基于子图同构的Hive数据操作合规分析方法
2022-12-28陈兴蜀罗永刚袁道华
陈 丽 陈兴蜀 罗永刚* 杨 露 袁道华
①(四川大学软件学院 成都 610065)
②(四川大学网络空间安全研究院 成都 610065)
③(四川大学计算机学院 成都 610065)
1 前言
随着大数据技术的发展和应用,应用程序(App)和网站利用大数据平台来存储和处理收集的个人信息。海量个人信息在大数据平台上汇聚的同时,数据违规使用导致隐私泄露的风险加剧。近年隐私泄露安全事件频频发生,如在未经用户事先同意及未提供充分信息的情况下,亚马逊欧洲公司通过Azmazon.fr网页在用户电脑中放置用于广告目的的数据(Cookies),被法国国家信息自由委员会(France''s National Commission for Information technology and civil Liberties, CNIL)限制委员会处以3.5×106欧元的罚款;以及2018年7月9日至10日,VDAI发现由于立陶宛支付公司 (MisterTango)技术和组织措施不足,支付数据可在网上公开获得,导致来自不同国家的12家银行的 9000 笔付款受到了影响。以上案例的隐私泄露不仅对个人造成伤害,也对企业名誉和财产造成了严重的损失。所以各个国家出台法律[1]保障个人信息的安全,如我国的《中华人民共和国网络安全法》和GB/T 35273–2017《信息安全技术 个人信息安全规范》(以下简称《信息安全规范》)、欧洲的《通用数据保护条例》等等,对个人信息的收集使用提出了要求。在大数据环境下,数据使用的合规性分析可以帮助企业满足国家关于数据安全相关法律的要求和降低个人隐私泄露的风险,因此针对大数据平台下的数据使用的合规性研究是十分有意义的。
目前大数据审计方法主要分为3类:信息技术(Information Technology, IT)内部审计方法[2,3]、传统审计方法、基于大数据审计[4–7]的方法以及基于全球万维网(World Wide Web, WWW)信息的审计方法[8–14]。IT内部审计方法,解决了关系数据库审计功能相对较弱的问题,通过审计规则来对数据库操作进行约束,且提供了带界面的程序方便审计人员操作审计记录和审计规则,但存在性能较低、对审计人员的关于计算机的专业知识要求较高等问题。