基于时空融合深度学习的工业互联网异常流量检测方法
2022-12-28胡向东
胡向东,张 婷
(重庆邮电大学 自动化学院/工业互联网学院,重庆 400065)
0 引 言
工业互联网是一种将“人、机、物”通过网络互相联结的新兴工业生态[1],它将工业系统与互联网技术相连接,推动着工业生产方式的变革。随着工业化与信息化的深度融合发展,工业生产制造也变得更加智能高效,但随之而来的却是工业互联网所遭受的网络攻击行为日益增多。2014年的“Havex”病毒[2]和2021年美国成品油管道运营商Colonial Pipeline遭到勒索软件的攻击事件[3]更是敲响了工业互联网信息安全的警钟。如何及时发现工业互联网中的攻击行为并采取相应的防护措施,对于维护工业互联网的安全有着重要的意义。异常流量检测技术可以实时监视网络行为并有效识别网络攻击,从而实现对网络安全的有效防护。
近年来,传统机器学习方法在异常流量检测领域取得了一定的成果。文献[4]提出一种基于决策树的异常检测方法,既可检测智能电网中的网络攻击又可将其与物理干扰区分开,但该方法对样本各特征间的关联性较不敏感,且易出现过拟合现象。文献[5]提出一种基于最小依赖最大显著性算法的模糊粗糙集方法,用于删除数据集中的冗余属性,然后利用改进的K近邻算法完成异常流量检测。文献[6]利用主成分分析法去除由小波前导多重分形理论提取的流量特征的冗余特征,使用支持向量机对其进行流量分类。文献[5-6]均使用了特征选择方法去除流量数据的冗余特征,再结合模型进行异常流量检测,取得了较好的检测结果。但这些特征选择方法通常需要专家经验且特征选择的结果在很大程度上影响了检测效果。
与传统机器学习方法不同,深度学习方法可通过多个隐藏层提取数据特征,在处理大量复杂的流量数据方面表现出显著的优势。文献[7]设计了一种由门控循环单元(gate recurrent units, GRU)和多层感知器组成的网络模型,使用KDD 99和NSL-KDD数据集[8]进行实验。虽取得较好的检测结果,但数据集较为老旧,不能反映当前的网络现状。文献[9]利用密集连接卷积神经网络提取流量数据的空间特征,并改进Softmax损失函数最终实现对异常流量数据的有效检测。但损失函数的设计依赖于流量数据特点,泛用性较差。文献[10]使用相关信息熵算法对流量数据进行特征选择,利用卷积神经网络(convolutional neural networks, CNN)和双向长短时记忆网络(bidirectional long short-term memory, BiLSTM)分别提取流量数据的空间和时序特征,并利用多头注意力机制将已提取的特征进行融合,最后使用BiLSTM对融合特征进行学习,实现对流量数据的异常检测。但该方法在数据预处理阶段对流量数据进行了特征选择,不能很好地体现深度学习自主提取特征能力较强的优势。同时,模型结构较为复杂,需要调整的超参数较多,难以满足系统智能化发展的要求。
