基于ZYNQ的深度学习卷积神经网络加速平台设计
2022-12-26刘之禹王英鹤
刘之禹,李 述,王英鹤
(1.哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080;2.哈尔滨理工大学 电气与电子工程学院, 哈尔滨 150080)
0 引言
当今时代人工智能技术发展迅速,深度学习也是其中的重点领域之一,尤其是卷积神经网络用途最广泛,图像分类,目标检测等图像处理技术都需要它[1]。随着算法的不断优化,其网络性能也在不断提升,但其参数量也在大幅度增长,如VGG系列,残差网络系列,有的甚至可以达到几亿参数,面对如此庞大的数据量就需要提升神经网络的推理速度[2]。深度神经网络的硬件部署情况各有优劣,其在CPU上运行速度过慢,在GPU上运行虽然速度很快,但其功耗过高,并且价格昂贵,不适合部署在移动端设备上。而FPGA由于其高度并行性,可重构性,功耗低,并且相对于专用集成电路成本低,因此可以较好地实现卷积神经网络的加速[2]。但目前大部分研究人员设计的传统的硬件加速器,一般只能针对某种特定的神经网络模型进行加速。目前各种神经网络算法迭代速度快,硬件设计卷积神经网络架构较难,周期长,容易跟不上算法的快速发展,并且当将不同的神经网络部署在不同的硬件设备上时,要进行适配,性能优化,写算子代码等大量重复性工作,及其耗费时间人力,因此通用深度学习加速器应运而生。例如中科院和寒武纪研究的Diannao系列芯片[4],谷歌的TPU,英伟达的NVDLA,都是性能不错的通用型硬件加速芯片,可对多种神经网络进行部署加速。但在这些芯片在设计出来之后,还要解决如何让不同的深度学习框架训练出来的网络都能与该芯片兼容的难题,这就需要深度学习编译器来解决,它可以作为神经网络模型与硬件之间的桥梁,当今应用较多的深度学习编译器框架有TVM,GLOW等[5]。
本设计针对NVDLA的官方深度学习编译器进行了优化,采用了Tengine这一开源的AI推理框架来代替官方的编译器,并且在软硬协同的ZYNQ平台上设计了一套完整的深度学习加速器平台。
1 NVDLA介绍
NVDLA是英伟达官方于2017年发布的一款开源深度学习加速器[6],它可用于卷积神经网络的推理操作。它是一款高度可配置的CNN加速器框架,包含full,large,small版本,small版本规模最小,仅支持int8类型的运算,适合部署在嵌入式移动端设备上,并且可以在它上面部署不同的神经网络模型。总体框架包含了软件与硬件设计两个部分,small的系统结构如图所示。CPU与CSB接口相连,负责配置NVDLA的内部寄存器数据来完成所要运行的操作,IRQ接口为外部中断接口,NVDLA会向CPU发送一些中断信号。DBBIF接口与外部DRAM相连,负责从NVDLA中存入和取出输入输出数据,CPU也与DRAM相连获取操作指令数据,NVDLA系统框架如图1所示。