传统的审计方法分为基于触发器的审计、基于日志的审计[15,16]。其中基于触发器的审计主要用于关系数据库,需要开发人员设计并开发相应的审计语句,可重用性较低且只能对部分操作进行记录,范围不全。而基于日志的审计方法,存在只能对特定的操作类型进行审计、数据库日志文件本身存在被篡改的风险以及日志冗余性较高等问题,难以体现审计信息的有效性和公平性。基于Web信息的审计方法,是将数据溯源机制应用在审计的过程中,对起源事件及其与使用策略的一致性进行建模,将起源记录建模为离散事件序列,而将使用策略建模为元组,并且考虑了派生、链接和时间方面的隐私政策。但是上述方法只适用于Web信息系统,不适用Hive。文献[14]将结构化查询语言(Structured Query Language, SQL)解析的逻辑计划进行简化,通过数据溯源进行合规分析,但它的审计范围并不完全,缺乏对数据使用目的和数据最小化的合规验证。
大数据治理框架主要使用两大组件 Apache Falcon和Apache Atlas。其中Apache Falcon主要对数据进行生命周期管理,涉及的过程有数据采集、数据处理、数据备份以及数据清洗,但缺乏数据审计。Apache Atlas实现大数据平台的数据安全和隐私保护,但存在只能对修改元数据的操作进行审计的问题。Apache Ranger提供集中管理的安全策略并监控用户的访问,是一个集中式安全管理框架,能够对数据平台的数据库进行细粒度的数据访问控制,解决了授权问题和审计问题。但存在无法从审计信息中直观看出数据的来源和整个演变过程,和无法直接根据合规要求对数据进行合规性检查的问题。
因此,大数据平台下的审计工作主要存在缺乏对数据使用目的和数据最小化的合规验证问题。Hibernate查询语言(Hibernate Query Language,HQL)无法直接进行合规分析,现有的规则(如访问控制)无法表示数据的使用目的和数据操作是导致这个问题的主要原因。
为了解决以上问题,本文提出一种基于子图同构的合规验证。本方法能够根据具体的业务场景制定满足其安全需求的审计方案,实现数据仓库Hive的审计。本文的主要工作及贡献如下:
(1)提出一种基于有向图来描述数据使用合规的表示方法,从而可以通过数据溯源图与子图同构算法实现数据合规验证。
(2)提出子图同构的合规验证方法,实现数据使用合规的自动判断,相比于其他合规算法,它对图匹配顺序进行了优化且算法复杂度较低,有较高的性能。