基于以上分析可知,深度学习方法较传统机器方法在异常流量检测领域具有一定的优势。针对传统的异常流量检测方法难以适应大量复杂的工业互联网流量特征提取的问题,本文提出一种基于时空融合深度学习的工业互联网异常流量检测方法。首先对类别不平衡的流量数据进行预处理,以形成样本分布较为均衡的流量数据集;然后使用融合聚合残差变换网络(aggregated residual transform network, ResNeXt)和GRU单元的深度学习模型从空间和时间维度提取流量数据特征,实现时空融合的数据特征综合提取,有效增强了工业互联网异常流量检测效果。
1 基于时空融合深度学习的工业互联网异常流量检测方法
本文提出的基于时空融合深度学习的工业互联网异常流量检测方法,其整体架构如图1所示,主要包括4个部分:①原始的工业互联网流量数据集;②数据预处理,包括替换默认值和无穷大值、数据过采样、数据归一化和数据集划分;③时空融合的深度学习模型设计与训练;④异常流量检测。
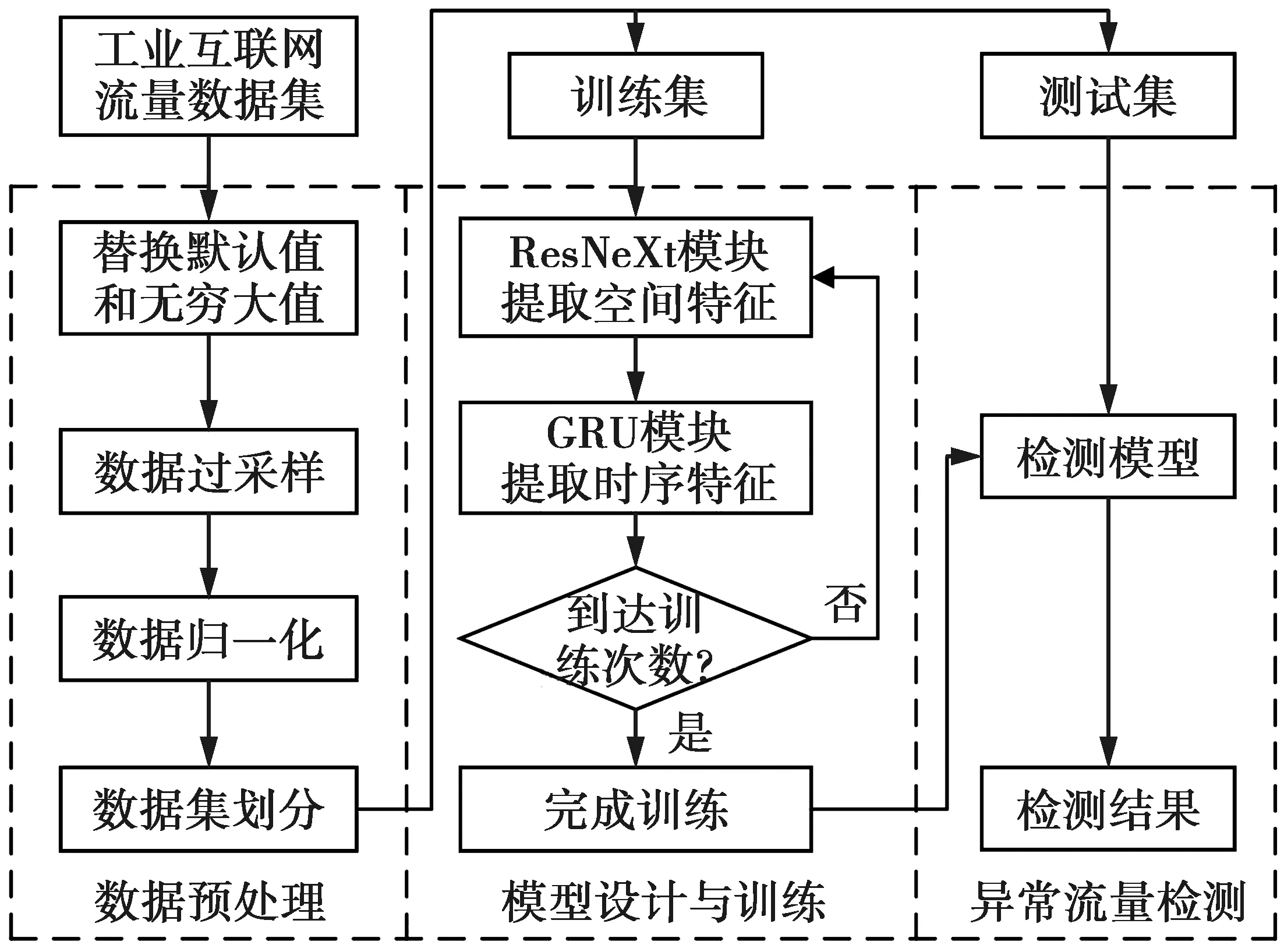
图1 基于时空融合深度学习的工业互联网异常流量检测整体架构Fig.1 Overall framework of abnormal traffic detection for industrial internet based on deep learning with time-space fusion
1.1 工业互联网流量数据集
当前,工业互联网主要由外部网络和工厂内部网络组成。其中,外部网络主要用于工厂与客户、产业链、云数据中心等之间通过公共互联网的方式实现互联;内部网络主要用于连接工厂内部各个要素,如生产人员、机器、仪表设备等。外部网络与工厂内部网络之间的互联,使得工厂内部网络存在遭受外部网络攻击的隐患,因此,对外部网络流入工厂内部网络的流量数据进行检测至关重要。
