基于通道注意力机制的单目深度估计
2022-12-26马燕新万建伟徐国权
张 聪 马燕新 万建伟 许 可 徐国权
(1.国防科技大学电子科学学院,湖南长沙 410073;2.国防科技大学气象海洋学院,湖南长沙 410073;3.海洋探测技术湖南省重点实验室,湖南长沙 410073)
1 引言
人工智能发展的三个阶段:低级-计算智能、中级-感知智能、高级-认知智能。感知智能中最重要的一个部分就是数据的收集。数据收集就要求机器人对自己所处的环境进行信息采集,获得有用的信息。单目深度估计技术就是赋予人工智能系统从一张RGB 图像中获取世界坐标系下的三维深度信息的能力,是数据收集系统中的一项重要技术。深度指的是空间中的目标到相机的距离[1]。
获取深度信息的第一种方法是通过深度传感器直接获取对应三维空间中的信息,如LIDAR[2-6]、RGB-D 相机[7-10]。RGB-D 相机通过TOF、双目、结构光等技术直接获得RGB 图像的像素级深度图,但是存在很大的缺陷,如测量范围有限、室外测量时对光照敏感。LiDAR 在无人驾驶和工业感知领域中广泛应用于对深度的测量,但是LiDAR 操作复杂难以普及。深度传感器的大尺度和高功耗以及成本高的缺陷,导致它们很难广泛应用于无人机和其他小型机器人上。综上所述,传感器直接获取深度的方法存在技术复杂,成本高,容易受环境影响[11]的问题,且很难直接生成稠密点云数据,因此很难大范围推广使用。获取深度信息的第二种办法就是通过多视角的立体匹配,但是这种方法不能处理遮挡,特征缺少或者具有重复纹理的区域。
获取深度的第三种方法是基于深度学习的深度估计的方法,其主要分为多视图深度估计和单幅图像深度估计。
基于深度学习的多视图深度估计MVS(Multiview stereo)将多帧图像和位姿输入到CNN 网络中直接得到深度图,基于学习的特征匹配解决了部分无纹理透明、反光等传统深度估计方法难以克服的问题,但由于GPU 的内存限制仍难以重建高分辨率场景,且需要对相机进行精准的校准。最具有代表性的工作就是MVSNet[12],其在网络中首先在2D 图像上进行特征提取,后通过单应变换构造代价体,最后对代价体进行正则化,回归得到深度图。其他的多视图立体匹配的方法有[13-16]。
相比于多视角深度估计,单幅图像的深度估计方法不需要对相机进行精准的校准。主要的思路就是通过卷积神经网络拟合输入的RGB 图像和输出深度之间的关系。Eigen 等人[17]首次利用卷积神经网络解决单目深度估计的问题,该网络由全局粗尺度网络和局部优化网络组成,首先对初始深度图进行回归,再通过优化网络得到深度图。但其处理方式太过简单以至于得到的深度图细节恢复不准确,存在边界扭曲的问题。Hu[18]等人在网络中引入多层特征和多任务损失。Hao[19]等人利用连续的膨胀卷积保留特征图的高分辨率。