(3)针对普遍关注的数据使用范围合规、处理方式合规、权限合规、目的合规等问题,在Apache Atlas溯源平台上进行了实验验证。
2 Hive的合规验证模型
为了实现对Hive数据操作的合规验证,本文首先对《信息安全规范》[1]中的原则和要求进行分析,归纳出数据安全合规规则中包含的合规要求,其中包括数据使用范围合规、处理方式合规、权限合规、目的合规,然后定义了合规验证模型来实现Hive的合规验证。
2.1 合规要求
《信息安全规范》中定义了个人信息安全基本原则和使用个人数据必须满足的要求,引入了审计私有数据处理。本文对其中原则和要求进行分析,得到以下合规要求并对其功能进行说明如表1所示。

表1 合规要求及其功能说明
安全管理员根据上述合规要求为Hive中个人数据使用创建相应的合规规则。
2.2 合规验证模型
为了从数据使用范围合规、处理方式合规、权限合规及目的合规4个方面对Hive数据操作进行合规验证,本文提出了基于子图同构的合规验证方法。Hive的合规验证模型如图1所示。
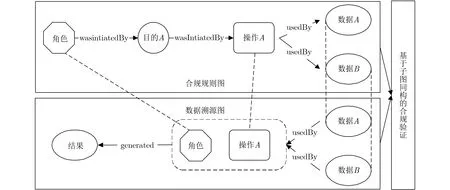
图1 Hive的合规验证模型
2.2.1 数据溯源图
数据溯源图[17]将需要进行合规验证的HQL转化为图,并描述了数据处理过程。对数据溯源图定义如定义1所示。
定义1数据溯源图可以使用4元组表示,G(V,E,R,A)是一个由顶点、边、边标签和属性构成的有向无环图,其中各组成元素具体的定义为

V表示点的集合,其中DU, OP, DR分别表示使用数据顶点、操作顶点以及结果顶点的集合,OP表示点的集合。E表示边的集合,另外R是指边标签类型的集合,包含了u sedBy 和 g enerated两种类型的标签。其中u sedBy表示对数据执行了某种操作,建立了使用数据与操作之间的关系。g enerated表示一个结果数据产生的过程,建立了操作与结果数据之间的关系。A表示溯源图中顶点和边包含的属性,其中g uid 表 示实体或关系的唯一标识,n ame表示实体的名称, typeName表示顶点或边的类型,createTime 表示创建时间,c reateBy表示创建者,version表示创建版本。
2.2.2 合规规则图
对数据操作的合规性检查是基于合规要求进行判定的,为此如何表示合规要求是实现合规验证的前提。本文使用合规规则图来描述合规规则。下面对合规规则图中的实体和实体间的关系进行定义。