图1 small版本NVDLA系统框图
NVDLA内部包含寄存器配置模块,与CSB接口相连,卷积运算模块,卷积缓冲运算模块,数据点操作激活函数模块(SDP),本地响应规范化模块(CDP),池化模块(PDP),以及small版本不支持的重塑reshape模块和桥接DMA模块。其中每个模块均与内存接口模块相连,每个模块都有一个寄存器配置接口和一个数据传送接口,图2为NVDLA内部数据流向模块图。数据从卷积模块处开始输入,一路送至CDP模块,最后通过内存接口输出数据。
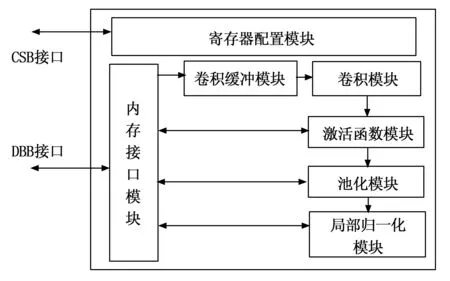
图2 small版本NVDLA内部模块
NVDLA框架整体包含软件与硬件两个层次,硬件即NVDLA的电路逻辑单元结构,是进行CNN推理运算的主要部分,主要通过硬件部分的高度并行性来加速神经网络的大量数据运算,其中包含了卷积运算,激活函数,池化,归一化4种算子。软件部分包括在CPU上运行的compiler与runtime两部分,compiler即深度学习编译器部分,负责接收由caffe训练的caffemodel模型,将其转化为一种中间表示(IR)形式,一种计算图表示结构,然后compiler再对该图进行一些网络结构的图优化,再转化为硬件层面上的抽象语法树结构,最后生成硬件可以识别的文件格式,便于不同神经网络在硬件上部署。runtime部分又分为UMD和KMD两个部分,UMD为用户模式驱动程序,通过接受compiler生成的loadable文件并解析。然后发送给KMD,即内核模式驱动程序,它接收到要进行推理的指定神经网络后,将硬件配置信息发送给硬件部分的配置寄存器,从存储器中取数据,执行所配置的寄存器操作,开始运行卷积网络并输出结果,NVDLA软件栈工作流程如图3所示。
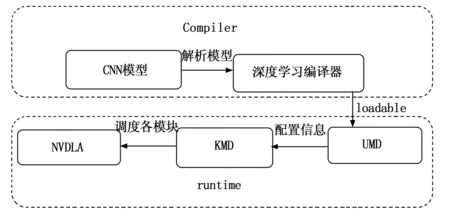
图3 软件栈流程
NVDLA硬件与软件部分代码完全开源,内容规范完整,尤其是它的硬件架构和软件编译器部分十分重要,为深度学习加速器的研究提供了极大的参考价值。
2 深度学习加速器
2.1 卷积运算特点
随着深度学习算法的不断优化,以及各种为了便携式嵌入式设备而研究的轻量型深度神经网络的出现,因此相应的深度学习加速器也成为了研究人员展开研究的热点。卷积神经网络更是深度神经网络中的主流方向,在深度学习加速器中,卷积相关的运算一般都占了一半以上的运行时间,绝大部分数据也都要进行卷积运算的过程,但卷积运算是十分规则的矩阵乘累加运算[7],并且其中涵盖着大量的数据重用[1],可以针对CNN的卷积运算的一致性而专门针对卷积运算设计相应的硬件电路结构[8],因此可以用FPGA或ASIC这种并行度高的硬件电路来设计卷积运算框架,来加速卷积运算[7]。卷积运算分为直接卷积运算与快速卷积运算,本设计只针对直接卷积运算,即将一个卷积核在输入图像上按指定步长滑动,卷积核的参数与相应位置的图像进行乘累加运算得到输出特征图的一个像素点的值。