基于上述问题和思路,本文提出了一种基于通道注意力机制的单目深度估计算法,具体贡献为:
1)设计通道注意力层:本文依据不同的通道对深度信息的贡献度不同,对通道进行编码具体操作将RGB图像通过一个全连接层将通道数扩展为64,将通道进行编码后送入编码器解码器网络中去估计深度图。实验表明,对通道进行编码后,在远距离与摄像机平行的平面上的估计效果有显著提升且能恢复出深度图中更多的细节信息。
2)设计跳跃连接:为解决现有的深度估计的方法在进行特征提取的时候使用连续的卷积和下采样极大地压缩了分辨率导致在恢复深度图的时候边缘定位不准确的问题,本文建立编码器到解码器的跳跃连接,提高网络对原始像素信息的利用率,提高网络对深度突然变化的细节方面估计的效果。
3)实验情况:在NYU Depth V2数据集上进行不同算法的深度估计对比实验,具体结果在除去rms指标以外的所有其他指标上,本文提出的算法取得了最优结果。在得到的深度图上恢复的物体边界更清晰,远距离同一平面上深度连续。
2 网络结构设计
整体网络结构如图1 所示,网络整体采用编码器-解码器结构,其中编码器采用的是DenseNet-169[20],解码器通过双线性插值的方法将特征图的上采样,最终回归出深度图。为了提高编码器对图像特征的表征能力,对通道进行编码,首先通过自动学习的方式获得通道对深度信息的贡献值,利用贡献值的大小为特征通道赋予权值,从而让网络特别关注某些通道,学习到更多的信息。此外,为了解决连续的卷积和下采样极大地压缩了分辨率导致在恢复深度图的时候边缘定位不准确的问题,本文融合低层的位置信息和高层的语义信息,建立编码器到解码器的跳连接。
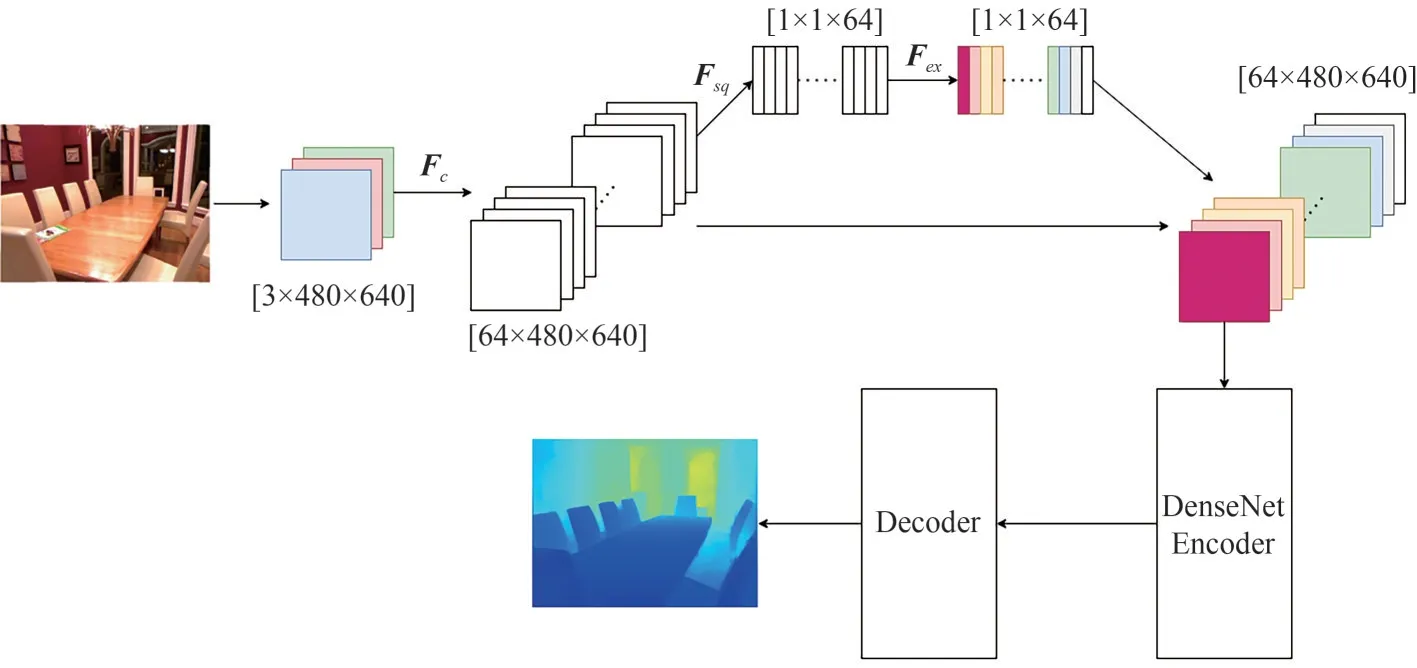
图1 网络整体架构图Fig.1 Overall network architecture diagram
2.1 通道注意力编码
在神经网络中,注意力机制通常是一个额外的神经网络,能够通过学习的方式选择输入的数据中较为重要的部分,在大量的信息中筛选出网络更加需要的信息[21]。本文的通道注意力编码主要分为压缩Fsq和扩展Fex两个部分[22],其作用是显式地实现对特征通道相互依赖关系的捕捉,选择对深度估计网任务更重要的通道。
进行通道注意力编码之前要通过标准卷积Fc完成维度的映射Fc:X→U,X∈RH'×W'×C',U∈RH×W×C,对应着网络中[3 × 480 × 640]映射到[64 × 480 ×640],Fc对应的公式(1):

