基于归一化回归算法的多参数模型用于原发性肝癌微小血管侵犯预测的研究*
2022-12-26王孜怡黄晨军高春芳曹宏伟
王孜怡,肖 潇,黄晨军,童 林,高春芳,,曹宏伟△
1.海军军医大学附属长海医院信息科,上海 200438;2.上海中医药大学附属岳阳中西医结合医院检验实验中心,上海 200437;3.上海东方肝胆外科医院检验科,上海 200438
肿瘤是严重危害人群健康的公共卫生问题。 根据最新发布的美国2022流行病学数据,肿瘤是仅次于心脏病的第二大致死性疾病,是60岁以上人群病死的重要病因。在排名前5位的肿瘤相关死亡病因中,男性肝癌位列第5位,其中在40~59 岁人群则位列第4,在60~79岁位列第5,提示肝癌是40~79岁这一中老年龄段人群的重要肿瘤相关死亡病因[1]。全世界新发肝癌的50%病例在中国[2],在我国肝癌是仅次于肺癌的高发病率和高病死率肿瘤[3]。我国年龄和性别分层的流行病学数据表明,肝癌在15岁以上男性肿瘤的发病率和病死率中都位列前茅[3]。我国80%以上的原发性肝癌与乙型肝炎病毒(HBV)感染有关,虽然近年来我国HBV表面抗原(HBsAg)阳性率呈现下降趋势,但是由于HBsAg携带者存量巨大,所以HBV感染作为原发性肝癌的高危因素在我国肝癌发病中仍然长期占据高位[4-5]。目前早期肝癌的5年生存率高达70%以上,而晚期肝癌5年生存率不足10%[6],因此早期发现、精准诊断和治疗是提高生存率、降低病死率的重要环节。微小血管侵犯(MVI)是肝癌具有侵袭性、转移性生物学行为的组织学标志,可用于预测肝癌的预后、复发、生存,发生肝内、肝外转移时,肝癌细胞沿着血管迁移,故MVI也是临床上肝癌复发的重要病理指标[7-9]。通常MVI信息的获取需通过手术标本的组织学分析,有严格的手术采集要求和标准,包括准确采样肿瘤与非肿瘤交界面的组织标本等。若能术前精准预测,或者对于未接受手术治疗者进行MVI预测,则对患者精准治疗方案的制订和预后判断有重要意义。本研究基于临床常用的3种肝癌标志物——甲胎蛋白(AFP)、甲胎蛋白异质体(AFP-L3)、异常凝血酶原Ⅱ(PIVKAⅡ),对检测结果数据采用归一化处理并建模后,用于辅助判断原发性肝细胞癌(HCC)患者是否发生MVI。
1 资料与方法
1.1一般资料 本研究纳入2016年1月至2017年12月在上海东方肝胆外科医院住院并接受HCC手术治疗的患者1 314例,这些患者均经术后病理检测证实为HCC且在未行手术切除之前完成了AFP、AFP-L3和PIVKAⅡ的检测,并剔除了正在使用维生素K和华法林治疗的研究对象,以免对PIVKAⅡ检测结果产生干扰。本研究经上海东方肝胆外科医院伦理委员会批准,所有患者知情同意。
1.2仪器与试剂 AFP检测方法为电化学发光法(Roche),检测设备为罗氏 Cobas e601 全自动免疫分析仪,检测试剂为罗氏诊断公司原装配套试剂。AFP-L3采用凝集素亲和富集加全自动化学发光检测,凝集素亲和富集试剂盒为北京热景生物技术有限公司产品,富集后得到的核心岩藻糖基化蛋白检测方法同上述AFP,作为AFP-L3数值。计算AFP-L3/AFP的百分比[10],参考试剂盒说明,>10% 定义为AFP-L3 阳性。PIVKAⅡ 采用酶化学发光法检测,检测设备为富士瑞必欧的LUMIPULSE G1200全自动免疫分析仪,试剂为配套原装试剂。