快速卷积计算包括FFT和Winograd变换等方法[10],通过优化卷积运算来减少耗费资源和功耗的乘法次数来提升卷积操作性能。卷积运算之后还会紧跟池化层也叫下采样层可用于降维并将特征信息进行压缩减小运算量,分为最大池化,最小池化,平均池化三重计算。然后有非线性层,它对卷积层或全连接层的输出施加激活函数来为网络引入非线性特征,来增强网络的学习能力,如Relu,sigmoid函数等。一般最后有全连接层,每一层的神经元都与下一层的每个神经元相连,全连接层的参数量一般占了网络中的大部分参数,全连接层的输出结果连接softmax函数,其结果为分类结果,卷积神经网络结构[10]如图4所示。
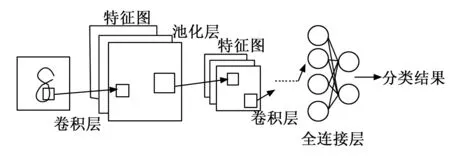
图4 卷积神经网络结构
式(1)为卷积神经网络计算的公式,O为输出特征图,I代表输入特征图,W为卷积核,b为偏置,C为卷积通道数,F为卷积核的宽和高,S为指定的步长。
O[n][x][y]=Relu(b[n]+

(1)
2.2 深度学习编译器
由于CNN算法框架的增多,如yolo,bert系列等,它们的网络结构不同,算子种类也不尽相同,算子组合方式多种多样,并且应用场景也随之被不断发掘。随着各种嵌入式移动设备广泛应用,因此就需要将各种深度学习算法部署在各种硬件上[12],如CPU,GPU,FPGA,NPU(Neural Nework Unit)等。以前的方法是由人工针对各种网络结构去做优化,写出算子代码,并且还要针对不同的硬件后端,还要去做优化测试和适配,而这会带来极大的工作量[13]。因此就要想办法高效的将不同的神经网络可以用一种较为容易的方法去部署到不同的硬件上,让它们之间形成一道通用的桥梁,因此深度学习编译器就被提了出来[10]。
广义的编译器技术在计算机中应用广泛,它是一种程序,将某种高级语言如Java,Go,Python等,转换为一个中间表示,再把他翻译成等价含义的另一种目标语言程序,一般为机器语言或低级语言。深度学习编译器的过程与其类似,因为深度神经网络结构本身抽象化之后就是一个有向图结构,图的每一个节点代表一个卷积计算过程,两个节点之间包含着所对应的数据,因此深度学习编译器主要是对计算图相关的优化,包括前端,后端[5]。编译器前端先实现一个解析的功能,先接受由深度学习训练框架训练好的网络,再把它们转换成一个中间的表示形式,构建了一个有向计算图的表示形式。再对该有向图进行硬件无关的优化,比如算子融合,层融合等优化方法,可以将计算图的结构变的简化一些,减少神经网络的推理运行时间。然后将优化后的图IR送给后端,后端与部署目标硬件关系十分紧密,负责基于特定硬件的优化,如对硬件在运行推理操作时的数据存取,内存管理,计算单元调度等操作做出一系列指定,生成针对目标硬件体系结构的优化代码[11]。有时不同的硬件对应着不同的体系结构,如嵌入式设备一般采用ARM体系结构[14],主机采用X86架构,以及现如今发展最为火热的RISC-V等[11],因此针对不同体系结构的硬件后端,设计编译器时也要有所区分。