定义2角色(Role),表示合规规则中信息主体授权的数据操作参与者,其能出于某种目的、方式、范围以及规则等对信息主体的数据进行操作。

定义3目的(Purpose),表示角色执行数据操作的行为意图。
定义4数据(Data),表示数据操作过程中的操作实体,并且这种数据操作满足某种目的。例如在统计目的下,可以对Hive的表、列等进行处理。
定义5操作(Process),表示数据操作过程中可以对数据使用具有某种目的的运算,例如为了对学生成绩进行分析时的求平均值、最大值等操作。
定义6依赖关系(Dependence),表示各个实体之间的关系。包括目的与使用数据之间的关系、使用数据与操作之间、角色与目的之间的关系。
本文使用有向无环图来表示合规规则图,其中顶点表示目的、角色、数据及操作,边表示目的与使用数据的关系、使用数据与操作的关系及角色与目的的关系。对合规规则图定义如定义7所示。
VR表 示顶点的集合,其中PR表示目的顶点的集合,DuR表示使用数据顶点的集合,O PR表示操作顶点的集合, R oleR表示用户角色顶点的集合,VR至少包含R oleR。ER表示边标签类型的集合,它可以为空,即不授予用户权限。RR表示边标签类型的集合。图中边有两种类型:一种类型是w asInitiatedBy,表示由特定目的发起的一组操作或某种目的下进行的数据操作,建立了角色和目的、目的与操作之间的关系;另一种类型是u sedBy,表示对数据执行了某种操作,建立了数据与操作之间的关系。AR表示合规规则图中顶点和边包含的属性,其中g uid表示实体或关系的唯一标识, name表示实体的名称,t ypeName表 示顶点或边的类型,c reateTime表示创建时间,c reateBy 表示创建者,v ersion表示创建版本。
例如角色被授权在目的A下只能对数据A和数据B执行操作A。产生的合规规则图如图2所示。

图2 合规规则图示例
2.2.3 基于子图同构的合规验证