1.3方法 对数据进行缺失值处理,对缺失值的处理有3种:删除记录、数据插补和不处理。本研究中采用删除记录的方法。采用逻辑回归(LR)方法,对3项常用的肝癌标志物AFP、AFP-L3、PIVKAⅡ建模,使用Python进行数据集7∶3(建模组∶验证组)的划分并获得数据的MVI预测效率。
1.4统计学处理 所用数据采用Python语言进行统计。归一化处理则将完整的数据缩放在(-1,1)区间内。非正态分布的计量资料以M(P25,P75)表示,两组间比较采用非参数Mann-Whitney检验。计数资料以例数或百分率表示,比较采用χ2检验。以P<0.05为差异有统计学意义。在模型参数方面进行了调整:(1)为防止过拟合,进行正则化处理;(2)使用梯度下降法优化损失函数并调整标本权重以提高模型预测能力。
2 结 果
2.1入组患者的临床基本信息 依据入组的原发性肝癌组织病理学MVI结果,将所有入组的1 314例HCC 患者分为以下两组:无MVI组(MVI-0组)和存在不同程度MVI的MVI-1+MVI-2组即MVI-1+2组,两组的基线信息见表1。在纳入的1 314例HCC患者中,存在MVI的患者共616例,占46.9%。

表1 入组的HCC患者基本临床特征
2.2模型与诊断 使用Pycharm软件建模,自建LR模型公式,即1.08×AFP+0.34×AFP-L3+0.26×PIVKAⅡ。使用Python进行数据集7∶3(建模组∶验证组)的划分并预测MVI结果。
2.3模型对MVI的预测价值 建模组中LR模型诊断MVI的AUC为0.647,与单独采用AFP诊断MVI的相同,见表2。但在验证组中,与AFP、AFP-L3、PIVKAⅡ检测相比,LR模型诊断MVI的AUC为0.720,AUC高于单独应用AFP-L3和PIVKAⅡ诊断MVI的AUC(0.651、0.601),也略高于单独应用AFP诊断MVI的AUC(0.700)。当LR模型最佳截断值为-1.16时,诊断MVI的灵敏度为77.1%,准确度为64.7%。 见表3。
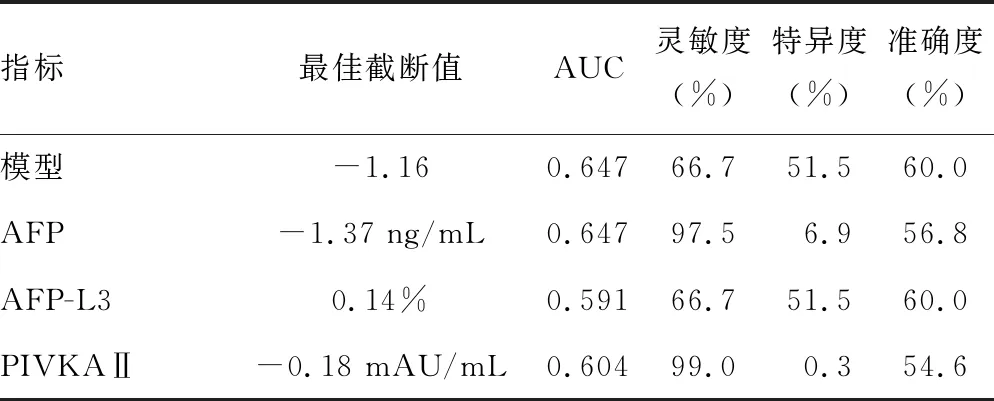
表2 建模组各指标对MVI的诊断性能
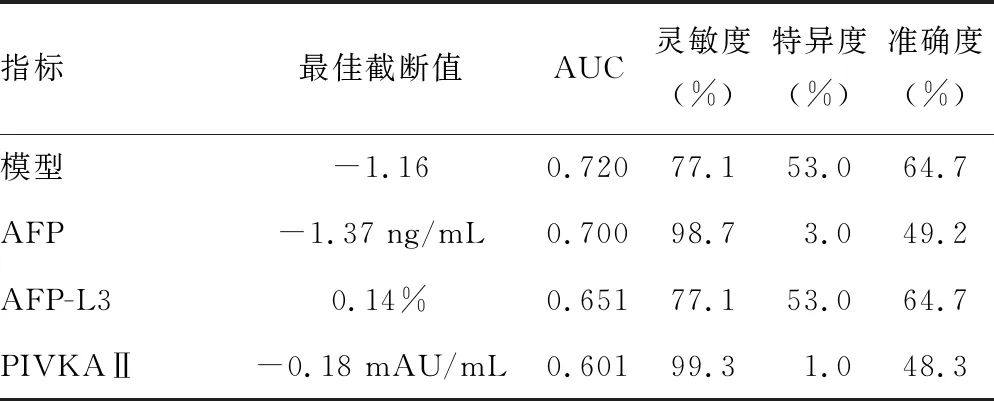
表3 验证组各指标对MVI的诊断性能
3 讨 论
本研究主要基于目前临床常用的肝癌标志物AFP、AFP-L3、PIVKAⅡ开展对于HCC患者是否存在MVI的非创性预测,之前已有类似的研究[9]。本研究通过数据归一化处理和LR,建立了多参数诊断模型,用于HCC患者MVI的预测,预测患者是否发生MVI的AUC达到0.720,高于单独应用AFP-L3和PIVKAⅡ(0.651、0.601),也略高于单独应用AFP(0.700)。术前MVI的非创性预测有助于辅助临床制订更为精准的手术治疗方案,而对于非手术治疗的MVI预测,则可辅助临床判断HCC复发、转移及预后。