本文研究的重点是对外部网络的流量数据进行检测,防止异常流量流入内部网络,从而有效避免工厂内部网络遭受网络攻击。因此,本文采用由通信安全机构和加拿大网络安全研究所共同设计系统方法所生成的格式为CSV的CSE-CIC-IDS2018数据集[11]。该数据集共有10个CSV文件,每个文件含有高达百万条的原始流量数据。由于数据量过大,考虑到时间成本,本实验所用数据集从5个CSV文件中各随机抽取5 000条流量数据组成,数据类别的分布情况如表1所示。其中每条流量数据由78个流量特征和所属类别标签组成,由于篇幅有限,本文只给出了流量数据的部分特征属性,如表2所示。
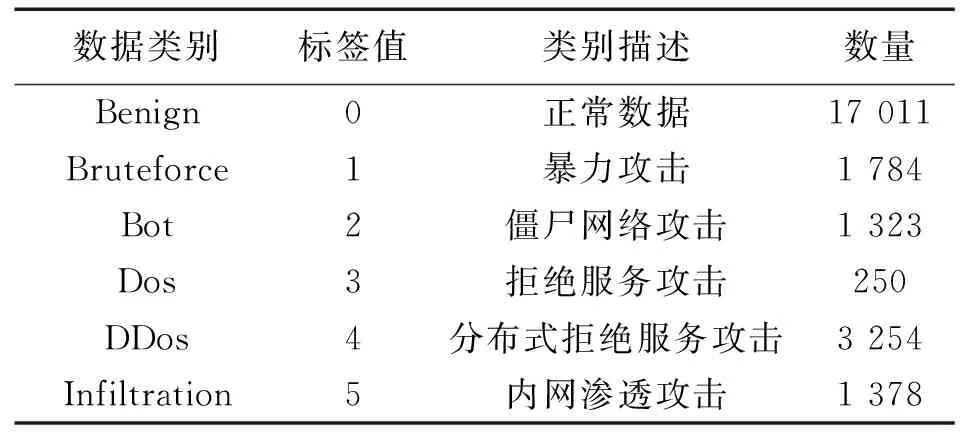
表1 实验数据集的类别分布Tab.1 Category distribution of the experimental data set
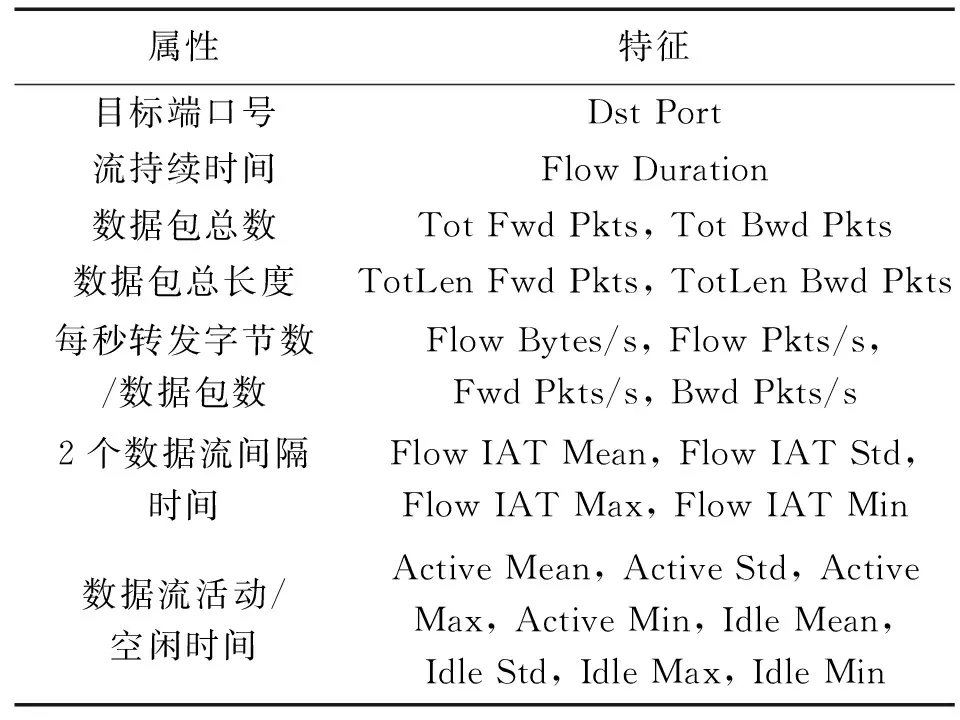
表2 流量数据的部分特征属性Tab.2 Some characteristic attributes of traffic data
1.2 数据预处理
数据预处理模块首先处理原始工业互联网流量数据的默认值和无穷大值,然后对少数类样本进行过采样,最后对数据进行归一化处理并将其划分为训练集和测试集,为模型提供合理的输入数据。
1.2.1 替换默认值和无穷大值
如果特征中存在默认值(NaN)或无穷大值(Infinity),则需要统计包含这些特征值的样本在整个数据集中所占的比例,该比例决定了采用何种方式替换NaN和Infinity[12]。在本实验数据集中,Flow Bytes/s和Flow Pkts/s特征中存在NaN和Infinity,且包含它们的样本数占整个数据集的比例不超过1%,所以将NaN和Infinity替换为0。
1.2.2 数据过采样
在工业互联网异常流量检测领域,少数类样本数量较少是影响模型检测性能的一个重要因素。由表1可知,实验数据集的类别分布不平衡,属于Dos类别的样本数远少于正常样本数。本文采用SMOTEENN方法[13]对少数类样本进行处理,以形成样本分布较为均衡的数据集,过采样前后数据集的类别分布如表3所示。
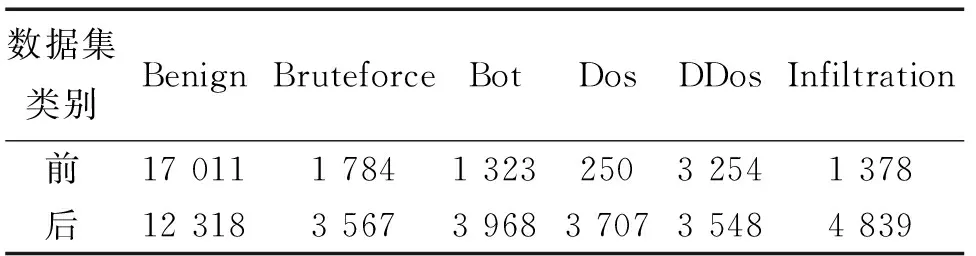
表3 过采样前后数据集的类别分布Tab.3 Category distribution of the data set before and after oversampling
SMOTEENN的过程为①利用欧式距离计算数据集中少数类各样本x的k近邻样本;②从k近邻样本中随机选取n个样本,令其中一个为xi(1≤i≤n),与原样本x根据(1)式计算生成新的样本xnew;③使用欧式距离计算x和xnew合并后各样本x′的k近邻样本的标签值;④统计标签值出现的次数,如果与x′不同的标签值占多数则删除样本x′,反之则保留x′。