NVDLA的官方也发布了相应的编译器,它只能接受caffe训练的模型,tensorflow与caffe都是目前流行的深度学习框架,而caffe训练框架已逐渐被其余训练框架取代[15]。NVDLA官方的编译器设计流程为,首先接受caffemodel后,通过解析器解析网络模型结构,生成IR中间表示,然后构建一个抽象语法树,也就是一个跟硬件架构无关的图优化结构,然后又根据硬件特点转化成一个跟硬件相关的的抽象语法树,该语法树包含了硬件的寄存器配置和内存分配信息,经过转化生成了一个针对硬件的图优化结构。与硬件无关的抽象语法树就是整个卷积神经网络各算子按顺正常序连接的形式。
2.3 Tengine深度学习推理框架的应用
Tengine是一个灵活,轻型的边缘AI计算框架,并且开源免费,它能够快速将深度学习前端模型部署到各种CPU,GPU,NPU平台,也具有深度学习编译器功能,可以进行模型转换,模型量化,多种端侧部署功能,可以高效地发挥端侧不同芯片的异构计算能力。它可以接收大部分训练框架如caffe,tensorflow等,通过序列化操作[5],转换成抽象计算图形式,然后再对其进行图优化操作,统一保存为一种tmfile格式的文件。如果有量化需求的话可以使用Tengine自带量化工具进行int8的对称和非对称量化两种量化形式,直接导入网络模型和训练集即可完成量化。在后端进行部署时,Tengine有着独特的自动切图机制,可将支持NPU的算子在NPU上运行,不支持NPU的算子切到CPU或其他设备上去运行,这充分发挥了设备的异构计算能力。对接后端时要注意,针对不同的后端设备,可以通过修改Tengine的接口函数文件,给硬件分配各节点和输入数据的内存以及切图模式,将已经转换为Tengine的与硬件无关的计算图变成与硬件相关的计算图结构。在不同的硬件后端上部署神经网络时,要添加该网络对应的算子,Tengine官方针对不同训练框架所对应的算子与硬件相关的就是根据硬件架构将每个算子映射到NVDLA的不同模块上的各模块连接方式。例如卷积模块包含一个输入与权重相乘的乘法模块和其相乘结果与偏置相加的加法模块,这样一个卷积算子就映射到了两个模块上,接着生成针对NVDLA硬件的优化代码,最后生成loadable数据流文件。然后是进行runtime阶段,负责硬件方面的配置和调度,它接收loadable文件,然后开始配置NVDLA的寄存器配置,内存分配,处理终端等配置。官方的编译器的缺点明显,比如现如今tensorflow,pytorch等已成为主流训练框架,而它只能接受caffe训练的框架,其次量化方面必须要下载TensorRT,并且还要写python代码来进行操作,过程复杂。此外官方的支持的算子数量少,官方源码难以修改去添加其他算子,而以上缺点采用Tengine推理框架可以得到较好的解决,官方编译器的工作流程如图5所示[5]。

