变分自编码器和注意力机制的异常入侵检测方法
2022-12-28施媛波
施媛波
(昆明城市学院 ,昆明 650106)
0 引 言
随着云计算和物联网等互联网服务新技术的出现,网络安全变得越来越重要。网络入侵检测系统(network intrusion detection system, NIDS)在计算机网络安全中发挥着核心作用,它提供了针对恶意活动的适当保护[1-2]。NIDS的目标是通过分析网络流量特征和恶意活动规律来建立一个可以区分攻击和正常网络流的预测模型,用于发现计算机网络中任何未经授权的访问[3]。尽管网络入侵检测系统已经发展了数十年,但是,现有的NIDS仍然面临着日益复杂的互联网攻击和海量数据入侵检测的挑战[4-5]。
基于检测方法,NIDS系统可以分为两种类型[6]:第一种是基于签名的,旨在通过将输入流量与预定义签名进行比较来检测攻击;第二种是基于异常的,旨在关注正常环境下活动的行为,通过分析正常的网络行为来确定网络是否被视为入侵。由于传统的入侵检测系统设计的性能较差,使得这类方法具有较高的误报率和低准确率[7]。近年来,随着深度学习技术在多个行业中的快速进展,深度学习模型已广泛用于入侵检测领域,为入侵检测领域提供了一个新的方向。深度学习方法集成了高级特征提取和分类任务,克服了浅层学习的一些局限性,有效促进了入侵检测系统的发展。文献[8]提出了一个在线异常检测系统,通过使用一组人工神经网络来识别对本地网络的攻击,以协同区分正常和异常流量模式。文献[9]提出了一种基于深度神经网络的入侵检测方法,通过监督学习方法来识别不可预见和不可预测的入侵。文献[10]针对网络入侵检测系统检测精度低的问题,采用堆叠式非对称自动编码器和随机森林方法来检测网络攻击。文献[11]提出一种基于Bi-long short-term memory(Bi-LSTM)和注意力机制的网络入侵检测方法,该方法为了克服网络入侵记录特征冗余造成的检测性能低的问题,利用Bi-LSTM网络进行长距离依赖特征提取,并引入注意力机制增加对特征重要性的计算。尽管上述基于深度学习的入侵检测方法在一定程度上取得了较好的检测效果,但是仍然面临着许多问题和挑战。首先,在实际网络环境中,不同类型的网络流量不平衡,并且网络入侵记录少于正常记录。分类器偏向于更频繁出现的记录,这降低了少数攻击的检测率。其次,由于网络流量大,结构复杂,传统的分类器算法难以达到较高的检测率。第三,物联网和云服务的广泛使用,导致各种新的攻击正频繁出现。由于许多未知攻击没有出现在训练数据集中,因此现有入侵检测方法通常在检测未知攻击方面表现不佳。