xnew=x+rand(0,1)×|x-xi|
(1)
1.2.3 数据归一化
在实验数据集中,各流量特征间因不同的量纲关系数值差异较大,为使数据间具有可比性,本文对过采样后的数据进行归一化处理,具体过程如下。
首先将实验数据集的流量特征与类别标签进行分离,然后将分离出的流量特征数据用m行n列的矩阵M表示为
(2)
(2)式中,Emn表示第m个样本的第n个流量特征值。
以各流量特征为单位对矩阵M进行划分,矩阵M又可表示为
M=[S1,S2,…,Si,…,Sn]
(3)
(3)式中:Si表示所有样本的第i个流量特征值。
Si=[E1i,E2i,…,Emi]T
(4)
然后,对所有样本的各流量特征值进行数值归一化,具体计算公式为
(5)
最后,经过归一化处理后的流量特征数据可表示为
(6)
1.2.4 数据集划分
将经过归一化处理后的数据集以7∶3的比例划分为用于训练模型的训练集和用于测试模型的测试集,二者的类别分布情况如表4所示。
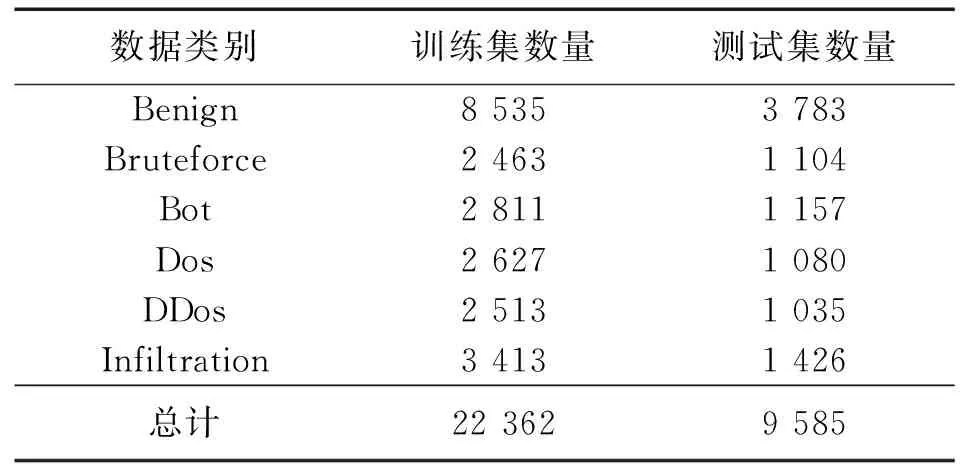
表4 实验数据集的类别分布Tab.4 Category distribution of the experimental data set
1.3 时空融合深度学习模型设计
对工业互联网流量数据进行特征提取时,不仅需要考虑流量特征在空间维度上的联系,而且有必要考虑它在时间维度上的依赖关系。因此,本文设计了融合ResNeXt网络与GRU单元的深度学习模型,模型结构如图2所示。

图2 时空融合深度学习模型结构Fig.2 Structure of the deep learning method with time-space fusion
将预处理后的流量数据作为模型的输入,若将其时间步直接设定为流量特征数即78,模型的训练速度非常缓慢。考虑不是每个特征间都具有时间相关性,因此,设定其时间步t为39,每个时间步对应的特征长度为2。首先,由卷积层、最大池化层和3个不同的聚合残差变换块组成的Res NeXt模块对输入数据进行空间特征提取,并将其输出作为GRU模块的输入;然后,GRU模块对输入数据进行时序特征提取,并将其输出作为减轻模型过拟合而引入的Dropout层的输入;最后,Softmax分类器对Dropout层的输出数据进行分类,得到最终检测结果。
表5展示了该模型结构的具体参数。其中,f、k、s、p分别表示卷积核数、卷积窗口大小、卷积/池化步长、池化窗口大小,c、u分别表示组卷积数和节点数,d表示丢失率。
