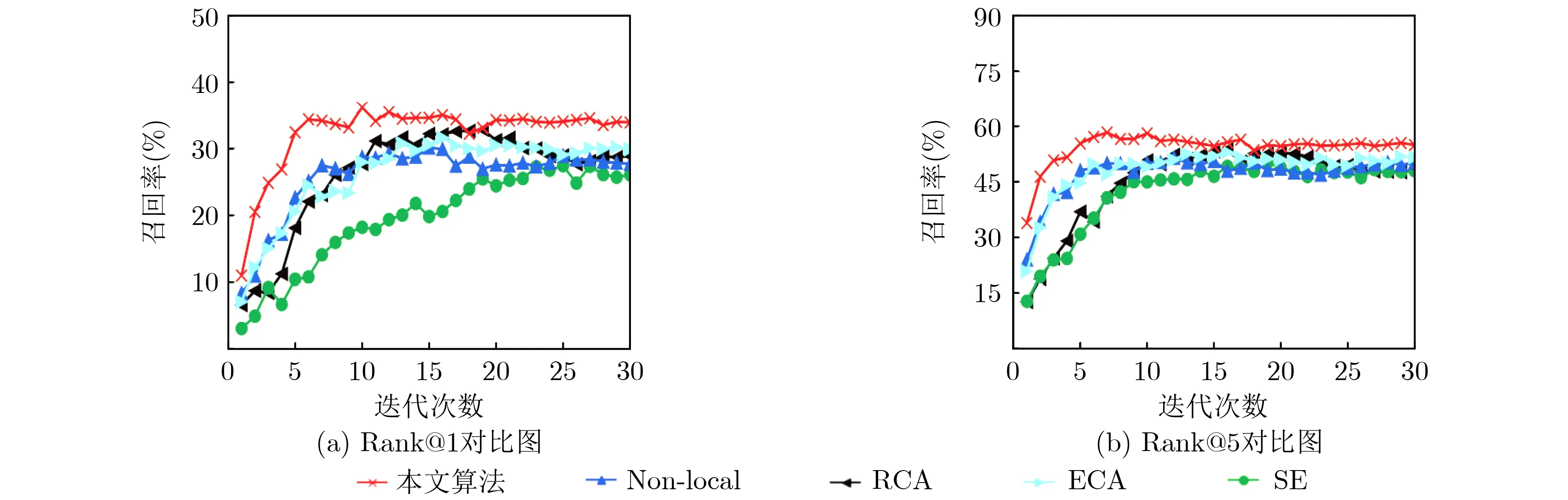
图5 不同的注意力对模型召回率的影响(IoU=0.5)
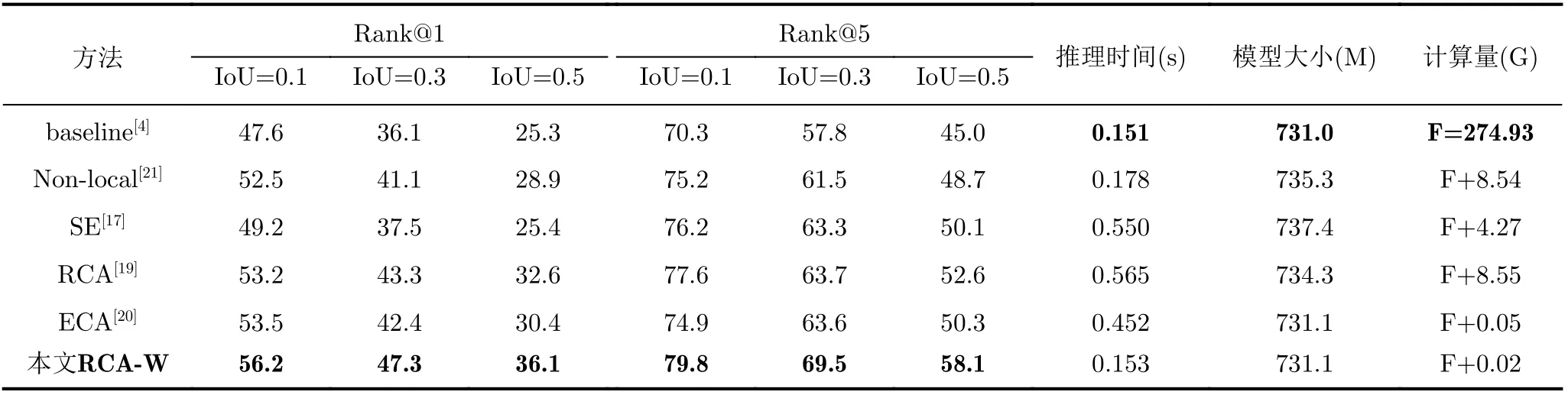
表5 SFEN使用不同的注意力模型在TACoS数据集上的对比结果
5.6 超参数分析
为了探究不同的超参数对模型的影响,本文在TACoS和ActivityNet Captions数据集上进行了超参数实验,通过计算 IoU = 0.5 下的召回率,对k,α和β进行分析。
首先分析k对模型的影响,由于训练过程需要计算得分排名前k的预测片段与真实片段中心偏差的二范数,故将k从1开始选取并依次增加,直至模型的召回率无法提升。在两个数据集上的实验结果如图6所示,其中横坐标表示k值,纵坐标表示模型的召回率。可以看出,在TACoS和ActivityNet Captions数据集上,k分别取1和4时模型取得了最好的表现,而当k>5时,模型在两个数据集上的召回率均出现了持续的下降,说明当k过大时,可能会导致训练的不稳定,影响检索性能。
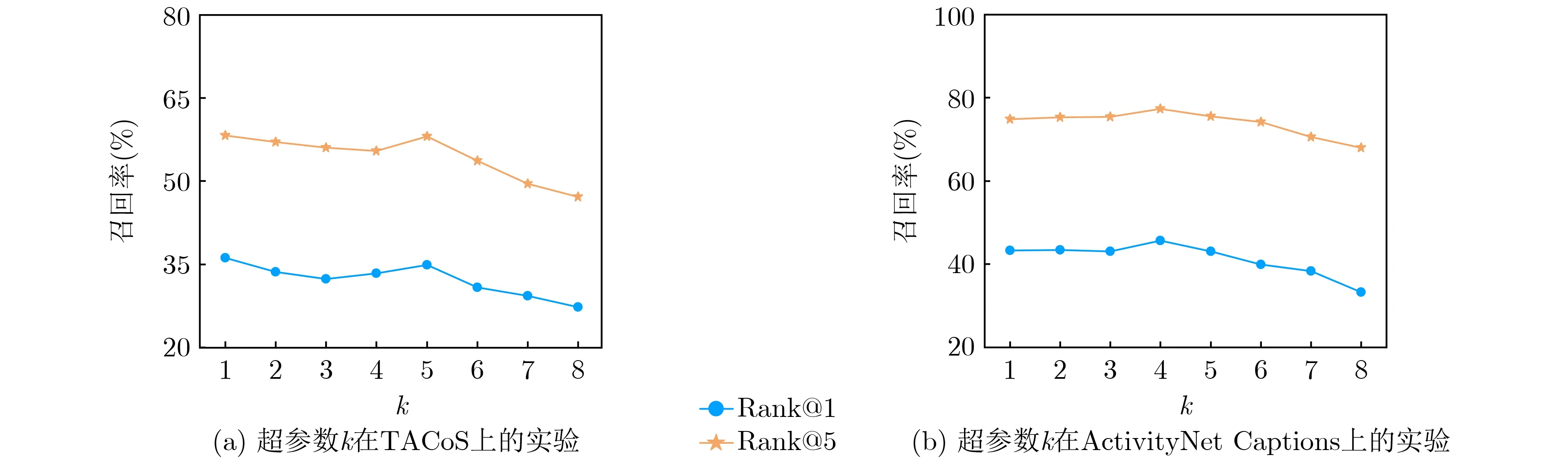
图6 超参数k 对模型召回率的影响(IoU=0.5)
为了探究视频片段定位损失和中心时刻回归损失的不同组合对模型的影响,使用网格搜索法对α和β的选取进行研究。受到GPU的限制,本文将α和β固定在[ 0.4, 0.6, 0.8, 1.0, 1.2]内,在两个数据集上分别进行网格搜索实验。