考虑到上述因素,提出了一种基于变分自动编码器和注意力机制的入侵检测方法,该方法能够显式地探究训练样本中隐含的潜在变化和多样性,通过使用重建概率作为异常分数,能够对异常网络流量实行有效检测。此外,所提模型将自注意机制引入到变分自编码器中,获得每个变量的动态权重,进而将样本中包含的变化因子融合到最终潜变量中,从而有效提高了模型对未知攻击的检测性能,对不平衡网络流量集中的异常流量检测率也有一定的改善。
1 相关内容
1.1 变分编码器
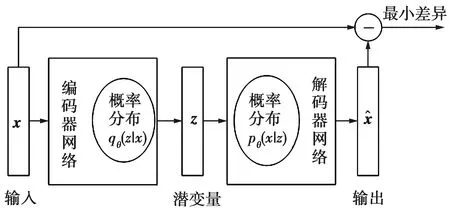
图1 变分编码器的架构Fig.1 Architecture of variational encoder
在VAE中,z被约束为根据先验分布pθ(z)进行分布,从而迫使模型学习输入数据的分布。由于边际似然是难以处理的,因而输入数据的边际似然的变分下界是VAE的目标函数。边际似然计算公式为
(1)
对于不同数据点的边际可能性,使用变分推理技术进行求解,即通过找到近似后验qφ(z|x)来解决该问题。给定一个推理模型qφ(z|x),VAE的损失函数可写为
L(θ,φ;x)=Eqφ(z|x)[logpθ(x|z)]-
DKL(qφ(z|x)||pθ(z))
(2)
(2)式中,DKL是z的近似后验和先验之间的Kullback-Leibler散度。在训练过程中,近似后验qφ(z|x)的参数是通过VAE用神经网络实现的。似然概率pθ(x|z,c)的分布根据数据的性质而变化,当输入数据为连续变量时,应用多元高斯分布;如果是二进制变量,则使用伯努利分布。
1.2 基于VAE的异常检测
异常检测又被称为离群点检测,是机器学习研究领域中与现实紧密联系、有广泛应用需求的一类问题。分析和检测异常点非常重要,因为它揭示了有关数据生成过程特征的有用信息。异常检测应用于网络入侵检测,信用卡欺诈检测,传感器网络故障检测,医疗诊断等众多领域。
基于VAE的异常检测方法采用半监督方式执行[13],即仅使用正常数据样本来训练变分自动编码器。训练后的VAE模型将以非常低的正则度重建正常输入数据,而对于异常数据则无法以低概率值进行重建。概率解码器gθ和编码器fφ分别对原始输入变量空间和潜变量空间中的各向同性正态分布进行参数化,且使用均值和方差参数计算从各向同性正态分布产生的原始数据概率。此外,选择重建概率(reconstruction probability, RP)作为异常分数来检测异常值,当遇到RP过高的输入数据时,即认为是异常数据。在基于VAE的异常检测过程中,通常选择Eqφ(z|x)[logpθ(x|z)]的蒙特卡罗估计作为RP。