基于上述数据溯源图和合规规则图构建,本文将数据合规验证问题转换为图匹配问题。由于VF3[18]算法能够解决图同构问题,且相比VF2[19]算法、Ullmann算法[20]做了图匹配顺序优化,因此本文在VF3算法基础上提出基于子图同构的合规验证。它将数据溯源图按照使用数据拆分为多个子图,分别与对应的合规规则图进行子图匹配,根据是否对数据溯源图中的所有节点匹配且目的标签是由一致,判断是否合规,最终实现个人信息的合规验证。基于子图同构的合规验证算法如表2所示:其中 V F3 表示V F3 子图同构算法,GR表示规则图,A1表 示查询出并展示的溯源图,M(s)表示规则图与数据溯源图匹配的部分,O Pi表 示第i个溯源图中的操作操作 1≤i ≤n,其中n表示溯源子图的个数,G−A1表 示剩余的数据溯源图,Ai表示数据溯源子图, PUMAP 表示图与目的对应关系。GR1表示涉及当前使用数据相关的规则信息。

表2 基于子图同构的合规验证算法
第1步,将数据溯源图和合规规则图作为VF3算法的输入进行子图匹配,获得匹配的节点集合M(s) 。第2步、第3步,若M(s)为空说明用户身份不验证(第22步),终止流程;若M(s)为1说明操作和用户身份验证不合规(第19步、第20步),终止流程;若M(s)中包含数据溯源图中所有节点,则获得目的A,第(8)步,若溯源图只使用一个数据,则说明目的合规终止流程,否则继续。第(6)~(17)步,将其余溯源图与合规规则图进行匹配,如果溯源图中所有图都能够被匹配,且目的相同,则说明目的合规,反之说明不合规。
3 Hive合规分析系统
为了验证本文所提合规验证方法,本文针对Hive中的数据设计了如图3所示的合规验证系统架构。系统主要包含以下模块。
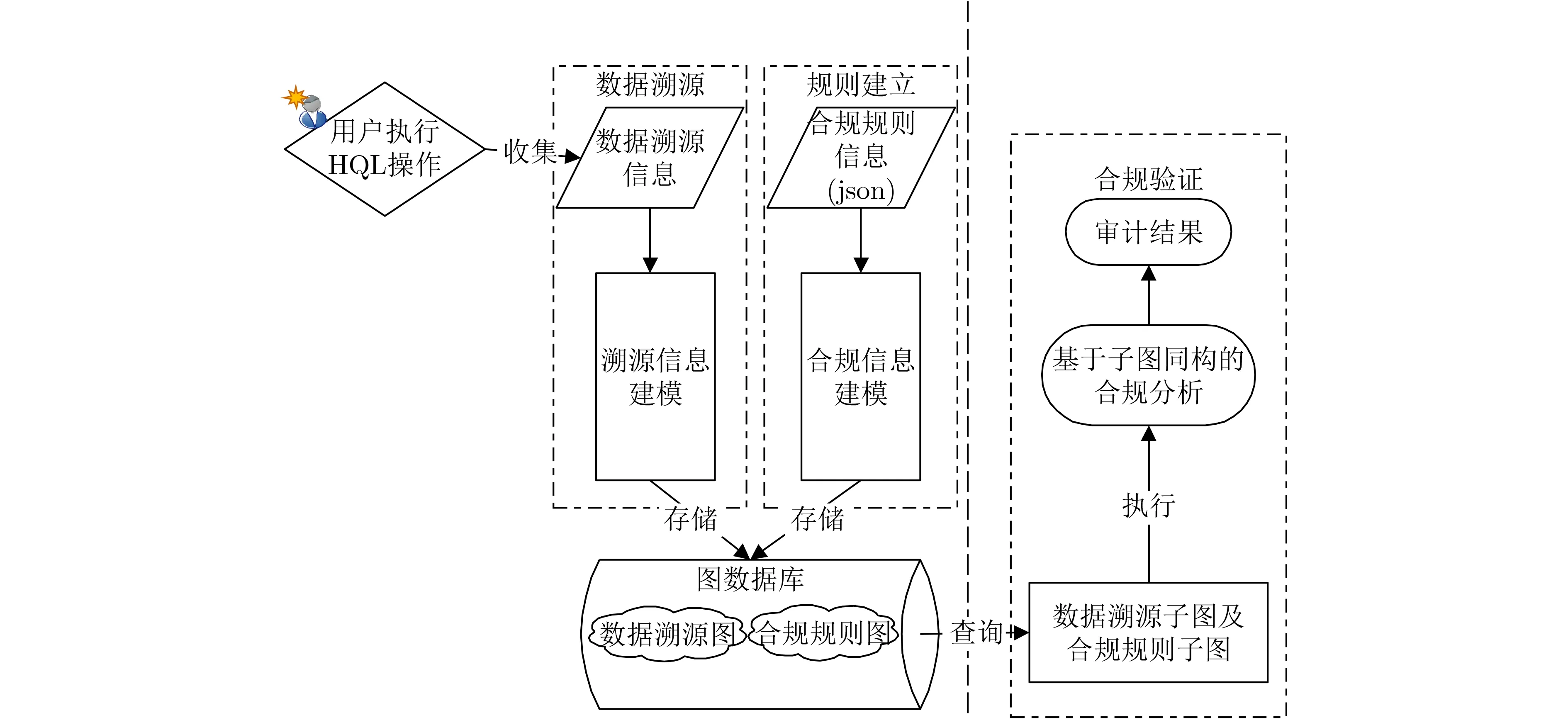
图3 合规验证系统架构
(1) 数据溯源。用户对Hive中的数据执行操作处理之后,数据溯源模块收集溯源信息,并通过溯源信息建模转化为数据溯源图,然后持久化存储在图数据库中。
(2) 规则建立。安全管理员事先根据合规要求在JS 对象简谱(JavaScript Object Notation,JSON)文件中制定合规规则,实现规则的批量导入。规则建立模块对导入的规则进行合规信息建模,转化为合规规则图并存储在图数据库中。
(3) 合规验证。事后当安全管理员查询数据的审计信息时,合规验证模块根据查询数据获得数据的溯源图,利用子图同构算法对数据溯源图进行合规分析,最终将合规分析结果以可视化的形式返回给安全管理员,产生审计结果。