其中,*表示卷积,vc=表示第c个卷积核,X=[x1,x2,…,xC'],uc表示U中第c个二维矩阵,下标c表示通道数。是一个2D 的卷积核,xs是第s个输入。由于输出是通过所有通道的和来产生的,所以通道之间的关系被隐式地嵌入到vc中,这些依赖性与空间的相关性混淆在一起,为了提高网络对信息特征的敏感度,因此重新校正通道编码,即通过压缩和扩展操作。
压缩操作Fsq的含义为:通过平均池化模块实现特征压缩,实现全局信息嵌入获取,具体而言为将H×W×C的特征层压缩到1 × 1 ×C。这属于空间维度的一种特征选择,由于全像素参与计算,所以使得该特征向量具有全局的感受野。通过压缩操作在网络编码器阶段得到更抽象的语义信息,有助于深度估计网络估计全局大平面深度的场景。

扩展操作Fex的含义为:在压缩操作之后通过扩展操作来完整的捕获通道维度上的依赖性,实现自适应重新校准的目标。具体而言就是将压缩操作后得到的全局特征描述符依次通过全连接层、RELU激活层、全连接层、Sigmoid激活层。通过扩展操作能使网络选取更加重要的通道信息,从而学习到场景中更多的细节信息。整个过程如下:

2.2 编码器-解码器
单幅图像深度估计的网络主要分为两个部分,第一部分是编码器,图像通过编码器提取特征,其中低层的是像素的位置信息,高层的是语义信息,然后送入第二部分解码器网络中,回归得到深度图。连续的卷积和下采样操作会损失很多像素信息,这是深度估计问题中需要解决的问题。本文利用跳跃连接的操作,将还没有经过下采样和卷积的特征图加到解码器网络中,提高网络对像素信息的利用率。通过这种方式,有助于深度图中的细节的恢复,即深度突然变化的边缘。编码器-解码器网络如图2所示。

图2 编码器-解码器网络Fig.2 Encoder-decoder network
编码器:编码器使用的是主流的分类网络DenseNet,并利用迁移学习,迁移在ImageNet[23]上的预训练模型DenseNet-169 的参数,减少网络模型的训练时间。编码器将输入的RGB 图片编码为特征向量。
解码器:将编码器得到的特征向量输入到解码器。解码器由编码器的跳连接和连续的上采样层构成。其中每个上采样层由2个双线性上采样块组成。最后编码器输出分辨率为320×240大小的深度图。
2.3 损失函数
深度估计任务中标准的损失函数就是定义预测的深度值和深度图的真实值之间的距离差别。不同的损失函数对深度估计网络的训练速度和估计性能的表现有很大影响。在深度估计文献[14-17]中有许多用于优化神经网络的损失函数。为了恢复场景物体的边界,本文定义的整体损失函数为L(y,)(公式(4)),其中利用预测的深度值和真实的深度值之间的差距对深度信息进行估计(公式(5)),利用像素梯度损失对深度图的高频信息(深度边缘)进行约束(公式(6)),利用结构相似性(Structural Similarity,SSIM)[24]图像任务的常用度量,来约束深度图的质量(公式(7))。