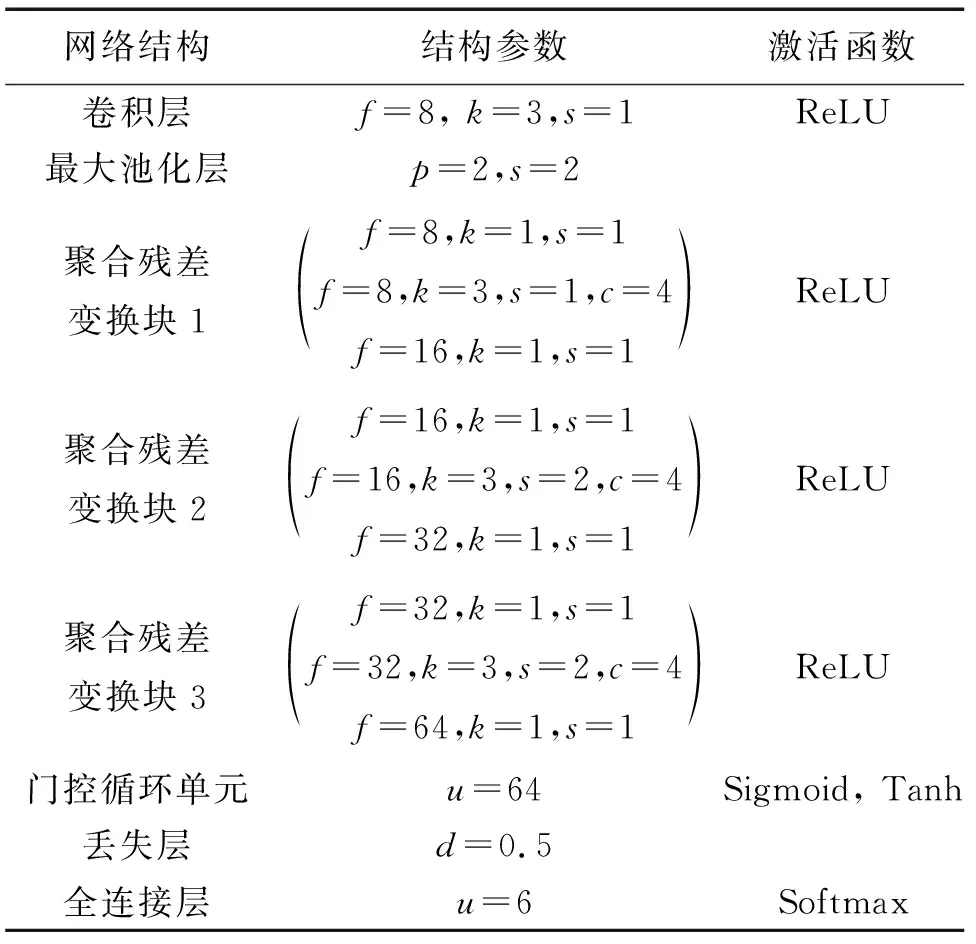
表5 模型结构参数Tab.5 Parameters of model structure
1.3.1ResNeXt网络模块
ResNeXt是文献[14]在残差网络结构的基础上改进而成的。该网络继承了残差网络使用的恒等映射思想,又采用相同的拓扑结构多分支代替残差网络的单一分支,从而使网络高度模块化,其特征学习能力更强。本文对ResNeXt结构进行改进并构建了ResNeXt网络模块,在保证流量数据时序性不变的基础上,实现从空间维度提取流量特征。
在卷积层中,多个卷积核对输入流量数据进行卷积和非线性激活操作,其计算公式为
(7)
在最大池化层中,通过池化窗口在卷积层输出数据上以一定的步长滑动,并取池化窗口中的最大值作为输出值,实现在保留流量数据主要特征的同时降低卷积层输出数据的维度。
聚合残差变换块是ResNeXt网络模块的主要组成部分,如图3所示。文献[14]提出的聚合残差变换块可用图3a表示,但二维卷积会破坏流量数据的时序性,不能直接用于融合模型中。因此,本文对该聚合残差变换块进行了一定的改进,其结构见图3b。
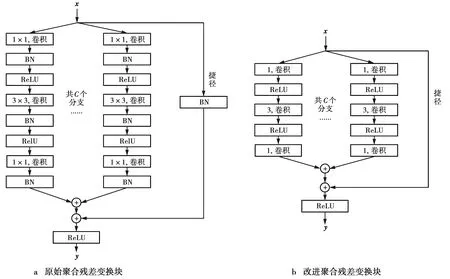
图3 聚合残差变换块结构Fig.3 Structure of the aggregated residual transform block
由图3可知,改进聚合残差变换块是将原始聚合残差变换块的卷积窗口大小和卷积步长由二维变为一维,使卷积操作仅对每一个时间域内的流量数据有效,实现在保留流量数据其时序性的基础上提取其空间特征。除此之外,由模型训练过程可知,若使用BN操作会导致训练数据的准确率震荡,且模型训练耗时较长,因此,改进聚合残差变换块去除了BN操作,以缩短训练时长且使模型的训练准确率相对平稳。
令x为输入,y为输出,Ti(x)为每个分支对输入的变换,C为拓扑结构相同的分支数量,聚合残差变换可表示为
(8)
若输入的维度与聚合变换后的维度不一致时,在捷径中引入线性投影矩阵Ws可使两者维度匹配,此时的聚合残差变换可表示为
(9)
1.3.2GRU单元
GRU单元是LSTM的一种变体[15],它将LSTM的输入门和遗忘门耦合为更新门,并将LSTM的细胞状态和隐藏状态合并为单一的隐藏状态。其结构如图4所示。
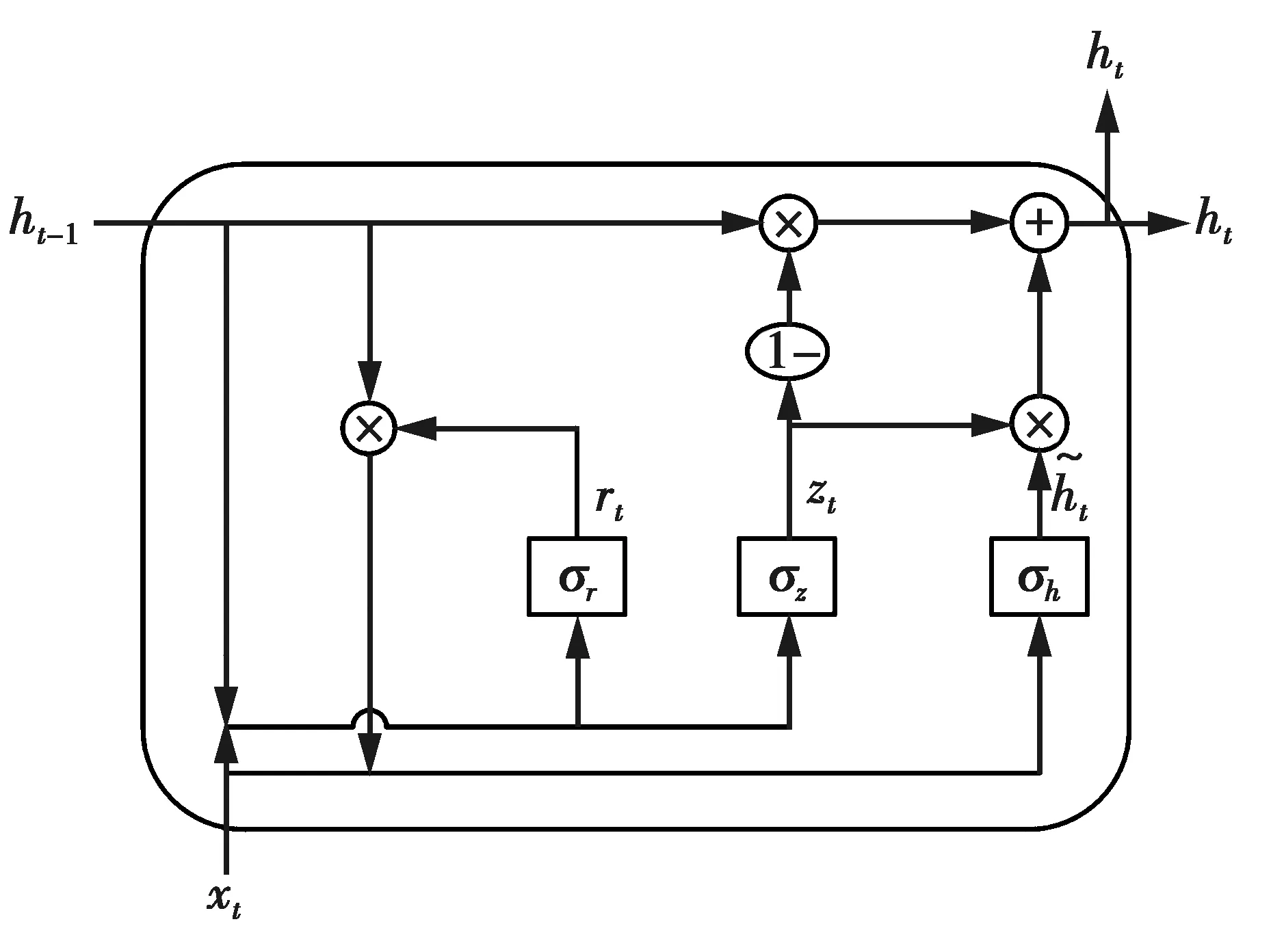
图4 GRU单元结构Fig.4 Structure of GRU cell
