基于像素特征的微表情识别
2022-12-28张家波甘海洋
张家波,甘海洋,李 杰
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
心理学家Ekman在分析一段采访抑郁症患者的视频时首次观察到微表情[1]。微表情是一种微妙的、不自主的面部表情,当人们试图掩饰自己真正的情绪时就会出现。因为能够揭示真实情感,微表情识别在情感接口、临床诊断、刑侦测谎、安全等领域有着广泛的应用前景,越来越多的研究者们开始关注微表情识别。
表情持续时间短且表达强度低,没有经过特殊训练的人很难发现并识别微表情。2002年,Ekman开发了第一个微表情训练工具(micro-expression training tool, METT)。经过METT训练,人工微表情识别能力有了很大提升。需要说明的是,即使经过METT训练也只有少部分的人才能正确区分它们,并且识别率只有47%。因此,开发自动微表情识别算法是非常必要的。为了帮助人们识别微表情,研究人员提出了很多微表情识别方法。局部二值模(local binary pattern, LBP)是一种能够有效描述图像局部纹理的特征,在图像处理领域被广泛应用。文献[2]通过提取图像序列的LBP特征用于表征面部表情。但是这种方法只提取了纹理特征,忽略了图像序列的上下文信息。
为了克服这个缺点,文献[3-5]在3个正交平面(x-t, y-t, x-y)提取LBP特征,将时间维度和空间特征相结合。为了更好地描述微表情的特点,文献[6]基于LBP-TOP提出了一种改进的算法,实验结果显示所提算法能有效描述面部表情变化。文献[7]借鉴LBP-TOP原理,提出具有时空域描述能力的时空韦伯局部描述子(spatio-temporal weber local descriptor,STWLD)来提取动态纹理信息,然而提取图像序列的特征会不可避免地引入冗余信息。此外,因为光流特征可以很好地表征运动信息,所以得到了广泛应用。文献[8]只提取面部感兴趣区域的光流特征用于识别微表情,从而消除无表情区域的干扰。文献[9]通过提取顶点帧加权的光流特征表征微表情。这两种方法在消除冗余信息的同时也会丢失一些局部特征。文献[10]提出了基于光流估计的面部动态映射来描述面部的细微运动,然而每个样本都提取10帧图像的光流需要消耗较长时间。文献[11]基于光流特征计算运动边界直方图描述微表情。文献[12]通过累积特定间隔内相邻的光流以计算运动强度,在一定程度上放大了运动强度。光流特征可以很好地描述面部运动信息,但是计算复杂比较耗时。
随着卷积神经网络的发展,越来越多的研究者开始将微表情识别与深度学习相结合。文献[13]用顶点帧微调经过预训练的resnet10网络,在SAMM[14](the spontaneous actions and micro-movements)和CASME Ⅱ15](the Chinese academy of sciences micro-expression) 数据集上取得了很好的识别效果。但是这种方法忽略了时间信息。为了提取更丰富的面部信息,文献[16]在经典的VGG16模型基础上对相邻两层的表情信息进行加权融合。文献[17-18]将CNN和LSTM(long short-term memory)相结合,CNN用于提取图像的空间特征,LSTM用于提取序列的上下文信息。文献[19-20]则使用3D CNN网络模型同时提取时空特征。由于单网络提取的特征难以有效描述面部的细微运动,所以研究者们开始搭建多流网络来提取更丰富的特征。文献[21-22]搭建双流网络提取不同的特征。值得注意的是文献[22]用性别信息辅助分类。文献[23]搭建了一个三流网络,将两个光流分量和光应变作为输入。文献[24]将人脸数据输入预训练的带有注意力模块的残差网络进行微调。文献[25]在文献[19]的基础上加入了遗传算法(genetic algorithm,GA)对模型学习的特征进行降维,只保留有利于分类的特征。实验结果表明遗传算法能显著提升深度学习模型的识别精度。基于深度学习的方法取得了明显的进步。需要说明的是,目前输入的特征并不能有效地描述微表情。研究更具表征性的特征是非常必要的,因此本文设计了一种新的特征提取方法,并结合CNN模型进行分类,如图1所示。