本研究中选用AFP、AFP-L3、PIVKAⅡ的依据是基于目前国际和临床上已获得一定认可用于HCC诊断的GALAD模型。 GALAD模型最初于2014年由JOHNSON等[11]建立,2016年BERHANE等[12]基于国际多中心队列进行了充分验证,结果提示其可用于HCC诊断并具有较单个指标更好的诊断性能。GALAD模型包括性别(G)、年龄(A)以及3种血清学标志物AFP(A)、AFP-L3(L)、PIVKAⅡ(D)共5项。 本团队在前期国内多中心队列研究中证明其对于HCC的早期诊断具有很好价值[12-13],但GALAD模型用于MVI的预测效果尚有限[13]。本研究在预实验中发现,加入性别、年龄并没有显著提升该模型的效率,因此本研究仅针对临床常用的指标展开预测MVI的建模性和验证性研究。
本研究采用的建模方法是LR方法,LR是一种线性分类器,可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值代入回归方程可以求出应变量的估计值,从而可以进行预测等相关研究。LR方法是目前临床多参数建模性研究中的最常用方法[14]。目前已经获得NMPA注册证的微小RNA panel就是采用了LR模型[15],其作为HCC标志物已被纳入2022版的中国原发性肝癌防治指南[5]。
数据缺失和数据标准化处理是建模性研究中的关键问题。数据缺失主要包括记录缺失和字段信息缺失等情况,对数据分析有较大影响,使结果不确定性增加。通常对缺失值的处理有3种:删除记录、数据插补和不处理。本项目采用删除记录的方法,最大程度减少了因数据缺失对模型稳定性带来的影响。在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。目前数据的标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,但在数据标准化方法的选择上,还没有通用的法则可以遵循。其中最典型的方法就是数据的归一化处理,即将数据统一映射到(-1,1)区间上。归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。各个特征对结果做出的贡献相同时,可以比较出参数之间分类效果的差异。归一化后有提升模型的收敛速度和精度的优势。采用归一化处理数据后,本研究中所建立的模型较本团队前期建立的MVI模型的预测效率有了明确提升[16]。在本研究中,其应用优势还在于能缩小由于不同临床实验室采用不同检测系统可能对模型稳定性带来的影响,这也是本研究的亮点之一。
综上所述,本研究基于临床常用的3项肝癌标志物(AFP、AFP-L3、PIVKAⅡ),通过数据归一化和LR建模,可辅助临床进行HCC患者发生MVI的预测,对于HCC患者的精准施治和临床预后判断提供了全新手段。未来需要进一步多中心研究验证该模型的稳定性和有效性,并在实践中不断优化。