2 基于VAE和注意力的异常检测方法
本文提出了一种基于VAE和注意力机制的异常检测方法。变分自动编码器是一种将变分推理与深度学习相结合的概率图形模型,使用重建概率作为异常分数,比重建误差更具原则性和客观性。此外,该方法能够显式地探究训练样本中隐含的潜在变化和多样性,并通过引入自注意机制获得每个变量的动态权重,进而将样本中包含的变化因子融合到最终潜变量中,从而有效提高了模型的检测性能。
2.1 注意力联合变分自动编码器
VAE是一种无监督模型,只能生成与输入类似的输出数。这种方式不足以充分把握输入数据的本能特征,且在编码过程中没有关注潜在量之间的关系。为了克服上述缺点和局限性,本文提出了一种注意力联合变分自动编码器框架,如图2所示。该框架分为3个步骤:首先,在编码过程中生成多个中间连续潜在变量;其次,通过引入自注意力机制,对中间潜在变量进行加权和求和,获得最终的潜在变量;然后,将最终的潜在变量进行解码。所提出的方法通过提取和整合原始样本丰富的特征信息来提高检测率。
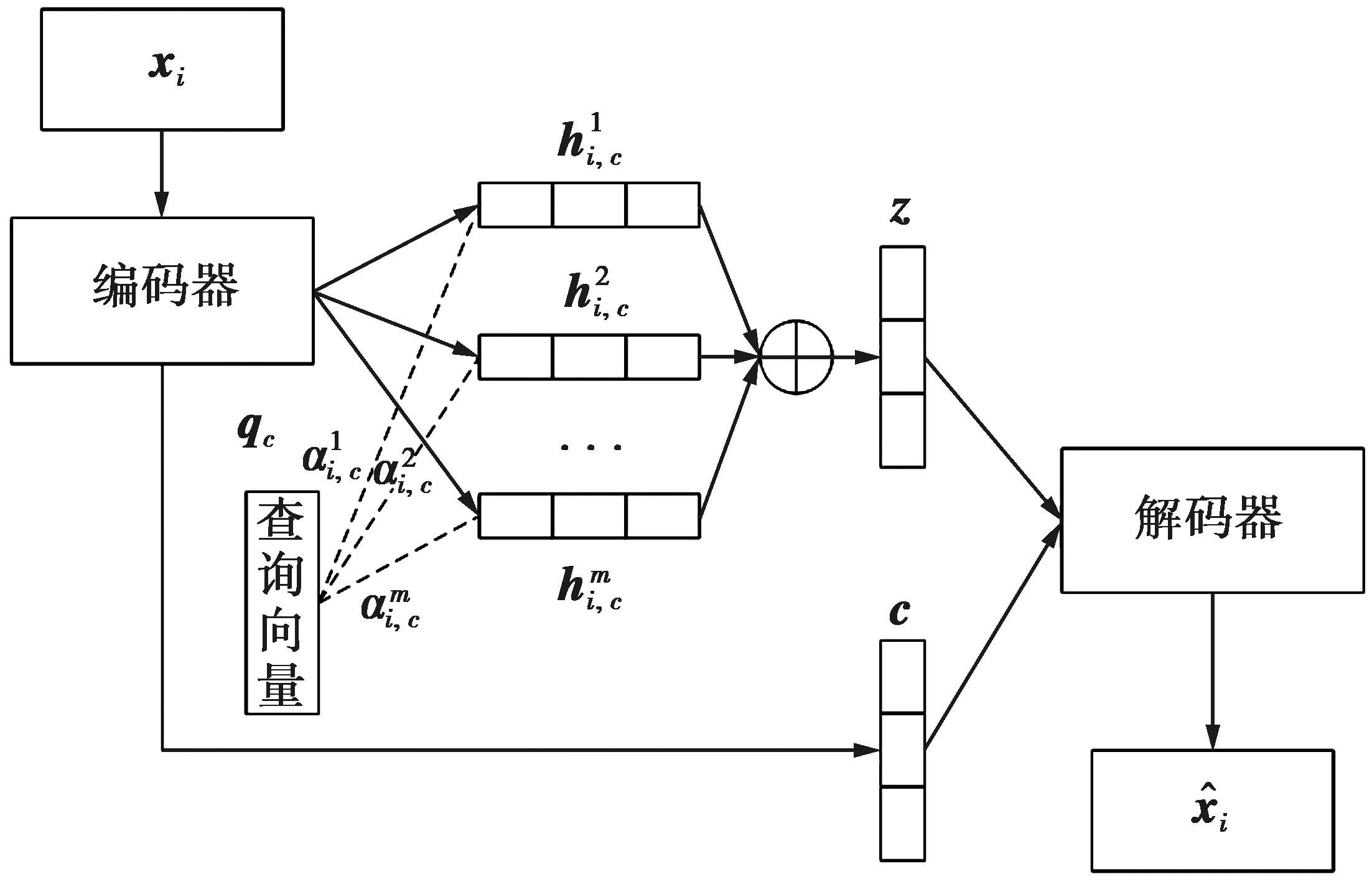
图2 注意力联合变分自动编码器框架示意图Fig.2 Schematic diagram of attentionjoint variational automatic encoder frame
如图2所示,编码器分别从样本数据x中生成潜在变量z和c;然后,解码器对z和c进行重构获得输出结果。对于连续潜在变量的推论过程,所提模型生成了多个中间潜在变量,即
(3)
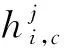
(4)
(4)式中,j=1,2,…,m。
第2步,引入一种类似于softmax的计算方法,将前一阶段的相似度得分转化为对齐权重,计算公式为
(5)
(6)
利用后验qφ(z,c|x)、先验p(z,c)和似然概率pθ(x|z,c),所提方法的目标函数可以写为
L(θ,φ;x)=Eqφ(z|x)[logpθ(x|z,c)]-
DKL(qφ(z,c|x)||p(z,c))
(7)
假设连续和离散的潜变量是条件独立的,即qφ(z,c|x)=qφ(z|x)×qφ(c|x)p(z,c)=p(z)×p(c)。则在训练过程中通过增加信息容量来提高模型的性能,表示为
L(θ,φ;x)=Eqφ(z,c|x)[logpθ(x|z,c)]-
β|DKL(qφ(z|x)||p(z))-Dz|-
β|DKL(qφ(c|x)||p(c))-Dc|
(8)