图3显示了对数据操作的审计及合规管理的实现原理与流程。该架构利用数据溯源实现对数据操作的审计,并且支持安全管理员根据法律法规、行业规范等合规要求制定合规规则。通过合规验证模块对数据处理过程进行合规性分析,并将合规结果返回给安全管理员,有助于安全管理员及时发现违规的数据操作并提早解决。
4 实验与分析
4.1 实验环境
为了实现基于子图同构的Hive数据操作合规验证,实验中使用了4台物理服务器搭建海杜普(Hadoop)集群,包含1台主节点和3台从节点。另外配置了1台Mysql服务器作为Hive的元数据存储库。5台服务器配置为Intel(R)Xeon(R)CPU E5-2680 V4 @2.40 GHz的CPU和200 GB内存。
本文使用事务处理性能委员会-决策支持(The Transaction Processing performance Council- Decision Support, TPC-DS)基准对提出的方法进行有效性和性能分析。由于本文所提合规分析方法主要出于保护用户个人信息的目的,因此只对TPCDS基准中描述用户个人信息的顾客(Customer)、顾客地址(Customer_address)、顾客人口统计(Customer_demographics) 3张表制定了使用的合规规则,如表3所示。这些规则是TPC-DS所有查询语句使用这3张表合规性的依据,写在Json文件中,作为合规验证实验的输入。
4.2 有效性测试分析
为了对本文所提方法进行有效性验证,分别以用户root1, root2, root3身份各提交33条查询语句(query1-33, query396, query67-99)。执行查询语句查看审计结果就可以得知数据操作的合规性。即是否满足表3的合规规则。获得的结果如图4所示,图中的合规验证结果均由人工逐条对查询语句进行分析验证,证明系统合规判定结果都是正确的。
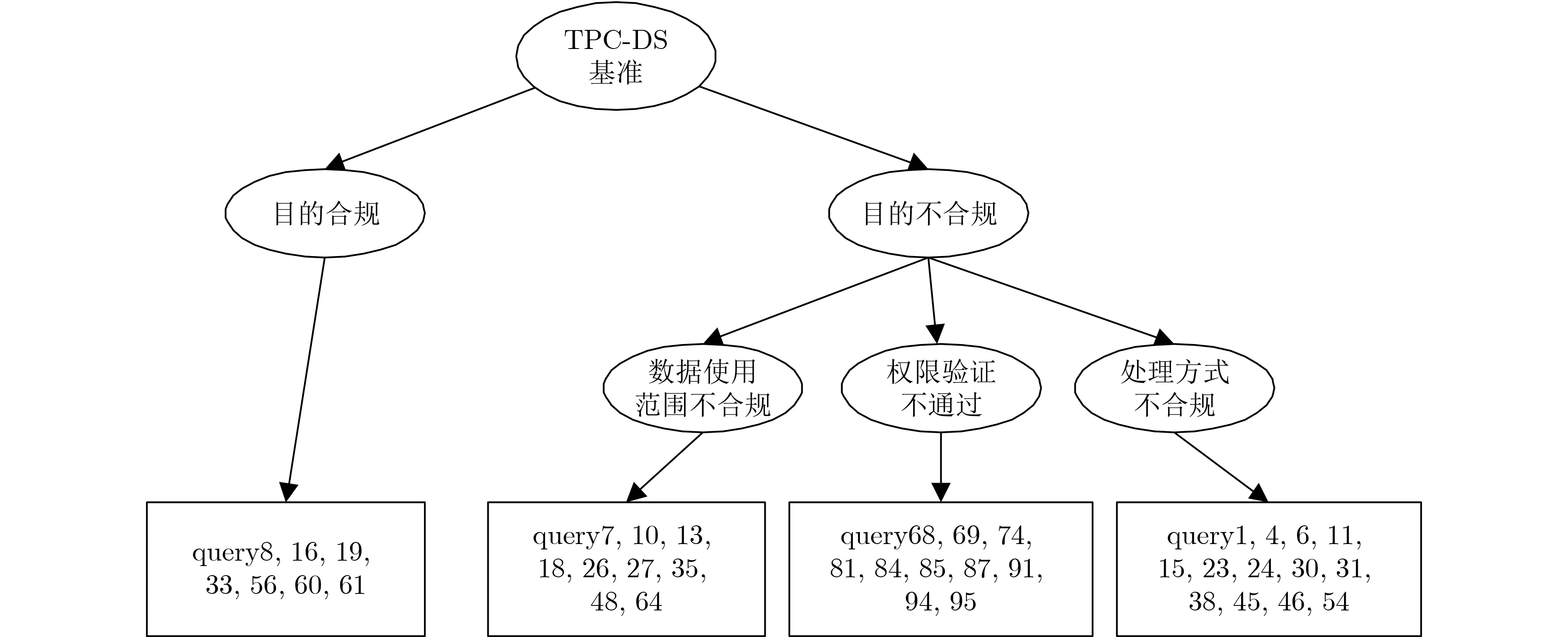
图4 合规验证结果统计
(1)数据使用范围合规验证结果。所有的用户提交的99 条查询中共有9条查询存在数据使用范围不合规的情况,如图5所示的query35,访问了表Customer_address,超过了表3的合规规则2定义的数据范围Customer, Customer_demographics,因此判定为数据使用范围不合规。
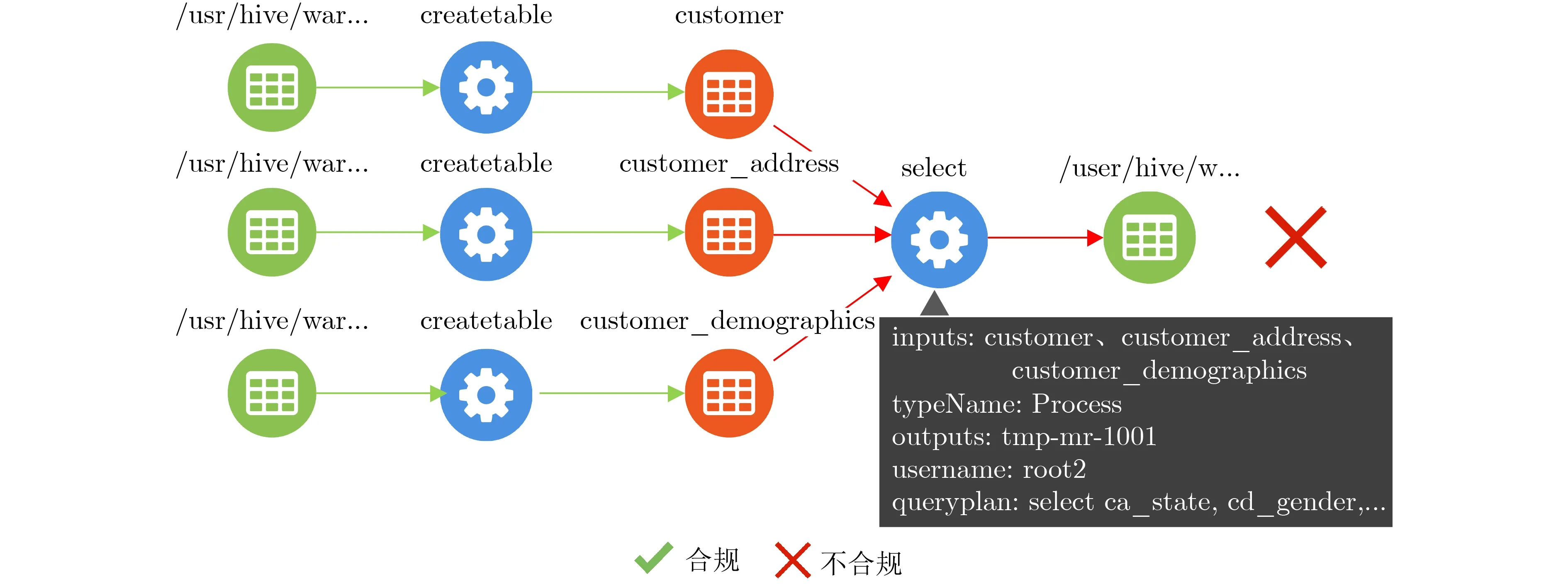
图5 query35查询的合规结果