图5 NVDLA官方的compiler流程
大部分都已经添加,因此可以直接从源码文档中寻找对应算子自行添加。Tengine在执行时,通过将待分类的图像输入给Tengine编译好的可执行分类程序,就可以输出分类结果。Tengine系统框架如图6所示。并且Tengine还提供了灵活的调试功能,它可以输出每个节点的输入输出数据,以及每个算子中的参数和设备运行算子的执行时间,为调试后端硬件功能提供了极大便利。

图6 Tengine系统框架图
本设计采用Tengine编译器代替官方的编译工具,即在原来官方编译流程中的通用抽象语法树处插入Tengine的编译器。在这之前仍然采用官方的编译器去生成中间表示IR,然后在通用语法树处接入Tengine编译工具,这样可以采用Tengine编译器来对计算图结构进行切图,图优化等操作,使NVDLA得到由Tengine优化的结构,将原来生成loadable文件的过程去掉,直接将tmfile文件交给runtime部分。与后端设备对接时要实现以下几个功能,首先要初始化数据,为优化的计算图结构开辟内存,然后要把数据送入NVDLA,以及取出NVDLA的输出数据,最后,释放空间内存,要写出以上函数来实现对接。Tengine代替原来编译器流程的结构如图7所示[14]。

图7 Tengine框架编译流程
2.4 量化技术
神经网络的参数量化技术,目前也是压缩神经网络的主流方法之一。神经网络训练时都是32位浮点数,量化是指将参数量化成16位8位4位等低精度格式,目前主流量化方案是int8量化,这样可以降低设备对于网络模型的存储压力[16],大量减少了数据访存次数和计算量同时降低了功耗[17]。并且也有研究表明,由于CNN对于噪声不敏感,因此int8量化后的网络与之前浮点32位的网络精度相差无几[18],并且硬件比较适合进行定点运算[19]。量化方案包含对称量化与非对称量化,对称量化是将待量化数据绝对值的最大值映射到新数据范围内的最大值,非对称量化是指将待量化数据的最大值和最小值映射到新范围内的最大值最小值,本设计针对对称量化展开研究。
量化的过程为先计算数据的最大最小值,计算出缩放因子scale,然后得到它的数据分布,最后对其进行数据截断。Tengine的量化原理与TensorRT类似,采用一种反量化方法,即将输入数据和权重进行int8量化,即把它们与scale相乘,偏置值不量化,然后输入数据与权重相乘,之后再转换成浮点32位,最后再与偏置值相加得到结果[20]。Tengine的量化工具经过官方研究表明其效果好于大部分NPU自带的量化工具。Tengine已经根据量化原理设计好量化工具,在工具库里可以找到,直接输入要量化的tmfile格式的文件模型执行量化程序来量化,量化时还需要加上训练集中的一部分数据来进行量化时的校准,使得量化结果更为准确。