图1 基于像素特征的微表情识别Fig.1 Micro expression recognition based on pixel features
1 面部像素特征提取
面部像素特征提取的第一步是对图像进行灰度化操作以减少图像通道。灰度化是根据RGB三通道数值进行加权计算得到的,坐标为(x,y)的像素点进行灰度化操作的具体计算公式为
(1)
(1)式中:(x,y)表示像素点的位置;Red(x,y)、Green(x,y)和Blue(x,y)分别表示红色通道、绿色通道以及蓝色通道的数值;Gray(x,y)表示计算出的灰度值。
然后,使用Dlib算法[26]进行人脸对齐和面部裁剪,以消除背景区域的图像噪声。处理后的图像大小进一步归一化为224×224。由于3个常用的基准数据集规模较小,因而这里使用了数据增强处理,将图像进行镜像翻转以及随机旋转(-15°,15°)。
经过预处理以后,图像被读入程序以矩阵的形式呈现,表示为
(2)
(2)式中:Fi表示第i帧图像的像素矩阵;Puv(u=1,2,…,m,v=1,2,…,n)表示在坐标(u,v)处的像素值。当面部表情发生变化时,相应区域的像素值就会发生变化。将有表情的面部图像和无表情的面部图像做差后,面部的表情变化就会显示出来,表示为
Si=Fi-F1
(3)
(3)式中:Si表示第i帧图像与第一帧图像做差后的结果,处理后的效果见图2。
图2来自于CASME Ⅱ数据集中的sub01。三张图像分别为起始帧、顶点帧和做差后的结果。从图中可以看出相对于起始帧,顶点帧在眉毛处有较明显的变化。因此通过两张图像做差处理后动作变化被凸显出来。由于微表情的表达强度低,做差后表情变化也不明显,所以本文通过将每一帧图像与第一帧图像做差后的结果进行累加来突出这种变化,表示为
(4)
(4)式中:R表示整个图像序列处理完的结果;N表示图像序列的帧数。处理后的效果见图3。
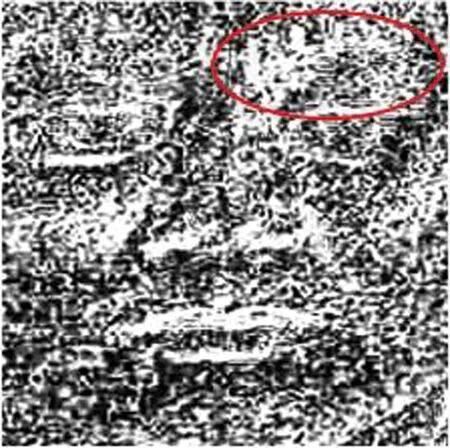
图3 面部像素特征Fig.3 Facial pixel feature
2 基于像素特征的微表情识别
文献[27]提出的VGG网络在图像分类领域显示出了优异性能,在微表情识别领域也被广泛应用[28-30]。本文将提取的面部特征输入VGG网络进行分类。由于微表情数据集规模较小,为避免过拟合,本文只使用了比较浅的网络结构,称之为Shallow VGG(SVGG)。SVGG模型共有12层,包含6个卷积层、3个池化层和3个全连接层。
卷积层用于提取图像的纹理和边缘特征。对于每个卷积层,卷积核大小设置为5×5,步长设置为1。卷积层使用的是relu激活函数。每层的核数分别为32、32、64、64、128、128。
池化层对输入的特征维度进行下采样,使参数减少一半。过多使用最大池层会丢失一些小而精确的特征,因此只在第2、4和6层卷积层使用最大池化层。池化层的窗口大小为2×2,步长设置为1。
前两层的全连接层具有2 048个结点,以减少模型中的参数量,防止过拟合。从全连接层输出的特征被传递到输出层,通过softmax函数进行分类。分类为第c类表情的概率为
(5)
(5)式中:y是输入xj的标签,C是总的类别数。利用损失函数和随机梯度反向传播(SGD)更新网络参数,对网络进行优化,本文使用的损失函数是交叉熵损失函数(crossentropy loss,CELoss),表示为