3 实验结果与分析
3.1 数据集和实验参数设置
目前,最常用、引用最广泛的单目深度估计数据集是NYU Depth V2[8],本文同样采样该数据集进行训练与测试。NYU Depth V2 数据集是一个面向室内环境的、主要用于场景理解RGBD 数据集。数据集中的RGBD 数据均是基于微软的Kinect 在不同室内环境采集到的,共包含1449 幅带有详细标注、深度进行补全的图像对,RGB 图像与深度图像的分辨率分别为640×480 和320×240,其中795 幅图像对用于训练,其余654 幅图像对用于深度估计测试。在训练阶段,将原始分辨率的图像作为网络的输入,同时将数据集中的真值深度图下采样到320×240,并且设置网络中深度图的深度范围为0~10 m。在测试阶段,网络将得到的一半分辨率的深度图进行2 倍上采样以匹配真值深度图的分辨率,同时对得到的深度图精度进行评估。
本实验基于显存为11 G 的2080ti 显卡进行训练;环 境:python 版本为3.7,cuda 版本为11.4,paddlepaddle 版本为2.2.1;初始参数设置:学习率为0.0001,块大小设置为2,训练轮数设置为20。
3.2 评价指标
为了评价和比较各种深度估计网络的性能,参考文献[19]中提出了一种普遍接受的评价方法,该方法有四个评价指标:不同阈值下的准确率(δ1,δ2,δ3)、绝对相对误差(AbsRel)、均方根误差(RMSE)、平均绝对对数误差(log10)。这些指标的具体公式为:

其中di是像素i的预测深度值,而表示深度的真值。N为具有实际深度值的像素总数,thr为阈值。
3.3 实验结果
3.3.1 公开数据集结果与分析
在NYU Depth V2数据集上进行不同算法的深度估计对比实验,定量实验结果如表1 所示,部分估计结果示例如图3 所示。由表1 可以看出,在除去RMSE指标以外的所有其他指标上,本文提出的算法取得了最优结果,具体而言,在δ1指标上取得了0.889的最优结果,在δ2指标上取得了0.978的最优结果,在δ3指标上取得了0.994 的最优结果,在AbsRel 取得了0.109 的最优结果,在log10取得了0.046的最优结果,证明了本文算法的有效性。与文献[27]的算法相比,本文算法在δ1、δ2、δ3三个指标上分别提升了7.3%、13.4%、0.2%。在AbsRel、RMSE、log10三个指标上,误差分别减少了5.5%、8.5%、10.8%。