表3 合规规则信息
(2)处理方式合规验证。所有的用户提交的99条查询中共有13条查询存在处理方式不合规情况。
如图6所示的query6的对表customer以及customer_address执行了select操作,但合规规则1中授权对表customer以及customer_adderss的操作是rank, avg, sum, count, substr,超过了允许的操作范围,因此判定为处理方式不合规。
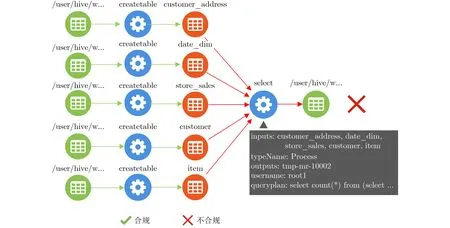
图6 query6查询的合规结果
(3)权限合规验证结果。所有的用户提交的99条查询中共有10条查询存在权限不合规情况。合规规则中只允许了root1和root2访问和处理3张表,因此由root3用户提交的query94被判定为权限不合规,如图7所示。
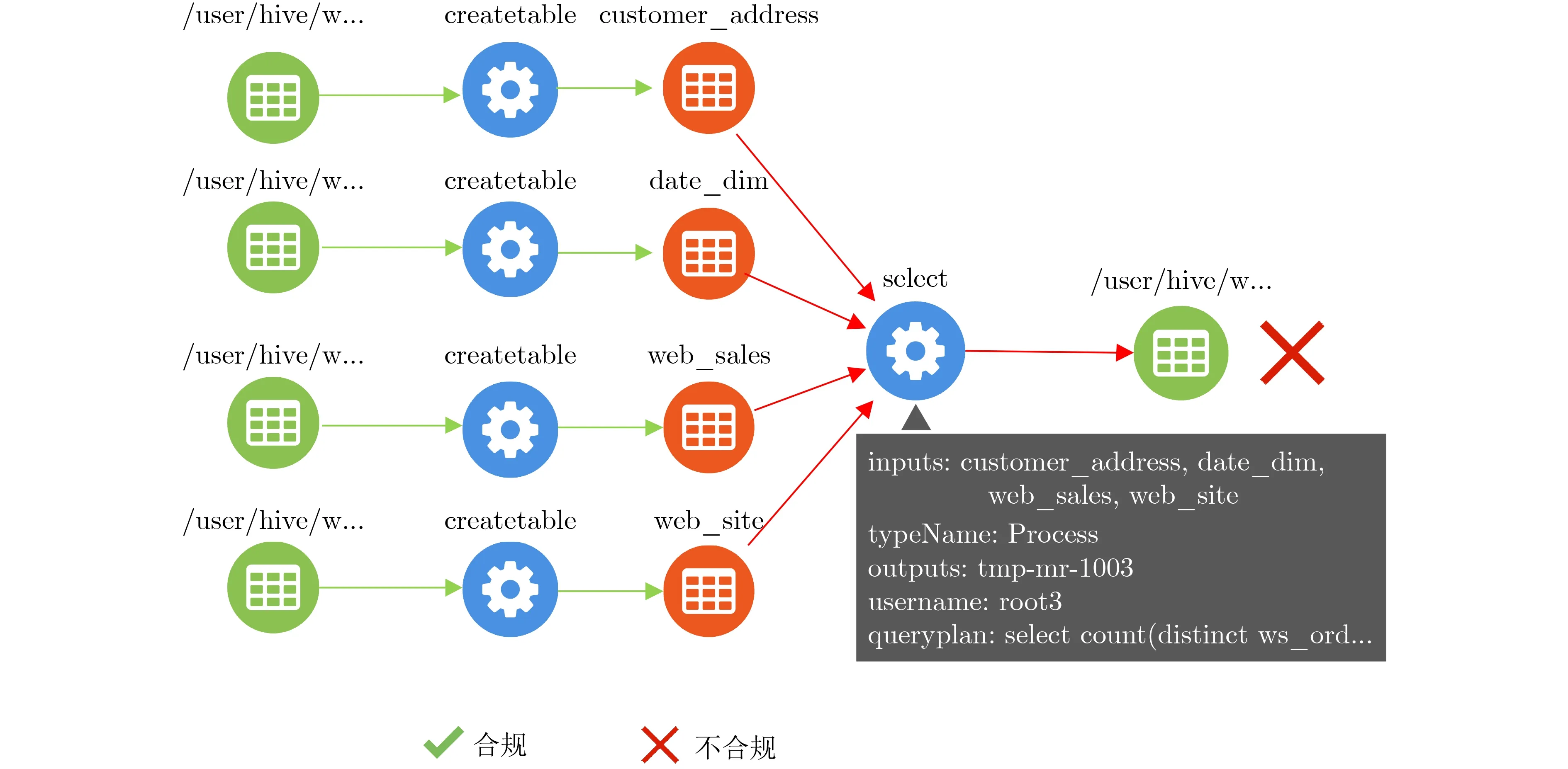
图7 query94查询的合规结果
(4)目的合规验证结果。所有的用户提交的99条查询中共有7条查询目的合规,如图8所示,由root提交的query16对customer_address执行count操作,与合规规则1中定义的角色、使用数据范围和操作都一致,即query16符合StatisticalAnalyse的数据使用目的,因此这条查询被判定为目的合规。
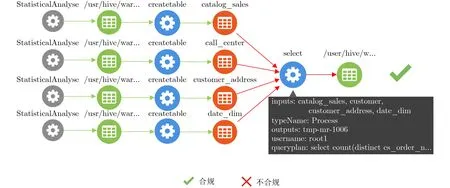
图8 query16查询的合规结果
4.3 性能测试分析
为了测试本文所提基于子图同构的合规验证方法对性能的影响,本文首先对合规验证时间开销进行测试,然后基于子图同构的合规验证与其他的合规验证方法时间开销进行对比实验分析。
4.3.1 合规验证时间开销测试
实验分为6组,单表HQL记录数据量从500~20000条,数据库数据量从10000~400000条。对加入合规验证前后同一数据表进行合规验证以获得其审计信息的时间。实验结果如图9所示,与未加入审计相比,加入审计所带来的额外时间消耗较少。经过统计,合规分析时间占整个溯源和合规验证过程的0.07%左右。对实验进行分析,相比于原有的系统只是增加了图算法过程,而图算法执行效率较高,故加入审计所带来的额外时间消耗较小。
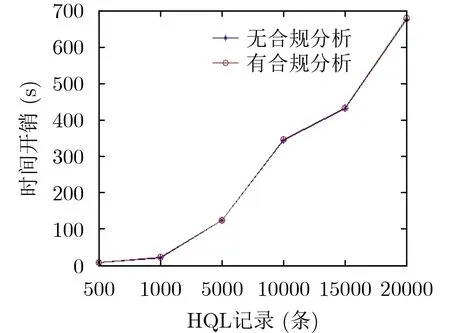