(8)式中:dz和dc分别表示连续通道和离散通道的受控信息的容量,并且它们的值在训练过程中逐渐增加;b是一个常数,通过约束kullback-leibler散度项来匹配dz和dc。
2.2 模型训练
对于提出的异常检测模型,本文采用NSL-KDD数据集[14]和UNSW-NB15数据集[15]进行训练。所提出的模型输入值必须是一个实向量,因此需要将入侵检测数据集中的每个符号特征转化为一个数值特征。NSL-KDD数据集包含3个符号特征和38个数字特征,UNSW-NB15数据集包含3个符号特征和40个数字特征。所有符号特征通过独热编码(one-hot-coding)技术转换成二进制。NSL-KDD和UNSW-NB15数据集分别转换为122维和196维特征。使用最小-最大归一化方法将所有数据缩放到[0,1]范围内。在对入侵检测数据集中的所有数据进行预处理后,通过标签重组和Adam优化算法来优化编码器θ和解码器φ,达到训练模型的目的。
VAE的训练通过使用反向传播算法来执行。重构概率使用蒙特卡罗梯度技术结合重参数化方法计算获得。给定测试数据x,编码器将潜在的高斯变量μ和σ的参数估计作为输出,然后根据潜在变量的分布N(μ,σ2),采用重参数化对z进行L次采样得
zl=μ+σ·ξl
(9)
(9)式中:ξ~N(0,I);l=1,…,L。因此,重建概率可以由VAE根据先验pθ(z)采样L次的平均重建误差计算获得,表示为
(10)
利用产生原始输入变量分布参数的随机潜变量计算RP。这从根本上等同于从近似后验分布中取出的某些潜在变量产生数据的概率。RP不仅考虑原始输入和重构之间的差异,而且还通过考虑方差参数来考虑重构的可变性,而且通过使用此函数可以增强对根据变量方差进行重构的选择性敏感性。
对于所提出的注意力联合变分自编码器,为进一步明确模型的有效性和可用性,本文给出了其在理论上的时间复杂度。所提模型由两部分组成,其一,利用自注意机制确定潜在变量,每一层执行的时间复杂度为O(n2·d);其二,执行变分自编码器获得检测效果,每一层执行的时间复杂度为O(n·d2+n·d2),n表示序列长度,d表示序列维度。因此,所提模型的总时间复杂度为O(n2·d)+O(n·d2)。
训练完成参数优化后,利用模型进行异常检测。当网络行为与所提模型学习到的正常行为有很大差异时,通常会观察到很高的重构误差。当输入特征的重构误差超出阈值时,即可将该数据视为攻击流量。图3给出了基于注意力联合变分自动编码器的异常检测流程图。

图3 所提模型的工作流程Fig.3 Workflow of the proposed model