在网络结构上,本文算法相较于[27]建立编码器到解码器的连接,融合低层的像素信息和高层的语义信息,降低网络的损失,保证了本文算法的有效性。与文献[28]的算法相比,本文算法在δ1、δ2两个指标上,分别提升了5.0%、0.4%。在AbsRel、log10两个指标上,误差分别减少了12.8%、15.2%。在网络结构上,本文算法与[28]的区别在于在编码器中嵌入通道注意力,能够使网络自适应的学习通道的权重能够提高得到的深度图的精度,减少像素深度信息的误差,保证了本文算法的有效性。
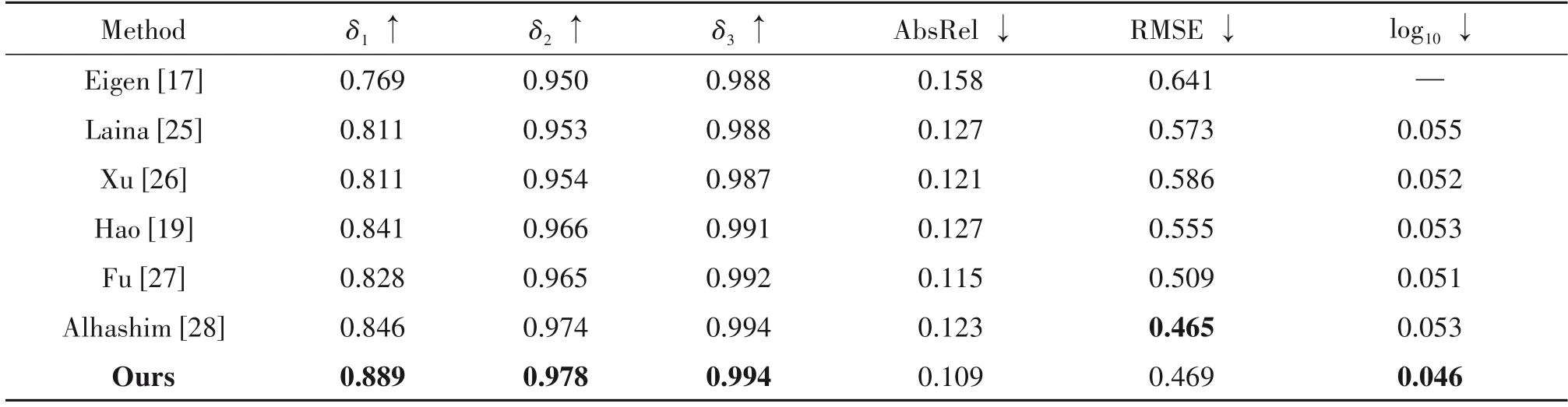
表1 单目深度估计网络性能Tab.1 Monocular depth estimation network performance
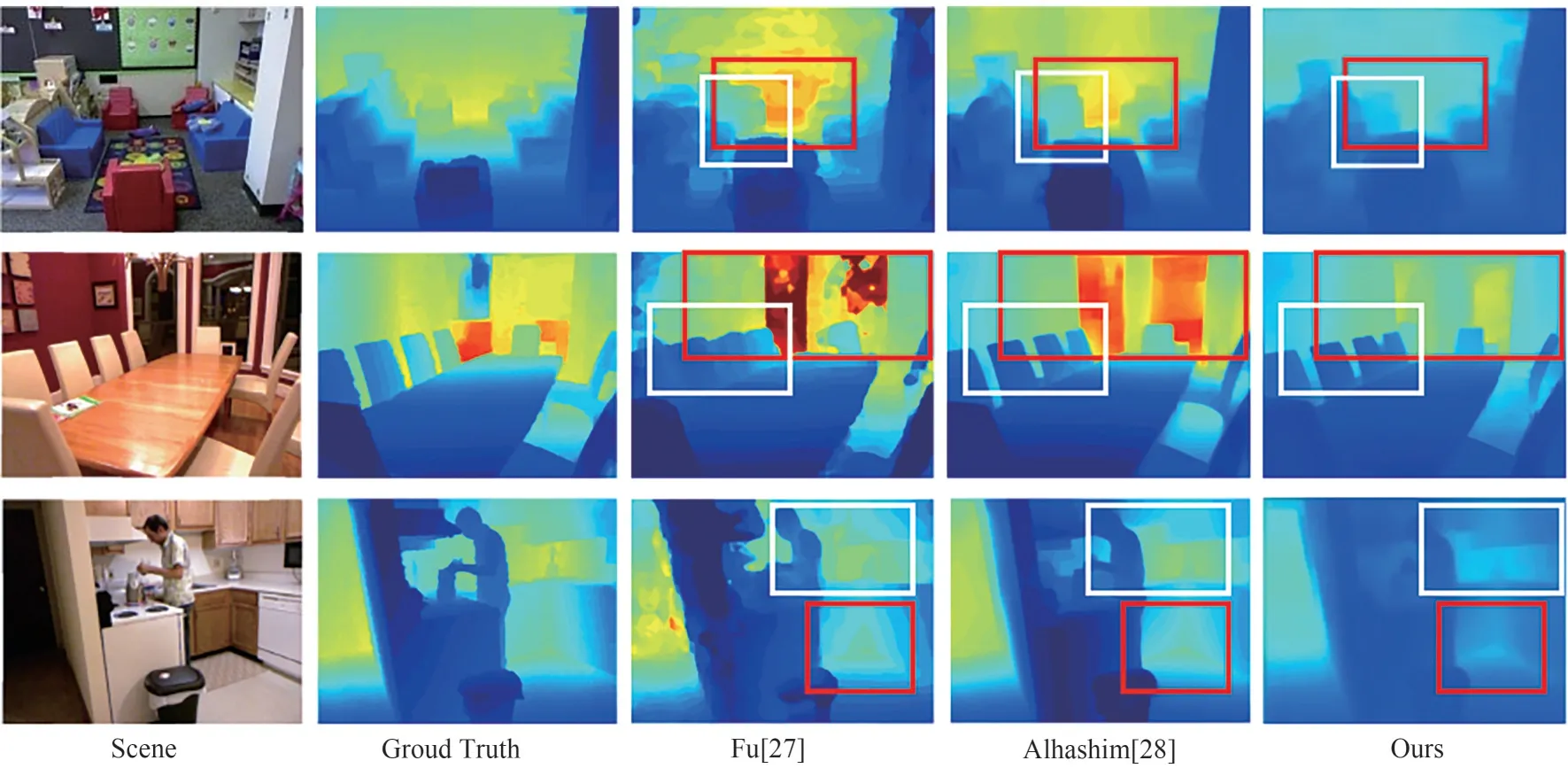
图3 深度图可视化结果图Fig.3 Depth map visualisation results
部分估计结果如图3所示,图中第一列为实验场景的RGB 图像,第二列为准确深度结果。后面三列分别为文献[27]、文献[28]以及本文算法的深度估计结果。不难看出,本文算法的估计结果更光滑,对场景细节恢复更好,同时在与摄像机平行的平面上获得的深度是连续的。如图中方框标注区域,该区域均是距离摄像机较远的位置且存在阴影或者透明区域,本文算法的估计效果均为最优。第一行方框标注中的沙发以及角落,文献[27]与[28]恢复效果均较比本文算法要模糊。第二行中,红色框标注出的柱子本文算法大致恢复出来并有所区分,白色框标注的椅子也完全区分开来。第三行中,白色框与红色框标注区域均存在直角角落区域,本文算法估计结果中角落区域十分明显,其余算法均将该角落恢复成平面区域了。本文算法对局部区域的细节学习更为充分,因而可以恢复出更多的细节结构。
3.3.2 真实场景测试结果与分析
用训练好的网络模型在真实场景下进行测试,结果良好,可视化结果如图4。该模型用于真实场景时,能够精确的恢复出物体的边界。同时在距离相机深度相同的平面上,获得的深度是连续的。具体而言,办公室和会议室场景中能够清晰恢复场景边界。由真实场景测试结果可知,该模型具有良好的泛化性,具有实用价值。

图4 真实场景测试结果Fig.4 Real scenario test results
3.3.3 消融实验结果与分析