GRU单元含有更新门和重置门,分别用于控制更新和忽略历史隐藏状态信息的程度。其计算过程可表示为
rt=σr(Wr·[ht-1,xt]+br)
(10)
zt=σz(Wz·[ht-1,xt]+bz)
(11)
(12)
(13)
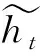
1.4 模型训练与检测
时空融合深度学习模型设计完成后,使用训练集对模型参数进行训练,利用交叉熵损失函数计算真实值与前向传播得到的模型预测值之间的误差,对其进行反向传播,并在该过程中,引入Adam算法不断优化模型参数,使模型预测值最接近真实值。当模型训练完成后,对测试集进行异常检测,输出检测结果,从而验证模型的检测性能。
2 实验与结果分析
2.1 实验环境和参数设置
本文实验配置的环境参数如表6所示。由于模型的检测性能及训练时间与模型的超参数设置密切相关,因此对模型的超参数组合进行训练,最终确定取值如下:批处理数量为256,训练轮数为400。
表6 实验环境参数Tab.6 Experimental environment parameters
2.2 评价指标
本文使用4个指标来评估时空融合深度学习模型的性能:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值,各自的计算方法为
(14)
(15)
(16)
(17)
(14)—(17)式中:TP表示模型检测正确的攻击类别的样本数;TN表示模型检测正确的正常类别的样本数;FP表示模型检测为攻击类别而实际为正常类别的样本数;FN表示模型检测为正常类别而实际为攻击类别的样本数。
2.3 实验结果分析
为验证本文提出的方法在工业互联网异常流量检测领域的优势,本文进行了多组对比实验,包括数据过采样效果对比、模型检测性能对比和模型运行时间对比。
2.3.1 数据过采样效果对比
保持其他步骤不变,使用本文提出的模型对过采样处理前后的数据集进行对比实验,结果如图5所示。由于流量数据的类别分布不平衡,存在攻击类检测准确率低但总体准确率高的现象。该现象说明在样本分布不平衡的情况下总体准确率不能较好地反映模型性能[16],因此,本次对比实验使用上述提及的除准确率以外的其余3个指标来评估模型性能。由图5可知,SMOTEENN方法较大提高了模型的召回率和F1值,表明了数据过采样能有效提升模型对流量数据的检测效果。
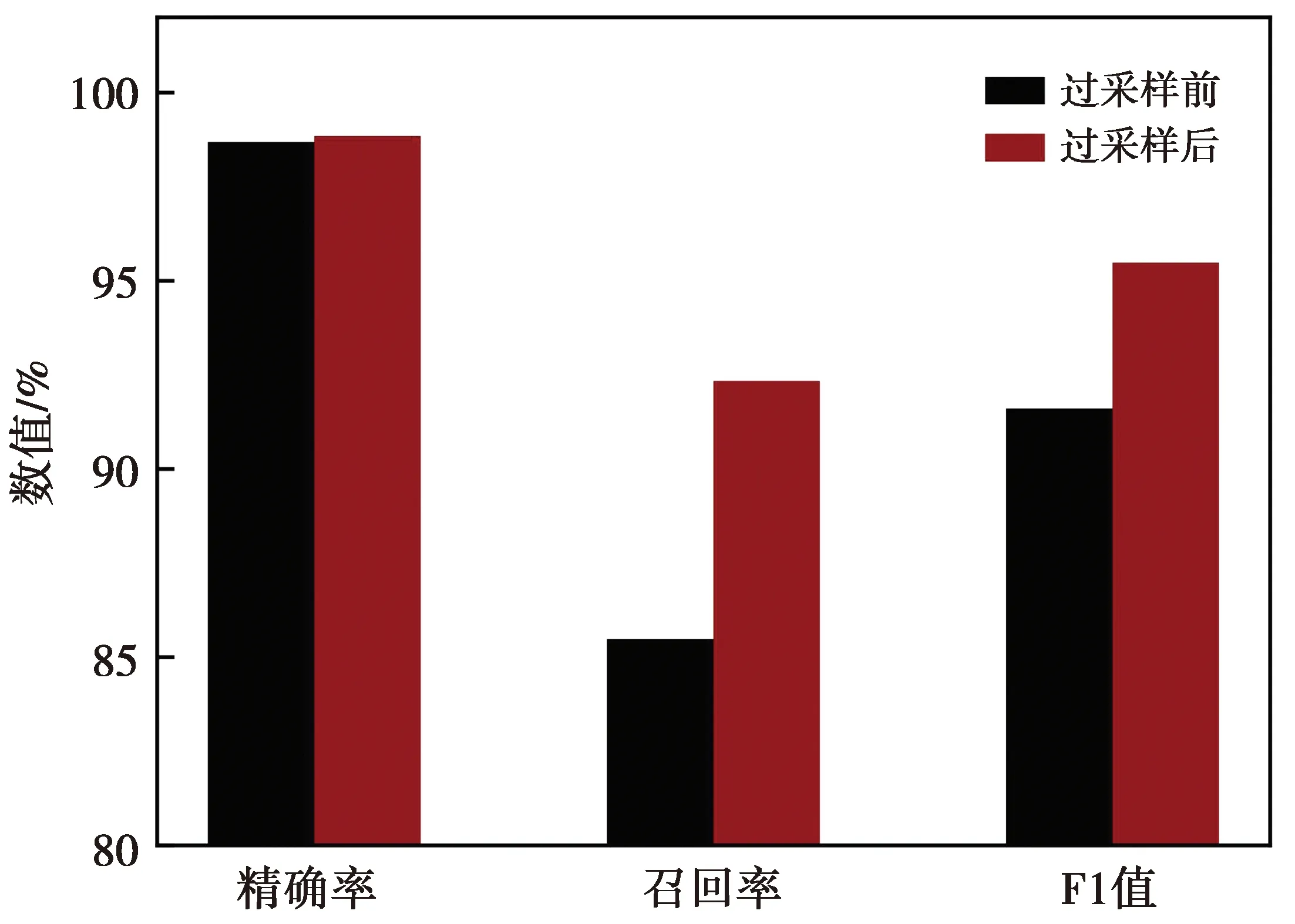
图5 过采样前后模型性能对比Fig.5 Model performance comparison before and after oversampling