所提方法的伪代码如下。
1)初始化训练样本集:正常数据X,异常数据X′以及阈值a;
2)利用样本训练注意力联合变分自动编码器的参数以及基于(6)式确定连续潜变量z为
trainAttVAE(X)→z
trainAutoencoder(X′)→z′
3)利用变分自动编码器z和z′分别计算重构概率RP和RP′;
4)将重构概率与阈值做比较,判断x是否为异常值;
5)返回结果。
3 实验与结果分析
为验证所提模型的有效性,采用NSL-KDD数据集和UNSW-NB15数据集进行测试,并将测试结果与基于BiLSTM和注意力机制(BiLSTM-Att)[11]、基于对抗式自动编码器(adversarial auto-encoder, AAE)[16]、基于对数余弦条件变分自动编码器(log-cosh conditional variational autoencoder, LCVAE)[17]和基于合成少数过采样技术(synthetic minority oversampling technique, SMOTE)[18]等入侵检测方法进行对比。本实验基于Python 3.6版本和PyTorch 1.3版本,所有实验在Intel Core i74720HQ CPU上执行,该CPU运行环境为64位Windows 10操作系统,32 GB RAM。
本文选择了一种简单形式的深度自动编码器体系结构来进行实验。对于VAE而言,编码器有两个具有512和256维的隐藏层,解码器则有两个具有256和512维的隐藏层,VAE的瓶颈层有64个维度。每层的激活函数是ReLU。另外,需要设置两个重要参数:学习率和迭代周期。学习率是VAE模型中的一个重要参数,学习率过高将导致损失激增,而学习率太小则将导致模型收敛缓慢或过度拟合。对于学习率的设置,本文尝试使用了0.1、0.01、0.001、0.000 1、0.000 01等作为测试值。经过测试后的学习率为0.001。模型进行30 000次迭代训练,批次大小为8 192。为了平衡VAE损失函数在两个目标之间保持平衡,将β设置为0.5,参数Dz和Dc均设置为1.0。自注意力机制中的m设置为3。
3.1 数据集和评估指标
NSL-KDD数据集中有5种类别:正常、拒绝服务、探针攻击、远程到本地和用户到根。该数据集包含KDDTrain+、KDDTrain+_20Percent、KDDTest+和KDDTest-21共4个子集,其中的每条数据记录包含41个特征属性和1个类标签。在本文实验中,选择KDDTrain+_20Percent作为训练集, KDDTest+作为测试集。NSL-KDD数据集具体细节由表1给出。