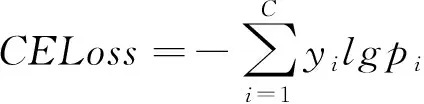
(6)
(6)式中:yi是标签,yi∈{0,1};pi是模型输出的预测值。
3 实验分析
3.1 数据集
本文实验将3个微表情数据集SAMM[14]、CASME Ⅱ[15]和SMIC[31]合并为一个数据集来使用,以创建一个真实的场景。受试者来自不同的背景;合成数据集包含442个视频,来自68个对象;情绪标签被重新分类为积极、消极和惊讶。数据集详细信息见表1。
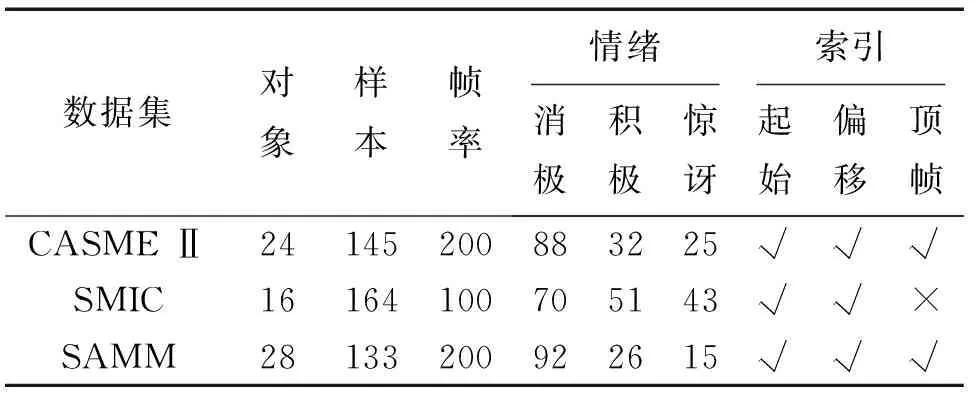
表1 数据集信息Tab.1 Dataset details
1)SMIC:数据集收集了16名参与者共164个视频片段,视频帧率是100 fps;提供了包括情绪状态、动作单元、开始帧、偏移帧索引等信息;但是,没有提供每个视频的顶点帧信息。样本分为3类:积极、消极和惊讶。
2)CASME Ⅱ:数据集由26名参与者共255个视频组成,视频帧率是200 fps。数据集提供的信息包括情绪状态、动作单元、起始帧、顶点和偏移帧索引。这些视频分为恐惧(2)、厌恶(63)、快乐(32)、压抑(27)、惊讶(25)、悲伤(7)和其他(99)等7类。为了在之后的实验中进行跨数据集评估,情绪状态被重新分为积极(快乐)、消极(压抑和厌恶)和惊讶等3类。
3)SAMM:数据集包含32名参与者共159个自发视频,视频帧率是200 fps。每个视频都被分配了它的情绪标签、动作单元、顶点帧、起始帧和偏移帧的索引。这个数据集共有愤怒(57)、幸福(26)、悲伤(6)、惊讶(15)、蔑视(12)、厌恶(9)、恐惧(8)和其他(26)等8类表情。为了在之后的实验中进行跨数据集评估,这些图像数据被重新分类,包括消极(愤怒,蔑视,厌恶,恐惧和悲伤)、积极(快乐)和惊讶等3个类别。
3.2 实验设置
模型参数设置如表2所示。为了减少过拟合现象,在两个全连接层后采用dropout正则化操作。dropout ratio设置为0.5,使其保持原输出的50%。实验使用K折交叉验证方法。数据集随机分为K份,其中K-1份作为训练集,剩余的作为测试集。本实验中K设置为5。

表2 模型参数Tab.2 Parameters of model
考虑到数据集分布的不均衡性,本文使用Acc(accuracy),UF1(unweighted f1 score)和UAR(unweighted average recall)3个指标来评估模型性能。
(7)
(7)式中:TP、TN、FP和FN分别是真正例、真反例、假正例和假反例。
(8)
(8)式中:C是表情的类别数,F1i为
(9)
(10)
所有实验都在Ubuntu 16.04系统上进行,深度学习框架选择Keras2.4.3与TensorFlow 2.2.0。模型在32 GB的NVIDIA Tesla V100 GPU上训练,训练设置的基本参数如表3所示。

表3 模型主要训练参数设置Tab.3 Main training parameters of the model
3.3 对比模型介绍
为了验证所提方法的有效性,引入8个模型进行比较,实验结果如表4所示。对比模型的简要描述如下。
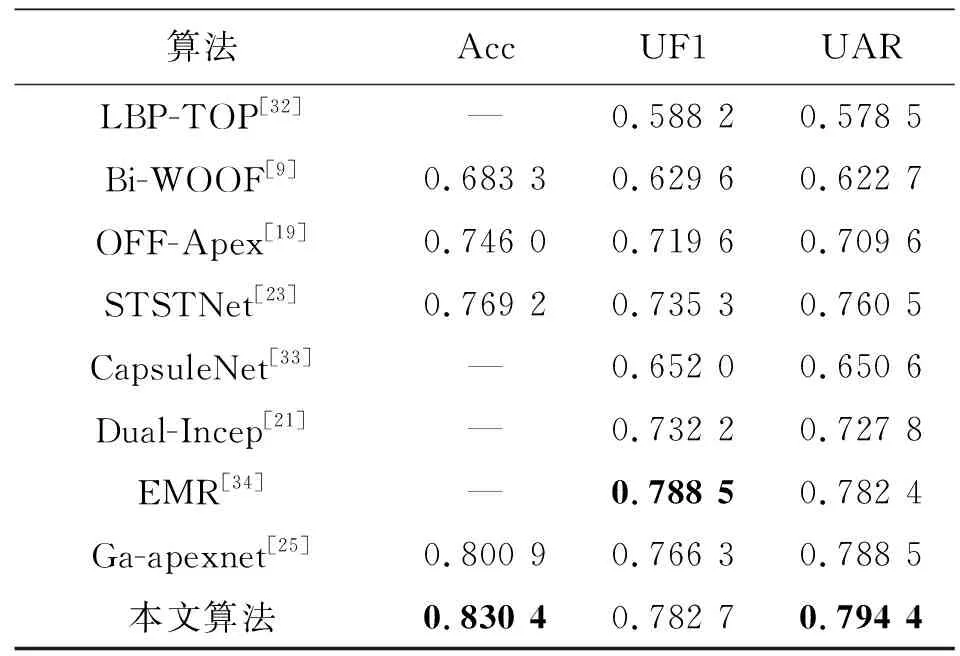
表4 实验结果对比Tab.4 Comparison of experimental results
1)LBP-TOP[32]:在3个正交平面上提取LBP特征来描述微表情,最后使用SVM进行分类。
2)Bi-WOOF[9]:提取顶点帧的光流特征作为输入,并对光流特征进行加权处理。
3)OFF-Apex[19]:提取顶点帧光流特征的垂直分量和水平分量,输入双流CNN网络进行分类。
4)STSTNet[23]:提取顶点帧光流特征的垂直分量、水平分量和光应变作为输入,然后采用三流CNN网络进行分类。