如图7所示,当分别固定α和β并增大另一方时,引起了召回率先升高后降低的波动,说明两项损失均对检索结果产生了一定影响。当模型取得最好的表现时,α和β在TACoS数据集上分别取为1.0和0.8,而在ActivityNet Captions数据集上取为1.0和0.6。上述结果表明,在两个数据集上的参数选取过程具有大致相同的趋势。
5.7 可视化结果
本文将所提方法在TACoS[26]数据集上的部分实验结果进行了可视化,并与基准方法2D-TAN[4]和真实值进行了对比,结果如图8所示,本文方法的预测结果更接近真实值。

图 7 超参数α 和β 对模型召回率的影响(Rank@1 IoU=0.5)

图8 在TACoS上的部分可视化结果
6 结束语
针对现有方法对视频特征关系表达不足的问题,本文提出一种基于显著特征增强的跨模态视频片段检索方法,以TAN网络作为主干框架,学习视频片段的空间关系,然后使用RCA-W学习特征间的显式关系,提升了神经网络对视频语义的理解能力。在通用数据集TACoS和ActivityNet Captions上与当前主流的跨模态视频检索方法进行了对比,本文方法取得了最好的表现。此外,利用消融实验将所提的RCA-W与多个注意力模块分别从召回率、模型大小、推理时间和计算量4个方面进行了比较,证明了所提方法的优越性。虽然本文的方法在公开的数据集上取得了较好的性能,但是要应用在现实场景中还需进一步探索,下一步将围绕如何提升模型的泛化性能进行研究。