为了验证本文算法中各个模块在深度估计中的性能,本节在NYU Depth V2数据集上进行消融实验,主要分析通道注意力机制、编码器结构、跳连接结构等。设置三个消融方式:①编码器端是否嵌入通道注意力;②编码器不同的层数对网络模型精度的影响;③是否加入跳跃连接。具体精度结果见表2。由表2可以看出,在没有跳连接和通道注意力模块的时候网络模型精度较低。当编码器的层数为169 时,网络模型在大多数评价指标上取得最高精度。详细结果分析如下:
(1)通道注意力机制分析
消融方式①对通道注意力机制对网络的性能影响进行分析,设计网络SE-Densedepth-161 与网络None SE 进行测试,SE-Densedepth-161 中包含有通道注意力机制,None SE 不含注意力机制,其实验结果如表2 中第三行与第一行所示,对应的示例结果为图5中第二列与第五列。在编码器中嵌入通道注意力后,在δ1、δ2两个指标上,分别提升了5.0%、0.4%。在AbsRel、log10两个指标上,误差分别减少了12.8%、15.2%。在编码器中嵌入通道注意力,能够使网络自适应的学习通道的权重能够提高得到的深度图的精度,减少像素深度信息的误差,保证了本文算法的有效性。
(2)编码器层数分析
消融方式②对编码器层数对网络的性能影响进行分析,设计网络SE-Densedepth-161、网络SEDensedepth-169和网络SE-Densedepth-201进行测试,SE-Densedepth-161 中编码器层数为161,SEDensedepth-169中编码器层数为169,SE-Densedepth-201中编码器层数为201,其实验结果如表2中第二行、第三行和第四行所示,对应的示例结果为图5中第二列、第三列和第四列。SE-Densedepth-169相较于SEDensedepth-161的实验结果,在δ1、δ2、δ3三个指标上,分别提升了5.7%、1.3%、0.2%。在AbsRel、RMSE、log10三个指标上,误差分别减少了21.1%、14.4%、19.5%。SE-Densedepth-169相较于SE-Densedepth-201 的实验结果,在δ1、δ2两个指标上,分别提升了0.5%、0.3%。在AbsRel、RMSE、log10三个指标上,误差分别减少了2.7%、2.5%、2.1%。当编码器的层数为169 时,网络模型在大多数评价指标上取得最高精度。编码器层数减少会失去精度,编码器层数为201 时不但造成网络参数过多的问题,也难以带来精度的提升。
(3)跳连接操作分析