2.3.2 模型检测性能对比
为了验证时空融合深度学习模型的性能,基于相同数据集的情况下,将融合模型ResNeXt-GRU与传统机器学习方法SVM和深度学习方法MMN-CNN[17]、ResNeXt、GRU、BiLSTM进行对比实验。
图6为融合模型与单一模型的训练准确率变化曲线。为保证检测指标值的可靠性,将上述各模型独立重复训练10次,取其平均检测指标值作为最终结果,如表7所示。
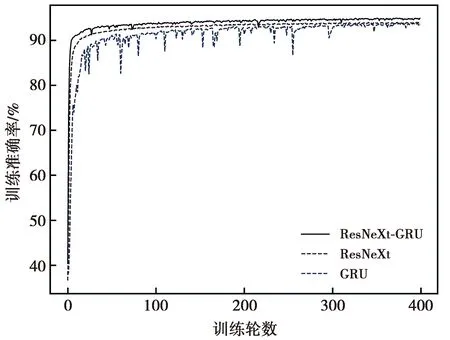
图6 不同模型的训练准确率变化曲线Fig.6 Change curve of training accuracy of different models
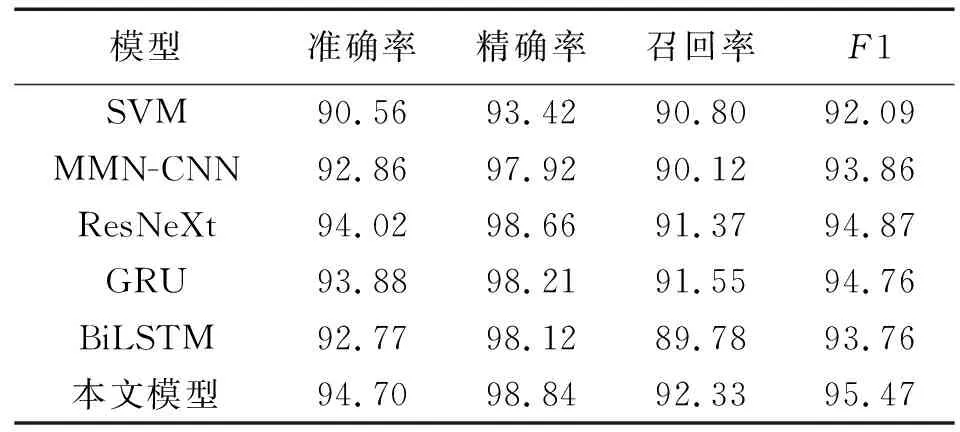
表7 不同异常流量检测模型的性能Tab.7 Performance of different abnormal traffic detection models %
由图6可知,融合模型与单一模型随着不断的训练,在320轮训练之后训练准确率均趋于稳定且整体高于90%,但融合模型的优势更为明显。GRU模型虽然经过400轮训练后其训练准确率可基本持平于ResNeXt模型,但该模型的训练曲线波动较大。融合模型ResNeXt-GRU不仅可以平稳地训练而且能达到较高的训练准确率,这说明融合模型的设计能提升工业互联网异常流量检测效果。
由表7可知,SVM的准确率和F1值最低,主要原因是该模型的优势在于解决小样本问题,在处理大量复杂的流量数据时具有局限性。MMN-CNN和ResNeXt可从空间维度提取流量数据特征,但MMN-CNN的检测性能指标值均低于ResNeXt,主要原因是其浅层结构不能较充分地提取复杂的流量数据特征。GRU和BiLSTM可从时间维度提取流量数据特征,GRU的检测性能指标值高于BiLSTM但基本持平于ResNeXt,说明采用合适的模型从空间或时间维度提取流量数据特征均可达到较好的检测效果。与上述检测模型相比,本文提出的时空融合深度学习模型ResNeXt-GRU的检测性能指标值均最高,其准确率达到94.70%,相较于ResNeXt和GRU分别高出0.68%和0.82%,这说明了融合模型较单一模型在工业互联网异常流量检测领域具有更明显的优势。