表1 NSL-KDD数据集的细节描述Tab.1 Detailed description of the NSL-KDD dataset
UNSW-NB15是一个新的数据集,由澳大利亚网络安全中心在2015年建立,能够真正反映现代网络的正常活动。UNSW-NB15数据集包含正常、泛型、漏洞利用、模糊测试、拒绝服务、踩点、渗透分析、后门、shellcode和蠕虫等10种类别。该数据集分为训练集和测试集,其中训练数据集包含175 341条记录,测试数据集包含82 332条记录,每条记录具有47个特征属性和2个类标签。本文选择除去目的IP、目的端口、源IP、源端口、开始时间和结束时间外的43个属性向量进行测试。表2给出了UNSW-NB15数据集的具体细节。

表2 UNSW-NB15数据集的细节描述Tab.2 Detailed description of UNSW-NB15 dataset
通过分析训练的入侵检测模型的准确率和F-分数来衡量所提出方法的整体性能。准确率是正确标记流量的比率,定义为
(11)
(11)式中:TP和TN分别表示为正确预测流量为正常和攻击类型的样本数;FP和FN分别表示为错误预测流量为正常和攻击类型的样本数。准确率越高,模型的性能越好。
F分数是精度p和召回率r的调和平均值,表示为
(12)
(12)式中,精度p衡量入侵检测系统仅识别攻击的能力,计算公式为
(13)
召回率r可以看作是系统发现所有攻击的能力,计算公式为
(14)
F值越高,算法所达到的精确性和召回率之间的平衡越好。
3.2 实验结果分析
采用2个实验来验证所提算法性能的优越性。第一个实验是针对2个数据集不同类型的攻击,所提模型的检测效果测试;第二个实验是对比研究,通过与其他几种入侵检测算法结果对比验证所提算法的优势。图4—图5给出了所提方法在NSL-KDD数据集和UNSW-NB15数据集中的测试结果。

图4 所提模型对NSL-KDD数据集5种类型的检测Fig.4 Proposed model detects 5 types of NSL-KDD dataset
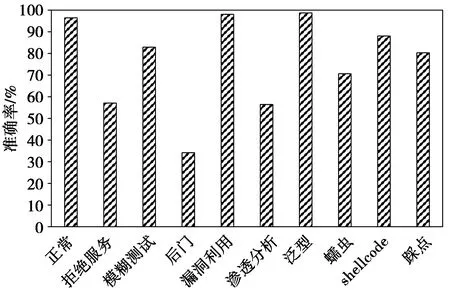
图5 所提模型对UNSW-NB15数据集10种类型的检测Fig.5 Proposed model detects 10 types of UNSW-NB15 dataset