消融方式③对跳连接操作对网络的性能影响进行分析,设计网络SE-Densedepth-169 与网络None skip connect 进行测试,SE-Densedepth-169 中包含有跳连接操作,None skip connect 不含跳连接操作,其实验结果如表2中第三行与第五行所示,对应的示例结果为图5中第三列与第六列。在δ1、δ2、δ3三个指标上,分别提升了15.4%、3.4%、0.6%。在AbsRel、RMSE、log10三个指标上,误差分别减少了51.3%、33.2%、45.6%。加入跳连接操作后,能够融合低层特征图像素的位置信息和高层特征图的语义信息提高逐个像素估计的精度,证明了本算法的有效性。

表2 消融实验性能结果比较Tab.2 Comparison of ablation performance results
部分消融实验的估计结果如图5 所示,图中第一列为实验场景的RGB 图片,第二列、第三列和第四列分别为编码器层数161、169 和201 的深度估计结果,第五列和最后一列分别为没有嵌入通道注意力和没有跳连接的深度估计结果。不难看出,SEDensedepth-169 的估计结果更光滑对场景细节恢复的更好。具体如图中红色方框标注的区域,该区域对场景中物体边界的恢复效果均优于其他结果。具体而言,第一个场景中沙发边界区域以及角落、第二个场景人手中的水杯、第三个场景人和人背后的电脑、第四个场景的门框和第五个场景左侧背景墙均比其他消融方案边界清晰。通过直观可视化可以得到三点结论:①没有嵌入通道注意力的可视化结果相比于其他结果,在与摄像机平行的平面上深度不连续且细节恢复不准确。嵌入通道注意力,即网络通过对特征通道的权重学习,有利于解决深度估计任务中与摄像机平行的平面的深度出现断层的情况且能学习到场景中更多细节;②层数少于169 的情况或多于169 的情况均会出现深度边缘的模糊,如第三行办公室人物的轮廓;③在没有跳连接时,得到场景的深度出现模糊。这表明跳连接能够提高网络对低层信息的利用率,有助于得到高精度的深度图。因此通道注意力模块和跳连接操作对同一距离像素点的深度和局部区域的细节学习更为充分,可以得到同一距离深度连续且细节更为丰富的深度图。

图5 消融实验结果可视化Fig.5 Visualization of ablation results
4 结论
本文利用对图像的通道进行编码,通过学习的方法重点关注对深度估计性能贡献较大的通道,提高编码器对图像特征的表征能力,然后送入编码器-解码器网络中去进行单幅图像的深度估计。编码器采用的是训练好的DenseNet169模型,能够避免重复训练,减少训练时长。在NYU Depth V2数据集上的测试结果与之前的方法相比,在与摄像机平行的平面上,获得的深度是连续的,在深度突然变化的区域中,获得的物体边缘更加准确。同时在真实数据集上进行测试,网络能够准确的得到场景中物体的边缘,证明了网络具有优秀的泛化性和鲁棒性,进一步推动了单目图像深度估计的实用化进程。