3 实验结果与分析
3.1 实验环境介绍
本实验硬件平台采用赛灵思的ZYNQ UltarSCALE+系列的ZCU104开发板搭载双核ARM A53处理器,PC端使用vivado和petalinux开发软件和pycharm软件进行神经网络训练,采用tensorflow框架训练网络,PC端的中央处理器型号为i5-1035G1。
使用mnist手写数字训练集训练lenet-5网络和cifar-10训练集训练resnet-18网络,将训练好的模型分别采用NVDLA官方的深度学习编译器和Tengine的编译器去将该模型转化为NVDLA硬件可以接受的形式,在开发板上对测试集进行推理,最后分析实验结果。
3.2 NVDLA在FPGA上的映射
官方发布的NVDLA是针对ASIC设计的,现要将其映射到FPGA上。首先要将NVDLA中的RAM结构替换为FPGA上的BRAM资源,因为官方的代码描述的RAM是RTL行为级的,直接映射到FPGA上的话,会使的FPGA上的查找表资源来实现RAM,会浪费大量资源。然后还要关闭门控时钟,因为FPGA上的时钟资源与ASIC不同,如果采用ASIC的门控时钟行为,会导致保持时间违例[13]。
图8和图9为NVDLA的寄存器配置部分仿真图和数据传输接口部分仿真图。NVDLA作为从机,与其进行数据交互的CPU作为主机。如图8所示,当输入信号valid与NVDLA的给出的输出信号ready同时为高时,代表握手信号成功,write写信号被拉高,寄存器地址和要写入的数据发送给NVDLA。如图9所示,当valid信号和ready信号同时为高时,数据写入NVDLA的内部存储单元内。
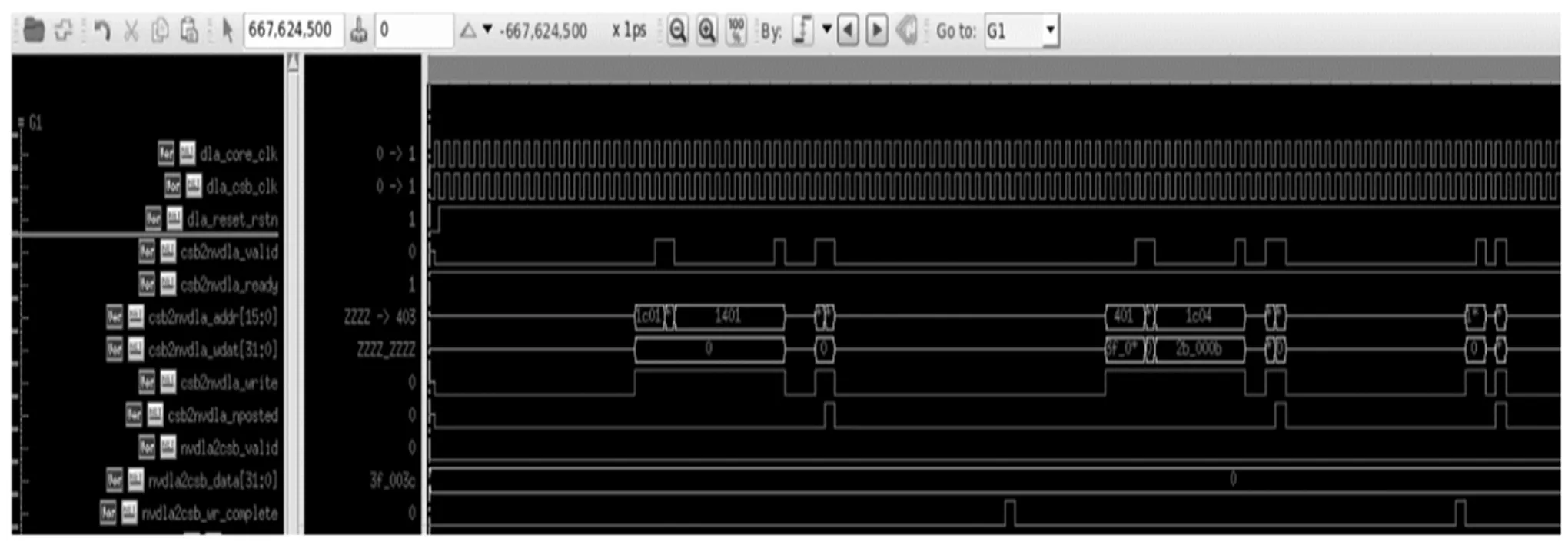
图8 NVDLA寄存器配置接口仿真图

图9 NVDLA数据传输接口仿真图
例化NVDLA模块后还需要将它与CPU相连,ZCU104上的ARM处理器可当作CPU使用。NVDLA的CSB接口上加一个CSB转APB协议的转接器模块,并且想要与ARM通信只能采用AXI协议,因此要设计一个APB转AXI的桥接模块将NVDLA与ARM相连。还要将csb_clk与core_clk两个时钟短接,它们负责寄存器的读写最后得出,时钟频率定为100 Mhz,时序符合要求,FPGA的资源占用情况见表1。还要生成xsa文件,用于在 petalinux中定制操作系统。
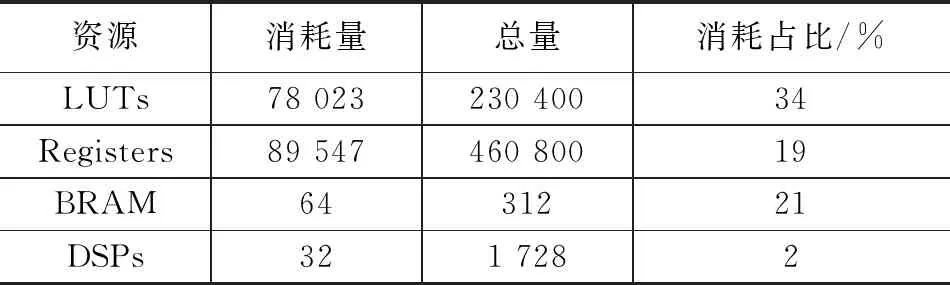
表1 资源使用情况
与NVDLA的加速任务,异步电路的存在使得vivado难以进行静态时序分析,因此要把它转换成同步时序电路。将各个模块集成连线,设计成完整的SOC系统,进行逻辑综合布局布线,得到时序符合要求的设计,图10为NVDLA总体电路结构图。

图10 NVDLA总体电路结构图
3.3 网络模型训练