从图4中可以看出,在5种攻击类型的检测中,所提方法对正常类型和拒绝服务的检测准确率最高。此外,由于测试数据集中的远程到本地和用户到根攻击中有一半以上没有出现在训练数据集中,因此所提方法虽然对远程到本地和用户到根攻击的检测率相较于其他攻击类型较低,但是也能证明所提模型在检测未知攻击方面具有不错的性能。
同理,从图5中也能看出所提模型在正常、漏洞利用和泛型3个攻击类型的检测率最高,对Backdoor攻击类型的检测率最低。
此外,为了验证所提方法在实际应用中的效果,将该方法在时间上的开销与自编码器(auto encoder,AE)和VAE方法进行了对比。图6给出了所提模型与其他方法检测NSL-KDD数据集中单个样本时的平均执行时间。从图6中可以看出,因为所提模型引入了注意力机制,所以在检测过程中消耗了更多的时间。然而,时间开销的增加是为了取得更高的检测准确性。
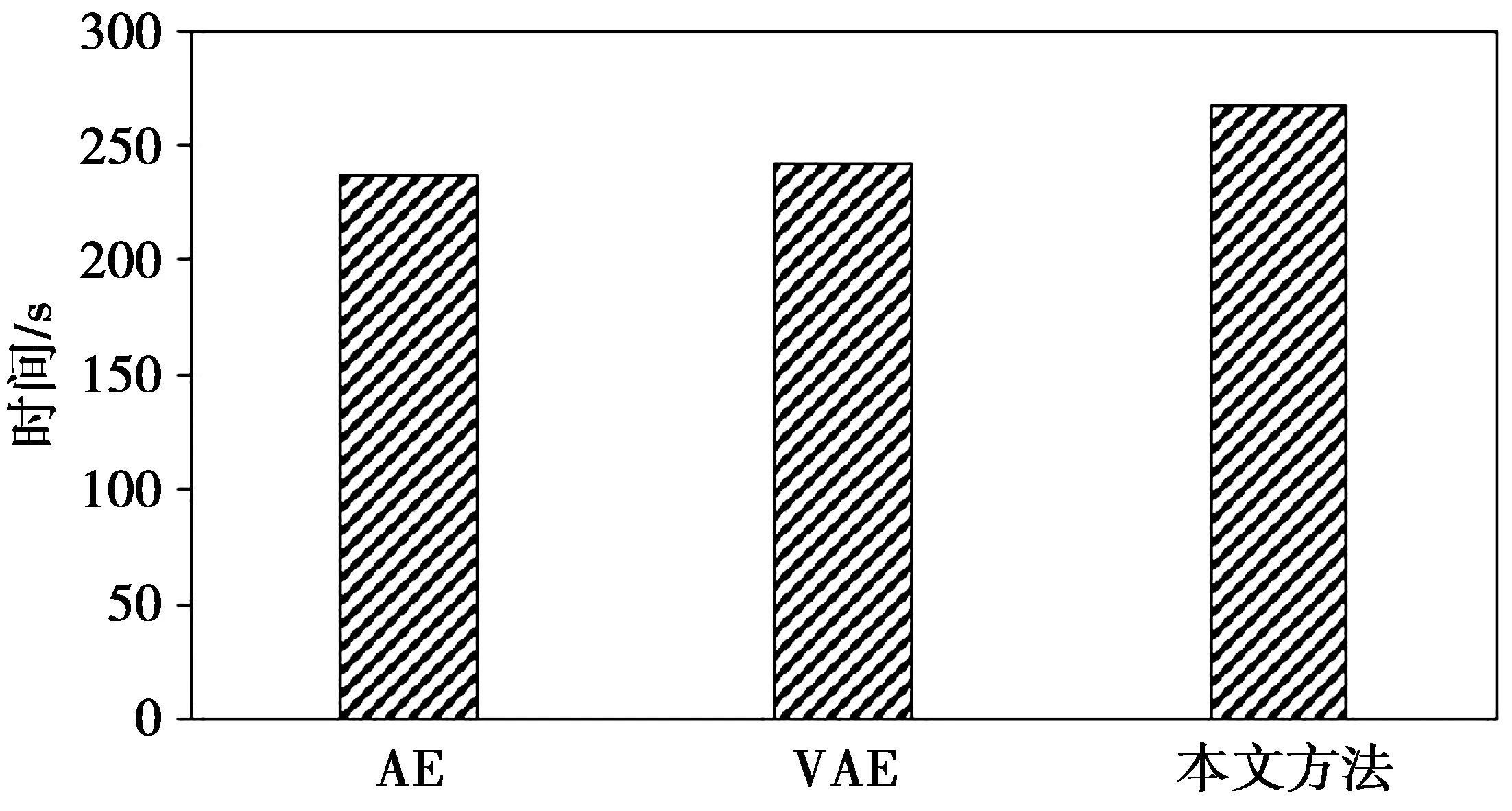
图6 所提模型与其他方法的时间开销对比Fig.6 Time cost comparison between the proposed model and other methods
图7和图8给出了不同方法在NSL-KDD数据集和UNSW-NB15数据集中的准确率和F1分数对比结果。从图中的结果可以看出,相对于其他几种检测方法,本文基于VAE和注意力机制的异常检测方法在2个数据集中均能获得最佳的测试结果。
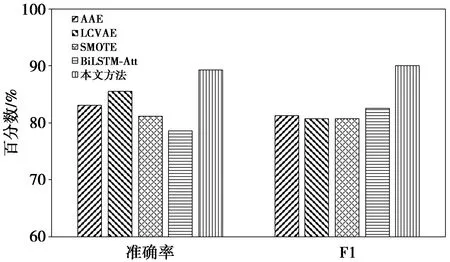
图7 不同方法在NSL-KDD数据集检测结果Fig.7 Test results of different methods in the NSL-KDD data set
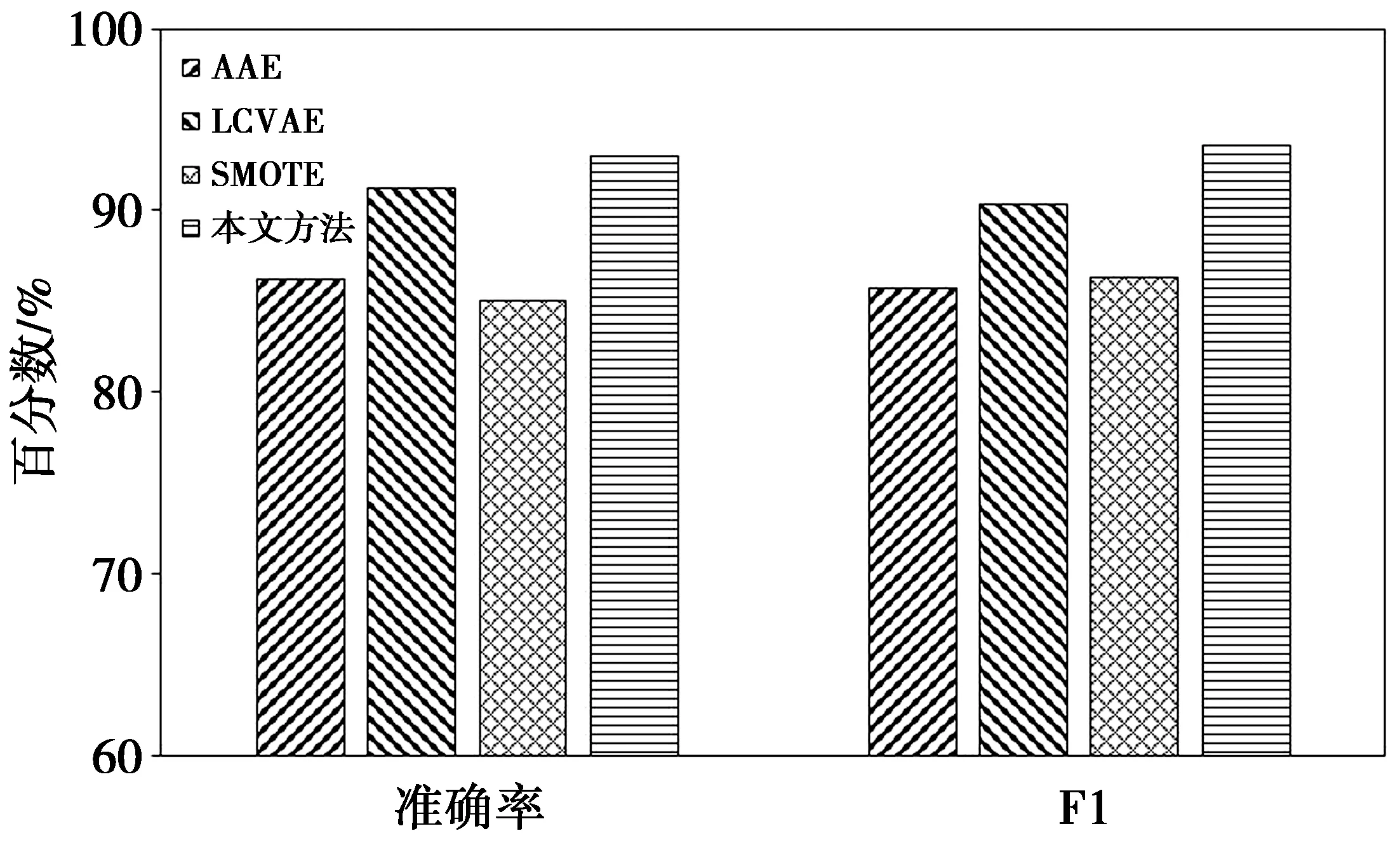
图8 不同方法在UNSW-NB15数据集检测结果Fig.8 Test results of different methods in the UNSW-NB15data set
4 结 语
本文提出了一种基于VAE和注意力机制的异常入侵检测方法,用于解决当前基于深度学习的入侵检测算法在检测未知攻击时精度不足的问题。所提方法首先对输入数据进行预处理操作;其次,将预处理后的数据输入变分自编码器中进行训练,计算原始数据与重建数据之间的重建误差;然后,根据重建误差,通过设置适当的阈值来区分流量数据中的异常行为。为了提高方法的检测精度,本文将自注意力机制引入到VAE中,通过考虑样本特征中隐含的潜在变化和多样性来改善模型的检测性能。实验结果表明,所提模型能够有效检测流量中的异常行为,比其他入侵检测方法具有更优的检测精度。