图7展示了上述不同模型对各类流量数据的检测准确率。与其他模型相比,本文模型对Benign和Infiltration类别的流量数据具有更高的检测准确率,对其他类别的流量数据也有很好的检测效果。对于Benign和Dos类别的流量数据,SVM具有最低的检测准确率。虽然每个模型对Bruteforce、Bot、DDos类别的流量数据可达到近100%的检测准确率,但对Infiltration类别的流量数据其检测效果均欠佳,有待后续进一步改进。
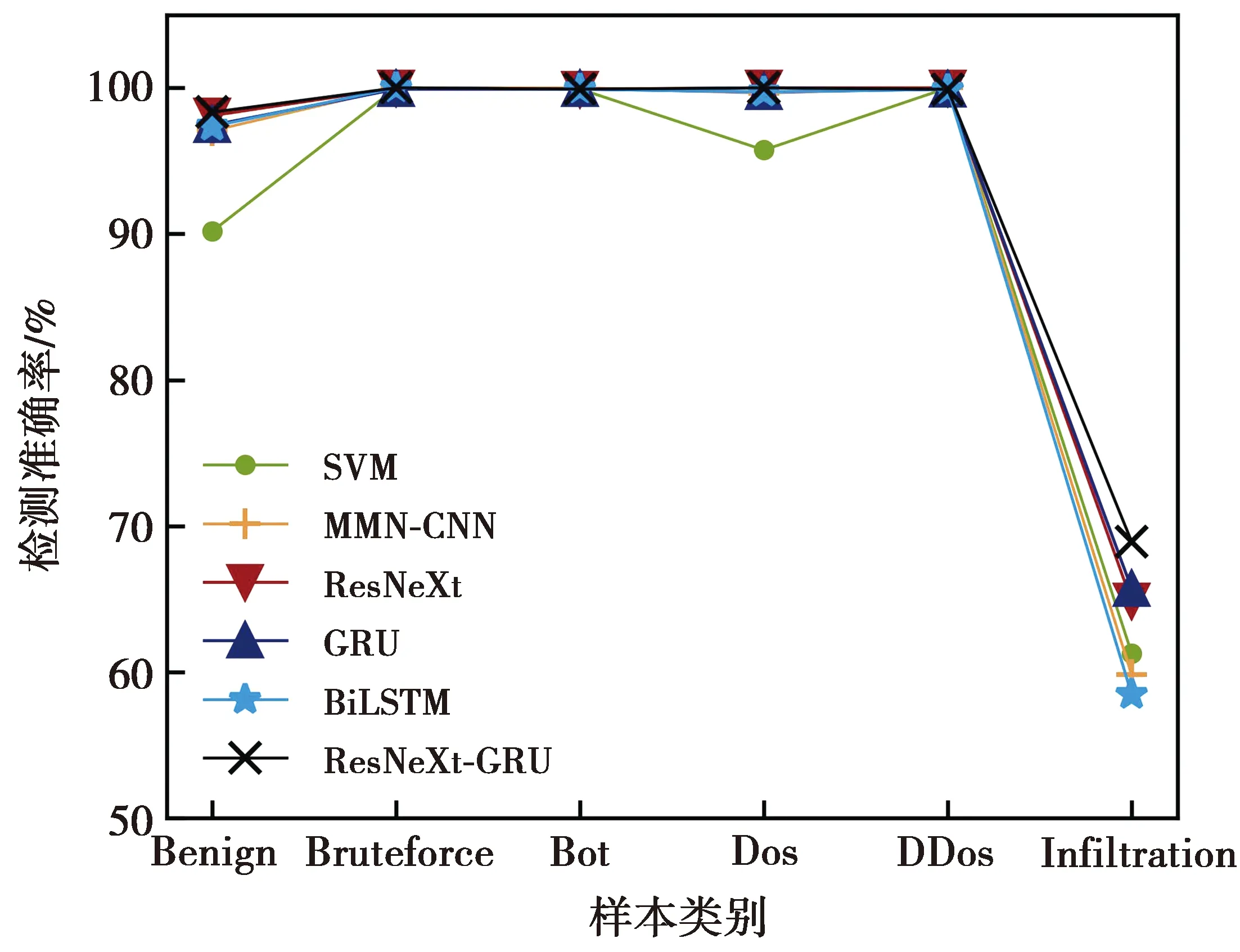
图7 不同模型对各类数据的检测准确率Fig.7 Detection accuracy of various types of data by different models
2.3.3 模型运行时间对比
表8展示了上述提及的异常流量检测模型在相同数据集下的运行时间,包括模型训练时间与模型测试时间。SVM由于其结构简单所以训练耗时最短,但面对大量复杂的流量数据时该模型的检测性能差且测试时间长,不满足工业互联网对异常流量数据快速且准确地检测的指标要求。ResNeXt较MMN-CNN具有更深的网络结构,其训练与测试时间相对较长。GRU是对LSTM结构的简化,BiLSTM由2个方向上的LSTM组成,所以,GRU较BiLSTM具有更少的参数量,其训练与测试时间更短。而本文模型使用ResNeXt提取流量数据的空间特征,并将其输出作为GRU的输入数据,相较于单一GRU模型的输入数据,其时间步较短,因此其训练时间较短。但融合模型较单一模型具有更高的复杂度,所以其测试时间稍长。结合表7综合考虑,本文提出的时空融合深度学习模型检测效果最佳。

表8 不同异常流量检测模型的运行时间Tab.8 Running time of different abnormal traffic detection models s
3 结束语
针对传统的异常流量检测方法难以适应大量复杂的工业互联网流量特征提取的问题,本文提出了一种基于时空融合深度学习的工业互联网异常流量检测方法。首先,分析工业互联网流量数据,通过数据变换、过采样等预处理操作为网络模型提供合理的输入数据;然后,对聚合残差变换块进行改进并构建了ResNeXt网络模块,实现从空间维度提取流量特征;最后,利用GRU模块对ResNeXt的输出数据进行时序特征提取,实现时空融合的流量数据特征综合提取,有效增强了对流量数据的检测效果。实验测试结果表明,本文提出的时空融合深度学习模型较单一模型有着更好的检测性能,其检测效果较传统的异常流量检测方法也有了较大提升,模型的准确率和F1值可达到94.70%和95.47%。后续的研究主要从2个方面展开:①优化模型结构,进一步提升对Infiltration类别数据的检测准确率;②有效降低模型的运行时间。