图9 加入合规分析前后的溯源时间开销
4.3.2 不同方法的合规验证性能对比
首先设置了6组实验测试不同大小的合规规则图对同一数据溯源图的匹配时间的影响,其中合规规则数从100~10000条,数据库合规规则数从2000~200000条,数据溯源图中的HQL数为500条。测试本文方法与VF2算法、Ullmann算法以及文献[10]基于集合的合规验证的时间开销对比。实验结果如图10所示,随着合规规则数量增加,合规分析时间也在增加。但本文方法增加速度明显最低。对4种方法进行分析,可得相比与其他算法,基于子图同构的合规验证能够同时进行数据溯源图与合规验证图的合规分析、对图匹配顺序进行了优化且算法复杂度较低,故性能较高。
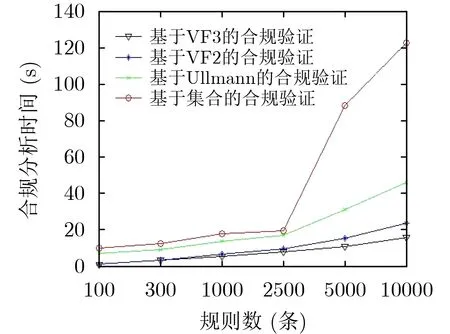
图10 不同合规规则图大小对合规验证时间的影响
然后在相同数量的合规规则图下,测试了不同大小的数据溯源图对合规分析的时间开销影响。实验设置为6组,其中单表HQL记录数目从20000~2 0 0 0 0 0 条,数 据 库H Q L 记 录 数 从4 0 0 0 0 0 ~4000000条,合规规则图数量为1000条。实验结果如图11所示,由于数据溯源图中顶点增加,则待匹配的查询图集合增大,导致合规分析的时间逐渐增长。但可以看出基于子图同构的合规验证时间增长的速度较缓慢。原因上文已提到。综上所述,本文提出的基于VF3的合规验证比其他合规验证方法整体性能更优。
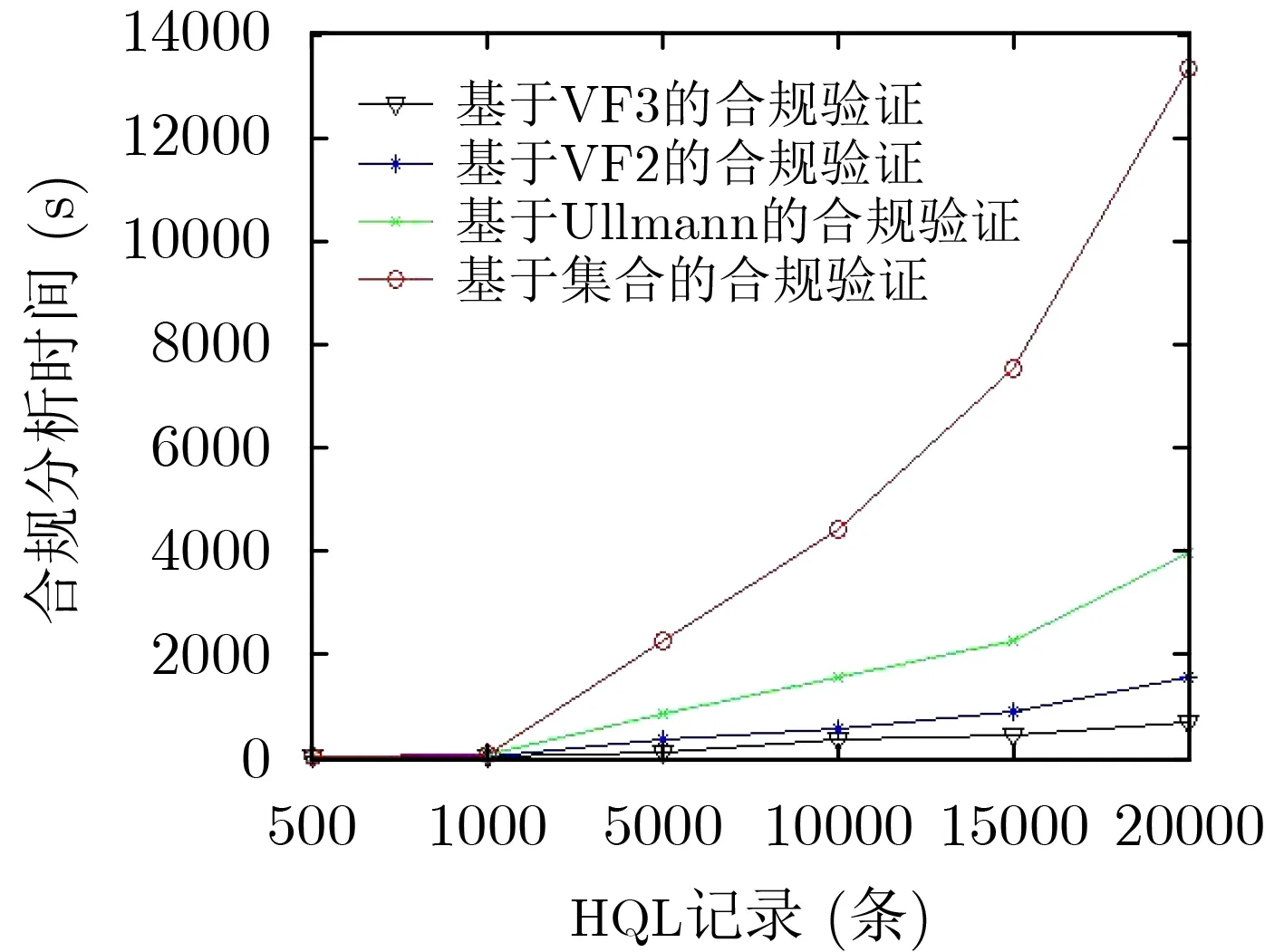
图11 不同数据溯源图大小对匹配时间的影响
5 结束语
本文为了解决大数据平台中缺乏对数据使用目的和数据最小化的合规验证问题,提出了基于子图同构的合规验证方法。首先,定义了一种能够描述数据使用目的的数据合规规则,并由合规规则图表示,作为合规验证的依据;然后,使用子图同构算法实现了对Hive查询语句的数据使用范围、处理方式、权限和目的的合规验证。本文在Apache Atlas中实现了基于子图同构的Hive数据操作合规分析方法,并在TPC-DS基准数据集上对该方法的功能和性能进行了实验验证。实验结果表明,本文方法能够对Hive数据操作的数据使用目的进行合规验证,加入合规分析对整个溯源过程影响较小。且相比于基于集合、VF2以及Ullmann的合规验证整体性能更优。