在pycharm软件上采用tensorflow框架训练lenet-5和resnet-18两个网络。mnist手写数字数据集训练集60 000张图片,测试集10 000张图片,cifar-10数据集训练集有50 000张图片,测试集有10 000张图片,resnet-18网络比lenet-5复杂。训练模型的精确度如表2所示,均为32位浮点数形式,tensorflow训练模型输出为pb格式文件。

表2 PC端训练模型精确度
3.4 开发板推理网络模型对比
为了在开发板上完整设计NVDLA平台,还需要ZYNQ上移植一个ubuntu16.04的操作系统,存放在SD卡上,插到开发板卡槽上,打开开发板启动开关即可运行Linux系统。同时还要将由vivado生成的xsa文件导入petalinux软件中,定制操作系统镜像文件,将NVDLA设计增加到了系统的设备树中,这样就可以在Linux系统中使用NVDLA外设。整个平台的架构如图11所示,通过键盘输入Linux系统下的各种指令,在显示屏上查看结果。
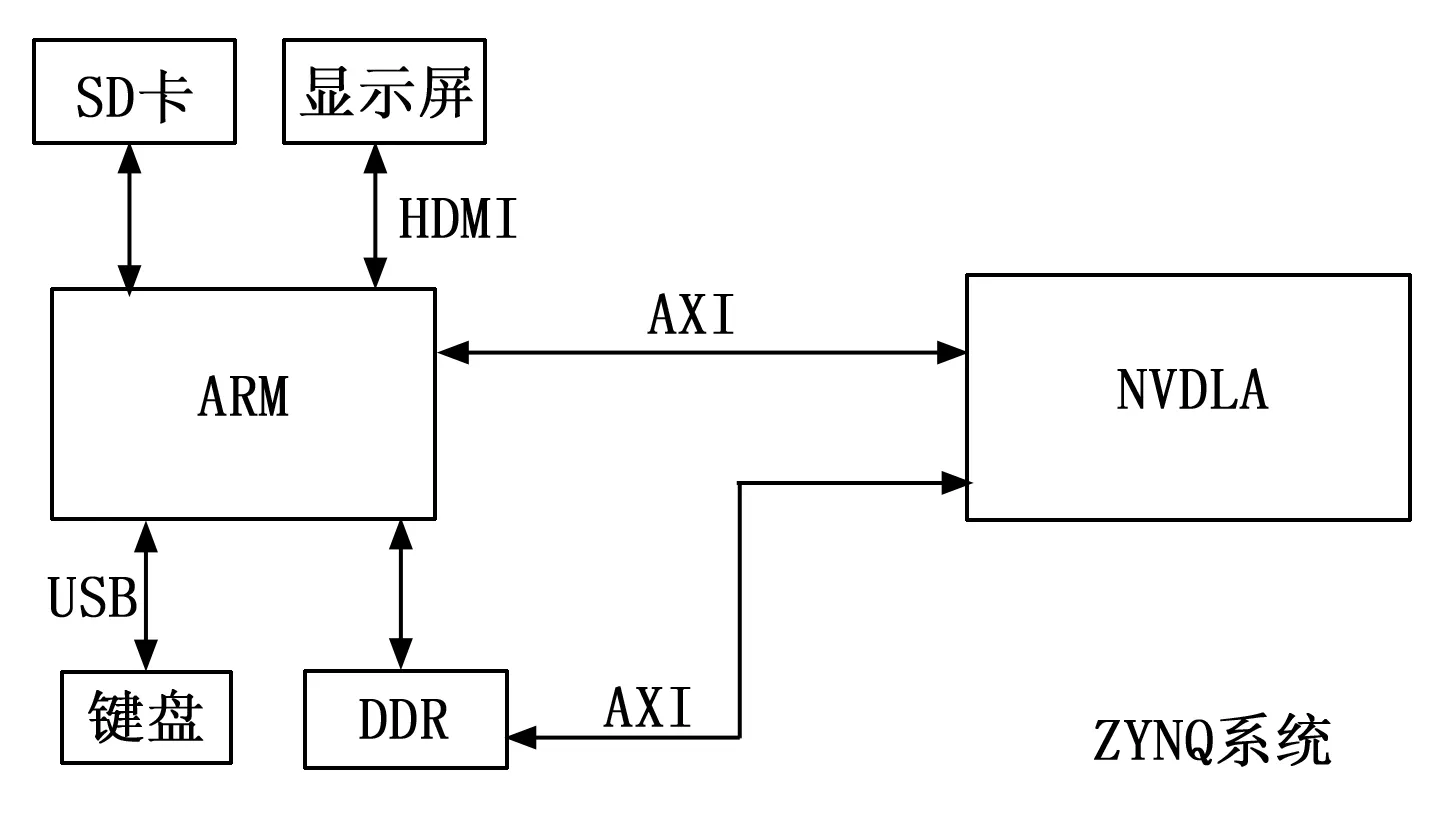
图11 系统架构图
采用NVDLA官方编译器与Tengine编译器分别优化转换以上两个网络,进行int8量化,将测试集的图片输入,分析它们的运行时间后再将两个网络在CPU上运行,得到数据分析对时间和准确率,然后并将它们对比,结果如表3所示。

表3 不同方案数据对比
如表3对比可知,由于lenet-5网络简单,因此使用不同编译器的网络优化效果不明显,对比使用CPU推理网络有大约30%的加速效果。对于resnet-18网络,由于该网络较为复杂,因此可以明显看出采用Tengine的编译器优化结构效果要好于采用官方编译器,速度增加了约2.5倍,对比CPU增加了约3.7倍,并且功耗也比CPU低约6.5倍。

表4 准确率对比 %
量化后的测试集准确率如表4所示,由于采用官方编译器与Tengine编译器的量化方案不同,因此准确率会有一些差别,与表2中原来的32位浮点数形式的准确率对比,误差在合理范围之内。
4 结束语
针对多种卷积神经网络实现硬件加速时,在不同硬件后端部署时遇到的效率低的问题,提出了采用Tengine这一深度学习推理框架的方案来解决该问题,在ZYNQ平台上部署了完整流程的深度学习加速器。又对深度学习编译器和NVDLA特性结构进行研究,将Tengine这一框架应用于NVDLA上,使用Tengine的编译器来将CNN模型与NVDLA硬件部分对接。通过实验在ZCU104开发板上搭建了NVDLA这一加速器平台,实现了lenet-5和resnet-18两个网络的图像分类任务。实验结果表明使用Tengine工具链的深度学习加速器可以支持接受多种深度学习训练框架模型,并且其图优化结果要好于官方的深度学习编译器,使得卷积神经网络推理速度更快,量化工具等其余功能使用起来也很方便,对于研究卷积神经网络的落地应用有一定的研究意义。