5)CapsuleNet[33]:将顶点帧进行灰度处理后输入胶囊网络进行分类。
6)Dual-Incep[21]:提取中间帧光流特征的水平分量和垂直分量,输入Inception搭建的双流网络
7)EMR[34]:提取顶点帧的光流特征输入Resnet18,并将最后一个卷积层的特征图分为上下两部分来分析。
8)Ga-apexnet[25]:在文献[19]的基础上加入遗传算法对特征进行降维处理。
对比模型中,LBP-TOP和Bi-WOOF是基线对比方法,OFF-Apex是一个经典的双流网络模型,Ga-apexnet则是在OFF-Apex基础上加入了遗传算法对模型提取的特征进行降维。另外4个模型是2019年微表情识别大赛中排名前4的模型。
3.4 结果分析
1)分类结果。表4显示,本文方法在3个评价指标上都明显优于两种基线方法。本文所提方法的UF1和UAR指标比基线方法LBP-TOP分别高19.45%和21.59%。Bi-WOOF和本文所提方法的差距也很明显。这是由于基于手工特征的方法提取到的面部特征不能有效描述微表情,导致识别效果并不理想。
与OFF-ApexNet相比,本文所提方法在3种指标上分别高8.44%、6.31%和8.48%。文献[21,23,33-34]是MEGC 2019(facial micro-expression grand challenge 2019)排名前四的团队提交的。与这4种方法相比,本文的UF1只比文献[34]低0.58%,UAR比4种方法都要好。本文的精度比STSTNet高了6.12%,当然更优于没有提交精度的另外3种方法。Ga-apexnet在OFF-ApexNet工作基础上加入了遗传算法,对提取的高级特征做了进一步筛选,相比原有的方法有了明显的进步,但是,其精度仍然比本文低,这是因为输入的传统特征限制了模型性能。
2)混淆矩阵。图4给出了本文方法在混合数据集以及每个单数据集上的混淆矩阵。由图4可以看出,整体上消极类的精度最好。这是消极类的数据在数量上占主导地位造成的。消极类的精度在SAMM数据集上达到了1,表明本文的方法可以很好地描述消极类表情;在SMIC数据集上则相对较差,这是因为该数据集的帧率较低,导致一些重要的面部信息没有被收集到。

图4 数据集混淆矩阵Fig.4 Confusion of matrix
3)不同特征对比。为了进一步验证所提出像素特征的有效性,本文在SVGG网络上对比了几种常用的图像特征。如图5所示。
因为SMIC数据集只有灰度图像,所以本文选择把3个数据集的顶点帧转换为灰度图像作为一种对比特征。此外,顶点帧的LBP特征和光流特征也被作为对比特征。对比试验中使用了相同的数据增强策略,通过镜像翻转和随机旋转(-15°,15°)对数据进行扩增。从图5可以看出,本文方法具有明显的优势,其Acc指标比灰度图像、LBP特征和光流特征分别高10.62%、11.41%和7.51%。这是因为本文提出的像素特征通过做差可以凸出面部的细微变化,之后的累加处理可以进一步放大这种差异,处理后的图像更有利于模型分类。

图5 不同特征对比Fig.5 Comparison of different features
4 结 论
针对跨数据集的微表情识别,本文提出了一种新的特征提取方法。通过对图像进行像素级处理,将面部区域的变化在一定程度上凸显出来。在3个基准数据集(CASME II, SAMM, SMIC)上的验证表明所提方法有效,比其他先进方法表现出更好的性能。未来的工作重点是对模型提取的特征进行筛选,提取最具代表性的特征。此外,当前的数据集都来源于实验室条件下收集的正向面部表情图像,尚无真实环境下收集的数据集。在实际应用过程中,面部表情图像往往存在姿态多样化、背景光照复杂等问题,下一步还需在真实环境下进一步验证所提算法的有效性。
